客户端应用程序在运行过程中可能会产生错误,例如调用服务端接口超时、客户端处理业务逻辑发生异常、应用程序突然闪退等。这些异常信息都是会产生日志记录的,并通过上报到指定的日志服务器进行压缩存储。 本篇博客以一个应用实时日志分析平台作为案例来讲述ELK(ElasticSearch、LogStash、Kibana)在实际业务中的具体用法,让读者能够从中理解ELK适用的业务场景及实现细节。
2.内容在传统的应用场景中,对于这些上报的异常日志信息。通常适用Linux命令去分析定位问题,如果日志数据量小,也许不会觉得有什么不适。假若面对的是海量的异常日志信息,这时还用Linux命令去逐一查看、定位,这将是灾难性的。需要花费大量的时间、精力去查阅这些异常日志,而且效率也不高。 因此,构建一个应用实时日志分析平台就显得很有必要。通过对这些异常日志进行集中管理(包括采集、存储、展示),用户可以在这样一个平台上按照自己的想法来实现对应的需求。
1.自定义需求用户可以通过浏览器界面访问Kibana来制定不同的筛选规则,查询存储在ElasticSearch集群中的异常日志数据。返回的结果在浏览器界面通过表格或者JSON对象的形式进行展示,一目了然。
2.命令接口对于周期较长的历史数据,如果不需要可以进行删除。在Kibana中提供了操作ElasticSearch的接口,通过执行删除命令来清理ElasticSearch中无效的数据。
3.结果导出与共享在Kibana系统中,分析完异常日志后可以将这些结果直接导出或者共享。Kibana的浏览器界面支持一键式结果导出与数据分享,不需要额外的去编写代码来实现。
2.1 架构与剖析搭建实时日志分析平台涉及到的组件有ElasticSearch、LogStash、Kibana、Kafka,它们各自负责的功能如下:
- ElasticSearch:负责分布式存储日志数据,给Kibana提供可视化的数据源;
- LogStash:负责消费Kafka消息队列中的原始数据,并将消费的数据上报到ElasticSearch进行存储;
- Kibana:负责可视化ElasticSearch中存储的数据,并提供查询、聚合、图表、导出等功能;
- Kafka:负责集中管理日志信息,并做数据分流。例如,Flume、LogStash、Spark Streaming等。
将日志服务器托管的压缩日志统计收集到Kafka消息队列,有Kafka实现数据分流。通过LogStash工具消费Kafka中存储的消息数据,并将消费后的数据写入到ElasticSearch进行存储,最后通过Kibana工具来查询、分析ElasticSearch中存储的数据,整个体系架构如图10-17所示。
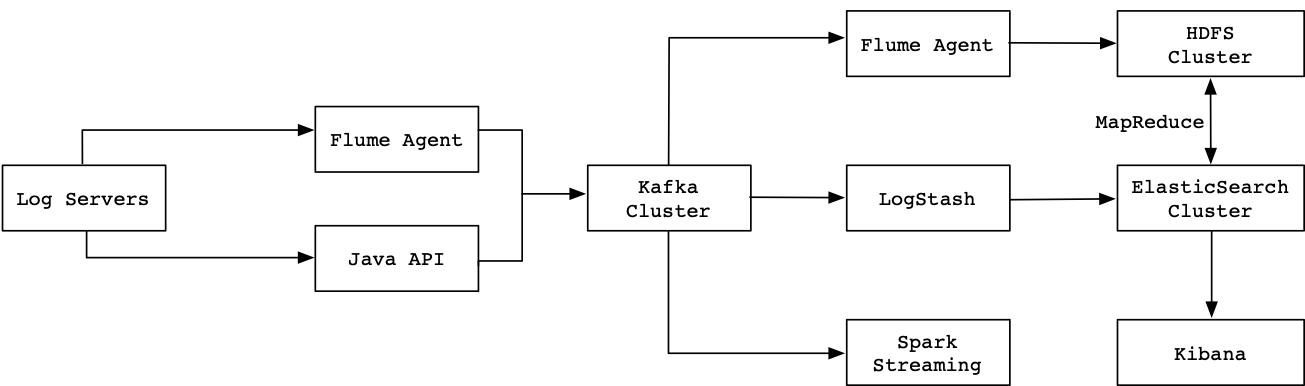
数据源的收集可以采用不同的方式,使用Flume Agent采集数据则省略了额外的编码工作,使用Java API读取日志信息则需要额外的编写代码来实现。
这两种方式将采集的数据均输送到Kafka集群中进行存储,这里使用Kafka主要是方便业务拓展,如果直接对接LogStash,那么后续如果需要使用Spark Streaming来进行消费日志数据,就能很方便的从Kafka集群中消费Topic来获取数据。这里Kafka起到了很好的数据分流作用。
实时日志分析平台可以拆分为几个核心模块,它们分别是数据源准备、数据采集、数据分流、数据存储、数据查看与分析。在整个平台系统中,它们执行的流程需要按照固定的顺序来完成,如下图所示。

a. 数据源准备
数据源是由异常压缩日志构成的,这些日志分别由客户端执行业务逻辑、调用服务端接口这类操作产生。然后将这些日志进行压缩存储到日志服务器。
b. 数据采集
采集数据源的方式有很多,可以选择开源的日志采集工具(如Apache Flume、LogStash、Beats),使用这些现有的采集工具的好处在于省略了编码工作,通过编辑工具的配置文件即可快速使用,缺点在于针对一些特定的业务场景,可能无法满足。
另外一种方式是使用应用编程接口(API)来采集,例如使用Java API读取待采集的数据源,然后调用Kafka接口将数据写入到Kafka消息队列中进行存储。这种方式的好处在于对于需要的实现是可控的,缺点在于编码实现时需要考虑很多因素,比如程序的性能、稳定性、可扩展性等。
c. 数据分流
在一个海量数据应用场景中,数据采集的Agent是有很多个的,如果直接将采集的数据写入到ElasticSearch进行数据存储,那么ElasticSearch需要同时处理所有的Agent上报的数据,这样会给ElasticSearch集群服务端造成很大的压力。
因此需要有个缓冲区来缓解ElasticSearch集群服务端的压力。这里使用Kafka来做数据分流,将Agent上报的数据存储到消息队列。然后在通过消费Kafka中的Topic消息数据后存储到ElasticSearch集群中,这样不仅可以缓解ElasticSearch集群服务端的压力,而且还能提高整个系统的性能、稳定性、扩展性。
d. 数据存储
这里使用ElasticSearch集群来作为日志最终的存储介质。通过消费Kafka集群中的Topic数据,按照不同的索引(Index)和类型(Type)存储到ElasticSearch集群中。
e. 数据可视化
异常日志数据落地在ElasticSearch集群中,可以通过Kibana来实现可视化功能。用户可以自定义规则来查询ElasticSearch集群中的数据,并将查询的结果以表格或者JSON对象形式输出。同时,Kibana还提供了一键导出功能,将这些查询的结果从Kibana浏览器界面导出到本地。
1. 数据源采集
这里通过Apache Flume工具将上报的异常日志数据采集到Kafka集群进行存储。在日志服务器部署一个Flume Agent进行数据采集,Flume配置文件所包含的内容见如下代码:
# 设置代理别名 agent.sources = s1 agent.channels = c1 agent.sinks = k1 # 设置收集方式 agent.sources.s1.type=exec agent.sources.s1.command=tail -F /data/soft/new/error/logs/apps.log agent.sources.s1.channels=c1 agent.channels.c1.type=memory agent.channels.c1.capacity=10000 agent.channels.c1.transactionCapacity=100 # 设置Kafka接收器 agent.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink # 设置Kafka的broker地址和端口号 agent.sinks.k1.brokerList=dn1:9092,dn2:9092,dn3:9092 # 设置Kafka的Topic agent.sinks.k1.topic=error_es_apps # 设置序列化方式 agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder # 指定管道别名 agent.sinks.k1.channel=c1
然后在Kafka集群上使用命令创建名为“error_es_apps”的Topic,创建命令如下所示:
# 创建Topic,3个副本,6个分区 [hadoop@dn1 ~]$kafka-topics.sh --create –zookeeper\ dn1:2181,dn2:2181,dn3:2181 --replication-factor 3\ --partitions 6 --topic error_es_apps
接着启动Flume Agent代理服务,具体命令如下所示:
# 在日志服务器上启动Agent服务 [hadoop@dn1 ~]$ flume-ng agent -n agent -c conf -f $FLUME_HOME/conf/flume-kafka.properties\ -Dflume.root.logger=DEBUG,CONSOLE
2. 数据分流
将采集的数据存储到Kafka消息队列后,可以供其他工具或者应用程序消费来进行数据分流。例如,通过使用LogStash来消费业务数据并将消费后的数据存储到ElasticSearch集群中。
如果LogStash没有按照X-Pack插件,这里可以提前安装该插件。具体命令如下所示:
# 在线安装 [hadoop@nna bin]$ ./logstash-plugin install x-pack # 离线安装 [hadoop@nna bin]$ ./logstash-plugin install file:///tmp/x-pack-6.1.1.zip
安装成功后,在Linux控制台会打印日志信息,如下图所示:

然后,在logstash.yml文件中配置LogStash的用户名和密码,具体配置内容见代码:
# 用户名 xpack.monitoring.elasticsearch.username: "elastic" # 密码 xpack.monitoring.elasticsearch.password: "123456"
最后配置LogStash的属性,连接到Kafka集群进行消费。具体实现内容见代码:
# 配置输入源信息 input{ kafka{ bootstrap_servers => "dn1:9092,dn2:9092,dn3:9092" group_id => "es_apps" topics => ["error_es_apps"] } } # 配置输出信息 output{ elasticsearch{ hosts => ["nna:9200","nns:9200","dn1:9200"] index => "error_es_apps-%{+YYYY.MM.dd}" user => "elastic" password => "123456" } }
在配置输出到ElasticSearch集群信息时,索引建议以“业务名称-时间戳”来进行命名,这样做的好处在于后续删除数据的时候,可以很方便的根据索引来删除。由于配置了权限认证,索引需要设置用户名和密码。 配置完成后,在Linux控制台执行LogStash命令来消费Kafka集群中的数据。具体操作命令如下所示:
# 启动LogStash消费命令
[hadoop@nna ~]$ logstash -f $LOGSTASH_HOME/config/kafka2es.conf
如果配置文件内容正确,LogStash Agent将正常启动消费Kafka集群中的消息数据,并将消费后的数据存储到ElasticSearch集群中。 启动LogStash Agent之后,它会一直在Linux操作系统后台运行。如果Kafka集群中Topic有新的数据产生,LogStash Agent会立刻开始消费Kafka集群中的Topic里面新增的数据。
3. 数据可视化
当数据存储到ElasticSearch集群后,可以通过Kibana来查询、分析数据。单击“Management”模块后,在跳转后的页面中找到“Kibana-Index Patterns”来添加新创建的索引(Index)。在添加完成创建的索引后,单击“Discover”模块,然后选择不同的索引来查询、分析ElasticSearch集群中的数据
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
联系方式:邮箱:smartloli.org@gmail.com
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社区1):424769183
QQ群(Kafka并不难学): 825943084
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!
热爱生活,享受编程,与君共勉!
公众号:
