在微服务中,我们将业务拆分成一个个的服务,服务与服务之间可以相互调用,但是由于网络原因或者自身的原因,服务并不能保证100%可用,如果单个服务出现问题,调用这个服务就会出现网络延迟,此时若有大量的网络涌入,会形成任务堆积,最终导致服务瘫痪。
接下来我们模拟一个高并发的场景
-
编写java代码
@RestController @Slf4j public calss OrderController2{ @Autowired private OrderService orderSerivce; @Autowired private ProductService productService; @RequestMapping("/order/prod/{pid}") public Order order(@Pathvariable("pid") Integer pid){ Product product = productService.findByPid(pid); Try{ Thread.sleep(100) }catch(InterruptedException e){ e.printStackTrace(); } Order order = new Order(); order.setUid(1); order.setUsername("测试账号"); order.setPid(pid); order.setPname(product.getPname()); order.setPprice(product.getPprice()); order.setNumber(1); return order; } @RequestMapping("/order/message") public String message(){ return "高并发下的问题测试"; } } -
配置tocmat 并发数
server: port:8091 tomcat: max-threads: 10 -
接下来使用压测工具,对请求进行压测
下载地址:https://jmeter.apache.org
第一步:修改配置,并启动软件
进入bin目录,修改jmeter.properties 文件中的语言支持为language=zh_CN,然后县级jmeter.bat 启动软件。
第二步:添加线程组
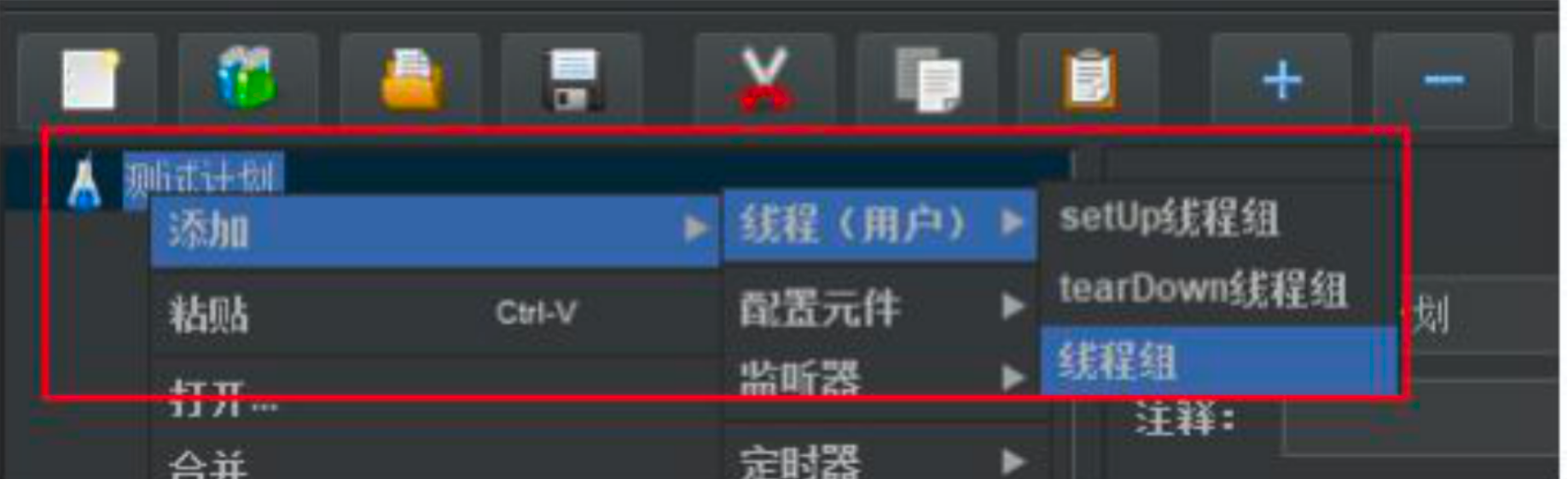
第三步:配置线程并发数

第四步:添加http取样

第五步:配置取样,并启动测试

-
访问message方法观察效果
-
结论:
*此时会发现,由于order方法囤积了大量的请求,导致message方法的访问出现了问题,这就是服务雪崩的雏形
*在分布式系统中,由于网络原因或者自身原因,服务一版无法保证100%可用,如果一个服务出现了问题,调用这个服务就会出现线程阻塞的情况,此时若有大量的请求涌入,就会出现多条线程阻塞等待,进而导致服务瘫痪
由于服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成才灾难性的严重后果,这就是服务故障“雪崩效应”。
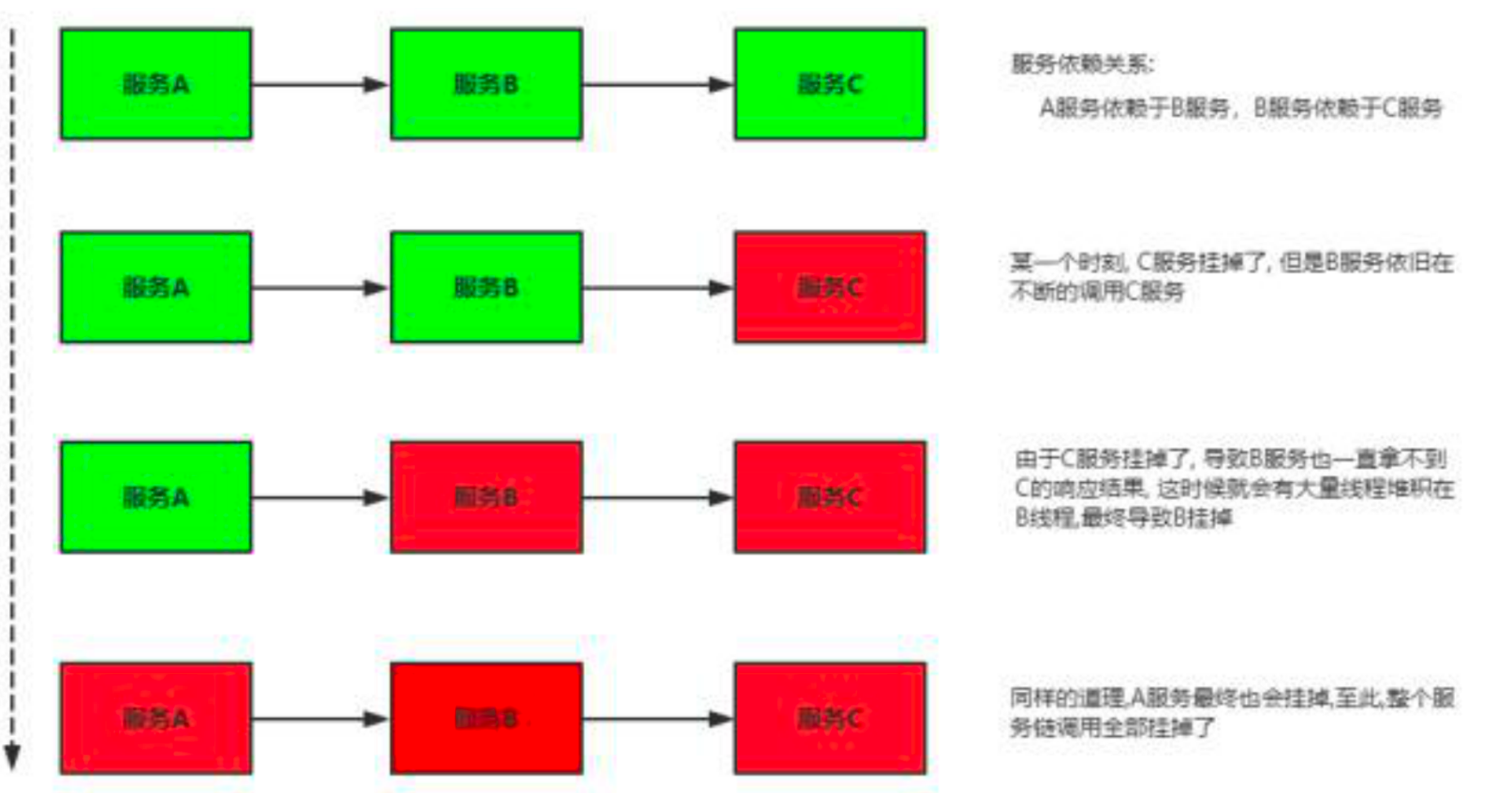
