Prometheus 包含一个存储在本地磁盘的时间序列数据库,同时也支持与远程存储系统集成,比如grafana cloud 提供的免费云存储API,只需将remote_write接口信息填写在Prometheus配置文件即可。
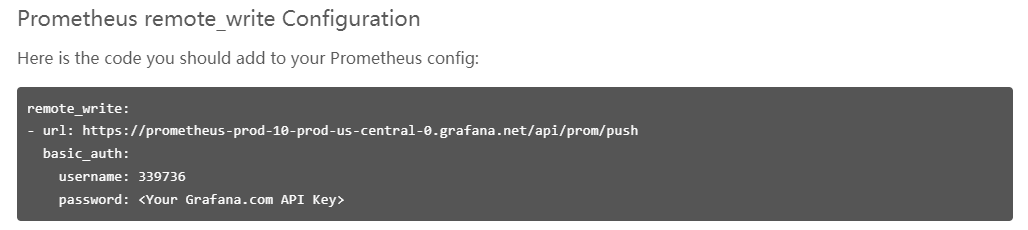
本文不涉及远程存储接口内容,主要介绍Prometheus 时序数据的本地存储实现原理。
什么是时序数据?在学习Prometheus TSDB存储原理之前,我们先来认识一下Prometheus TSDB、InfluxDB这类时序数据库的时序数据指的是什么?
时序数据通常以(key,value)的形式出现,在时间序列采集点上所对应值的集,即每个数据点都是一个由时间戳和值组成的元组。
identifier->(t0,v0),(t1,v1),(t2,v2)...
Prometheus TSDB的数据模型
<metric name>{<label name>=<label value>, ...}
具体到某个实例中
requests_total{method="POST", handler="/messages"}
在存储时可以通过name label来标记metric name,再通过标识符@来标识时间,这样构成了一个完整的时序数据样本。
----------------------------------------key-----------------------------------------------value---------
{__name__="requests_total",method="POST", handler="/messages"} @1649483597.197 52
一个时间序列是一组时间上严格单调递增的数据点序列,它可以通过metric来寻址。抽象成二维平面来看,二维平面的横轴代表单调递增的时间,metrics 遍及整个纵轴。在提取样本数据时只要给定时间窗口和metric就可以得到value

上面我们简单了解了时序数据,接下来我们展开Prometheus TSDB存储(V3引擎)
Prometheus TSDB 概览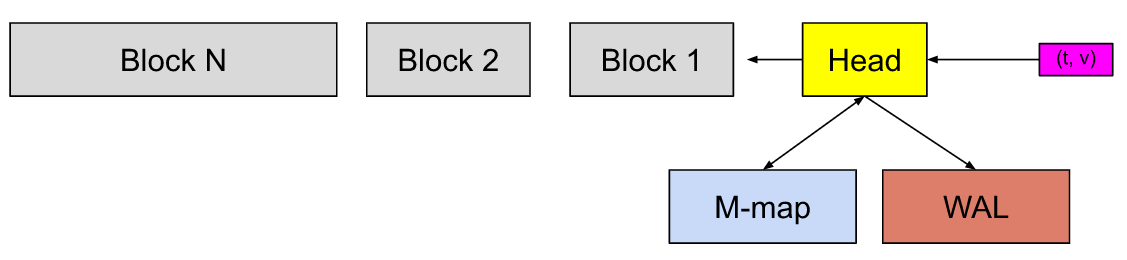
在上图中,Head 块是TSDB的内存块,灰色块Block是磁盘上的持久块。
