 Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场景,例如翻译,生成式问答,文本摘要等等,本章分别介绍3种不同的方案:UNILM,MASS,BART
Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场景,例如翻译,生成式问答,文本摘要等等,本章分别介绍3种不同的方案:UNILM,MASS,BART
Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场景,例如翻译,生成式问答,文本摘要等等
最初Transformer的Encoder+Deocder结构是在机器翻译领域,Encoder的部分通过双向LM来抽取输入的全部上下文信息,Decoder通过单向LM在Encoder抽取信息的基础上完成生成任务。但后续的预训练模型,Bert和GPT各自选取了Transformer的一部分来实现各自的目标。Bert只用了Encoder,核心是基于AutoEncoding reconstruction loss的双向LM,适用于NLU任务。GPT只用了Decoder,核心是基于AutoRegression perplexity loss的单向语言模型,适用于NLG任务。那想要兼顾双向理解和生成能力,就要探索如何能让AE和AR在训练过程进行梦幻联动,以下分别介绍3种不同的方案
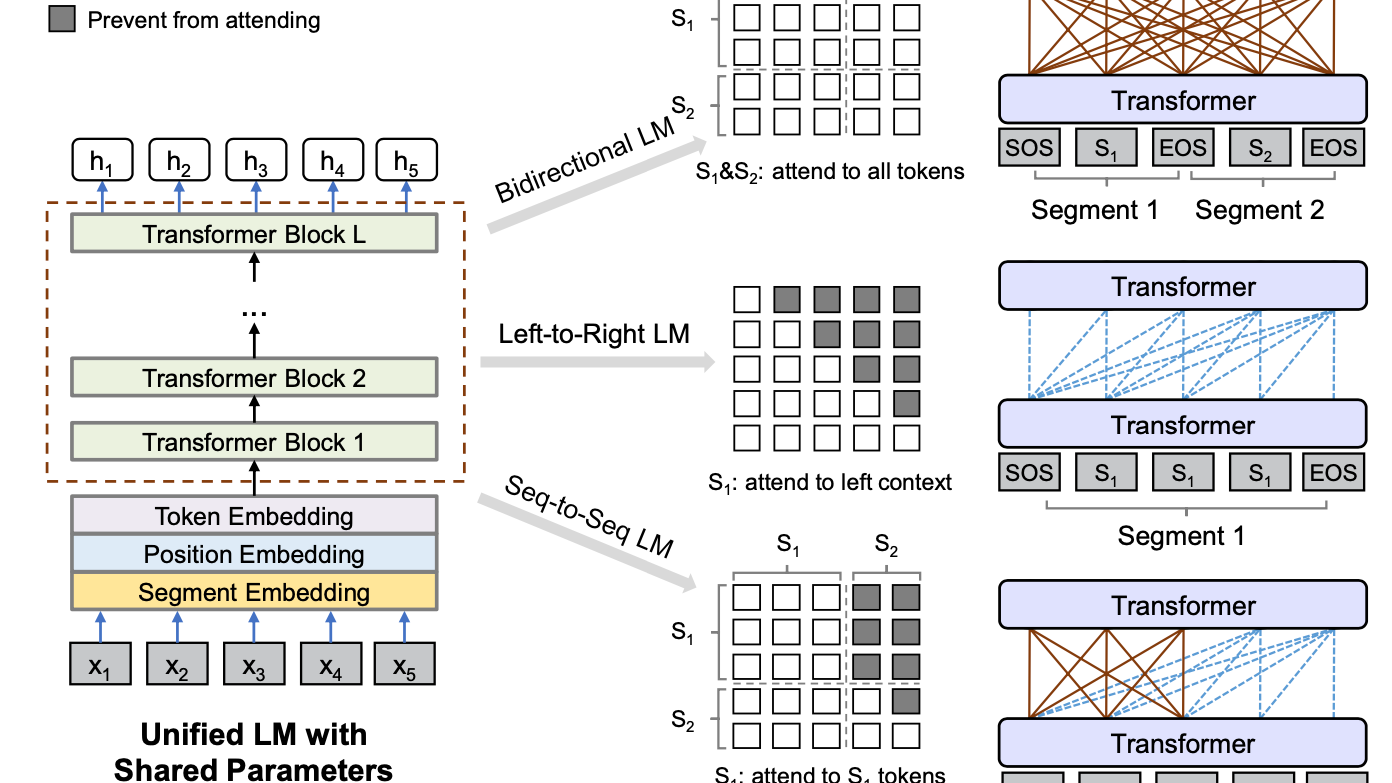
UNILM 1.0UNILM完美诠释了MASK在手,要啥都有的极简设计原理。通过三种不同的attention MASK,使用Multitask的训练方式在相同的Transformer backbone里面实现了三种任务的融合,分别是双向LM(BERT),单向LM(GPT),seq2seqLM(transformer)。管你是Encoder还是Decoder本质只是Attention计算中可见信息的差异,那调整MASK就完事了~

预训练任务
UNILM的预训练任务,都是基于AE的reconstruction任务,和Bert相同的是,都是随机MASK15%的token,其中80%会被MASK替换,10%保留原始token,10%随机token。不同的是UNILM在80%的情况下会MASK1个token,剩余情况下会随机遮盖bigran或者trigram。
那同样是AE,UNILM是如何做到学到AR相关的信息的呢?这和UNILM的训练方式有关,它采用了Multitask的训练方式,在一个batch的样本中,采用三种不同的attention mask,让相同的模型参数分别学习单向,双向,seq2seq的语言信息,包括
- \(\frac{1}{3}\)的时间训练双向LM: 和BERT相同使用self-attention MASK,并且在以上的MLM任务上,同时也加入了NSP任务
- \(\frac{1}{3}\)训练seq2seq LM:segment1使用self-attention MASK, segment2使用Future MASK,同样是对MASK进行还原
- \(\frac{1}{6}\)的时间训练从左->右单向LM,\(\frac{1}{6}\)的时间训练从右->左单向LM:只不过这里没有使用对整个sequence进行还原的perplexity loss,而同样是对MASK进行还原,只不过只使用单向信息
这里感觉虽然UNLIM实现了单向的信息传递,但和AR之间还是有本质差异的,因为并不是对连续token进行递归预测,而依旧条件独立的对MASK token进行还原,虽然引入了bigram和trigram的MASK,但是效果有限,感觉这里限制了生成的效果。所以有没有可能在共享参数的前提下,直接引入perplexity loss进行训练呢?