如果您正在构建软件即服务 (SaaS) 应用程序,您可能已经在数据模型中内置了租赁的概念。 通常,大多数信息与租户/客户/帐户相关,并且数据库表捕获这种自然关系。
对于 SaaS 应用程序,每个租户的数据可以一起存储在单个数据库实例中,并与其他租户保持隔离和不可见。这在三个方面是有效的。 首先,应用程序改进适用于所有客户端。 其次,租户之间共享数据库可以有效地使用硬件。 最后,为所有租户管理单个数据库比为每个租户管理不同的数据库服务器要简单得多。
但是,传统上,单个关系数据库实例难以扩展到大型多租户应用程序所需的数据量。 当数据超过单个数据库节点的容量时,开发人员被迫放弃关系模型的优势。
Citus 允许用户编写多租户应用程序,就好像他们连接到单个 PostgreSQL 数据库一样,而实际上该数据库是一个水平可扩展的机器集群。 客户端代码需要最少的修改,并且可以继续使用完整的 SQL 功能。
本指南采用了一个示例多租户应用程序,并描述了如何使用 Citus 对其进行建模以实现可扩展性。 在此过程中,我们研究了多租户应用程序的典型挑战,例如将租户与嘈杂的邻居隔离、扩展硬件以容纳更多数据以及存储不同租户的数据。PostgreSQL 和 Citus 提供了应对这些挑战所需的所有工具,所以让我们开始构建吧。
我们将为跟踪在线广告效果并在顶部提供分析仪表板的应用程序构建后端。 它非常适合多租户应用程序,因为用户对数据的请求一次只涉及一家公司(他们自己的)。Github 上提供了完整示例应用程序的代码。
citus-example-ad-analytics
- https://github.com/citusdata/citus-example-ad-analytics
让我们从考虑这个应用程序的简化 schema 开始。 该应用程序必须跟踪多家公司,每家公司都运行广告活动。 广告系列有许多广告,每个广告都有其点击次数和展示次数的关联记录。
这是示例 schema。稍后我们将进行一些小的更改,这使我们能够在分布式环境中有效地分发和隔离数据。
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial PRIMARY KEY,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blacklisted_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE ads (
id bigserial PRIMARY KEY,
campaign_id bigint REFERENCES campaigns (id),
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE clicks (
id bigserial PRIMARY KEY,
ad_id bigint REFERENCES ads (id),
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL
);
CREATE TABLE impressions (
id bigserial PRIMARY KEY,
ad_id bigint REFERENCES ads (id),
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL
);
我们可以对 schema 进行一些修改,这将在像 Citus 这样的分布式环境中提高性能。 要了解如何,我们必须熟悉 Citus 如何分发数据和执行查询。
关系数据模型非常适合应用程序。 它保护数据完整性,允许灵活查询,并适应不断变化的数据。 传统上唯一的问题是关系数据库不被认为能够扩展到大型 SaaS 应用程序所需的工作负载。开发人员必须忍受 NoSQL 数据库 — 或后端服务的集合 — 才能达到这个规模。
使用 Citus,您可以保留数据模型并使其可扩展。Citus 对应用程序来说似乎是一个 PostgreSQL 数据库,但它在内部将查询路由到可并行处理请求的可调整数量的物理服务器(节点)。
多租户应用程序有一个很好的特性,我们可以利用它:查询通常总是一次请求一个租户的信息,而不是多个租户的信息。例如,当销售人员在 CRM 中搜索潜在客户信息时,搜索结果是特定于他的雇主的; 其他企业的线索和注释不包括在内。
由于应用程序查询仅限于单个租户,例如商店或公司,因此快速进行多租户应用程序查询的一种方法是将给定租户的所有数据存储在同一节点上。 这最大限度地减少了节点之间的网络开销,并允许 Citus 有效地支持所有应用程序的连接(joins)、键约束(key constraints)和事务(transactions)。 有了这个,您可以跨多个节点进行扩展,而无需完全重新编写或重新构建您的应用程序。
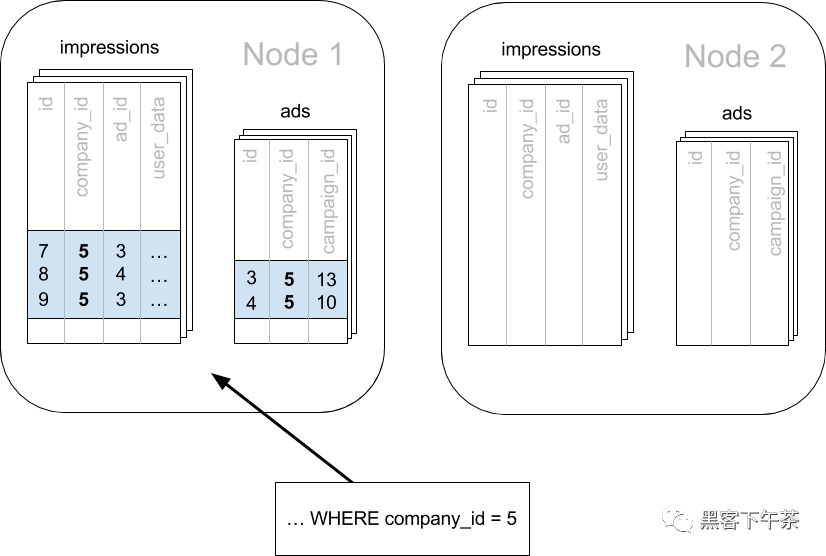
