你好呀,我是歪歪。
我来填坑来啦。

上周发布了《当Synchronized遇到这玩意儿,有个大坑,要注意!》这篇文章。
文章的最后,我提到了《Java并发编程实战》的第 5.6 节的内容,说大家可以去看看。
我不知道有几个同学去看了,但是我知道绝大部分同学都没去看的,所以这篇文章我也给大家安排一下,怎么去比较好的实现一个缓存功能。
感受一下大师的代码方案演进的过程。
需求这不都二月中旬了嘛,马上就要出考研成绩了,我就拿这个来举个例子吧。
需求很简单:从缓存中查询,查不到则从数据库获取,并放到缓存中去,供下次使用。
核心代码大概就是这样的:
Integer score = map.get("why");
if(score == null){
score = loadFormDB("why");
map.put("why",score);
}
有了核心代码,所以我把代码补全之后应该是这样的:
public class ScoreQueryService {
private final Map<String, Integer> SCORE_CACHE = new HashMap<>();
public Integer query(String userName) throws InterruptedException {
Integer result = SCORE_CACHE.get(userName);
if (result == null) {
result = loadFormDB(userName);
SCORE_CACHE.put(userName, result);
}
return result;
}
private Integer loadFormDB(String userName) throws InterruptedException {
System.out.println("开始查询userName=" + userName + "的分数");
//模拟耗时
TimeUnit.SECONDS.sleep(1);
return ThreadLocalRandom.current().nextInt(380, 420);
}
}
然后搞一个 main 方法测试一下:
public class MainTest {
public static void main(String[] args) throws InterruptedException {
ScoreQueryService scoreQueryService = new ScoreQueryService();
Integer whyScore = scoreQueryService.query("why");
System.out.println("whyScore = " + whyScore);
whyScore = scoreQueryService.query("why");
System.out.println("whyScore = " + whyScore);
}
}
把代码儿跑起来:

好家伙,第一把就跑了个 408 分,我考研要是真能考到这个分数,怕是做梦都得笑醒。

Demo 很简单,但是请你注意,我要开始变形了。
首先把 main 方法修改为这样:
public class MainTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
ScoreQueryService scoreQueryService = new ScoreQueryService();
for (int i = 0; i < 3; i++) {
executorService.execute(()->{
try {
Integer why = scoreQueryService.query("why");
System.out.println("why = " + why);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
}
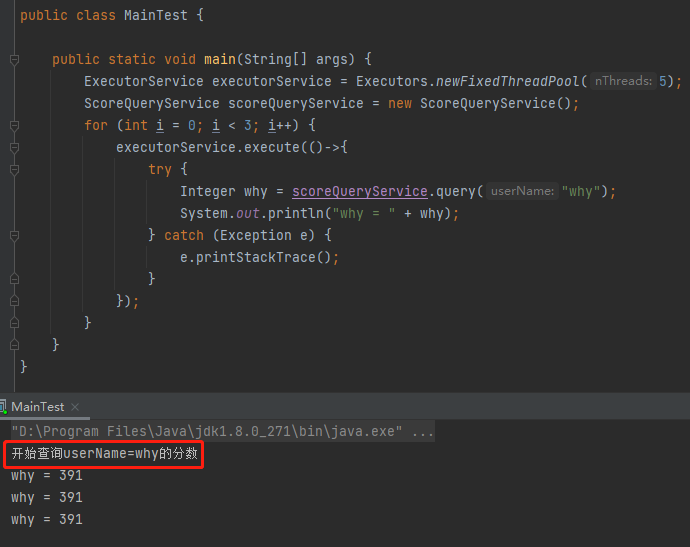
利用线程池提交任务,模拟同一时间发起三次查询请求,由于 loadFormDB 方法里面有模拟耗时的操作,那么这三个请求都不会从缓存中获取到数据。
具体是不是这样的呢?
看一下运行结果:
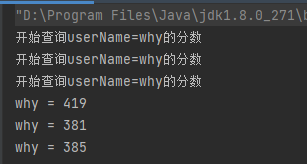
输出三次,得到了三个不同的分数,说明确实执行了三次 loadFormDB 方法。
好,同学们,那么问题就来了。
很明显,在这个场景下,我只想要一个线程执行 loadFormDB 方法就行了,那么应该怎么操作呢?
