朋友们可以关注下我的公众号,获得最及时的更新:

或者关注我的知乎账号 : https://www.zhihu.com/people/zhangyachen
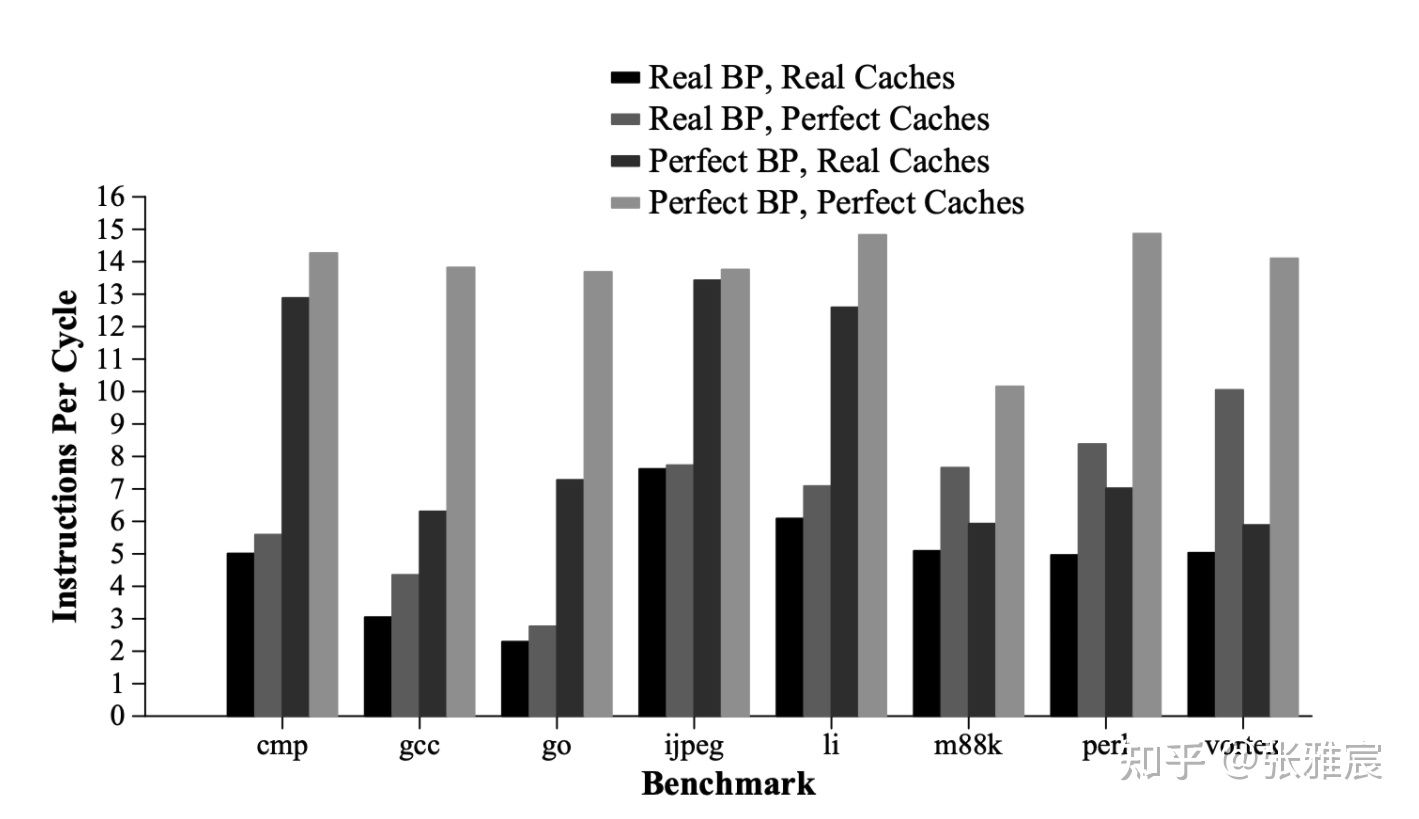
人们一直追求CPU分支预测的准确率,论文Simultaneous Subordinate Microthreading (SSMT)中给了一组数据,如果分支预测的准确率是100%,大多数应用的IPC会提高2倍左右。
为了比较不同分支预测算法的准确率,有个专门的比赛:Championship Branch Prediction(CPB)。CPB-5的冠军是TAGE-SC-L,在TAGE-SC-L Branch Predictors Again中有详细描述:
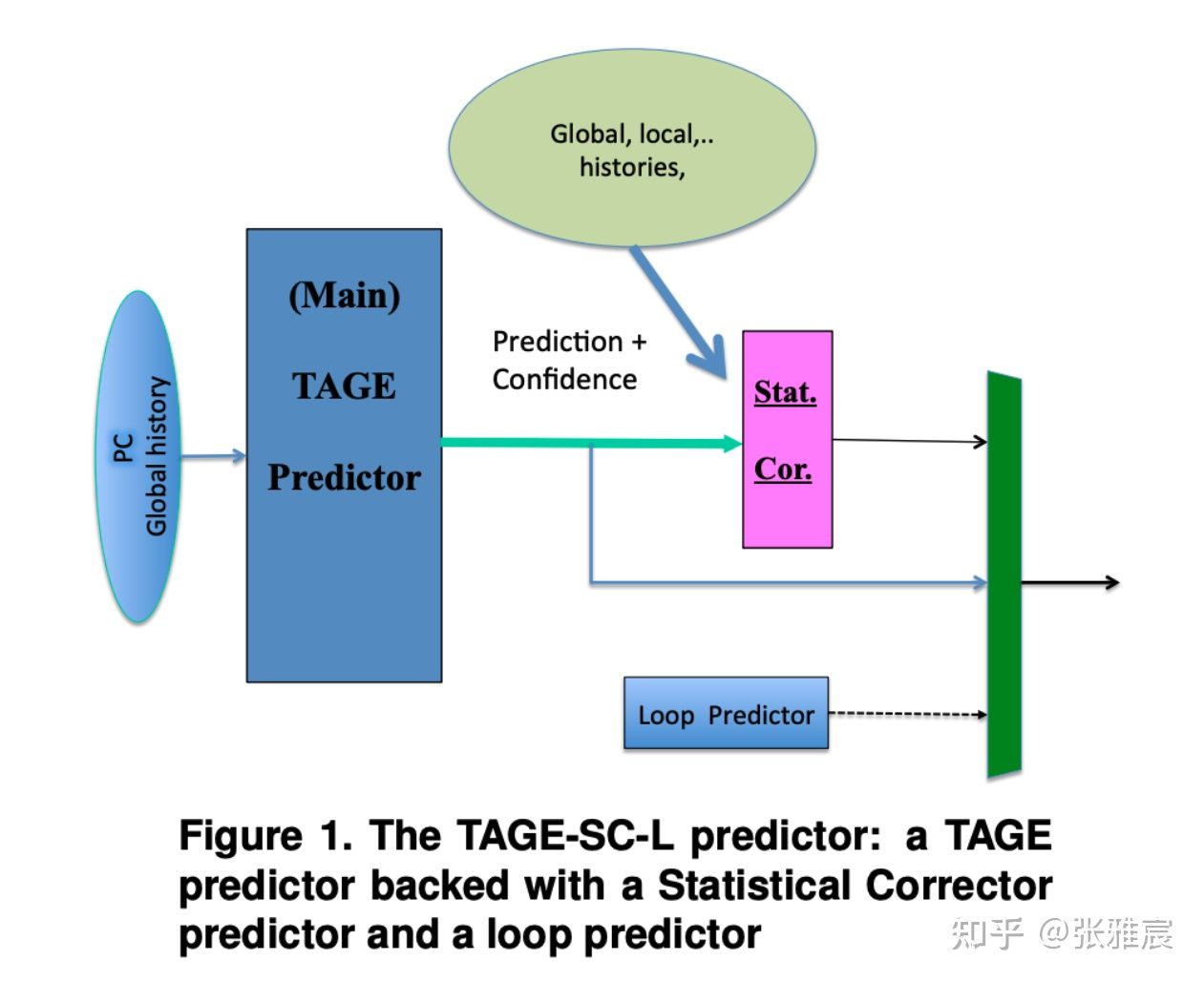
但是分支预测准确率高意味着更复杂的算法,占用更多的硅片面积和更多的功耗,同时还会影响CPU的周期时间。更不幸的是,不同程序呈现不同的特性,很难找到一种放之四海而皆准的分支预测算法。一种算法可能对一类程序有很高的准确率,但是对另一类程序的效果却不尽然。
另外现代计算机都是Superscalar架构,取指阶段会同时取出多条指令(fetch group),这需要对取出的指令全部进行分支预测。而且这种情况下的misprediction penalty是M * N,预测失败的无用功更多。(M = fetch group内指令数, N = branch resolution latency,也就是决定分支最终是否跳转需要多少周期)
分支预测大方向包含四个主题:
- 在取指阶段指定是不是分支,在Multiple-Issue Superscalar背景下复杂很多。
- 如果指令是分支指令,判断该指令taken or not taken(跳转 or 不跳转)。这里有些特殊的是无条件执行的分支指令,例如call/jump。
- 如果分支指令跳转,预测该分支的目标地址 —— Branch Target Address,这里分为PC-relative直接跳转(direct)和Absolute间接跳转(indirect)。
- 如果预测失败,需要有恢复机制,不能执行wrong path上的指令。
分支预测是影响CPU性能的关键因素之一,需要在硬件消耗、预测准确度和延迟之间找到一个平衡点。为了理解分支预测算法本身,假设CPU每周期只取一条指令。
先说下相对简单的目标地址预测
目标地址预测分支的目标地址BTA(Branch Target Address)分为两种:
- 直接跳转(PC-relative, direct) : offset以立即数形式固定在指令中,所以目标地址也是固定的。
- 间接跳转(absolute, indirect):目标地址来自通用寄存器,而寄存器的值不固定。CALL和Return一般使用这种跳转。
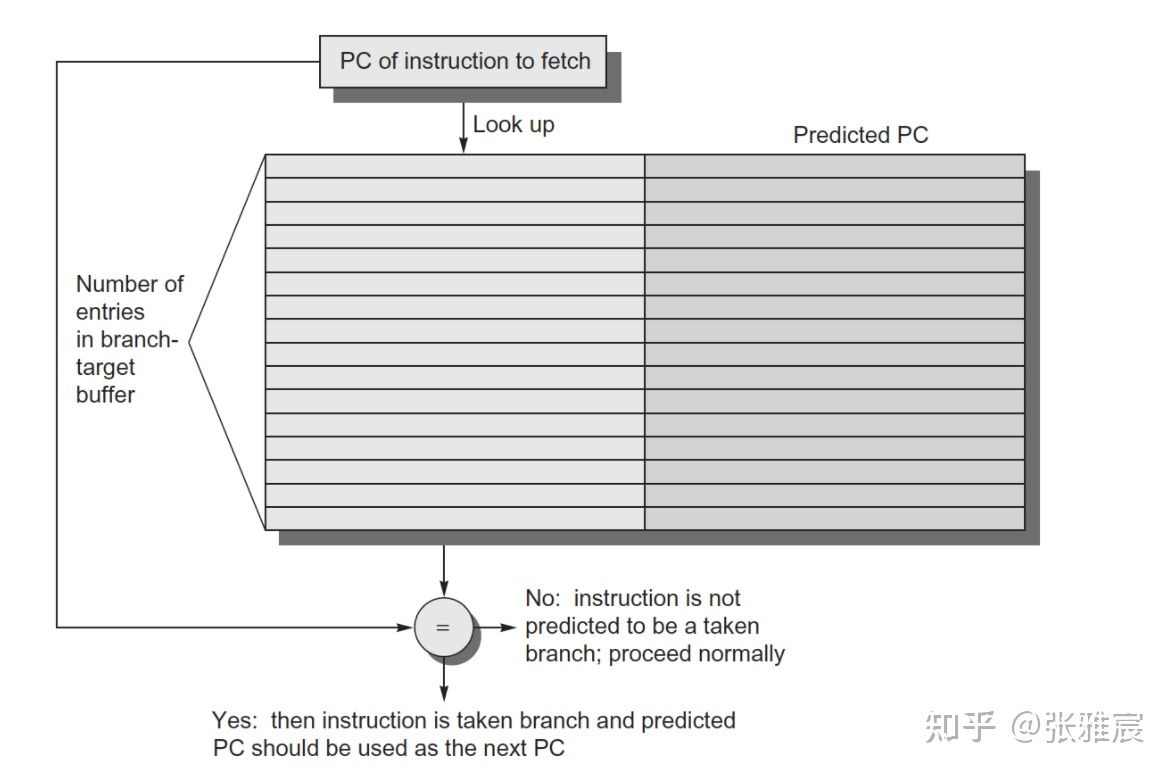
使用BTB(Branch Target Buffer)记录目标地址,相当于一个Cache。为了节省资源,BTB一般只记录发生跳转的分支指令目标地址,不发生跳转的目标地址其实就是顺序取指令地址。
下面是最简单的一个BTB结构:
BTB还有其他变种:
- 如果BTB容量有限,BTB entry中需要有PC值的一部分作为tag。
- 在上面的基础上,做组相连结构,不过一般way的个数比较小。
- 为了快速识别分支类型,还可以存分支是call、return还是其他。
