本篇原文为 introduction to x64 assembly ,如果有良好的英文基础,可以点击该链接进行下载阅读。本文为我个人:寂静的羽夏(wingsummer) 中文翻译,非机翻,著作权归原作者所有。
本篇不算太长,是来自Intel的官方下载的介绍性文档,如有翻译不得当的地方,欢迎批评指正。翻译不易,如有闲钱,欢迎支持。注意在转载文章时注意保留原文的作者链接,我(译者)的相关信息。话不多说,正文开始:
很多年了,PC端程序员使用x86汇编来编写高性能的代码。但是32位的PC已经正在被64位的替代,并且底层的汇编代码也已经改变了。这个是对x64汇编难得可贵的介绍。阅读该篇文章不需要x86汇编前置知识,但如果你会它会让你更快更容易的学会x64汇编。
x64是英特尔和AMD的32位x86指令集体系结构ISA的64位扩展的通用名称。AMD推出了x64的第一个版本,最初名为x86-64,后来改名为AMD64。英特尔将其实现命名为IA-32e,之后命名为EMT64。两个版本之间有一些轻微的不兼容,但大多数代码在两个版本上都可以正常工作;有关详细信息,请参阅《Intel®64 and IA-32 Architectures Software Developer's Manuals》和《AMD64 Architecture Tech Docs》。我们统称之为x64。请不要把IA-64和64位Intel® Itanium®体系结构相混淆。
本篇介绍不会涉及硬件的相关细节,比如缓存、分支预测和其他高级话题。有一些参考将会在本文章末尾处给出来帮助大家以后深入这些领域。
汇编一般用于白编写应用程序对性能极其苛刻要求的部分,尽管对于大多数开发者来说做到比C++编译器更好是非常困难的。汇编知识对于调试代码来说十分有用——有时编译器会生成错误的汇编代码或者对在调试器中单步调试代码确认错误原因有更好的帮助。代码优化者们有时候会犯错。当你没有源代码的时候,汇编就可以派上用场,提供修复代码的接口。汇编可以让你改变修改当前已经存在的可执行文件。如果你想知道你所用的编程语言在底层的实现,汇编是必需品。学会它你就可以知道为什么有时候它运行的慢或者为什么其他运行的快。最后一点,汇编代码知识在逆向分析恶意程序是不可或缺的。
当在一个现有使用的平台学习汇编的时候,首先要学习寄存器组。
大体架构 目前64位的寄存器允许访问各种大小和位置,我们定义一个字节8个位,一个字16个位,一个双字32个位,一个四字64位,一个双四字为128位。Intel使用小端存储,意味着低地址存低字节。
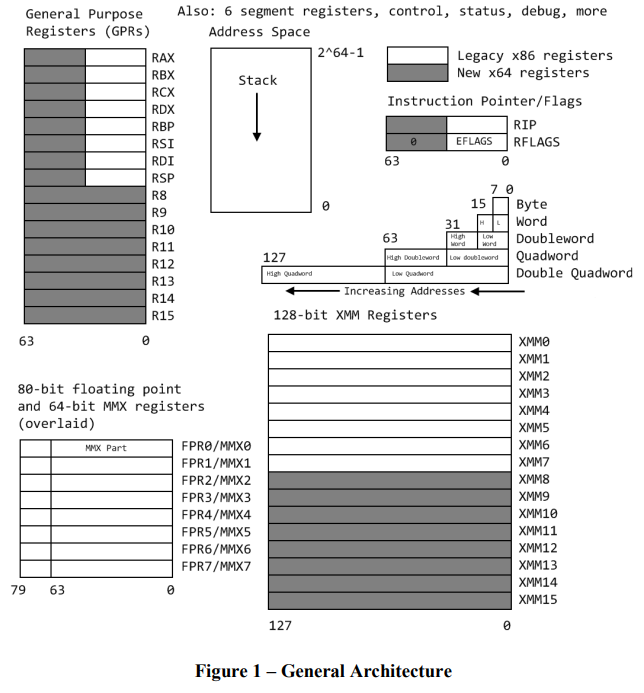
图一展示了16个64位通用寄存器,第一组8个寄存器被命名(因为历史原因)为RAX、RBX、RCX、RDX、RBP、RSI、RDI和RSP。第二组8个寄存器用R8 - R15命名。将字母E替换用开头的字母R,能够访问低32位(RAX的EAX)。类似的RAX、RBX、RCX和RDX可以通过去掉首字母R来访问低16个字节(RAX的AX),通过再把X替换成L可以访问低16位(AX的AL)或通过再把X缓存H访问较高的16位(AX的AH)。R8到R15也可以用相同的方式进行访问,像这样:R8四字,R8D低双字,R8W低字,R8B低单字节(MASM表示方式,Intel 表示方式为 R8L)。注意这里没有R8H。
