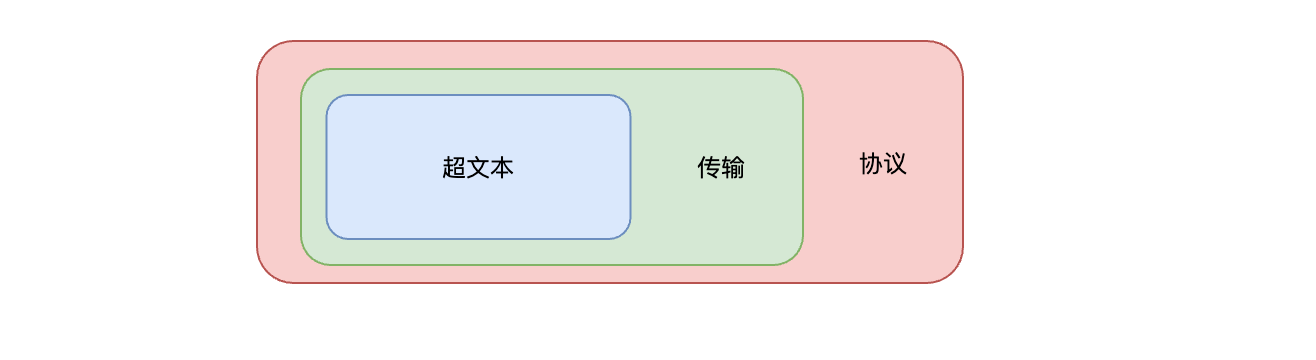
它是一种超文本传输协议,用来传输超文本
-
超文本:早期互联网只有文本被解析成二进制之后进行传输,后来互联网迅速的发展出现了视频、音频、图片等等信息进行传输,这种扩大后的语义称之为超文本。
-
传输:两台计算机之间进行通讯,超文本会被解析成二进制通过载体:光纤、电缆等等传输到另一台计算机。
-
协议:协议意味着有多个参与者为了达成某个共同的目的而站在了一起,除了要无疑义地沟通交流之外,还必须明确地规定各方的责、权、利”
HTTP是一个用在计算机世界里的协议,它确立了一种计算机之间交流通信的规范,以及相关的各种控制和错误处理方式。HTTP是构建互联网的重要基础技术,它没有实体,依赖许多其他的技术来实现,但同时许多技术也都依赖于它。
HTTP相关概念- 浏览器(Web):用于检索、查看互联网上网页资源的应用程序,本质上是一个HTTP协议中的请求方,使用HTTP协议获取网络上的各种资源,通常都简单地称之为“客户端”
- Web服务器(Web Service):包含硬件和软件两个含义,硬件可以表现为一台机器。软件可以表现为提供Web服务的应用程序,用来响应请求返回信息
- CDN(Content Delivery Network):它可以缓存源站的数据,让用户找到最近的节点,可以用作网络加速外,还提供负载均衡、安全防护、边缘计算、跨运营商网络等功能
- 爬虫(Crawler):是一种可以自动访问Web资源的应用程序
- WebService:是一种由W3C定义的应用服务开发规范,使用client-server主从架构,通常使用WSDL定义服务接口,使用HTTP协议传输XML或SOAP消息,也就是说,它是一个基于Web(HTTP)的服务架构技术,服务端和客户端可以采用不同的语言开发,具有跨平台跨语言的优点。
- 代理(Proxy):是HTTP协议中请求方和应答方中间的一个环节,既可以转发客户端的请求,也可以转发服务器的应答
- 正向代理:靠近客户端,代表客户端向服务器发送请求;
- 反向代理:靠近服务器端,代表服务器响应客户端的请求;
- DNS(Domain Name System):也叫域名解析服务,用有意义的名字来作为IP地址的等价替代。
TCP/IP协议:TCP/IP协议实际上是一系列网络通信协议的统称,主要包含TCP、IP协议还有一些其他协议
IP协议(InternetProtocol):主要是解决寻址和路由,用IP来定位世界上每一台计算机
TCP协议(Transmission Control Protocol):它位于IP协议之上,基于IP协议提供可靠的、字节流形式的通信,是HTTP协议得以实现的基础。
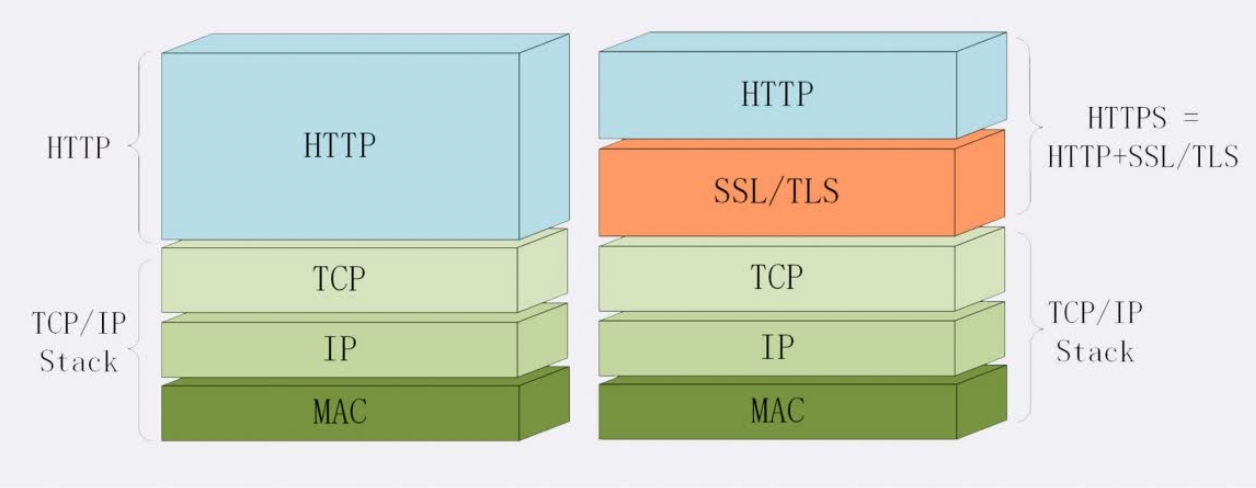
HTTPS协议:由HTTP协议+SSL/TLS加密协议组成,使得访问更加安全了。SSL的全称是“Secure Socket Layer”,综合了对称加密、非对称加密、摘要算法、数字签名、数字证书等技术,相当于在不安全的环境中为HTTP套上一副坚固的盔甲
网络分层模型TCP/IP协议总共有四层,就像搭积木一样,每一层需要下层的支撑,同时又支撑着上层。它的层次顺序是“从下往上”
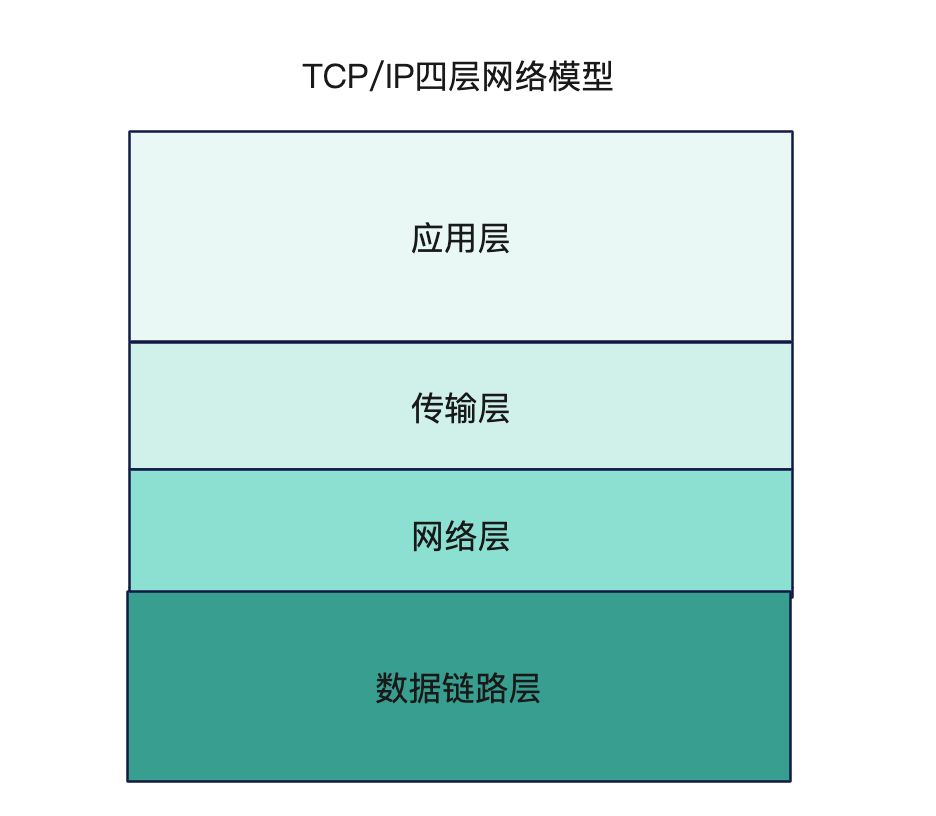
- 数据链路层:负责在以太网、WiFi这样的底层网络上发送原始数据包,工作在网卡这个层次,使用MAC地址来标记网络上的设备,所以有时候也叫MAC层。
- 网络层:我们A主机和F主机中间隔了很多其他主机,可能A和F主机就不在同一个子网里面,也可能在,我们就需要去判断发送者和接收者是不是在通一个子网,这时候有一个IP协议
- 传输层:在IP地址标记的两点之间“可靠”地传输,是TCP协议工作的层次,包括TCP和UDP
- 应用层:为应用程序提供服务有各种面向具体应用的协议。例如Telnet、SSH、FTP、SMTP、HTTP等等
MAC层的传输单位是帧(frame),IP层的传输单位是包(packet),TCP层的传输单位是段(segment),HTTP的传输单位则是消息或报文(message)。
OIS七层模型:开放式系统互联通信参考模型(OpenSystem Interconnection Reference Model)
TCP/IP发明于1970年代,当时除了它还有很多其他的网络协议,整个网络世界比较混乱,国际标准组织(ISO)注意到了这种现象,就想要来个“大一统”。于是设计出了一个新的网络分层模型,想用这个新框架来统一既存的各种网络协议。