看到这个问题的瞬间,不知道你的脑袋里面有没有电光火石般的想起缓存问题三连击:缓存雪崩、缓存击穿、缓存穿透。
毕竟应对缓存击穿的解决方案之一就是只需要一个请求线程去做构建缓存,其他的线程就轮询等着。
然后脑海里面自然而然的就浮现出了 Redis 分布式锁的解决方案,甚至还想到了应该用 setNX 命令来保证只有一个线程放行成功。嘴角漏出一丝不易察觉的笑容,甚至想要关闭这篇文章。
不好意思,收起你的笑容,不能用 Redis,不能用第三方组件,只能用 JDK 的东西。

别问为什么,问就是没有引入。
这个时候你怎么办?
初始方案听说不能用第三方组件之后,你也一点不慌,大喊一声:键来。

拿着键盘只需要啪啪啪三下就写完了代码:
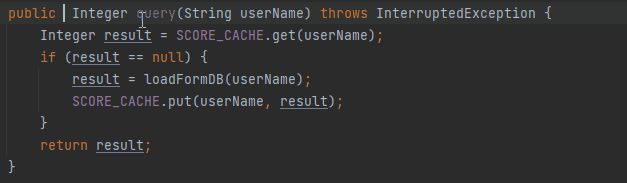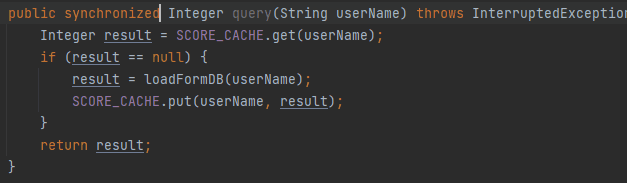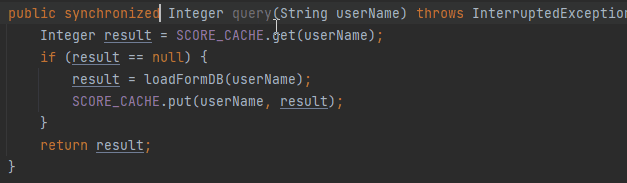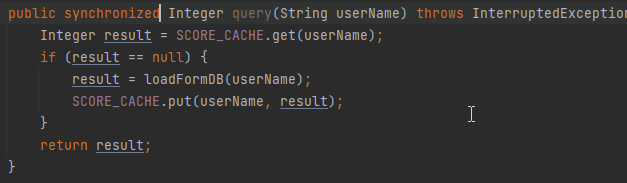
加上一个 synchronized 关键字就算完事,甚至你还记得程序员的自我修养,完成了一波自测,发现确实没有问题:
loadFromDB 方法只执行了一次。
但是,朋友,你有没有想过你这个锁的粒度有点太大了啊。
直接把整个方法给锁了。
本来一个好好的并行方法,你给咔一下,搞成串行的了:
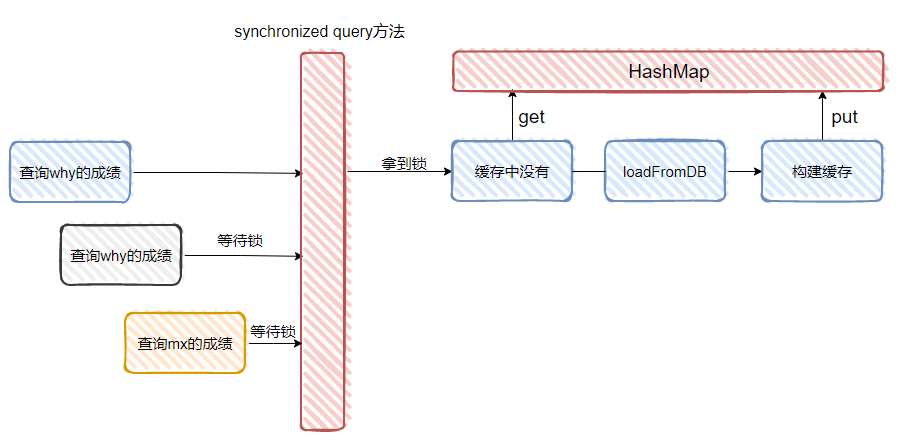
而且你这是无差别乱杀啊,比如上面这个示意图,你要是说当第二次查询 why 的成绩的时候,把这个请求给拦下来,可以理解。
但是你同时也把第一次查询 mx 的成绩给拦截了。弄得 mx 同学一脸懵逼,搞不清啥情况。
注意,这个时候自然而然就会想到缩小锁的粒度,把锁的范围从全局修改为局部,拿出比如用 why 对象作为锁的这一类解决方案。
比如伪代码改成这样:
Integer score = map.get("why");
if(score == null){
synchronized("why"){
score = loadFormDB("why");
map.put("why",score);
}
}
如果到这里你还没反应过来,那么我再换个例子。
假设我这里的查询条件变 Integer 类型的编号呢?