雪崩发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方法相应变慢,亦或者是某台机器的资源耗尽。我们无法完全杜绝雪崩源头的放生,只有做好了足够的融租哦,保证在一个服务发生问题,不会影响到其他服务的正常运行,也就是“雪落而不雪崩”。
4.3常见的容错方案要防止雪崩的扩散,我们就要做好服务的容错,容错说白了就是保护自己不被猪队友拖垮的一些措施,下面介绍常见的服务容错思路和组件。
常见的容错思路:
常见的容错思路有隔离、超时、限流、熔断、降级这几种,下面分别介绍下。
-
隔离
它是指将系统按照一定的原则划分为若干个服务模块,各个模块之间相互独立,无强依赖。当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不波及其他模块,不影响整体的系统服务,常见的隔离方式有:线程池隔离和信号量隔离

-
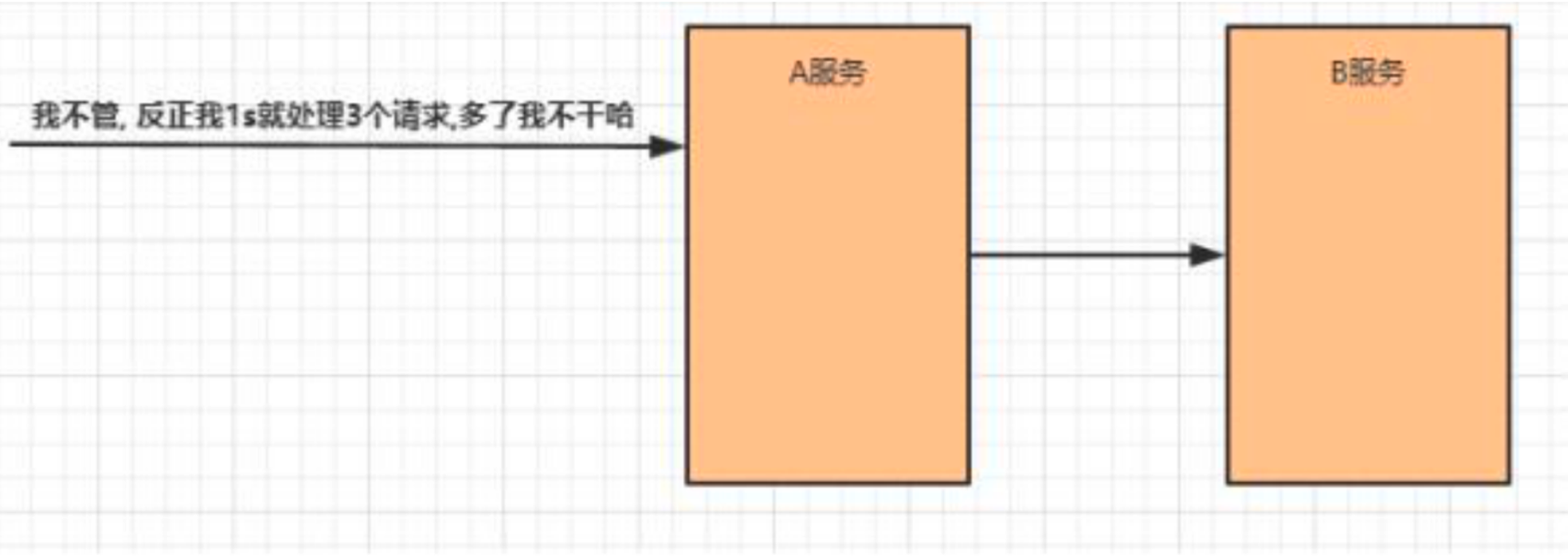
超时
在上游服务调用下有服务的时候,设置一个最大响应时间,如果炒股哦这个时间,下游未做出反应,就断开请求,释放掉线程
-
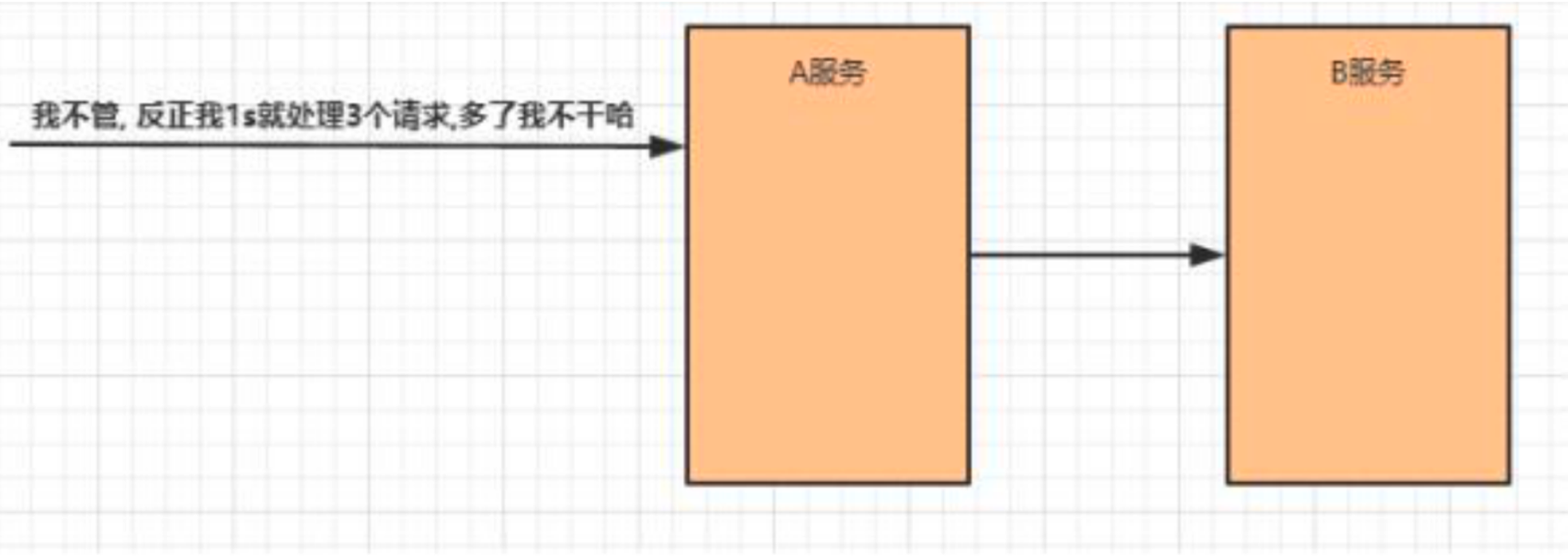
限流
限流就是限制系统的输入和输出流量已达到保护系统的目的。为了保证系统的稳固运行,一单达到限制的阈值,就需要限制流量并采取少量措施以完成限制流量的目的。
-
熔断
在互联网系统中,当下有服务因访问压力过大而影响变慢或失败,上游服务为了保护系统整体可用性,可用暂时切断对下有服务的调用,这种牺牲局部,保全整体的措施就叫做熔断

服务熔断一般有三种状态:
-
熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制
-
熔断开启状态(Open)
后续对该服务接口的调用不在经过网络,直接执行本地的fallback方法
-
版熔断状态(Half-Open)
尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率,如果成功率达到预期,则说经服务已恢复,进入熔断关闭状态,如果成功率仍旧很低,则重新进入熔断关闭状态。
-
-
降级
降级其实就是为服务提供一个托底方案,一单服务无法正常调用,就使用托底方案。
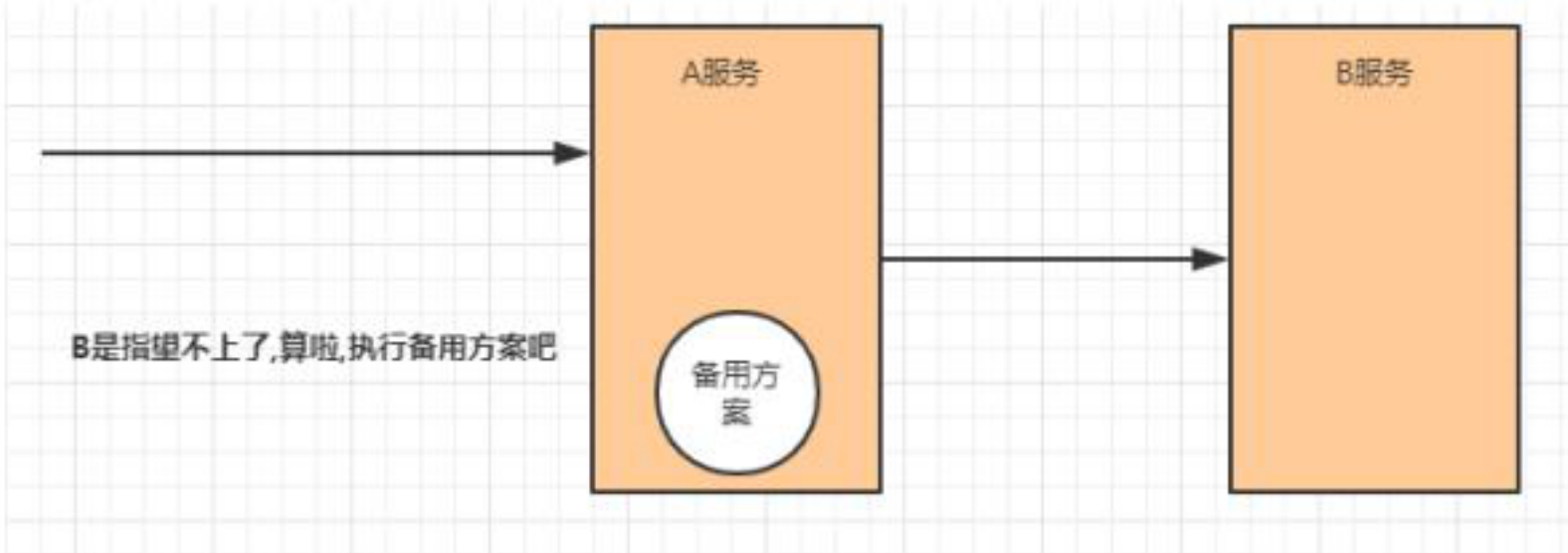
-
Hystrix
Hystrix是由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止级联失败,从而提升系统的可用性和容错性。
-
Resilience4J
Resilience4J一款非常轻量、简单、并且文档非常清晰、丰富的熔断工具,这也是Hystrix官方推荐的替代产品。不仅如此,Resilience4J还原生支持Spring Boot 1.x/2.x,而且监控也支持和prometheus等多款主流产品进行整合。
-
Sentinel
Sentinel是阿里巴巴开源的一款断路器实现,本身在阿里内部已经被大规模采用,非常稳定。
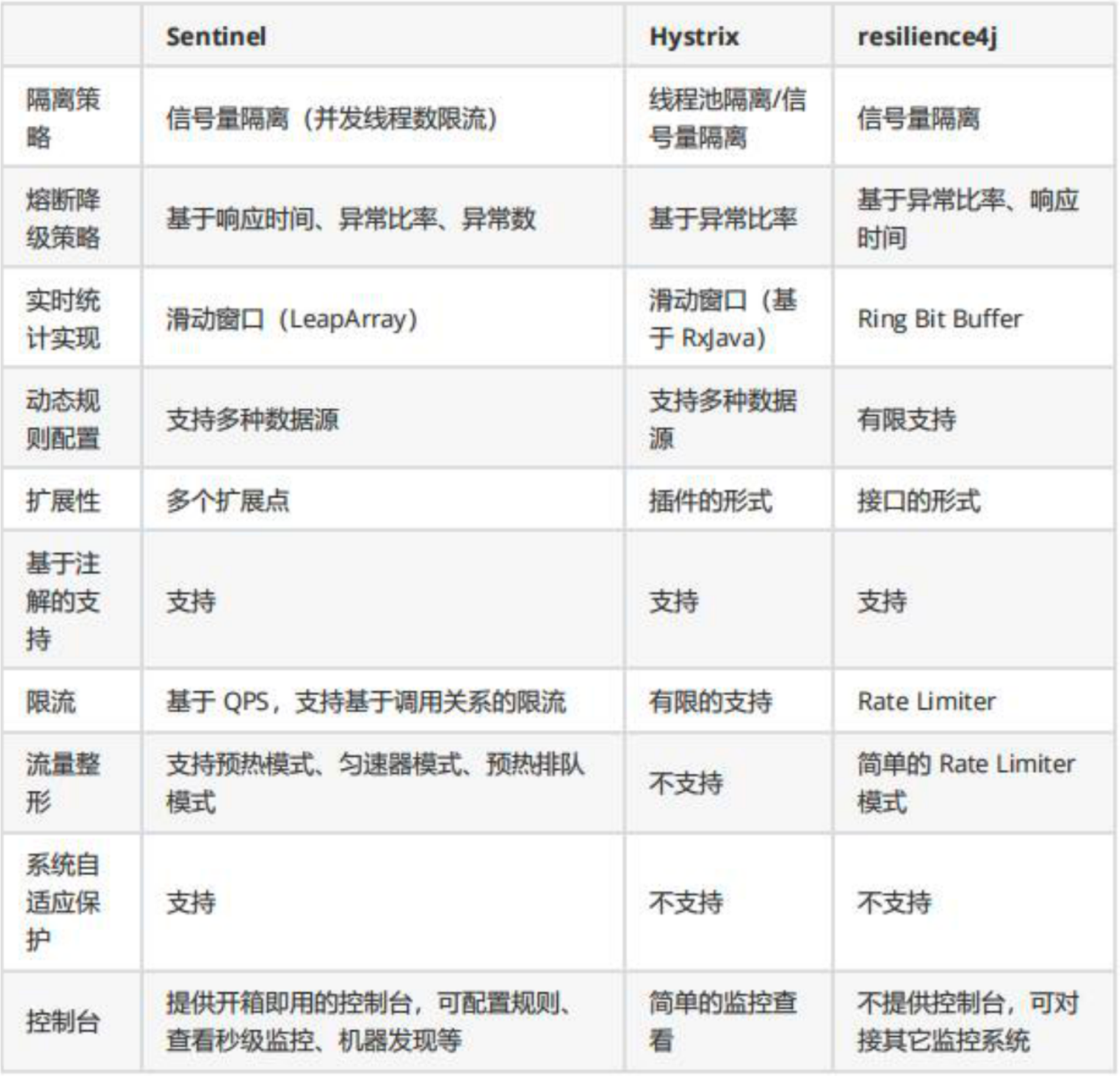
下面是三个组件的在各方面的对比:
Sentinel(分布式系统的流量方卫兵)是阿里巴巴开源的一套用于服务容错的中和解决方案。它以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来保护服务的稳定性。
Sentinel具有以下特征:
- 丰富的应用场景:Sentinel承接了阿里巴巴近10年的双十一大促流浪的核心场景,例如秒杀(即突发榴莲个控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实施熔断下游不可用应用等。
- 完备的实时监控:Sentinel提供了实时的监控功能。通过控制台可以看到接入应用的单台机器秒级数据,甚至500台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel提供了开箱即用的与其他开源框架/库的整合模块,例如与SpringCloud、Dubbo、gRPC的整合。只需要引入相应的依赖并进行简单的配置即可快速地接入Sentinel。
- 完善的SPI扩展点:Ssentinel提供了简单易用、完善的SPI扩展接口。您可以通过实现扩展接口来快速的定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel分为两个部分
- 核心库(Java客户端)不依赖任何框架、库,能够运行于所有java运行时环境,同事对Dubbo/SpringCloud 等框架也有较好的支持。
- 控制台(Dashboard)基于Spring Boot开发,打包后可以直接运行,不需要额外的tomcat等应用容器。
为微服务集成Sentinel非常的简单,只需要添加Sentinel的依赖即可
-
在pom.xml中添加下面依赖