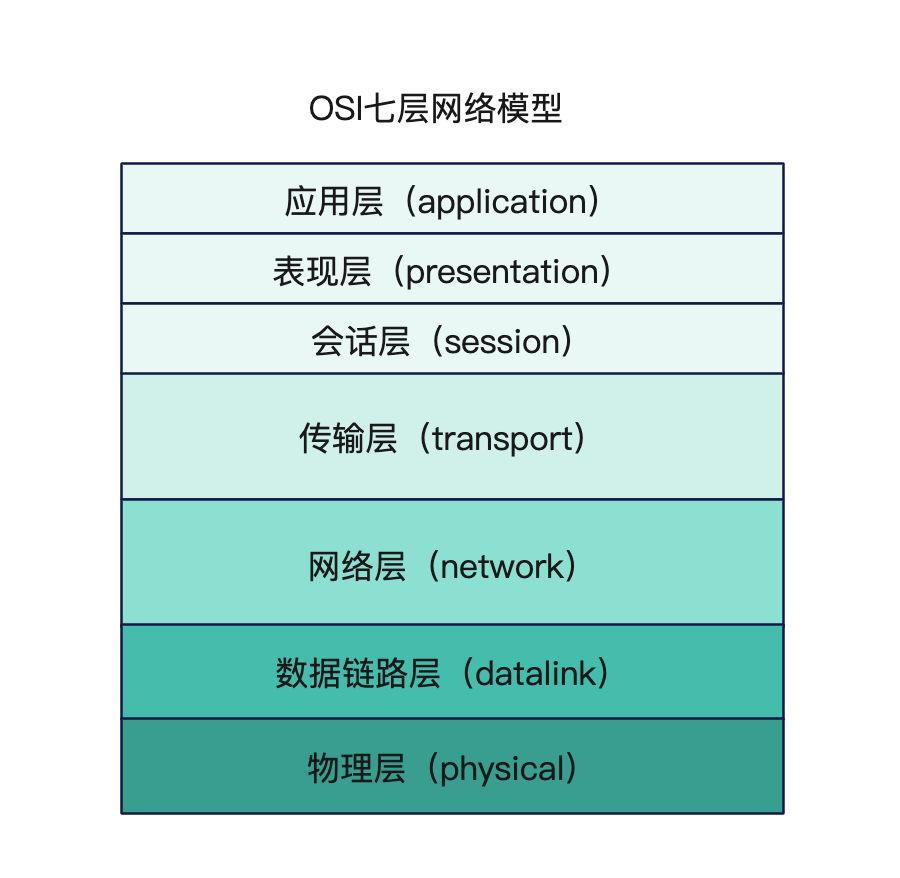
相比TCP/IP四层多了物理层、表现层、会话层
- 物理层:互联物理链路,物理介质。网线,光纤,无线电波等等,以二进制电信号的形式传输数据
- 会话层:每次断联不可能要手动去连接,它实现了断点续传、自动收发包的功能,还有自动寻址的功能
- 表现层:翻译工作,针对不同的系统如Windows、Linux、Mac,提供一种公共语言,进行通信
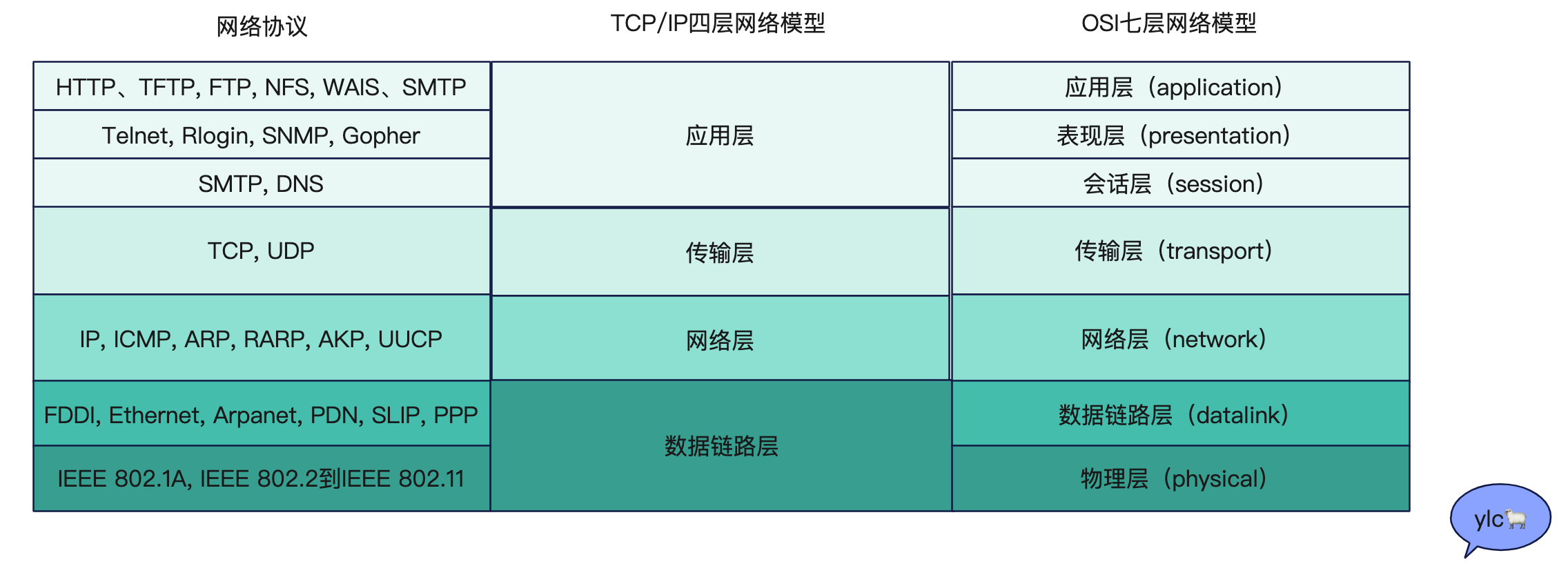
两个分层模型的映射关系
协议工作方式
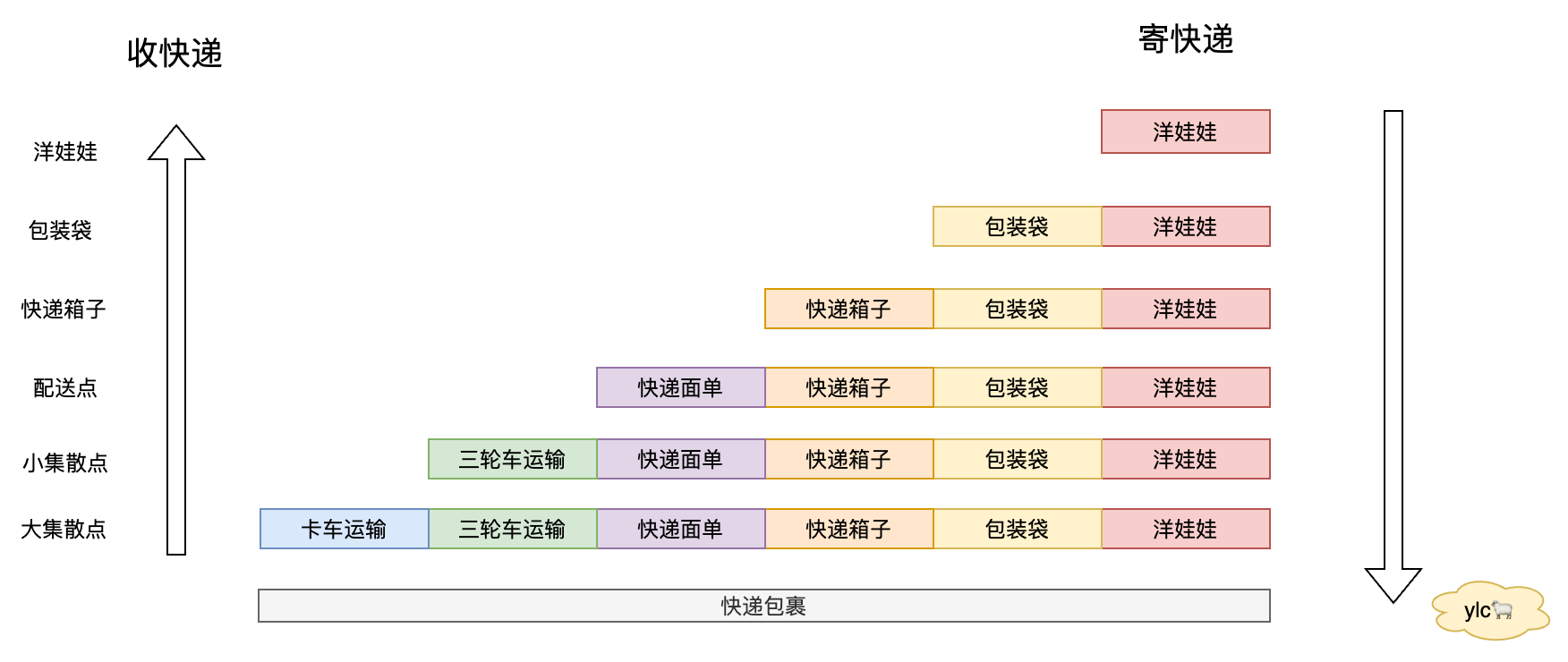
可以把这个过程想像成发快递的过程,需要寄一个毛绒玩具,首先需要拿一个包装袋套一下,然后去到快递点会加上一个箱子,并且贴上一个快递面单,贴上之后利用小三轮运到集散中心,然后在集散中心利用大货车运往目的地
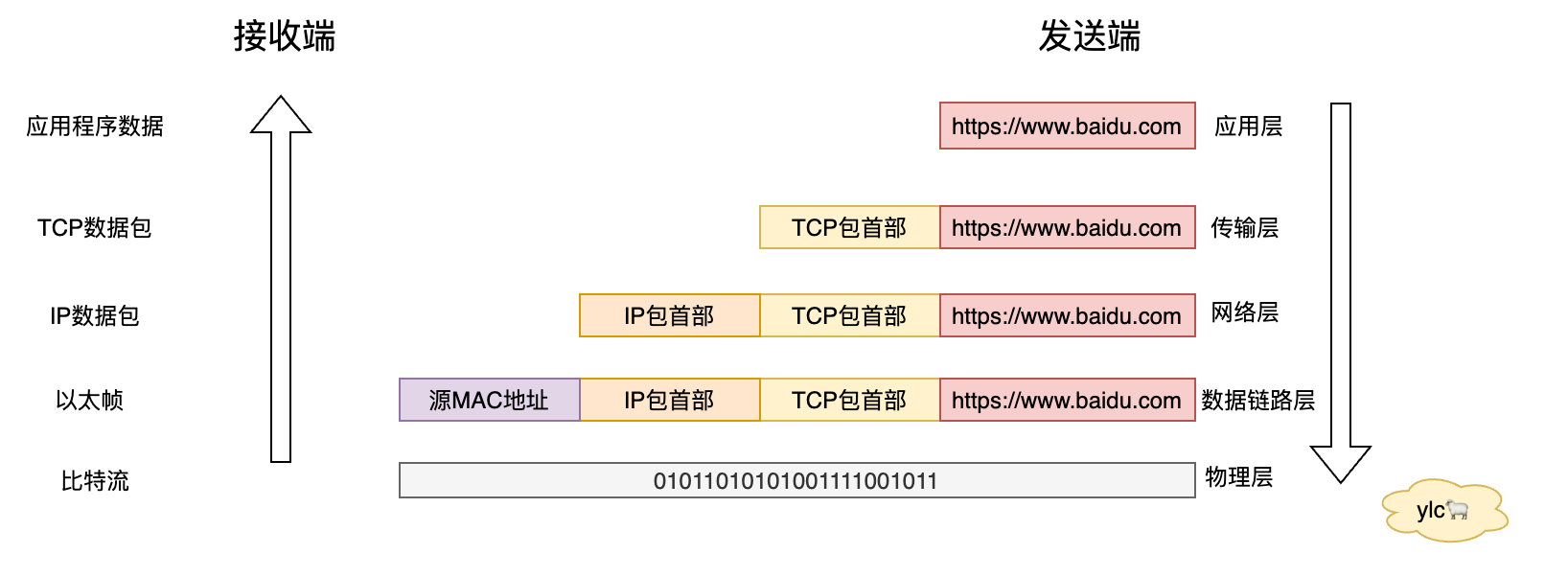
https://www.baidu.com 先通过应用层进入传输层,在传输层封装一个TCP的头部端口,这个端口是用来判断用什么应用程序来处理。(HTTPS默认端口443),发送给网络层,网络层给头部增加了一个IP信息,源主机和目的地址,寻址。
然后发送给数据链路层,数据链路层给头部增加了源MAC地址。然后发送给物理层,物理层转化为比特流,发送给百度服务器。
百度服务器收到信封自下而上,在物理层收到数据把比特流重组,就能够到数据链路层变成了以太帧的数据,拆封信封根据里面的源MAC地址传给网络层,网络层拆开发现有TCP的头部还含有端口。
网络层看完发送给传输层,传输层根据的端口号443,交给对应的协议HTTPS,传输至应用层,应用层根据请求消息给你一个响应请求,响应请求就是一个百度页面
HTTP协议是运行在TCP/IP上的,IP协议在MAC层之上,使用IP地址把MAC编号转换成了四位数字,对数据链路层做了一层抽象
IP地址又分为内网外网:
-
内网:在一个局域网内可以访问,不能被外界访问。例如公司内网,出了公司就访问不了了,内网访问外网需要经过交换机,路由器之后才连到外网的,内网的类型
A类:10.0.0.0——10.255.255.255
B类:172.16.0.0——172.31.255.255
C类:192.168.0.0——192.168.255.255
-
外网:在一个广域网内可以访问,广域网并不等同于互联网,外网就不经路由器或交换机就可以上网的网络。
A类:地址范围是1.0.0.0 到 127.255.255.255,主要分配 给大量主机而局域网网络数量较少的大型网络;
B类:地址范围是128.0.0.0 到191.255.255.255,一般用于国际性大公司和政府机构;
C类:地址范围是192.0.0.0 到223.255.255.255,用于一般小公司校园网研究机构等;
D类:地址范围是224.0.0.0 到 239.255.255.255,用于特殊用途,又称做广播地址;
E类:地址范围是240.0.0.0 到255.255.255.255,暂时保留。
一般网站都是使用域名,再通过域名解析服务解析成IP地址,域名方便记忆,它是一个有层次的结构,用.分割成多个单词。例如www.baidu.com, www表示万维网服务,baidu代表百度公司一级域名,com代表网站顶级域名。
域名解析
IP地址必须转换成MAC地址才能访问主机一样,域名也必须要转换成IP地址,这个过程就是“域名解析”DNS。
- 根域名服务器(Root DNS Server):管理顶级域名服务器,返回“com”“net”“cn”等顶级域名服务器的IP地址
- 顶级域名服务器(Top-level DNS Server):管理各自域名下的权威域名服务器,比如com顶级域名服务器可以返回apple.com域名服务器的IP地址
- 权威域名服务器(Authoritative DNS Server):管理自己域名下主机的IP地址,比如apple.com权威域名服务器可以返回www.apple.com的IP地址。
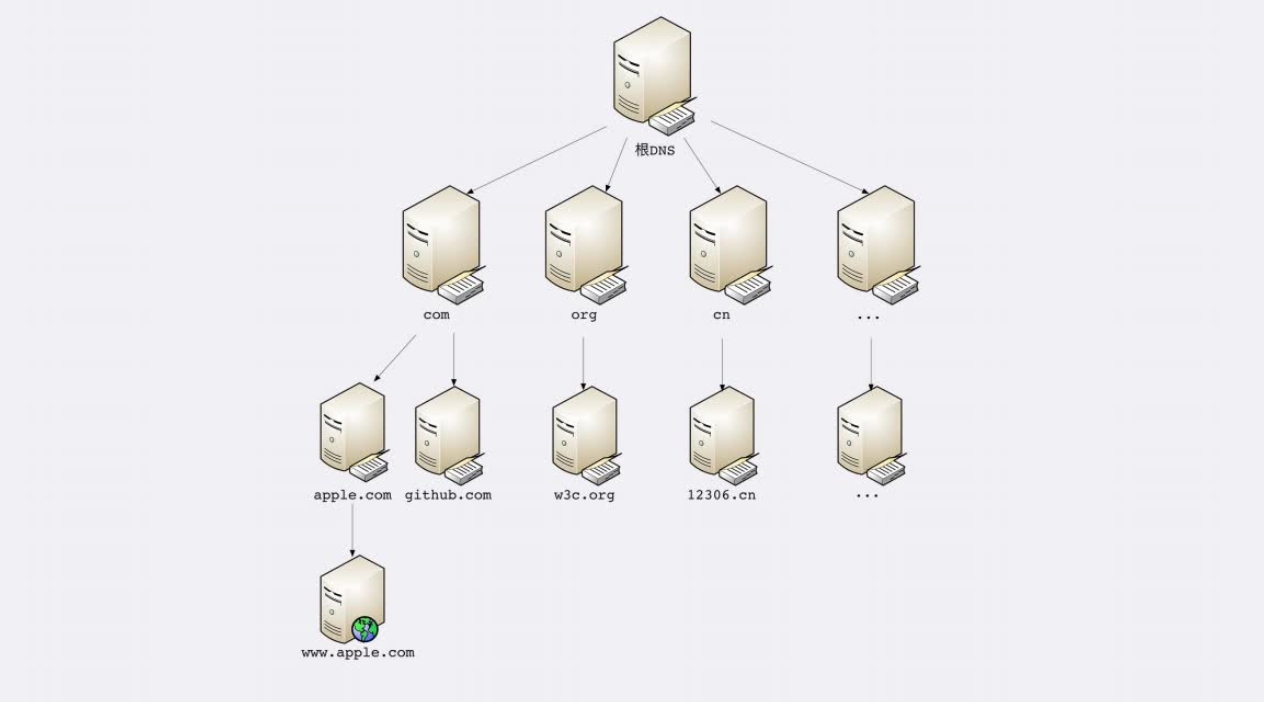
有了这个系统之后,任何一个域名只需要从上至下查询,最终就获得了域名的地址
要访问“www.apple.com”,就要进行下面的三次查询:
- 访问根域名服务器,它会告诉你“com”顶级域名服务器的地址
- 访问“com”顶级域名服务器,它再告诉你“apple.com”域名服务器的地址