首先传入的样本(t,v)进入 Head 块,为了防止内存数据丢失先做一次预写日志 (WAL),并在内存中停留一段时间,然后刷新到磁盘并进行内存映射(M-map)。当这些内存映射的块或内存中的块老化到某个时间点时,会作为持久块Block存储到磁盘。接下来多个Block在它们变旧时被合并,并在超过保留期限后被清理。
Head中样本的生命周期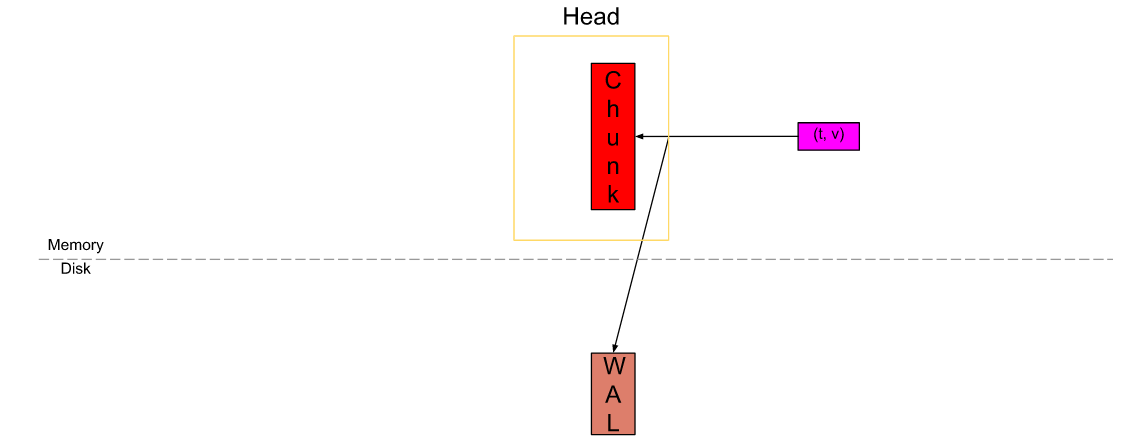
当一个样本传入时,它会被加载到Head中的active chunk(红色块),这是唯一一个可以主动写入数据的单元,为了防止内存数据丢失还会做一次预写日志 (WAL)。
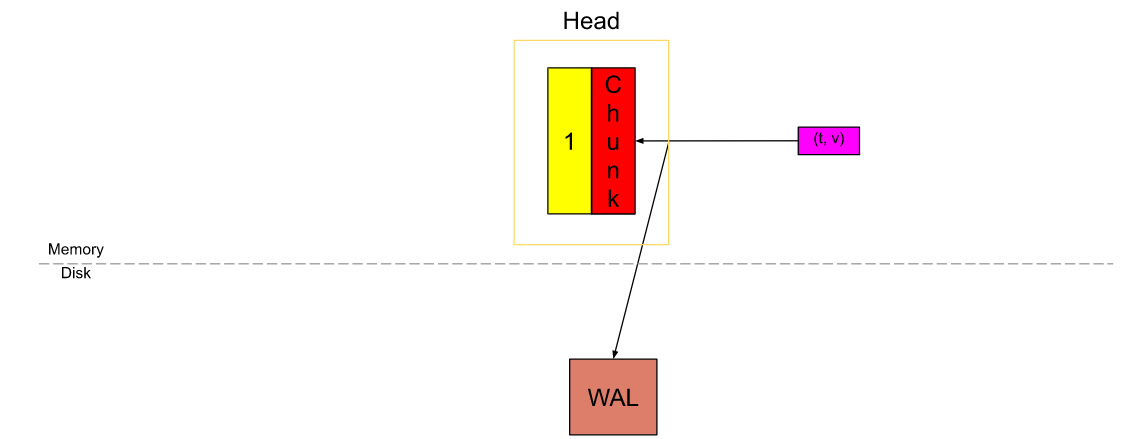
一旦active chunk被填满时(超过2小时或120样本),将旧的数据截断为head_chunk1。
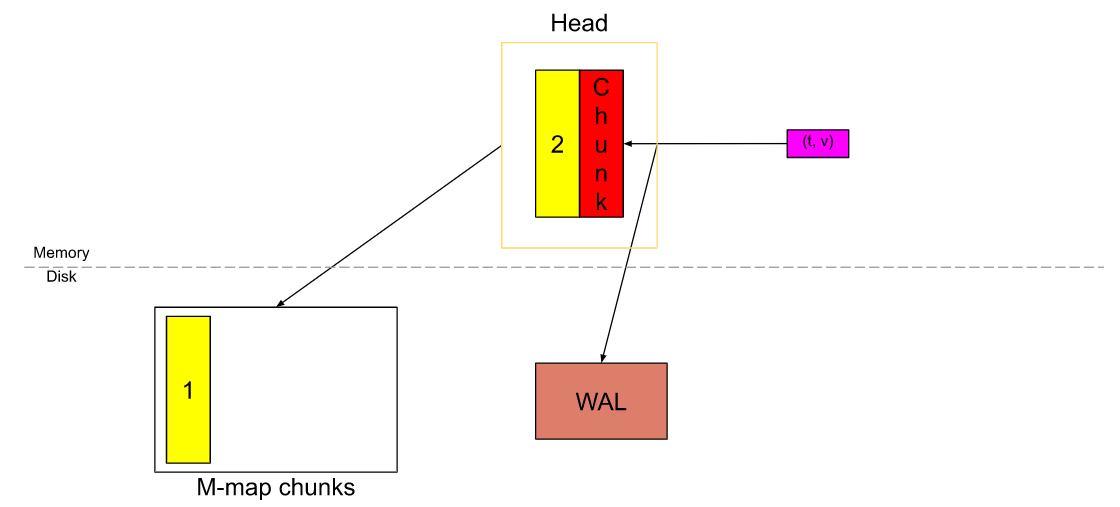
head_chunk1被刷新到磁盘然后进行内存映射。active chunk继续写入数据、截断数据、写入到内存映射,如此反复。
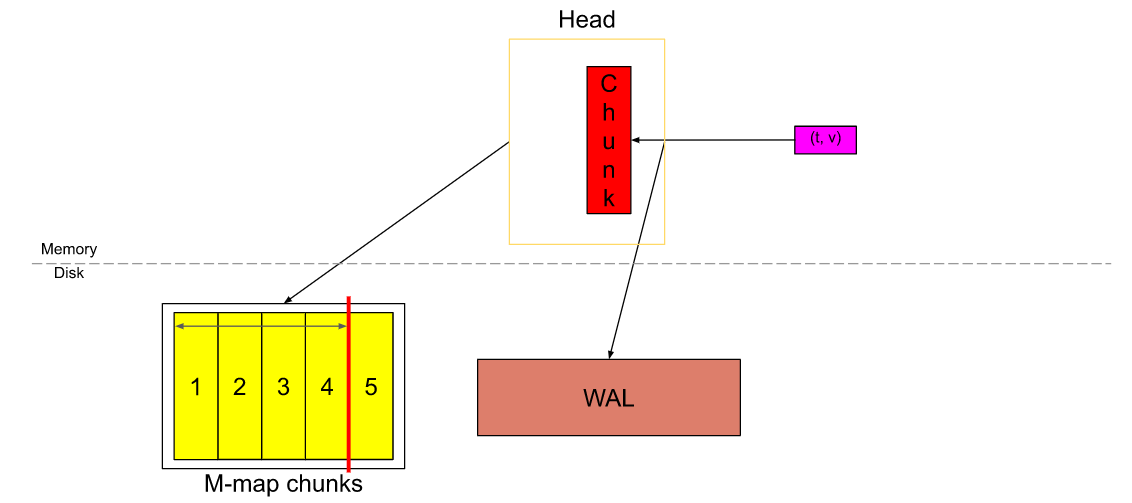
内存映射应该只加载最新的、最被频繁使用的数据,所以Prometheus TSDB将就是旧数据刷新到磁盘持久化存储Block,如上1-4为旧数据被写入到下图的Block中。
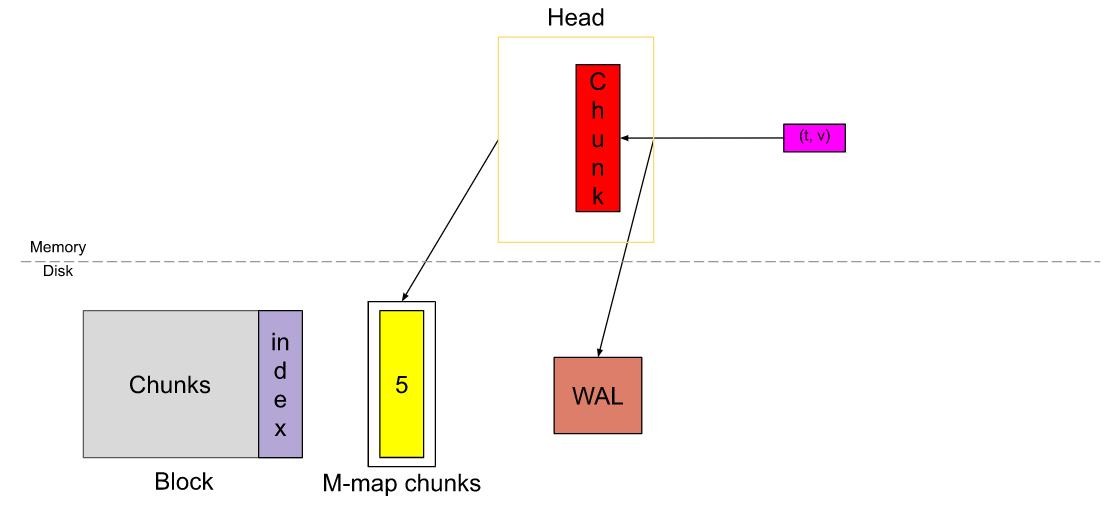
此时我们再来看一下Prometheus TSDB 数据目录基本结构,好像更清晰了一些。
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98 # block ID
│ ├── chunks # Block中的chunk文件
│ │ └── 000001
│ ├── tombstones # 数据删除记录文件
│ ├── index # 索引
│ └── meta.json # bolck元信息
├── chunks_head # head内存映射
│ └── 000001
└── wal # 预写日志
├── 000000002
└── checkpoint.00000001
└── 00000000