- BTB中存放t具体的target instruction,不存放BTA,流水线不需要再去额外取指令。这样可以做branch folding优化,效果对unconditional branches尤其明显。
间接跳转一般用在switch-case指令实现(类似jmpq *$rax,$rax是case对应label地址)、C++这种虚函数调用等。
如果间接跳转是用来调用函数,那么目标地址还是固定的,用BTB就可以来预测。但如果是switch-case这种,虽然分支指令地址是相同的,但是目标地址不固定,如果还是用BTB,准确率只有50%左右。很多CPU针对间接跳转都有单独的预测器,比如的Intel的论文The Intel Pentium M Processor: Microarchitecture and Performance,其中介绍了Indirect Branch Predictor:额外引入context-information——Global Branch History:

而对于return这种间接跳转来说,目标地址同样不固定,因为可能多有个caller调用同一个函数。CPU一般采用RAS(Return Address Stack),将CALL指令的下一条指令地址写入RAS,此时该地址在栈顶,下次return时可以直接从栈顶pop该地址用作return的目标地址。
对于递归的程序来说,RAS保存的都是一个重复值,所以有的处理器会给RAS配一个计数器。如果将写入到RAS的地址和上一次写入的相同,说明执行的是一个CALL指令,直接将RAS对应的entry加1即可,保持栈顶指针不变,这相当于变相增加了RAS的容量。
一个8-entry的RAS可以达到95%的准确率。
分支方向预测分成静态预测和动态预测两种:
- 静态预测,Static prediction
- Always taken
- Predict branch with certain operation codes
- BTFN (Backward taken, forward not taken)
- Profile-based
- Program-based
- Programmer-based
- 动态预测,Dynamic prediction
- Last time prediction (single-bit)
- Two-bit counter based prediction (bimodal prediction)
- Two Level Local Branch Prediction (Adaptive two-level prediction)
- Two Level Global Branch Prediction (Correlating Branch Prediction)
- Hybrid Branch Prediction (Alloyed prediction)
- Perceptrons Prediction
- TAgged GEometric History Length Branch Prediction (TAGE)
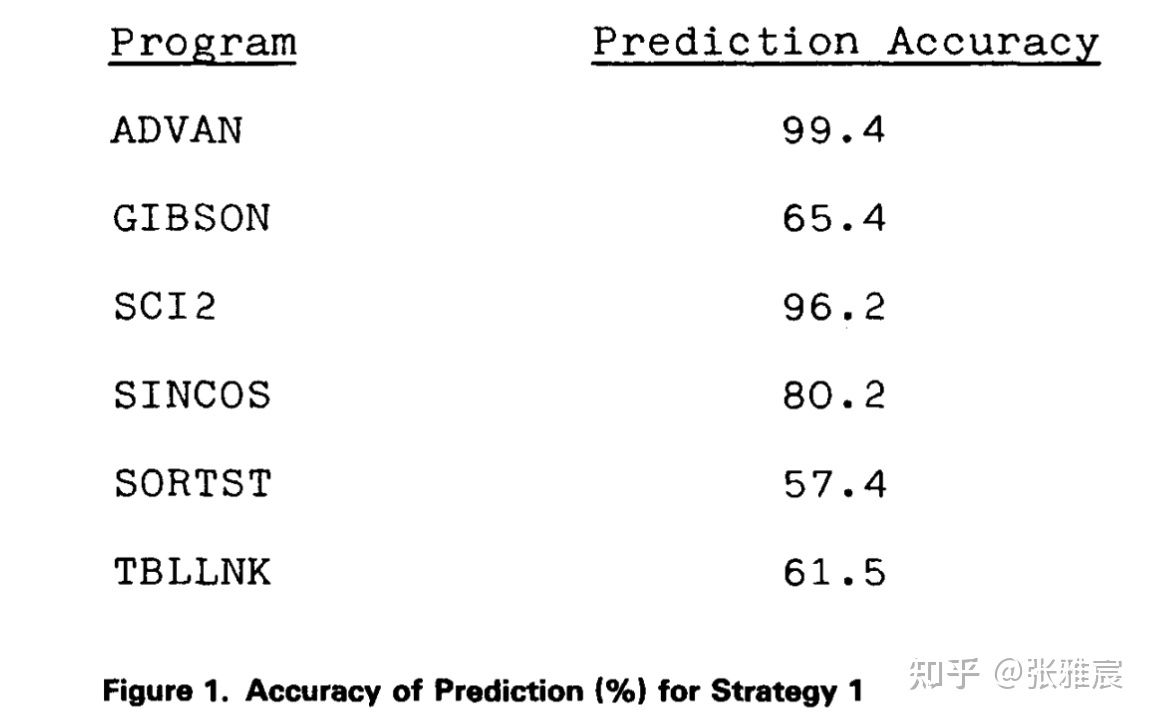
先看静态预测,1981年的论文A STUDY OF BRANCH PREDICTION STRATEGIES 对前三种静态预测的准确率做过描述和准确率统计。
静态预测 Always taken全部跳转,准确率在不同程序上差别很大。Always taken实现成本极低,其他分支预测算法的准确率都应该比这个高,否则还不如用这个策略。
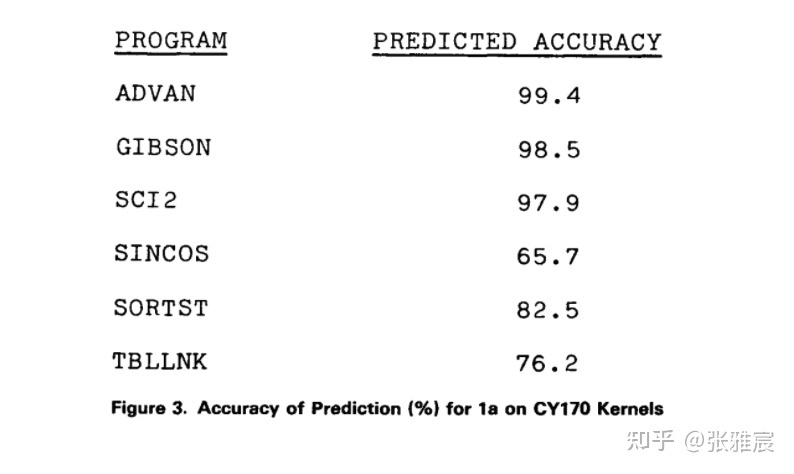