- 最后访问“apple.com”域名服务器,就得到了“www.apple.com”的地址
如果每台机器都去根节点访问,那么速度和压力可想而知,为了解决这个问题,用到了缓存服务,在用户访问的时候记录下来,当下次访问就直接从缓存中拿数据了。知名的DNS有Google的“8.8.8.8”,本地也可以配置主机映射,比如访问github太慢,直接映射到对应的IP地址,可以加快访问速度
域名还可以用来做负载均衡,一般一个域名对应多个IP地址,在客户端实现负载均衡。实现重定向,某台服务器需要短暂维护,把域名对应的ip地址改为其他的。
HTTP组成请求报文由三大部分组成:起始行、请求头部、实体
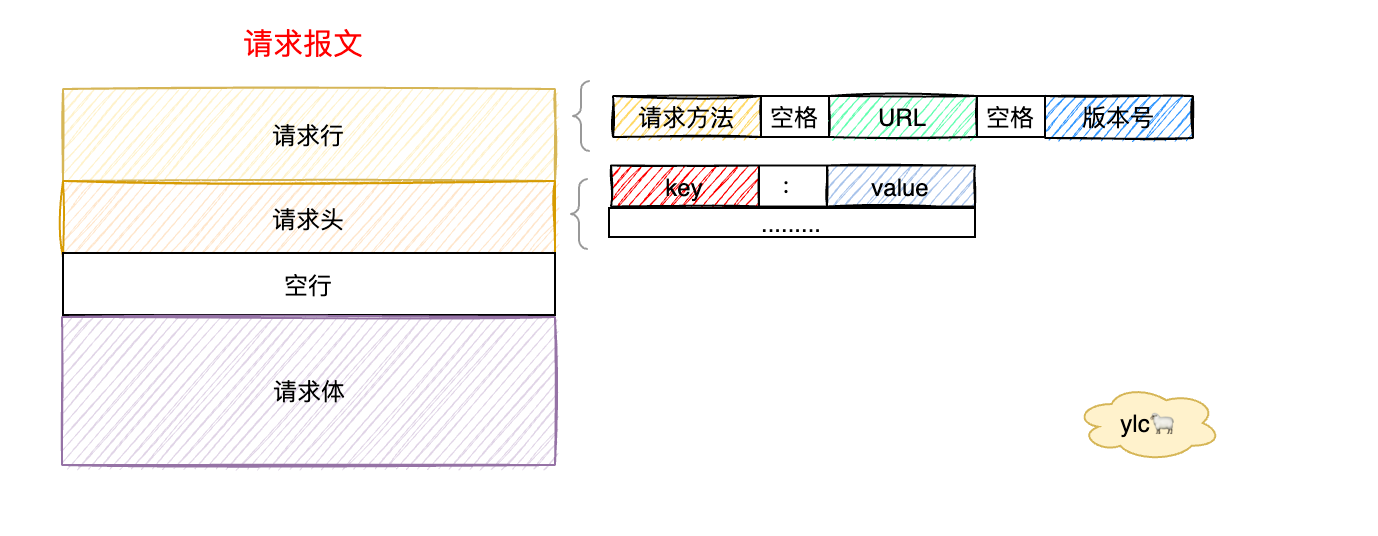
响应报文也类似,唯一的区别是响应行不同
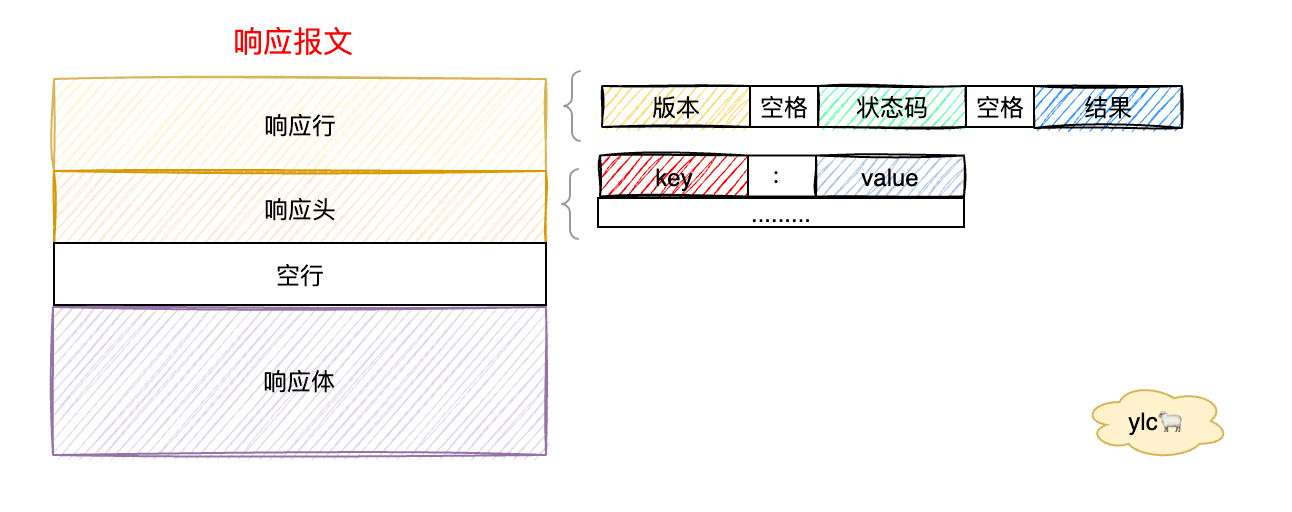
2.1 起始行
包含请求方法、URL、版本号。例如
GET /index.html HTTP/1.1
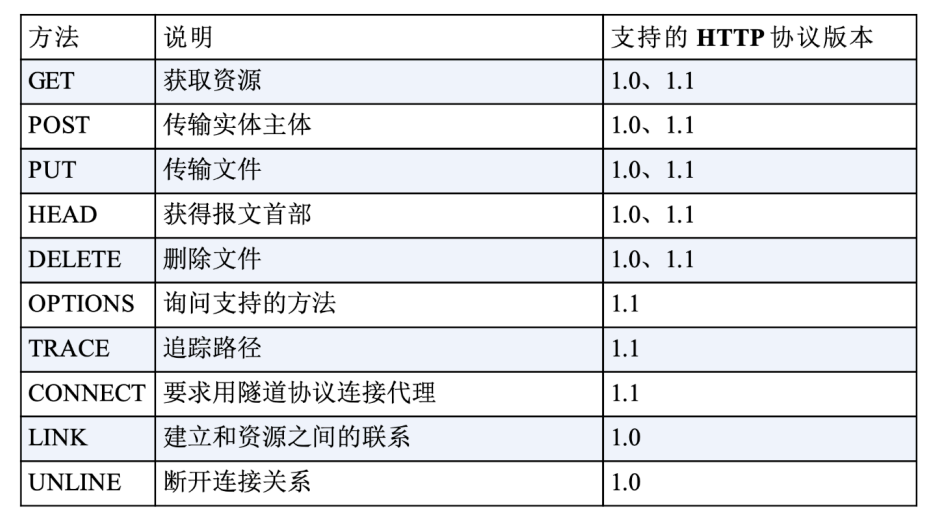
2.1.1请求方法
- GET:获取资源,可以理解为读取或者下载数据
- HEAD:获取资源的元信息
- POST:向资源提交数据,相当于写入或上传数据
- PUT:类似POST
- DELETE:删除资源
- CONNECT:建立特殊的连接隧道
- OPTIONS:列出可对资源实行的方法
- TRACE:追踪请求-响应的传输路径
2.1.2 URL
用户定位互联网上的具体资源,整个完整URL就是:请求协议+主机+端口

-
请求协议可以为ftp://、http://、ssh://
-
主机就是host
-
端口默认http为80、https为443、ssh为22
最后效果就是:https://www.baidu.com:443
2.1.3 版本号
HTTP 1.0、HTTP 1.1、HTTP 2.0
HTTP 1.0:1996年引入,用户名和密码没有加密、不支持断点续传一次传送全部数据等等,发送短链接都需要三次握手四次挥手效率低,确立了大部分现在使用的技术,但它不是正式标准
HTTP 1.1:1999年引入,使用长连接一次建立可以多次发送数据、可以控制缓存失效、并且支持断点续传。是目前互联网上使用最广泛的协议,功能也非常完善
HTTP 2.0:2015年开发的,使用压缩算法压缩、基于HTTPS更加安全、多路复用。但还未普及
2.2 请求头部
头部字段是key-value的形式,key和value之间用“:”分隔,最后用CRLF换行表示字段结束。
HTTP头字段非常灵活,不仅可以使用标准里的Host、Connection等已有头,也可以任意添加自定义头,这就给HTTP协议带来了无限的扩展可能,基本上可以分为四大类:
-
通用字段:在请求头和响应头里都可以出现

-
请求字段:仅能出现在请求头里,进一步说明请求信息或者额外的附加条件
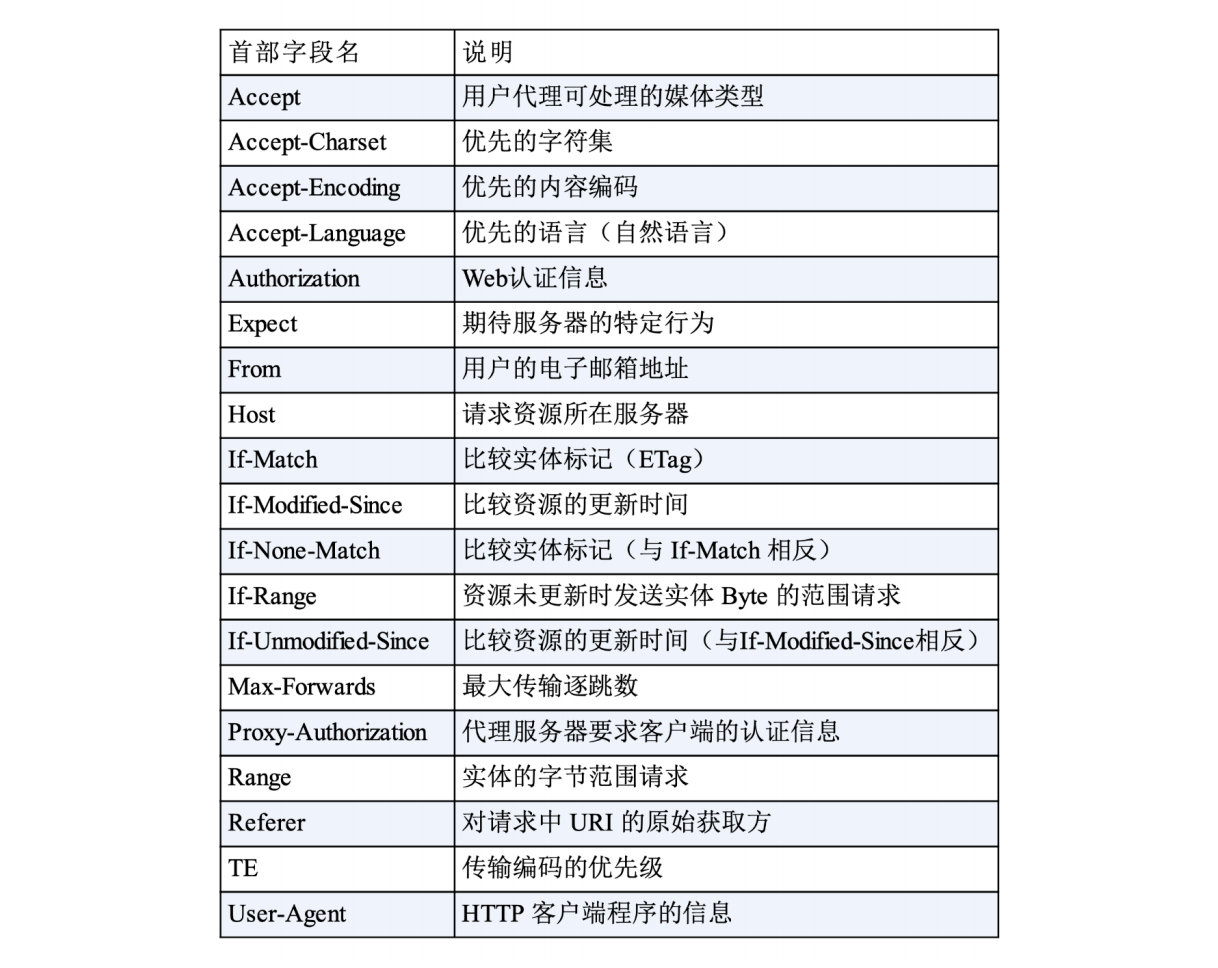
-
响应字段:仅能出现在响应头里,补充说明响应报文的信息
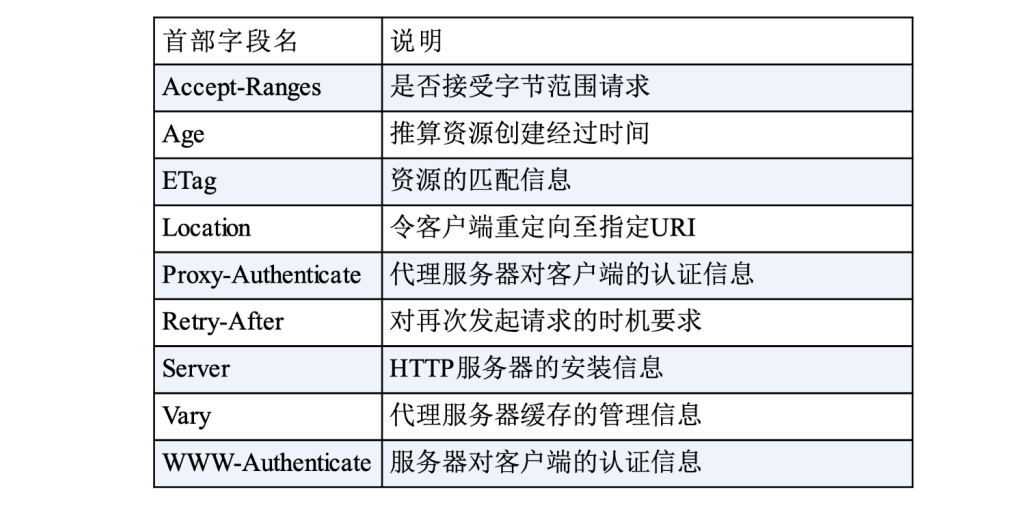
-
实体字段:它实际上属于通用字段,但专门描述body的额外信息
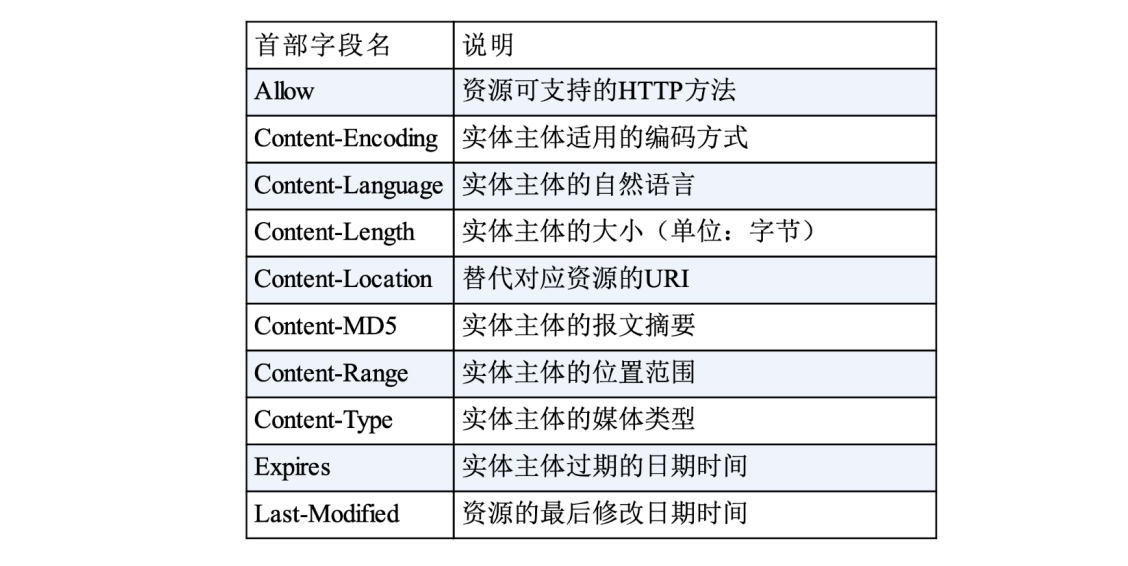
2.3 实体
实体Body中包含一大坨数据,但是很难判断具体是什么类型的数据,只能靠猜前面一些字节来推导,但也有可能判断失误并且效率也不太高。HTTP协议正对这种情况诞生了一个解决方案,方案的名字叫做 多用途互联网邮件扩展(MultipurposeInternetMailExtensions),简称为MIME。
MIME把数据分成了八大类,每个大类下再细分出多个子类,标记的字段为Accept,以下是常见类型
- text:即文本格式的可读数据,我们最熟悉的应该就是text/html了,表示超文本文档,此外还有纯文本text/plain、样式表text/css等。
- image:即图像文件,有image/gif、image/jpeg、image/png等。
- audio/video:音频和视频数据,例如audio/mpeg、video/mp4等。
