若希望更早前了解BurpSuite的介绍,请访问第二篇(渗透测试之BurpSuite工具的使用介绍(二)):https://www.cnblogs.com/zhaoyunxiang/p/16000296.html
五、Burp Scanner 模块使用介绍:
1.Burp Scanner是什么:
Burp Scanner是一个进行自动发现 web应用程序的安全漏洞的工具。它是为渗透测试人员设计的,并且它和你现有的手动执行进行的 web应用程序半自动渗透测试的技术方法很相似。
使用的大多数的 web扫描器都是单独运行的:你提供了一个开始 URL,单击”go”,然后注视着进度条的更新直到扫描结束,最后产生一个报告。Burp Scanner和这完全不同,在攻击一个应用程序时它和你执行的操作紧紧的结合在一起。让你细微控制着每一个扫描的请求,并直接反馈回结果。
Burp Scanner可以执行两种扫描类型:
1. Active scanning扫描器向应用程序发送大量的伪造请求,这些请求都是有一个基础请求衍生出来的,然后通过分析响应结果来查找漏洞特征。
2.Passive scanning扫描器不发送他自己的任何新请求,只分析现有的请求和响应的内容,从这些信息中推断出漏洞。
你可以在目标应用程序使用两种不同方式:
1.Manual scanning你可以发送其他 Burp工具的一个或多个请求,来对这些特定的请求执行主动或被动的扫描。
2. Live scanning as you browse你可以配置扫描器来自动执行主动或被动的扫描那些你浏览应用程序时经过代理的请求。
这种自动探测漏洞的方法给渗透测试人员带来了几点好处:
1.通过逐个的请求,能快速可靠地对常规的漏洞进行扫描,这很大程度地减少你的测试精力,还能使你对那些不能进行自动可靠地探测的漏洞直接使用个人经验来判断。
2.每种扫描的结果会被立即显示出来,并通报出在这个请求中包含的其他的测试操作。
3.Burp避免了其他扫描器的令人沮丧的问题,进行一次自动扫描需要 1年的时间,并还不能保证扫描是否有效,或者是否遇到了影响扫描效率的问题。
Burp精准地控制着要扫描的内容,并对扫描结果和应用程序上的广范围的影响进行实时监控,Burp Spider让你把可靠自动化的优点和人类直观智慧结合起来,常常会得到压倒性的结果。
2.主动扫描
在这种扫描模式下,Burp使用应用程序的一个叫做” base request”单个请求,通过一些方法修改后,来触发一些漏洞存在的迹象。这些被修改过的请求被发送到应用程序,然后分析响应的结果。在许多情况下,根据初步探测的结果,会发送进一步的请求。这种操作模式会产生大量的恶意的请求,并导致应用程序妥协。你要谨慎地使用这种扫描模式,仅当得到应用程序的所有者允许时,并且警告过他们自动扫描会给他们的应用程序和数据带来影响。如果可能,扫描不用的系统,并在扫描前进行备份。
对应用程序中的已知缺陷的漏洞的自动探测是很可靠的。Burp的主动扫描能力的是为扫描器能可靠地查找到基于输入的漏洞而设计的。为了避免在其他地方产生的误报, Burp在他的输出上给了你自信,让你集中精力到那些需要提供人类经验和智慧的工作上。
Burp主动扫描能确认的问题大体上可分为下面 两类:
1.在客户端上的输入漏洞,如:跨站点脚本,HTTP消息头注入,开放重定向。
2.在服务端的输入漏洞,如:SQL注入,操作系统命令注入,文件路径遍历。
可以以非常高的可靠度探测到第 1类的问题。在大多数情况下,在客户端上,和查找漏洞相关的任何事情都是可见的。例如,为了探测反射型 XSS,Burp Scanner会在应用程序的每个入口点提交一些良性的输入,并查看回复的响应。如果有回复,Burp会解析出响应的内容来确定回复显示的上下文。然后通过许多修改的输入来确定在上下文里组成一个攻击的字符串是否被回复了。Burp Scanner有打破输入过滤的广泛能力,并且绕过 web服务器的相关设置,来检查所有使用的上下文。通过先前检查的反馈对决策树进行全面检查,Burp能高效地模拟一个富有经验并且有条不紊的测试人员的检测行为,如一个输入封装计划。第 2类问题本来就不适合使用自动化手段探测,因为大多数情况下和漏洞有关的行为只能发生在服务端,客户端能看到的现象太少。例如,SQL注入漏洞会在响应中返回详细的数据库错误,或者完全地被遮盖。Burp Scanner使用许多技术来确认盲服务端注入问题,有延时,改变布尔条件,以及执行模糊的响应比较,等等。此时这些技术会比用在第 1类问题时产生更多的错误。然而,Burp Sanner在这里却实现了一个高的成功率,能可靠地发现许多问题,这对测试人员来说是费力的或者困难的来进行诊断。
3.被动扫描
在这种模式下,Burp不会向服务器发送任何新的请求。它只分析现存的请求和响应,并从中推断出漏洞。在你访问的任何授权应用程序,使用这种操作模式是安全和合法的。
只使用这种被动的技术,Burp Scanner能发现几种漏洞,有:
1.明文提交的密码。
2.不安全的 cookie属性,如丢失 HttpOnly和安全标志。
3.开放的 cookie范围。
4.跨站点脚本泄露 Referer信息。
5.自动填充的表单。
6.SSL保护的缓冲区内容。
7.目录遍历。
8.提交的密码会在后面返回的响应中。
9.不安全的会话令牌传输。
10.信息泄露,如互联网 IP地址,电子邮件地址,堆栈跟踪,等。
11.不安全的视图配置。
12.不清楚的,没完成的,不正确或不标准的内容类型指示。
这些问题都是相对平淡的,对我们来说记录它们显得无聊和重复。但是作为一个渗透测试人员,有人责任指出它们。在你浏览应用程序一次时,Burp Scanner既然可靠地扫描出这些问题,你就应该理智清楚它们。
在下面的一些情况,只进行被动的扫描是有好处的:
1.因为被动扫描不必向应用程序发送任何新的请求,你就可以安全地用在重要的应用程序上,你可以完全地控制发送的每一个请求。
2.有些应用程序对攻击的反应是很气愤的,当收到一个恶意的请求时,会终止你的会话或者锁定你的账号。在这种情况下,只能一次次地进行手工测试,这时你可以通过被动扫描来确认许多问题,而不会出现麻烦。
3.如果你没被授权进行攻击一个目标,你可以像普通用户那样浏览应用程序使用被动扫描来确认漏洞。如果你提出了一个新的渗透测试方案,你可以通过被动扫描你的目标来获得对安全状态的了解,甚至在你进行测试之前,有希望发现一些公布的问题。
4.开始扫描
Manual scanning在 Burp Suite的任何地方的都可以把一个或多个 HTTP请求发送到Scanner执行主动或被动的扫描。例如,你使用 Burp Proxy拦截下一个感兴趣的请求,你可以通过使用上下文菜单,只对这一个请求进行扫描:
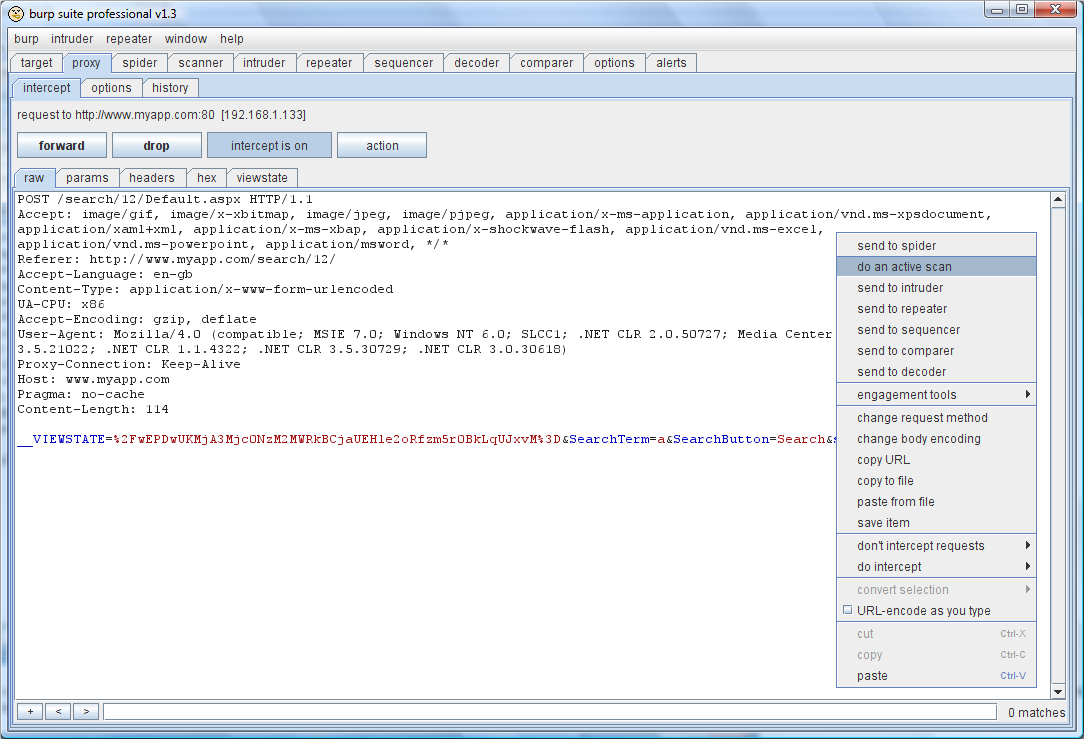
同样地,你可以选择目标站点地图上或者历史记录里的一系列的请求,把它们发送到Scanner上。因此,在浏览完应用程序一圈并建立起它内容的全面地图后,你就可以告诉 Burp扫描应用程序功能的特定区域:
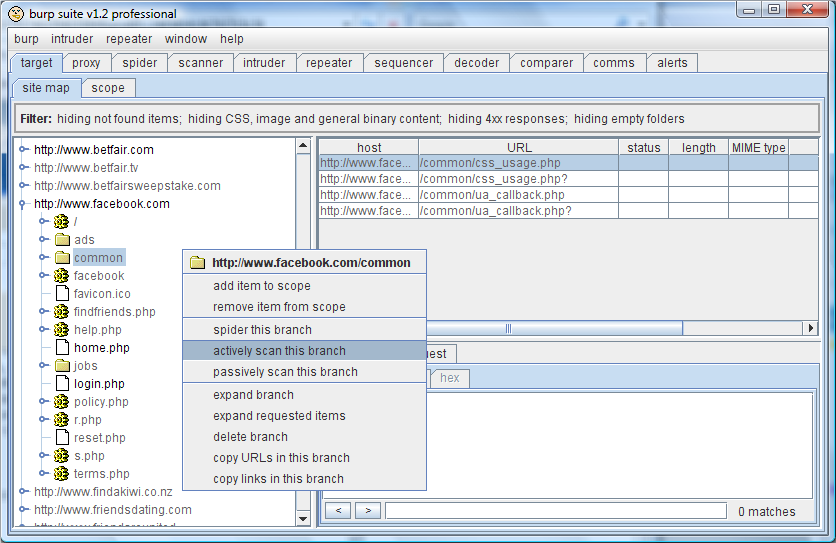
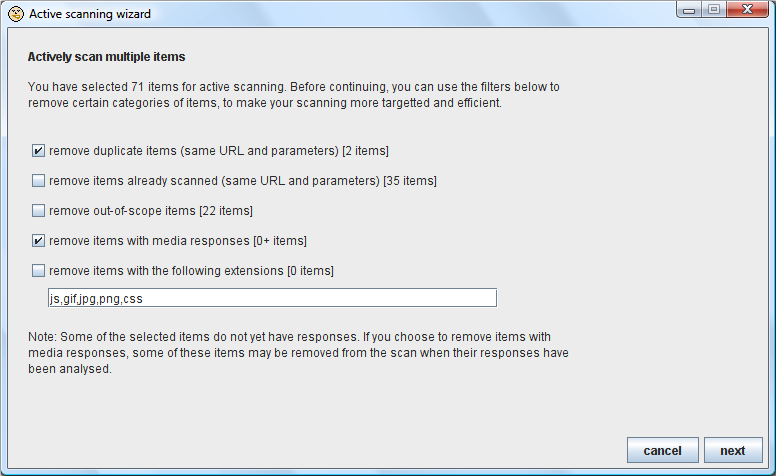
如果你选择了多个项并把它们发送到主动扫描,Burp会启动一个简洁的向导,让你微调你的选择。向导的第一个画面为你提供了许多直观的过滤器来删除那些需要的潜在项 (重复的,已经扫描过的,媒体内容,等等),以及显示过滤器影响到的项有多少:
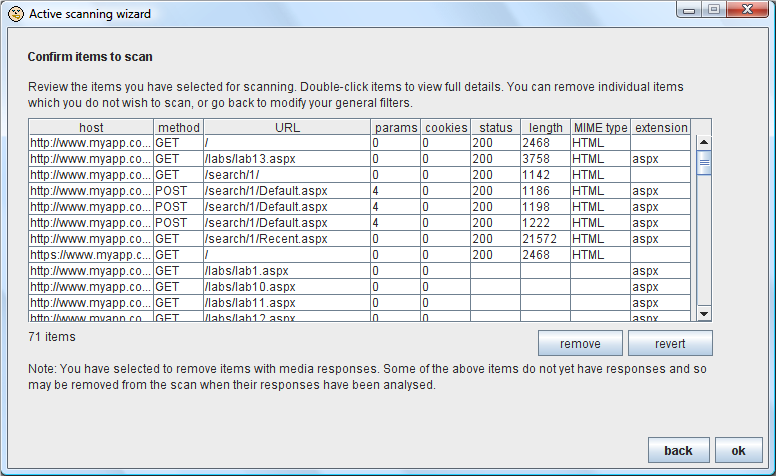
第二个向导画面向显示了剩下项的表单,你可以使用多种相关的属性对表格进行排序,查看所有的请求和响应,以及删除单个项:
这时向导设置已经完成,以平常方式来对这些选中进行扫描。