 Predict branch with certain operation codes
Predict branch with certain operation codes
该策略应用在IBM System 360/370上,是Always taken的一个改进版,根据分支指令的operation code来觉得是否taken,比如<0、==、>=预测跳转,其他不跳转。
和Always taken结果对比来看, GIBSON的预测准确率从65.4%提高到了98.5%,唯一下降的是SINCOS,论文里给的理由是branch if plus被预测成了不跳转,否则准确率会和Always taken策略下的准确率持平。
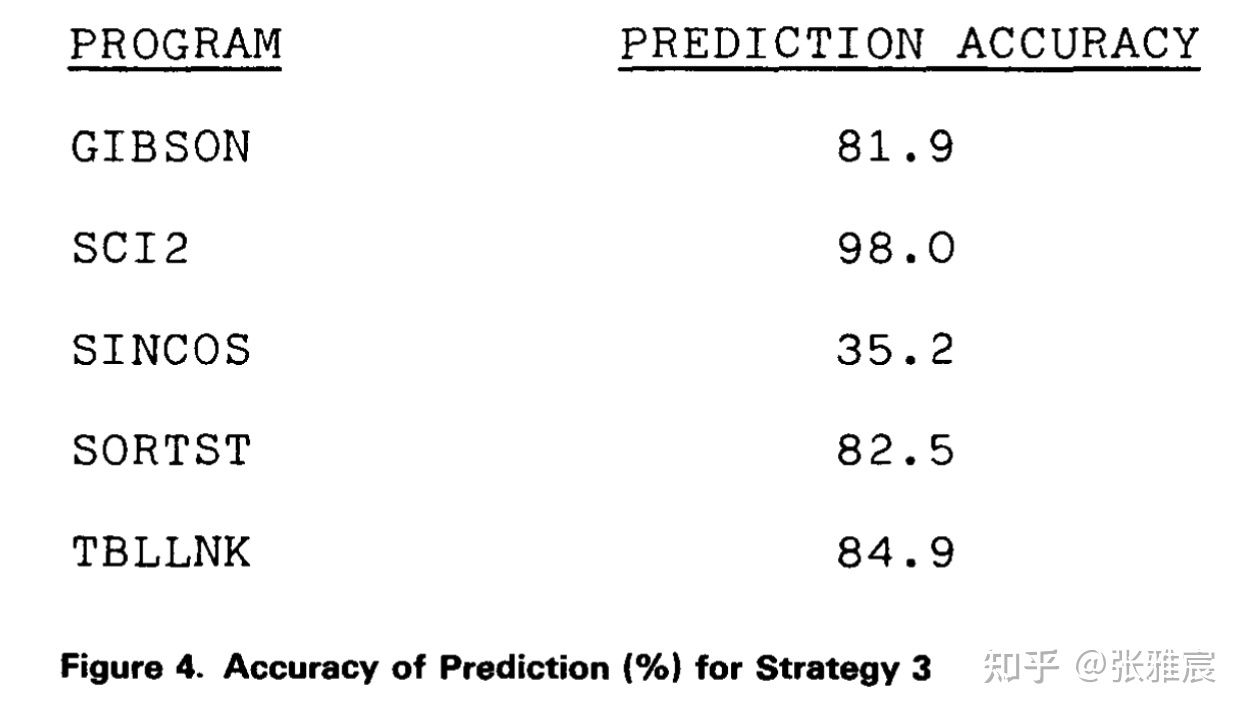
 BTFN (Backward taken, Forward not taken)
BTFN (Backward taken, Forward not taken)
这个算法策略主要受到loop循环的启发。当循环跳转时,target address都是在当前PC值的前面(backward),循环结束时target address在PC值的后面(forward)。
但是这个策略的准确率在不同程序表现上差别很大,SINCOS上的预测准确率甚至降到了35.2%。而且该策略还有个缺点:需要计算target address并和当前PC值进行比较才能预测下一个PC值,这会比其他策略多消耗时钟周期,预测失败后的recovery成本也较高。
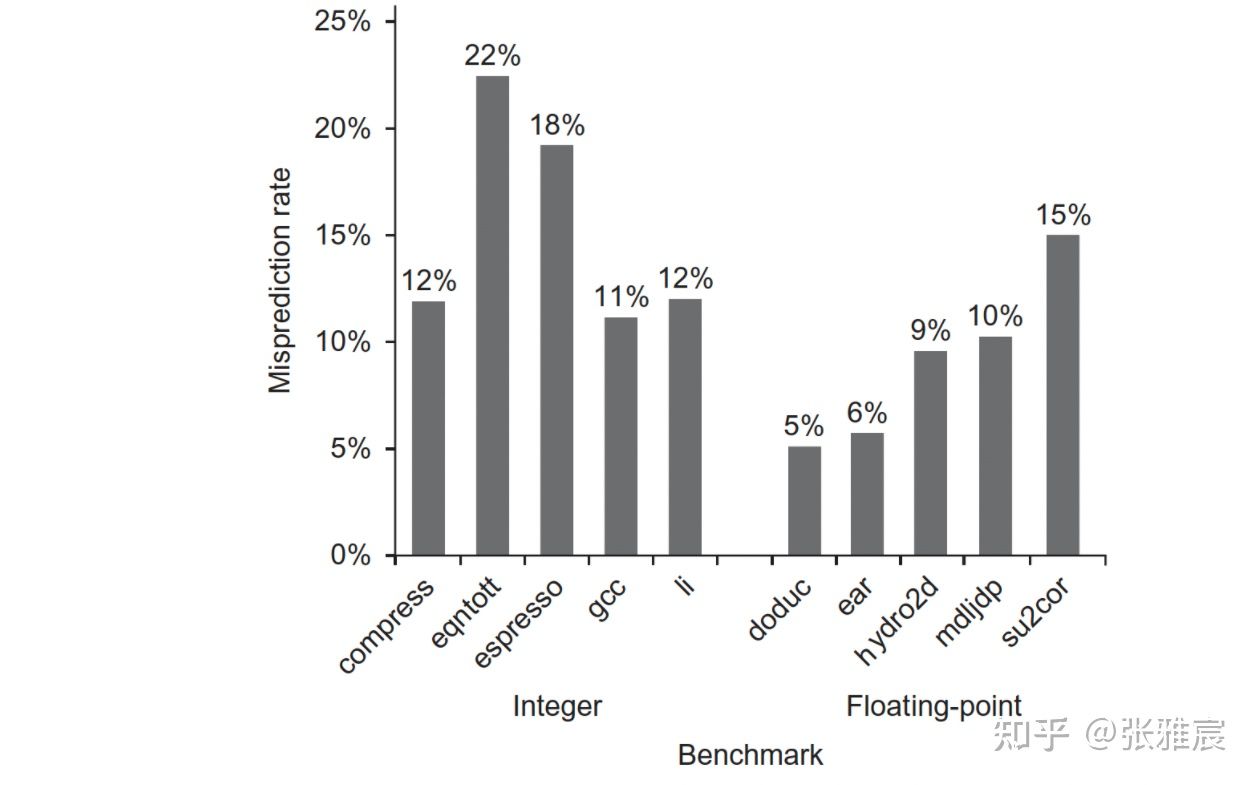
 Profile-based
Profile-based
利用编译器收集运行时的信息(Profile-guided optimization, PGO)来决定分支是否跳转,编译后的代码会插入额外的命令统计实际执行时的情况,比如GNU C++编译器的Compiler Profiling, -fbranch-probabilities。需要一个compiler-profile-compier的过程。
下图是在SPEC92 benchmark下,采用这种策略的不同程序分支预测结果:
Program-based
论文Branch prediction for free详细介绍了Program-based方式的分支预测。例如:
- opcode heuristic : 将BLEZ预测为not taken等。(负数在很多代码里代表error values)
- loop heuristic : 与BTFN一样。
- Pointer comparisons
这个方法优点是不需要额外的profiling,缺点是Heuristic也可能没有代表性。该方法的平均预测失败率在20%左右。
Programmer-based由实际写代码的人来给出分支是否跳转的信息。这个不需要提前的profiling和analysis,但是需要编程语言、编译器和ISA的支持。
比如gcc/clang的__builtin_expect和C++20新增的likely, unlikely , 这也更利于编译器对代码结构进行排列。
constexpr double pow(double x, long long n) noexcept {
if (n > 0) [[likely]]
return x * pow(x, n - 1);
else [[unlikely]]
return 1;
}
静态预测的优点是功耗小,实现成本低,但是最大的缺点是无法根据动态的程序输入变化而改变预测结果,dynamic compiler(JAVA JIT、Microsoft CLR)会在一定程序上改善这个缺点,但也有runtime overhead。所以现代CPU通常采取动态预测的方式。
