现在开始正式的进入战术部分,我看前面发的一些文章,只要有代码的阅读量就高,没代码的就差太多了,难道是因为平台只要看到代码才会加强推荐吗?真要是这样那我是真醉了,其实学习DDD光看代码还真不行,需要很多理论支持的。如果您是新的读者我建议先把前面的内容都翻看一下,至少得有一些理论依据作支撑后面学习起来才会更有效率。本章主要讲解实体,属于战术部分最为核心的内容。有人说聚合重要,但聚合也是实体,重要度都高,所以要先讲基础的。
一、两类模型实体包含两类。如果只有属性及“getter/setter”方法,这叫“贫血模型”,DDD不推荐使用这种模型。再说了,数据模型本身就是贫血的,再多引个贫血的领域模型除了各种赋值操作外根本就没个卵用。另外一种模型叫“充血模型”,“充血模型”不仅要包含属性,还要包含业务方法,下面两张图展示了两类模型在设计时的区别。把充血模型比喻成“人”最合适,有属性还有行为。本章及后续文章所涉及实体和值对象都属于充血模型。


您可别简简单单的认为这两种模型只是在包含方法上有区别,这里面的学问大着呢,你理解透了才能在用的时候不至于抓瞎。
首先咱们先说其意义,贫血模型是一种数据传输对象,它用于表现数据;充血模型由于其包含了对象属性和业务能力,可以有效的表达真实世界中各类活灵活现的事务,比较适合作为领域模型来用。还有一点,您就没法通过贫血模型来进行业务推测,所以一般称之为反模式。是不是会惊呆了?“啥玩意儿,什么叫通过模型推导业务?”。这东西明摆着嘛,您通过对业务进行分析来设计领域模型,当然也可以通过领域模型反向推导出业务能力了。别抬杠说不行,那只能说明设计不到位,不是业务上没讲明白就是模型上少东西。比如您看上面“贫血模型”那张图,你能知道这个实体的业务能力是什么吗?第二张的“充血模型”就可以看出来:1)支持修改订单价格,且修改价格时订单不能是已完成的状态;2)不支持变更下单日期。为什么人常说业领域模型反映了业务规则,就是指这种可相互推导的能力。那么好了,领域模型这么重要,从何而来?答:根据业务需求进行推断和设计出来的,实体的识别会占用您的大部分工作,只要这东西搞定,编写代码就分分钟的事情了。我见过有些架构师只管设计然后让开发去实现,这种行为基本上是来搞笑的。您只要敢这么干,开发就敢违背你的设计而放飞自我。所以,好的架构师一定也是个优秀的研发,也要实际的参与一线的研发任务。
第二,您别以为使用了Java或C#这种面向对象的语言就能写出面向对象的程序,无数的程序员用着面向对象的语言写着面向过程的代码。没办法,下了班就想玩儿王者荣耀,一点学习的心思都没有。再说了,咱可是大学生,天之骄子,只有破大专才需要恶补上学时的不足。
第三,贫血模型一般出现在事务脚本式开发中,学习曲线较低,代码几乎无复用性;充血模型自治力高,可也不是属样都特别牛掰。这东西拆分出的组件(子对象、嵌套对象等)特别多,代码编写复杂也不易理解。我自己的代码三个月不看都会蒙圈。
最后,假如您在设计或开发时发现存在着大量的无业务方法的贫血模型,在排除设计方式不正确的原因之外,也说明了此时使用事务脚本的方式实现代码会更好。您也别抬杠,OOP就是特别麻烦,需要多写业务模型、资源仓库等相关的代码。实现方式不对除了费力不讨好外只能用于拿出去装开发高手了。
二、实体定义实体的简单定义为:一种领域模型,此模型的定义并非来自于属性,而是一连串的连续事件和标识。说它是领域模型这个很好理解,“一连串的连续事件”是什么意思?“标识”是什么意思?让我们分别解释一下。“一连串的连续事件”就是说实体这个东西会由于某些事件而引发变化,可不管怎么变化其本质是不变的。比如说“人”这个实体,体重属性会随着减肥事件而产生变化,可再怎么变,这个人本质上仍然还是他。类似的还有性别,以当前的科技也不是不可变的,比如去趟泰国……就算是这人挂了,他还是他。不过话又说回来了,“人”的属性比如外形的变化可以让熟悉他的人都认不出来,那要怎么去唯一定位这个人呢?这其实就是“标识”的作用了。现实中,“人”一般会有身份证号,这个就可作为标识来用。标识一定是唯一且不变的,极端情况下实体可能没有属性,但也得有ID。当然了,咱不能抬扛说没有方法和属性只有ID能否还算为实体,设计出这么一个东西除了作为超类用,没其它太大的价值。