- application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的有application/json,application/javascript、application/pdf等,另外,如果实在是不知道数据是什么类型,像刚才说的“黑盒”,就会是application/octet-stream,即不透明的二进制数据。
还需要有一个Encodingtype,告诉数据是用的什么编码格式,标记的字段为Accept-Encoding
- gzip:GNUzip压缩格式,也是互联网上最流行的压缩格式
- deflate:zlib(deflate)压缩格式,流行程度仅次于gzip
- br:一种专门为HTTP优化的新压缩算法(Brotli)
通过Accept和Accept-Encoding就可以轻松识别出body的类型,也就能够正确处理数据了。
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
accept-encoding: gzip, deflate, br
如果求报文里没有Accept-Encoding字段,就表示客户端不支持压缩数据;如果响应报文里没有Content-Encoding字段,就表示响应数据没有被压缩
语言类型与编码
上面两个字段解决了识别和压缩问题,但是不同国家不同的语言类型,以及有不同的编码规则。不知道对方使用什么编码就会导致接收的时候无法识别有效信息,因此出现了Unicode和UTF-8,一种统一的编码规则方案
请求头传输字段:表示想要的数据语言
Accept-Language:zh-CN,zh,en
Accept-Charset:gbk,utf-8
响应头传输字段:表示实际使用的字段
Content-Language:zh-CN
Content-Type:text/html;charset=utf-8
内容协商的质量值
在使用accept、Accept-Encoding、Accept-Language等请求头字段,可以用q设定优先级,权重的最大值是1,最小值是0.01,默认值是1,如果值是0就表示拒绝。
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
HTTP大文件传输
有时候网页里面包含太多的数据几百MB或者几G几十G那种图片视频,这样的数据需要带宽太高没发一次性传输过来,只能通过类似水管流水一样输出。为了完成这种传输,HTTP产生了几种方案
-
数据压缩
可以体积变小,对于视频那样的数据本身就经过压缩了,作用就不大
-
分块传输
把一整块数据分为一小块分别传输,这一带宽也不会很高
-
范围请求
有时候看视频需要跳过部分观看,其实就是想获取其中某一段数据,HTTP里面有一个范围请求的概念
请求头里面有一个字段,格式是“bytes=x-y”
range:bytes=1512145-1591415
响应头里面有个字段,片段的实际偏移量和资源的总大小,格式是bytesx-y/length
Content-Range: bytes 1512145-1591415/2736753
-
多段数据
一次请求获取多个片段
Range:bytes=0-9,20-29
响应报文的数据类型是“multipart/byteranges”,body里的多个部分会用boundary字符串分隔。
HTTP是请求应答模式,每次都会先和服务器建立连接三次握手,然后收到响应之后会关闭连接四次挥手。这个连接过程很短暂又称为短连接,相当于重复的开启关闭步骤这样非常消耗时间。
针对这个缺点,出现了长连接的方式,就是打开连接之后不会立马关闭,而是等执行完操作或者等待一定时间才关闭。关于连接的相关字段是告诉服务器这是一个长连接
Connetion:Keep-Alive
但是长连接一直不关闭也会消耗服务器资源,因此可以使用
- 使用“keepalive_timeout”指令,设置长连接的超时时间,如果在一段时间内连接上没有任何数据收发就主动断开连接,避免空闲连接占用系统资源。
- 使用“keepalive_requests”指令,设置长连接上可发送的最大请求次数。比如设置成1000,那么当Nginx在这个连接上处理了1000个请求后,也会主动断开连接。
服务器收到请求报文,解析后需要进行处理,最后是拼出一个响应报文发回客户端。
响应报文由响应头加响应体数据组成,响应头又由状态行和头字段构成,状态码的意义在于用于表达HTTP数据处理的状态
-
1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
-
2××:成功,报文已经收到并被正确处理;
- 200:请求成功,响应头后有body数据