动态预测动态预测的优点是可以根据分支历史输入和结果进行动态调整,且不需要static profiling,缺点是需要额外的硬件支持,延迟也会更大。
Last time prediction (single-bit)缓存上一次分支的预测结果。缺点是只有单比特,无容错机制。比如分支历史是TNTNTNTNTNTNTNTNTNTN,此种算法的准确率是0%。
Two-bit counter based prediction (bimodal prediction)该算法不会马上利用前一次的预测结果,而是【前两次】,核心是分支指令偶尔发生一次方向改变,预测值不会立刻跟着变。
每个分支对应4个状态:Strongly taken、Weakly taken、Weakly not taken、Strongly not taken。初始状态可以设为Strongly not taken或者Weakly not taken.
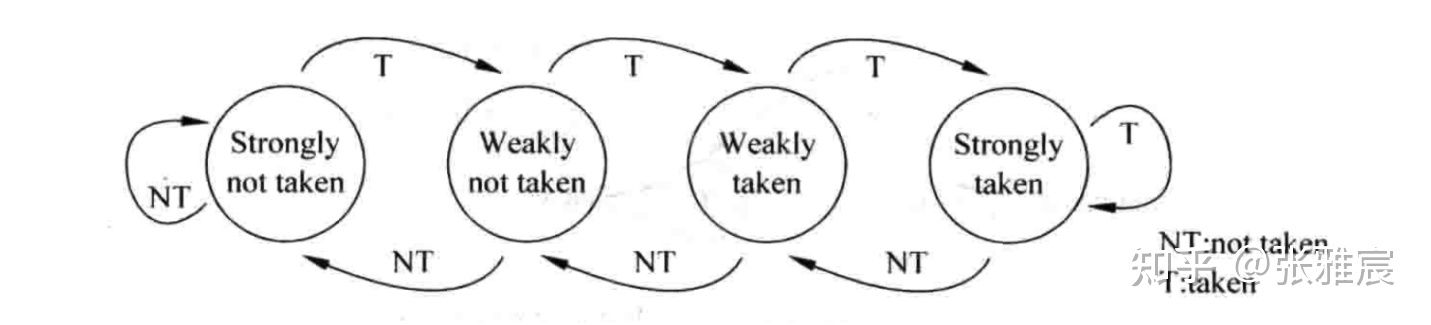
从上图可以看出来,之所以叫【饱和】,是因为计数器在最大值和最小值时达到饱和状态,如果分支方向保持不变,也不会改变计数器状态。更一般的,有n位饱和计数器,当计数器的值大于等于(2^n - 1)/2时,分支预测跳转,否则不跳转。n一般最多不超过4,再大也没有用。
由于不可能为每个分支都分配一个2位饱和计数器,一般使用指令地址的一部分去寻址Pattern History Table(PHT),PHT每一个entry存放着对应分支的2位饱和计数器,PHT的大小是2^k * 2bit。但是这种方式寻址,会出现aliasing的问题,如果两个分支PC的k部分相同,会寻址到同一个PHT entry。如果两个分支的跳转方向相同还好,不会互相干扰,这种情况叫neutral aliasing。但如果两个分支跳转方向不相同,那么PHT entry的计数器会一直无法处于饱和状态,这种叫negative aliasing。后文说到其他分支预测方法怎么缓解这个问题的。
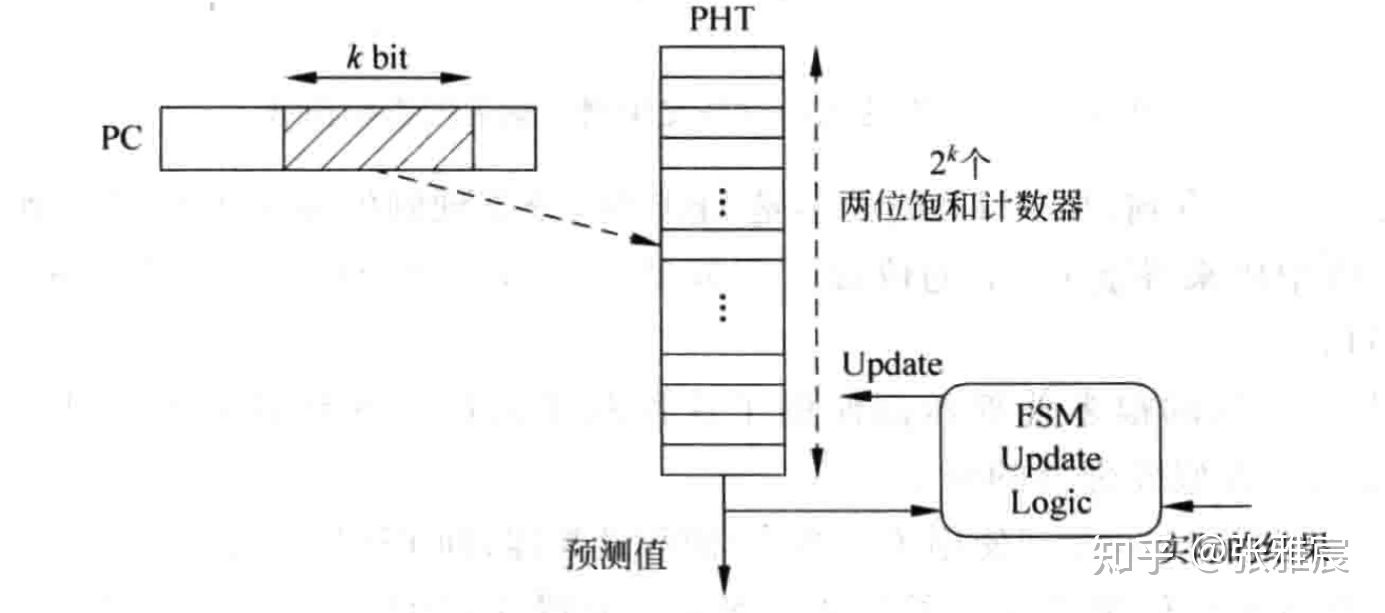
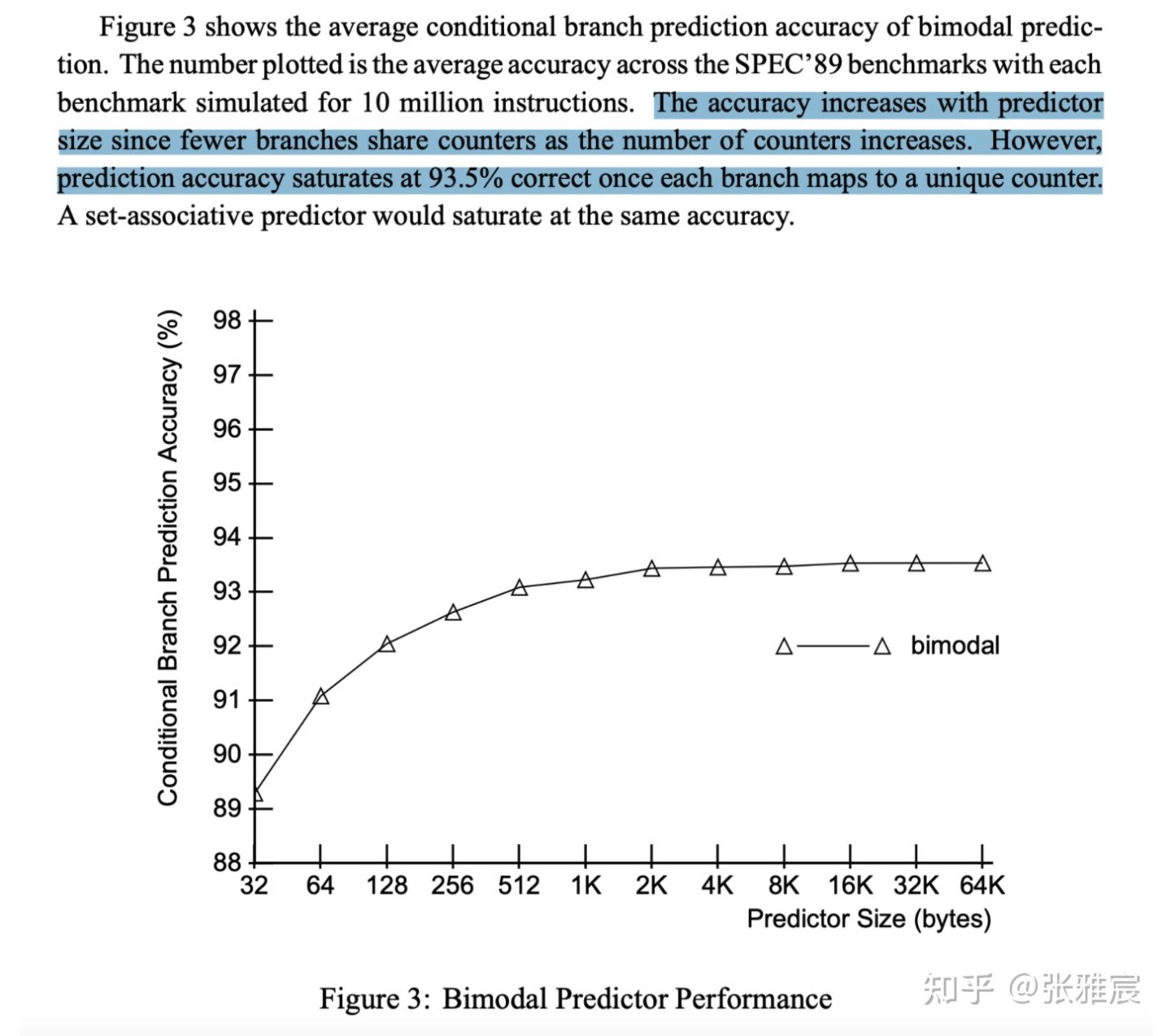
PHT的大小也会直接影响分支预测的准确率。论文Combining Branch Predictors有一组测试数据,随着PHT增大,预测准确率在93.5%左右达到饱和。当PHT是2KB时,用分支地址中的k=log(2*1024*8b/2b)=13位去寻址PHT.
 饱和计数器的更新
饱和计数器的更新
有3个时机供选择:
- 分支预测后。
- 分支结果在流水线执行阶段被实际计算后。
- Commit/Retire阶段。
第一个方案虽然更新快,但是结果不可靠,因为预测结果可能是错误的。
第二个方案的更新阶段比第三个早,但是最大的缺点是当前分支有可能处于mis-prediction路径上,也就是之前有分支指令预测失败了,会导致它从流水线中被flush,对应的技术器不应该被更新。
第三个方案的缺点是从预测到最终更新计数器的时间过长,导致该指令可能在这期间已经被取过很多次了,例如for循环体很短的代码,这条指令在进行后面分支预测的时候,并没有利用之前执行的结果,但是考虑到饱和计数器的特点,只要计数器处于饱和状态,预测值就会固定,即使更新时间晚一点,也不会改变计数器状态,所以并不会对预测器的准确率产生很大的负面影响,该方案是一般采取的方案。
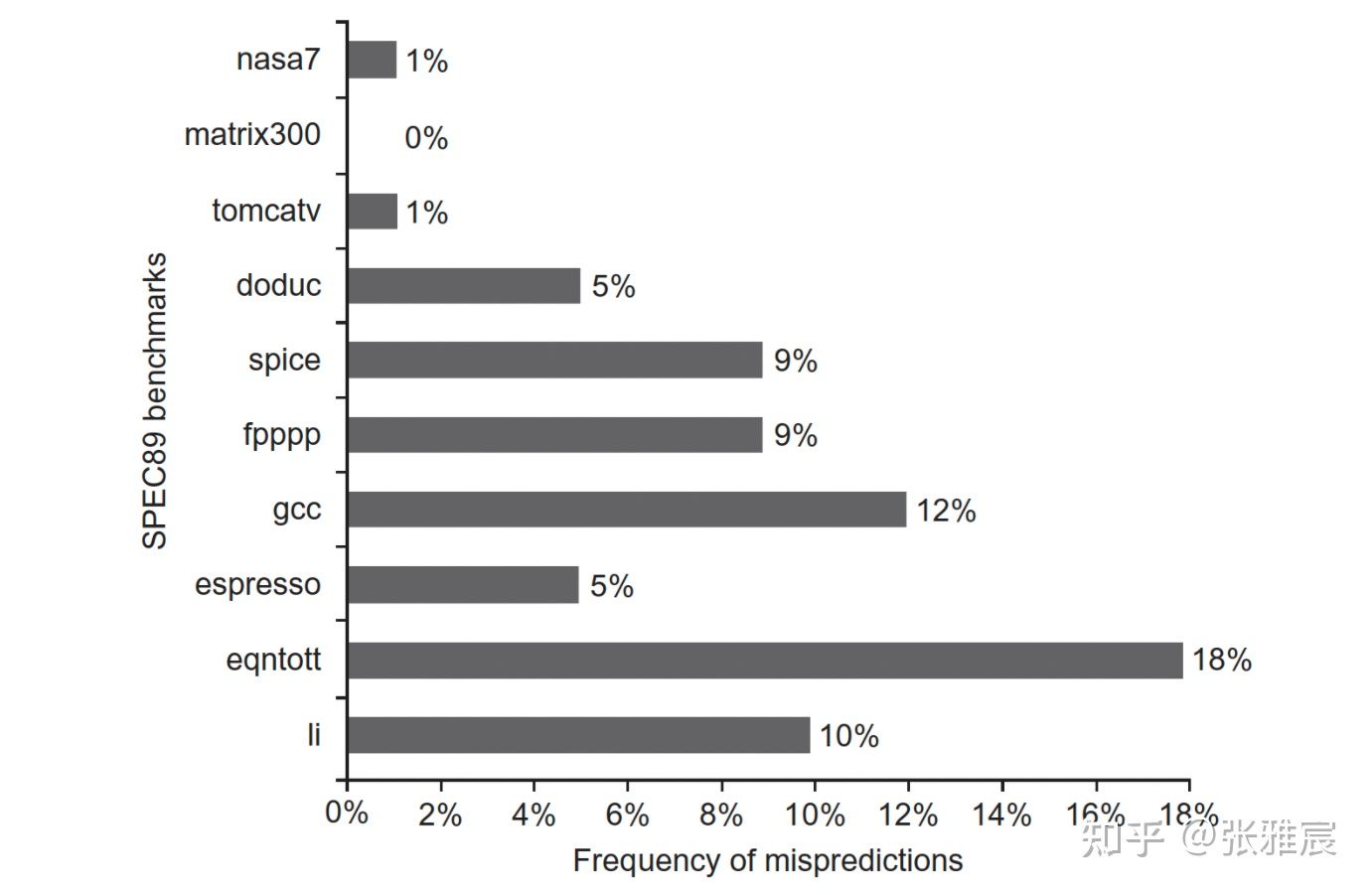