我们在 Citus 中通过确保 schema 中的每个表都有一个列来清楚地标记哪个租户拥有哪些行来做到这一点。 在广告分析应用程序中,租户是公司,因此我们必须确保所有表都有一个 company_id 列。
当为同一公司标记行时,我们可以告诉 Citus 使用此列来读取和写入同一节点的行。 在 Citus 的术语中,company_id 将是分布列,您可以在分布式数据建模中了解更多信息。
- 分布式数据建模
- https://docs.citusdata.com/en/v10.2/sharding/data_modeling.html#distributed-data-modeling
在上一节中,我们确定了多租户应用程序的正确分布列:公司 ID(company_id)。 即使在单机数据库中,通过添加公司 ID 对表进行非规范化也是很有用的,无论是为了行级安全还是为了额外的索引。 正如我们所看到的,额外的好处是包括额外的列也有助于多机器扩展。
到目前为止,我们创建的 schema 使用单独的 id 列作为每个表的主键。Citus 要求主键和外键约束包括分布列。 这一要求使得在分布式环境中执行这些约束更加有效,因为只需检查单个节点即可保证它们。
在 SQL 中,此要求转化为通过包含 company_id 来组合主键和外键。 这与多租户情况兼容,因为我们真正需要的是确保每个租户的唯一性。
综上所述,这里是为按 company_id 分配表准备的更改。
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial, -- was: PRIMARY KEY
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blacklisted_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id) -- added
);
CREATE TABLE ads (
id bigserial, -- was: PRIMARY KEY
company_id bigint, -- added
campaign_id bigint, -- was: REFERENCES campaigns (id)
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id), -- added
FOREIGN KEY (company_id, campaign_id) -- added
REFERENCES campaigns (company_id, id)
);
CREATE TABLE clicks (
id bigserial, -- was: PRIMARY KEY
company_id bigint, -- added
ad_id bigint, -- was: REFERENCES ads (id),
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id), -- added
FOREIGN KEY (company_id, ad_id) -- added
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial, -- was: PRIMARY KEY
company_id bigint, -- added
ad_id bigint, -- was: REFERENCES ads (id),
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id), -- added
FOREIGN KEY (company_id, ad_id) -- added
REFERENCES ads (company_id, id)
);
您可以了解有关在多租户架构迁移中迁移您自己的数据模型的更多信息
。
- 多租户架构迁移
- https://docs.citusdata.com/en/v10.2/develop/migration_mt_schema.html#mt-schema-migration
本指南旨在让您可以在自己的 Citus 数据库中进行操作。 本教程假设您已经安装并运行了 Citus。如果您没有运行 Citus,则可以使用单节点 Citus 中的选项之一在本地安装设置 Citus。
- 单节点 Citus
- https://docs.citusdata.com/en/v10.2/installation/single_node.html#development
您将使用 psql 运行 SQL 命令并连接到 Coordinator 节点:
- Docker:
docker exec -it citus_master psql -U postgres
此时,您可以在自己的 Citus 集群中随意下载并执行 SQL 以创建模式。 一旦模式准备好,我们就可以告诉 Citus 在工作人员上创建分片。 从协调器节点运行:
此时,您可以通过下载 schema.sql并执行 SQL 来创建 schema,在你自己的 Citus 集群中进行操作。一旦 schema 准备好,我们可以告诉 Citus 在 workers 上创建 shards。从 coordinator 节点运行:
- schema.sql
- https://examples.citusdata.com/mt_ref_arch/schema.sql
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
create_distributed_table 函数通知 Citus 表应该分布在节点之间,并且应该计划对这些表的未来传入查询以进行分布式执行。 该函数还在工作节点上为表创建分片,这些分片是 Citus 用于将数据分配给节点的低级别数据存储单元。
- create_distributed_table
- https://docs.citusdata.com/en/v10.2/develop/api_udf.html#create-distributed-table
下一步是从命令行将样本数据加载到集群中。
# download and ingest datasets from the shell
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
如果您使用 Docker,则应使用 docker cp 命令将文件复制到 Docker 容器中。
for dataset in companies campaigns ads clicks impressions geo_ips; do
docker cp ${dataset}.csv citus:.
done
作为 PostgreSQL 的扩展,Citus 支持使用 COPY 命令进行批量加载。 使用它来摄取您下载的数据,如果您将文件下载到其他位置,请确保指定正确的文件路径。 回到 psql 里面运行这个:
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
好消息是:一旦您完成了前面概述的轻微 schema 修改,您的应用程序就可以用很少的工作量进行扩展。你只需将应用程序连接到 Citus,让数据库负责保持查询速度和数据安全。
任何包含 company_id filter 的应用程序查询或更新语句将继续按原样工作。 如前所述,这种 filter 在多租户应用程序中很常见。使用对象关系映射器 (ORM) 时,您可以通过 where 或 filter 等方法识别这些查询。
ActiveRecord:
Impression.where(company_id: 5).count
Django:
Impression.objects.filter(company_id=5).count()
基本上,当在数据库中执行的结果 SQL 在每个表(包括 JOIN 查询中的表)上包含 WHERE company_id = :value 子句时,Citus 将识别出该查询应该路由到单个节点,并按原样在那里执行。这确保了所有 SQL 功能都可用。该节点毕竟是一个普通的 PostgreSQL 服务器。
此外,为了更简单,您可以使用我们的 Rails 的 activerecord-multi-tenant 库或 Django 的 django-multitenant 库,它们会自动将这些过滤器添加到您的所有查询中,即使是复杂的查询。查看我们的 Ruby on Rails 和 Django 迁移指南。
- activerecord-multi-tenant
- https://github.com/citusdata/activerecord-multi-tenant
- django-multitenant
- https://github.com/citusdata/django-multitenant
- Ruby on Rails
- https://docs.citusdata.com/en/v10.2/develop/migration_mt_ror.html#rails-migration
- Django
- https://docs.citusdata.com/en/v10.2/develop/migration_mt_django.html#django-migration
本指南与框架无关,因此我们将指出一些使用 SQL 的 Citus 功能。 发挥您的想象力,以了解这些陈述将如何以您选择的语言表达。
这是在单个租户上运行的简单查询和更新。
-- campaigns with highest budget
SELECT name, cost_model, state, monthly_budget
FROM campaigns
WHERE company_id = 5
ORDER BY monthly_budget DESC
LIMIT 10;
-- double the budgets!
