 在聊 Unicode 之前先讲讲设计层面的东西。编码模型是字符集编码的设计指导框架,有助于我们更好更透彻地理解各具体的编码标准。
在聊 Unicode 之前先讲讲设计层面的东西。编码模型是字符集编码的设计指导框架,有助于我们更好更透彻地理解各具体的编码标准。
上一篇《字符集编码(上):Unicode 之前》我们讲了 Unicode 之前的传统字符集编码标准产生的历史背景,以及因存在多种编码标准而带来的混乱,这种局面强烈要求一种新的、统一的现代编码标准的出现——这个统一的编码标准就是 Unicode。
不过本篇我们先不讲 Unicode,而是讲讲字符集编码设计的理论框架:字符编码模型。
字符集编码模型大体上分四层(也有说五层的,这里只讨论四层)。
第一层:抽象字符表 ACR(Abstract Character Repertoire)
它明确了该编码标准可以对哪些字符进行编码。
有些标准是封闭性的,即其能够编码的字符是固定的(比如 ASCII、ISO 8859 系列等);有些是开放性的,可以不断地往里面加入新字符(比如 Unicode)。
这里强调了字符是抽象的,这一点和我们对“字符”的直觉理解不同。我们对“字符”的直觉上(视觉上)的理解其实是指字形。
有些字符是不可见的,比如控制字符(如 ASCII 中的前 32 个字符)。
有些字形是由多个字符组合成的,比如西班牙语的 ñ 由 n 和 ~ 两个字符组成(这一点上 Unicode 和传统编码标准不同,传统编码标准多是将 ñ 视作一个独立的字符,而 Unicode 中将其视为两个字符的组合)。
抽象的另一层含义是,一个字符可能会有多种视觉上的字形表示。比如一个汉字有楷、行、草、隶等多种形体,阿拉伯字符根据其在文中出现的位置会表现为不同的形态。字符集编码将这些形态都视为同一个字符(即字符集编码是对字符而非字形编码)。

汉字“山”的不同形态
第二层:编码字符集 CCS(Coded Character Set)
有了第一层的抽象字符集列表,这层我们给列表中的每个字符分配一个唯一的数字编码(一般是非负整数)。这个数字编码有个专门的名字叫码点(Codepoint)。
注意这层我们没有提计算机,所谓码点是人类意义上的编号,就像你给面前的一堆水果,苹果编 1 号,香蕉编 2 号一样,还扯不到计算机那里去。实践中常用十六进制编号表示,而且一些单字节编码标准的码点和其在计算机中的字节值是一致的,所以人们常常把两者混用。在一些多字节编码标准中,码点和计算机字节值不是一回事,比如 GB 2312,其码点(区位码)和计算机表示(内码)是不同的。
虽然都是给字符编码(编号),但不同标准的编码方式是不同的。比如 GB 2312 是通过 94 × 94 的矩阵格子,也就是区位号的方式,而 Unicode 是通过加 1 的方式(从 0 开始往后依次 1,2,3,......)。
在这层,每个字符都分配了唯一的编码。要小心地理解这句话,它有两层含义:1. 抽象字符表中字符是唯一的;2. 编码字符集中编码是唯一的。然而,如果你看了 Unicode 的字符集,你可能觉得不是这么回事。比如热力学单位 K(开尔文)和拉丁字母 K 本质上是一个字符(在各个层面上长得都一模一样,仅仅是含义不一样),在 Unicode 中却分配了两个码点——难道 Unicode 将这两个 K 看作两个不同的字符?
