论文地址:https://graz.pure.elsevier.com/en/publications/acoustic-echo-cancellation-with-cross-domain-learning
具有跨域学习的声学回声消除 摘要:本文提出了跨域回声控制器(CDEC),提交给 Interspeech 2021 AEC-Challenge。该算法由三个构建块组成:(i) 时延补偿 (TDC) 模块,(ii) 基于频域块的声学回声消除器 (AEC),以及 (iii) 时域神经网络 (TD-NN)用作后处理器。我们的系统获得了 3.80 的整体 MOS 分数,而在 32 毫秒的系统延迟下仅使用了 210 万个参数。
关键字:声学回声消除、神经网络、残余回声消除
1 引言回声消除 (AEC) 在当今的 VoIP 语音通信和视频会议系统中发挥着重要作用。由于室内声学,在扬声器和耳机麦克风、听筒或任何其他用于语音通信的音频硬件之间会出现回声。根据房间的混响时间,声学回声可能会非常突出,甚至会显着降低语音清晰度和语音质量 [1]。这在免提场景中尤其是一个问题 [2]。因此,高效的 AEC 解决方案是可靠语音通信的重要组成部分。典型的 AEC 将扬声器和麦克风之间的回声脉冲响应 (EIR) 建模为线性 FIR 滤波器,并使用归一化最小均方 (NLMS) 算法 [3, 4] 自适应地调整该滤波器。许多实现需要语音活动检测器 (VAD) 在双方通话期间停止适应,即当近端和远端说话者同时说话时 [3,5]。更复杂的实现通过使用状态空间模型 [6] 或卡尔曼滤波器 [7] 来解释双方对话。然而,线性回声模型不能考虑回声路径中的非线性失真,或麦克风拾取的附加噪声。 SpeexDSP [8]、WebRTC [9] 或 PjSIP [10] 等商业 AEC 框架依赖于传统的非线性回声和噪声去除方法,例如 Wienerfilters [11]、Volterra 内核 [12] 或 Hammerstein 模型 [13]。
最近,已经提出神经网络用于非线性残余回声和噪声去除[14-19]。从深度学习的角度来看,这些任务可以看作是语音或音频源分离问题 [2,14,18-23]。尽管该研究领域近年来进展迅速 [24, 25],但大多数基于 NN 的说话人分离算法对计算的要求很高,没有因果关系,并且不能在实时应用中工作。能够进行实时处理的系统在逐帧的基础上运行。特别是,循环神经网络 (RNN),如门控循环单元 (GRU) [26] 或长短期记忆 (LSTM) [27] 网络用于模拟人类语音中的时间相关性,同时遵守实时典型 AEC 应用的约束 [2, 19, 28]。类似的架构 [29-31] 已应用于实时信号增强,作为对 Interspeech 2020 [32] 的深度噪声抑制挑战和 ICASSP AEC 挑战 [33] 的贡献。
本文介绍了我们对 Interspeech 2021 AEC-Challenge 的贡献,该挑战由三个级联模块组成:(i) 基于 PHAse 变换的广义互相关 (GCCPHAT) [4] 的时延补偿 (TDC) 模块,其中补偿近端扬声器和麦克风信号之间的延迟。 (ii) 一种频域状态空间块分区 AEC 算法 [6],它去除了线性回波分量。 (iii) 时域神经网络 (TD-NN),它可以同时去除非线性残余回声和附加噪声。我们将我们的系统称为跨域回声控制器 (CDEC),因为它同时在频域和时域中运行。我们模型的评估基于使用 ITU P.808 框架 [33] 的感知语音质量指标,该框架报告平均意见分数 (MOS)。此外,我们报告了其他指标,例如 MOSnet [34] 和 ERLE [35]。最后,我们还报告了我们的 CDEC 系统在每帧音频数据的 MAC 操作方面的计算复杂性。