该算法的评价准确率在85%-90%之间。下图是采用SPEC89 benchmark,4096-entry 2-bit PHT的预测准确率情况。20世纪90年代很多处理器采用这种方法,比如MIPS R10K,PHT=1Kb、IBM PowerPC 620,PHT=4Kb。
但是对于TNTNTNTNTNTNTNTNTNTN这种极端情况,准确率是50%(假设初始计数器的状态是weakly taken),还是不可接受。
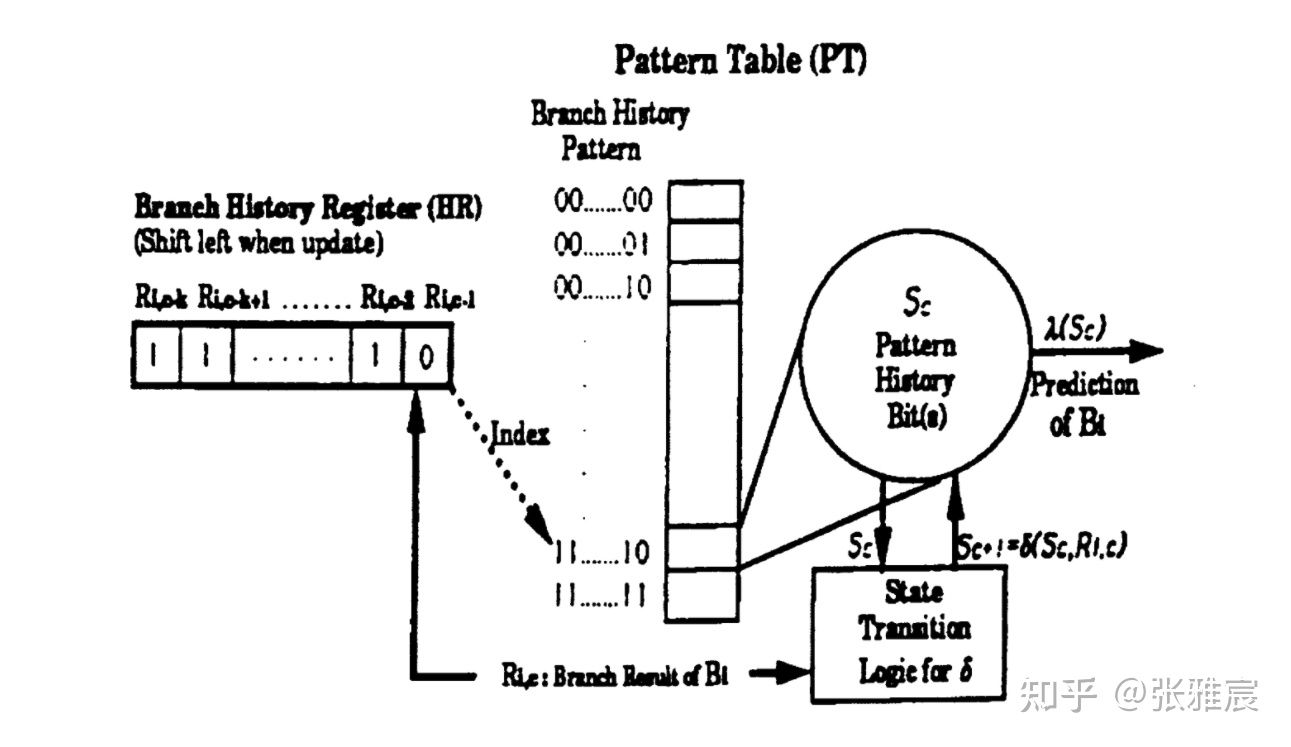
Two Level Local Branch Prediction (Adaptive two-level prediction)1991年的论文Two-Level Adaptive Training Branch Prediction提出可以基于分支历史结果进行预测,每个分支对应一个Branch History Register(BHR),每次将分支结果移入BHR。
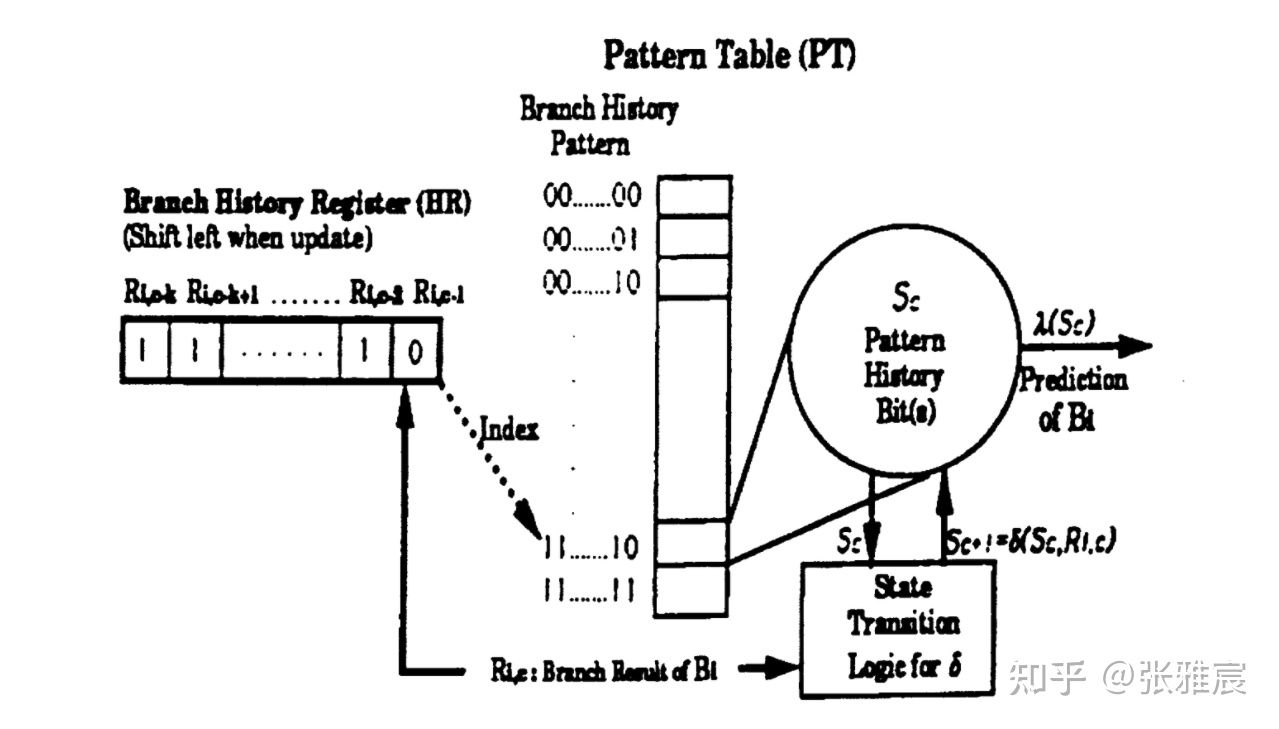
从上图可以看出为什么是Two-level :
- First level : 一组位宽为n位的BHR,记录分支过去n次的结果,使用分支PC寻址。所有BHR组合在一起称为Branch History Register Table(BHRT or BHT)。
- Second level : 使用BHR去寻址PHT,大小为2^n * 2bit,PHT每个entry存储对应BHR的2位饱和计数器。
假如分支结果是TNTNTNTNTNTNTNTNTNTN,BHR是2位,那就需要一个有着4个entry的PHT。BHR的值交替出现10和01。当BHR的值是10时,对应PHT的第2个entry,因为下次分支肯定是跳转,所以该entry对应的饱和计数器是Strongly taken状态。当分支需要进行预测时,发现BHR=10,会预测下次跳转。
再比如论文Combining Branch Predictors中的例子,一个道理,不详细解释了。

该论文测试对比了在不通过PHT大小下Local History Predictor和Bimodal Predictor的准确率。随着PHT体积增大,Local History Predictor的准确率维持在97%左右。

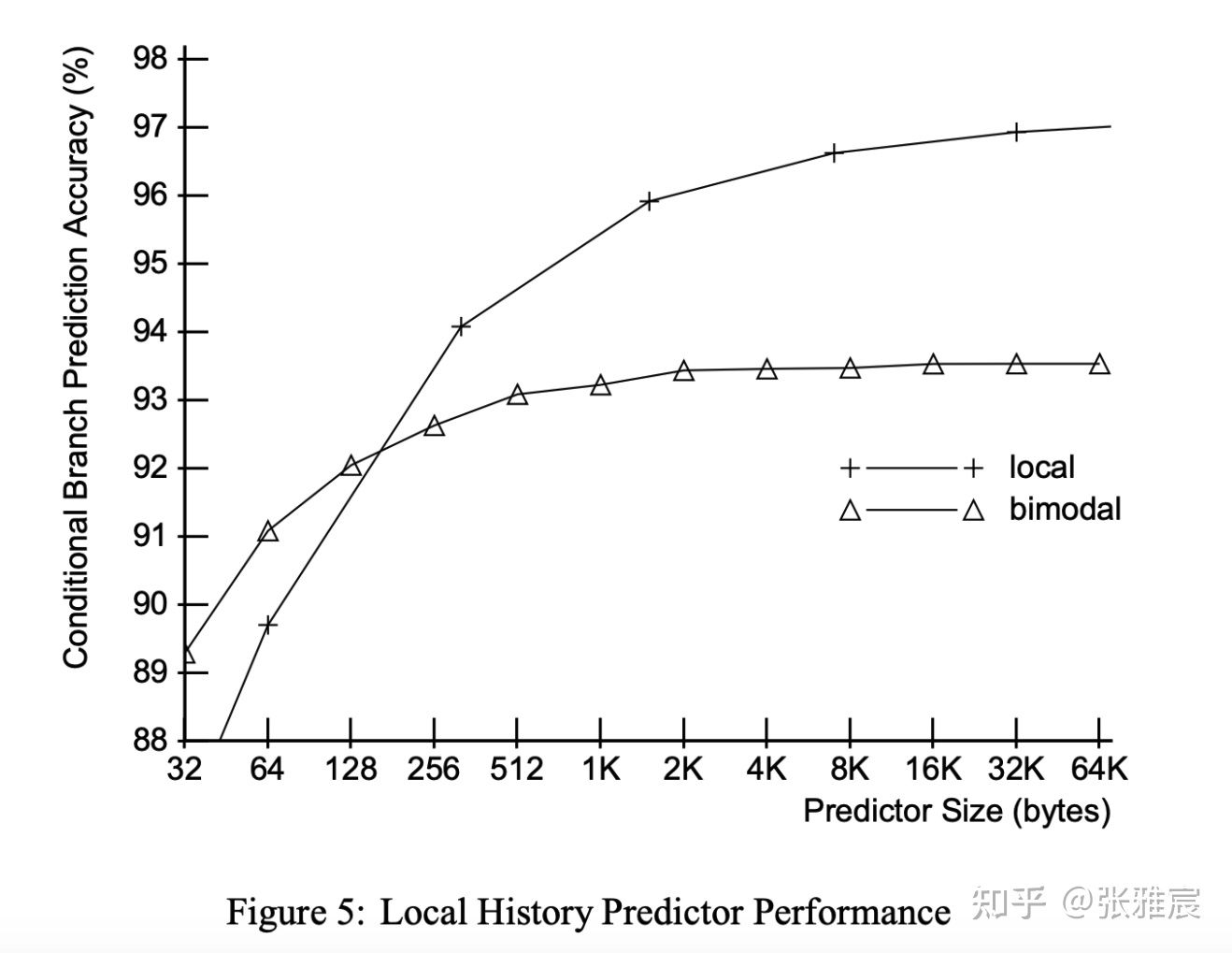
该算法还有2个需要权衡的地方:
- BHR的位宽大小 : PHT entry的计数器达到饱和状态的时间称为training time. 在这段时间内,分支预测的准确率较低,而training time取决于BHR的位宽。【位宽过大】需要更多的时间,而且增加PHT体积,但是也会记录更多的历史信息,提高预测准确度。但是【位宽过小】会不能记录分支的所有结果,小于循环周期,使用2位的BHR去预测NNNTNNNTNNNT,PHT entry的计数器无法达到饱和状态,预测结果就差强人意。BHR位宽需要实际进行权衡和折中。
- Aliasing/Interference in the PHT : 与2-bit counter算法一个问题,下文详述。
该算法思想是一个分支的结果会跟前面的分支结果有关。
下面的例子,如果b1和b2都执行了,那么b3肯定不会执行。只依靠b3的local branch history无法发现这个规律。
if (2 == aa) { /** b1 **/
aa = 0;
}
if (2 == bb) { /** b2 **/
bb = 0
}
if (aa != bb) { /** b3 **/
...