- 204:请求成功,响应头后没有body数据
-
3××:重定向,资源位置发生变动,需要客户端重新发送请求;
-
301:永久重定向,说明请求的资源已经不存在了,需改⽤新的 URL 再次访问
-
302:临时重定向,资源还在,暂时需要⽤另⼀个 URL 来访问
-
304:表示资源未修改,定向已存在的缓冲⽂件,也称缓存᯿定向,⽤于缓
存控制
-
-
4××:客户端错误,请求报文有误,服务器无法处理;
- 400:通用的错误码,表示请求报文有错误
- 403:表示服务器禁止访问资源
- 404:找不到资源
- 405:不允许使用某些方法操作资源,例如不允许POST只能GET
-
5××:服务器错误,服务器在处理请求时内部发生了错误
- 500:通用的错误码
- 502:服务器作为网关或者代理时返回的错误码,
- 503:超时响应
浏览网站的时候经常有各种链接,我们点击这个链接就会跳转到另一个页面,这个行为是我们主动控制触发,却是服务器控制的它去请求这个URL然后返回数据,也叫跳转(Forward)
但是还有一种不是我们能够控制的,是服务器主动控制的,客户端去请求那个URL,URL地址栏会变,这个叫重定向(Redirect)
直接转发 Forward 就相当于:“A找B借钱,B说没有,然后B去找C借,借到借不到都会把消息传递给A”;
间接转发 Redirect 就相当于:"A找B借钱,B说没有,让A去找C借"。
forward:一般用于用户登陆的时候,根据角色转发到相应的模块 redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等
HTTP缓存浏览器使用HTTP获取资源的成本较高,有必要把来之不易的数据缓存起来,缓存的流程是
- 浏览器发现缓存无数据,于是发送请求,向服务器获取资源;
- 服务器响应请求,返回资源,同时标记资源的有效期;
- 浏览器缓存资源,等待下次重用
Cache-Control:max-age=30
这个max-age表示从创建这个响应报文,整个缓存的生存时间
HTTP缓存有几种不同的缓存类型
no_store:不允许缓存,用于某些变化非常频繁的数据,例如秒杀页面;no_cache:它的字面含义容易与no_store搞混,实际的意思并不是不允许缓存,而是可以缓存,但在使用之前必须要去服务器验证是否过期,是否有最新的版本;must-revalidate:又是一个和no_cache相似的词,它的意思是如果缓存不过期就可以继续使用,但过期了如果还想用就必须去服务器验证。
Last-modified:就是文件的最后修改时间。
真正使用到缓存就是在前进后退的时候,这个时候不会发送新的请求,不再进行网络通讯,这个实现的原理就是
HTTP协议定义了一系列“If”开头的“条件请求”字段,专门用来检查验证资源是否过期,最常用的是if-Modified-Since和If-None-Match这两个,有两种不同条件搭配使用
- 第一次响应报文提供
ETag,第二次请求时就可以发出If-None-Match带上缓存里的原值,验证资源是否是最新的,资源没有变就返回一个304,表示缓存依然有效 - 第一次响应报文提供
Last-modified,第二次请求时就可以发出If-Modified-Since带上缓存里的原值,验证资源是否是最新的
ETag是“实体标签”(EntityTag)的缩写,是资源的一个唯一标识,主要是用来解决修改时间无法准确区分文件变化的问题,ETag就可以精确地识别资源的变动情况,让浏览器能够更有效地利用缓存。
强ETag要求资源在字节级别必须完全相符,弱ETag在值前有个“W/”标记,只要求资源在语义上没有变化,但内部可能会有部分发生了改变
HTTP的Cookie机制HTTP是无状态的,意味着每个请求都是独立的,也无法知道前面的信息,也无法纪录信息,但有的场景交互是需要承前启后的,两种用于保持 HTTP 连接状态的技术就应运而生了,一个是 Cookie,而另一个则是 Session。
Cookie是服务器用于标记客户端的,让服务器记住不同的客户端身份,用户第一次访问浏览器,服务器不知道它的身份,因此会在头部放置一个Set-Cookie,里面可以放置多个值,但大小也是有限制的。
请求头:
Set-Cookie:tst=; path=/; expires=Thu, 01 Jan 1970 00:00:00 GMT; domain=.zhihu.com; httponly
响应头:
Cookie: tst=; path=/; expires=Thu, 01 Jan 1970 00:00:00 GMT; domain=.zhihu.com; httponly