2 提出的系统 2.1 问题表述在典型的 AEC 系统中,有两个输入信号可用: (i) 远端麦克风信号 x(t),由本地扬声器播放。 (ii) 近端麦克风信号 d(t),可描述为以下分量的叠加:
\[ d(t)=x\left(t-\Delta_{t}\right) * h(t)+s(t)+n(t)+v(t) (1) \]其中 \(h(t)\) 表示近端扬声器和近端麦克风之间的 EIR,\(s(t)\) 是所需的近端扬声器,$n(t) $ 是近端麦克风位置处的一些附加噪声, \(v(t)\) 是由扬声器或放大器中的非线性失真引起的残余回声。远端信号 \(x(t)\) 和 EIR \(h(t)\) 的卷积由\(*\)运算符表示。请注意,远端信号延迟了未知的时间延迟\(\Delta_{t}\),这是由相应通信设备的音频前端的延迟引起的。音频驱动程序可能会引入进一步的延迟,该驱动程序通常使用中断驱动的音频数据块处理。在现代声音服务器上,此延迟可以调整并由内核控制。但是,由于多任务操作系统中的高系统负载,它可能会发生变化。图 1 显示了远端和近端所涉及的信号,以及我们为近端提出的跨域回波控制器 (CDEC)。它由三个模块组成:(i)基于 GCC-PHAT 的时延补偿(TDC),(ii) 频域状态空间块分区 AEC,以及 (iii) 时域后处理神经网络 (TD-NN)。下面,我们将详细介绍这三个模块。
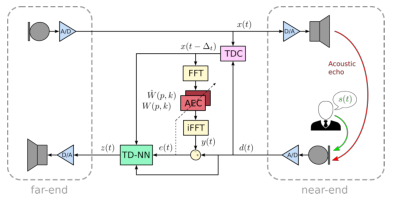
图 1:跨域回声控制器 (CDEC) 的结构。
通常,AEC 能够将远端信号 \(x(t)\) 和近端信号 \(d(t)\) 之间的时间延迟\(\Delta_{t}\)建模为滤波器权重中的前导零。然而,更实际的做法是在 AEC 之前明确补偿此延迟,以保持建模的 EIR 较短,从而节省计算资源。虽然这种延迟可能是未知的,但我们坚持通常在实时音频处理框架中做出的假设 [8-10]。特别是,我们假设延迟不超过1s,并且至少稳定10s。
我们采用 GCC-PHAT 算法 [4] 在频域中比较远端信号\(x(t)\)和近端信号\(d(t)\),即我们将互相关\(\Phi(l, k)\)评估为
\[ \Phi(l, k)=\Phi(l, k) \alpha+(1-\alpha) X(l, k) D(l, k)^{*} (2) \]其中\(X(l, k)\)和\(D(l, k)\)分别表示信号\(x(t)\)和\(d(t)\)的频域表示。时间帧用 \(l\) 表示,频率窗口用 \(k\) 表示。平滑常数\(\alpha\)决定了准确度和对时间延迟\(\Delta_{t}\)突然变化的反应时间之间的权衡。该时间滞后估计为
\[ \Delta_{t}=\underset{t}{\operatorname{argmax}} \mathcal{F}^{-1} \frac{\Phi(l)}{|\Phi(l)|} (3) \]其中\(\mathcal{F}^{-1}\)表示逆 FFT,\(\Phi(l)=[\Phi(l, 1), \ldots, \Phi(l, K)]^{T}\),并且 \(K\) 是频率窗口的数量。在\(f_{s} = 16\)kHz 时,1s 的最大延迟补偿相当于所需的 FFT 大小为 16384 点。
2.3 AEC模块对于时间对齐的信号\(x\left(t-\Delta_{t}\right)\)和\(d(t)\),我们采用频域状态空间块分区 AEC 算法 [6],它操作块\(\boldsymbol{x}^{\prime}(l)\)和\(d^{\prime}(l)\)分别为近端扬声器和麦克风信号。每个块使用各自时域信号的最新 \(2T\) 最新样本,即