Live scanning可以使用另一种方式—”live scanning”来执行扫描。在这种模式下,你告诉 Burp你使用主动或被动扫描的目标范围,然后它会自动启动扫描,对你使用应用程序产生的相关请求进行主动或被动的扫描。当使用这种模式操作时,你需要作为一个普通用户简单地把应用程序访问一圈,向 Burp显示出应用程序内容和功能的位置,然后它就会在后台进行查找漏洞。当使用现场扫描时,你细微地控制着 Burp将要自动地扫描的请求。如果你已经为你的工作配置一个目标范围,然后你可以简单地告诉 Burp扫描属于范围内的每一个请求。另外,你可以自定义一个用来主动和被动的扫描范围。在下面的这个例子里,Burp配置为使用主动扫描发送到 www.myapp.com的每一个请求,除了登陆请求,使用被动扫描发送到其他目的地的任何请求:
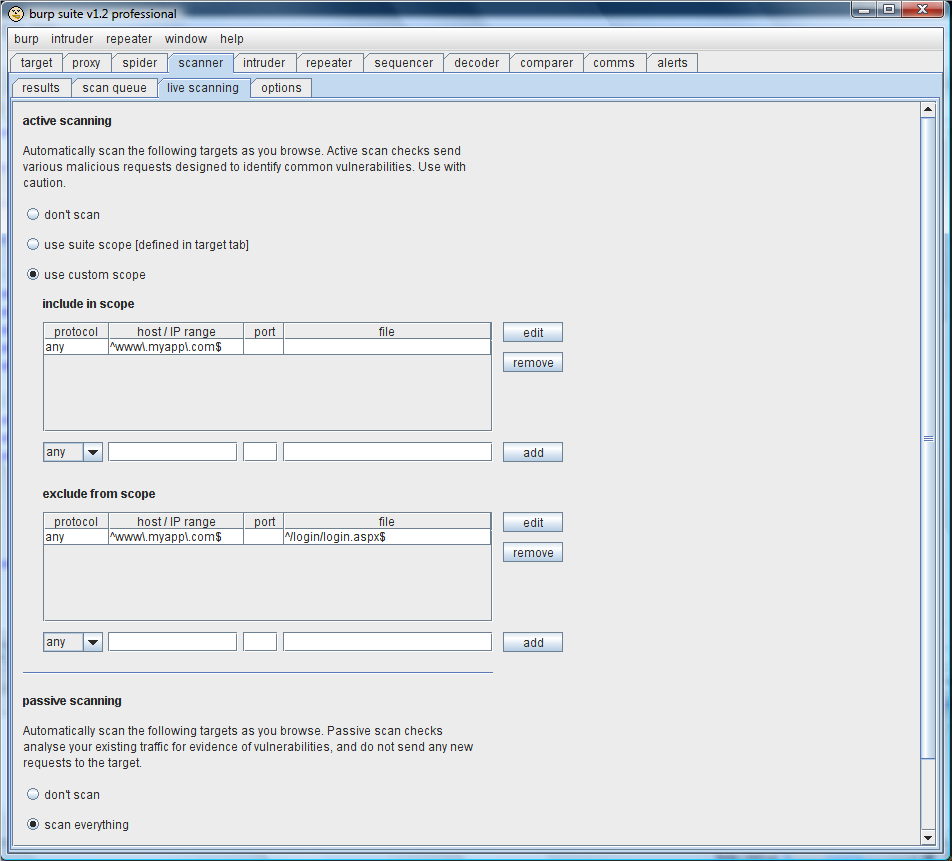
注意现场扫描会忽略对媒体(图像,等)资源的请求,在这些资源里请求不包含非 cookie参数。这些请求的静态资源几乎不会有任何安全问题,所以扫描器会忽略它们。 (这对手动扫描无效—如果你手动地选择了这样的一些项,并把它们发送到主动扫描,这时它们当然会通过正常的发送被扫描了)。
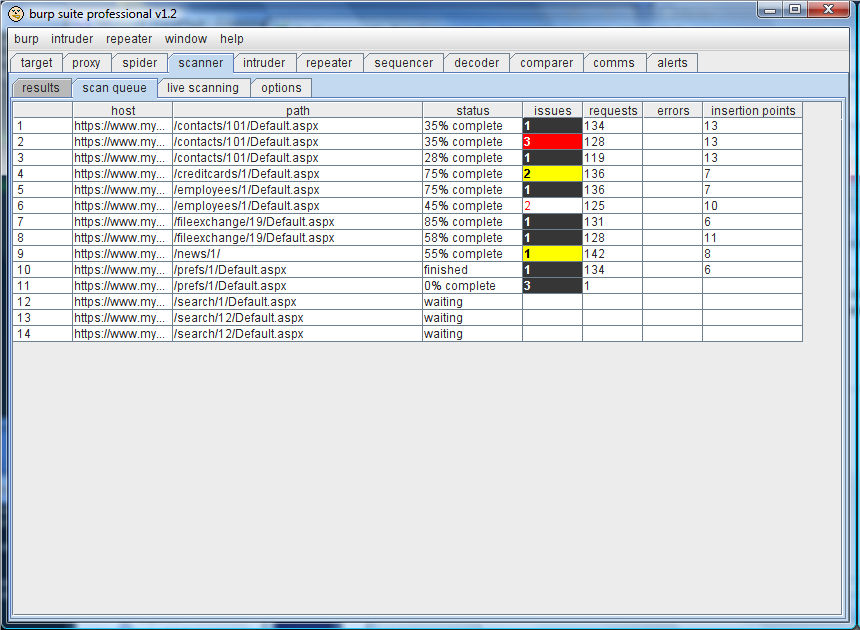
Active scan queue当你发送请求到主动扫描时,它们会被立即处理。因为主动扫描会像服务器发送大量的请求,发送的请求会被添加到一个队列里。一个有许多参数的经典请求会在 1到 2分钟内扫描完,扫描队列通过配置的线程池来扫描,所以等待扫描项的数目会变得非常大。当每一项都被扫描完时,扫描队列表会显示出它的进展——发出的请求数,完成百分比,确认的漏洞。根据接近最严重问题的可信度和严重性,把项的最后的值图成了彩色:
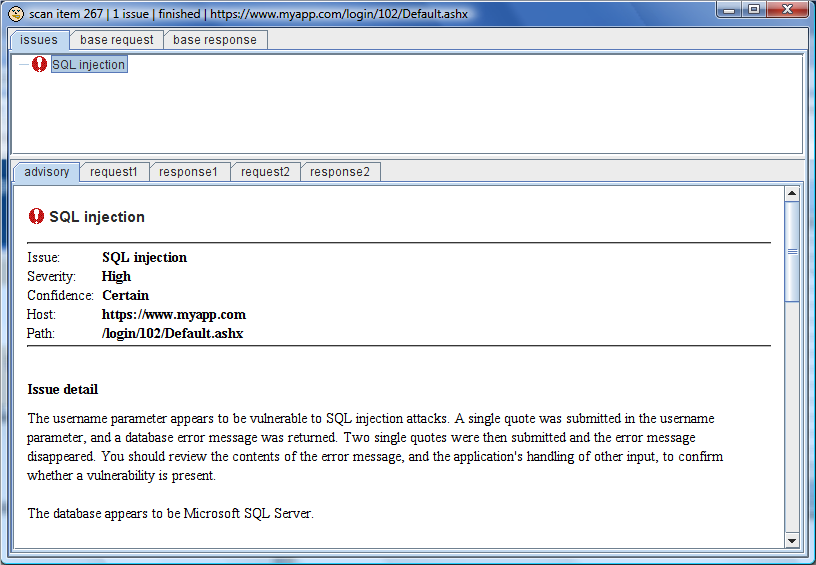
你可以双击扫描队列里那些显示已确认有问题的任何项,查看项的基础请求和响应:
你可以使用上下文菜单在扫描队列上进行许多操作:
1.显示选中项的细节。
2.取消选中的项。
3.再次扫描选中的项。
4.暂停或继续扫描器。
使用这些方法,Burp Scanner让你对它做的每事情都细微地控制着,并和其他测试操作紧紧地结合在一起。它让你设置自己感兴趣的应用程序的区域的优先权,使用现场扫描浏览它们,或者从站点地图选中它们进行扫描。它立即提供关于这些区域的反馈,来通知你的手动测试结果。
5.审查结果:
除了上面单个请求视图里发现的问题,Burp Scanner保存了一份对所有发现的问题的汇总记录,在一个目标应用程序的站点地图的视图树上显示出来。选中视图树上的一个主机或者文件夹显示出在站点上这个分支列举出的所有已确认的问题:

当发现同类型的多个问题时,这些问题会在面板的右上部汇总成一个问题。你可以展开这个汇总项来查看每个有问题的实例。在面板右上部里选中一个问题,在面板右下部里显示出这个问题的完整细节。这包含了自定义的漏洞咨询,所有相关的请求和响应,来理解和再现这个问题。
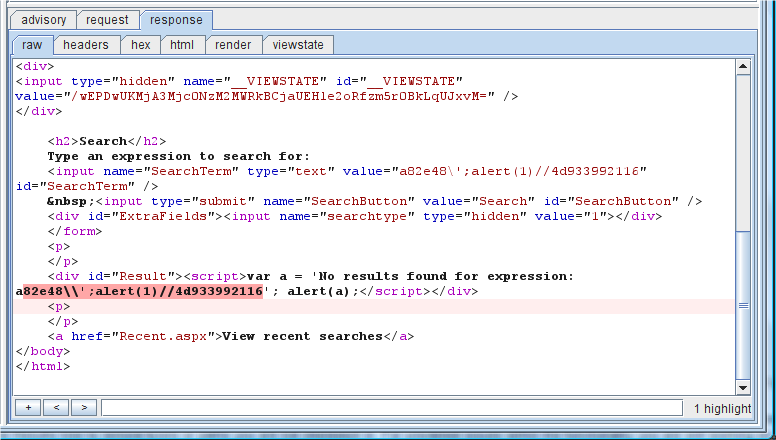
咨询包含了对了问题的标准描述和它的应对,以及这个问题特征和整治手段的描述。在上面的例子中,跨站点脚本咨询告诉我们:
1.提供了攻击输入的请求参数(搜索关键词)。
2.响应中的输入返回的上下文语法(在一个 JavaScript的片段里的一个单引号分割的字符串)。
3.这个应用程序在我们的输入中过滤了单引号字符,但是却没过滤反斜杠,这就让我们回避了过滤器。
4.Burp向应用程序提交了理论上的有效载荷,这个有效载荷的格式被返回了。
5.这个原本的请求使用的是 POST方法,Burp能把它转换成 GET方法的请求来方便地证实和发现这个问题。
Burp Scann对每一个发现的问题都给出了一个安全等级(高,中,低,信息性的)和可信度(一定,坚定,暂定)。当使用一个不太可靠的技术确认一个问题时,Burp通过降低可信度来让你注意。在咨询的旁边,Burp显示了那些用来确认问题的请求和响应,并对相关部分进行加亮。你可以查看 Burp是怎样来确认这个问题的,并能迅速地明白这个漏洞的本质。你也可以把这些请求发送到其他工具上进行手动验证这个问题,或者微调 Burp搜集的攻击理论。
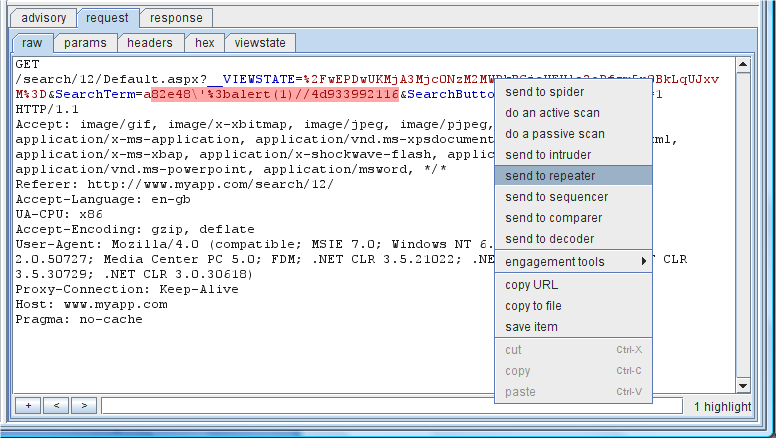
在扫描到的问题的列表里,你可以对单个或多个的安全级别和可信度进行修改 (通过上下菜单),或者集中删除问题(通过上下文菜单或使用”del”键)。
注意如果你删除一个问题,Burp重新发现同一问题(例如,如果你重新扫描同样的请求),这个问题会再次被报出。相反,如果你把这个问题标记为误判,就不会出现相同的问题了。因此,删除问题的最好办法是再结果视图树上清除那些你不感兴趣的主机或路径。对于那些你不想要问题,当你正在使用它的功能时,可以使用误判标记。
6.扫描优化:
Burp Scann会实时给提供正在执行的操作的细节信息。在扫描队列里,你可以监视每一个基础请求的扫描过程。这个表格向你显示了 Burp放置有效负荷的”插入点”的数量,以及产生的攻击请求的数量。(后者不是前者的一个线性函数,通过观察应用程序的行为来反馈到后面的请求,就和一个测试人员一样)。
这个信息让你可以快速地查看扫描进度是否太慢,以及了解其原因。通过这个信息,你可以采取一些手段来优化你的扫描。在扫描队列里一个上下文菜单,你可以使用它对单个项进行取消或者重新设置优先权。通过你对应用程序的了解,你可以使用这个选项来对扫描器进行优化。
Attack insertion points扫描速度和效率的关键因素是攻击插入点的选择。Burp让你能细微地控制着进行有效负荷攻击的基础请求的位置,这时你可以下面的配置项:
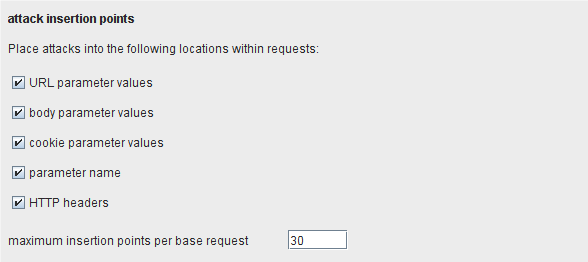
复选框让你能够定义使用 HTTP请求进行攻击的位置:
1.URL,消息体,以及 cookie参数的值。
2. Parameter name –如果被选中,Burp会添加一个参数到请求中,并且攻击参数名字的位置,如果仅仅测试过参数值,常常能探测丢失的不寻常的错误。
3.HTTP headers –如果被选中,Burp会对 User-Agent和 Referer headers的位置进行攻击,常常使用日志功能来探测 SQL注入或保存型 XSS的问题。
4. AMF string parameters –对动作消息格式的请求,Burp攻击那些基于字符串数据类型的消息。
5. REST-style URL parameters –如果被选中,Burp会攻击那些有部分 URL路径的每个目录和文件名。
你可以对 Burp在个基础请求中的攻击插入点数量设置一个限制。偶尔,HTML表单里会包含大量的区块(几百,或者更多)。如果 Burp对每个模块进行完全的漏洞扫描,这次扫描会花费大量的时间才能完成。如果你遇到表单的参数非常多时,设置一个插入点的限制数量,防止扫描止步不前。使用限制后,进入扫描队列的项就会指示出跳过的插入点的数量,让你能手动查看这些基础请求,然后决定是否值得对它的所有可能的进入点进行完整的漏洞扫描。
你可以告诉 Burp使用” intelligent attack selection”。这个选项让 Burp执行或者忽略基于每个攻击插入点基值的服务端检查。例如,如果参数的值包含有不能在文件名中正常显示的第 53页字符时,Burp会跳过这个参数的文件路径遍历检查。使用这个选项可以大大加快扫描,而且这样存在丢失实际存在的漏洞的风险也最小。
插入点配置让你指出 Burp在服务端注入检查跳过的参数。这些检查相对比较消耗时间,因为 Burp发送大量的盲目探测多种漏洞的请求。如果你认为请求里的某个参数不会产生漏洞(例如,仅仅由平台或者 web服务器使用的内置参数),你可以告诉 Burp不要测试这些。(注意客户端会检查像执行的跨站点脚本,因为如果一个参数没有问题,每个请求参数的测试会花费扫描过程中最小开销时间)