我们需要定期删除旧的 wal 数据,否则磁盘最终会被填满,并且在TSDB重启时 replay wal 事件时会占用大量时间,所以wal中任何不再需要的数据,都需要被清理。而checkpoint会将wal 清理过后的数据做过滤写成新的段。
如下有6个wal数据段
data
└── wal
├── 000000
├── 000001
├── 000002
├── 000003
├── 000004
└── 000005
现在我们要清理时间点T之前的样本数据,假设为前4个数据段:
检查点操作将按000000 000001 000002 000003顺序遍历所有记录,并且:
- 删除不再在 Head 中的所有序列记录。
- 丢弃所有 time 在
T之前的样本。 - 删除
T之前的所有 tombstone 记录。 - 重写剩余的序列、样本和tombstone记录(与它们在 WAL 中出现的顺序相同)。
checkpoint被命名为创建checkpoint的最后一个段号checkpoint.X
这样我们得到了新的wal数据,当wal在replay时先找checkpoint,先从checkpoint中的数据段回放,然后是checkpoint.000003的下一个数据段000004
data
└── wal
├── checkpoint.000003
| ├── 000000
| └── 000001
├── 000004
└── 000005
上面我们认识了wal和chunks_head的存储构造,接下来是Block,什么是持久化Block?在什么时候创建?为啥要合并Block?
Block的目录结构
├── 01BKGTZQ1SYQJTR4PB43C8PD98 # block ID
│ ├── chunks # Block中的chunk文件
│ │ └── 000001
│ ├── tombstones # 数据删除记录文件
│ ├── index # 索引
│ └── meta.json # bolck元信息
磁盘上的Block是固定时间范围内的chunk的集合,由它自己的索引组成。其中包含多个文件的目录。每个Block都有一个唯一的 ID(ULID),他这个ID是可排序的。当我们需要更新、修改Block中的一些样本时,Prometheus TSDB只能重写整个Block,并且新块具有新的 ID(为了实现后面提到的索引)。如果需要删除的话Prometheus TSDB通过tombstones 实现了在不触及原始样本的情况下进行清理。