由于用于新寄存器的REX操作码前缀中的编码问题,访问字节寄存器时存在一些奇怪的限制:一条指令不能同时引用一个旧的高位字节(AH、BH、CH、DH)和一个新的字节寄存器(如R11B),但它可以使用低位字节(AL、BL、CL、DL)。这是通过将使用REX前缀的指令(AH、BH、CH、DH)更改为(BPL、SPL、DIL、SIL)来实现的。
64位的指令指针RIP指向下一个将要执行的指令,并且支持64位平坦内存模型。后面将介绍当前操作系统中的内存地址布局。栈指针RSP指向最后一个被压入栈的地址,栈是向小地址增长的,被用来存储函数调用流程的返回地址,在像C/C++这类高级语言传递参数,在调用约定中存储“影子空间”。
RFLAG寄存器存储标志位,用来表示操作结果或者寄存器的控制。这通过在X86的32位寄存器EFLAG高位扩展保留目前不使用的32个位得到的。表1列举了最有用的标志。绝大多数其他标志提供给操作系统级别的任务并且经常用来设置值为之前读到的数值。

浮点数处理单元FPU包含了八个FPR0到FPR7寄存器,状态和控制寄存器和其他一些特殊寄存器。FPR0-7每一个都能够存储如表2所示的类型的一个值。浮点值操作遵守IEEE 754标准。注意大多数C/C++编译器支持32位和64位的float和double类型,但并不是80位的数值能够从汇编获取。这些寄存器和8个64位的MMX寄存器共享空间。

BCD编码通过一些8位的指令支持,并且浮点寄存器支持的奇数格式提供了一种80位、17位的BCD类型。
16个128位XMM寄存器(比x86多8个)可以包含更多的细节。
最后的寄存器包含段寄存器(大多数在X64未被使用),控制寄存器,内存管理寄存器,调试寄存器,虚拟化寄存器,跟踪各种内部参数(缓存命中/未命中、分支命中/未命中、执行的微操作、计时等)的性能寄存器。最值得关注的性能操作码是RDTSC,它用于计算处理器周期以分析小代码段。
全部细节都可以在 http://www.intel.com/products/processor/manuals/ 上获取的《Intel® 64 and IA-32 Architectures Software Developer's Manuals》的第五卷中找到。它们可以以PDF格式免费下载,在CD上订购,并且通常可以在列出时作为精装集免费订购。
单指令多数据(SIMD)指令对多条数据并行执行单个命令,是汇编例程的常见用法。MMX和SSE命令(分别使用MMX和XMM寄存器)支持SIMD操作,这些操作可并行执行多达八条数据的指令。例如,可以使用MMX在一条指令中向八个字节添加八个字节。
八个64位MMX寄存器MMX0-MMX7在FPR0-7之上有别名,这意味着任何混合FP和MMX操作的代码都必须小心不要覆盖所需的值。MMX指令对整数类型进行操作,允许对MMX寄存器中的值并行执行字节、字和双字操作。大多数MMX指令以P开头,表示打包。算术、移位/循环移位、比较,例如:PCMPGTB意为比较压缩有符号字节整数是否大于。
十六个128位XMM寄存器允许每条指令对四个单精度或两个双精度值进行并行操作。一些指令也适用于压缩字节、字、双字和四字整数。这些指令称为Streaming SIMD Extensions(SSE),有多种形式:SSE、SSE2、SSE3、SSSE3、SSE4,可能在打印数值时会使用更多。英特尔
已经宣布了更多类似的扩展,称为英特尔高级矢量扩展