Cookie其他属性
- Expires:过期时间,可以理解为“截止日期
- Max-Age:相对时间,多少秒以后过期。Max-Age优先级更高,会先采用Max-Age
- Domain:Cookie的作用域,让浏览器仅发送给特定的服务器和URI,避免被其他网站盗用
- Path:Cookie所属的路径
- HttpOnly:保证Cookie的安全性,Cookie只能通过浏览器HTTP协议传输,禁止其他方式访问
- SameSite:防范“跨站请求伪造”(XSRF)攻击,可以严格限定Cookie不能随着跳转链接跨站发送
- Secure:这个Cookie仅能用HTTPS协议加密传输,明文的HTTP协议会禁止发送。但Cookie本身不是加密的,浏览器里还是以明文的形式存在
Cookie的作用
- 有状态的会话事务和身份识别:可以保持登录状态免登录,还可以作为身份标识
- 广告跟踪:其他网站给你贴小标签,存储在它们的Cookie中,也叫第三方Cookie,上其他的网站,别的广告就能用Cookie读出你的身份,然后做行为分析,再推给你广告
Host :指定服务器域名,例如Host: gitee.com
Content-Length :表明返回body数据的长度,Content-Length: 1000
Connetion :要求服务器使用持久连接,Connection: keep-alive
Content-Type:用于服务器响应的时候告诉客户端是什么格式的数据,一般是 Content-Type: text/html; charset=utf-8
Content-Encoding:说明字段的压缩方式,例如Accept-Encoding: gzip, deflate
User-Agent:是请求字段,描述发起HTTP请求的客户端
HTTP协议中有两个角色,请求方和应答方,现在还有一个角色就是HTTP代理,代理服务本身不生产内容,而是处于中间位置转发上下游的请求和响应
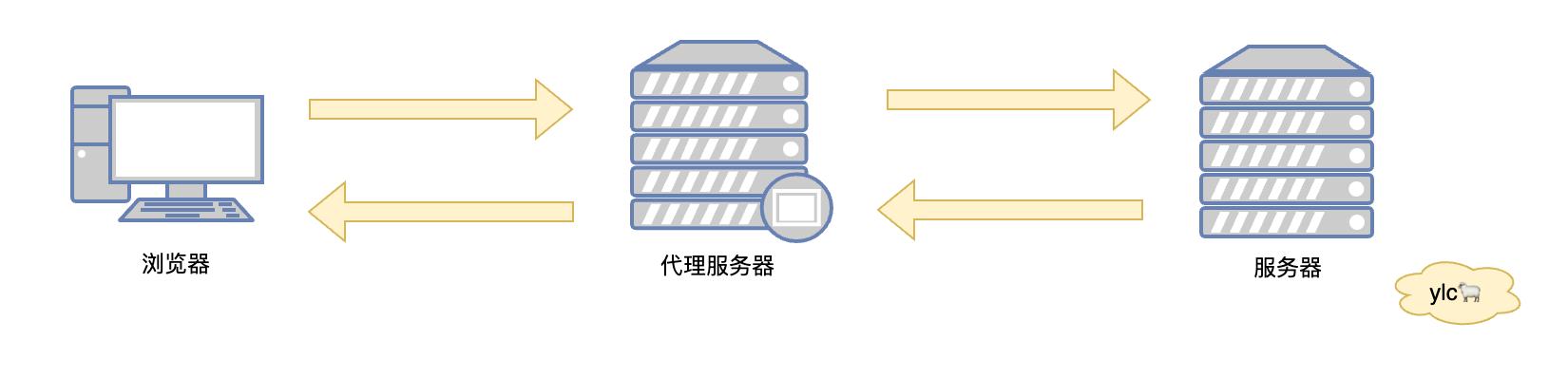
代理服务的作用
那么这个代理的作用是什么呢?因为代理是中间角色,所以两边客户端和服务器都不知道对方是具体是谁,又可以分为正向代理和反向代理
正向代理是代理客户端向服务器发送消息,例如我们想去访问国外网站无法直接访问,需要通过代理服务器帮我们和目标服务器进行交互,目标服务器不知道真正的访问要访问的是谁
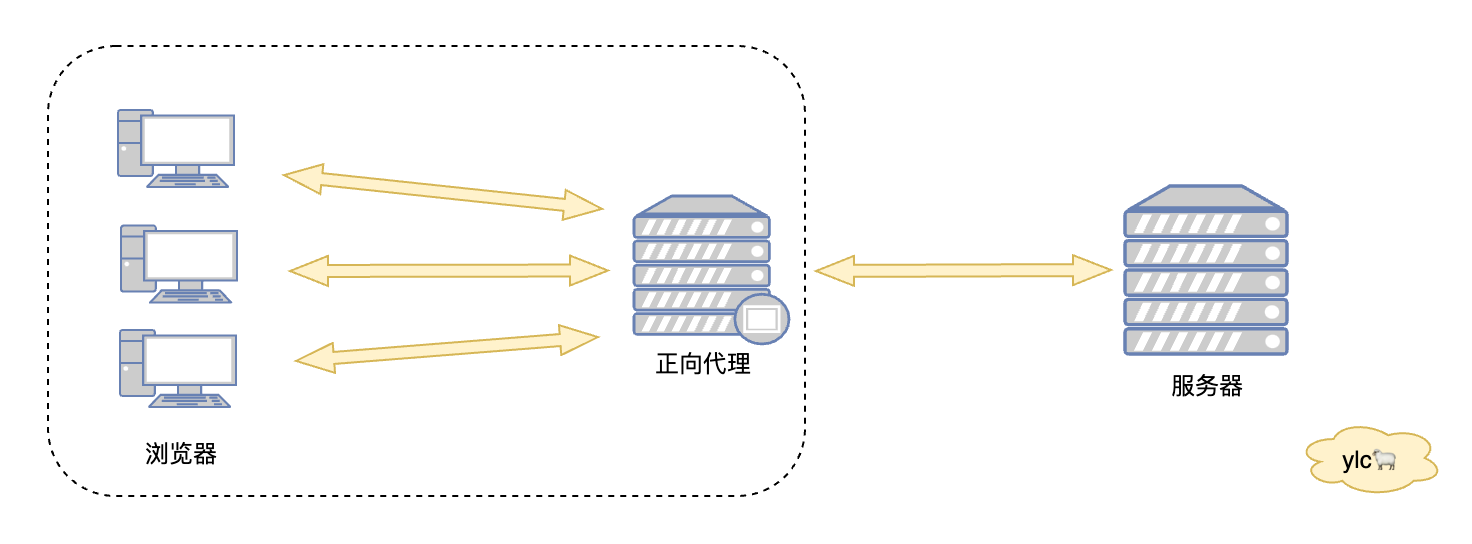
正向代理的主要作用就是突破访问限制、隐藏客户端、提高访问速度
反向代理是代理服务器向客户端发送消息,例如在一线城市租房经常会遇到二房东,所谓二房东就是自己在很多真正的房东那里把房子承包下来,然后租给租户,但租户根本不知道真正的房东是谁。
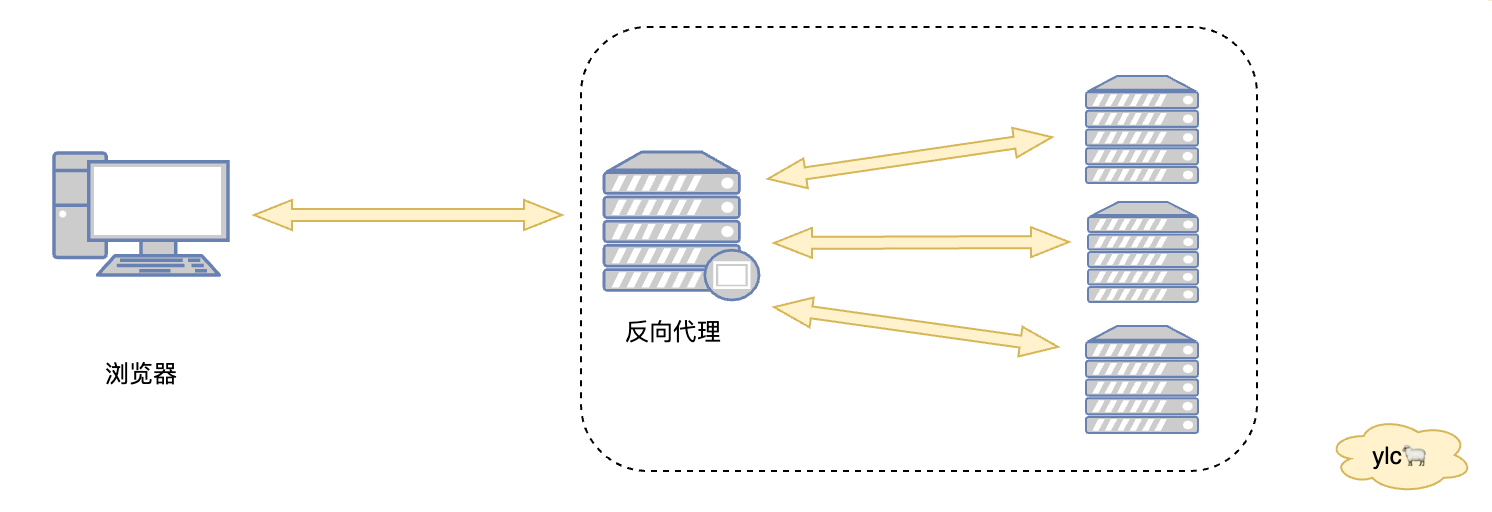
反向代理可以用来负载均衡、隐藏服务器、提供安全保障
HTTP中代理需要使用Via字段表明代理身份,每经过一个代理节点就会在字段里面增加一个代理人,但是也不清楚客户端的信息。
通常服务器需要知道客户端的真实IP地址,最常用的两个头字段是“X-Forwarded-For”和“X-Real-IP”分别表示为谁转发还有客户端的IP地址
HTTP缓存代理HTTP代理只是一个中转的作用,但是对于那种读多写少的数据,一秒钟成千上万次的请求,如果缓存几秒钟的的数据就可以降低服务器的压力。
在HTTP中,HTTP缓存代理很特殊既是服务器也可以是客户端,HTTP本身也有缓存属性,为了区分HTTP缓存代理使用了新的属性:private、public
private表示缓存只能在客户端保存,是用户“私有”的,不能放在代理上与别人共享。而“public”的意思就是缓存完全开放,谁都可以存,谁都可以用。

HTTP整个传输过程完全透明,任何人都能够在链路中截获、修改或者伪造请求/响应报文,数据不具有可信性。这样对于银行、购物、个人信息等等数据都不安全
HTTPS在 HTTP 与 TCP 层之间加⼊了 SSL/TLS 协议,可以很好的解决了上述的⻛险,默认端口号是443,请求-应答模式、报文结构、请求方法、URI、头字段、连接管理等等都完全沿用HTTP,但是HTTPS增加了四大安全特性,分别是:
- 机密性(Secrecy/Confidentiality):只有可信的人才能访问
- 完整性(Integrity):传输过程中没有被窜改