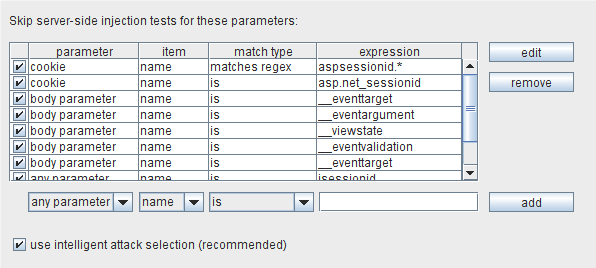
和其他值一样,你可以通过 URL路径的位置(用斜杠分开)来确认 REST参数。要这样做,在参数下拉菜单里选中”REST parameter”,在项下拉菜单选中”name”,然后指定你想排除测试的 URL路径里的位置序列号。你可以设置任意参数,Burp不会任何检查的。
为主动扫描指定完整的自定义攻击插入点是非常有可能的,所以你可以指定基础请求的任意位置来放置攻击字符串。要使用这个功能,就需要把这个相关基础请求发送到 Intruder,通过常规方式使用有效负荷位置界面来定义每个开始/结束的插入点,并选中 Intruder菜单选项里的” actively scan defined insertion points”.Active scanning engine
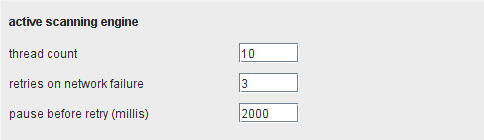
这个选项让你微调 Burp的扫描引擎,这依据应用程序的反应和自己的处理能力以及带宽。如果你发现你的扫描进度很慢,但应用程序正常,CPU使用率很低,这时你可以加大扫描线程的数量来使你的扫描更快。如果你发现有连接错误产生,应用程序开始慢下来,或者你的电脑很卡,你就应该降低线程数量,并且增加处理网络错误数量和在处理暂停的时间。如果应用程序的功能是处理一个基础请求接口和其他请求返回的响应直接的操作,你需要把线程数量降到 1,以确保每次只扫描一个基础请求。如果你想避免应用程序超载,或者保持网络上隐身,你可以使用这个阀门设置来添加固定或随机的请求间隔。
由于一些应用程序重定向到包含你提交的值的第三方 URL。Burp通过不跟踪任何接收到的重定向,保护你在不经意间会攻击第三方应用程序。如果扫描的请求是在定义的目标范围内(例如,使用目标范围来控制扫描的内容),Burp会只跟着范围内的重定向。如果请求不在范围内(例如,你可以手动执行一次对范围外请求的扫描),Burp只跟踪和已扫描的请求的主机端口一致的重定向,并且不能满足范围排除规则(如,”logout.aspx”)。
Active scanning areas
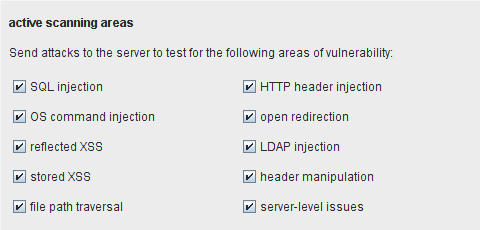
这些选项让你在主动扫描时定义执行哪些选择。每个执行的选择都会增加请求的次数和整体扫描的时间。你可以根据自己对应用程序技术的了解,打开或关闭单个选择,或者对扫描要求有多严。例如,如果你知道应用程序不使用任何 LDAP,你就可以关闭 LDAP注入测试。在对每一个插入点进行全面的漏洞检查之前,或者你可以配置 Burp在应用程序上进行一次快速的检查,只查找 URL和消息体里参数里的 SQL注入和 XSS漏洞。
Passive scanning areas
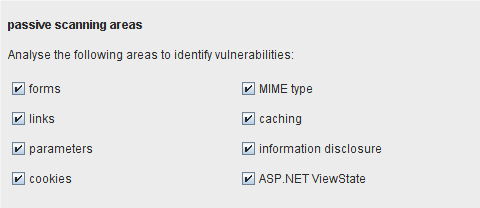
被动扫描不会发生它自己的任何请求,并且每个被动检测在电脑上的执行过程都是可以忽略不计的。不过,如果你对其中的一些项不感兴趣或者不想看到它们的扫描结果,可以使单个的选项设为不可用。
7.报告:
当你完成测试后,可以把所有的或者选中的问题以 HTML格式导出。要这样,就选中显示出的汇总结果里需要的问题(可以选中多个主机,文件夹,问题等等),然后在上下文菜单中选” report issues”。报告向导会让你为自己的报告选择许多项:
1.报告的格式(屏幕,打印)。
2.问题的描述级别和包含的建议。
3.是否显示请求和响应的细节,或者像提取的,或者不是。
4.发现的问题类别是包含的还是排除的。
5.是否通过类型,安全或者 URL来组织问题。
6.报告的标题,及其大小,等等。
跨站点脚本漏洞的报告会被优先显示出来,所有的细节都列出来了,以友好的打印格式显示出提取的应用程序响应的提取,像这样:

你也可以使用 XML格式来报告这些问题,这样能很容易地和其他工具整合在一起。XML有一个平整的结构,在每一个问题的报告中包含了问题的列表,通过 meta信息来显示问题类型,URL,等等。看起来像这样的:
<!DOCTYPE issues [ <!ELEMENT issues (issue*)> <!ATTLIST issues burpVersion CDATA ""> <!ATTLIST issues exportTime CDATA ""> <!ELEMENT issue (serialNumber, type, name, host, path, location, severity, confidence, issueBackground?, requestresponse*)> remediationBackground?, issueDetail?, remediationDetail?, <!ELEMENT serialNumber (#PCDATA)> <!ELEMENT type (#PCDATA)> <!ELEMENT name (#PCDATA)> <!ELEMENT host (#PCDATA)> <!ELEMENT path (#PCDATA)> <!ELEMENT location (#PCDATA)> <!ELEMENT severity (#PCDATA)> <!ELEMENT confidence (#PCDATA)> <!ELEMENT issueBackground (#PCDATA)> <!ELEMENT remediationBackground (#PCDATA)> <!ELEMENT issueDetail (#PCDATA)> <!ELEMENT remediationDetail (#PCDATA)> <!ELEMENT requestresponse (request?, response?)> <!ELEMENT request (#PCDATA)> <!ELEMENT response (#PCDATA)> ]>
序列号是一个对其他单个问题的不同的长整数。如果你想从同一个 Burp实例上,多次导出问题,你可以通过序列号来确认增加的新问题。
类型包含了一个用来唯一地确认查找的内容类型(SQL注入,XSS等等)的整数,在不同的 Burp实例间,这个值是稳定的。
名字包含了相应的问题类型的描述名字。
路径包含了问题的 URL(不包含查询字符串)。
位置包含了攻击进入点的 URL和描述,以及相关项(一个特殊的 URL参数,请求消息头,等等)。
其他的项,有些事可选的,用户可以通过报告向导来选择,能进行自我解释。
六、BurpSuite的攻击模块(Burp Intruder):
1.Burp Intruder是什么:
Burp Intruser是一个对 web应用程序进行自动化的自定义攻击的工具。
Burp Intruder不是一个点击工具。要想高效地使用它,你需要明白目标应用程序是怎样工作的,以及一些 HTTP协议的知识。在你使用 Burp Intruder进行攻击之前,你需要调查清楚目标应用程序的功能和结构,尤其是再浏览器和服务器直接传输的许多 HTTP消息。你可以使用标准浏览器和 Burp Proxy拦截和查看应用程序产生的请求和响应。当你确认了一些一些感兴趣的 HTTP请求需要更严格的检查时,你就已经为使用 Burp Intruder准备好。Burp Intruder是高度可配置的,并被用来在广范围内进行自动化攻击。你可以使用 Burp
Intruder方便地执行许多任务,包括枚举标识符,获取有用数据,漏洞模糊测试。合适的攻击类型取决于应用程序的情况,可能包括:缺陷测试:SQL注入,跨站点脚本,缓冲区溢出,路径遍历;暴力攻击认证系统;枚举;操纵参数;拖出隐藏的内容和功能;会话令牌测序和会话劫持;数据挖掘;并发攻击;应用层的拒绝服务式攻击。要想知道关于使用 BurpIntruder执行的这类攻击的讨论细节,可以查看 The Web Application Hacker's Handbook的第13章。Burp Intruder有许多预设的攻击”有效负荷”(在探索发现常规漏洞中有用的字符串)列表。它包含了许多工具,这些工具动态地产生适合应用程序内的特定机制的攻击载体。外部的文件也可被加载并纳入到 Burp Intruder(如,枚举用户名的列表,新发型的漏洞的模糊字符串)。