\[ \begin{aligned} &\boldsymbol{x}^{\prime}(l)=x(t+n-2 T) \\ &\boldsymbol{d}^{\prime}(l)=d(t+n-2 T) (4) \end{aligned} \]其中\(n=\{0 \ldots 2 T-1\}\),
请注意,为了简化符号,我们使用 \(t\) 作为离散时间索引。块重叠 50%,或时域中的 \(T\)个样本。 AEC 将一个可能很长的回波尾分成 \(P\) 个分区,即
\[ \begin{aligned} Y(l, k) &=\sum_{p=0}^{P-1} X(l-p, k) W(p, k) \\ e^{\prime}(l) &=\boldsymbol{d}^{\prime}(l)-\mathcal{F}^{-1}\{\boldsymbol{Y}(l)\} \end{aligned} (5) \]其中\(W(p, k)\)表示滤波器权重的第\(p\)个块。时域块\(e^{\prime}(l)\)表示第 \(l\) 个时间帧的残差信号。为了避免混叠伪影,使用了重叠保存方法 [4]。特别是,只有最后的 \(T\) 个样本(即最近的样本)用于重建时域残差信号 \(e(t)\),即
\[ e(t+n-T)=e^{\prime}(l, n+T) (6) \]其中,\(n=\{0 \ldots T-1\}\),因此,AEC 的总体系统延迟为 \(T\) 个样本,而与使用的分区 \(P\) 的数量无关。为了模拟长达 0.25 秒的回声尾,我们在式5中使用 \(P = 16\) 个块。为了避免滤波器权重中的混叠,时域权重的每个块的最后 \(T\) 个样本是零填充的,即
\[ \begin{aligned} \boldsymbol{w}(p) &=\mathcal{F}^{-1}\{\boldsymbol{W}(p)\}, \\ w(p, n+T) &=0 \\ \boldsymbol{W}(p) & \leftarrow \mathcal{F}\{\boldsymbol{w}(p)\} \end{aligned} (7) \]其中,\(n=\{0 \ldots T-1\}\),
滤波器权重\(W(p, k)\)的更新规则可以在 [6] 中找到。为了解释由自发音量变化或近端扬声器突然移动引起的 EIR 突然变化,我们使用第二组滤波器权重\(\hat{W}(p, k)\)作为阴影权重。算法 1 说明了这些权重是如何更新的。

阴影权重基于 ERLE \(\mathcal{E}(l)\)更新,对前景权重\(W(p, k)\)和阴影权重\(\hat{W}(p, k)\)进行连续评估,即
\[ \begin{gathered} \mathcal{E}(l)=10 \log _{10} \frac{\sum_{k}|D(l, k)|^{2}}{\sum_{k}|E(l, k)|^{2}} \\ \hat{\mathcal{E}}(l)=10 \log _{10} \frac{\sum_{k}|D(l, k)|^{2}}{\sum_{k}|\hat{E}(l, k)|^{2}} \end{gathered} (8) \]其中\(D(l, k), E(l, k)\)和\(\hat{E}(l, k)\) 分别是\(\boldsymbol{d}^{\prime}(l), \boldsymbol{e}^{\prime}(l)\)和\(\hat{e}^{\prime}(l)\)的 FFT。块\(\hat{e}^{\prime}(l)\)是通过将阴影权重\(\hat{W}(p, k)\)插入到等式5中获得的。算法1中的更新规则保证了每一帧都使用ERLE最高的权重。因此,AEC 能够快速重新适应最后一个已知的好过滤器权重。