实体并不是独立存在的,它还会同其它的对象产生关联。一个“人”有各种属性,会干各类事情,这是“人”的特征与能力,可人并不是独立的。在与其它的人产生了关系关联后就出现了各类角色比如父亲、母亲、上下级等;在与其它的事务产生了行为关联后就出现了需要其它事务配合才能完成能的活动比如结婚、离婚。可以这么说,正是因为有了关联,实体才能变得有血有肉有活力。所以在设计实体时就会出现继承、嵌套对象、外部对象依赖等各类关联,也让实体变得复杂。
三、实体的特征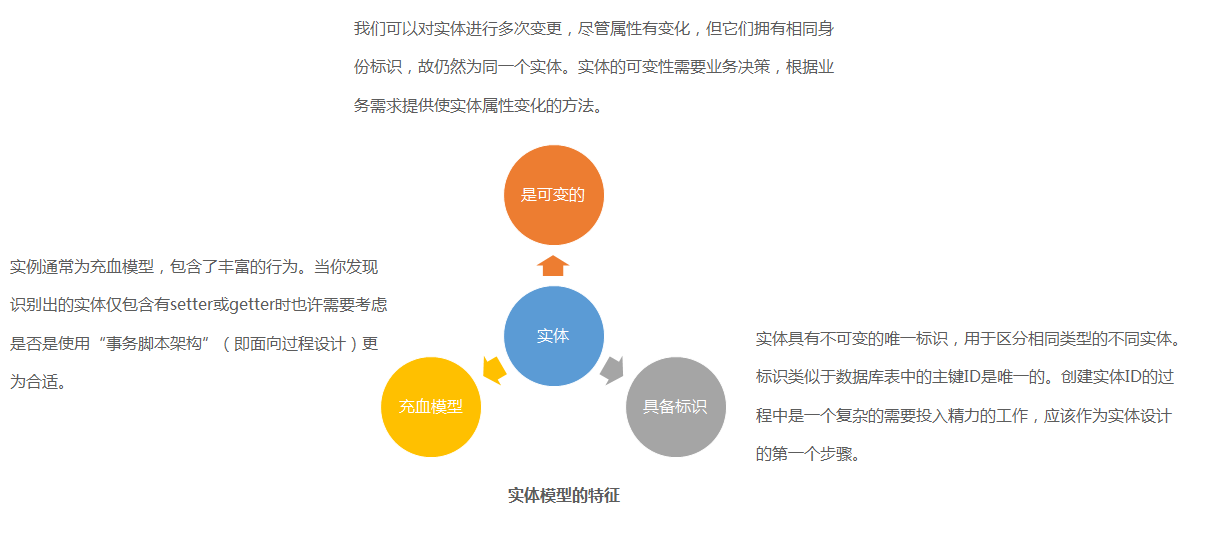
实体的特征主要有三点,不过最值得一说的就是ID这块。另外,实体设计起来非常容易和我们后面讲的“值对象”弄混了,也就是初学者常常遇到的不知道一个对象到底应该设计为实体还是值对象。这东西别说小白了,好多有经验的人做的时候也经常搞乱呢,所以需要使用迭代式设计来解决。回到ID这个问题上面,您在实际使用的时候尽量别用UUID,这东西做个Token什么的还凑合,作为业务ID就差了点意思,本身没什么规律也慢,毕竟我们通常会将实体的ID也同时作为数据库表的ID来用,而UUID的无序性造成插入和检索效率都不怎么高。想简单一点整个雪花算法就差不多了,绝对够用,毕竟并不是所有的单位都和大厂一样能资源和能力建立分布式ID生成系统。
有些工程师喜欢使用数据库的自增长ID作为实体ID,这种方式我在项目中用过,效果一般,有些情况下还特别麻烦。比如在进行实体的批量新建时,引入了“工作单元”后,需要把待执行久的对象放到一个Map中,但这个时候实体没有ID,多实体的情况下绝对扯犊子。另外的场景比如序列化实体后再发布一个领域事件,事件中需要有一个实体的ID,所以你就需要使用一些手段来保证实体序列化后事件能获取到这个ID。所以以我个人的经验,最好使用预生成ID也就是在创建实体的时候进行ID的创建,延迟ID的方式写代码比较难受。
实体的ID通常会跟随实体的一生,因为是不变的,在设计实体的时候不应该有类似“setId()”这种方法,唯一给ID赋值的方式就是通过构造函数。另外还需要注意的就是有些人喜欢使用一些框架比如“Entity Framework”,使用后就不用再考虑领域模型持久化的事情。我本人写了10年左右的C#后转行Java,所以不太清楚EF框架这几年的变化。但就我个人而言,不是很喜欢使用这种编程方式,过于依赖框架不说,涉及一些关系特别复杂的聚合时简直麻烦死了。但是,EF可以让工程师聚焦于业务模型的设计,由框架自动生成业务模型的子类并隐蔽的完成序列化工作的这种方式是推荐的。所以如果BC设计的合理,使用EF框架也挺好。
四、实体设计经验实体的设计需要研发人员投入很多的精力,也是最容易出现设计不当的情况。如果细节上的失误其实问题不大,因为有BC进行隔离出现问题后一般并不会出现大面积蔓延。就怕是在设计的时候让实体脱离了BC的约束而出现了超级类,这种情况下,且不说BC间的交互来往变多,代码的维护也比较恶心。所以在设计的时候,要确保你的实体不论是在属性方面还是责任方面都不要脱离BC的责任约束。比如在“鉴权”的BC中,关注的就是用户的角色和权限,您就不要把用户的交易流水信息做为用户的属性,那是“账务”BC所关心的。我们设计BC的目的就是为了实现业务责任单一化,那其内部的实体也得遵从这个原则,不能做超出所在BC责任范围外的事儿。
另外一条需要额外注意的原则就是实体的构造。构造实体通常包含两种方式,一是构造函数,二是使用工厂。使用构造函数时你需要保证其参数应能够使得当前实体在构造后是合法的,该有值的有值,该不为“null”不能为“null”。比如“用户”对象包含了ID和用户名两个属性,那么你在使用构造函数时需要为这两个属性赋值,而且要保证其值是合法的比如用户名是空字符串,不能超过某个长度。那位可能会问,要是不合法要怎么办?抛个业务异常呗,看一下如下代码。
