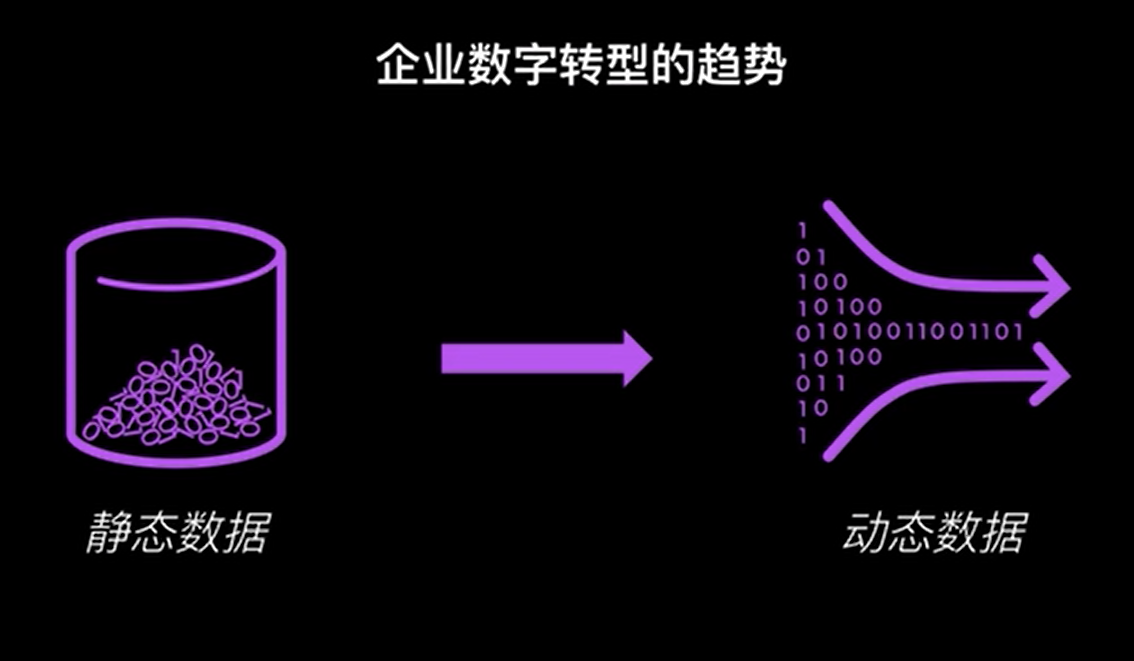
 LinkedIn数据驱动主要有两点领悟,其一是强调动态数据有效性要远远大于静态数据,其二是要利用所有数据化信息而不仅仅是交易核心数据。
本篇主要从Kafka诞生背景开始,一步步引出Kafka的Connect组件,而Confluent也免费开源100多种Connector,最后用一个完整的Source和Sink例子带入门如何在分布式模式使用Kafka的Connector
概述
背景
LinkedIn数据驱动主要有两点领悟,其一是强调动态数据有效性要远远大于静态数据,其二是要利用所有数据化信息而不仅仅是交易核心数据。
本篇主要从Kafka诞生背景开始,一步步引出Kafka的Connect组件,而Confluent也免费开源100多种Connector,最后用一个完整的Source和Sink例子带入门如何在分布式模式使用Kafka的Connector
概述
背景
Apache Kafka 是最大、最成功的开源项目之一,可以说是无人不知无人不晓,在前面的文章《Apache Kafka分布式流处理平台及大厂面试宝典》我们也充分认识了Kafka,Apache Kafka 是LinkedIn 开发并开源的,LinkedIn 核心理念之一数据驱动主要有两点领悟,其一是强调动态数据有效性要远远大于静态数据,何为动态数据和静态数据,可以简单理解静态数据则为我们目前基于各种各样的数据库或文件系统等存储系统,而动态数据是基于事件驱动的理念如现在主流Apache Kafka和Apache Pulsar。其二是要利用所有数据化信息而不仅仅是交易核心数据,非交易核心数据量比交易核心数据量往往要大100倍都不止。作为当时开发出Apache Kafka实时消息流技术的几个团队成员出来创业,其中Jay Kreps带头创立了新公司Confluent,还有饶军也是Confluent联合创始人之一,而Confluent的产品基本都是围绕着Kafka来做的。基于动态数据理念是Apache Kafka 到Confluent企业化之路的主引线。
Confluent公司官网地址 https://www.confluent.io/
Confluent 开创了一个新的数据基础设施,专注于他们动态数据 —— 本质上是数据流(流动中的数据),适合实时数据,公司的使命是“让数据动起来”。Confluent 以 Kafka 为核心,是将其商业化最成功的领先独立公司之一。对数据的集成和连接进行实时操作,如果要真正利用Kafka,使用Confluent是目前最佳事先方案。 官网主要产品如下
而核心的商业化产品为Confluent Platform(可以在本地进行部署)和Confluent Cloud(托管在云中,并在混合云基础设施的环境中工作)。
- Confluent Platform是一个流数据平台,实现数据流集成,能够组织管理来自不同数据源的数据,拥有稳定高效的系统。Confluent Platform 很容易的建立实时数据管道和流应用。通过将多个来源和位置的数据集成到公司一个中央数据流平台,Confluent Platform使您可以专注于如何从数据中获得商业价值而不是担心底层机制,如数据是如何被运输或不同系统间摩擦。具体来说,Confluent Platform简化了连接数据源到Kafka,用Kafka构建应用程序,以及安全,监控和管理您的Kafka的基础设施。