}
local branch history使用BHR记录。类似的,如果要记录程序中所有分支指令在过去的执行结果,需要一个位宽为n的Global History Register(GHR),再去寻址对应PHT中的饱和计数器,整体结构跟Two Level Local Branch Prediction很像。下图的HR既可以指BHR,也可以指GHR。
再比如论文Combining Branch Predictors中的例子,常见的两层for循环,GHR的0是内层循环j=3 not taken的结果:
 BHR/GHR更新时机
BHR/GHR更新时机
同样是三种选择:
- 分支预测后。
- 分支结果在流水线执行阶段被实际计算后。
- Commit/Retire阶段。
Global Branch Prediction中GHR更新一般是在分支预测后直接更新(speculative)。因为GHR记录的全局分支历史,在现代CPU都是Superscalar架构的背景下,如果在分支retire后或者流水线分支结果实际被计算出来之后再更新,该指令后来的很多分支指令可能已经进入流水线中,他们都使用相同的GHR,这就违背了GHR的作用。如果当前指令预测失败,后续指令都使用了错误的GHR,其实也没有关系,因为反正他们随后都会从流水线中被flush掉。但是需要一种机制对GHR进行recover,这是另外一个话题。
Local Branch Prediction中的BHR跟GHR有所不同,是在指令retire阶段更新(non-speculative),由于记录的是local branch history,只有在for循环体很短的情况,才可能出现一条指令在流水线提交阶段更新BHR时,流水线内又出现了这条分支使用BHR进行预测的情况。但这种情况不会对预测性能有太大影响,因为经过warmup/training之后,预测器会预测for循环一直跳转。而其他两个阶段更新需要recover机制,收益也不明显。
GHR/BHR对应的PHT饱和计数器还是在指令retire阶段更新,理由跟two-bit counter一样。
Aliasing/Interference in the PHT不同分支使用相同PHT entry,最坏情况导致negative aliasing:
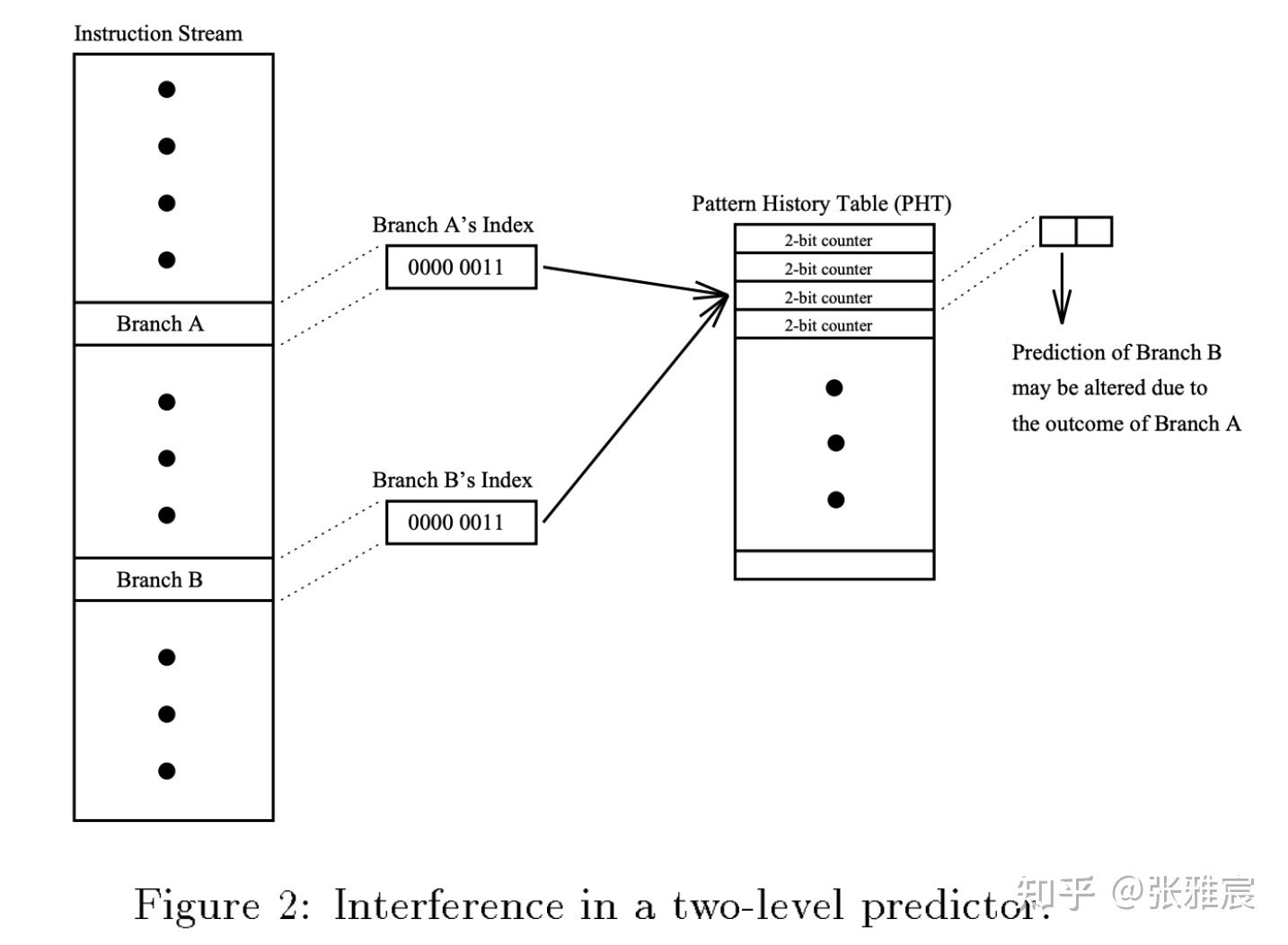
可以通过下面的方法有效缓解:
- 增大PHT体积
使用更多的PC bit去寻址,但也需要兼顾成本。
- 过滤biased branch
很多分支在99%的情况下跳转方向是一致的,论文Branch classification: a new mechanism for improving branch predictor performance提出可以检测具有这些特点的分支,使用简单的last-time或者static prediction方法去预测,防止它们污染其他分支结果。
- Hashing/index-randomization
最典型的还是McFarling在Combining Branch Predictors里提出的Gshare,增加额外的context information,将GHR与PC进行XOR hash去寻址PHT:
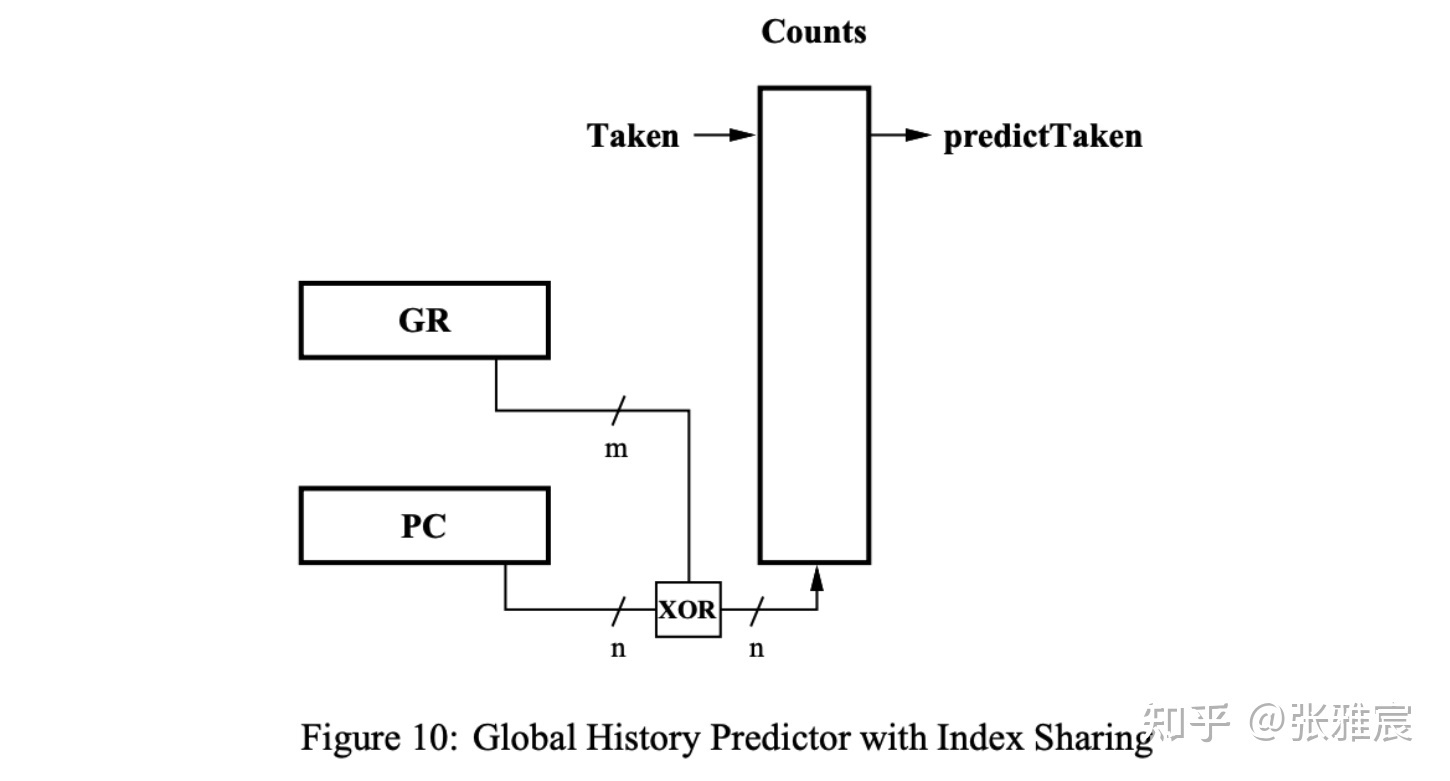
再比如Gskew以及其各种变种,核心思想是使用多个hash方式和PHT,最后使用majority vote进行决策:

- Agree prediction
论文The Agree Predictor: A Mechanism for Reducing Negative Branch History Interference提出了agree predictior,从论文名字也可以看出来是为了解决PHT的aliasing问题。
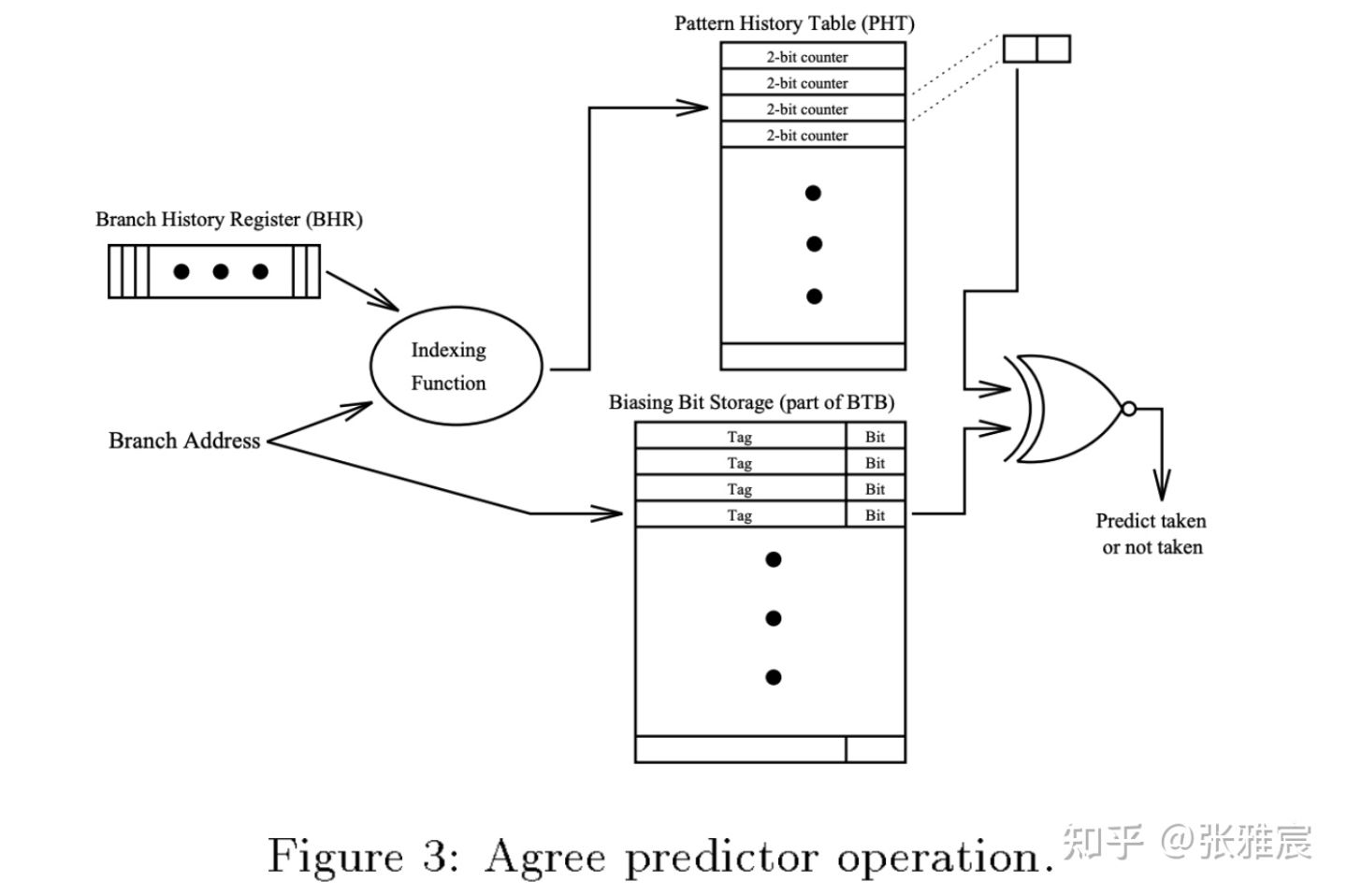
左边是上面提过的Gshare结构,区别在右边:
- 基于大多数分支总是倾向于一个跳转方向,每个分支在BTB中增加一个bias bit,代表该分支倾向于taken还是not taken。
- PHT中还是2位饱和计数器,但是更新逻辑不同:当最终跳转,结果和bias bit相同(agree)时,计数器自增,否则自减(disagree)。
如果选择了正确的bias bit,即使两个分支寻址到一个PHT entry,那计数器也会一直自增到饱和,即agree状态。