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> -
编写一个Controller测试使用
@RestController @Slf4j public class orderCOntroller3{ @RequestMapping("/order/message1") public String message2(){ return "message1"; } @RequestMapping("/order/message2") public String message2(){ return "message2"; } }
Sentinel提供一个轻量级的控制台,它提供机器发现、单机资源实时监控以及规则管理等功能。
-
下载jar包,解压到文件夹。https://github.com/alibaba.Sentinel/releases
-
启动控制台
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-xxx.jar -
修改shop-order,在里面加入有关控制台的配置
spring: cloud: sentinel: transport: port: 9999 dashboard: localhost:8080 -
通过浏览器访问localhost:8080 进入控制台(默认用户名密码是:sentinel/sentinel)
-
补充:
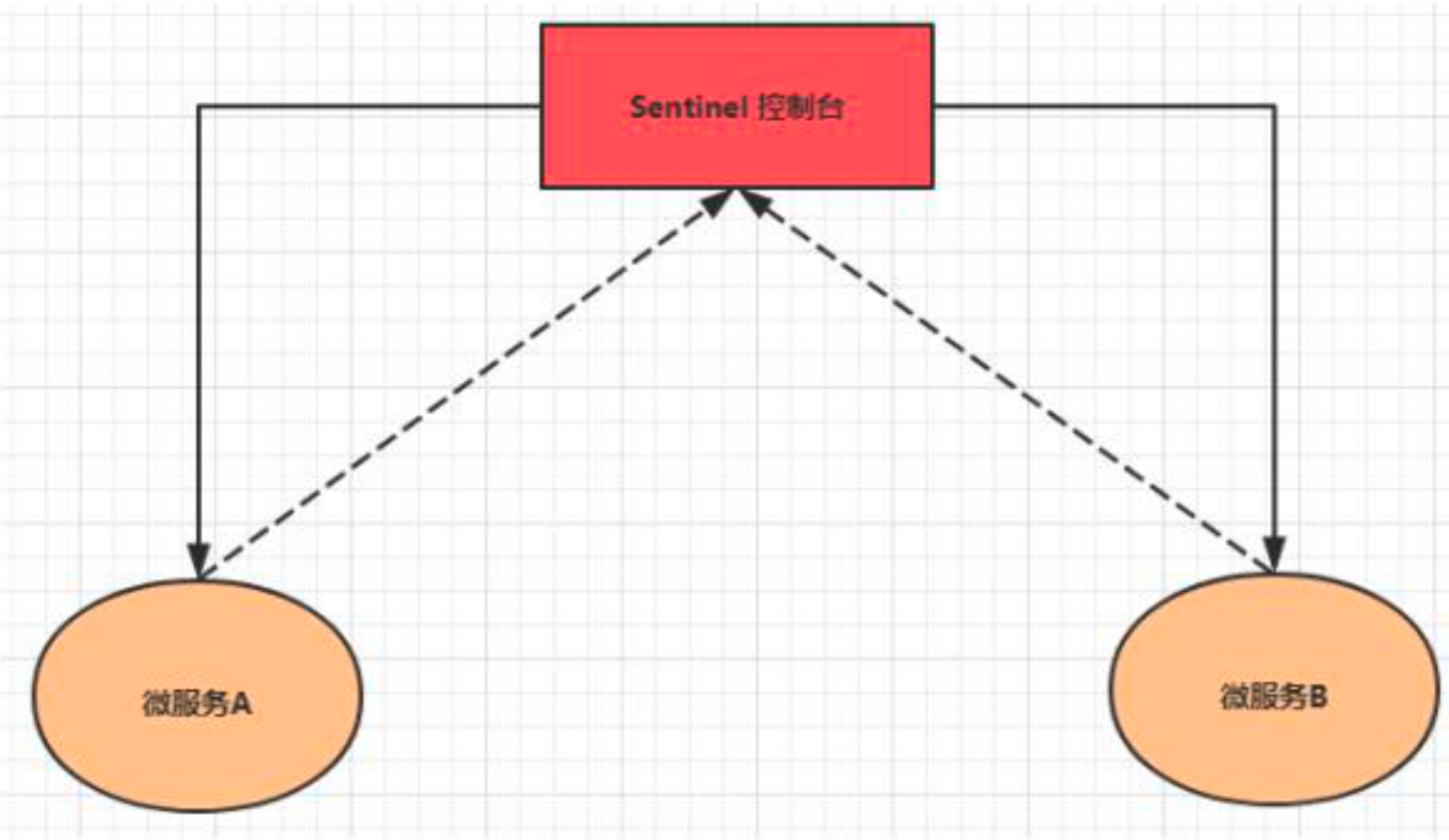