Confluent Platform又分为三块
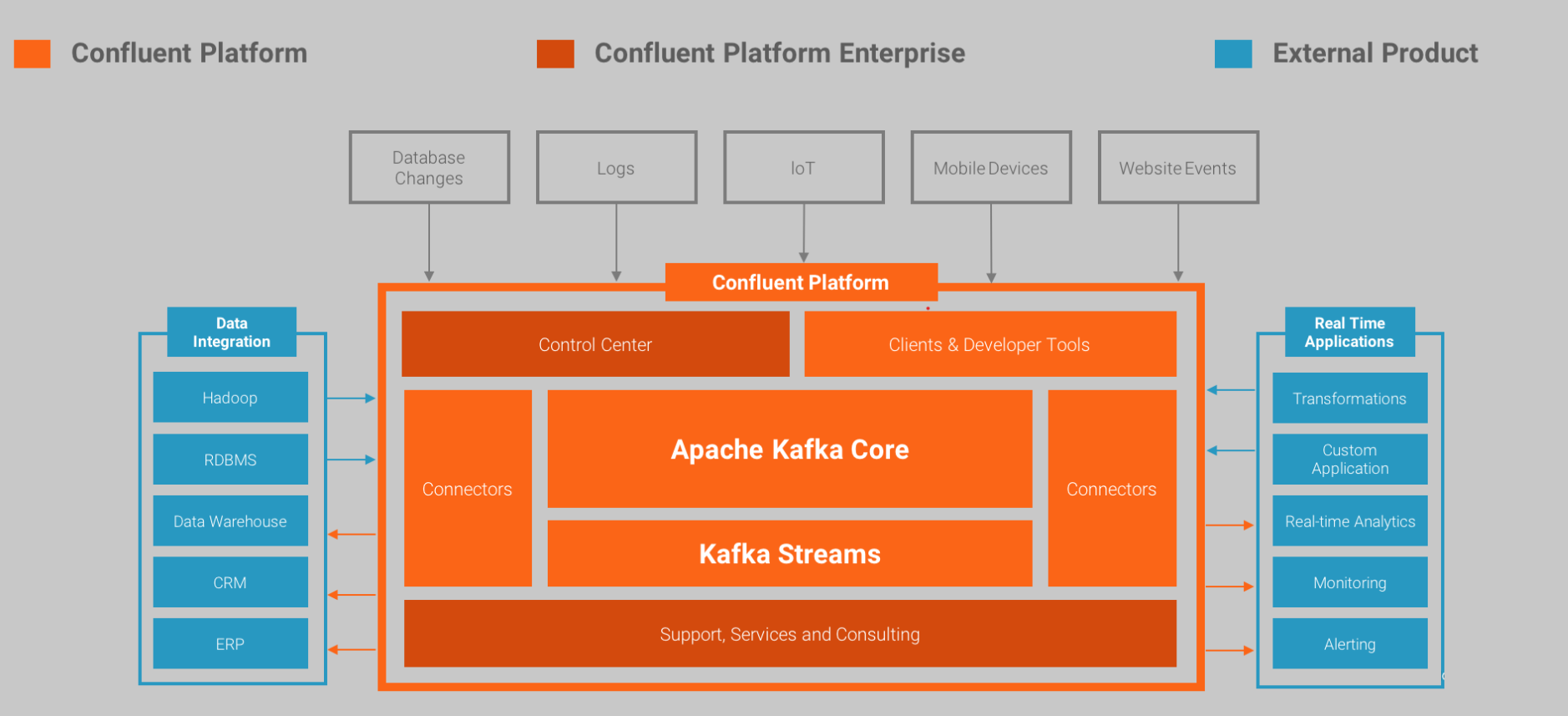
提供了KafkaSteams和KsqlDB企业级Kafka应用特性
- 完整:利用开源 Apache Kafka 的功能和我们重要的专有功能,为动态数据创建了一个完整的平台。使用特定工具(例如 ksqlDB)并行移动和处理数据,ksqlDB 是一种原生的动态数据数据库,允许用户仅使用几条 SQL 语句以及 100 多个连接器来构建动态数据应用程序。
- 无处不在:已经构建了一个真正的混合和多云产品。可以在客户的云和多云环境中为他们提供支持,本地,或两者的结合。从一开始就认识到云之旅不是一蹴而就的,使用户有效地进行数字化转型,基本的动态数据平台,可以在整个技术环境中无缝集成。
- 云原生。 Confluent 为动态数据提供真正的云功能。 提供完全托管的云原生服务,该服务具有大规模可扩展性、弹性、安全性和全球互联性,可实现敏捷开发。这与采用内部软件并简单地在云虚拟机上提供它所产生的体验完全不同。使用 Confluent,开发人员和企业都可以专注于他们的应用程序并推动价值,而无需担心管理数据基础设施的运营开销。

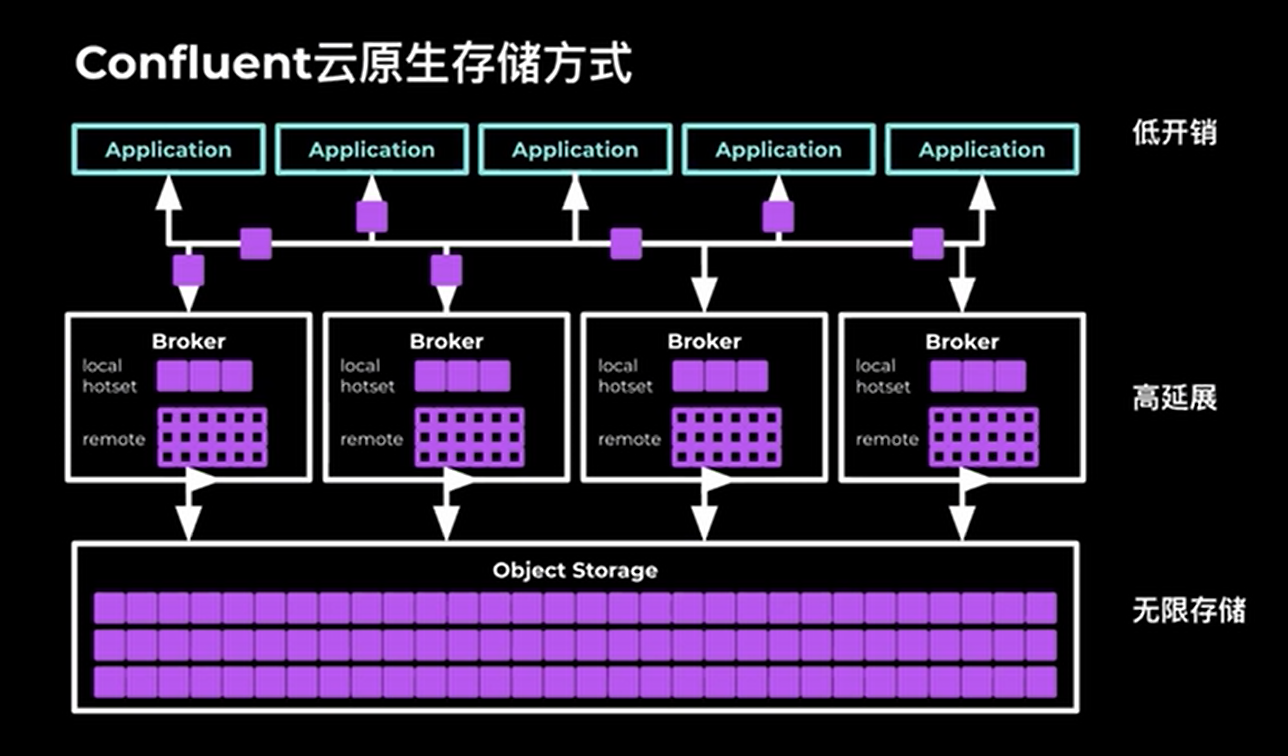
存储方式采用云原生的架构,和Apache Pulsar一样采用存储和计算分离的架构,可以很方便实现分布式扩容,存储资源不够单独扩容存储,计算资源不够单独扩容计算。
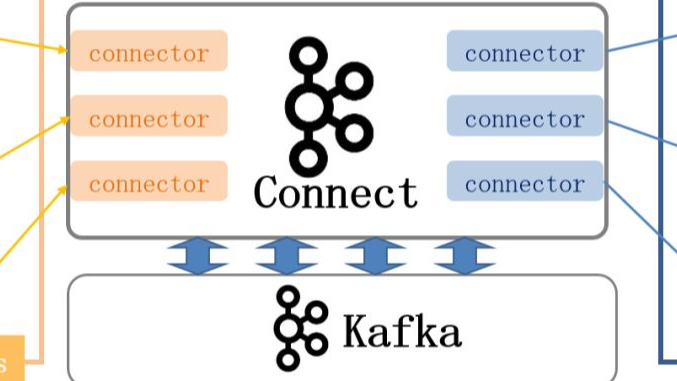
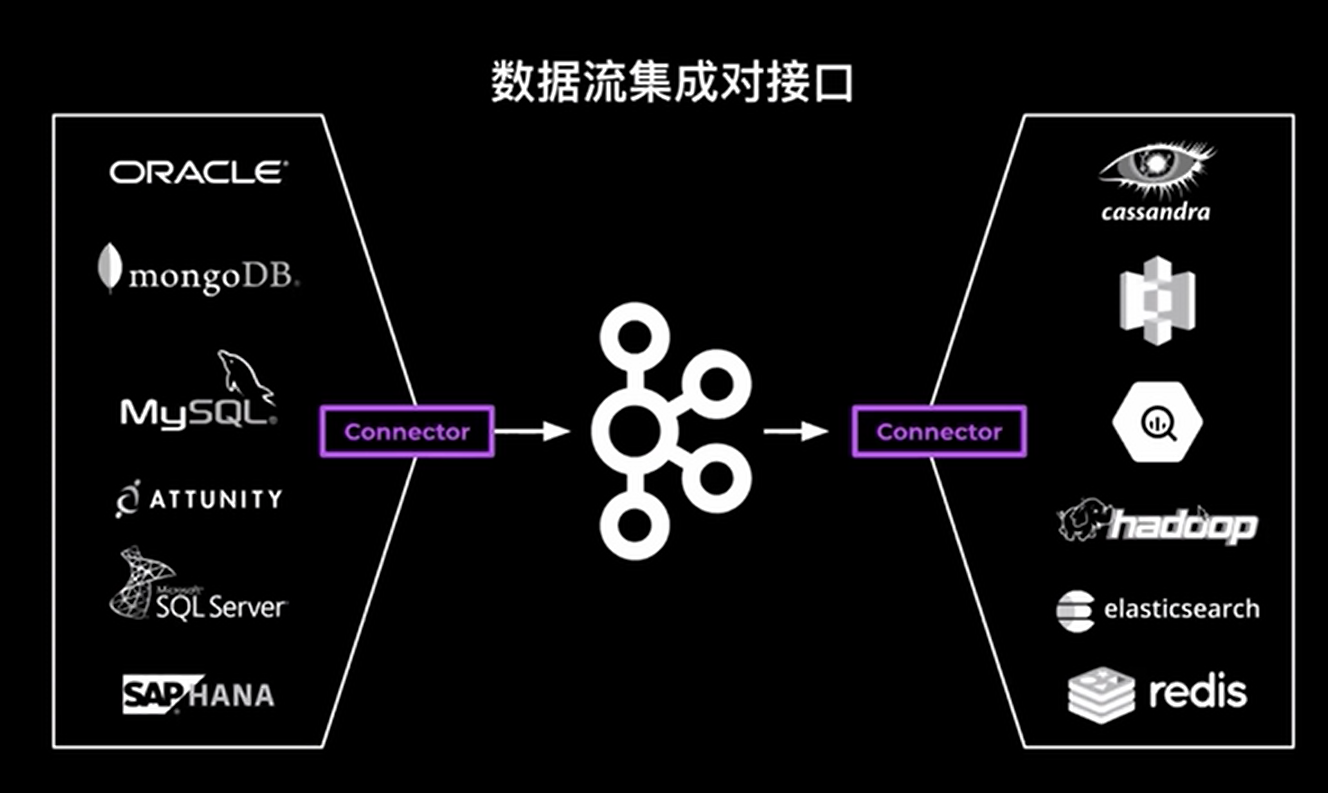
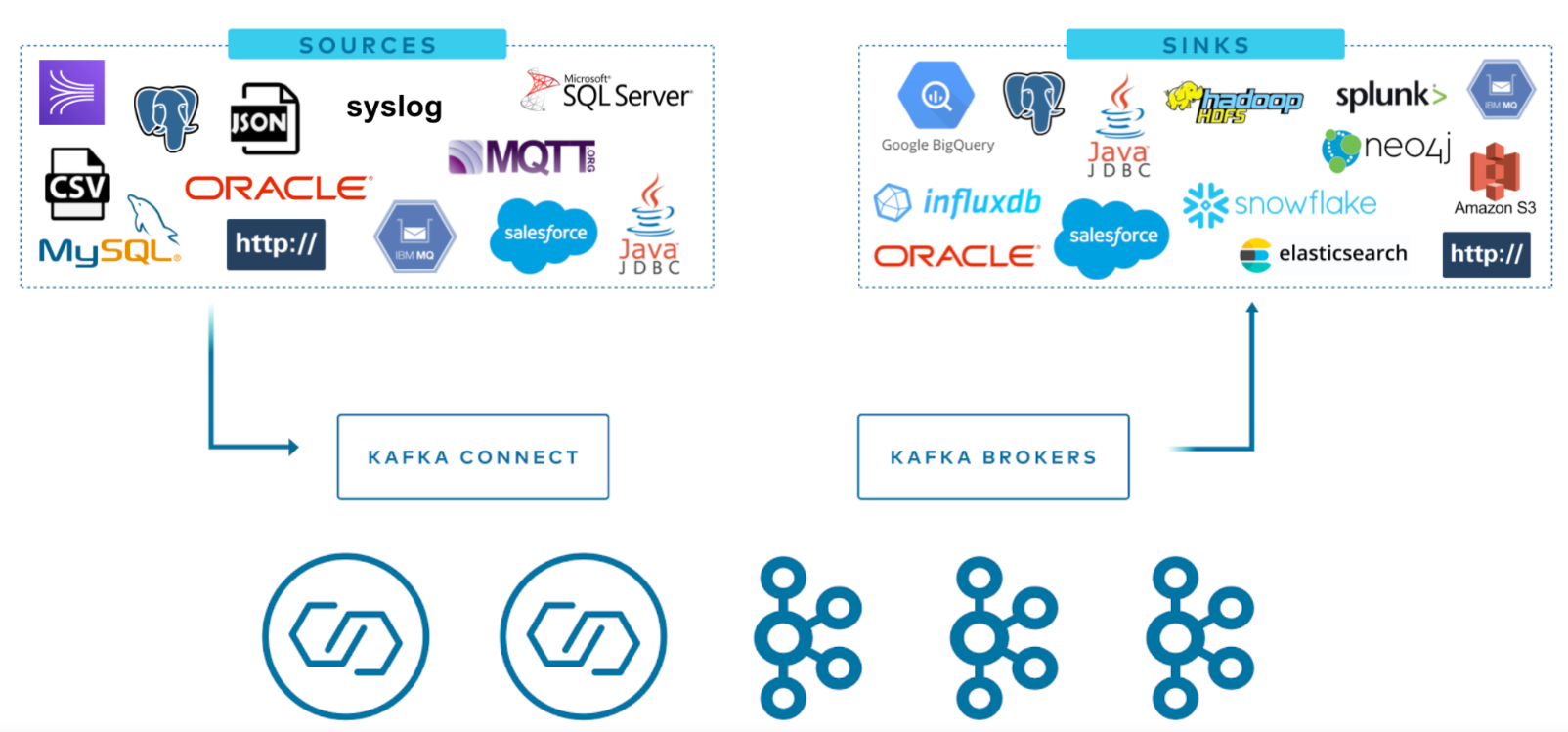
Kafka Connect是Apache Kafka的一个组件,用于执行Kafka和其他系统之间的流集成,比如作为用来将Kafka与数据库、key-value存储系统、搜索系统、文件系统等外部系统连接起来的基础框架。通过使用Kafka Connect框架以及现有的连接器可以实现从源数据读入消息到Kafka,再从Kafka读出消息到目的地的功能。Kafka Connect可以很容易地将数据从多个数据源流到Kafka,并将数据从Kafka流到多个目标。Kafka Connect有上百种不同的连接器。Confluent 在 Kafka connect基础上实现了上百种不同的connector连接器免费让大家使用,而且Confluent 在GitHub上提供了源码,可以根据自身业务需求进行修改。其中最流行的有:
- RDBMS (Oracle, SQL Server, DB2, Postgres, MySQL)
- Cloud Object stores (Amazon S3, Azure Blob Storage, Google Cloud Storage)