在 Unicode 中,字符并不是用图形(字形)来表达的(因为字符和字形是两码事,一个字符可能会有多种字形,用哪种来表示?),而是用字符名称来表达的。在 Unicode 字符集中,字符名称是唯一的(而且不可变),这些名称分配的码点也是唯一的。拉丁字母 K 在 Unicode 中的字符名称是“Latin Capital Letter K”,码点是 004B,开尔文 K 的名称是“KELVIN SIGN”,码点是 212A。
在人类意义上来说,谁都清楚这两个字符其实就是同一个,难道 Unicode 是根据字符含义编码的?不是的。因为 Unicode 出现得比较晚,在这之前存在大量的传统编码标准,其中有些标准将这两个 K 视为不同的字符,Unicode 要兼容这些传统编码,也就只能违心地跟随了(至于为啥必须跟随,后面有详细说明)。
第三层:字符编码形式 CEF(Character Encoding Form)
这层说的是码点如何在计算机中表示。
第二层的码点是人类意义上的编码,但字符集编码最终是要让计算机来处理的,所以还必须把人类意义上的码点翻译成计算机意义上的表达形式。
这里有两步:
-
首先要定义计算机表达字符编码的单位,术语叫编码单元(Code Unit),简称码元。
-
然后定义表达规则,即如何用一个或多个码元来表示码点。
举个快递打包的例子:
假如快递公司要运送一车鸡蛋,他肯定不能像堆煤一样把鸡蛋堆在集装箱里。
首先他要准备若干大小相同的包装箱,比如 50 * 50 * 40 的纸板箱。
然后他要确定如何将鸡蛋放在这些纸板箱里——一般是不能直接堆放的,要先将鸡蛋放在蛋托里,然后将蛋托叠放入纸板箱里。
由于一方面蛋托的大小是固定的,而且为了装箱便利,快递公司决定所有的纸板箱都是一样大的,所以即使最后只剩下一个鸡蛋,也要装入一个独立的同样大小的纸板箱里(空余部分用泡沫填充),而不能因为鸡蛋数量少就装入一个小的比如 20 * 20 * 15 的纸板箱中。
如果将上面的一堆鸡蛋比作待编码字符的话,大小相同的包装箱就是编码单元(码元),如何将鸡蛋放入这些包装箱中则是编码规则。
所以这层说的是在计算机层面用多大的码元(容器)以及用什么样的规则来表达第二层定义的(人类意义上的)码点。
比如在上篇文章中我们提到 GB 2312,它本质上是第二层的标准,即它定义的是人类层面的码点——区位码。该区位码如何在计算机中表示呢?现在使用最广泛的编码形式是 EUC-CN(比如微软的 codepage 936 就是用该编码形式编码的),其码元大小是 8 bit,GB 2312 使用该编码形式编码,简单说就是在原始区码和位码基础上加上十六进制 A0 得到内码,然后放入两个码元中(详情参见《字符集编码(上):Unicode 之前》)。
这里有个问题可能让人迷惑:为什么非要定义个大小固定的码元?比如 GB 2312 使用 EUC-CN 编码方式时,为什么是用两个 8 bit 的码元而不是用一个 16 bit?它俩不是一个意思吗?
上面快递运输的例子中,快递公司之所以采用统一大小的包装箱,一方面因为蛋托大小是固定的,另一方面为了装箱的便利,所以如果最后多出一部分鸡蛋,会单独使用一个包装箱,而不是和前面的一起使用一个更大一点的,也不是自己单独使用一个更小一点的。
计算机也是如此。计算机为了处理上的便利,会定义若干种数据处理单元。计算机在物理层面的处理单元是比特,在逻辑层面上,存储和传输使用的单位是字节(byte,8 bit)——这也是我们最熟悉的单位;在 CPU 指令执行上,除了字节,还有字(word,16 bit)、双字(double words,32 bit)、四字(quad words,64 bit)——这些就是 CPU 指令的处理单元。
C 语言里面整型有 char、short、int、long 这些类型,它们映射到机器指令上一般就是 byte、word、double words 和 quad words。比如下面一段 C 语言代码:
int main()
{
short s1 = 1;
long l1 = 1;
long l2 = 100000000;
long l3 = l1 + l2;
}
得到的汇编代码:
......
movw $1, -6(%rbp)
movq $1, -16(%rbp)
movq $100000000, -24(%rbp)
movq -16(%rbp), %rcx
addq -24(%rbp), %rcx
......