核心动作就是通过这些 HTTP请求重复地攻击。在调查阶段确认有基础请求派生的请求。Burp Intruder以特殊方式操纵这些基础请求来确认或探测应用程序漏洞。它使用一个或多个有效载荷来替换基础请求中的一部分来实现这个过程。可以为每次攻击配置时间和执行
方案。同时可以使用多线程来产生请求。限制请求可以防止入侵检测系统的探测。拒绝服务模型可以使用请求来轰炸服务器,这时会忽略所有接收到的响应。
当一次执行时,细节结果表格也就产生,显示出从服务器上接收到的每个请求的响应。结果里包含了所有的相关信息,可以使用它来查明一些感兴趣或成功的响应。除了常见的每次攻击的标准结果,在运行时可以对这些结果执行许多自定义的测试,这些结果同样被记录下来。例如,可以为 Burp Intruder精确配置指定一些 HTML页面上的信息(如,用户信息页面上的个人细节信息),并且在每个结果里记录这些信息。可以为做进一步操作导出所有结果,或者把它们当做输入文件进行下一步攻击。
Burp Intruder是一个 Java应用程序,可以在任何有 Java Runtime环境的平台上运行。它需要 1.5版本或者更新的。JRE可以免费从 java.sun.com上获得。
2.配置 Burp攻击模块( Intruder):
Burp Intruder控制面板让你在他们的数字选项里同时能配置一个或多个攻击。你可以使用 Intruder菜单创建一个新的选项或者重命名现存的选项。在一些子选项(target, positions, payloads, options)里进行每次攻击配置。创建一个新攻击的最简单的方法是通过其他 Burp工具(如代理历史记录或站点地图)定位相关的基础请求,然后使用上下文菜单里的” send to intruder”。这将会用相关的细节来填充 target和 positions选项。当你创建一个攻击选项时,可以通过 Intruder菜单来控制怎样设置 payloads和 options选项。通过这种方式,你可以在第一次攻击选项(如模糊所有参数和搜索错误消息)里设置一个标准的攻击配置,然后把这些标准复制到发送给 Intruder的每一次新攻击里。你可以使用Intruder菜单在任意选项之间复制攻击的配置,或者保存加载攻击配置。要开启一次攻击,需要设置攻击配置信息,然后在 Intruder菜单上选择” start attack”。下面的部分里描述了配置选项的细节。要加载一个保存的攻击,需在 Intruder菜单上选择” open saved attack”,然后选择需要的文件[Professional]版本。
33.目标选项:
这个选项是用来配置目标服务器的细节:
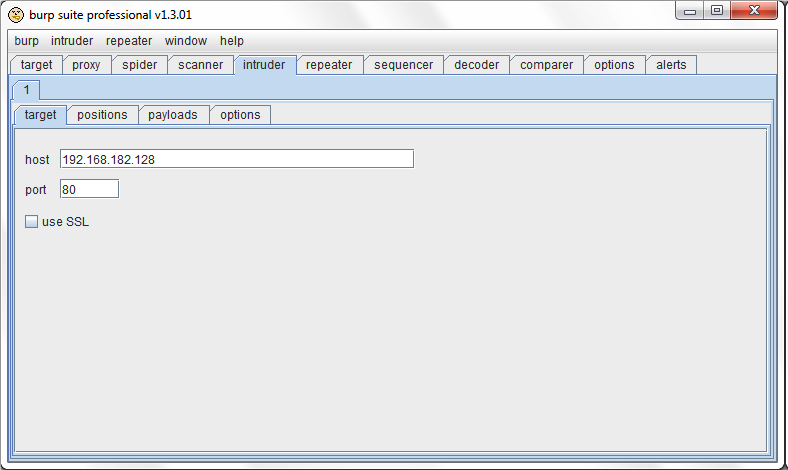
“host”区域是用来指定目标服务器的 IP地址或者主机名。”port”区域是用来指定 HTTP/S服务的端口号。”use SSL”框是用来是否使用 SSL连接。
4.位置选项:
这个选项是用来配置在攻击里产生的所有 HTTP请求的模板:
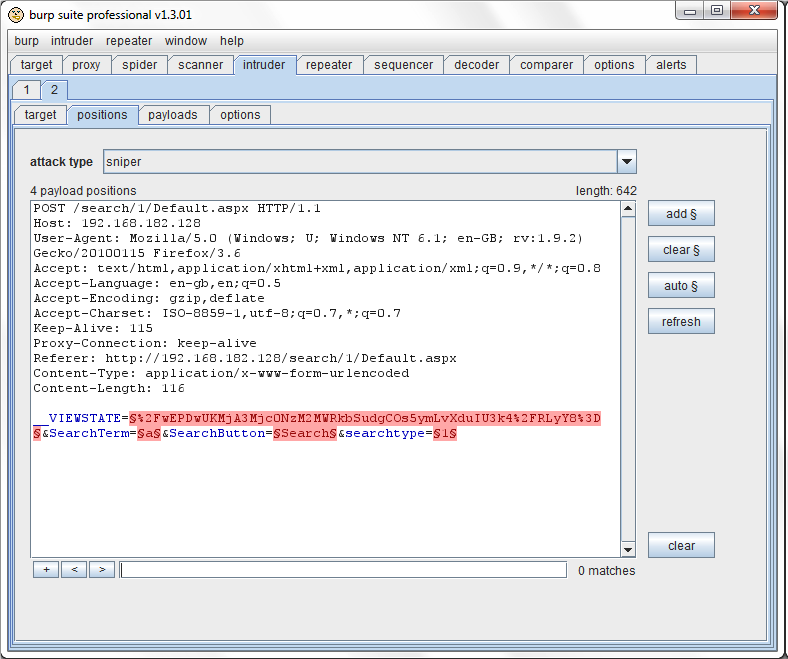
主文本编辑器是用来设置基础请求的内容,以及在攻击时,标记出有效负荷插入到单个HTTP请求的位置。这有一个有许多功能的上下文菜单。
设置攻击模板的最简单的方法是先定位出在一个其他 Burp工具里的相关请求,然后选中” send to intruder”选项。你可以从 Burp Suite里的任何显示出一个 HTTP请求或响应的地方发送请求,也可以从 Burp Proxy历史记录,站点地图里的视图树或者表格,以及从一个准备执行攻击的 Burp Intruder:
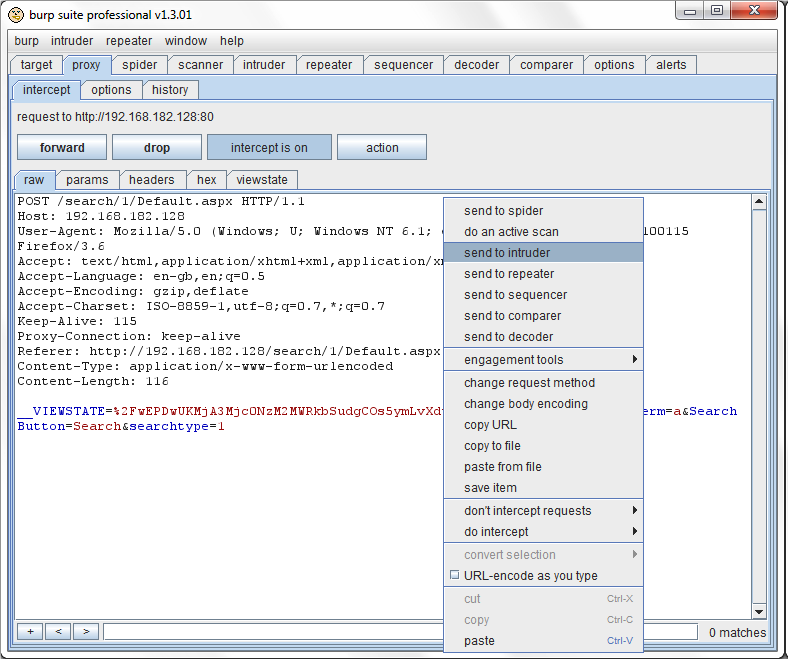
使用一对§字符来标记出有效负荷的位置,在这两个符号直接包含了模板文本的内容。当把一个有效负荷放置到一个给出的请求的特殊位置上时,就把这§符号放到这个位置,然后在两个符号之间的出现的文本都会被有效负荷替换。当有个特殊位置没有为一个给出的请求安排有效负荷时(这只适用”sniper”攻击类型—看下面),那个位置的§字符会被删除,出现在它们之间的文本不会变化。
当使用 Burp Suite发送一个其他地方的请求时,Burp Intruder会对你最想放置有效负荷的位置做一个最好的猜测,并且它把这些放置在每个 URL和主体参数的值里,以及每个cookie里。每个标记和它中间的文本都会被加亮以显得更清晰。你可以使用 Intruder菜单上的选项标记的位置是要替换还是附加现有的参数值。在上面的请求编辑器里,指出了定义位置的数量和文本模板的大小。
你可以使用选项上的按钮来控制位置上的标记:
1. add § —在当前光标位置插入一个位置标记。
2. clear § —删除整个模板或选中的部分模板里的位置标记。
3. auto § —这会对放置标记的位置做一个猜测,放哪里会有用,然后就把标记放到相应位置。这是一个为攻击常规漏洞(SQL注入)快速标记出合适位置的有用的功能,然后人工标记是为自定义攻击的。
4.refresh —如果需要,可以刷新编辑器里有颜色的代码。
5.clear —删除整个编辑器内容。
注意自动放置有效负荷位置需要识别出当前选中的请求模板内的 XML格式的数据。一些应用程序会在一个请求主体里发送封装的 XML格式的数据,如:
POST /function HTTP/1.0 Content-Type: multipart/form-data; boundary=weidhwiderfhwiuehwiuehfwerrf Content-Length: 202 --weidhwiderfhwiuehwiuehfwerrf Content-Disposition: form-data; name="data" <data> <param1>foo</param1> <param2>bar</param2> <param3>123</param3> </data> --weidhwiderfhwiuehwiuehfwerrf—
如果你在整个消息里都执行自动放置有效负荷的位置,Intruder会用单个插入点标出所有的 XML块,这些块未必都是你想要的。相反,如果你手动地选出那些 XML块,自动放置功能是识别出包含 XML的选择,并把单个 XML参数值标记为插入点。
“attack type”下拉菜单是用来定义 Burp Intruder行为的一个关键方面—为单个请求把有效负荷放置特定位置的方式。下面列出 4个可能的攻击类型:
sinper —这使用了单个有效负荷集合。它的目标是在每个位置上,并把每个有效负荷按顺序地插入到这些位置上。请求中的不是目标的位置不受影响—位置标记会被删除并且它们之间的模板里的文本不会变化。这类攻击类型对单独使用数据域来测试常规漏洞 (如,跨站点脚本)非常有效。攻击产生的大量请求是位置数量和有效负荷数量的产品。battering ram —这使用了单个有效负荷集合。它是通过有效负荷迭代,并一次在所有定义的位置插入有效负荷。当一次攻击需要在 HTTP请求(如,Cookie消息头和消息体里的用户名)中的多个位置上插入相同的有效负荷时,这个攻击类型非常有用。攻击产生的所有请求数量就是有效载荷的数量。