- Message queues (ActiveMQ, IBM MQ, RabbitMQ)
- NoSQL and document stores (Elasticsearch, MongoDB, Cassandra)
- Cloud data warehouses (Snowflake, Google BigQuery, Amazon Redshift)
可以自己运行Kafka Connect,或者利用Confluent Cloud中提供的众多托管连接器来提供一个完全基于云的集成解决方案。除了托管连接器外,Confluent还提供了完全托管的Apache Kafka、Schema Registry和ksqlDB。
- Schema-Registry是为元数据管理提供的服务,同样提供了RESTful接口用来存储和获取schemas,它能够保存数据格式变化的所有版本,并可以做到向下兼容。Schema-Registry还为Kafka提供了Avro格式的序列化插件来传输消息。Confluent主要用Schema-Registry来对数据schema进行管理和序列化操作。
Kafka Connect运行在自己的进程中,独立于Kafka broker。它是分布式的、可伸缩的、容错的,就像Kafka本身一样。使用Kafka Connect不需要编程,因为它只由JSON配置驱动。这使得它可以被广泛的用户使用。除了接收和输出数据,Kafka Connect还可以在数据通过时执行轻量级的转换。
Kafka Connect把数据从另一个系统流到Kafka,或者把数据从Kafka流到其他地方,下面是一些使用Kafka Connect的常见方式:
- 流数据管道:Kafka Connect可以用来从一个源(如事务数据库)获取实时事件流,并将其流到目标系统进行分析。因为Kafka存储每个数据实体(topic)的可配置时间间隔,所以可以将相同的原始数据流到多个目标。这可以是为不同的业务需求使用不同的技术,也可以是将相同的数据提供给业务中的不同领域(业务中有自己的系统来保存数据)。
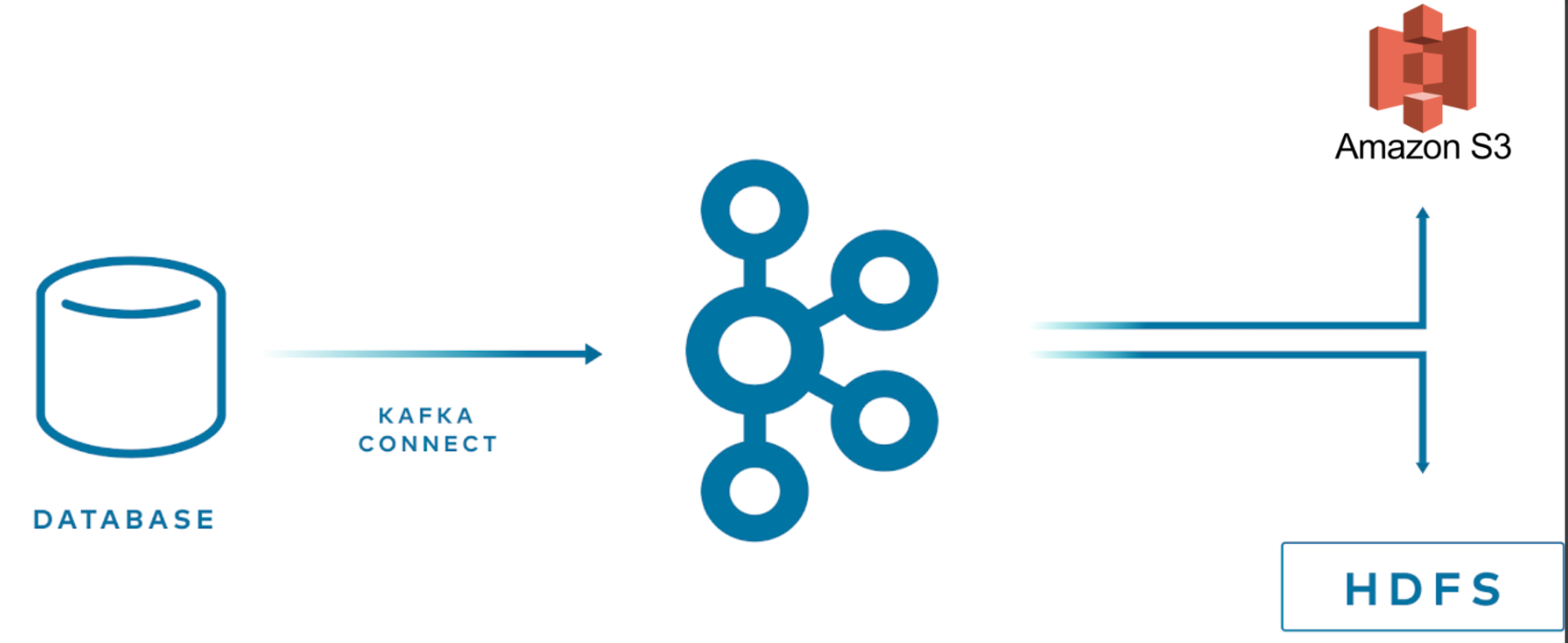
- 从应用程序写入数据存储:在应用程序中,可以创建想要写入目标系统的数据。可以是写入文档存储的一系列日志事件或是持久化到关系数据库的数据。通过将数据写入Kafka,并使用Kafka Connect负责将数据写入目标达到简化内存占用。

- 从旧系统到新系统的演化过程:在NoSQL存储、事件流平台和微服务等最新技术出现之前,关系数据库(RDBMS)实际上是应用程序中所有数据写入的地方。RDBMS在我们构建的系统中仍然扮演着非常重要的角色——但并不总是如此。有时我们会想使用Kafka作为独立服务之间的消息代理以及永久的记录系统。这两种方法非常不同,但与过去的技术变革不同,两者之间是无缝衔接的。通过使用变更数据捕获(CDC),我们可以近乎实时地从数据库中提取每一个INSERT, UPDATE,甚至DELETE到Kafka事件流中。CDC对源数据库的影响非常小,这意味着现有应用程序可以继续运行(并且不需要对其进行更改),同时可以由从数据库捕获的事件流驱动构建新的应用程序。当原始的应用程序在数据库中记录一些东西时(例如,下单),任何在Kafka中订阅事件流的应用程序都将能够基于这些事件采取行动(例如,一个新的订单服务)