- 身份认证(Authentication):确认对方的真实身份
- 不可否认(Non-repudiation/Undeniable):发生的传输行为不可抵赖
保障安全的秘密就是这个名字里的“s”,它代表SSL/TLS协议,把HTTP下层的传输协议由TCP/IP换成了SSL/TLS
SSL/TLS
SSL即安全套接层(Secure Sockets Layer),在OSI模型中处于第5层(会话层),有v2和v3两个稳定的版本,在V3时被改名TSL(传输层安全,Transport Layer Security),所以TLS1.0实际上就是SSLv3.1。
目前应用的最广泛的TLS是1.2,TLS由记录协议、握手协议、警告协议、变更密码规范协议、扩展协议等几个子协议组成,综合使用了对称加密、非对称加密、身份认证等许多密码学前沿技术,浏览器在使用TSL建立连接的时候会使用一套合适的加密算法,会有一串很长的字符:ECDHE-RSA-AES256-GCM-SHA384,基本的形式是:密钥交换算法+签名算法+对称加密算法+摘要算法。
对称加密与非对称加密
对称加密:加密和解密时使用的密钥都是同一个,没有密钥无法解密,常用的有:AES、ChaCha20,运算速度快
非对称加密:有一个公钥和私钥,公钥是公开的,私钥是保密的,公钥加密后只能用私钥解密,反过来,私钥加密后也只能用公钥解密,有几种:DH、DSA、RSA、ECC,但速度慢
把对称加密和非对称加密结合起来就得到了又好又快的混合加密,也就是HTTPS里使用的加密方式
HTTPS保障通讯安全的原理1、混合加密
通信刚开始的时候使用非对称算法,比如RSA、ECDHE,首先解决密钥交换的问题
用随机数产生对称算法使用的会话密钥,再用公钥加密
2、摘要算法
常见摘要算法有:MD5(Message-Digest5)、SHA-1(SecureHashAlgorithm1),但是不够安全,推荐使用SHA-2
SHA-2实际上是一系列摘要算法的统称,总共有6种,常用的有SHA224、SHA256、SHA384,分别能够生成28字节、32字节、48字节的摘要
例如:客户端在发送前通过SHA256加密传输内容,把传输内容和通过摘要算法加密后的传输内容一起发送,再通过会话密钥加密成密文发送给服务器,服务器解密成明文,然后服务器也用SHA256算出加密后的传输内容和摘要算法加密后的传输内容进行对比,说明数据是完整的
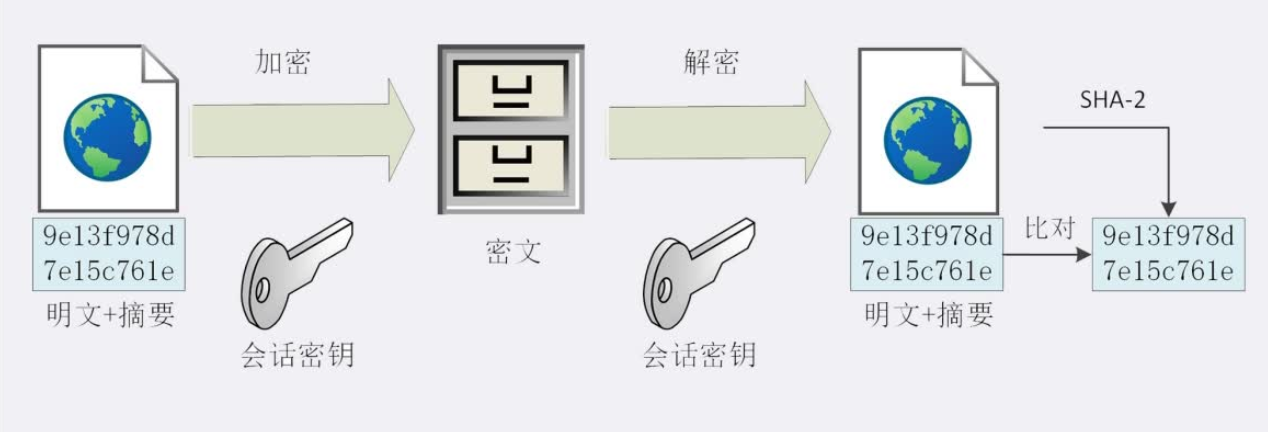
客户端发送的时候把「摘要 + 明⽂」⼀同加密成密⽂后,发送给服务器,服务器解密后,⽤相同的摘要算法算出发送过来的明文,然后对比
3、数字证书
私钥可以保证安全性,但是公钥却缺少防伪手段,这时候出现了CA(CertificateAuthority,证书认证机构)。它就像网络世界里的公安局、教育部、公证中心,具有极高的可信度,由它来给各个公钥签名,用自身的信誉来保证公钥无法伪造,是可信的。它包含序列号、用途、颁发者、有效时间等等,把这些打成一个包再签名,形成数字证书。作为信任链的源头CA有时也会不可信,解决办法有CRL、OCSP,还有终止信任。
HTTPS协议基本流程及优化前面说到HTTPS是 HTTP 与 TCP 层之间加⼊了 SSL/TLS 协议,TCP层之间有三次握手四次挥手,加上SSL/TLS 的握⼿涉及四次通信,总共是11次。
SSL/TLS 协议基本流程:
- 客户端向服务器发起加密通信请求包括:客户端⽀持的 SSL/TLS 协议版本、客户端⽣产的随机数、客户端⽀持的密码套件列表(生成会话密钥)
- 服务器收到客户端请求后,向客户端发出响应:确认 SSL/ TLS 协议版本、服务器⽣产的随机数、确认的密码套件列表、服务器的数字证书
- 客户端回应:查看CA 公钥确认服务器的数字证书的真实性、取出服务器的公钥然后使⽤它加密报⽂、产生第三个随机数
- 服务器的最后回应:查看第三个随机数通过加密算法计算会话秘钥,服务器握⼿结束通知,表示服务器的握⼿阶段已经结束
HTTPS优化
HTTPS慢的原因是多了SSL/TLS 的握⼿涉及四次通信,这里面又包含建立连接时的非对称加密握手,第二个是握手后的对称加密报文传输、获取CA证书等等一些网络耗时,主要优化是根据软件优化:
- 采用新版本的协议
- 使用更快的加密解密算法
- 使用证书优化
- 会话复用,一次建立连接多次通讯
1.GET是从服务器请求资源,一般是静态文本、图片、视频等等,POST则是提交数据,提交内容放在Body里面