这里汇编只用到两个指令:传送指令 mov 和 加法指令 add。这些指令后面都有个后缀(w 或 q),这些后缀就表示指令操作数的宽度,w 表示一个字 16 bit,q 表示四字 64 bit。movw 和 movq 在机器级别是两个不同的指令(虽然对于人类来说做的是相同的事情)。
注意,在人类意义上,100000000 比 1 占用空间要大得多,理论上在计算机中 1 应该比 100000000 占用更少的空间,但实际上它俩占用相同的空间,就算你把 l1 声明成 short,在做加法运算前计算机仍然要先将两者转换成相同的宽度(64 bit)再运算—— CPU 使用相同的编码单元处理这两个数。
和快递公司统一包装箱尺寸来提高装箱效率一样,计算机使用统一大小的编码单元(操作数的宽度)也是为了提高效率(以及计算机设计上的便捷性)。
上面举的是数值处理的例子,在字符编码上也是一样的道理,计算机层面的字符编码本质上就是数值处理,最终还是要由 CPU 指令来执行,不同大小的码元 CPU 处理指令是不同的。
很多地方讨论“字”的时候喜欢用“字节”来表示字的大小,比如双字(double word)大小是 4 字节。这种表述在理论层面上并不可取,因为字节和字是同一级别的计算机存储、传输和处理信息的单位,它们之间在理论上并不存在必然的等效关系,比如在理论上可以定义一个字等于 15 个比特——虽然实际中由于计算机存储使用字节作为单位,而为了处理上的方便,CPU 指令的处理单元也设计成存储单位(字节)的整数倍。
所以我们在讨论 CPU 指令处理单元时,是用比特来表示其绝对宽度,我们说一个字等于 16 比特,而不说一个字等于 2 个字节。理解了这层含义,能更好地理解字符集的编码单元,因为字符集编码单元的宽度理论上可以定义成任意比特(而不是必须等于字节的整数倍),比如 UTF-7 和 ISO 2022 就是 7 比特编码单元(一些早期的通信设备的传输宽度是 7 比特)。
虽然理论上码元的大小可以是任意比特,不过实际上由于个人计算机的存储和传输单位都是字节(8 bit),所以绝大部分的码元宽度都是字节的整数倍,最常用的是 8 bit(如 UTF-8)、16 bit(如 UTF-16) 和 32 bit(如 UTF-32)。
一个码点需要一个或多个码元来表示,而且一种编码方式中,一个码点需要的码元数可能不是固定的,比如 GB 3212 的 EUC-CN 编码方式中,ASCII 字符需要一个码元,汉字需要两个码元;UTF-8 中不同的字符可能需要 1 ~ 4 个码元来表示——这种编码方式称为变长编码方式(相反,如果所有字符都使用固定数量的码元表示,则称为定长编码方式,如 UTF-32)。
字符集(第二层码元)和编码方式之间是多对多的关系。一种字符集可以使用多种编码方式,比如 GB 2312 可以使用 EUC-CN 编码方式,也可以使用 ISO 2022 编码方式;反过来,一种编码方式可以应用于多种字符集,比如 EUC 编码方式可以用于 GB 2312,也可以用于 JIS X 0208(一种日语字符集编码标准)。
第四层:字符编码方案 CES(Character Encoding Scheme)
理论上,第三层已经定义了计算机层面的编码方式,为什么还要第四层呢?
现代计算机采用 8 bit(1 字节)存储方案,对于超过 8 bit 的数据单元(如 short、int、long 以及超过 8 bit 宽度的码元)要用多个字节来表示(比如 11 比特的码元需要用到两个字节即 16 比特,而不是 1 个字节加 3 比特)。
由于历史原因,多字节数据单元在存储(寄存器、内存、磁盘等)方案上,不同软硬件厂商存在不同的实现方式,大体分为大端(big-endian)和小端(little-endian)两种方案。
我们以两字节数据单元 short 类型为例,看看两种方案的区别。
short foo = 0x2710;