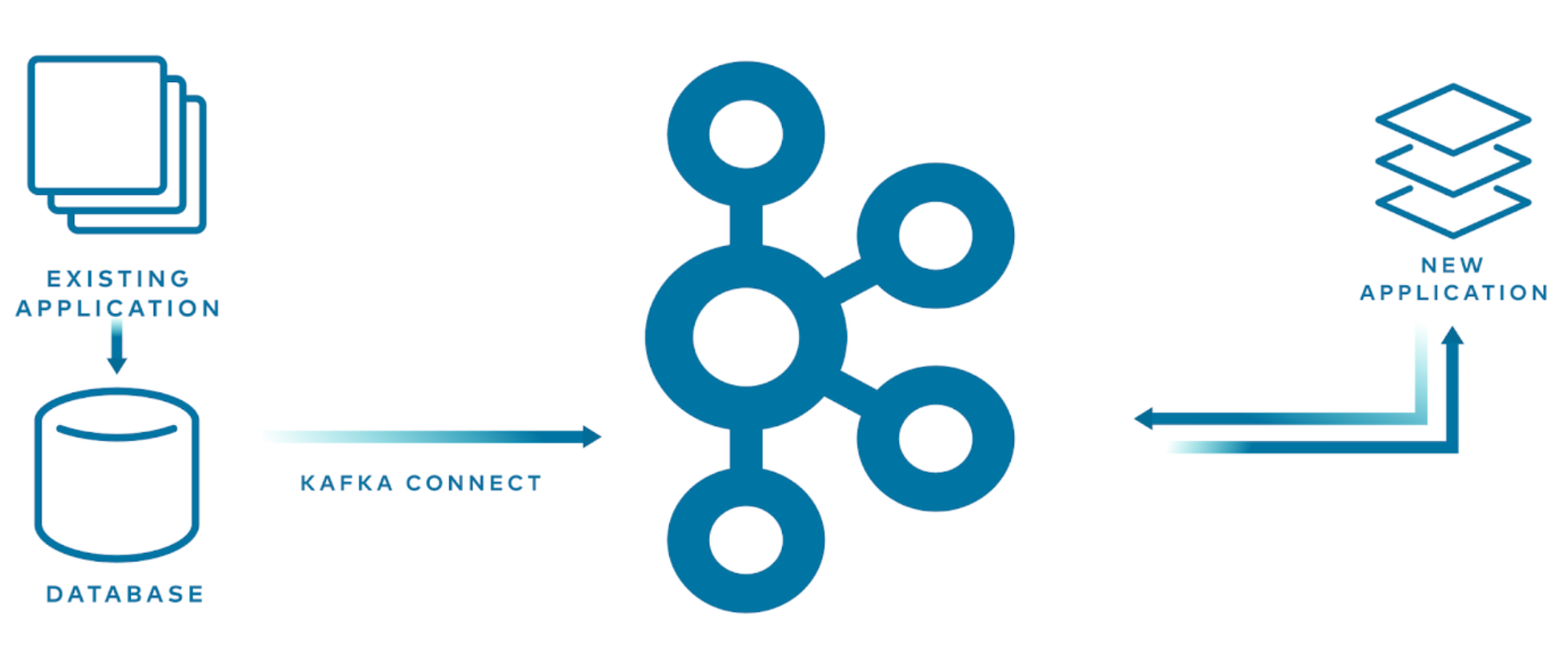
- 使现有的系统处理实时:许多组织在他们的数据库中都有静止的数据,比如Postgres, MySQL或Oracle,并且可以使用Kafka Connect从现有的数据中获取价值,并将其转换为事件流并实现数据驱动分析。
任何Kafka Connect管道的关键组件都是连接器。Kafka Connect由社区、供应商编写,或者偶尔由用户定制编写,它将Kafka Connect与特定的技术集成在一起。例如:
- Debezium MySQL源连接器使用MySQL bin日志从数据库读取事件,并将这些事件流到Kafka Connect。
- Elasticsearch接收器连接器从Kafka Connect获取数据,并使用Elasticsearch api,将数据写入Elasticsearch。
- Confluent的S3连接器既可以作为源连接器,也可以作为接收连接器,将数据写入S3或将其读入。
Connector和任务是逻辑工作单元,并作为流程运行。这个进程在Kafka Connect中被称为worker。Kafka Connect worker可以在两种部署方式中运行:独立的或分布式的。
- 布式模式(推荐):在多台机器(节点)上连接工人。它们形成一个Connect集群。Kafka Connect在集群中分布正在运行的连接器。您可以根据需要添加或删除更多节点。连接器是通过Kafka Connect提供的REST API创建和管理的。可以容易地添加额外的worker,从Kafka Connect集群中添加worker时,任务会在可用的worker之间重新平衡,以分配工作负载;如果缩减集群或者worker崩溃了Kafka Connect将再次重新平衡,以确保所有连接器任务仍然被执行。建议的最小worker数量是2个,分布式模式也具有更强的容错能力。如果一个节点意外离开集群,Kafka Connect会自动将该节点的工作分配给集群中的其他节点。并且,因为Kafka Connect将连接器的配置、状态和偏移量信息存储在Kafka集群中,在这里它被安全地复制,所以失去一个Connect worker运行的节点不会导致任何数据的丢失.由于可伸缩性、高可用性和管理优势,建议在生产环境中采用分布式模式。如果您有多个worker同时在一台机器上运行,了解资源限制(CPU和内存)。从默认堆大小设置开始,监视内部指标和系统。检查CPU、内存和网络(10GbE或更高)是否满足负载要求。
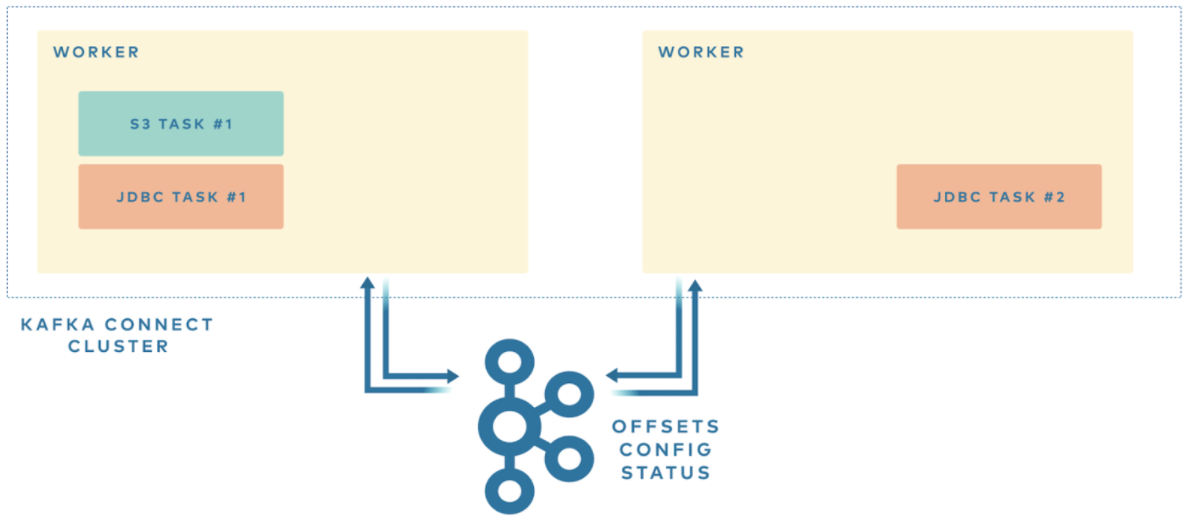
- 独立模式(单机模式):在独立模式下,Kafka Connect worker使用文件存储来保存它的状态。连接器是从本地配置文件创建的,而不是REST API。因此,您不能将worker集群在一起,不能扩展吞吐量,也没有容错能力。常用于在本地机器上开发和测试Kafka Connect非常有用。它也可以用于通常使用单个代理的环境(例如,发送web服务器日志到Kafka)
