哈希表是一种根据关键字key来访问值value的一种数据结构。
哈希表的本质是数组加哈希函数。数组不难理解,那什么是哈希函数?
在哈希表中,它的作用就是将哈希表的某个key作为输入,然后经过一系列的运算后,得到数组的某
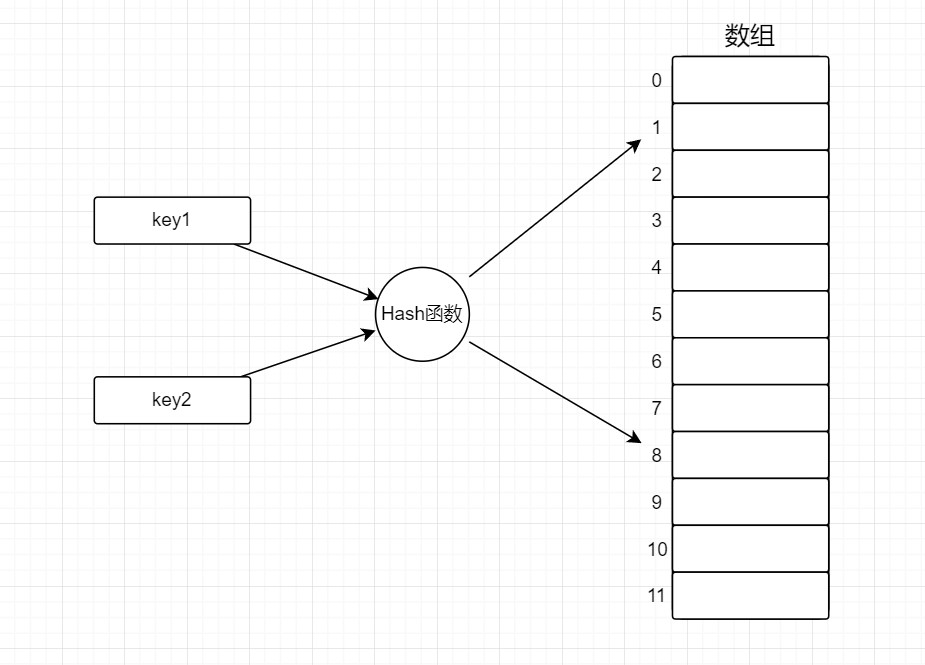
个索引。一种很朴素的思路是,先用key计算出一个很大的数,然后对数组长度取模,从而得到索引,这只是众多方法中的一种,其他的比如:直接寻址法,平方取中法等。
得到索引后就可以通过索引对数组执行插入或查找的操作,因为本质上是通过索引来访问数组,所以哈希表的插入和查找的效率非常高,时间复杂度都是O(1)。
我们不难发现哈希函数是整个哈希表的关键。所以为了更好的性能,我们希望在尽可能短的时间内,相同的key经过哈希函数的计算,可以得到相同的索引,不同的key经过哈希函数的计算,可以得到不同的索引,但在实际中往往事与愿违,不同的key小概率会计算出相同的索引,这就是哈希冲突(collision),几乎所有的哈希函数都存在这个问题。
这里介绍几个常见的解决哈希冲突的方法:
开放寻址法开放寻址是一种思想,如果通过哈希函数计算出的索引所对应的空间已经被占用了,就再找一个还没被占用的空间将数据存进去。
常见的体现开放寻址思想的方法:
- 线性探测法:简单来说就是从当前被占用的空间的索引开始,向下遍历整个数组,直到找到空闲空间为止。如下图所示:
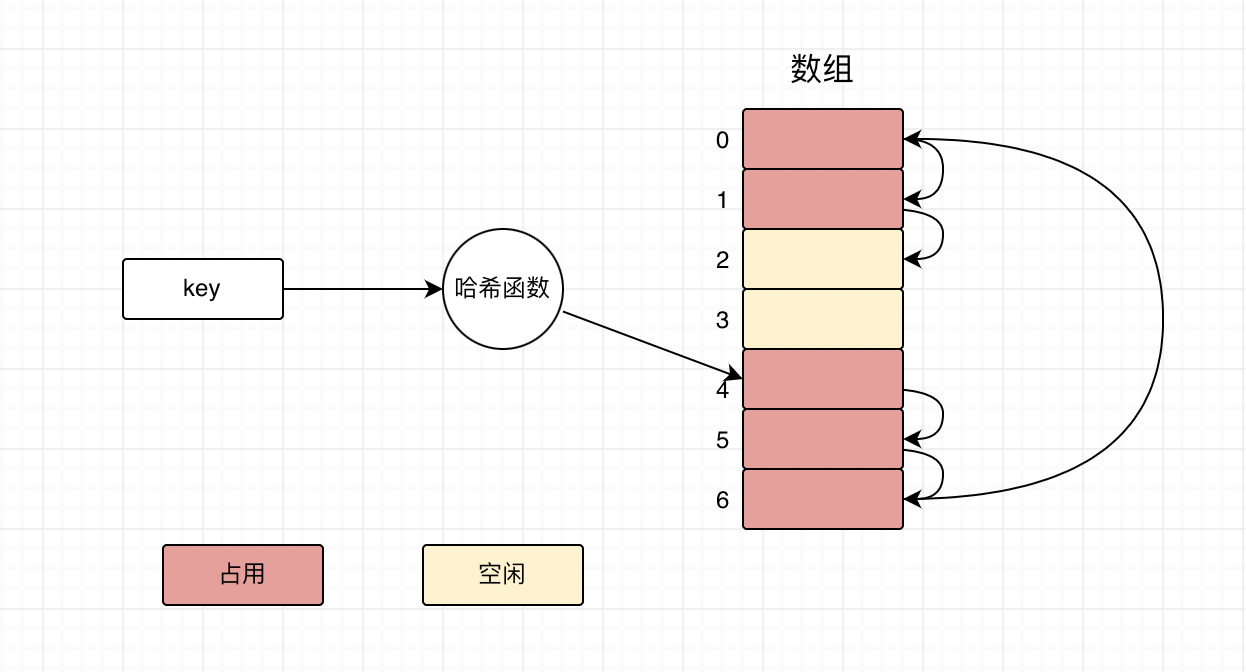
- 双重哈希法:使用多个哈希函数来计算索引,如果第一个哈希函数计算得到的索引所对应的空间已被占用,就用第二个,第二个被占用就用第三个,以此类推,直到计数出没被占用的空间对应的索引。
链表法是一种更加常见的解决哈希冲突的方法,Java中的HashMap就是采用这种方法。在这种方法中,数组索引对应的空间并不直接存储数据,而是存储一个链表的地址,而数据存在链表中。如下图所示:
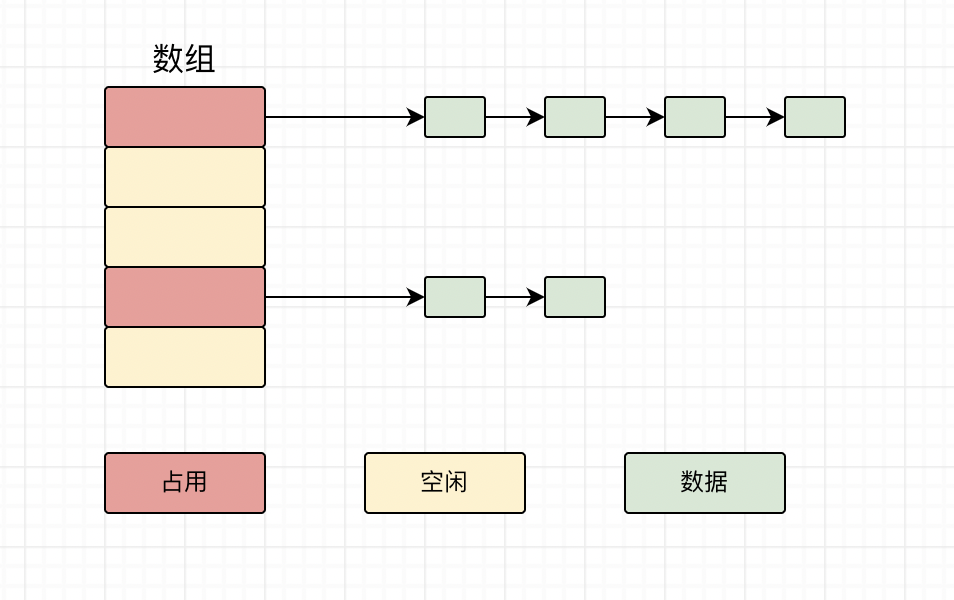
这样发生冲突时,就可将冲突的key对应的数据存在同一个链表上,当需要取数据时,就先找到key对应的链表,然后遍历链表。
上面说的方法只能在一定程度上解决哈希冲突,因为毕竟数组的容量有限,当频繁插入数据时,因为数组的容量有限,所以就会使哈希冲突加剧,进而使链表的长度增加,链表的长度增加,就会使得查找的性能降低,这不是我们想看到的结果,所以要对数组扩容。
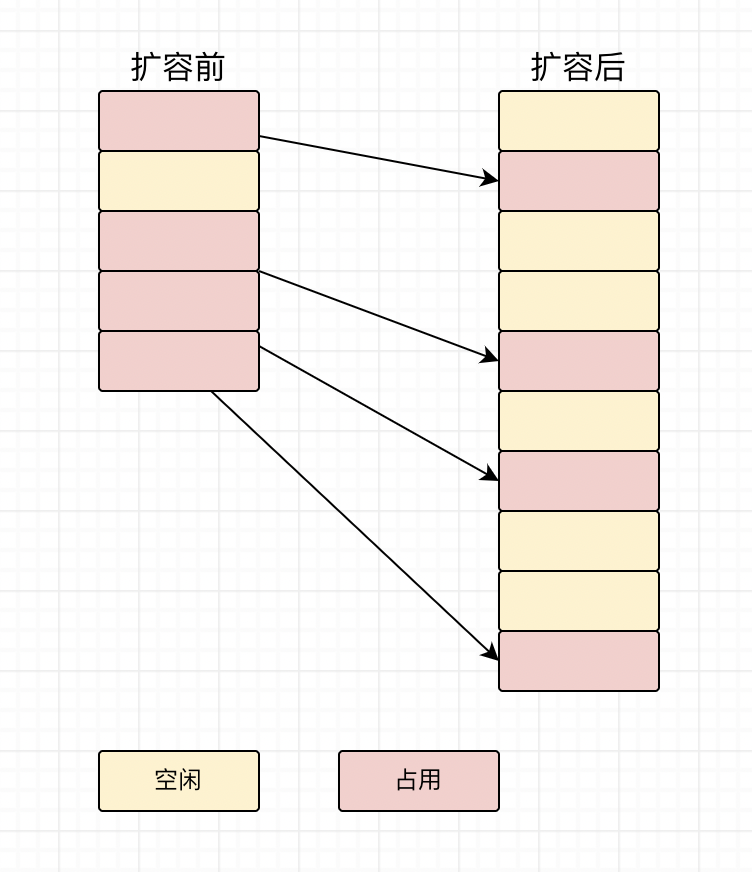
那什么时候给数组扩容呢?装载因子(已插入元素的数量除以数组容量)超过某一阈值时就进行扩容,Java中HashMap的装载因子是0.75,当然,也可以是别的值。因为之前插入的元素都是按照原数组的长度来计算索引的,所以一旦数组扩容后,长度改变,就要重新进行计算,然后将已插入的元素移动到新的位置上,所以数组扩容不仅仅只是将容量增大而已。