pitchfork —这个是用在多个有效负荷集合。在每个定义的位置有不同的有效负荷集合(最多 8个)。攻击同时通过所有的有效负荷集合进行迭代,并在每一个位置上插入一个有效载荷。例如,第一个请求会把第一个有效负荷集合里第一个有效负荷插入到第一个位置,第二个有效载荷集合里的第一个有效负荷插入到第二个位置。第二个请求会把第一个集合里的第二个有效负荷插入到第一个位置,把第二个有效负荷里的第二个有效负荷插入到第二个位置,等等。当攻击需要将不同的但相关的输入插入到 HTTP请求(如,一个数据域里的用户名,以及在其他数据域里的一个和用户名相关的 ID号)的多个位置里时,这个攻击类型会有用的。攻击产生的所有的请求数量是最小有效负荷集合里的有效负荷数。
cluster bomb—这个使用了多个有效负荷集合。每个定义的位置(最多 8个)都有一个不同的有效负荷集合。攻击会按照每个有效负荷集合的顺序进行迭代,于是所有的有效负荷排列组合都会被测试。例如,如果有 2个有效负荷位置,攻击会把第一个有效负荷集合里的第一个有效负荷放置在第一个位置,在位置 2里会迭代第二个有效负荷里的所有有效负荷;然后他会把第一个集合里第二个有效负荷放在第一个位置,然后在位置 2上迭代集合 2里的所有有效负荷。当攻击需要在 HTTP请求(如,一个参数里的用户名和另一个参数里的密码)里插入不同的并且不相关的输入时,这个攻击类型会很有效。攻击产生的请求数量是在所有定义集合里的有效负荷数量—应该是最大值。
5.有效负荷选项:
这个选项是用来配置一个或多个有效负荷的集合。如果定义了 “ cluster bomb”和”pitchfork”攻击类型,然后必须为每定义的有效负荷位置(最多 8个)配置一个单独的有效负荷。使用” payload set”下拉菜单选择要配置的有效负荷。对于每个有效负荷集合,都会定义一个有效负荷 “源”(如,preset list, character blocks,brute forcer)来使用,并且在每个有效负荷上执行多种附加的处理。在 Burp Intruder中有大量的可用的有效负荷源。其中的一些是高度可配置的,并且提供了许多自定义攻击。通过下拉菜单为当前有效负荷选中源。每个有效负荷源在下面都一一介绍。
6.有效负荷源
Preset list
这是一个简单的有效负荷源,配置有效负荷的预设列表:
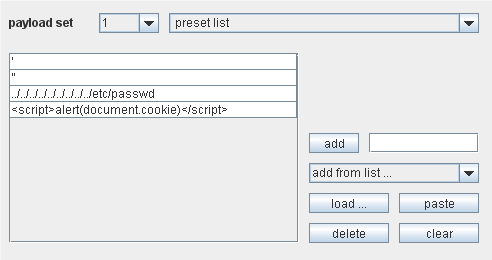
配置列表的主控制台在面板的右下方。可以通过文本框和”add”按钮手动地添加项。可以通过下拉菜单” add from list”来添加有用的有效负荷预设列表,包括常用的用户和密码,以及用来探测像 SQL注入的这样常规漏洞的字符串。”load”按钮是用来导入文件的。”paste”按钮式用来添加粘贴板上的列表项。 “delete”按钮删除选中的项,”clear”按钮删除列表里的所有项。
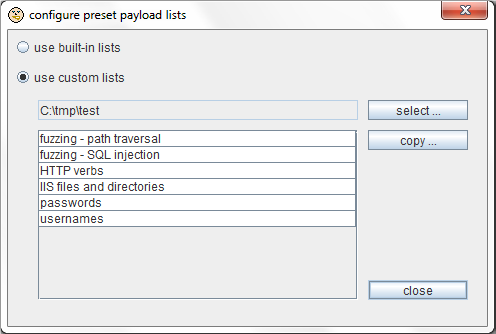
你可以通过” add from list”菜单自定义有效负荷的预设列表。首先,选择 Intruder菜单里的” configure preset payload lists”,然后选择你自己的包含有效负荷文件的目录。你可以使用”copy”按钮把 Burp的内置有效负荷列表复制到你自定义的目录,和你的有效负荷列表一起使用:
Runtime file
这个有效负荷源配置了一个外面的文本文件,在运行时可以通过这个文件读取里面的有效负荷。当需要一个非常大的预设有效负荷列表时,这很有用了,避免了把整个列表都放到内存里。从文件里的一行读取一个有效负荷,因此有效负荷不会包含换行符。

Custom iterator
这个有效负荷源提供了一种强大的方式,通过给出的模板,来产生自定义的字符和其他项的排列。例如,使用表单里个人编号 AB/12,工资应用程序来识别单个人员;你需要通过迭代所有的人员编号来获取所有个人细节。
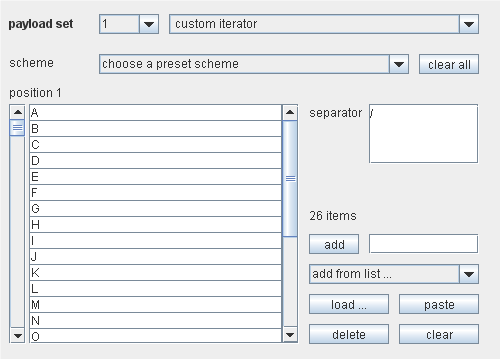
自定义的迭代器定义的用来产生排列的位置不能超过 8个。每个位置使用一个列表来配置,以及一个可选的分隔符,这个分隔符是被插入到那个位置和下一个之间。在上面的例子中,位置 1和 2是用 A-Z项来配置,位置 3和 4用 0-9项来配置,并且位置 2会被设置分隔符/。当执行攻击时,自定义的迭代器会迭代每个位置里的项,以覆盖到所有的排列可能。
因此,在这个例子中,有效负荷的总数量等于 26*26*10*10.“scheme”下拉菜单用来为自定义迭代器选择一个预设的配置。这些可以被许多标准的攻击或者自定义攻击的修改使用。可用的 scheme有”目录/文件扩展名”,这些可以被用来枚举web内容,”密码+数字”可以为密码猜测攻击提供一个扩展的字符列表。
在右下方得控制按钮是用来配置每个位置上的项。他们的功能和在 preset list source中一样。”clear”按钮是删除自定义迭代器上所有位置里配置。
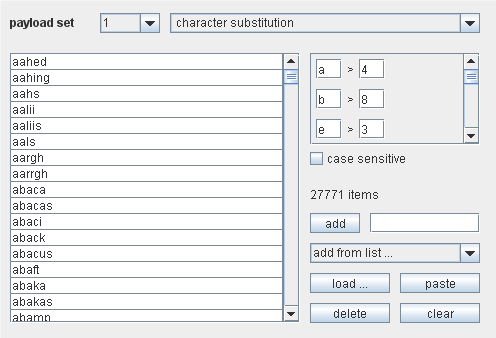
Character substitution
这个有效负荷源需要一个有效负荷项的预设列表,在自定义规则下,通过用不同字符把替换项里的单个字符,然后从这些项里产生许多有效负荷。这个有效载荷源在密码猜测攻击中很有用。例如,在字典单词上产生许多变化:
在右下方的控制项是用来配置预设项的列表。它们的功能和上面的一样。右面的复选框列表是用来配置提交规则。当攻击执行时,字符提交源会按顺序地处理每个预设项。对于每个项,它都会产生一些有效负荷,来包含通过提交规则提交的字符的所有排列。例如,对于上面截图里的第一个项,就会产生下面的有效负荷:
aahed
4ahed
a4hed
44hed
aah3d
4ah3d
a4h3d
44h3d
Case substitution
这个有效负荷源需要一个有效负荷项的预设列表,调整每一项里的字符,从这些项里产生出一个或多个有效负荷。这个有效负荷源在猜测密码攻击时,会很有用。例如,在字典单词上产生许多变化:
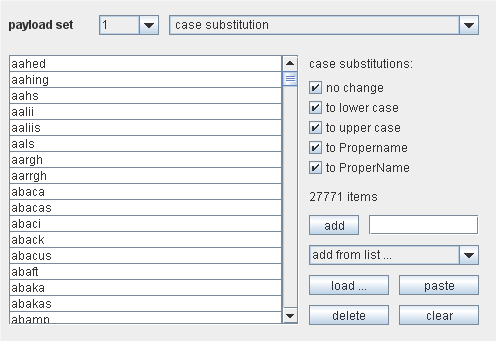
右下方得控制项是用来配置预设项的列表。它的功能和上面的一样。
右边的复选框是用来配置提交规则。可用的规则执行下面的功能:
no change —这个项是让不要修改有效负荷集合。
to lower case —所有的字母被转换成小写的,并且结果添加到有效负荷集合。
to upper case —所有的字母被转换成大写的,并且结果添加到有效负荷集合。
to Propername —项里的第一个字母转换成大写,后面的字母转换成小写,结果添加到有效负荷集合。
to ProperName —项里的第一个字母转换成大写,后面的字母不变,结果添加到有效负荷集合。
当攻击执行时,提交源会按顺序执行每一个预设项。对于每个项,它都会使用选中的提交规则产生一个有效负荷。如果这个规则产生了一个全新的有效负荷,它就会被加到有效负荷集合里(如,重复的有效负荷会被丢弃)。例如,对于上面截图里的第一个项,就会产生下面的有效负荷:
aahed
AAHED
Aahed
Recursive grep
这个有效负荷源带有”extract grep”功能(下面会介绍)。它允许通过对早期请求的响应来递归地产生有效负荷。”extract grep”功能会通过匹配一个正则表达式来捕获一个服务器响应的一部分。和"recursive grep"一起,从先前的服务器响应捕获的文本将用作后续请求的有效负荷。
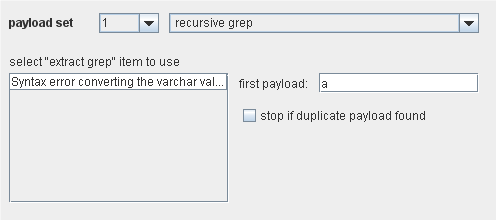
这可以用在许多的枚举任务里。例如,可以用来通过 SQL注入来枚举数据库的内容,递归查询格式为:
union select name from sysobjects where name>'a'
服务器的错误信息会泄露一个数据库对象的名字:
Syntax error converting the varchar value 'accounts' to a column of data type int.