(Intel® Advanced Vector Extensions,Intel® AVX),具有新的256位宽数据路径。SSE指令包含浮点和整数类型的移动、算术、比较、混洗和解包以及按位运算。指令名称包括诸如PMULHUW和RSQRTPS之类的美。最后,SSE引入了一些内存预取指令(为了性能)和内存栅栏(为了多线程安全)。
表3列出了一些命令集、操作的寄存器类型、并行操作的项目数以及项目类型。例如,使用SSE3和128位XMM寄存器,您可以并行处理2个(必须是64位)浮点值,甚至可以并行处理16个(必须是字节大小的)整数值。
要查找给定芯片支持的技术,有一条CPUID指令会返回特定于处理器的信息。
Internet搜索支持x64的汇编器,例如Netwide Assembler NASM、称为YASM的NASM重构版本、快速平面汇编器FASM和传统的Microsoft MASM。甚至还有一个免费的用于x86和x64程序集的IDE,称为WinASM。每个汇编器
对其他汇编器的宏和语法有不同的支持,但汇编代码与C++或各版本是Java等汇编器的源代码不兼容。
对于下面的示例,我使用平台SDK中免费提供的64位版本的MASM,ML64.EXE。对于下面的示例,请注意MASM语法的形式为:
指令 目标操作数, 源操作数
有些汇编器可能将源操作数和目标操作数位置对调,故请你认真阅读文档。
C/C++编译器通常允许使用内联汇编在代码中嵌入汇编,但Microsoft Visual Studio各版本的64位C/C++代码不再支持,这可能会简化代码优化器的任务。 这留下了两个选择:使用单独的汇编文件和外部汇编器,或使用头文件intrn.h中的内在函数(参见Birtolo和MSDN)。 其他编译器具有类似的选项。
使用内部函数(intrinsics)的一些原因:
- x64 不支持内联汇编。
- 易于使用:您可以使用变量名,而不必处理寄存器手动分配。
- 比汇编更跨平台:编译器制造商可以将内在函数移植到各种架构。
- 优化器更适用于内部函数。
例如,Microsoft Visual Studio 2008各版本有一个内部函数,它将16位值中的位向右循环移位b位并返回结果。在C中这样给出:
unsigned short a1 = (b>>c)|(b<<(16-c));
它将其扩展到十五个汇编指令(在Debug版本中与在Release版本中构建整个程序优化使其更难区分,但长度相似),于此同时如果使用一样的内部函数:
unsigned short a2 = _rotr16(b,c);
上式就会扩展为四个指令。有关更多信息,请阅读头文件和文档。
汇编指令基础 寻址方式在介绍一些基本指令之前,您需要了解寻址方式,即指令可以访问寄存器或内存的方式。以下是常见的寻址方式和示例:
- 立即寻址:值存在指令当中。
ADD EAX, 14 ; add 14 into 32-bit EAX
- 寄存器到寄存器寻址:
ADD R8L, AL ; add 8 bit AL into R8L
- 间接寻址:
这种寻址方式允许使用8、16或32位的大小,任何用于基址和索引的通用寄存器,以及1、2、4或8的比例来乘以索引。从技术上讲,这些也可以以段FS:或GS:为前缀,但这很少用到。
MOV R8W, 1234[8*RAX+RCX] ; move word at address 8*RAX+RCX+1234 into R8W
有很多合法的写法。以下指令是等价的:
MOV ECX, dword ptr table[RBX][RDI]
MOV ECX, dword ptr table[RDI][RBX]