2.GET是不安全的请求url有长度限制2048byte(2kb),post对把请求参数放在请求体里面长度没有限制
3.GET请求在回退时是无害的,而post请求在回退时会被再重新执行一次
4.GET请求的静态资源会被缓存,而post请求不会被缓存
HTTP特性优点
最大的优点是简单、灵活和易于扩展;
拥有成熟的软硬件环境,应用的非常广泛,是互联网的基础设施;
是无状态的,可以轻松实现集群化,扩展性能,
缺点
是明文传输,数据完全肉眼可见,能够方便地研究分析,但也容易被窃听,不安全
是不安全的,无法验证通信双方的身份,也不能判断报文是否被窜改;
性能不算差,但不完全适应现在的互联网,还有很大的提升空间。
为什么HTTP是无状态协议HTTP对用户的操作没有记忆力,每个请求都是完全独立的,每个请求包含了处理这个请求所需的完整的数据,发送请求不涉及到状态变更,因此我们登录之后再次就可以免登录不是HTTP的作用,而是Cookie机制,让浏览器具有记忆力。
Cookie
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就向客户端浏览器颁发一个Cookie。客户端会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容
如果不设置过期时间那么浏览器关闭就会消失,如果设置过期时间那么关闭浏览器直到在设定有效期内都有效
但是服务端无法识别具体是哪个客户端发来的信息
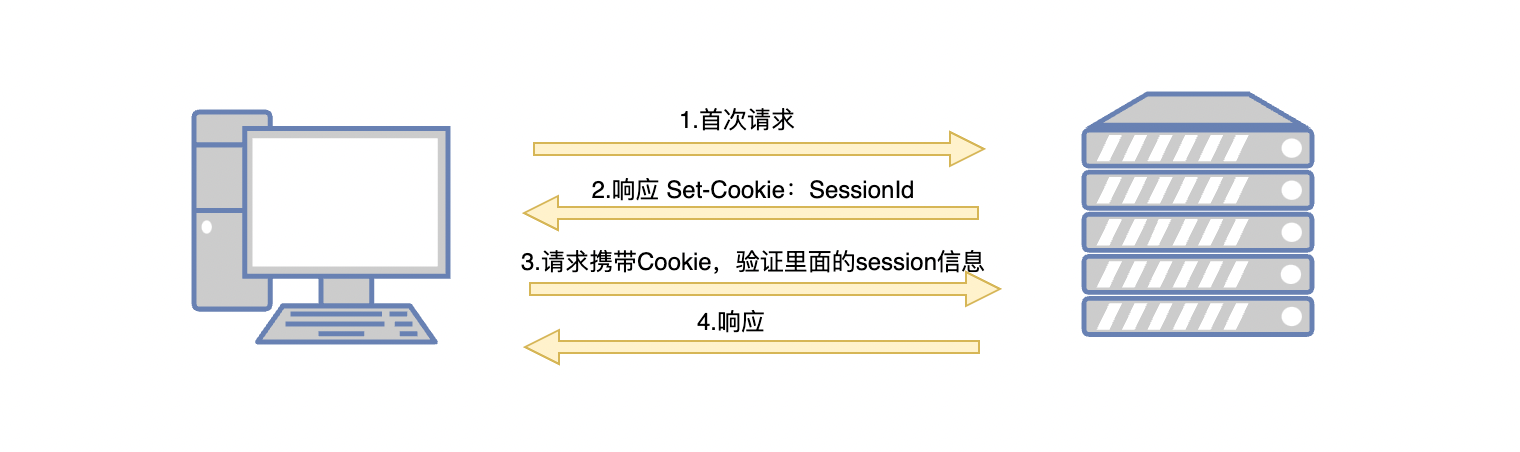
Session
Session保存在服务器上,客户端请求服务器后,服务器都会建立一个session并自动分配一个SessionId,用于标识用户的唯一身份,当客户端浏览器再次访问时只需要从该Session中查找该用户的状态
有了Cookie和Session就可以识别身份了,比如:有很多人来了我家里喝茶,但是我都不认识那些人。假如我给来喝茶的人颁发一个序号,那么当他下次来喝茶我就知道这个人之前来过是老朋友了
Cookie 和 Session 有什么不同- 作用范围不同,Cookie 保存在客户端(浏览器),Session 保存在服务器端。
- 存取方式的不同,Cookie 只能保存 ASCII,Session 可以存任意数据类型,一般情况下我们可以在 Session 中保持一些常用变量信息,比如说 UserId 等。
- 有效期不同,Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭或者 Session 超时都会失效。
- 隐私策略不同,Cookie 存储在客户端,比较容易遭到不法获取,早期有人将用户的登录名和密码存储在 Cookie 中导致信息被窃取;Session 存储在服务端,安全性相对 Cookie 要好一些。
- 存储大小不同, 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie。
第一种方案,每次请求中都携带一个 SessionID 的参数,也可以 Post 的方式提交,也可以在请求的地址后面拼接 ?SessionID=XXX
第二种方案,Token 机制。Token 机制多用于 App 客户端和服务器交互的模式,也可以用于 Web 端做用户状态管理。
如何解决跨域请求?Jsonp 跨域的原理是什么?说起跨域请求,必须要了解浏览器的同源策略,同源策略/SOP(Same origin policy)是一种约定,由 Netscape 公司 1995年引入浏览器,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到 XSS、CSFR 等攻击。所谓同源是指"协议+域名+端口"三者相同,即便两个不同的域名指向同一个 ip 地址,也非同源。
解决跨域请求的常用方法是:
- 通过代理来避免,比如使用 Nginx 在后端转发请求,避免了前端出现跨域的问题。
- 通过 Jsonp 跨域
- 其它跨域解决方案:Cron
- 首先浏览器会根据输入URL地址,去找本地是否被DNS缓存,有的话直接返回IP,假如没有回查询本机的host文件是否有配置IP地址
- 如果也没有那就直接向网络中发起一个DNS查询,通过DNS根域名服务器->顶级域名服务器->权威DNS服务器获取到域名对应的IP
- 浏览器需要和目标地址进行TCP连接,经过三次握手
- 浏览器向服务器发送请求,服务器响应请求,然后就会进行四次挥手关闭连接
参考资料:
罗剑锋.透视HTTP协议.极客时间
小林Coding-图解网络