在了解 TCP 的基本机制后本文继续介绍 Linux 内核提供的链接队列、TW_REUSE、SO_REUSEPORT、SYN_COOKIES 等机制以优化生产环境中遇到的性能问题。
连接队列Linux 内核会维护两个队列:
- 半连接队列: syn_backlog, 服务端收到了 SYN 但未回复的连接, 队列的大小通过 net.ipv4.tcp_max_syn_backlog 指定
- 全连接队列: accept_backlog, 三次握手完成但未调用 accept 的连接, 队列的大小为 min(net.core.somaxconn, backlog), 其中 backlog 是
listen(int sockfd,int backlog)函数的参数
队列满后服务器会丢弃溢出的连接会导致的情况:
- 半连接被丢弃后,客户端 SYN 会超时,客户端将重新尝试建立连接
- 全连接被丢弃后,客户端认为连接存在,服务端认为不存在。客户端使用此连接发送数据包后服务端可以返回 RST (reset) 要求重置连接或者设置定时任务重传服务端SYN/ACK给客户端。
全连接队列溢出时服务器根据 net.ipv4.tcp_abort_on_overflow 参数决定如何处理:
- 当 tcp_abort_on_overflow=0,服务端丢弃三次握手的ACK保持在 SYN_RECV 状态,设置一个定时任务重传服务端 SYN/ACK 包, 最大重试次数由 tcp_synack_retries 配置决定
- 当 tcp_abort_on_overflow=1:服务端直接返回RST,要求重置连接
上述参数配置可以通过 sysctl -w 命令进行修改,例如:sysctl -w net.core.somaxconn=32768。机器重启后使用 sysctl -w 进行的修改会丢失,若需要持久化配置可以在 /etc/sysctl.conf 文件中增加一行 net.core.somaxconn= 4000 , 然后运行 sysctl -p 使修改生效。
连接队列溢出会导致无法与服务器建立新连接或者客户端出现大量 connection reset by peer 错误。
使用netstat -s | grep overflowed 可以检查是否出现全连接队列溢出的情况:
# netstat -s | grep overflowed
11451 times the listen queue of a socket overflowed
上面的输出表示某个 listen 状态的 socket 全连接队列溢出了 11451 次。这个数字是个累计值,可以多执行几次来判断溢出次数是否在上升。
使用 netstat -s | grep SYNs | grep dropped 可以检查是否出现半连接队列溢出的情况:
# netstat -s | grep SYNs | grep dropped
32404 SYNs to LISTEN sockets dropped
上面的输出表示有 32404 次 SYN 被丢弃,这个数字同样是累计值。
tw_reuse 和 tw_recycle我们之前提到 time wait 状态会持续 60s, 过多 TIME_WAIT 状态的连接会占用非常有限的 TCP 端口导致无法建立新的连接。
net.ipv4.tcp_max_tw_buckets 参数控制系统中 TIME_WAIT 状态连接的最大数量。默认值是 NR_FILE*2,并且会根据系统的内存容量被调整。
检测 TIME_WAIT 是否过多
TIME_WAIT 状态的连接过多会在 dmesg 内核日志中报错: kernel: TCP: kernel: TCP: time wait bucket table overflow.
使用 netstat 命令可以查看各状态连接数:
#netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
CLOSE_WAIT 36
ESTABLISHED 35
TIME_WAIT 173
awk 命令不好记可以直接 wc 数行数:
# netstat -n | grep 'TIME_WAIT' | wc -l
172
在正式介绍 tw_reuse 和 tw_recycle 之前我们先来介绍它们依赖的 tcp_timestamps 机制。
TCP 最早在 RFC1323 中引入了 timestamp 选项, timestamp 有两个目的:一是更精确地估算报文往返时间(round-trip-time, RTT) 二是防止陈旧的报文干扰正常的连接。
在引入 timestamps 机制之前,tcp 协议栈通过发送数据包和收到 ACK 的时间差来计算 RTT,在出现丢包时这一计算方式会出现问题。比如第一次发送的时间为 t1, 重传包的时间是 t2, 发送方在 t3 收到了 ack, 由于不知道这个 ack 包是确认第一个数据包还是确认重传包我们也无法确定 RTT 是 t3 - t2 还是 t3 - t1。
在设置 net.ipv4.tcp_timestamps=1 之后, 发送方在发送数据时将发送时间 timestamp 放在包里面, 接收方在收到数据包后返回的ACK包中将收到的timestamp返回给发送方(echo back),这样发送方就可以利用收到 ACK 包的时间和 ACK 包中的echo back timestamp 确定准确的 RTT。
TCP 序列号采用 32 位无符号整数存储,SEQ 在达到最大值后会从 0 开始再次递增,这种循环被称为序列号回绕。由于回绕现象存在ACK和重传机制无法通过序列号唯一确定数据包,从而导致错误。
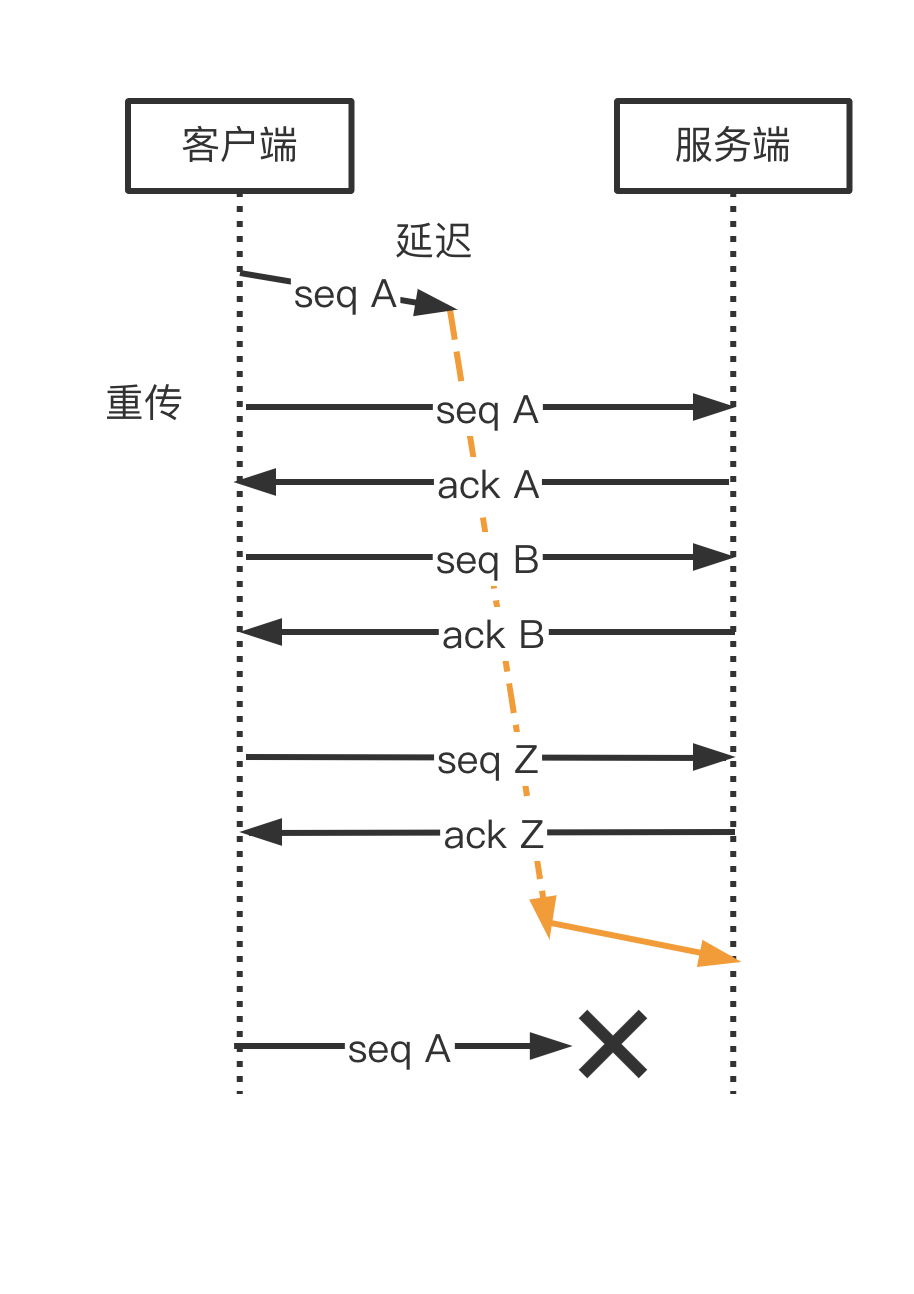
上图中由于回绕出现了两个 SEQ=A 的包,接收方把上一次循环的 SEQ A 当做了当前的 SEQ A 丢弃了正常的数据包导致数据错误。