比如我的编号是 200,是不是伪代码就变成了这样:
Integer score = map.get(200);
if(score == null){
synchronized(200){
score = loadFormDB(200);
map.put(200,score);
}
}
看到这里你要是还没反应过来的话我只能大喊一声:你个假读者!之前发的文章肯定没看吧?
之前的《当Synchronized遇到这玩意儿,有个大坑,要注意!》这篇文章不全篇都在说这个事儿吗?
你要不知道问题是啥,你就去翻一下。
这篇文章肯定也不会往这个方向去写。不能死盯着 synchronize 不放,不然思路打不开。

我们这里不能用 synchronized 这个玩意。
但是你仔细一看,如果不用 synchronized 的话,这个 map 也不行啊:
private final Map<String, Integer> SCORE_CACHE = new HashMap<>();
这是个 HashMap,不是线程安全的呀。
怎么办?
演进呗。
演进一下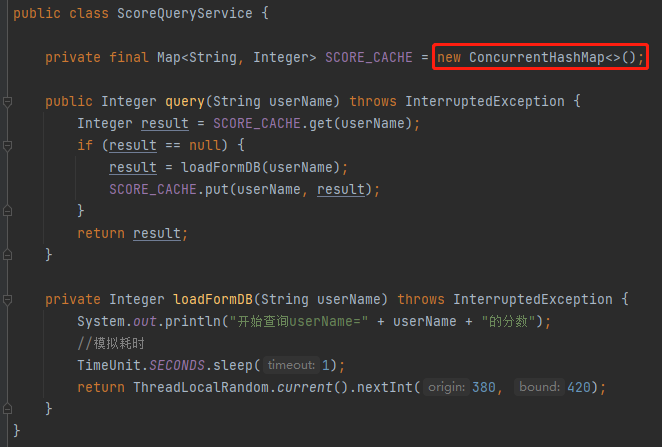
这一步非常简单,和最开始的程序相比,只是把 HashMap 替换为 ConcurrentHashMap。
然后就啥也没干了。
是不是感觉有点懵逼,甚至感觉有一定被耍了的感觉?
有就对了,因为这一步改变就是书里面的一个方案,我第一次看到的时候反正也是感觉有点懵逼:

我真没骗你,不信我拍照给你看:
.png)
这个方案和初始方案比,唯一的优点就是并发度上来了,因为 ConcurrentHashMap 是线程安全的。
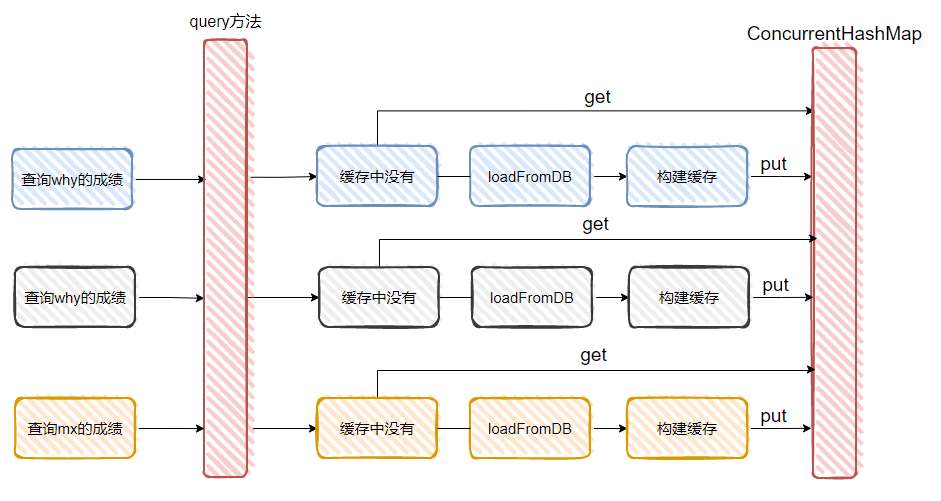
但是,整个方案作为缓存来说,从上面的示意图也能看出,就是一句话:卵用没有。

因为根本就不能满足“相同的请求下,如果缓存中没有,只有一个请求线程执行 loadFormDB 方法”这个需求,比如 why 的短时间内的两次查询操作就执行两次 loadFormDB 方法。
它的毛病在哪儿呢?