-
Kafka Connect只有一个必要的先决条件来启动;也就是一组Kafka broker。这些Kafka代理可以是早期的代理版本,也可以是最新的版本。虽然Schema Registry不是Kafka Connect的必需服务,但它可以让你轻松地使用Avro, Protobuf和JSON Schema作为通用的数据格式来读取和写入Kafka记录。这使编写自定义代码的需求最小化,并以灵活的格式标准化数据。
-
Kafka Connect被设计成可扩展的,所以开发者可以创建自定义的连接器、转换或转换器,用户可以安装和运行它们。在一个Connect部署中安装许多插件是很常见的,但需要确保每个插件只安装一个版本。
-
Kafka Connect插件可以是:文件系统上的一个目录,包含所有需要的JAR文件和插件的第三方依赖项。这是最常见和首选的。一个包含插件及其第三方依赖的所有类文件的JAR。一个插件永远不应该包含任何由Kafka Connect运行时提供的库。
-
Kafka Connect使用一个定义为逗号分隔的插件目录路径列表来查找插件。worker路径配置属性配置如下:plugin.path=/usr/local/share/kafka/plugins。安装插件时,将插件目录或JAR(或一个解析到这些目录之一的符号链接)放置在插件路径中已经列出的目录中。或者可以通过添加包含插件的目录的绝对路径来更新插件路径。使用上面的插件路径的例子,可以在每台运行Connect的机器上创建一个/usr/local/share/kafka/plugins目录,然后把插件目录(或者超级jar)放在那里。
- Connectors:通过管理task来协调数据流的高级抽象
- Kafka Connect中的connector定义了数据应该从哪里复制到哪里。connector实例是一种逻辑作业,负责管理Kafka与另一个系统之间的数据复制。
- 我们在大多数情况下都是使用一些平台提供的现成的connector。但是,也可以从头编写一个新的connector插件。在高层次上,希望编写新连接器插件的开发人员遵循以下工作流。
- Tasks:如何将数据复制到Kafka或从Kafka复制数据的实现
- Task是Connect数据模型中的主要处理数据的角色,也就是真正干活的。每个connector实例协调一组实际复制数据的task。通过允许connector将单个作业分解为多个task,Kafka Connect提供了内置的对并行性和可伸缩数据复制的支持,只需很少的配置。
- 这些任务没有存储任何状态。任务状态存储在Kafka中的特殊主题
config.storage.topic和status.storage.topic中。因此,可以在任何时候启动、停止或重新启动任务,以提供弹性的、可伸缩的数据管道。 - Task Rebalance
- 当connector首次提交到集群时,workers会重新平衡集群中的所有connector及其tasks,以便每个worker的工作量大致相同。当connector增加或减少它们所需的task数量,或者更改connector的配置时,也会使用相同的重新平衡过程。
