在之前的文章中,介绍了 ES 整体的架构和内容,这篇主要针对 ES 最小的存储单位 - 文档以及由文档组成的索引进行详细介绍。
会涉及到如下的内容:
- 文档的 CURD 操作。
- Dynamic Mapping 和显示 Mapping 的区别
- 常见 Mapping 类型与常见参数介绍
- Index Template 和 Dynamic Template
和常见的数据库类似,ES 也支持 CURD 操作:
下面展示了对单个 ES 文档的操作:
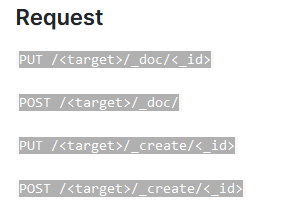 创建或者更新索引中的文档。在指定 id 的情况下,如果 id 存在,则会更新。如果不指定,则会创建。
Get
创建或者更新索引中的文档。在指定 id 的情况下,如果 id 存在,则会更新。如果不指定,则会创建。
Get
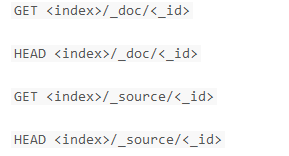 查询某个文档。
Delete
DELETE /
查询某个文档。
Delete
DELETE /下面是实际操作文档的例子, 打开 kibana 的开发者工具:
先来创建一个文档:
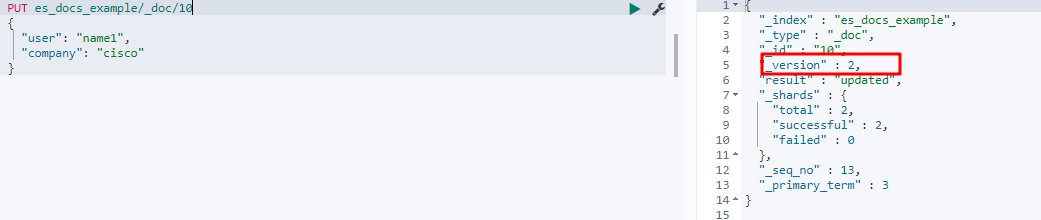
ES 在创建文档时,会有两种方式 index 和 create。index 与 create 不同在于,在指定 id 的情况下,如果 id 存在,index 会覆盖,同时版本号+1,而 create 会报错不让创建。
这里手动指定 id 为10,使用 index 方法,创建了一个文档,注意版本号为 1。

注意再次发送同样的情况,可以看到正常执行,版本号变成 2了。
但是使用 create 方法:

这里报错,显示文档已经存在。
需要注意的 ES 这里的更新并不是正常理解的更新,而是先把老文档删掉,然后创建一个新文档出来。
接着对文档进行更新:

可以看到这里只更新 user 字段,这种更新和之前 index 那种更新不同,属于部分更新,将增加的内容 merge 进原始文档。
对文档进行读取,这里由于之前更新了三次,所以 version = 3:

删除文档就很好理解了,但有一点需要注意,删除文档时并不会立马释放空间,而是将文档标记位 deleted 状态,后台进程会在合适的时候清理这些标记位已经删除的文档。
批量文档操作批量写入
相较于当个文档的操作,大批量的操作对于 ES 来说,是更为常见的场景。ES 也提供了批量 API,该 API 支持在一次 API请求中包含 4 种类型, 并且 Response 中会针对每一条操作返回一个对应的结果。
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
批量读取
可以同时传入多个文档 id,进行读取,多个文档可以属于不同的索引。
GET /_mget
{
"docs": [
{
"_index": "my-index-000001",
"_id": "1"
},
{
"_index": "my-index-000001",
"_id": "2"
}
]
}
索引是多个文档的集合,体现了逻辑空间的概念。对于每个索引来说都可以设置 Mapping 和 Setting 两部分。
其中 Mapping 定义了文档包含字段的类型与名称,以及如倒排索引,分词的一些设置。Setting 定义了如何将数据分布保存在不同的节点上。
数据类型ES 中的数据类型分为三种:
- 简单类型
- 复杂类型
- 对象类型
- 嵌套类型
- 特殊类型
- 地理位置等
下图中显示了 ES 中常见的简单数据类型以及和 SQL 对应的关系。
null
null
NULL
0
boolean
boolean
BOOLEAN
1
byte
byte
TINYINT
3
short
short
SMALLINT
5
integer
integer