UPDATE campaigns
SET monthly_budget = monthly_budget*2
WHERE company_id = 5;
用户使用 NoSQL 数据库扩展应用程序的一个常见痛点是缺少 transactions 和 joins。但是,事务在 Citus 中的工作方式与您期望的一样:
-- transactionally reallocate campaign budget money
BEGIN;
UPDATE campaigns
SET monthly_budget = monthly_budget + 1000
WHERE company_id = 5
AND id = 40;
UPDATE campaigns
SET monthly_budget = monthly_budget - 1000
WHERE company_id = 5
AND id = 41;
COMMIT;
作为 SQL 支持的最后一个 demo,我们有一个包含聚合(aggregates)和窗口(window)函数的查询,它在 Citus 中的工作方式与在 PostgreSQL 中的工作方式相同。 该查询根据展示次数对每个广告系列中的广告进行排名。
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
简而言之,当查询范围为租户时,插入、更新、删除、复杂的 SQL 和事务都按预期工作。
到目前为止,所有表都通过 company_id 分发,但有时有些数据可以由所有租户共享,并且不“属于”特定的任何租户。 例如,所有使用此示例广告平台的公司都可能希望根据 IP 地址获取其受众的地理信息。在单机数据库中,这可以通过 geo-ip 的查找表来完成,如下所示。(一个真实的表可能会使用 PostGIS,但可以使用简化的示例。)
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
为了在分布式设置中有效地使用此表,我们需要找到一种方法来共同定位 geo_ips 表,不仅针对一个公司,而且针对每个公司。这样,在查询时不需要产生网络流量。 我们在 Citus 中通过将 geo_ips 指定为参考表来执行此操作。
- 参考表
- https://docs.citusdata.com/en/v10.2/develop/reference_ddl.html#reference-tables
-- Make synchronized copies of geo_ips on all workers
SELECT create_reference_table('geo_ips');
参考表在所有工作节点之间复制,Citus 在修改期间自动保持它们同步。 请注意,我们调用 create_reference_table 而不是 create_distributed_table。
- create_reference_table
- https://docs.citusdata.com/en/v10.2/develop/api_udf.html#create-reference-table
现在 geo_ips 已建立为参考表,使用示例数据加载它:
\copy geo_ips from 'geo_ips.csv' with csv
现在,将点击与这个表联接(join)起来可以高效地执行。例如,我们可以询问点击广告290 的每个人的位置。
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
多租户系统的另一个挑战是保持所有租户的 schema 同步。 任何 schema 更改都需要一致地反映在所有租户中。在 Citus 中,您可以简单地使用标准 PostgreSQL DDL 命令来更改表的 schema,Citus 将使用两阶段提交协议将它们从 coordinator 节点传播到 worker。
例如,此应用程序中的广告可以使用文本标题。我们可以通过在 coordinator 上发出标准 SQL 来向表中添加一列:
ALTER TABLE ads
ADD COLUMN caption text;
这也会更新所有 worker。 此命令完成后,Citus 集群将接受在新 caption 列中读取或写入数据的查询。
有关 DDL 命令如何通过集群传播的更完整说明,请参阅修改表。
- 修改表
- https://docs.citusdata.com/en/v10.2/develop/reference_ddl.html#ddl-prop-support
鉴于所有租户共享一个共同的 schema 和硬件基础设施,我们如何容纳想要存储其他人不需要的信息的租户? 例如,一个使用我们广告数据库的租户应用程序可能希望通过点击存储跟踪 cookie 信息,而另一个租户可能关心 browser agents。 传统上,使用多租户共享模式方法的数据库采用创建固定数量的预分配“自定义”列,或具有外部“扩展表”。 但是,PostgreSQL 为其非结构化列类型提供了一种更简单的方法,尤其是 JSONB。
- JSONB
- https://www.postgresql.org/docs/current/static/datatype-json.html