tombstones 可以认为是一个删除标记,它记载了我们在读取序列期间要忽略哪些时间范围。tombstones 是Block中唯一在写入数据后用于存储删除请求所创建和修改的文件。
tombstones中的记录数据结构如下,分别对应需要忽略的序列、开始和结束时间。
┌────────────────────────┬─────────────────┬─────────────────┐
│ series ref <uvarint64> │ mint <varint64> │ maxt <varint64> │
└────────────────────────┴─────────────────┴─────────────────┘
meta.json
meta.json包含了整个Block的所有元数据
{
"ulid": "01EM6Q6A1YPX4G9TEB20J22B2R",
"minTime": 1602237600000,
"maxTime": 1602244800000,
"stats": {
"numSamples": 553673232,
"numSeries": 1346066,
"numChunks": 4440437
},
"compaction": {
"level": 1,
"sources": [
"01EM65SHSX4VARXBBHBF0M0FDS",
"01EM6GAJSYWSQQRDY782EA5ZPN"
]
},
"version": 1
}
记录了人类可读的chunks的开始和结束时间,样本、序列、chunks数量以及合并信息。version告诉Prometheus如何解析metadata
Block合并
我们可以从之前的图中看到当内存映射中chunk跨越2小时(默认)后第一个Block就被创建了,当 Prometheus 创建了一堆Block时,我们需要定期对这些块进行维护,以有效利用磁盘并保持查询的性能。
Block合并的主要工作是将一个或多个现有块(source blocks or parent blocks)写入一个新块,最后,删除源块并使用新的合并后的Block代替这些源块。
为什么需要对Block进行合并?