使用” accounts”,再查询确认下一个对象。使用 recursive grep有效负荷可以简单地自动执行这个任务,进而快速地枚举出数据库里的所有对象。有效负荷里使用的第一个请求必须是手动指定的。当重复连续地发现 recursive grep项时,就可以停止了,因为这就说明了枚举已经完成。注意由于有效载荷的本质属性,使用它的攻击就不能进行多线程请求。
Illegal Unicode这个有效负荷源需要一个有效负荷项的预设列表,在每一项里用指定字符的非法Unicode编码替换字符本身,从这些项里产生出一个或者多个有效负荷。在尝试回避基于模式匹配的输入验证时,这个有效负荷会有用的,例如,在防御目录遍历攻击时../和\..序列的期望编码的匹配。
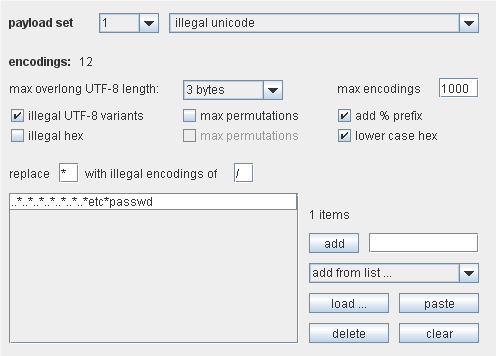
右下方的控制项是用来配置预设项的列表。它的功能和上面的一样。顶端的 2个文本框是来配置在每个预设项里提交的字符(*那里),以及为非法编作基础的字符(/那里)。可以通过字母的 ASCII编码或者 2位十六进制编码来指定这个字母—这对于指定那些无法打印的字符是很有用的,如空字符。
中间的控制项是用来产生非法编码的类型。在下面解释:
maximum overlong UTF-8 length Unicode编码方案允许最多使用 6字节表示一个字符。使用一种类型就可以正确地表示出 (0x00-0x7F) Basic ASCII字符。然而,使用多字节的Unicode方案也能表示出它们(如,”overlong”编码)。下拉菜单用来指定是否使用超长编码,以及应该设定的最大使用型号。
illegal UTF-8 variants如果选择的最大超长 UTF-8长度为 2字节以上,这个选项是可用的。当使用多字节编码一个字符时,第一个字节后面的字节应该用 10XXXXXX这样的二进制格式,来指出后续的字节。然而,第一个字节里最有意义的位会指出后面还有多少后续字节。因此,Unicode编码例程会安全地忽略掉后续字节的前 2位。这就意味着每个后续字节可能有 3个非法变种,格式为 00XXXXXX,01XXXXXX和 11XXXXXX。如果选中这个选项,则非法 Unicode有效负荷源会为每个后续字节生成 3个附加编码。
max permutations如果选择的最大超长 UTF-8长度为 3字节以上,这个选项可用,并且选中” illegal UTF-8 variants”。如果” max permutations”没被选中,则在生产非法变种时,非法 Unicode有效负荷源会按顺序处理每个后续字节。为每个后续字节产生 3个非法变种,并且其他的后续字节不会改变。如果” max permutations”被选中了,然而,非法 Unicode有效负荷源会为后续字节生成所有的非法变种排序—如,多个后续字节会同时被修改。在目标系统上回避高级模式匹配控制时,这个功能就会很有用。
illegal hex这个选择基本上一直可用。当使用超长编码和后续字节的非法变种(如果选中)生成非法编码项列表时,通过修改由此产生的十六进制编码可能会迷惑到某种模式匹配控制。十六进制编码使用字符 A—F代表十进制 10—15的值。然而有些十六进制编码会把 G解释为 16,H为 17,等等。因此 0x1G会被解释为 32。另外,如果非法的十六进制字符使用在一个 2位数的十六进制编码的第一个位置,则由此产生的编码就会溢出单个字节的大小,并且有些十六进制编码只使用了结果数字的后 8个有效位,因此 0x1G会被解码为 257,而那时会被解释为 1。每个合法的 2位数的十六进制编码有 4—6种相关的非法十六进制表示,如果使用的是上面的编码,则这些表示会被解释为同一种十六进制编码。如果”illegal hex”被选中,则非法 Unicode有效负荷源会在非法编码项列表里,生成每个字节的所有可能的非法十六进制编码。
max permutations如果选中的最大超长 UTF-8长度为 2字节以上并且” illegal hex”也被选中,则这个选项可用。如果” max permutations”没被选中,在生成非法十六进制编码时,非法 Unicode有效负荷源会按顺序处理每个字节。对于每个字节,会生成 4—6个非法十六进制编码,其他的字节不变。如果” max permutations”被选中,然而,非法 Unicode有效负荷源会为所有的字节,生成非法十六进制的所有排序—如,多个字节会被同时修改。在目标系统上回避高级模式匹配控制时,这个功能会非常有用。
add % prefix如果选中这个选项,在产生的有效负荷里的每个 2位数十六进制编码前面,都会插入一个%符号。
lower case hex这个选项决定了是否在十六进制编码里使用大小写字母。
max encodings这个选项为会产生的非法编码数量放置了一个上界。如果大量使用超长编码或者选中了最大排序,这个选项会很有用,因为那会生成大量的非法编码。当攻击执行时,这个有效负荷源会迭代所有预设项列表,在非法编码集合里,每个预设项替换每个项里的指定字符的所有实例。
Character blocks
使用一个给出的输入字符串,这个有效负荷源产生指定大小的字符块。在对本机 (非托管)上运行的软件进行探测缓冲区溢出和其他边界条件漏洞时,这个选项很有用。
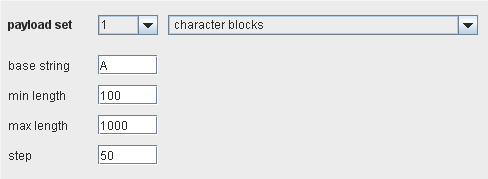
“string”字段指定了输入字符串,从这里产生字符块。”min”和”max”字段指定了产生字符块的最小和最大长度。”step”字段指定了每个字符块的长度增量。
Numbers
这个有效负荷产生的数字,是顺序的或者随机的,使用一个指定的格式:
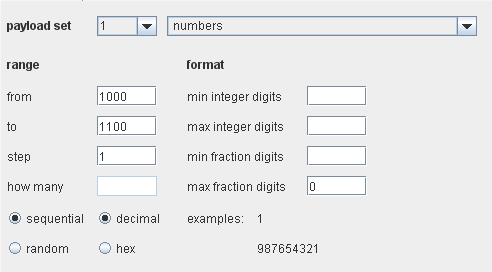
“from”和”to”字段指定了产生的最小和最大的数。如果选中” sequential”,数字就以”from”字段里的值作为起点,以” step”字段里的值做为增量。如果选中” random”,”howmany”字段指定生成数字的数量。数字是以十进制或者十六进制的格式生成。如果选中十六进制,则”form”,”to”以及”step”字段必须是十六进制整数;否则是十进制的整数或分数。在右手边的控制项指定了要用到的数字格式。Dates这个有效负荷在一个指定的范围内,在一个指定的间隔内,以一个指定的格式,产生日期。这个选项在数据挖掘(拖出在不同天里的订单条目)或者暴力攻击(猜测一个由生日组成的用户认证)中有用。
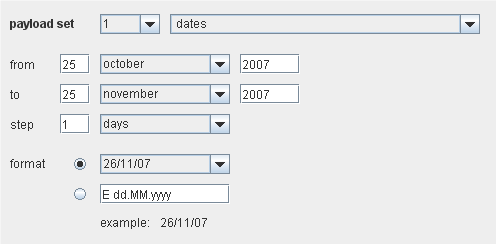
产生的日期是从”from”控制项里指定的日期开始,使用”step”控制项里指定的间隔来增加,直到或者包含了”to”控制项里的指定日期。在”format”下拉菜单里可以选择一些预设的日期格式,或者自定义一个可以在文本字段里输入的日期格式。下面的例子说明了可以用来指定自定义的日期格式的编码:
E Sat
EEEE Saturday
d 7
dd 07
M 6
MM 06
MMM Jun
MMMM June
yy 03
yyyy 2003
/ . : etc
/ . :
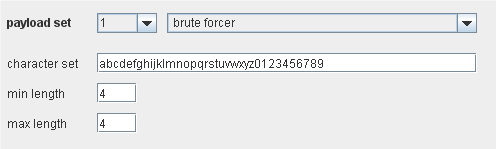
Brute forcer
这个有效载荷源产生一个指定长度的有效载荷集合,这里面包含了指定字符集的所有排序可能。
Null payloads
这个有效载荷源能产生”null”有效载荷—如,0长度的字符串。它可以产生一个指定数量的空有效载荷,也可一直继续下去。
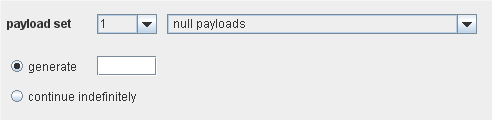
当一次攻击需要重复同一请求,而不是做修改的基础模板,这个有效载荷就有用了。要完成这个工作,把一对位置标记一起放在请求模板的一个位置。这个可以在许多攻击中使用,例如测序分析中获取 cookie,应用层的拒绝服务攻击,这里通过重复发送请求以在服务器上执行一个超载任务,保持一个用在其他地方进行断断续续测试的会话令牌。Char frobber
这个有效载荷是在每个有效载荷位置现有基值或者知道的字符串上进行操作的,它通过一次一个字符,在基类字符串上循环,把那个字符 ASCII码加 1。
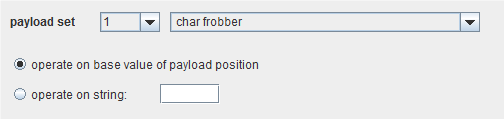
当测试参数值或部分值哪个更影响应用程序的响应,这个有效载荷源就有用了。特别是在测试复杂的会话令牌的哪一部分实际上是用来跟踪会话状态的。如果你修改会话令牌里的单个字符的值后,在你的会话里,请求仍然能被处理,则就有可能是这个字符不是用来跟踪你的会话的。