INTEGER
10
long
long
BIGINT
19
double
double
DOUBLE
15
float
float
REAL
7
half_float
half_float
FLOAT
3
scaled_float
scaled_float
DOUBLE
15
keyword type family
keyword
VARCHAR
32,766
text
text
VARCHAR
2,147,483,647
binary
binary
VARBINARY
2,147,483,647
date
datetime
TIMESTAMP
29
ip
ip
VARCHAR
39
Dynamic Mapping
我们知道,Mapping 类似于数据库 Scheme 的定义,但回想之前对文档 CURD 的操作时,我们并未手动设置 Mapping,但可以自动创建文档,原因就在于利用了 Dynamic Mapping 的特性。就是即使索引不存在时,也可以手动创建索引,并根据文档信息自动推算出对应的 Mapping 关系。
比如之前创建的文档,如下就是生成的 Mapping 关系,ES 自动将 company 和 user 推断为 text 字段。
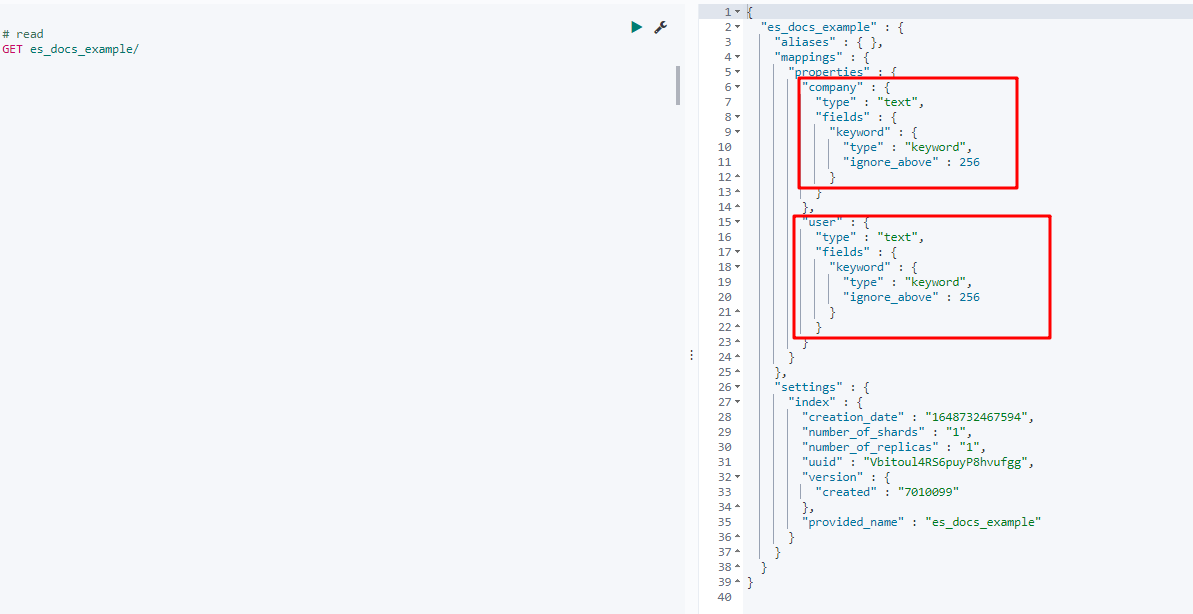
当 Dynamic Mapping 也有自己的缺点:就是推算不准确,比如上面的例子,company 和 user 的字段为 keyword 类型更为合适,以至于搜索时出现一些问题。
dynamic Mapping 可以通过 dynamic 字段进行控制, 其值为 true,false,strict 三种类型。
对于已经创建的索引,在修改 Mapping 分为两种情况:
- 增加新的字段:
- dynamic 为 true,新字段写入后,Mapping 也会被更新
- dynamic 为 false,字段可以写入到 _source, 但 Mapping 不会被更新,自然也不会被索引
- dynamic 为 strict,不允许写入
- 修改已经存在字段的类型:
- 不允许修改,因为 Lucene 生成的倒排索引,不允许被修改。
- 除非重新生成索引。
与 Dynamic Mapping 不同,显示指定 Mapping 可以允许我们手动指定 Mapping 结构。
编写 Mapping 有两种方式:
- 可以参考 doc
- 利用 dynamic 自动创建功能,查询后,自己再编辑成想要的结构。
看一个简单的例子:
PUT user
{
"user" : {
"mappings" : {
"properties" : {
"company" : {
"type" : "keyword"
"null_value": "NULL"
}
},
"name" : {
"type" : "keyword",
"index_options": "offsets"
},
"id_card" : {
"type" : "keyword",
"index": false # 表示该字段不需要被索引,不用被搜索到
}
}
}
}
"null_value":表示对 NULL 值可以进行搜索。
"index": false 表示该字段不需要被索引,不用被搜索到
"index_options": "offsets" 表示对倒排索引的结构进行设置:
- docs :表示记录 doc id
- freqs :表示记录 doc id 和 term frequencies
- position :表示记录 doc id 和 term frequencies 和 term position(Text 类型默认记录为 position)
- offsets: 表示记录 doc id 和 term frequencies 和 term position 以及 character offset.