请注意,我们的 schema 在 clicks 中已经有一个名为 user_data 的 JSONB 字段。每个租户都可以使用它进行灵活的存储。
假设公司 5 在字段中包含信息以跟踪用户是否在移动设备上。 该公司可以查询以查找谁点击更多,移动访问者或传统访问者:
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
数据库管理员甚至可以创建部分索引来提高单个租户查询模式的速度。这是一项改进公司 5 对移动设备用户点击的过滤器的方法:
- 部分索引
- https://www.postgresql.org/docs/current/static/indexes-partial.html
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
此外,PostgreSQL 支持 JSONB 上的 GIN 索引。 在 JSONB 列上创建 GIN index 将为该 JSON 文档中的每个 key 和 value 创建一个索引。这加速了许多 JSONB 运算符,例如 ?、?| 和 ?&。
- GIN 索引
- https://www.postgresql.org/docs/current/static/gin-intro.html
- JSONB 运算符
- https://www.postgresql.org/docs/current/static/functions-json.html#FUNCTIONS-JSONB-OP-TABLE
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
随着业务的增长或租户想要存储更多数据,多租户数据库应针对未来规模进行设计。 Citus 可以通过添加新机器轻松扩展,而无需进行任何更改或让应用程序停机。
能够重新平衡 Citus 集群中的数据使您可以增加数据大小或客户数量并按需提高性能。 添加新机器允许您将数据保留在内存中,即使它比单台机器可以存储的数据大得多。
此外,如果只有少数大型租户的数据增加,那么您可以将这些特定租户隔离到单独的节点以获得更好的性能。(租户隔离是 Citus 企业版的一个功能。)
要横向扩展您的 Citus 集群,请首先向其中添加一个新的 worker 节点。在 Azure Database for PostgreSQL - Hyperscale (Citus) 上,可以使用 Azure Portal 添加所需数量的节点。或者,如果您运行自己的 Citus 安装,则可以使用 citus_add_node UDF 手动添加节点。
- citus_add_node
- https://docs.citusdata.com/en/v10.2/develop/api_udf.html#citus-add-node
添加节点后,它将在系统中可用。但是,此时没有租户存储在上面,Citus 还不会在那里运行任何查询。要移动现有数据,您可以要求 Citus 重新平衡数据。 此操作在当前活动节点之间移动称为分片的行束,以尝试均衡每个节点上的数据量。
SELECT rebalance_table_shards('companies');
Rebalancing 保留了 Table Co-Location,这意味着我们可以告诉 Citus 重新平衡公司表,它会接受提示并重新平衡由 company_id 分配的其他表。 此外,使用 Citus 企业版,应用程序在分片重新平衡期间无需停机。 读取请求无缝地继续,并且写入仅在它们影响当前正在运行的分片时才被锁定。 在 Citus 社区版中,对分片的写入在重新平衡期间被阻止,但读取不受影响。
- Table Co-Location
- https://docs.citusdata.com/en/v10.2/sharding/data_modeling.html#colocation
您可以在此处了解有关分片重新平衡如何工作的更多信息:Scaling Out(添加新节点)。
- Scaling Out(添加新节点)
- https://docs.citusdata.com/en/v10.2/cloud/performance.html#scaling-out
本部分使用仅在 Citus Enterprise 中可用的功能。
上一节描述了随着租户数量的增加而扩展集群的通用方法。 但是,用户经常有两个问题。首先是他们最大的租户如果变得太大会发生什么。 第二个是在单个工作节点上托管大型租户和小型租户对性能的影响,以及可以做些什么。
关于第一个问题,调查来自大型 SaaS 站点的数据表明,随着租户数量的增加,租户数据的大小通常倾向于遵循 Zipfian 分布。
- Zipfian 分布
- https://en.wikipedia.org/wiki/Zipf's_law
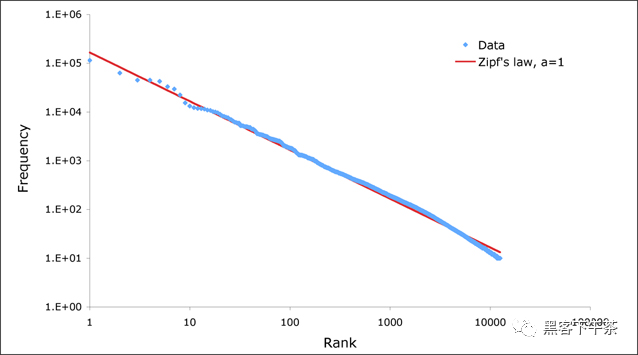
例如,在一个包含 100 个租户的数据库中,预计最大的租户将占数据的 20% 左右。 在一个大型 SaaS 公司更现实的例子中,如果有 10k 个租户,最大的将占数据的 2% 左右。即使是 10TB 的数据,最大的租户也需要 200GB,这很容易适应单个节点。
另一个问题是关于大型和小型租户在同一节点上时的性能。 标准分片重新平衡将提高整体性能,但它可能会或可能不会改善大小租户的混合。 再平衡器只是分配分片以均衡节点上的存储使用,而不检查在每个分片上分配了哪些租户。
为了改善资源分配并保证租户的 QoS,将大型租户移动到专用节点是值得的。 Citus 提供了执行此操作的工具。
在我们的例子中,假设我们的老朋友公司 id=5 非常大。 我们可以分两步隔离此租户的数据。我们将在此处介绍这些命令,您可以咨询 Tenant Isolation 以了解有关它们的更多信息。
- Tenant Isolation
- https://docs.citusdata.com/en/v10.2/admin_guide/cluster_management.html#tenant-isolation
首先将租户的数据隔离到一个适合移动的专用分片中。CASCADE 选项也将此更改应用于我们由 company_id 分发的其余表。
SELECT isolate_tenant_to_new_shard(
'companies', 5, 'CASCADE'
);
输出是专用于保存 company_id=5 的分片 ID:
┌─────────────────────────────┐
│ isolate_tenant_to_new_shard │
├─────────────────────────────┤
│ 102240 │
└─────────────────────────────┘
接下来,我们将数据通过网络移动到一个新的专用节点。 如上一节所述创建一个新节点。记下其主机名,如 Cloud Console 的 “Nodes” 选项卡中所示。
-- find the node currently holding the new shard
SELECT nodename, nodeport
FROM pg_dist_placement AS placement,
pg_dist_node AS node
WHERE placement.groupid = node.groupid
AND node.noderole = 'primary'
AND shardid = 102240;
-- move the shard to your choice of worker (it will also move the
-- other shards created with the CASCADE option)
-- note that you should set wal_level for all nodes to be >= logical
-- to use citus_move_shard_placement.
-- you also need to restart your cluster after setting wal_level in
-- postgresql.conf files.
SELECT citus_move_shard_placement(
102240,
'source_host', source_port,
'dest_host', dest_port);
您可以通过再次查询 pg_dist_placement 来确认分片移动。
- pg_dist_placement
- https://docs.citusdata.com/en/v10.2/develop/api_metadata.html#placements
有了这个,您现在知道如何使用 Citus 为您的多租户应用程序提供可扩展性。 如果您有现有架构并希望将其迁移到 Citus,请参阅多租户转换。
- 多租户转换
- https://docs.citusdata.com/en/v10.2/develop/migration.html#transitioning-mt
要调整前端应用程序,特别是 Ruby on Rails 或 Django,请阅读 Ruby on Rails 或 Django。 最后,尝试 Azure Database for PostgreSQL - Hyperscale (Citus),这是管理 Citus 群集的最简单方法。
- Ruby on Rails
- https://docs.citusdata.com/en/v10.2/develop/migration_mt_ror.html#rails-migration
- Django
- https://docs.citusdata.com/en/v10.2/develop/migration_mt_django.html#django-migration
- Azure Database for PostgreSQL - Hyperscale (Citus)
- https://docs.microsoft.com/azure/postgresql/quickstart-create-hyperscale-portal
- 扩展我们的分析处理服务(Smartly.io):使用 Citus 对 PostgreSQL 数据库进行分片