Bit flipper
这个有效载荷是在每个有效载荷位置现有基值或者知道的字符串上进行操作的,它通过一次一个字符,在基类字符串上循环,翻转顺序上的每(指定的)一位。
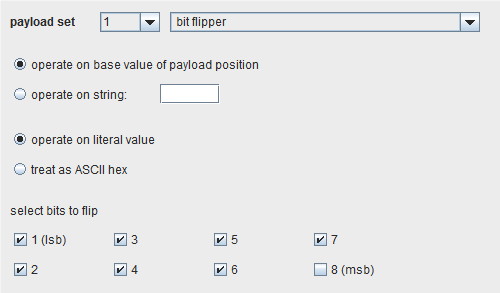
你可以配置位翻转要么为了操作字面基础值,要么把基础值当成 ASCII十六进制字符串。例如,如果基础值是”ab”,则通过字面字符串操作和翻转所有的位,产生下面的有效载荷:
`b
cb
eb
ib
qb
Ab
!b
áb
ac
a`
af
aj
ar
aB
a"
aâ
如果是”ab”当做一个 ASCII十六进制字符串,然后翻转所有位,就得到下面有效载荷:
aa
a9
af
a3
bb
8b
eb
2b
这个有效载荷源非常有用在对 char frobber相似的情况下,但你需要有细微控制权。例如,如果一个会话令牌或者其他参数值包含一个有意义的数据,但这个数据使用了一种 CBC模式密码加密了,就由可能通过修改前面密码块里的位来系统地改变部分加密数据。在这种情况下,你可以在有效载荷源上使用位翻转来确定修改加密值里的单个位的影响,弄清楚应用程序是否有漏洞。
Username generator
这个有效载荷源需要人名作为输入,使用许多常规方案来产生用户名。
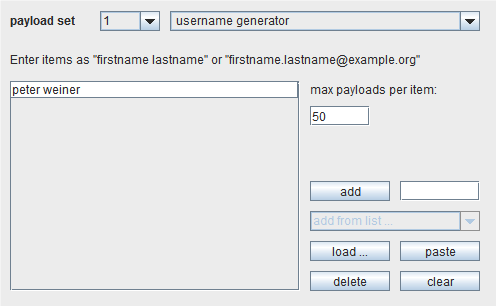
例如,提供”peter weiner”这个名字,就会产生 115个可能的用户名,如下:
peterweiner
peter.weiner
weinerpeter
weiner.peter
peter
weiner
peterw
peter.w
wpeter
w.peter
pweiner
p.weiner
weinerp
weiner.p
。。。
如果你的目标是一个特殊人物的用户,这个有效载荷源就有用了,并且你不知道应用程序里使用的用户名或电子邮件地址方案。
有效载荷的处理(Payload processing)
对于每个有效载荷集合,除了使用有效载荷的”源”,在每个有效载荷上可能执行定义的许多附加处理过程。选中有效载荷源执行所有操作后,这个处理过程就开始了:
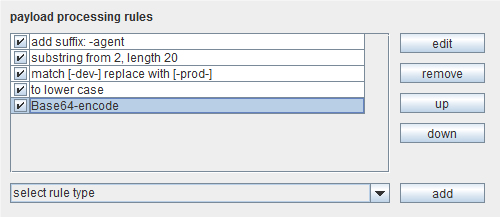
执行队列中的定义规则,并且通过切换开关来帮助排除配置中的问题。可用下面类型的
规则:
1.添加前缀
2.添加后缀
3.匹配/替换
4.子字符串(从一个指定的偏移到一个指定的长度)
5.转换子字符串(从有效载荷的结尾索引的子字符串)
6.修改状况(一些为 case substitution的有效载荷源选项)
7.编码(URL,HTML,Base64,ASCII十六进制以及多平台的组合字符串)
8.解码(URL,HTML,Base64,ASCII十六进制以及多平台的组合字符串)
9.哈希表
10.添加原来的有效负荷(如果你需要在同一个有效载荷里包含原来的和哈希格式,这会有用)。
最后,你可以配置最终的有效载荷里的字符,把它进行 URL编码,这样在 HTTP请求里更安全地传输。

建议使用最终的 URL编码配置,而不是一个有效载荷过度规则。因为 payload grep选项是用来在使用最终的 URL编码之前为显示的有效载荷检查响应。
选项卡(Options tab)
这个选项里包含了许多配置控制着单个攻击行为的选项。

如果选中”update Content-Length header”框,Burp Intruder会使用每个请求的 HTTP主体长度的正确值,添加或更新这个请求里 HTTP消息头的内容长度。这个功能对一些需要把可变长度的有效载荷插入到 HTTP请求模板主体的攻击是很有必要的。这个 HTTP规范和大多数 web服务器一样,需要使用消息头内容长度来指定 HTTP主体长度的正确值。如果没有指定正确值,目标服务器会返回一个错误,也可能返回一个未完成的请求,也可能无限期地等待接收请求里的进一步数据。
如果选中”set Connection: close”框,则 Burp Intruder会添加或更新 HTTP消息头的连接来请求在每个请求后已关闭的连接。在多数情况下,这个选项会让攻击执行得更快。注意:早期的 Burp Intruder版本在这里包含往请求里添加 cookie头的选项,这是依据不同请求的响应。现在这些配置被删除了,你可以使用 suite-wide session handling support来代替。
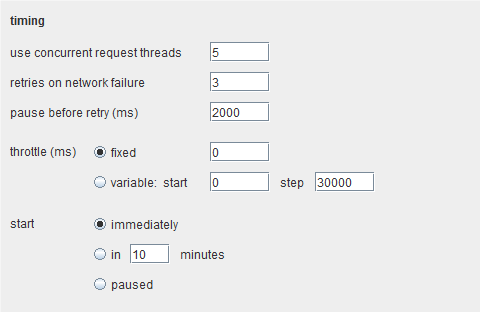
concurrent threads设置决定了攻击是否使用单线程或多线程来同步地加载请求。使用多线程能迅速地加快一次大型攻击,影响时间的主要因素就是处理请求和接收响应之间的延时。这可以用来测试应用程序漏洞的并发处理。这也可用来增加应用层拒绝服务的效果。retry设置决定了如果产生网络错误(如,连接被拒绝或超时),Burp会重发一个请求的次数,以及等待的时间间隔。
throttle设置用来配置请求之间需要的延时。可能会需要一个固定的延时作为隐形的防护措施,来保留带宽和处理能力,以避免影响其他活动,这样就可以定期执行请求操作,如保持一个断断续续地用在其他地方测试的会话令牌存活。一个可变的延时会对自动探测会话超时值很有用。
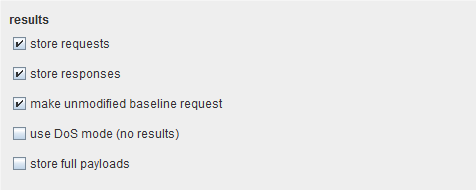
start设置决定了攻击在加载时是否立即执行,或者在一个指定的延时后开始,或者一直等到选中”恢复”命令。如果配置的一个攻击需要在一些未知点上执行,或者为以后的使用保存,那么这个功能就有用了。
storage设置决定了攻击是否会保存单个请求和响应的内容。保存请求和响应需要在消耗临时目录里的磁盘空间,但能让你在攻击时完整地查看它们,如果需要可以重复发请求,也可以把它们发送到其他 Burp工具上。
如果选中”make unmodified baseline request”,这时除了配置攻击请求,Burp还会除了模板请求,使用所有有效载荷位置来设置它们的基础值。这样请求在结果表格里会以#0项显示出来。
如果选中”DoS mode”,则攻击会和平常一样地处理请求,但不会等待处理服务器返回的响应。当每个请求都处理完后,关闭 TCP连接。这个功能可以通过重复地发送请求,使服务器执行超负荷任务,来对有漏洞的应用程序执行应用层的拒绝服务攻击。如果选中”store full payloads”,Burp会完整地保存每一个结果的有效载荷值。这个选项会消耗一些内存,如果你想在运行时执行某种操作,这个就可能是需要的了,如修改有效载荷的 grep设置,重新处理一个使用修改请求模板的请求。
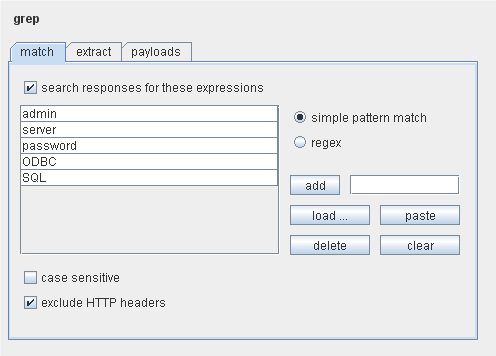
“grep”设置是用在运行时,配置在服务器响应里执行的模式匹配测试。这有 3种测试类型:
1. match grep —这个是用来检查每个服务器响应里指定表达式,要么简单的模式匹配,要么 Perl—like正则表达式。对于每个指定的表达式,攻击会在结果表里包含一个列来指明是否找到一个匹配。基本功能有广泛的应用,例如:密码猜测攻击,扫描”密码错误”或者”登陆成功”的短语,SQL注入漏洞测试,扫描包含”ODBC”“error”的消息,等等。如果使用正则表达式来匹配表达式,可能会包含换行符。
2. extract grep —这个是用来检查每个服务器响应里指定表达式,是否存在紧随匹配表达式的要提取的文本(知道指定的符号或者最大长度)。对于每个指定的表达式,攻击都在结果列表里包含一个从服务器响应里提取的文本的列。这个功能可以用来进行数据挖掘,通过数据挖掘能获得 web页面里的有用信息,并且需要一个提取这些信息的自动化方法。例如,如果你获得了一个通向管理员用户的页面,通过它能够修改由 URL查询字符串指定的 ID的用户的账户信息,这时重复地通过用户 ID来提取每一位用户的用户名和密码。
3. payload grep —这个是用来检查每个服务器响应中的用在相关请求中的有效载荷字符串。这个功能在探测跨站点脚本和其他响应注入漏洞中会有用。这漏洞产生在用户把输入动态插入到应用程序的响应里。
如果选中”match against pre-encoded payloads”,则会搜索响应里的每一个应用编码之前的有效载荷字符串的原来格式。设置的这些常常都是很有必要的,例如,如果你使用 XSS测试有效载荷里的印刷字符,这通常需要在有效载荷处理选项里的 URL编码,但如果应用程序有漏洞,就会在响应里显示出每个编码格式。