Sentinel的控制台其实就是一个Soringboot编写的程序。我们需要将我们的微服务程序注册到控制台上,即在微服务中指定控制台的地址,并且还要开一个跟控台传递数据的端口,控制台也可以通过次端口调用微服务中的监控程序获取微服务的各种信息。
- 通过控制台为message1添加一个流控规则
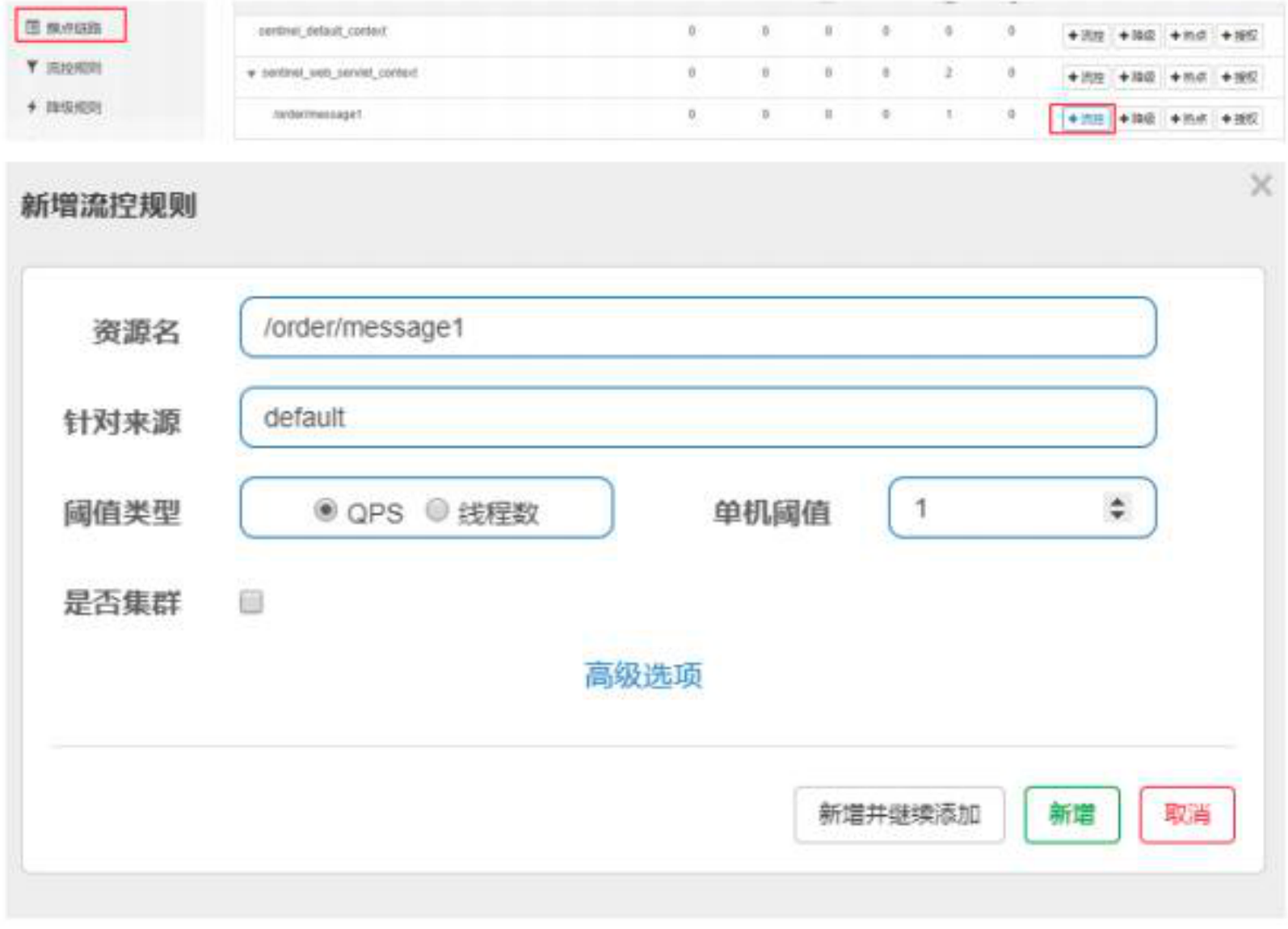
- 通过控制台快速频繁访问,观察效果

-
资源
资源就是Sentinel要保护的东西,资源是Sentinel的关键概念。它可以是java应用程序中的任何内容,可以是一个服务,也可以是一个方法,甚至是一段代码。
我们入门案例中的message1方法就可以认为是一个资源
-
规则
规则就是用来定义如何进行保护资源的,作用在资源之上,定义以什么样的方式保护资源,主要包括里流量控制规则,熔断降级规则以及系统保护规则。
我们入门案例中就是message1资源设置了一种流控规则,限制了进入message1的流量。
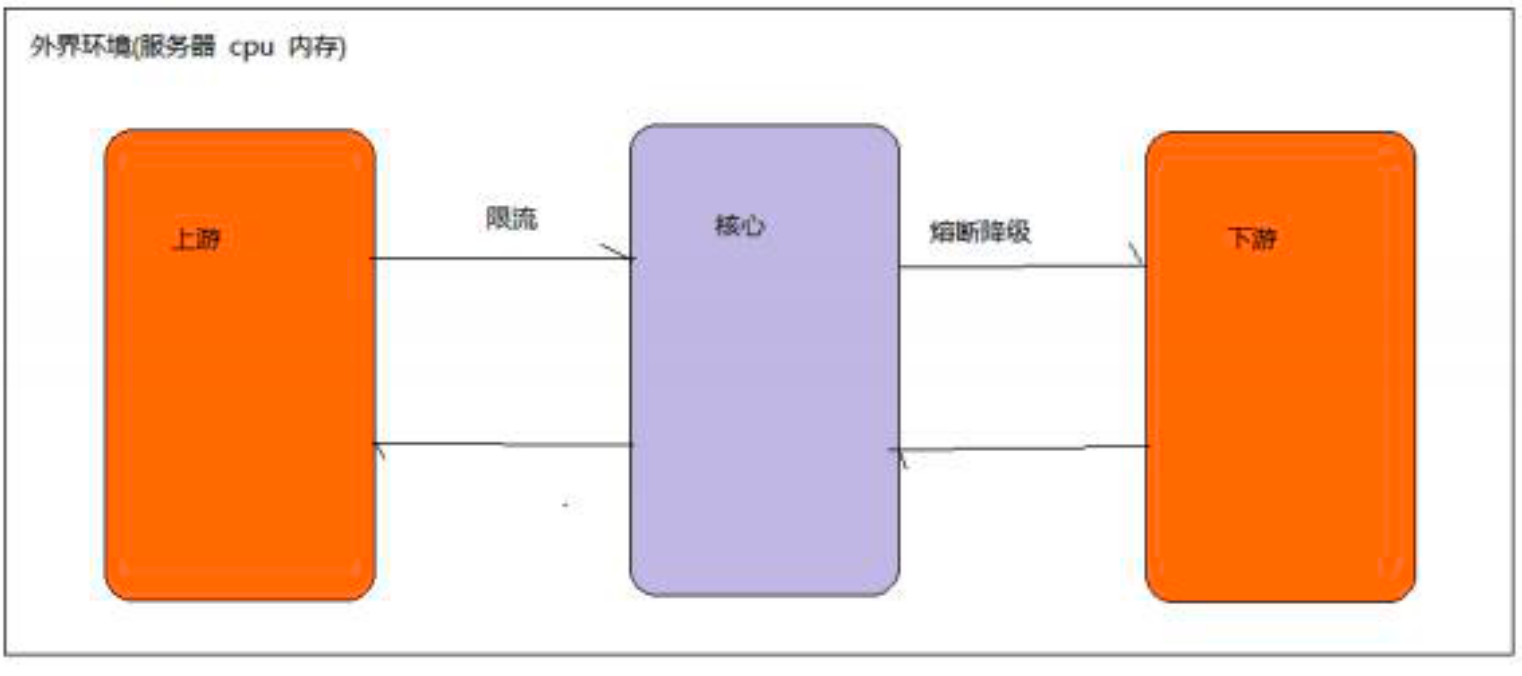
Sentinel的主要功能就是容错,主要体现为一下3个方面:
-
流量控制
流量控制在网络传输中是有一个常用的概念, 它用于调整网络包的数据,任意时间来到请求往往是随机不可控的,而系统的处理能力是有限的的,我们需要根据系统的处理能力对流量进行控制,Sentinel作为一个调配器,可以根据需要把随机的请求调整为合适的形状。
-
熔断降级
当检测到调用链路中某个资源出现不稳定的表现,例如请求响应时间长或者比例升高的时候,则对这个资源的调用进行限制,让请求快速失败,避免影响到其他的资源而导致级联故障