2.4 TD-NN模块考虑式1的系统模型中的非线性残余回波 v(t) 和附加噪声 n(t)。我们在时域中使用一个小型神经网络。与 AEC 类似,它对 \(T\) 个样本块进行操作,重叠率为 50%。图 2 说明了时域神经网络 (TDNN) 的结构。上面的分支在潜在空间中推导出一个掩码 $m(l) $。特别是,掩码估计分支使用内核大小为 \(F = 1600\) 个样本且步幅为 \(S = 128\) 个样本的 Conv1D 层来转换四个信号 \(x(t)\)、\(y(t)\)、\(d(t)\) 和 $e (t) $ 转化为每个信号具有 \(H\) 个神经元的潜在表示。请注意,此 Conv1D 层使用过去 1600 个相应信号的样本,即它看到过去 100 毫秒音频数据的上下文。每个信号都通过即时层归一化单独归一化,以解决各个级别的变化。即时层归一化类似于标准层归一化[36]。该分支中的最后一个前馈 (FF) 层使用 softplus 激活函数,以提供不受约束的掩码。
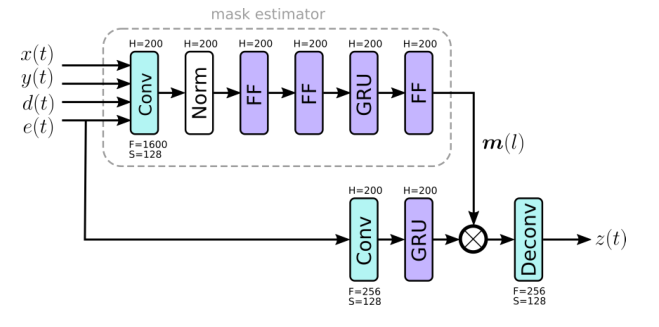
图 2 中的下部分支说明了将掩码应用于潜在空间中的残差信号 \(e(t)\)。在那里,Conv1D 层使用 \(F = 256\) 个样本的内核大小和 \(S = 128\) 个样本的步幅来产生 \(H = 200\) 个神经元的潜在空间。掩码 \(m(l)\) 与 GRU 层获得的潜在表示相乘。最后,使用 Conv1D Transpose 层来预测增强的时域输出 \(z(t)\)。它使用与 Conv1D 层相同的参数,即 \(F = 256\) 和 \(S = 128\)。信号重建是通过重叠相加方法 [4] 实现的,它占 \(F + S\) 样本的总前瞻。
3 实验 3.1 数据集AEC 挑战赛提供来自 2,500 多个音频设备和真实环境中的人类扬声器的录音。它涵盖了以下三种场景:近端单讲(NE)、远端单讲(FE)和双讲(DT)。对于训练,提供了两个数据集,真实记录和合成示例 [33]。合成数据集提供了 10,000 个示例,分别代表单讲、双讲、近端噪声、远端噪声和各种非线性失真情况。真实数据集提供了超过 37,000 条单讲和双讲记录,包括和不包括回声路径变化、背景噪声和非线性失真。为了使用 P. 808 框架进行评估,挑战组织者提供了一个包含 800 条话语的测试集。测试集分为三个场景,即NE、FE和DT。
3.2 数据增强为了得到训练的基本事实,我们只使用远端单对话文件,其中合成数据集中有 10,000 个,真实数据集中有 7,282 个。特别是,我们只使用远端 \(x(t)\) 和近端 \(d(t)\) 信号对,其中\(d(t)>-40 d B_{F S}\)的平均能量。否则信号被拒绝。
我们通过将干净的 WSJ0 数据 [37] 作为所需的近端语音 \(s(t)\) 混合到近端麦克风信号 \(d(t)\) 中来生成双向通话示例。我们从\(-6 \ldots 6 dB\)之间的均匀分布中随机选择回声和所需语音信号 \(s(t)\) 之间的信干比 (SIR)。为了考虑到训练数据中不同麦克风的种类繁多,我们使用 20 波段均衡器执行随机频谱整形,其中\(-12 \ldots 12 dB\)之间均匀分布的增益应用于每个单独的频段。
为了模拟加性噪声,我们使用来自 YouTube 的 20 种不同声音类别的 20 小时作为噪声信号 \(n(t)\)。加性噪声的 SNR 从\(12 \ldots 36 dB\)之间的均匀分布中随机选择。噪声仅添加到模拟数据集中。