- 当一个worker失败时,task在活动的worker之间重新平衡。当一个task失败时,不会触发再平衡,因为task失败被认为是一个例外情况。因此,失败的task不会被框架自动重新启动,应该通过REST API重新启动。
- Workers:执行Connector和Task的运行进程。
- Converters: 用于在Connect和外部系统发送或接收数据之间转换数据的代码。在向Kafka写入或从Kafka读取数据时,Converter是使Kafka Connect支持特定数据格式所必需的。task使用Converters将数据格式从字节转换为连接内部数据格式,反之亦然。并且Converter与Connector本身是解耦的,以便在Connector之间自然地重用Converter。默认提供一些Converters:
- AvroConverter(建议):与Schema Registry一起使用
- JsonConverter:适合结构数据
- StringConverter:简单的字符串格式
- ByteArrayConverter:提供不进行转换的“传递”选项
- Transforms:更改由连接器生成或发送到连接器的每个消息的简单逻辑。
- Connector可以配置Transforms,以便对单个消息进行简单且轻量的修改。这对于小数据的调整和事件路由十分方便,且可以在connector配置中将多个Transforms连接在一起。然而,应用于多个消息的更复杂的Transforms最好使用KSQL和Kafka Stream来实现。
- Transforms是一个简单的函数,输入一条记录,并输出一条修改过的记录。Kafka Connect提供许多Transforms,它们都执行简单但有用的修改。可以使用自己的逻辑定制实现转换接口,将它们打包为Kafka Connect插件,将它们与connector一起使用。
- 当Transforms与Source Connector一起使用时,Kafka Connect通过第一个Transforms传递connector生成的每条源记录,第一个Transforms对其进行修改并输出一个新的源记录。将更新后的源记录传递到链中的下一个Transforms,该Transforms再生成一个新的修改后的源记录。最后更新的源记录会被转换为二进制格式写入到Kafka。Transforms也可以与Sink Connector一起使用。
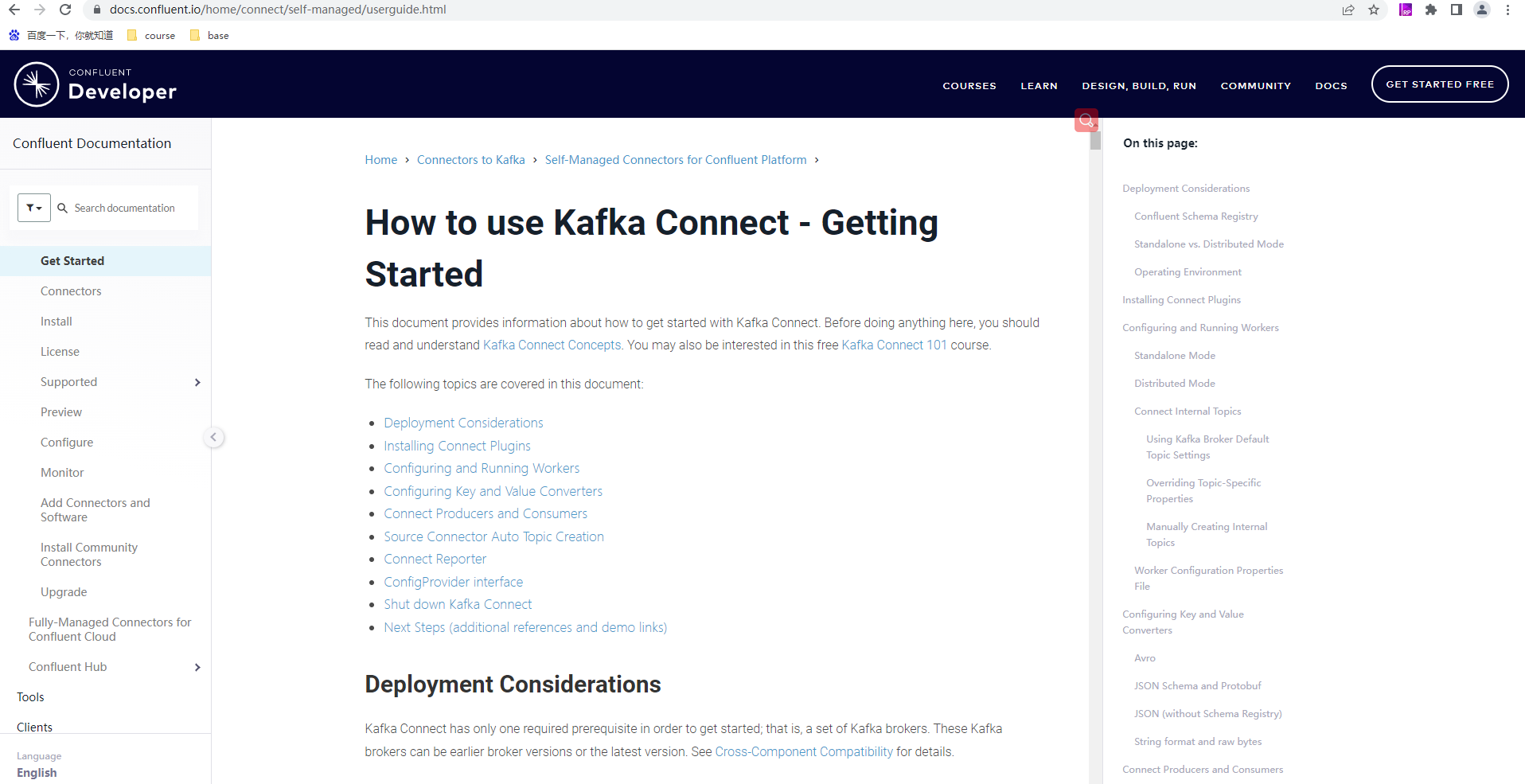
在Kafka安装目录下也已自带Connect脚本和简单模板配置文件,而Confluent Platform中也会包含了更多worker示例配置属性文件(如etc/schema-registry/connect-avro-distributed.properties、etc/schema-registry/connect-avro-standalone.properties)。
官方使用说明