public class Order extends EntityModel<Long> { private String name; public Order(Long id, String name) throws OrderCreationException { super(id); this.setName(name); } public String getName() { return name; } public void setName(String name) throws OrderCreationException { if (StringUtils.isEmpty(name)) { throw new OrderCreationException(); } this.name = name; } }
以我的经验来看,每个实体都应该有一个构造函数用于构造实体,不论其有多少个属性。属性多了您可以将部分属性包装成值对象,如果不想值对象对外暴露可以将构造函数设置为“protected”,然后建立一个继承于本实体的工厂对象,将构造实体时所需要的数据以视图模型的方式传进去,然后在工厂内部进行实体的构造,请看如下代码。
public class Order extends EntityModel<Long> { private String name; private Contact contact; protected Order(Long id, String name, Contact contact) throws OrderCreationException { super(id); this.name = name; this.contact = contact; } public String getName() { return name; } public Contact getContact() { return contact; } } public class OrderFactory extends Order { private OrderFactory(Long id, String name, Contact contact) throws OrderCreationException { super(id, name, contact); } public static Order create(OrderVO orderInfo) throws OrderCreationException { if (orderInfo == null) { throw new OrderCreationException(); } Contact contact = new Contact(orderInfo.getEmail(), orderInfo.getName()); return new Order(0L, orderInfo.getName(), contact); } }
上面的案例中,如果想直接通过构造函数创建“Order”类型的对象,就需要创建“Contact”类型的对象也就是您还需要了解“Contact”对象的构造方式。这还只是一个嵌套对象,如果多了那简直就是构造噩梦。通过使用工厂的方式,您不仅把对象的创建细节放在了工厂中进行封装,而且还能避免如“Contact”类型的泄露,这是一举几得来着?上述代码请注意标红的部分,虽然是细节但很重要。对象的创建方式总结一下,属性少时直接使用构造函数否则建立一个对象工厂。
还有一条值得分享的实体设计经验就是我们在确定实体的属性后只提供getter方法,根据需要再提供对应的用于修正属性的方法,这种方式可以最大化保障实体信息的安全以及防止属性被意外篡改。实际上,对象的封装性越好,后续出现问题的可能性就会越少。尤其是团队协作时,您哪知道谁手欠意外改了某个属性而引发程序BUG。
总结其实涉及实体的内容挺多的,比如实体的存储、验证、编写方法时的注意事项等,能想得上来的原则就好多。比如在验证方面,我个人一般会使用二级验证+内、外验证的方式来实现,这方面内容值得开一个新的章节做细讲。下一章,我展示一下个人在实际的项目中是如何使用实体的,敬请关注。