如果多个线程都是查 why 这个人成绩的前提下,如果一个线程去执行 loadFormDB 方法了,而另外的线程根本感知不到有线程在执行该方法,那么它们冲进来后一看:我去,缓存里面压根没有啊?那我也去执行 loadFormDB 方法吧。
完犊子了,重复执行了。
那么在 JDK 原生的方法里面有没有一种机制来表示已经有一个请求查询 why 成绩的线程在执行 loadFormDB 方法了,那么其他的查询 why 成绩的线程就等这个结果就行了,没必要自己也去执行一遍。
这个时候就考验你的知识储备了。
你想到了什么?

FutureTask 是异步编程里面的一个非常重要的组成部分。
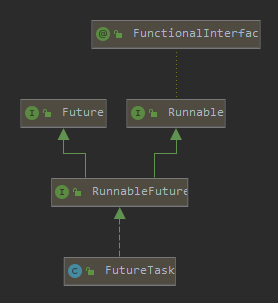
比如线程池的应用中,当你使用 submit 的方式提交任务时,它的返回类型就是 Future:
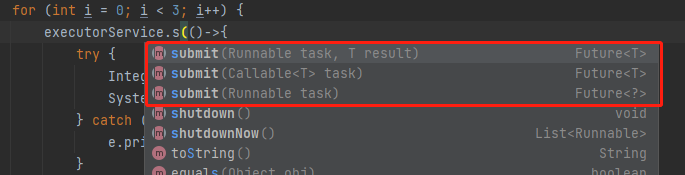
反正基于 Future 这个东西,可以玩出花儿来。
比如我们的这个场景中,如果要用到 FutureTask,那么我们的 Map 就需要修改为这样:
Map<String, Future
> SCORE_CACHE = new ConcurrentHashMap<>();
通过维护姓名和 Future 的关系来达到我们的目的。
Future 本身就代表一个任务,对于缓存维护这个需求来说,这个任务到底是在执行中还是已经执行完成了它并不关心,这个“它”指的是 SCORE_CACHE 这个 Map。
对于 Map 来说,只要有个任务放进来就行了。
而任务到底执行完成没有,应该是从 Map 里面 get 到对应 Future 的这个线程关心的。
它怎么关心?
通过调用 Future.get() 方法。
整个代码写出来就是这样的:
public class ScoreQueryService {
private final Map<String, Future<Integer>> SCORE_CACHE = new ConcurrentHashMap<>();
public Integer query(String userName) throws Exception {
Future<Integer> future = SCORE_CACHE.get(userName);
if (future == null) {
Callable<Integer> callable = () -> loadFormDB(userName);
FutureTask futureTask = new FutureTask<>(callable);
future = futureTask;
SCORE_CACHE.put(userName, futureTask);
futureTask.run();
}
return future.get();
}
private Integer loadFormDB(String userName) throws InterruptedException {
System.out.println("开始查询userName=" + userName + "的分数");
//模拟耗时
TimeUnit.SECONDS.sleep(1);
return ThreadLocalRandom.current().nextInt(380, 420);
}
}
怕你不熟悉 futureTask ,所以简单解释一下关于 futureTask 的四行代码,但是我还是强烈建议你把这个东西掌握了,毕竟说它是异步编程的基石之一也不为过。
基石还是得拿捏明白,否则就容易被面试官拿捏。
Callable<Integer> callable = () -> loadFormDB(userName);
FutureTask futureTask = new FutureTask<>(callable);
futureTask.run();
return future.get();
首先我构建了一个 Callable 作为 FutureTask 构造函数的入参。
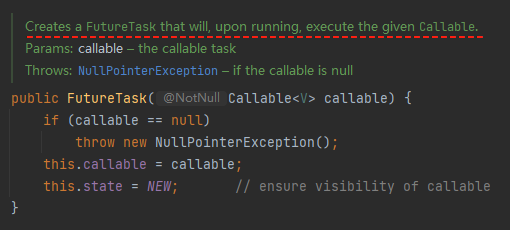
构造函数上面的描述翻译过来就是:创建一个 FutureTask,运行时将执行给定的 Callable。
“运行时”指的就是 futureTask.run() 这一行代码,而“给定的 Callable ”就是 loadFormDB 任务。
也就是说调用了 futureTask.run() 之后,才有可能会执行到 loadFormDB 方法。
然后调用 future.get() 就是获取 Callable 的结果 ,即获取 loadFormDB 方法的结果。如果该方法还没有运行结束,就死等。
对于这个方案,书上是这样说的:

主要关注我划线的部分,我一句句的说
它只有一个缺陷,即仍然存在两个线程计算出相同值的漏洞。
这句话其实很好理解,因为代码里面始终有一个“①获取-②判断-③放置”的动作。
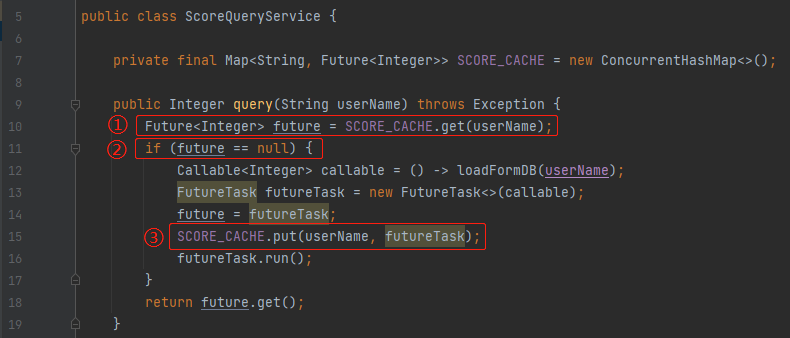
这个动作就不是原子性的,所以有一定的几率两个线程都冲进来,然后发现缓存中没有,就都走到 if 分支里面去了。
但是标号为 ① 和 ② 的地方,从需求实现的角度来说,肯定是必不可少的。
能想办法的地方也就只有标号为 ③ 的地方了。
到底啥办法呢?
不着急,下一小节说,我先把后半句话给解释了:
这个漏洞的发生概率要远小于 Memoizer2 中发生的概率。
Memoizer2 就是指前面用 ConcurrentHashMap 替换 HashMap 后的方案。
那么为什么引入 Future 之后的这个方案,触发刚刚说到的 bug 的概率比之前的方案小呢?
答案就藏在这两行代码里面:
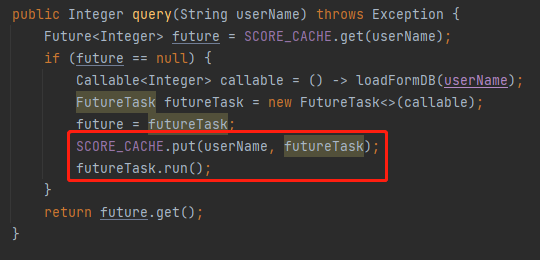
之前是要把业务逻辑执行完成,拿到返回值之后才能维护到缓存里面。
现在是先维护缓存,然后再执行业务逻辑,节约了执行业务逻辑的时间。
而一般来说最耗时的地方就是业务逻辑的执行,所以这个“远小于”就是这样来的。
那怎么办呢?
接着演进呀。
最终版书里面,针对上面那个“若没有则添加”这个非原子性的动作的时候,提到了 map 的一个方法:
.png)
Map 的 putIfAbsent,这个方法就厉害了。带你看一下:
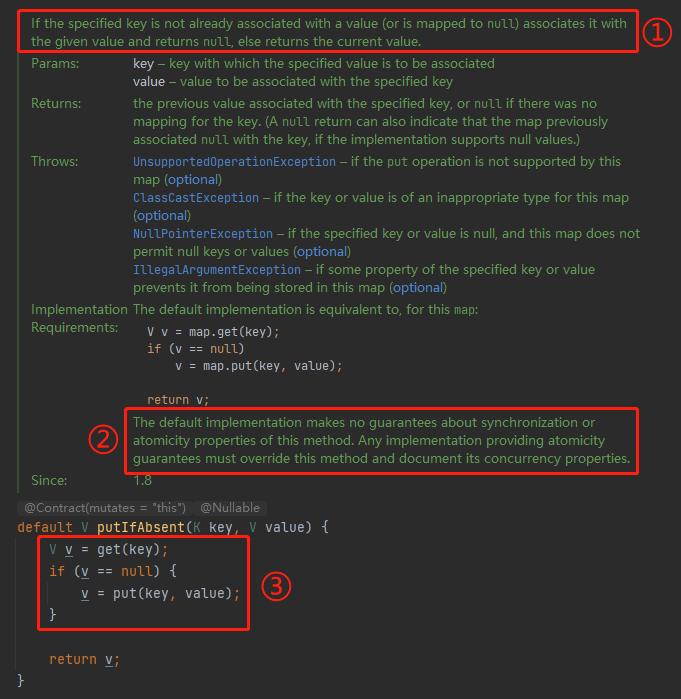
首先从标号为 ① 的地方我们可以知道,这个方法传进来的 key 如果还没有与一个值相关联(或被映射为null),则将其与给定的值进行映射并返回 null ,否则返回当前值。
如果我们只关心返回值的话,那就是:如果有就返回对应的值,如果没有就返回 null。
标号为 ② 的地方说的是啥呢?
它说默认的实现没有对这个方法的同步性或原子性做出保证。如果你要提供原子性保证,那么就请覆盖此方法,自己去写。
所以,我们接着就要关注一下 ConcurrentHashMap 的这个方法是怎么搞得了:
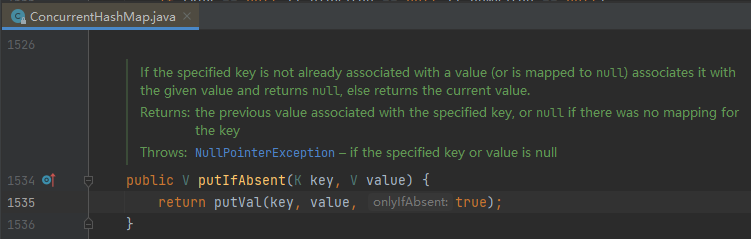
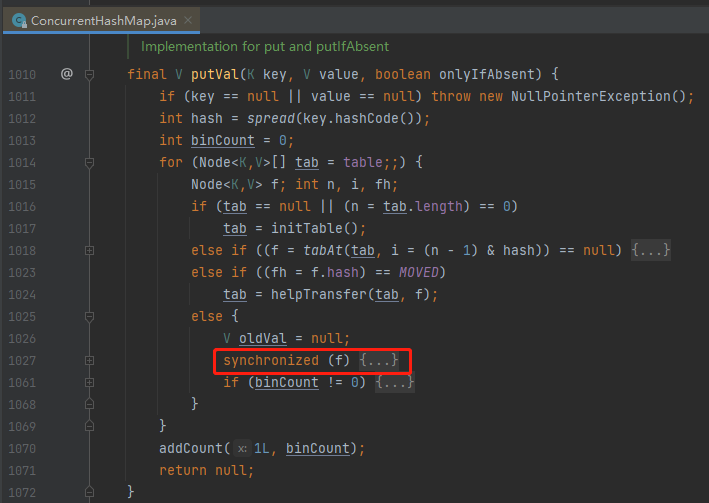
还是通过 synchronized 方法来保证了原子性,当操作的是同一个 key 的时候保证只有一个线程去执行 put 的操作。
所以书中给出的最终实现,是这样的:
public class ScoreQueryService {
public static final Map<String, Future<Integer>> SCORE_CACHE = new ConcurrentHashMap<>();
public Integer query(String userName) throws Exception {
while (true) {
Future<Integer> future = SCORE_CACHE.get(userName);
if (future == null) {
Callable<Integer> callable = () -> loadFormDB(userName);
FutureTask futureTask = new FutureTask<>(callable);
future = SCORE_CACHE.putIfAbsent(userName, futureTask);
//如果为空说明之前这个 key 在 map 里面不存在
if (future == null) {
future = futureTask;
futureTask.run();
}
}
try {
return future.get();
} catch (CancellationException e) {
System.out.println("查询userName=" + userName + "的任务被移除");
SCORE_CACHE.remove(userName, future);
} catch (Exception e) {
throw e;
}
}
}
private Integer loadFormDB(String userName) throws InterruptedException {
System.out.println("开始查询userName=" + userName + "的分数");
//模拟耗时
TimeUnit.SECONDS.sleep(5);
return ThreadLocalRandom.current().nextInt(380, 420);
}
}
与前一个方案,有三个不一样的地方。
第一个是采用了 putIfAbsent 替换 put 方法。 第二个是加入了 while(true) 循环。 第三个是 future.get() 抛出 CancellationException 异常后执行了清除缓存的动作。
第一个没啥说的,前面已经解释了。
第二个和第三个,说实话当他们组合在一起用的时候,我没看的太明白。
首先,从程序上讲,这两个是相辅相成的代码,因为 while(true) 循环我理解只有 future.get() 抛出 CancellationException 异常的时候才会起到作用。
抛出 CancellationException 异常,说明当前的这个任务被其他地方调用了 cancel 方法,而由于 while(true) 的存在,且当前的这个任务被 remove 了,所以 if 条件成功,就会再次构建一个一样的任务,然后继续执行:
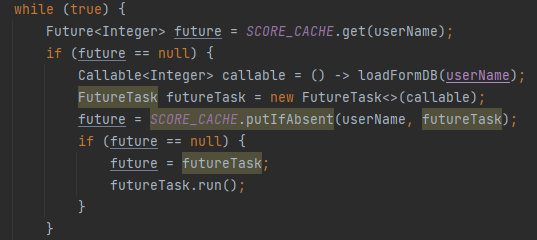
也就是说移除的任务和放进去的任务是一模一样的。
那是不是就不用移除?
没转过弯的话没关系,我先给你上个代码看看,你就明白了:
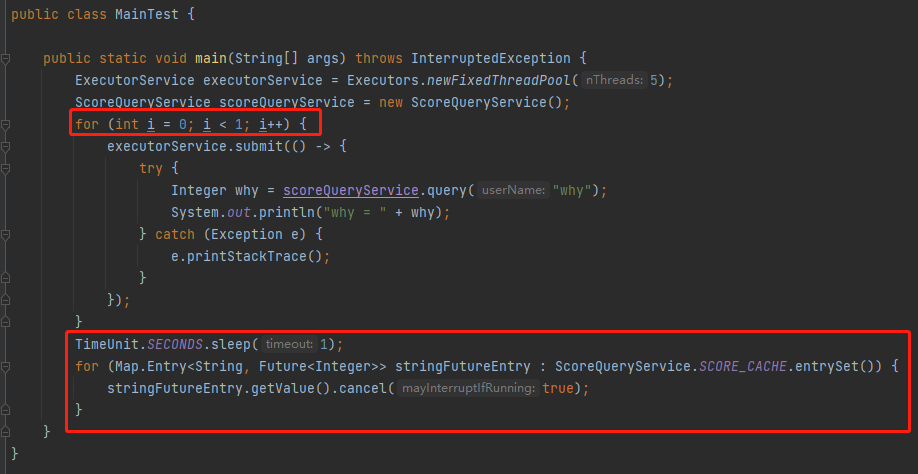
其中 ScoreQueryService 的代码我前面已经给了,就不截图了。
可以看到这次只往线程池里面扔了一个任务,然后接着把缓存里面的任务拿出来,调用 cancel 方法取消掉。
这个程序的输出结果是这样的:
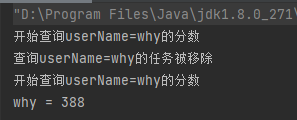
所以,由于 while(true) 的存在,导致 cancel 方法失效。
然后我前面说:移除的任务和放进去的任务是一模一样的。那是不是就不用移除?