PAWS (Protection Against Wrapped Sequences,即防止序号回绕)就是为了避免这个问题而产生的,在开启 tcp_timestamps 选项情况下,一台机器发的所有 TCP 包都会带上发送时的时间戳,PAWS 要求连接双方维护最近一次收到的数据包的时间戳(Recent TSval),每收到一个新数据包都会读取数据包中的时间戳值跟 Recent TSval 值做比较,如果发现收到的数据包中时间戳不是递增的,则表示该数据包是过期的,就会直接丢弃这个数据包。
tw_reuse开启 net.ipv4.tcp_tw_reuse 后客户端在调用 connect() 函数时,内核会随机找一个 time_wait 状态超过 1 秒的连接给新的连接复用,所以该选项只适用于连接发起方。
开启 tw_reuse 之后,tcp 协议栈通过 PAWS 机制来丢弃属于旧连接的数据包。因此必须打开 net.ipv4.tcp_timestamps 之后 tw_reuse 才会生效。
tw_recyclenet.ipv4.tw_recycle 同样利用 timestamp 来丢弃上一个连接的数据包从而不需要在 time_wait 状态等待太长时间即可关闭连接。
在打开 tw_recycle 后会自动启动 per-host paws 机制, 即对「对端 IP 做 PAWS 检查」,而非对「IP + 端口」四元组做 PAWS 检查。在开启 NAT 了网络中, 客户端 A 和 B 通过同一个 NAT 网关与服务器建立连接。 在服务器看来他们的 ip 地址相同,若 B 的 timestamp 比 客户端 A 的 小,那么由于服务端的 per-host 的 PAWS 机制的作用,服务端就会丢弃客户端主机 B 发来的 SYN 包。
由于 ipv4 地址紧张目前大多数设备均通过 NAT 接入网络(比如你的电脑和路由器), 所以在生产环境开启 tw_recycle极度危险。在 Linux 4.12 版本后,直接取消了 tw_recycle 参数。
SO_REUSEADDR 和 SO_REUSEPORT在调用 bind 后可以使用 setsockopt 函数为 socket 设置 SO_REUSEPORT 或 SO_REUSEADDR 选项。
SO_REUSEADDR因为服务进程关闭时服务器主动关闭了连接,进程关闭后有一些 Socket 处于 TIME_WAIT 状态,导致服务端重启后无法 bind 并 listen 原端口。
服务端在 bind 时设置 SO_REUSEADDR 则可以忽略 TIME_WAIT 状态的连接,重启后直接 bind 成功。SO_REUSEADDR 的作用仅限于让服务器重启后立即 bind 成功, 对性能无改善。
SO_REUSEPORTSO_REUSEPORT 允许多个进程同时监听同一个ip:port。SO_REUSEPORT 允许多进程监听同一个端口避免只有一个 listen 进程成为系统的性能瓶颈,随着 CPU 核数的增加系统吞吐量会线性增加。