假如两个分支br1和br2,taken的概率分别是85%和15%,且使用同一个PHT entry,按照传统的其他方案,两个分支跳转结果不同,更新计数器造成negative aliasing的概率是(br1taken, br2nottaken) + (br1nottaken,br2taken) = (85% * 85%) + (15% * 15%) = 74.5%。如果是agree predictor,br1和br2的bias bit分别被设置为taken和not taken,negative aliasing的概率是(br1agrees, br2disagrees) + (br1disagrees, br2agrees) = (85% * 15%) + (15% * 85%) = 25.5%,大大降低了negative aliasing概率。
除了上面的解决方案,还有The bi-mode branch predictor提出的bi-mode,mostly-taken和mostly-not-taken使用分开的PHT,降低negative aliasing、The YAGS Branch Prediction Scheme提出的YAGS预测器。
Hybrid Branch Prediction (Alloyed prediction)基于Global history的算法不能很好预测单个分支TNTNTNTNTN的情况,有些分支适合使用Local history去预测,有些适合Global history,还有些只要Two-bit counter就够了。Hybrid branch prediction思想是使用多个分支预测器,然后去选择最好最适合该分支的。
该方法的优点除了上面说的,还可以减少预测器整体的warmup/training time。warmup快的预测器可以在开始阶段优先被使用。缺点是需要额外新增一个meta-predictor去选择使用哪个预测器。
最经典的应该是Alpha 21264 Tournament Predictor,对应的论文The Alpha 21264 Microprocessor Architecture也是经典中的经典。
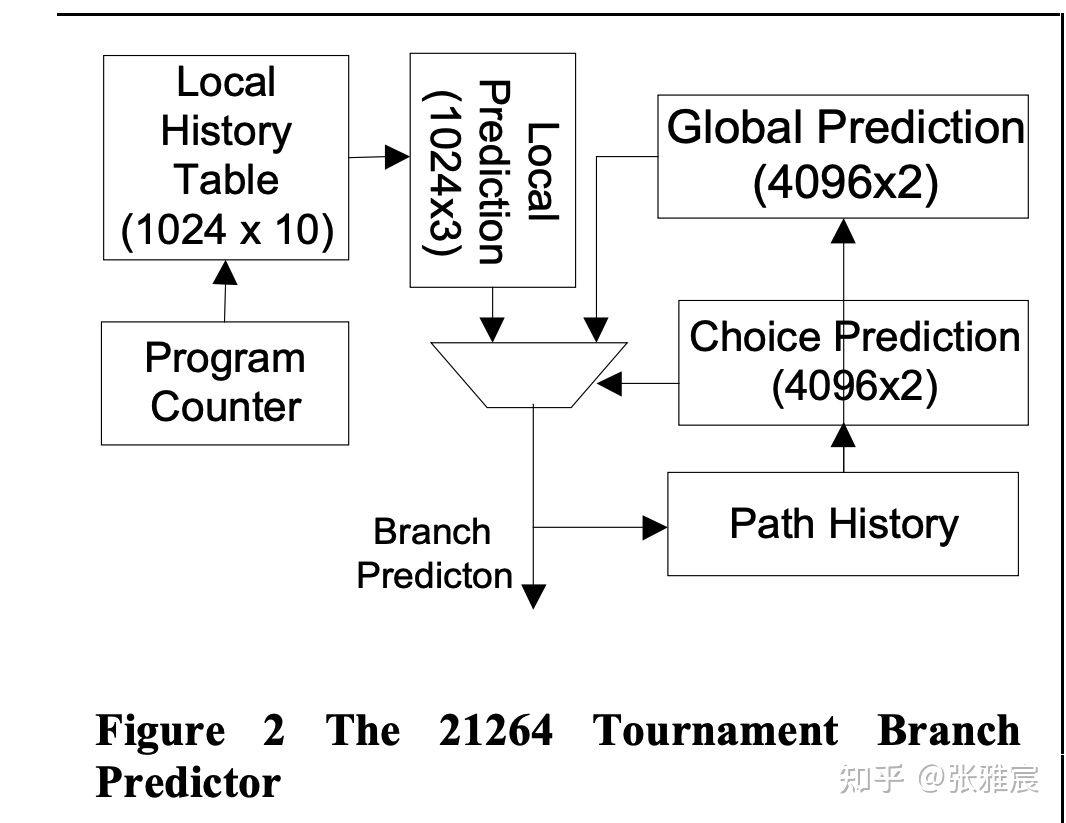
左边是local branch prediction,两级结构。第一级local history table大小是1024 * 10bit,也就是使用了10位宽的BHR,整个表格记录1024条分支历史信息。10位宽的BHR需要PHT支持1024个饱和计数器,Alpha 21264采用的是3位饱和计数器。
右边是global branch prediction,12位宽的GHR,记录全局过去12条分支的历史结果,PHT需要支持4096个饱和计数器,这里使用的2位饱和计数器,和local那里不一样。
至于meta-predictor就是图中标示的Choice Prediction,使用GHR寻址,所以有4096项,使用2位饱和计数器来追踪两个不同预测器的准确度,比如00代表local branch prediction准确率更高,11代表global branch prediction更好。
而各个预测器的更新跟之前说过的时机一样,BHR在指令retire更新,GHR在指令得到预测结果后更新,PHT中的饱和计数器在指令retire时更新。
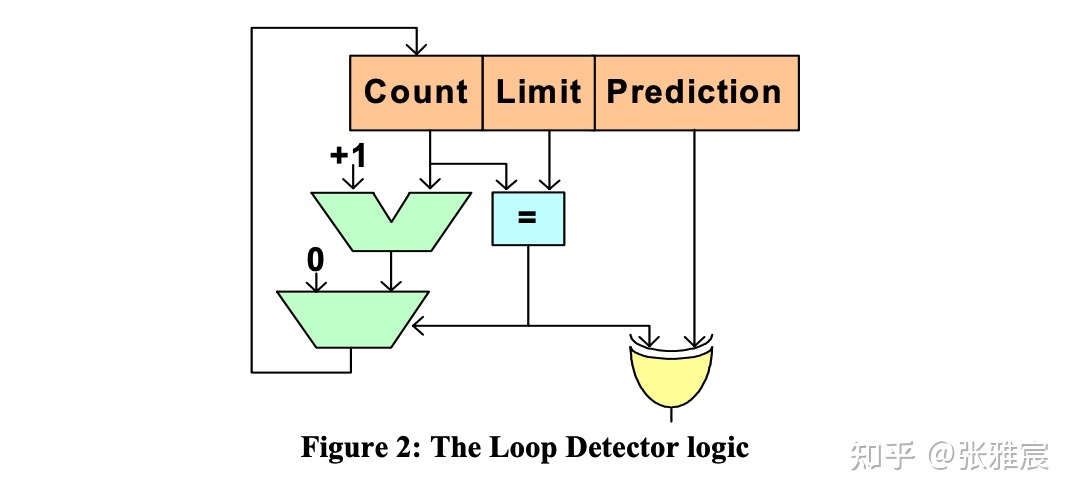
Loop Prediction
当分支是loop循环时,一般最后一次是预测失败的。Loop Predictor探测分支是否具有loop behavior并对该loop进行预测,loop behavior定义为朝一个方向taken一定次数,再朝相反方向taken一次,对每次循环都是相同次数的预测效果很好。现在很多分支预测器都集成了loop predictor,包括开头介绍的TAGE-SC-L。
下面的图参考Intel的论文The Intel Pentium M Processor: Microarchitecture and Performance:
 Perceptrons Prediction
Perceptrons Prediction
2001年的论文Dynamic Branch Prediction with Perceptrons提出完全不同的思想,采用机器学习的Perceptron去进行分支预测,这也是第一次将机器学习成功应用到计算机硬件上,虽然用到的方法很简单。
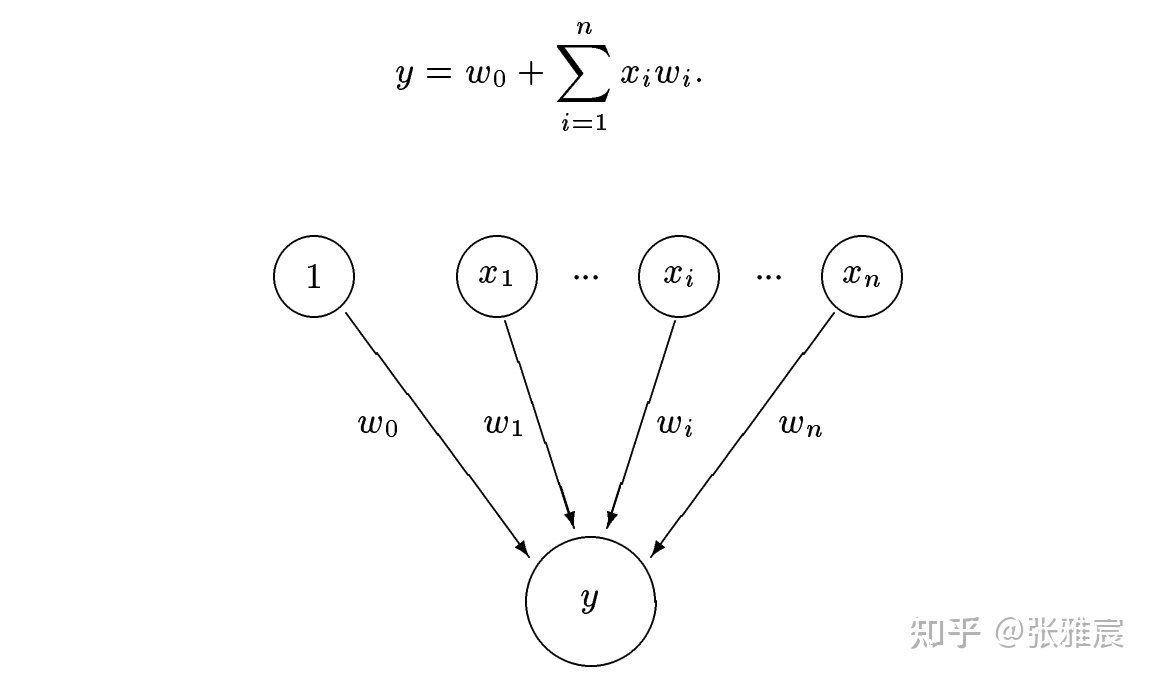
Perceptron学习xi和最终结果之间的linear function,每个分支对应一个Perceptron。w0是bias weight,若某个分支具有很强的倾向性,w0会对最终结果有很大的影响。xi是前面说过的GHR中对应的bit,只有0和1两种取值,x0恒等于1。wi是对应的weight。若y > 0,预测分支跳转,否则不跳转。