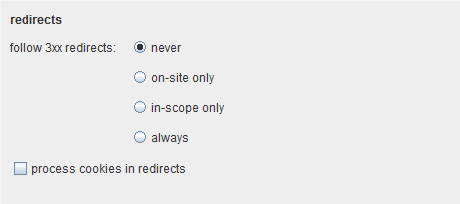
这重定向设置控制了 Burp Intruder在执行攻击时,是否跟踪 HTTP重定向(如,有 3xx状态码和包含一个新 URL的 Location header)。如果配置跟踪重定向,则 Intruder在接收到一个重定向时,会请求这个重定向 URL(如果需要,最多跟踪 10个重定向),并在结果里记录下后续响应的细节。在结果表格的一个列里会显示是否为每个结果跟踪重定向。你可以配置是否只跟踪站点(如,相同协议,主机和端口)重定向,或者只跟踪范围内(在目标范围定义的)重定向,或者跟踪所有的。
当一个应用程序对许多类型的输入都返回一个 3XX的响应,这个跟踪重定向的选项就会有用,在请求重定向目标时,会返回应用程序处理请求的感兴趣的特征。例如,当使用模糊技术测试常规漏洞时,应用程序会频繁地返回一个到错误页面的重定向,这个页面可能包含了关于错误本质的有用信息,通过这个错误能诊断出像 SQL注入这样的问题。
注意在跟踪重定向时,大多数情况下,要使用单线程进行攻击,例如,如果应用程序存储了下一个指向重定向目标的请求返回的会话信息。同样要注意自动地跟踪重定向有时会给你的攻击带来一些麻烦—例如,一些应用程序会对一些恶意请求响应到一个注销页面的重定向,这时跟踪重定向会导致你的会话终止,然而它不来不应该这样做。
如果选中”process cookies in redirects”,当跟踪重定向上时,任意设置为 3XX响应 cookie都会被提交。例如,当你尝试暴力进行登录挑战时,通过重定向页面来指示登录结果,并且每次的登录尝试都会有创建一个新的会话,这个就需要这个选项了。
启动一次攻击(Launching an attack)
为了创建一次新的攻击,使用控制面板选项来设置需要的配置信息,然后选择 Intruder菜单上的”start attack”。要想加载一个保存的攻击,选择 Intruder菜单上的”open saved attack”,然后选择所需的文件。
当执行一次新的攻击时,会在指定的配置信息上执行许多验证审查。这包括验证有效载荷位置和有效载荷集定义是否正确,时序和 grep设置是否可行,等等。有些故障会产生一些阻碍执行攻击的错误;产生的其他警告则会被忽略。
每次攻击都打开了一个分离的窗口。这个窗口显示出攻击产生的结果,使你能够实时修改攻击配置,同样也包含了的一系列控制选项,有保存结果,服务器响应和攻击自身。注意:当修改一个正在运行的攻击配置时,你应该小心地处理,在修改之前最好暂停。
结果选项(Results tab)
下面显示的就是一次执行的攻击的结果视图例子,在目标 web站点上枚举的基本内容:
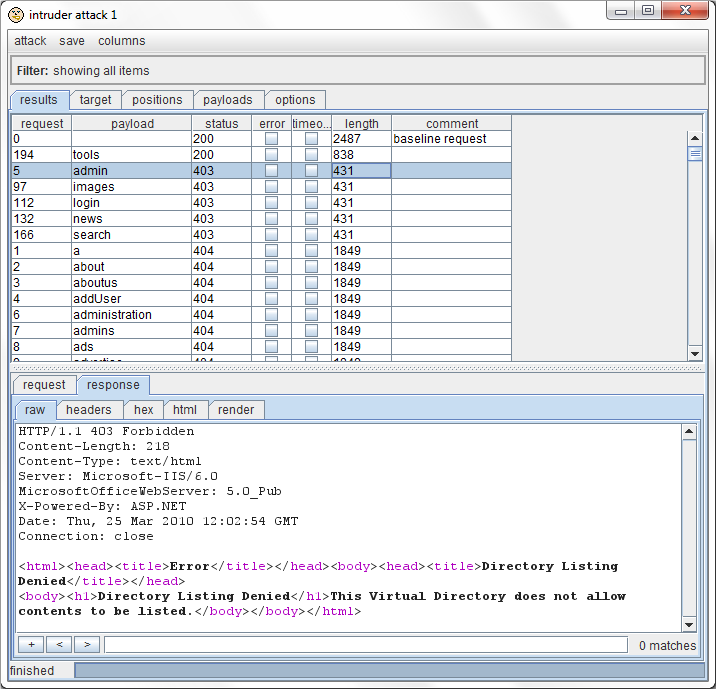
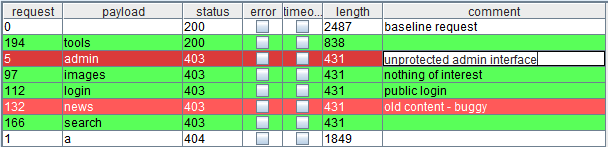
这次攻击使用了 sniper攻击类型,对一系列常用的 web目录进行请求。对于这次攻击,结果视图显示了默认的每次请求次数,使用的有效载荷位置,插入的有效载荷,从服务器上接收的 HTTP状态码,是否产生了超时或错误,以及服务器响应的长度。附加的结果列显示了,每个请求的"received response"和"finished response"计时器,以及接收到的 cookie。许多配置选项,如 grep功能,这会让附加列在结果视图里显示出来。使用”view”菜单来隐藏和显示这些列。通过单击结果列的相关标题头,来对整个结果集进行排序(按住 shift单击可以转换排序方式)。按住 Ctrl+单击标题可以复制该列的内容。[专业版]
一个对攻击结果进行有效解释的关键部分,定位在感兴趣或成功的服务器响应,以及产生这些响应的请求。通常情况下感兴趣的响应分为下面几种:
1.一个不同的 HTTP状态码。
2.一个不同长度的响应。
3.某个表达式存在或不存在。
4.一个错误或超时的产生。
5.接收或完成响应的时间。
例如,在一个探索内容的测试中,请求一个现存的资源,会返回一个长短不一的”200OK”的响应,然而请求一个不存在的资源时,会返回一个”404 not found”的响应,或者返回一个包含固定长度的自定义出错页面。在一次密码猜测攻击中,登陆失败会产生一个包含关键字”login failed”的”200 OK”的响应,然而成功的登陆会产生一个”302 Object moved”的响应,或者一个包含关键字”welcome”的不同长度的”200 OK”的响应。
Burp Intruder可以提供一些帮助来确认上面的那些区别。grep功能可以用来标记那些已知关键字的响应,或者从页面的关键部分提取感兴趣的信息。在结果视图里,可以通过单击列标题来对结果排序,或者按住 shift+点击标题来倒置排序。在上面的例子里,HTTP状态码是感兴趣结果的主要区别,并且可以通过排序查明这些。
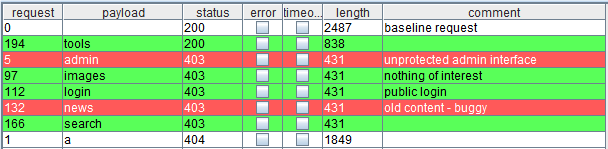
你可以通过添加批注和加亮来注释一个或多个项:
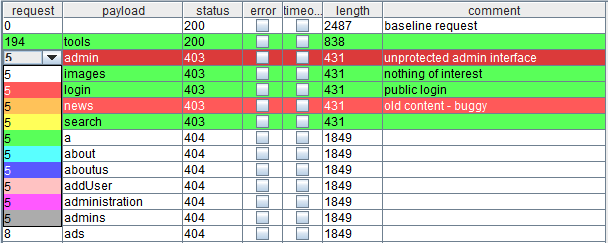
你可以使用最左边度的列表里的下拉菜单来加亮单个项:
你可以通过双击并编辑单元格就地对单个项进行注释:
当你已经注释好感兴趣的请求时,以后你就可以使用列排序和显示过滤器来快速地找到这些项。
如果攻击被配置为保存请求或/和响应,你就可以通过预览表格来查看这些,或者通过双击来显示这些请求和响应的细节。这些显示提供了细节分析和呈现出每个 HTTP消息。"previous"和"next"按钮可以用来循环结果集。如果结果视图里的表已被排序,则结果会以当前序列显示在那个视图里。

如果攻击是被配置来跟踪重定向,在初始清求和最后响应的旁边,所有的中间响应和请求都会被显示出来。
如果你使用”action”按钮来发送请求或响应到其他 Burp Suite工具里,如 Repeater。你可以在结果表里的项上右击来显示一个有许多选项的上下文菜单:
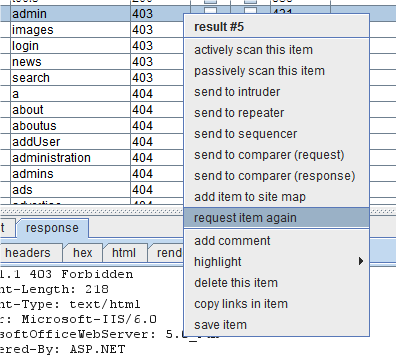
你可以发送选中的项到其他工具,添加多个项到 Suite站点地图上,使用批注和加亮来注释这些项,或者把项标记为重新请求。如果网路错误或其他问题影响了一些结果,这个选项就会有用了。如果你在攻击时修改了一些基础请求模板或者其他的项,如果可以,要被重发的请求会使用当前的配置进行重组。于是,例如,如果你的应用程序会话在攻击中被部分地终止了,你可以修改基础会话模板使用一个新的会话令牌,并重新处理任何失败的请求,使用你的新会话来执行。
在结果表的顶端是一个过滤栏,你可以使用它来隐藏一些结果,有 HTTP状态码,搜索项,以及用户使用的注释:
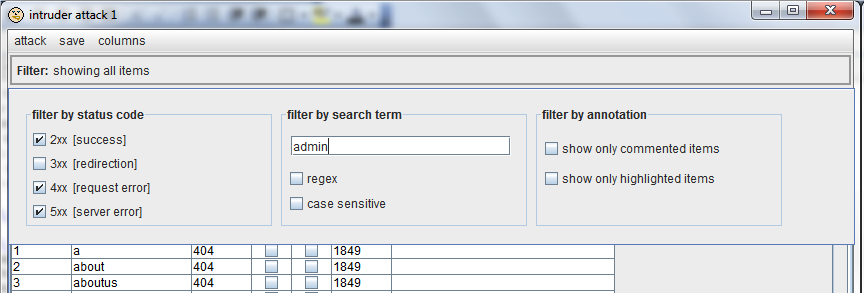
和过滤器一样,通过选中结果表里的一个或多个项,然后选择上下文菜单里的”delete”,你可以永久地删除结果里的项。
7.结果菜单:
结果视图里包含了许多有控制攻击命令的菜单,和保存结果,服务器响应和攻击自身。它们将在下面为大家介绍。
8.攻击菜单:
这里包含了暂停,继续,重复攻击的指令。
9.保存菜单:
attack—这个是用来保存当前攻击的一个副本以及结果。从 Burp Intruder控制面板里,加载保存文件作进一步使用。
results table —这个是用来把结果列表保存为一个文本文件。可以选择单个的行或列,以及整个表来保存。可以配置区域分隔符。这个功能是用于把结果导出到一个电子表格上作进一步分析,或者保存单个列(如使用提取 grep功能)到一个输入文件里,用于作进一步攻击或者其他工具上。
server response —这个是用来保存接收到的服务器对请求作出的完整响应。这些可以到自己的文件(按顺序编号)里,也可以串联到序列里的单个文件。attck configuration—这是用来保存当前执行攻击(不是结果)的配置,使你能够加载那个配置到 Intruder主控制面板来配置出一个相同或相似的攻击。
10.视图菜单:
这包含了查看或隐藏结果表里的每个可用的数据列 (这些列的可用性取决于当前攻击的配置)。
若希望更多的了解BurpSuite的介绍,请访问第四篇(渗透测试之BurpSuite工具的使用介绍(四)):https://www.cnblogs.com/zhaoyunxiang/p/16001087.html