为了进一步提高鲁棒性并模拟各种传输效果,我们在模拟数据集的每个远端信号 \(x(t)\) 中引入了单个人工延迟变化。延迟变化是从\(-20 \ldots 0 ms\)之间的均匀分布中随机选择的。这会导致 AEC 在每个话语期间重新适应。此外,为了反映测试数据中的突然幅度变化,我们通过从\(-20 \ldots 0 dB\)范围内的均匀分布增益衰减随机选择的麦克风信号 \(d(t)\) 的三分之一。最后,为了模拟削波伪影,我们以从\(-12 \ldots 0 dB\)范围内随机选择的幅度对麦克风信号进行削波。真实的数据集已经具有移动扬声器、附加噪声和一定量的非线性失真的特征。
通过这种设置,我们为三种场景(即 NE、FE 和 DT)中的每一种生成了 15,000 个信号对 \(x(t)\)、\(d(t)\)。我们将每个信号截断为 10 秒,以便能够将它们堆叠成批次进行训练。
3.3 CDEC训练在训练期间,我们首先使用式2中的 GCCPHAT 估计批量延迟。 每 10 秒一次,即每个训练话语一次。接下来,我们从式5-8执行 AEC。输出回波模型 \(y(t)\) 和残余信号 \(e(t)\)。根据非线性失真和附加噪声的数量,残差已经接近所需的近端语音 \(s(t)\)。如图 2 所示,我们使用四个信号 \(x(t)\)、\(y(t)\)、\(d(t)\) 和 \(e(t)\) 作为特征向量,将期望信号 \(s(t)\)作为目标向量。对于 NE 和 DT 场景,我们使用 SDR 作为成本函数,即
\[ \mathcal{L}_{\mathrm{SDR}}=10 \log _{10} \frac{\sum_{t} s(t)^{2}}{\sum_{t}[s(t)-z(t)]^{2}} (9) \]而我们使用 ERLE 作为 FE 场景的损失函数,即
\[ \mathcal{L}_{\mathrm{ERLE}}=10 \log _{10} \frac{\sum_{t} d(t)^{2}}{\sum_{t} z(t)^{2}} (10) \]我们将总损失函数定义为
\[ \mathcal{L}_{\mathrm{ERLE}}=-\mathcal{L}_{\mathrm{SDR}}-\lambda \mathcal{L}_{\mathrm{ERLE}} (11) \]我们设置\(\lambda=0.5\)。我们从三个场景 NE、FE 和 DT 中随机选择 40 个话语,概率为\(p_{N E}=0.25, p_{F E}=0.25\)以及 \(p_{D T}=0.5\)。
3.4 客观和主观的音频质量评估在存在混响、加性噪声和非线性失真的情况下,诸如语音质量感知评估 (PESQ) 等传统客观指标与主观语音质量测试的相关性并不好。因此,在 Amazon Mechanical Turk 平台上进行了基于 ITU P.808 众包框架 [33] 的研究。总共评估了四种场景:单讲近端(P.808)、单讲远端(P.831)、双方回声(P.831)和双方对话其他干扰(P.831)。我们评估了 ITU-T P.831 [38] 中定义的失真 MOS (DMOS) 和回声 MOS (EMOS)。有关评级过程的更多详细信息,请参见 [33]。此外,为了更好地了解 CDEC 的性能,我们还采用了额外的指标,例如 MOSnet [34] 和 ERLE [35]。
4 结果 4.1 客观和主观质量得分表1显示了使用挑战组织者提供的评估脚本获得的结果 [33]。可以看出,CDEC 大大提高了 DT 和 FE 场景的 EMOS 分数。然而,在 DT 和 NE 场景中 DMOS 分数的提高并不显著。
表 1:盲测集的 DMOS 和 EMOS 分数。

表 2 显示了 FE 场景的 ERLE,以及 DT 和 NE 场景的 MOSnet 分数。请注意,MOSnet 只需要增强波形即可获得分数 [34]。对于 FE 场景,可以看出与仅使用 AEC 相比,CDEC 系统极大地改进了 ERLE。对于 NE 和 DT 场景,CDEC 系统达到与 AEC 相同的 MOS。这表明 CDEC 在去除残余回声和其他干扰的同时保持了高精度的语音质量。
表 2:盲测集的 MOSnet 和 ERLE 分数。
 4.2 整体系统延迟
4.2 整体系统延迟
为了遵守挑战规则,CDEC 系统在大小为 \(T = 256\) 个样本的帧上运行。 TDC 模块连接 64 帧以使用式3计算延迟\(\Delta_{t}\)。每 10 秒一次。因此,TDC 模块的延迟在\(f_{s}=16 \mathrm{kHz}\)时等于 16ms。 AEC 模块对 \(2T\) 样本块进行操作,这些样本是通过连接 \(x(t)\) 和 \(d(t)\) 的两个最近帧获得的,如式4所示。由于重叠保存操作,它输出残差 \(e(t)\) 的最新帧,如第 2.3 节所述。因此,AEC 具有相同的 16 毫秒延迟。 TD-NN 模块对大小为 \(F = T = 256\) 个样本的单帧进行操作,步幅为 \(S = 128\) 个样本。反卷积层使用overlapadd方法,它需要两个输出帧存在,以便将它们移位并加在一起以获得最终的输出信号\(z(t)\)。因此,TD-NN 的延迟是 \(2T\) 个样本,相当于 32ms。由于所有三个模块都在相同的块上运行,因此 CDEC 系统的总延迟为 32 毫秒。
4.3 计算复杂度CDEC 模型的计算复杂度在四核 i5 2.5Ghz 参考系统上进行了评估。特别是,我们使用矩阵/向量库 Eigen 和 FFT 库 FFTW [39] 使用 C++ 中的单精度参考实现测量了 CDEC 系统前向传递的单帧的执行时间。 TD-NN 系统使用 210 万个参数,而 AEC 使用\(2 P \cdot 2 T=16384\)个复值滤波器权重,包括阴影权重。一个推理步骤每帧需要 228 us。特别是,TDC 模块需要 0.16 us,AEC 32.88 us 和 DNN 195 us 处理单帧。请注意,TDC 模块每 10 秒执行一次,因此它对单帧执行时间的贡献相当小。 CDEC 系统的整体执行时间是使用单个 CPU 时每 1 秒音频的 28.8 毫秒。在 XNNPACK的帮助下进行多线程执行的情况下,运行时间可以减少到 19.6 毫秒,处理一秒的音频。该模型可以使用稀疏格式和剪枝进一步缩小。此外,定点表示的使用大大降低了内存消耗和计算复杂度,如 [40] 所示。表 3 显示了 CDEC 模型的计算复杂度。
表 3:单精度 CDEC 模型的计算复杂度,在四核 i5 2.5GHz 参考系统上测量。
 5 结论
5 结论
我们展示了我们的跨域回声控制器 (CDEC)——一种为 2021 年语音间 AEC 挑战赛开发的实时 AEC 系统。该系统由三个模块组成,即延时补偿 (TDC) 模块、基于频域模块的声学回声消除器 ( AEC) 和时域神经网络 (TD-NN)。使用 ITU P.808 众包框架对 CDEC 进行了单声道和双声道回声场景的评估。特别是,它使用具有 2.1M 参数的模型报告了 3.80 的平均 MOS 分数。整个系统的整体延迟为 32ms,在 2.5 Ghz 四核 i5 系统上实时系数为 0.0288。
6 参考文献[1] H. Kuttruff, Room Acoustics, 5th ed. London–New York: Spoon Press, 2009.
[2] L. Pfeifenberger and F. Pernkopf,“Nonlinear Residual Echo Suppression Using a Recurrent Neural Network,” in Proc. Interspeech 2020, 2020, pp. 3950–3954.