下图是wi的调整过程。如果预测错误或者Perceptron的输出小于等于某个阈值,就对wi进行调整。因为t、xi的取值只有1和-1,如果xi的取值和最终分支结果相同,对应的wi就+1,否则-1。一旦某个xi和分支结果有强关联,对应的wi绝对值就会很大,对最终结果有决定性影响。w0比较特殊,x0恒等于1,w0跟t的值变化,如果t一直是1或者-1,那么w0绝对值也会很大,决定最终结果。
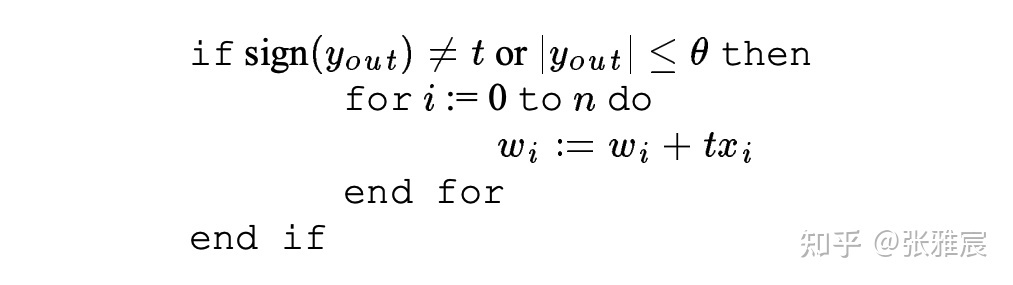
下图是整体流程,多了根据指令地址取对应Perceptron放到vector register的过程。
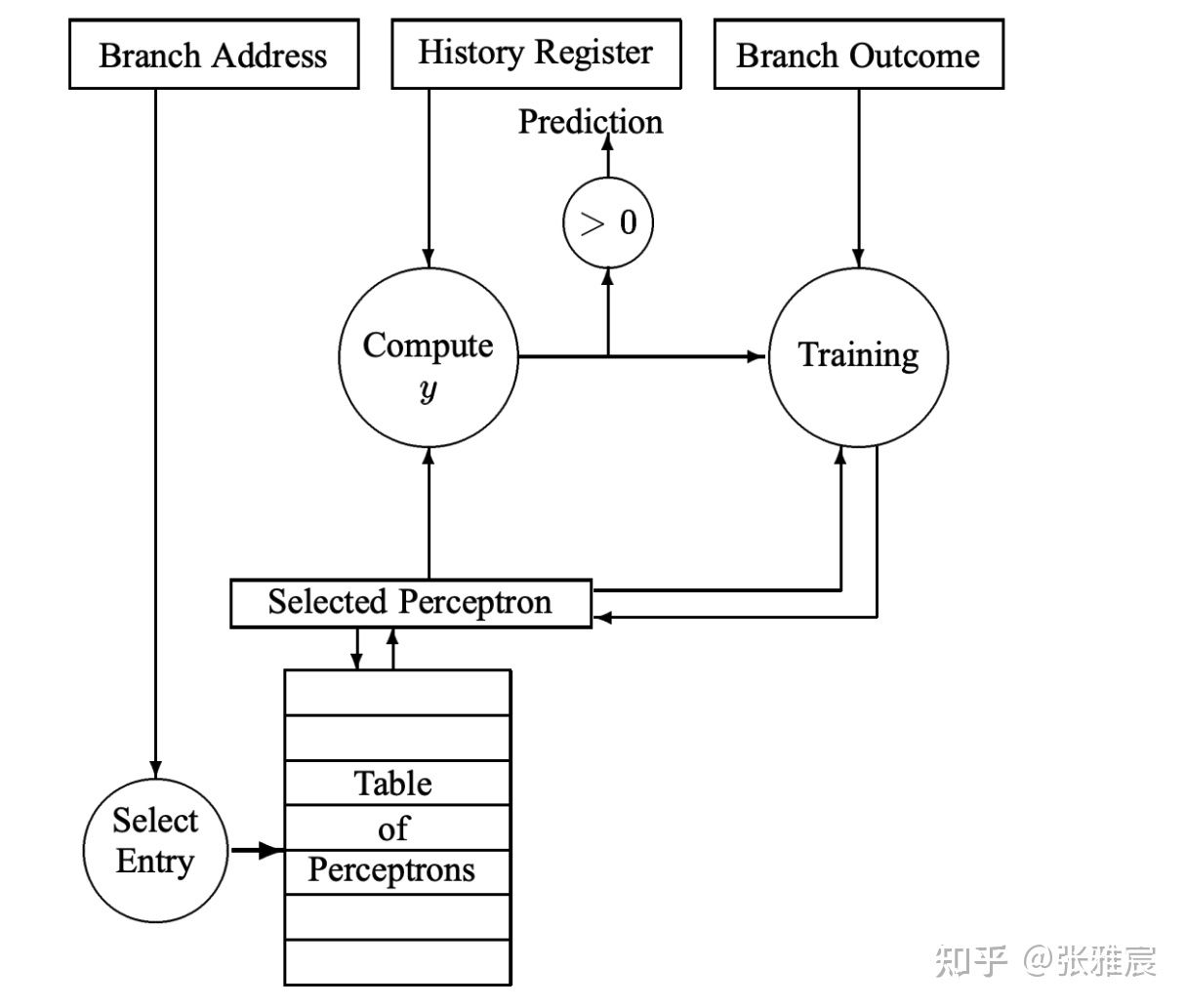
该算法的优点是可以使用位宽更大的GHR。在上面介绍的其他算法里,PHT的entry数目是2^(GHR位宽),但该算法仅仅为每一个分支分配一个Perceptron,增长是线性的。论文给出的算法预测准确率也很可观,感兴趣的可以去论文里看看。
算法缺点是只能学习linearly-separable function,不能学习比如XOR等更复杂的关系,防止分支预测期处理过复杂的模型而导致critical path延时变大:
if(condition1) {}
if(condition2) {}
if(condition1 ^ condition2) {}
后续还有很多人优化Perceptrons Prediction,比如2011年的论文An Optimized Scaled Neural Branch Predictor,2020年关于Samsung Exynos CPU Microarchitecture系列的论文Evolution of the Samsung Exynos CPU Microarchitecture,后者也是Perceptron Prediction应用在现代CPU上的典型案例。
 TAgged GEometric History Length Branch Prediction (TAGE)
TAgged GEometric History Length Branch Prediction (TAGE)
2006年的论文A case for (partially) tagged Geometric History Length Branch Prediction提出了TAGE prediction,分类属于PPM-based prediction,此后TAGE及其变种连续蝉联CBP比赛的冠军,包括开头介绍的TAGE-SC-L。很多现代CPU都使用了基于TAGE思想的分支预测器。
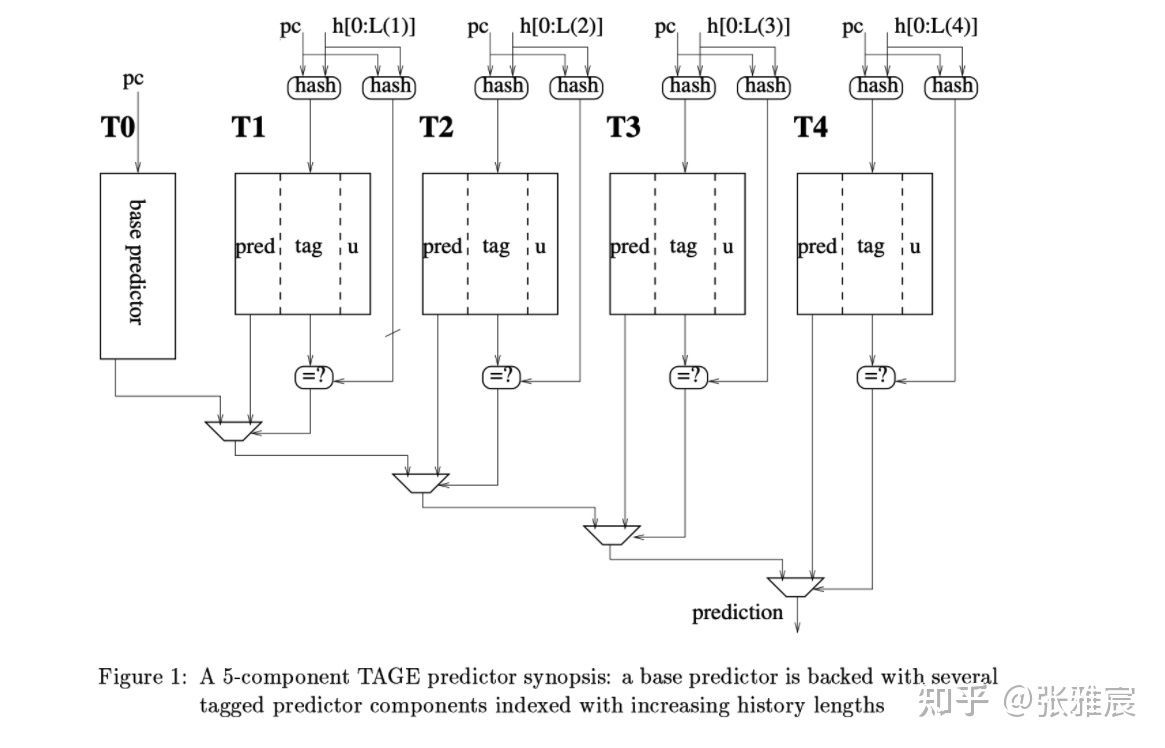
有几个关键点让TAGE脱颖而出:
- TA:Tagged,添加TAG数据。不同分支指令hash到同一个PHT entry可能会导致negative aliasing。TAGE采用partial tagging,为了防碰撞,生成TAG的hash和上一步寻址Tagged Predictor的hash函数也不同。
- GE:Geometric,将预测器分为一个2-bit Base Predictor和多个Tagged Predictor。
- Tagged Predictor使用PC和GHR[0:i]进行hash去寻址。i可以是一个等比数列a0∗q^(n−1) ,比如GHR[0:5],GHR[0:10],GHR[0:20],GHR[0:40]。这么做的目的是不同的分支需要不同长度的历史结果才能达到更好的准确率,而之前的算法使用相同位宽的GHR去寻址PHT。
- 最终预测采用对应GHR最长的那个Tagged Predictor给出的结果,如果都没有match上,使用一直能match的Base Predictor。
- 增加2-bit的useful counter,代表该预测值在过去是否对结果起到过正向作用。
Tagged Predictor的更新逻辑以及TAGE各种实验数据,可以看看论文,写的很详细,限于篇幅这里不列举了:

至于分支预测剩下两个主题那就更大更复杂了,感兴趣的可以参考《超标量处理器设计》4.4 - 4.5节,或者Onur Mutlu在Youtube上的Digital Design and Computer Architecture课程
参考资料:
- Onur Mutlu - Digital Design and Computer Architecture
- 《超标量处理器设计》第4章
- Computer Architecture —— A Quantitative Approach Sixth Edition
(完)
朋友们可以关注下我的公众号,获得最及时的更新: