HBase是Hadoop Database的简称,是建立在Hadoop文件系统之上的分布式面向列的数据库,它具有高可靠、高性能、面向列和可伸缩的特性,提供快速随机访问海量数据能力。
HBase采用Master/Slave架构,由HMaster节点、RegionServer节点、ZooKeeper集群组成,底层数据存储在HDFS上。
整体架构如图所示:
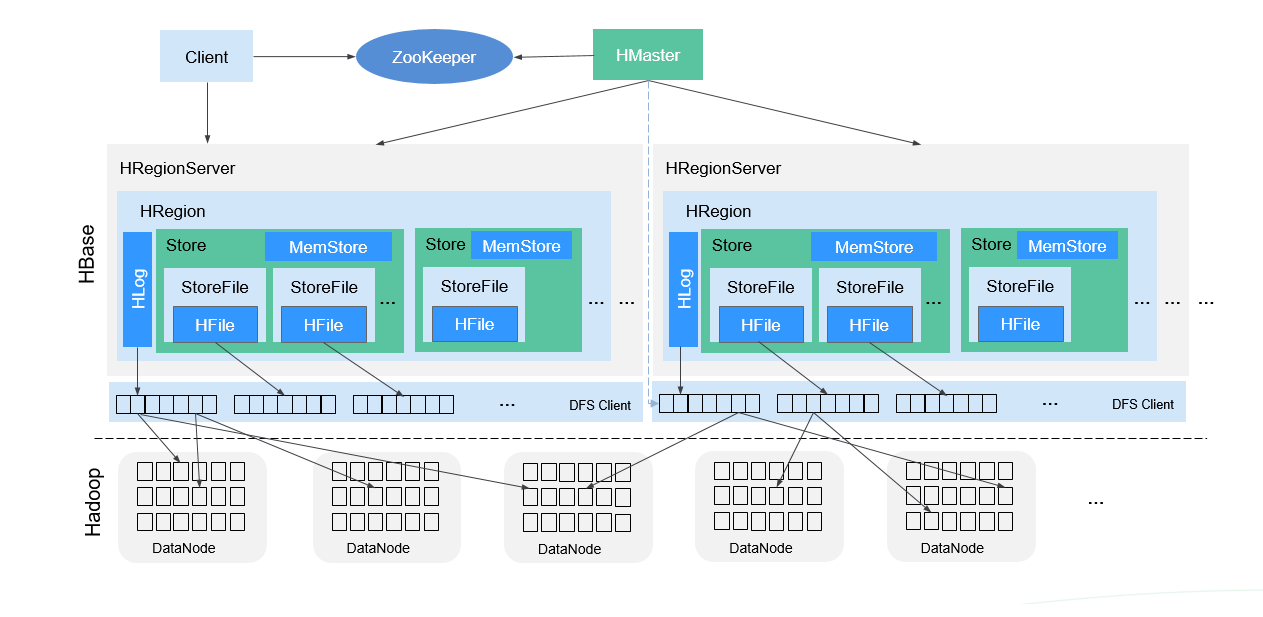
HMaster主要负责:
- 在HA模式下,包含主用Master和备用Master。
- 主用Master:负责HBase中RegionServer的管理,包括表的增删改查;RegionServer的负载均衡,Region分布调整;Region分裂以及分裂后的Region分配;RegionServer失效后的Region迁移等。
- 备用Master:当主用Master故障时,备用Master将取代主用Master对外提供服务。故障恢复后,原主用Master降为备用。
RegionServer主要负责:
- 存放和管理本地HRegion。
- RegionServer负责提供表数据读写等服务,是HBase的数据处理和计算单元,直接与Client交互。
- RegionServer一般与HDFS集群的DataNode部署在一起,实现数据的存储功能。读写HDFS,管理Table中的数据。
ZooKeeper集群主要负责:
- 存放整个 HBase集群的元数据以及集群的状态信息。
- 实现HMaster主从节点的Failover。
HDFS集群主要负责:
- HDFS为HBase提供高可靠的文件存储服务,HBase的数据全部存储在HDFS中。
结构说明:
Store
- 一个Region由一个或多个Store组成,每个Store对应图中的一个Column Family。
MemStore
- 一个Store包含一个MemStore,MemStore缓存客户端向Region插入的数据,当RegionServer中的MemStore大小达到配置的容量上限时,RegionServer会将MemStore中的数据“flush”到HDFS中。
StoreFile
- MemStore的数据flush到HDFS后成为StoreFile,随着数据的插入,一个Store会产生多个StoreFile,当StoreFile的个数达到配置的阈值时,RegionServer会将多个StoreFile合并为一个大的StoreFile。
HFile
- HFile定义了StoreFile在文件系统中的存储格式,它是当前HBase系统中StoreFile的具体实现。
HLog(WAL)
- HLog日志保证了当RegionServer故障的情况下用户写入的数据不丢失,RegionServer的多个Region共享一个相同的HLog。
HBase提供两种API来写入数据。
- Put:数据直接发送给RegionServer。
- BulkLoad:直接将HFile加载到表存储路径。
HBase为了保证数据可靠性,使用WAL(Write Ahead Log)来保证数据可靠性。它是HDFS上的一个文件,记录HBase中数据的所有更改。所有的写操作都会先保证将数据写入这个文件后,才会真正更新MemStore,最后写入HFile中。如果写WAL文件失败,则操作会失败。在正常情况下,不需要读取WAL文件,因为数据会从MemStore中持久化为HFile文件。但是如果RegionServer在持久化MemStore之前崩溃或者不可用,系统仍然可以从WAL文件中读取数据,回放所有操作,从而保证数据不丢失。
写入流程如图所示:
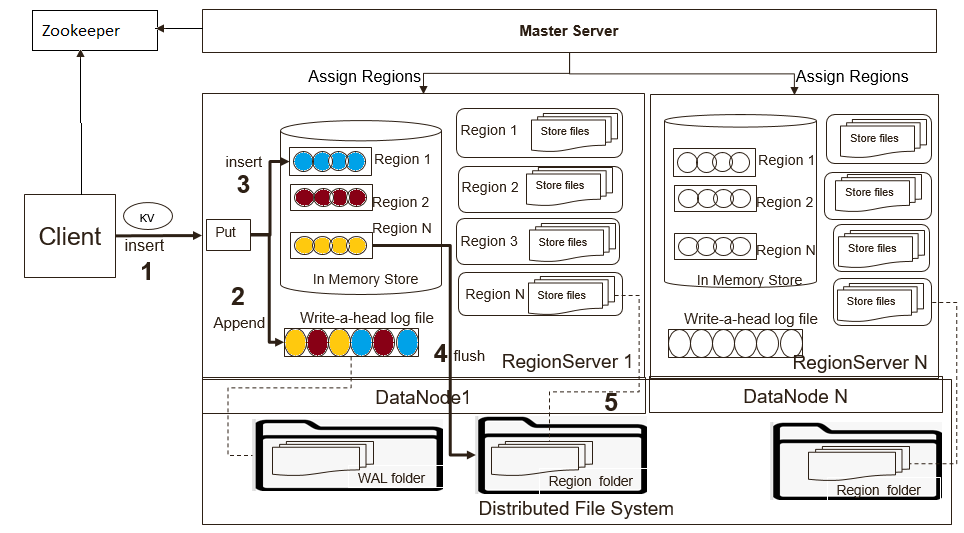
默认情况下RegionServer上管理的所有HRegion共享同一个WAL文件。WAL文件中每个记录都包括相关Region的信息。当打开Region时,需要回放WAL文件中属于该Region的记录信息。因此,WAL文件中的记录信息必须按Region进行分组,以便可以回放特定Region的记录。按Region分组WAL的过程称为WAL Split。
WAL Split由HMaster在集群启动时完成或者在RegionServer关闭时由ServershutdownHandler完成。在给定的Region再次可用之前,需要恢复和回放所有的WAL文件。因此在数据恢复之前,对应的Region无法对外服务。
HBase启动时,Region分配简要分配流程如下:
- HMaster启动时初始化AssignmentManager。
- AssignmentManager通过hbase:meta表查看当前Region分配信息。
- 如果Region分配依然有效(Region所在RegionServer依然在线),则保留分配信息。
- 如果Region分配无效,调用LoadBalancer来进行重分配。
- 分配完成后更新hbase:meta表。
本文主要关注集群重新启动和恢复相关内容,着重描述相关优化,减少HBase恢复时长。
RegionServer故障恢复流程当HMaster检测到故障时,会触发SCP(Server Crash Procedure)流程。SCP流程包括以下主要步骤:
- HMaster创建WAL Split任务,用于对属于崩溃RegionServer上Region进行记录分组。
- 将原属于崩溃RegionServer上Region进行重分配,分配给正常RegionServer。