MOV ECX, dword ptr table[RBX+RDI]
MOV ECX, dword ptr [table+RBX+RDI]
dword ptr告诉汇编器如何编码MOV指令。
- RIP 间接寻址
这是x64的新功能,允许在相对于当前指令指针的代码中访问数据表等,使与位置无关的代码更易于实现。
MOV AL, [RIP] ; RIP points to the next instruction aka NOP
NOP
不幸的是,MASM不允许这种形式的操作码,但其他汇编程序如FASM和YASM允许。相反,MASM隐式嵌入RIP相对寻址。
MOV EAX, TABLE ; uses RIP- relative addressing to get table address
- 特殊情况
一些操作码基于操作码以独特的方式使用寄存器。 例如,64位操作数值的有符号整数除法IDIV将RDX:RAX中的128位值除以该值,将结果存储在RAX中,余数存储在RDX中。
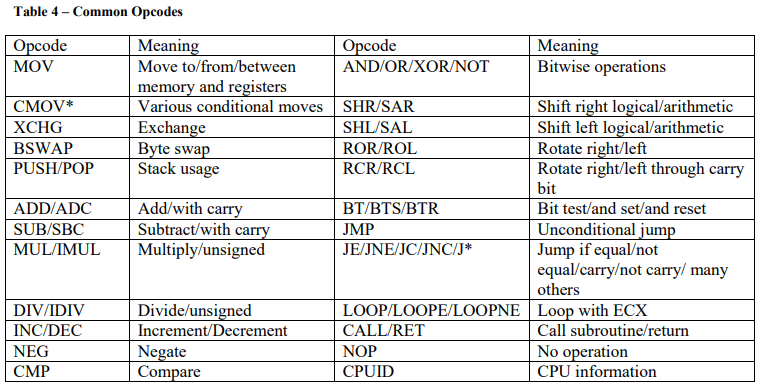
表4列出了一些常用指令。*表示此条目是多个操作码,其中*表示后缀。
常见的指令是LOOP指令,根据使用情况递减RCX、ECX或CX,如果结果不为0则跳转。例如:
XOR EAX, EAX ; zero out eax
MOV ECX, 10 ; loop 10 times
Label: ; this is a label in assembly
INX EAX ; increment eax
LOOP Label ; decrement ECX, loop if not 0
不太常见的操作码实现字符串操作、重复指令前缀、端口I/O指令、标志设置/清除/测试、浮点操作(通常以F开头,并支持移动、转为整数/从整数转、算术、比较、超出、代数和控制函数)、用于多线程和性能问题的缓存和内存操作码等。《The Intel® 64 and IA-32 Architectures Software Developer’s Manual》第2卷分为两部分详细介绍了每个操作码。
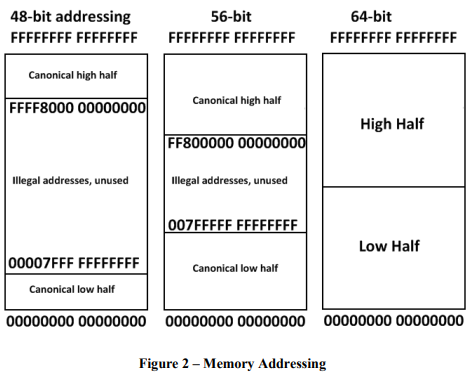
64位系统理论上允许寻址264字节的数据,但目前没有芯片允许访问所有16艾字节(exabytes)8,446,744,073,709,551,616字节)。例如,AMD架构仅使用地址的低48位,并且第48到63位必须是第47位的副本,否则处理器会引发异常。因此,地址是0到00007FFF'FFFFFFFF,从FFFF8000'00000000到FFFFFFFF'FFFFFFFF,总共256 TB(281,474,976,710,656字节)的可用虚拟地址空间。另一个缺点是寻址所有64位内存需要更多的分页表供操作系统存储,对于安装的系统少于所有16艾字节的系统使用宝贵的内存。请注意,这些是虚拟地址,而不是物理地址。
从结果上说,许多操作系统将这个空间的高半部分用于操作系统,从顶部开始向下增长,而用户程序使用下半部分,从底部开始向上增长。当前的Windows各版本使用44位寻址(16 TB =17,592,186,044,416字节)。生成的寻址如图2所示。由于地址是由操作系统分配的,因此生成的地址对用户程序不太重要,但用户地址和内核地址之间的区别对于调试很有用。
最后一个与操作系统相关的项目与多线程编程有关,但是这个话题太大了,无法在这里讨论。唯一值得一提的是,内存屏障操作码有助于保持共享资源不受损坏。
与操作系统库交互需要知道如何传递参数和管理堆栈。平台上的这些细节称为调用约定。
一个常见的x64调用约定是用于C风格函数调用的Microsoft的64调用约定(请参阅MSDN、Chen和Pietrek)。在各版本Linux下,这称为应用程序二进制接口 (Application Binary Interface,ABI)。请注意,此处介绍的调用约定不同于x64的各版本Linux系统上使用的调用约定。
对于Microsoft各版本操作系统的x64调用约定,额外的寄存器空间让fastcall成为唯一的调用约定(在x86下有很多:stdcall、thiscall、fastcall、cdecl等)。与C/C++风格函数交互的规则:
- RCX、RDX、R8、R9 按从左到右的顺序用于整数和指针参数。
- XMM0、XMM1、XMM2 和 XMM3 用于浮点参数。
- 附加参数从左到右压入堆栈。
- 长度小于 64 位的参数不进行零扩展;剩余的高字节为垃圾数据。
- 在调用函数之前,调用者有责任分配 32 字节的预留空间(如果需要,用于存储 RCX、RDX、R8 和 R9)。
- 调用者负责平衡清理栈空间。
- 如果 64 位或更小的数据,则在 RAX 中返回整数返回值(类似于 x86)。
- 浮点返回值在 XMM0 中返回。
- 较大的返回值(结构体)具有由调用者在堆栈上分配的空间,然后 RCX 在调用被调用者时包含指向返回空间的指针。然后将整数参数的寄存器使用推到右边。 RAX 将此地址返回给调用者。
- 堆栈是 16 字节对齐的。 call 指令压入一个 8 字节的返回值,因此所有非叶函数在分配堆栈空间时必须将堆栈调整为 16n+8 形式的值。
- 寄存器 RAX、RCX、RDX、R8、R9、R10 和 R11 被认为是易失的,并且必须在函数调用时被销毁。
- RBX、RBP、RDI、RSI、R12、R14、R14 和 R15 必须保存在任何使用它们的函数中。
- 请注意,浮点(以及 MMX)寄存器没有调用约定。
- 更多详细信息(可变参数、异常处理、堆栈展开)在 Microsoft 的网站上。
有了以上内容,这里有几个例子展示了x64的使用。第一个例子是一个简单的x64独立汇编程序,它弹出一个Windows的信息框。
; Sample x64 Assembly Program
; Chris Lomont 2009 www.lomont.org
extrn ExitProcess: PROC ; external functions in system libraries
extrn MessageBoxA: PROC
.data
caption db '64-bit hello!', 0
message db 'Hello World!', 0
.code
Start PROC
sub rsp,28h ; shadow space, aligns stack
mov rcx, 0 ; hWnd = HWND_DESKTOP
lea rdx, message ; LPCSTR lpText
lea r8, caption ; LPCSTR lpCaption
mov r9d, 0 ; uType = MB_OK
call MessageBoxA ; call MessageBox API function
mov ecx, eax ; uExitCode = MessageBox(...)
