哈希函数(hash function),又叫散列函数,哈希算法。散列函数把数据“压缩”成摘要,有的也叫”指纹“,它使数据量变小且数据格式大小也固定。
哈希函数将数据打乱混合,重新创建一个散列值。
我们经常用到的对用户登录密码加密,比如 md5 算法,其实就是一个散列函数。
value = hash_function(input_data),value 这个计算出来的值是大小固定的。
md5("hashmd5") = 46BD4AA9F79D359530D3D873BAC6F3DC,32 位的 md5 值。
当然也有 16 位的 md5 值。
经过哈希函数计算的散列值,会不会出现散列值相同情况?
当然会,这个就是散列值冲突。
所以一个好的哈希函数就很重要,要尽量避免出现散列值冲突。
常用的哈希算法:md5,sha-1,sha-256,sha-512 等等。
哈希表简介哈希表可以有很多英文名称,比如 hashtable,hashmap,symbol table,map 等等,英文名称虽然不同,但是数据结构基本差不多。
在 map 中,就是一种映射关系。一般保存 key:value 的键值对映射关系。
在哈希表中,key 经过哈希函数计算后存储到哈希表中,然后与 value 值关联对应。
哈希表的结构组成:数组array + 链表list。是一个组合结构。
比如:key:value 值,数组用来存储 key 经过哈希函数计算后的值与数组长度取余后的值,链表存储 key:value 值。
如下图:
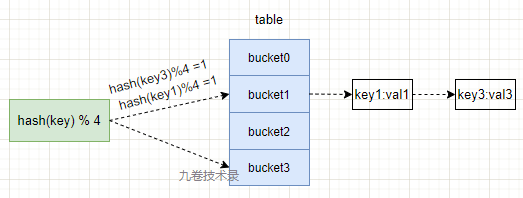
上图为什么是 2 个 key:val 在一起?
其实这就是 hash 冲突了,用链地址表来解决哈希冲突的问题。
Redis中的哈希表和字典dict 1. 哈希表各结构定义 哈希表dicthtredis3.0 中的哈希表叫 dictht,dictht 的定义:
// https://github.com/redis/redis/blob/3.0/src/dict.h#L69
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht { // 哈希表
dictEntry **table; // 哈希表的数组,数组中每个元素都是指针,指向 dictEntry 结构
unsigned long size; // 哈希表的大小,table 数组的大小
unsigned long sizemask; // 哈希表掩码,用于计算索引值,等于 size-1
unsigned long used; // 哈希表已有的节点(键值对)数量
} dictht;
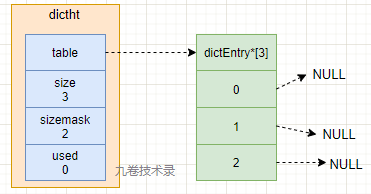
哈希表节点,有的地方取名为哈希桶 bucket,节点 Node 等等,不过表达意思是一样的。
上面 redis3.0 哈希表 dictht 里的节点 dictEntry 是怎么定义? 代码如下:
// https://github.com/redis/redis/blob/3.0/src/dict.h#L47
typedef struct dictEntry {
void *key; // 键 key
union { // 值 val
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 指向下一个哈希表节点,链表法解决hash冲突
} dictEntry;
key 属性保存键值对中的键,v 属性保存键值对中的值,其中这个 v 值可能是一个指针,或者是一个 uint64_t 整数,或者是 int64_t 整数,或是 double 类型浮点数。
dictEnty 表节点和 dictht 哈希表结构关系如下图:
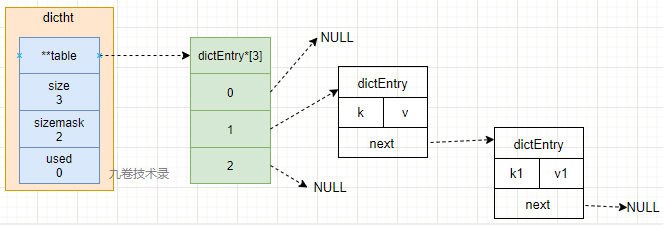
next:指向下一个哈希节点,用链表法来解决哈希冲突。
hash冲突:
上面的 dictEntry 结构里的属性 next 就是解决这个哈希键冲突问题的。
有冲突的值,就用链表来记录下一个值。
哈希算法Redis 中计算哈希值的哈希函数有好几个。
-
dictIntHashFunction 计算整型类型哈希值的哈希函数
unsigned int dictIntHashFunction(unsigned int key) -
dictGenHashFunction MurmurHash2 哈希算法, by Austin Appleby,用于计算字符串的哈希值的哈希函数
unsigned int dictGenHashFunction(const void *key, int len) -
dictGenCaseHashFunction djb 哈希算法,大小写敏感的哈希函数
/* And a case insensitive hash function (based on djb hash) */ unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len)
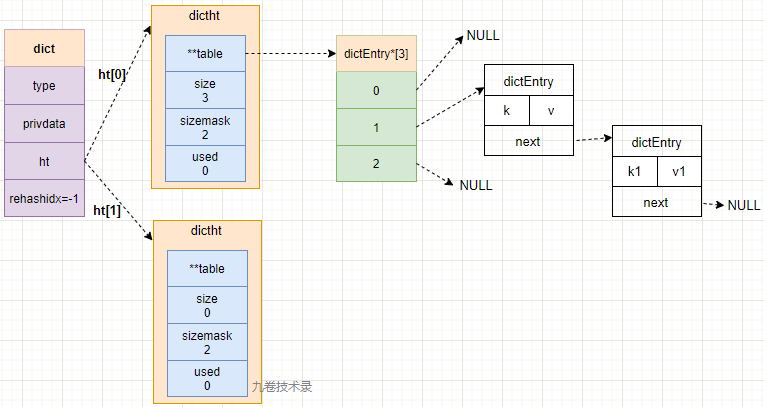
上面我们已经了解,在 Redis 中用 dictht 来表示哈希表,但是,在使用哈希表时,Redis 又定义了一个字典 dict 的数据结构。
为什么要再定义一个 dict 结构?