Sentinel对这个问题采取了两种手段
-
通过并发线程数进行控制
Sentinel通过限制资源并发线程的数量,来减少不稳定资源对其他资源的影响,当某个资源出现不稳定的情况下,例如响应时间过长,对资源的直接影响就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后,对该资源的新请求就会被拒绝。堆积的线程完成任务后才开始继续接受请求。
-
通过响应谁极爱你对资源进行降级
除了对并发线程进行控制以外,Sentinel还可以通过响应时间来快速降级不稳定的资源,当依赖对资源出现响应时间过长后,所有对改资源的访问都会被直接拒绝,知道过了指定的时间窗口之后才重新恢复。
Sentinel 和 Hystrix 的区别
两者的原则是一直的,都是当一个资源出现问题时,让其快速失败,不要波及到其他服务,但是限制的手段上,却采用了完全不一样的方法
- Hystrix 采用的是线程池隔离的方法,优点是做到了资源之间的隔离,缺点是增加了线程切换的成本
- Sentinel采用的是通过并发线程的数量和响应时间来对资源做限制
-
系统负载保护
Sentinel同事提供了系统维度的自适应保护能力,当系统负载较高的时候,如果还持续让请求进入可能会导致系统奔溃,无法响应。在集群环境下,会把本应该这台机器承载的流量转发到其他的机器上去,如果这个时候其他的机器出在一个边缘状态的时候,Sentinel提供了对应的保护机制,让系统的入口流量和系统的负载达到一个平衡,保证系统在能力范围之内处理最多的请求
总之一句话:我们需要做的事情,就是在Sentinel的资源上配置各种各样的规则,来实现各种容错的功能。