group.id(默认connect-cluster) - Connect cluster group使用唯一的名称;注意这不能和consumer group ID(消费者组)冲突。config.storage.topic(默认connect-configs) - topic用于存储connector和任务配置;注意,这应该是一个单个的partition,多副本的topic。你需要手动创建这个topic,以确保是单个partition(自动创建的可能会有多个partition)。offset.storage.topic(默认connect-offsets) - topic用于存储offsets;这个topic应该配置多个partition和副本。status.storage.topic(默认connect-status) - topic 用于存储状态;这个topic 可以有多个partitions和副本
建议允许Kafka Connect自动创建内部管理的Topics。如果需要手动创建示例如下
# config.storage.topic=connect-configs
bin/kafka-topics --create --bootstrap-server localhost:9092 --topic connect-configs --replication-factor 3 --partitions 1 --config cleanup.policy=compact
# offset.storage.topic=connect-offsets
bin/kafka-topics --create --bootstrap-server localhost:9092 --topic connect-offsets --replication-factor 3 --partitions 50 --config cleanup.policy=compact
# status.storage.topic=connect-status
bin/kafka-topics --create --bootstrap-server localhost:9092 --topic connect-status --replication-factor 3 --partitions 10 --config cleanup.policy=compact
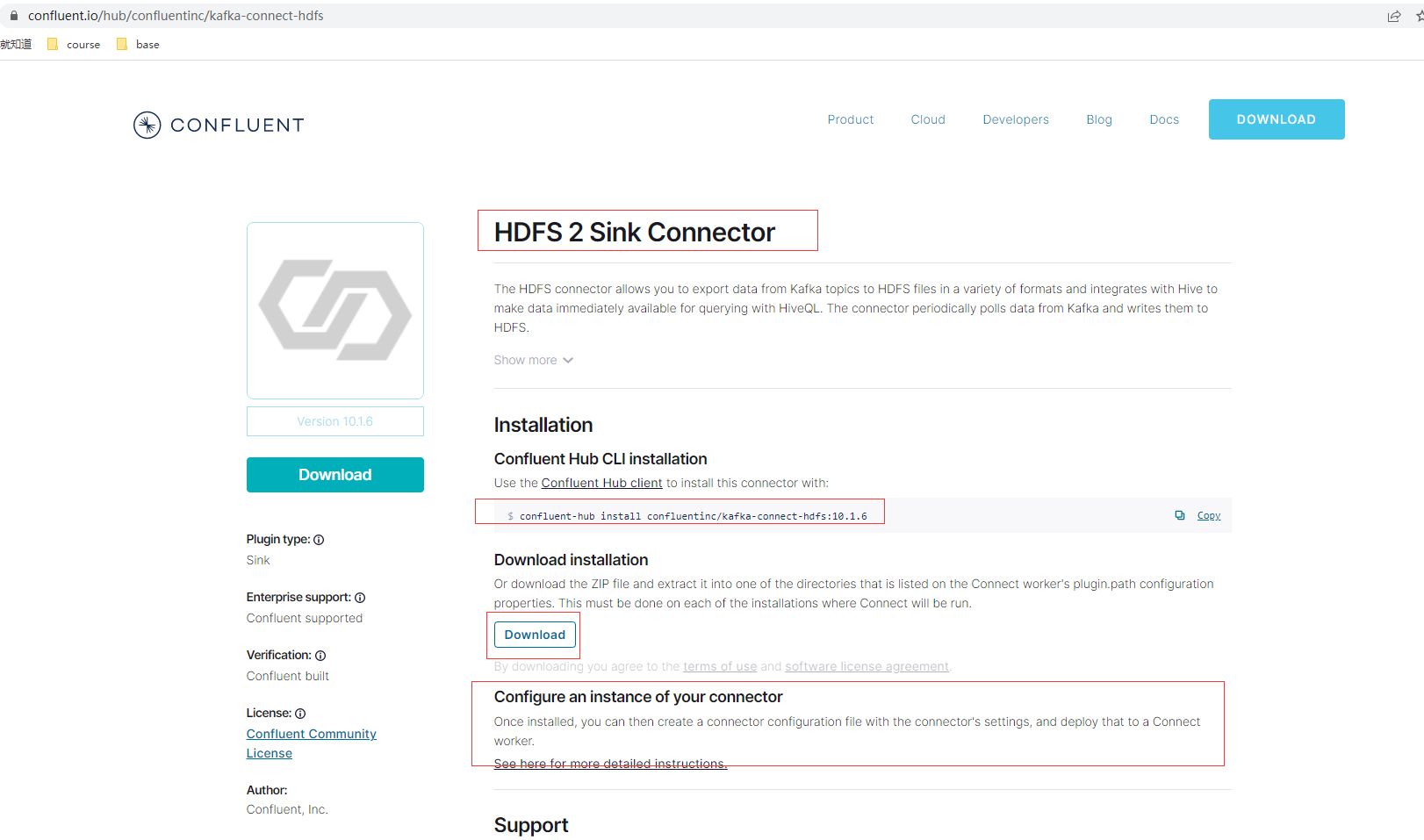
Confluent已提供很多Kafka Connect的实现的Connector连接器,可以先到这里搜索插件下载Confluent Hub插件下载地址 https://www.confluent.io/hub/
这里不做演示,独立模式通常用于开发和测试,或者轻量级、单代理环境(例如,发送web服务器日志到Kafka)。单机模式启动worker的示例命令:
bin/connect-standalone worker.properties connector1.properties [connector2.properties connector3.properties ...]