变量 foo 是 short 类型,是一个占用两个字节的数据单元。十六进制 2710,对应十进制 10000,二进制 00100111 00010000,其中左边的 27(二进制 00100111)称为高字节,右边的 10(二进制 00010000)称为低字节——高低字节是从人类阅读顺序(从左到右)说的。
大小端在存储(以及传输)上的区别就在于,到底是先存放高字节还是先存放低字节。
存储是从低地址往高地址进行的,大端方案是先存放高字节,即将高字节放在低地址位,低字节放在高地址位;小端方式是先存放低字节,即将低字节放在低地址位,高字节放在高地址位。
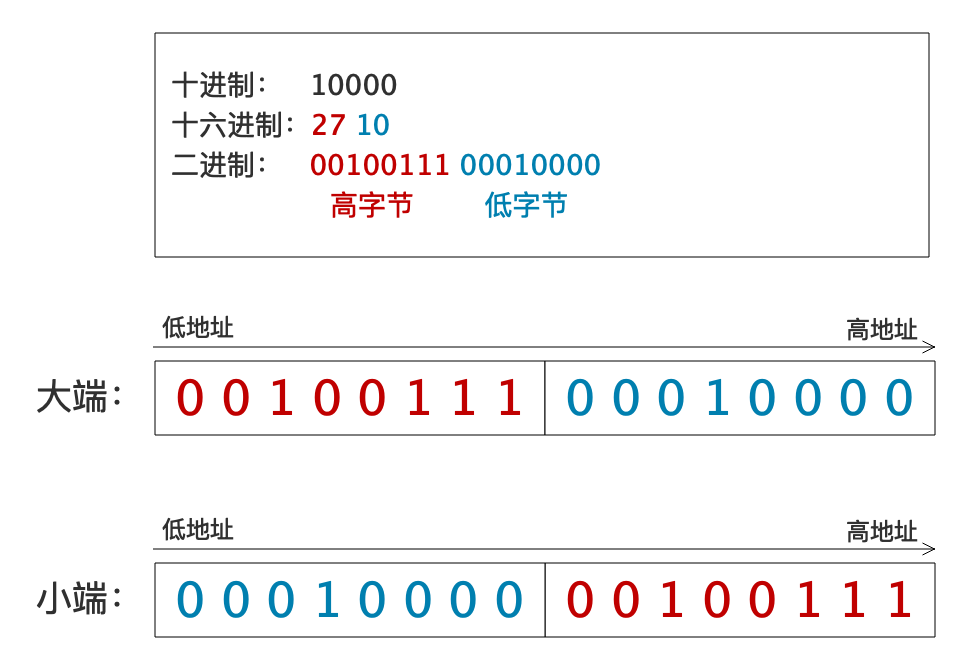
大端存储顺序和人类阅读顺序一致
大小端仅针对多字节数据单元(或说数据类型),典型地是各种 int 类型以及超过 8 bit 宽度的码元。单字节数据单元(如 char、小于等于 8 bit 的码元)不存在大小端问题。
英特尔的 x86 处理器以及 Windows 操作系统都是使用的小端模式,Mac OS 以及网络数据传输采用的是大端模式,有些 CPU 架构可以切换大小端(如 MIPS 架构)。
关于网络字节序:我们知道网络上传输的数据本质上是字节流(即网络层面根本不关心你传的内容是不是多字节数据单元,它仅仅将其视为一个个字节而已),按理应该不存在字节序的问题啊。
其实网络字节序说的是网络协议的首部涉及到多字节单元的部分应该如何发送。比如 IP 协议首部有报文长度以及 IP 地址信息,TCP 协议首部有端口号、序列号等信息,这些都是多字节数据单元,就会涉及到字节序的问题,网络协议要求采用大端序,也就是先发送高字节,后发送低字节。
回到字符编码方案上。由于在第三层定义码元的时候,码元是可以超过一个字节宽度的(比如 UTF-16 的 16 比特码元、UTF-32 的 32 比特码元),那么它就涉及到跟 int 数据类型一样的问题,即在存储的时候,先存高字节还是低字节。
这里有个问题:为什么要在字符编码模型中单独定义这一层来处理大小端问题?大小端问题难道不是操作系统和 CPU 关心和解决的事情吗,对应用层应该透明才对啊?
如果文本只需要在内存中存储,那根本不需要这一层,直接由操作系统处理大小端问题即可。问题在于,文本不仅需要在本地内存中存储,还要在磁盘中存储——这些存储在磁盘上的文本文件很可能需要在多个异构系统之间传阅。
假如张三在自己的 Mac 电脑上创建了一个文本文件,写了个汉字“啊”,并用 UTF-16 保存(在 CEF 层面,“啊”字的 UTF-16 编码值是 0x554A)。如果文本文件是按照操作系统的大小端来存储,那么该文本在 Mac OS 磁盘上的内容就是 55 4A(Mac OS 是大端存储,低地址存 55,高地址存 4A)。
然后张三将该文件发给李四,李四用 Windows 打开会怎样?
Windows 用的是小端存储方案,0x554A 在 Windows 上应该是低地址存 4A,高地址存 55,和 Mac OS 相反。现在 Windows 拿到 55 4A字节序列,会按照小端序解释为值 4A55,也就是它在 Windows 上是 0x4A55 对应的字符,也就是汉字“䩕”。结果就鸡同鸭讲了。
所以一旦涉及到异构系统之间的互操作,就必须明确字节序问题。有两种方案:
- 强制用一种字节序,比如网络传输就强制使用大端序(网络字节序);
- 使用字节序标记。字符集编码一般采用这种方案。Unicode 编码方案中有个叫 BOM(Byte Order Mark)的东西,就是用来做这事的。
其实 Unicode 完全可以采用第一种方案,也就是强制使用一种字节序,也就免去了那么多复杂问题——字节序本来就是个历史遗留问题。
UTF-8 是单字节码元,不存在字节序问题,但一些 UTF-8 文件也有 BOM 头,该 BOM 头主要是用来识别该文件是 UTF-8 编码的(不是必须的)。
讲完了四层模型,下一篇我们正式讲讲 Unicode。
老铁,如果觉得本文对你有帮助,麻烦帮点个右下角的“推荐”,感谢!