- 为了扩展哈希表(rehash)的时候,能够方面的操作哈希表。为此里面定义了 2 个哈希表 ht[2]。
字典 dict.h/dict 结构定义:
typedef struct dict {
dictType *type; // 指针,指向dictType 结构,dictType 中包含很多自定义函数,见下面
void *privdata; // 私有数据,保存dictType结构中的函数参数
dictht ht[2]; // hash表,ht[2] 表示有2张表
long rehashidx; /* rehashing not in progress if rehashidx == -1 *///rehash 标识,rehashidx=-1,没进行rehash
int iterators; /* number of iterators currently running */// 正在运行的迭代器数量
} dict;
*type:保存了很多函数,这些函数是操作特定类型键值对的函数,Redis 会为用途不同的字典设置不同类型特定函数。
ht[2]:包含 2 个 dictht哈希表,为什么有2张表?rehash 时会用到 ht[1]。一般情况下只使用 ht[0]。
rehashidx:这个属性与 rehash 有关,记录 rehash 目前的进度,如果目前没有进行 rehash,那么 rehashidx=-1。
dict.h/dictType 结构:
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); // 计算哈希值的函数
void *(*keyDup)(void *privdata, const void *key);// 复制键的函数
void *(*valDup)(void *privdata, const void *obj); // 复制值函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 对比键的函数
void (*keyDestructor)(void *privdata, void *key); // 销毁键的函数
void (*valDestructor)(void *privdata, void *obj); // 销毁值的函数
} dictType;
字典 dict 图示:
a. 什么是 rehash ?
- 扩大或缩小哈希表容量。
b. 为什么有 rehash ?
- 当哈希表的数据量持续增长,而哈希表容量大小固定时,就可能会有 2 个或以上数量的键被分配到哈希表数组的同一个索引上,于是就发生了冲突(collision)。
- 当然冲突可以用链表法(separate chaining)解决,但是为了哈希表的性能,要尽量避免冲突,就要对哈希表进行扩容或缩容。
哈希表中有一个负载因子(load factor)的概念:
负载因子 = 哈希表已保存的键值对数量(使用的数量) / 哈希表的长度
load_factor = ht[0].used / ht[0].size
这个负载因子的概念是用来衡量哈希表容量大小情况的。哈希表中的键值对数量少,负载因子也小。
当负载因子超过某个阙值时,为了维持哈希的容量在一定合理范围,就会对哈希表容量进行 resize 操作:
- 扩大哈希表容量
- 缩小哈希表容量
c. 什么时候进行扩容和缩容操作?
-
扩容条件
满足下面任一条件都会触发哈希表扩容
-
服务器目前没有执行 bgsave 命令,或 bgrewriteaof 命令,并且哈希表的负载因子 >=1
-
服务器目前在执行 bgsave 命令,或 bgrewriteaof 命令并且哈希表的负载因子 >5
-
-
缩容条件
- 哈希表的负载因子 < 0.1
d. 怎么操作扩容和缩容?
也就是说扩容和缩容的操作步骤是什么?
-
为字典 ht[1] 分配内存空间,空间大小取决于要执行的操作,以及当前 ht[0] 的键值对数量
-
如果是扩容操作,那么 ht[1] 的空间大小等于第一个 ht[0].used * 2 的 2^n(2的n次幂)
-
如果是缩容操作,那么 ht[1] 的空间大小等于第一个 ht[0].used 的 2^n(2的n次幂)
-
-
将 ht[0] 上所有键值重新计算哈希值和索引值后存放到 ht[1] 对应位置上
-
当 ht[0] 上所有的键值移动到 ht[1] 后,释放 ht[0],将 ht[1] 变成 ht[0],并在 ht[1] 上新建一个空哈希表
扩容代码简析:
_dictExpandIfNeeded :
// https://github.com/redis/redis/blob/3.0/src/dict.c#L923
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK; // 如果正在进行rehash,则返回
/* If the hash table is empty expand it to the initial size. */
// 如果 ht[0] 为空,则创建并初始化ht[0],然后返回
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
/*当 (ht[0].used/ht[0].size)>=1 并且,
满足dict_can_resize=1或ht[0].used/ht[0].size>5时,对字典进行扩容*/
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
// https://github.com/redis/redis/blob/3.0/src/dict.c#L58
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5;
dictExpand:
// https://github.com/redis/redis/blob/3.0/src/dict.c#L204
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table 新建一个哈希表*/
unsigned long realsize = _dictNextPower(size); // 计算扩容或缩容新版哈希表大小
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
// 如果哈希表正在rehash或新建哈希表大小小于现已使用的,则返回错误
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
缩容操作:
dictResize
// https://github.com/redis/redis/blob/3.0/src/dict.c#L192
int dictResize(dict *d)
{
int minimal;
// dict_can_resize 在 https://github.com/redis/redis/blob/3.0/src/dict.c#L58 这里是设置为 1,如果为0就返回,不进行后面操心
// 或者 dictIsRehashig() 真正进行rehash操心,也返回不rehash操作
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; // 获得已经使用ht的数量
if (minimal < DICT_HT_INITIAL_SIZE) // 这个最小值不能小于 DICT_HT_INITIAL_SIZE = 4
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); // 用dictExpand函数调整字典大小
}
// https://github.com/redis/redis/blob/3.0/src/dict.h#L100
/* This is the initial size of every hash table */
#define DICT_HT_INITIAL_SIZE 4
-
《redis设计与实现》