call ExitProcess
Start ENDP
End
将其保存为hello.asm,使用ML64编译,可在Microsoft Windows各种64位版本的SDK中使用
如下:
ml64 hello.asm /link /subsystem:windows /defaultlib:kernel32.lib /defaultlib:user32.lib /entry:Start
这使得Windows可执行并与适当的库链接。运行生成的可执行文件hello.exe,应该会弹出消息框。
第二个示例将程序集文件与各版本的Microsoft Visual Studio 2008下的C/C++文件链接。其他编译器系统类似。首先确保您的编译器是支持x64的版本。然后、
-
创建一个新的空 C++ 控制台项目。 创建一个你想移植到的函数程序集,并从 main 调用它。
-
要更改默认的 32 位构建,请选择构建/配置管理器。
-
在活动平台下,选择新建。
-
在平台下,选择 x64。 如果没有出现,请弄清楚如何添加 64 位 SDK 工具并重复该操作。
-
编译并单步执行代码。 在 调试-窗体——汇编窗体 下查看以查看汇编函数所需的生成代码和接口。
-
创建一个程序集文件,并将其添加到项目中。它默认是 32 位汇编器,这是正常的。
-
打开程序集文件属性,选择所有配置,编辑自定义构建步骤。
-
输入命令行
ml64.exe /DWIN_X64 /Zi /c /Cp /Fl /Fo $(IntDir)\$(InputName).obj $(InputName).asm并设置输出为
$(IntDir)\$(InputName).obj。 -
构建并运行。
举个例子,在main.cpp中,我们放置了一个函数CombineC,它对五个整数参数和一个双精度参数进行一些简单的数学运算,并返回一个双精度答案。我们在一个单独的文件CombineA.asm中的一个名为CombineA的函数中复制该功能。C++文件是:
// C++ code to demonstrate x64 assembly file linking
#include <iostream>
using namespace std;
double CombineC(int a, int b, int c, int d, int e, double f)
{
return (a+b+c+d+e)/(f+1.5);
}
// NOTE: extern “C” needed to prevent C++ name mangling
extern "C" double CombineA(int a, int b, int c, int d, int e, double
f);
int main(void)
{
cout << "CombineC: " << CombineC(1,2,3,4, 5, 6.1) << endl;
cout << "CombineA: " << CombineA(1,2,3,4, 5, 6.1) << endl;
return 0;
}
确保使函数外部C链接以防止C++名称混淆。程序集文件CombineA.asm内容为:
; Sample x64 Assembly Program
.data
realVal REAL8 +1.5 ; this stores a real number in 8 bytes
.code
PUBLIC CombineA
CombineA PROC
ADD ECX, DWORD PTR [RSP+28H] ; add overflow parameter to first parameter
ADD ECX, R9D ; add other three register parameters
ADD ECX, R8D ;
ADD ECX, EDX ;
MOVD XMM0, ECX ; move doubleword ECX into XMM0
CVTDQ2PD XMM0, XMM0 ; convert doubleword to floating point
MOVSD XMM1, realVal ; load 1.5
ADDSD XMM1, MMWORD PTR [RSP+30H] ; add parameter
DIVSD XMM0, XMM1 ; do division, answer in xmm0
RET ; return
CombineA ENDP
End
运行这个应该导致值1.97368被输出两次。
这是对x64汇编编程的简要介绍。下一步是浏览《Intel® 64 and IA-32 Architectures Software Developer‟s Manuals》。第1卷包含架构详细信息,如果您了解汇编,这是一个好的开始。其他地方是汇编书籍或在线汇编教程。要了解代码是如何执行的,在调试器中单步调试代码,查看反汇编,直到您可以阅读汇编代码以及您喜欢的语言,这很有指导意义。对于C/C++编译器,调试版本比发布版本更容易阅读,因此请务必从那里开始。最后,逛一下masm32.com的论坛以获取大量资料。
- “AMD64 Architecture Tech Docs,” available online at http://www.amd.com/us-en/Processors/DevelopWithAMD/0,,30_2252_875_7044,00.html
- NASM: http://www.nasm.us/
- YASM: http://www.tortall.net/projects/yasm/
- Flat Assembler (FASM): http://www.flatassembler.net/
- Dylan Birtolo, “New Intrinsic Support in Visual Studio 2008”, available online at http://blogs.msdn.com/vcblog/archive/2007/10/18/new-intrinsic-support-in-visual-studio-2008.aspx
- Raymond Chen, “The history of calling conventions, part 5: amd64,” available online at http://blogs.msdn.com/oldnewthing/archive/2004/01/14/58579.aspx
- “Intel® 64 and IA-32 Architectures Software Developer's Manuals,” available online at http://www.intel.com/products/processor/manuals/
- “Compiler Intrinsics”, available online at http://msdn.microsoft.com/en-us/library/26td21ds.aspx
- “Calling Convention”, available online at http://msdn.microsoft.com/en-us/library/9b372w95.aspx

 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可
本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可
【来源:国外高防服务器 http://www.558idc.com/stgf.html 欢迎留下您的宝贵建议】