- 上面对tombstones介绍我们知道Prometheus在对数据的删除操作会记录在单独文件stombstone中,而数据仍保留在磁盘上。因此,当stombstone序列超过某些百分比时,需要从磁盘中删除该数据。
- 如果样本数据值波动非常小,相邻两个Block中的大部分数据是相同的。对这些Block做合并的话可以减少重复数据,从而节省磁盘空间。
- 当查询命中大于1个Block时,必须合并每个块的结果,这可能会产生一些额外的开销。
- 如果有重叠的Block(在时间上重叠),查询它们还要对Block之间的样本进行重复数据删除,合并这些重叠块避免了重复数据删除的需要。
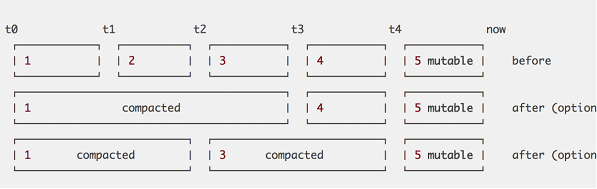
如上图示例所示,我们有一组顺序的Block[1, 2, 3, 4]。数据块1,2,和3可以被合并形成的新的块是[1, 4]。或者成对压缩为[1,3]。 所有的时间序列数据仍然存在,但是现在总体的数据块更少。 这显著降低了查询成本。
Block是如何删除的?
对于源数据的删除Prometheus TSDB采用了一种简单的方式:即删除该目录下不在我们保留时间窗口的块。
如下图所示,块1可以安全地被删除,而2必须保留到完全落在边界之后
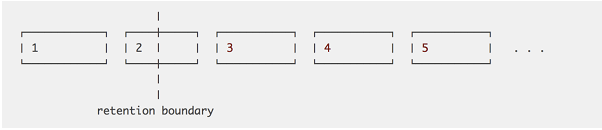
因为Block合并的存在,意味着获取越旧的数据,数据块可能就变得越大。 因此必须得有一个合并的上限,,这样块就不会增长到跨越整个数据库。通常我们可以根据保留窗口设置百分比。
如何从大量的series中检索出数据?在Prometheus TSDB V3引擎中使用了倒排索引,倒排索引基于它们内容的子集提供对数据项的快速查找,例如我们要找出所有带有标签app ="nginx"的序列,而无需遍历每一个序列然后再检查它是否包含该标签。
首先我们给每个序列分配一个唯一ID,查询ID的复杂度是O(1),然后给每个标签建一个倒排ID表。比如包含app ="nginx"标签的ID为1,11,111那么标签"nginx"的倒排序索引为[1,11,111],这样一来如果n是我们的序列总数,m是查询的结果大小,那么使用倒排索引的查询复杂度是O(m),也就是说查询的复杂度由m的数量决定。但是在最坏的情况下,比如我们每个序列都有一个“nginx”的标签,显然此时的复杂度变为O(n)了,如果是个别标签的话无可厚非,只能稍加等待了,但是现实并非如此。
标签被关联到数百万序列是很常见的,并且往往每次查询会检索多个标签,比如我们要查询这样一个序列app =“dev”AND app =“ops” 在最坏情况下复杂度是O(n2),接着更多标签复杂度指数增长到O(n3)、O(n4)、O(n5)... 这是不可接受的。那咋办呢?
如果我们将倒排表进行排序会怎么样?
"app=dev" -> [100,1500,20000,51166]
"app=ops" -> [2,4,8,10,50,100,20000]
他们的交集为[100,20000],要快速实现这一点,我们可以通过2个游标从列表值较小的一端率先推进,当值相等时就是可以加入到结果集合当中。这样的搜索成本显然更低,在k个倒排表搜索的复杂度为O(k*n)而非最坏情况下O(n^k)
剩下就是维护这个索引,通过维护时间线与ID、标签与倒排表的映射关系,可以保证查询的高效率。
以上我们从较浅的层面了解一下Prometheus TSDB存储相关的内容,本文仍然有很多细节没有提及,比如wal如何做压缩与回放,mmap的原理,TSDB存储文件的数据结构等等,如果你需要进一步学习可移步参考文章。通过博客阅读:iqsing.github.io
本文参考于:
Prometheus维护者Ganesh Vernekar的系列博客Prometheus TSDB
Prometheus维护者Fabian的博客文章Writing a Time Series Database from Scratch(原文已失效)
PromCon 2017: Storing 16 Bytes at Scale - Fabian Reinartz