主进程创建 socket、bind、 listen 之后,fork 出多个子进程,每个进程都在同一个 socket 上调用 accept 等待新连接进入:
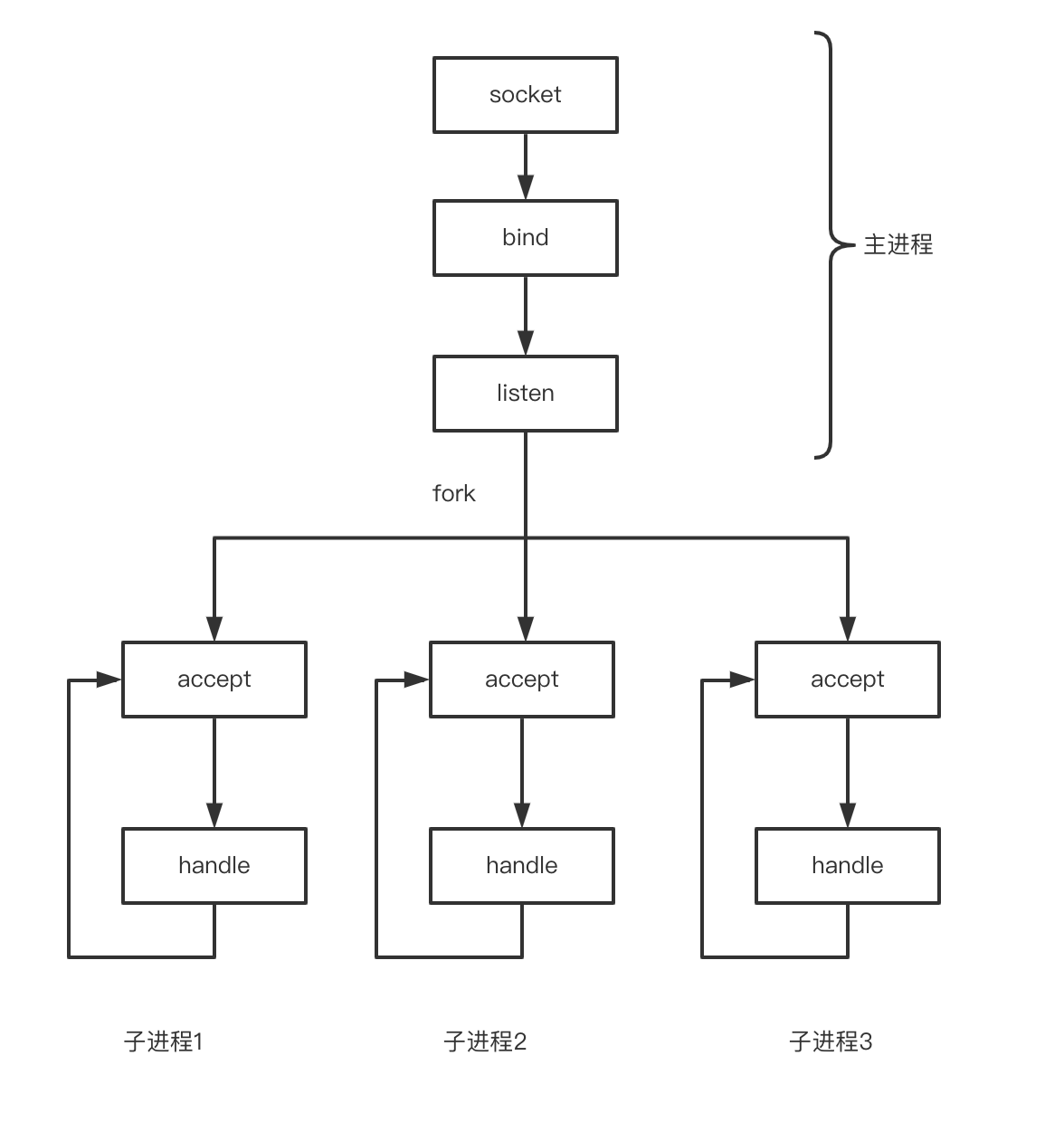
这一模型利用了多核CPU的优势但仍有两个缺点:
- 单一 listener工作进程会成为瓶颈, 随着核数的扩展,性能并没有随着提升
- 很难做到CPU之间的负载均衡
在 Linux 3.9 引入 SO_REUSEPORT 之后允许多个进(线)程 listen 同一个端口,因此我们可以先 fork 多个进程然后在每个子进程中进行创建 socket、bind、listen、accept。 内核会负责在多个 CPU 之间进行负载均衡, 也解决了单一 listener 称为系统瓶颈的问题。
syn cookies我们在前面提到当服务端收到来自客户端的 SYN 报文之后会向客户端回复 SYN + ACK 并将连接放入半连接队列中。若攻击者大量发送 SYN 报文服务端的半连接队列很快就会占满,导致服务器无法继续接收连接从而无法正常提供服务。这种攻击方式称为 SYN 洪泛(SYN Flood)攻击, 是一种典型的拒绝服务攻击方式。
syn cookies 的原理是服务端在握手过程中返回 SYN+ACK 后不分配资源存储半连接数据,而是根据 SYN 中的数据生成一个 Cookie 值作为自己的起始序列号。在收到客户端返回的 ACK 后通过其中的序列号判断 ACK 的合法性。由于建立连接的时候不需要保存半连接,从而可以有效规避 SYN Flood 攻击。
TCP连接建立时,双方的起始报文序号是可以任意的, SYN Cookies 利用这一特性构造初始序列号:
- 设t为一个缓慢增长的时间戳(典型实现是每64s递增一次)
- 设m为客户端发送的SYN报文中的MSS选项值
- 设s是连接的元组信息(源IP,目的IP,源端口,目的端口)和t经过密码学运算后的Hash值
则初始序列号n为:
- 高 5 位为t mod 32
- 接下来3位为m的编码值
- 低 24 位为s
客户端收到服务端的 SYN+ACK 后会向服务器返回 ACK, 且报文中ack = n + 1。接下来,服务器需要对 ack - 1 进行检查判断 t 是否超时以及 s 是否被篡改。若报文有效,则从中取出 mss 值建立连接。
SYN Cookies 同样存在一些缺点:
- MSS的编码只有3位,因此最多只能使用 8 种MSS值
- 服务器必须拒绝客户端SYN报文中的其他只在SYN和SYN+ACK中协商的选项,原因是服务器没有地方可以保存这些选项,比如Wscale和SACK
Linux 的 net.ipv4.tcp_syncookies 配置项可以开启 syn cookies 功能:
- 0表示关闭SYN Cookies
- 1表示在新连接压力比较大时启用SYN Cookies
- 2表示始终使用SYN Cookies