[3] S. Haykin, Adaptive Filter Theory, 4th ed. New Jersey: Prentice Hall, 2002.
[4] J. Benesty, M. M. Sondhi, and Y. Huang, Springer Handbook of Speech Processing. Berlin–Heidelberg–New York: Springer,2008.
[5] G. Enzner, H. Buchner, A. Favrot, and F. Kuech,“Chapter 30 acoustic echo control,” in Academic Press Library in Signal Processing: Volume 4, ser. Academic Press Library in Signal Processing, J. Trussell, A. Srivastava, A. K. Roy-Chowdhury, A. Srivastava, P. A. Naylor, R. Chellappa, and S. Theodoridis, Eds. Elsevier, 2014, vol. 4, pp. 807–877.
[6] F. Kuech, E. Mabande, and G. Enzner,“State-space architecture of the partitioned-block-based acoustic echo controller,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014, pp. 1295–1299.
[7] C. Wu, X. Wang, Y. Guo, Q. Fu, and Y. Yan,“Robust uncertainty control of the simplified kalmanfilter for acoustic echo cancelation,” Circuits, Systems, and Signal Processing, vol. 35, no. 12,pp. 4584–4595, 2016.
[8] “Speex-dsp,” Website, visited on February 19th 2020. [Online].Available: https://github.com/xiongyihui/speexdsp-python
[9] “Webrtc toolkit,” Website, 2011, visited on March 14th 2021.[Online]. Available: https://webrtc.org/
[10] “PjMedia– acoustic echo cancellation api.” Website, 2008, visited on March 13th 2021. [Online]. Available: https://www.pjsip.org/pjmedia/docs/html/group PJMEDIA Echo Cancel.htm
[11] H. Huang, C. Hofmann, W. Kellermann, J. Chen, and J. Benesty,“A multiframe parametric wienerfilter for acoustic echo suppression,” in IEEE International Workshop on Acoustic Signal Enhancement (IWAENC), 2016, pp. 1–5.
[12] F. Kuech and W. Kellermann,“A novel multidelay adaptive algorithm for volterrafilters in diagonal coordinate representation [nonlinear acoustic echo cancellation example],” in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), vol. 2, 2004, pp. ii–869.
[13] S. Malik and G. Enzner,“Fourier expansion of hammerstein models for nonlinear acoustic system identification,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2011, pp. 85–88.
[14] C. M. Lee, J. W. Shin, and N. S. Kim,“Dnn-based residual echo suppression,” in Interspeech, 2015.
[15] T. V. Huynh,“A new method for a nonlinear acoustic echo cancellation system,” in International Research Journal of Engineering and Technology, vol. 4, 2017.
[16] H. Zhang and D. Wang,“Deep learning for acoustic echo cancellation in noisy and double-talk scenarios,” in Interspeech, 2018,pp. 3239–3243.
[17] G. Carbajal, R. Serizel, E. Vincent, and E. Humbert,“Multiple-input neural network-based residual echo suppression,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 231–235.
[18] G. Carbajal, R. Serizel, E. Vincent, and E. Humbert,“Joint dnn based multichannel reduction of acoustic echo, reverberation and noise,” CoRR, vol. abs/1911.08934, 2019.
[19] Q. Lei, H. Chen, J. Hou, L. Chen, and L. Dai,“Deep neural network based regression approach for acoustic echo cancellation,”in International Conference on Multimedia Systems and Signal Processing (ICMSSP). New York, NY, USA: Association for Computing Machinery, 2019, p. 94–98.
[20] L. Pfeifenberger, M. Zöhrer, and F. Pernkopf,“Eigenvector-based speech mask estimation for multi-channel speech enhancement,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 12, pp. 2162–2172, 2019.
[21] L. Pfeifenberger, M. Zöhrer, and F. Pernkopf,“Dnn-based speech mask estimation for eigenvector beamforming,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, Mar. 2017, pp. 66–70.