关于倒排可以查看之前写的这篇文章。
Index Template 和 Dynamic Template Index Template考虑到数据不断增长的情况的,就需要按照一定的规则,将数据分散在不同的 Index 中。但每次都需要为每个 Index 设置 Mapping 和 Setting 关系。
这时 Index Template 就可以很好满足这个需求。
在 Index Template 中,可以通过设置一个通配名称,当创建的索引的名称,满足该条件时,就会使用模板的规则。
Note:
- 模板只会在创建新索引时生效,修改模板不会影响已经创建的索引。
- 可以设置多个模板,通过 "order" 参数,控制那个模板的规则生效。
下面这个例子就是为告警建立的一个 template,当创建的名字以 alarm 开头时,就会使用该索引。
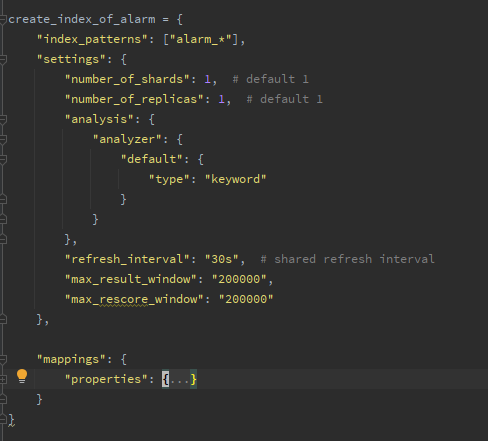
在上面 Dynamic Mapping 的介绍中知道,ES 对于没有设置 Mapping 字段的内容,会自己推算一个类型,但这就可能造成推算类型不准确的情况。
这时就可以用 Dynamic Template 来解决,通过规范插入的字段的名称,来指定他的类型:
- 比如可以 is 开头的字段,都设置成 boolean
- long_ 开头的字段,设置成 long
- 所有字符串类型,设置成 keyword
Dynamic Template 直接作用在索引上, 看下面这个例子。
PUT my-index-000001
{
"mappings": {
"dynamic_templates": [
{
"longs_as_strings": {
"match_mapping_type": "string",
"match": "long_*",
"unmatch": "*_text",
"mapping": {
"type": "long"
}
}
}
]
}
}
PUT my-index-000001/_doc/1
{
"long_num": "5",
"long_text": "foo"
}
当匹配到以 long 开头的字符串时并且不包含以 _text 结尾,会将其设置成 long 类。
总结本篇文章中,主要是对 ES 文档和索引的设置进行了说明。
ES 文档支持 CURD 操作,但需要知道 Index 和 create 的区别在于,对于指定 id 情况下的处理方式不同。同时为了适应大数据量的读取和写入,可以用 bulk api.
对于 ES 索引来说,在创建时,支持两种方式来指定 Setting 和 Mapping 的关系。一种 Dynamic Mapping,这种方式不需要手动设置 Index 格式,会根据文档自动的创建,但缺点在于推断的类型不不准确。而显示 Mapping,可以手动规定 index 的格式。
考虑到数据不断增长的情况,需要将数据拆分到不同的 index 上,可以通过 IndexTemplate 实现。
对于 Dynamic Mapping,推断不准确的情况,可以通过 Dynamic Template 手动规定创建的类型。
参考https://www.elastic.co/guide/en/elasticsearch/reference/7.16/docs.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/mapping-params.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic-templates.html