Kafka Connect是作为一个服务运行的,支持REST API来管理连接器。默认情况下,该服务运行在端口8083上。当在分布式模式下执行时,REST API将成为集群的主要接口;你可以向任何集群发出请求REST API会自动转发请求。目前REST API只支持application/json作为请求和响应实体内容类型。请求通过HTTP Accept头指定预期的响应内容类型和或者提交请求content - type报头指定请求实体的内容类型
Accept: application/json
Content-Type: application/json
-
GET /- 顶级(根)请求,获取服务REST请求的Connect worker的版本,源代码的git提交ID,以及该worker连接的Kafka集群ID -
GET /connectors- 返回活跃的connector列表 -
POST /connectors- 创建一个新的connector;请求的主体是一个包含字符串name字段和对象config字段(connector的配置参数)的JSON对象。 -
GET /connectors/{name}- 获取指定connector的信息 -
GET /connectors/{name}/config- 获取指定connector的配置参数 -
PUT /connectors/{name}/config- 更新指定connector的配置参数 -
GET /connectors/{name}/status- 获取connector的当前状态,包括它是否正在运行,失败,暂停等。 -
GET /connectors/{name}/tasks- 获取当前正在运行的connector的任务列表。 -
GET /connectors/{name}/tasks/{taskid}/status- 获取任务的当前状态,包括是否是运行中的,失败的,暂停的等, -
PUT /connectors/{name}/pause- 暂停连接器和它的任务,停止消息处理,直到connector恢复。 -
PUT /connectors/{name}/resume- 恢复暂停的connector(如果connector没有暂停,则什么都不做) -
POST /connectors/{name}/restart- 重启connector(connector已故障) -
POST /connectors/{name}/tasks/{taskId}/restart- 重启单个任务 (通常这个任务已失败) -
DELETE /connectors/{name}- 删除connector, 停止所有的任务并删除其配置 -
GET /connector-plugins- 返回已在Kafka Connect集群安装的connector plugin列表。请注意,API仅验证处理请求的worker的connector。这以为着你可能看不不一致的结果,特别是在滚动升级的时候(添加新的connector jar) -
PUT /connector-plugins/{connector-type}/config/validate- 对提供的配置值进行验证,执行对每个配置验证,返回验证的建议值和错误信息。
# FileStreamSource是Kafka本身就提供Connector实现,直接配置使用即可
# 将confluentinc-kafka-connect-hdfs-10.1.6.zip解压到指定插件目录,我这里在Kafka安装目录下的config/connect-distributed.properties配置项
plugin.path=/opt/kafka/connectors
vim /home/commons/kafka_2.13-3.1.0/config/connect-distributed.properties
# Broker Server的访问ip和端口号
bootstrap.servers=server1:9092,server2:9092,server3:9092
# 指定集群id
group.id=connect-cluster
# 指定rest服务的端口号
rest.port=8083
# 指定Connect插件包的存放路径
plugin.path=/opt/kafka/connectors
# 配置转换器
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false

# 在Kafka根目录下启动worker
./bin/connect-distributed.sh -daemon config/connect-distributed.properties
创建FileStreamSource的json文件filesource.json
{
"name":"local-file-source",
"config":{
"topic":"distributetest",
"connector.class":"FileStreamSource",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"org.apache.kafka.connect.storage.StringConverter",
"converter.internal.key.converter":"org.apache.kafka.connect.storage.StringConverter",
"converter.internal.value.converter":"org.apache.kafka.connect.storage.StringConverter",
"file":"/home/commons/kafka_2.13-3.1.0/distribute-source.txt"
}
}
创建HdfsSinkConnector的json文件hdfssink.json
{
"name": "hdfs-sink",
"config": {
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"tasks.max": "1",
"topics": "distributetest",
"topics.dir": "/user/hive/warehouse/topictest/",
"hdfs.url": "hdfs://192.168.3.14:8020",
"flush.size": "2"
}
}
curl -X GET http://localhost:8083/connector-plugins

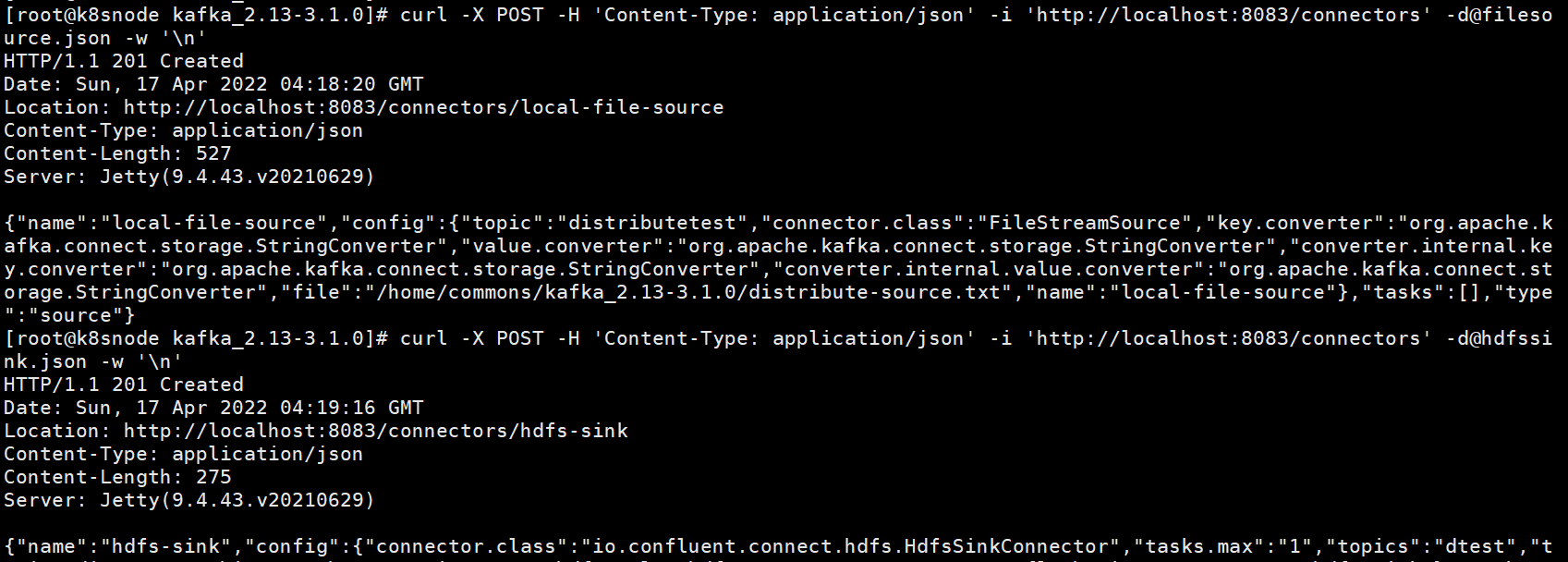
# 创建filesource和hdfssink
curl -X POST -H 'Content-Type: application/json' -i 'http://localhost:8083/connectors' -d@filesource.json -w '\n'
curl -X POST -H 'Content-Type: application/json' -i 'http://localhost:8083/connectors' -d@hdfssink.json -w '\n'
# 写入数据,消费kafka主题也订阅到相应的数据
echo "{"name":"zhangsan"}" >> distribute-source.txt
echo "{"name":"zhangsan1"}" >> distribute-source.txt
echo "{"name":"zhangsan2"}" >> distribute-source.txt
curl -X GET -H 'Content-Type: application/json' -i 'http://localhost:8083/connectors/hdfs-sink/status' -w '\n'

查看HDFS中也已经有相应的数据,如果需要更详细的数据可以从官方查找使用,后续我们再详细介绍更多实际使用场景

**本人博客网站 **IT小神 www.itxiaoshen.com
【转自:美国多ip服务器 http://www.558idc.com/mgzq.html 欢迎留下您的宝贵建议】