[22] H. Zhang, K. Tan, and D. Wang,“Deep learning for joint acoustic echo and noise cancellation with nonlinear distortions,” Interspeech, pp. 4255–4259, 2019.
[23] A. Fazel, M. El-Khamy, and J. Lee,“CAD-AEC: context-aware deep acoustic echo cancellation,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).IEEE, 2020, pp. 6919–6923.
[24] J. R. Hershey, Z. Chen, J. Le Roux, and S. Watanabe,“Deep clustering: Discriminative embeddings for segmentation and separation,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 31–35.
[25] M. Kolbak, D. Yu, Z. Tan, and J. Jensen,“Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 10, pp. 1901–1913, 2017.
[26] J. Chung, C¸ . Gülc¸ehre, K. Cho, and Y. Bengio,“Empirical evaluation of gated recurrent neural networks on sequence modeling,”CoRR, vol. abs/1412.3555, 2014.
[27] S. Hochreiter and J. Schmidhuber,“Long short-term memory,”Neural Computation, vol. 9, no. 8, p. 1735–1780, 1997.
[28] L. Ma, H. Huang, P. Zhao, and T. Su,“Acoustic echo cancellation by combining adaptive digitalfilter and recurrent neural network,”CoRR, vol. 2005.09237, 2020.
[29] J.-M. Valin, U. Isik, N. Phansalkar, R. Giri, K. Helwani, and A. Krishnaswamy,“A perceptually-motivated approach for lowcomplexity, real-time enhancement of fullband speech,” CoRR,vol. 2008.04259, 2020.
[30] Y. Hu, Y. Liu, S. Lv, M. Xing, S. Zhang, Y. Fu, J. Wu, B. Zhang,and L. Xie,“Dccrn: Deep complex convolution recurrent network for phase-aware speech enhancement,” CoRR, vol. 2008.00264,2020.
[31] N. L. Westhausen and B. T. Meyer,“Dual-signal transformation lstm network for real-time noise suppression,” CoRR, vol.2005.07551, 2020.
[32] C. K. A. Reddy, V. Gopal, R. Cutler, E. Beyrami, R. Cheng,H. Dubey, S. Matusevych, R. Aichner, A. Aazami, S. Braun,P. Rana, S. Srinivasan, and J. Gehrke,“The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results,” 2020.
[33] K. Sridhar, R. Cutler, A. Saabas, T. Parnamaa, M. Loide, H. Gamper, S. Braun, R. Aichner, and S. Srinivasan,“Icassp 2021 acoustic echo cancellation challenge: Datasets, testing framework, and results,” CoRR, vol. 2009.04972, 2020.
[34] C.-C. Lo, S.-W. Fu, W.-C. Huang, X. Wang, J. Yamagishi,Y. Tsao, and H.-M. Wang,“Mosnet: Deep learning based objective assessment for voice conversion,” CoRR, vol. 1904.08352,2019.
[35] I. T. Union,“Itu-t g.168: Digital network echo cancellers.” 2012.[Online]. Available: https://www.itu.int/rec/T-REC-G.168/en
[36] J. L. Ba, J. R. Kiros, and G. E. Hinton,“Layer normalization,”CoRR, vol. 1607.06450, 2016.
[37] D. B. Paul and J. M. Baker,“The design for the Wall Street Journal-based CSR corpus,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Banff, 1992,pp. 899–902.
[38] I. T. Union,“Subjective performance evaluation of network echo cancellers,” 1998. [Online]. Available: https://www.itu.int/rec/T-REC-P.831/en
[39] M. Frigo and S. G. Johnson,“The design and implementation of FFTW3,” Proceedings of the IEEE, vol. 93, no. 2, pp. 216–231,2005, special issue on“Program Generation, Optimization, and Platform Adaptation”.
[40] J.-M. Valin, S. Tenneti, K. Helwani, U. Isik, and A. Krishnaswamy, “Low-complexity, real-time joint neural echo control and speech enhancement based on percepnet,” CoRR, vol.2102.05245, 2021.