- 正常RegionServer执行Region上线操作,对需要恢复数据进行回放。
HMaster等待Namespace表超时终止
当集群进行重启时,HMaster进行初始化会找到所有的异常RegionServer(Dead RegionServer)并开始SCP流程,并继续初始化Namespace表。
如果SCP列表中存在大量的RegionServer,那么Namespace表的分配将可能被延迟并超过配置的超时时间(默认5分钟),而这种情况在大集群场景下是最常见的。为临时解决该问题,常常将默认值改大,但是必不能保证一定会成功。

另外一种方式是在HMaster上启用表来避免此问题(hbase.balancer.tablesOnMaster=hbase:namespace),HMaster会优先将这些表进行分配。但是如果配置了其它表也可以分配到HMaster或者由于HMaster性能问题,这将无法做到100%解决此问题。此外在HBase 2.X版本中也不推荐使用HMaster来启用表。解决这个问题的最佳方法是支持优先表和优先节点,当HMaster触发SCP流程时,优先将这些表分配到优先节点上,确保分配的优先级,从而完全消除此问题。
批量分配时RPC超时
HBase专门线性可扩展性而设计。如果集群中的数据随着表增加而增多,集群可以很容易扩展添加RegionServer来管理表和数据。例如:如果一个集群从10个RegionServer扩展到20个RegionServer,它在存储和处理能力方面将会增加。
随着RegionServer上Region数量的增加,批量分配RPC调用将会出现超时(默认60秒)。这将导致重新进行分配并最终对分配上线时间产生严重影响。
在10个RegionServer节点和20个RegionServer节点的测试中,RPC调用分别花费了约60秒和116秒。对于更大的集群来说,批量分配无法一次成功。主要原因在于对ZooKeeper进行大量的读写操作和RPC调用,用来创建OFFLINE ZNode节点,创建正在恢复的Region ZNode节点信息等。
恢复可扩展性测试在10到100个节点的集群测试中,我们观察到恢复时间随着集群规模的增大而线性增加。这意味着集群越大,恢复所需的时间就越多。特别是当要恢复WAL文件时,恢复时间将会非常大。在100个节点的集群中,通过Put请求写入数据的情况下,恢复需要进行WAL Split操作,发现需要100分钟才能从集群崩溃中完全恢复。而在相同规模的集群中,如果不写入任何数据大约需要15分钟。这意味着85%以上的时间用于WAL Split操作和回放用于恢复。
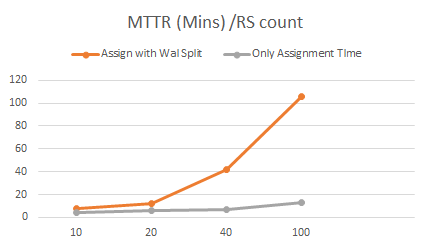
下面我们将分析测试过程中发现的瓶颈在哪里?
恢复耗时分析HDFS负载
在10个节点的HBase集群上,通过JMX来获取HDFS的RPC请求监控信息,发现在启动阶段有1200万读取RPC调用。
其中GetBlockLocationNumOps:380万、GetListingNumOps:13万、GetFileInfoNumOps:840万。
当集群规模达到100个时,RPC调用和文件操作将会非常大,从而对HDFS负载造成很大压力,成为瓶颈。可能由于以下原因导致HDFS写入失败、WAL Split和Region上线缓慢超时重试。
- 巨大的预留磁盘空间。
- 并发访问达到DataNode的xceiver的限制。
HMaster负载
HMaster使用基于ZooKeeper的分配机制时,在Region上线过程中HMaster会创建一个OFFLINE ZNode节点,RegionServer会将该ZNode更新为OPENING和OPENED状态。对于每个状态变化,HMaster都会进行监听并处理。
对于100个节点的HBase集群,大概将会有6,000,000个ZNode创建和更新操作和4,000,000个监听事件要进行处理。
ZooKeeper的监听事件通知处理是顺序的,旨在保证事件的顺序。这种设计在Region锁获取阶段将会导致延迟。在10个节点的集群中发现等待时间为64秒,而20节点的集群中等待时间为111秒。
.png)
GeneralBulkAssigner 在批量发送OPEN RPC请求到RegionServer之前会获取相关Region的锁,再收到RegionServer的OPEN RPC请求响应时才会释放该锁。如果RegionServer再处理批量OPEN RPC请求时需要时间,那么在收到确认响应之前GeneralBulkAssigner将不会释放锁,其实部分Region已经上线,也不会单独处理这些Region。
HMaster按照顺序创建OFFLINE ZNode节点。观察发现在执行批量分配Region到RegionServer之前将会有35秒的延迟来创建ZNode。
.png)
采用不依赖ZooKeeper的分配机制将会减少ZooKeeper的操作,可以有50%左右的优化。HMaster依然会协调和处理Region的分配。
提升WAL Split性能持久化FlushedSequenceId来加速集群重启WAL Split性能(HBASE-20727)
ServerManager有每个Region的flushedSequenceId信息,这些信息被保存在一个Map结构中。我们可以利用这些信息来过滤不需要进行回放的记录。但是这个Map结构并没有被持久化,当集群重启或者HMaster重启后,每个Region的flushedSequenceId信息将会丢失。
如果这些信息被持久化那么即使HMaster重启,这些依然存在可用于过滤WAL记录,加快恢复记录和回放。hbase.master.persist.flushedsequenceid.enabled 可用于配置是否开启此功能。flushedSequenceId信息将会定时持久化到如下目录 < habse root dir >/.lastflushedseqids。可以通过参数 hbase.master.flushedsequenceid.flusher.interval 来配置持久化间隔,默认为3小时。
注意:此特性在HBase 1.X版本不可用。
改善WAL Split在故障切换时稳定性(HBASE-19358)
在WAL记录恢复期间,WAL Split任务将会将RegionServer上的所有待恢复记录输出文件打开。当RegionServer上管理的Region数量较多时将会影响HDFS,需要大量的磁盘保留空间但是磁盘写入非常小。
当集群中所有RegionServer节点都重启进行恢复时,情况将变得非常糟糕。如果一个RegionServer上有2000个Region,每个HDFS文件为3副本,那么将会导致每个WAL Splitter打开6000个文件。
通过启用hbase.split.writer.creation.bounded可以限制每个WAL Splitter打开的文件。当设置为true时,不会打开任何recovered.edits的写入直到在内存积累的记录已经达到 hbase.regionserver.hlog.splitlog.buffersize(默认128M),然后一次性写入并关闭文件,而不是一直处于打开状态。这样会减少打开文件流数量,从hbase.regionserver.wal.max.splitters * the number of region the hlog contains减少为hbase.regionserver.wal.max.splitters * hbase.regionserver.hlog.splitlog.writer.threads。
通过测试发现在3节点集群中,拥有15GB WAL文件和20K Region的情况下,集群整体重启时间从23分钟缩短为11分钟,减少50%。
hbase.regionserver.wal.max.splitters = 5
hbase.regionserver.hlog.splitlog.writer.threads= 50
WAL Split为HFile(HBASE-23286)
WAL恢复时使用HFile文件替换Edits文件这样可以避免在Region上线过程中写入。Region上线过程中需要完成HFile文件校验、执行bulkload加载并触发Compaction来合并小文件。此优化可以避免读取Edits文件和持久化内存带来的IO开销。当集群中的Region数量较少时(例如50个Region)观察发现性能有显著提升。
当集群中有更多的Region时,测试发现由于大量的HFile写入和合并将会导致CPU和IO的增加。可以通过如下额外的措施来减少IO。
- 将故障RegionServer作为首选WAL Splitter,减少远程读取。
- 将Compaction延迟后台执行,加快region上线处理。
Observer NameNode(HDFS-12943)
当HBase集群规模变大时,重启会触发大量的RPC请求,使得HDFS可能成为瓶颈,可以通过使用Observer NameNode负担读请求来降低HDFS的负载。
总结通过上述分析,可以配置如下参数来提升HBase MTTR,尤其是在集群整体从崩溃中恢复的情况。
本文由华为云发布。