表现在代码里面就是这样的:
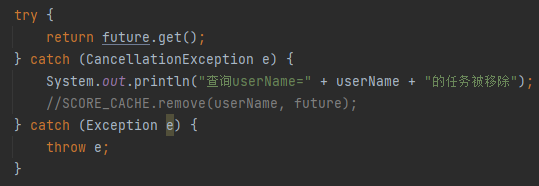
不知道作者为啥要专门搞个移除的动作,经过这一波分析,这一行代码完全是可以注释掉的嘛。
但是...
对吗?

这是不对的,老铁。如果这行代码被注释了,那么程序的输出就是这样的:
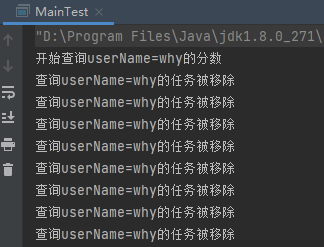
变成一个死循环了。
为什么变成死循环了?
因为 FutureTask 这个玩意是有生命周期的:
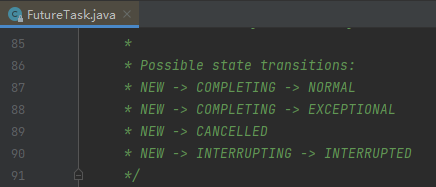
被 cancelled 之后,生命周期就完成了,所以如果不从缓存里面移走那就芭比Q了,取出来的始终是被取消的这个,那么就会一直抛出异常,然后继续循环。
死循环就是这样来的。
所以移除的动作必须得有, while(true) 就看你的需求了,加上就是 cannel 方法“失效”,去掉就是可以调用 cannel 方法。
关于 FutureTask 如果你不熟悉的话,我写过两篇文章,你可以看看。
《老爷子这代码,看跪了!》
《Doug Lea在J.U.C包里面写的BUG又被网友发现了。》
接着,我们再验证一下最终代码是否运行正常:
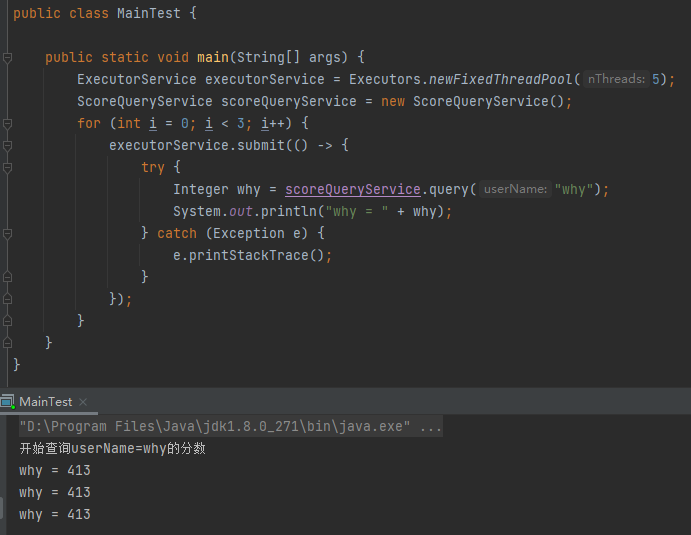
三个线程最终查出来的分数是一样的,没毛病。
如果你想观察一下阻塞的情况,那么可以把睡眠时间拉长一点:
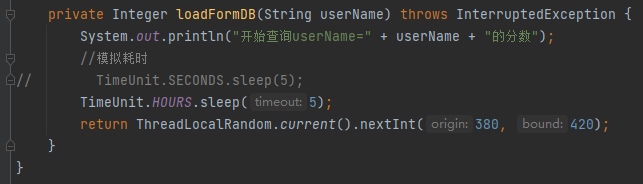
然后,把代码跑起来,看堆栈信息:
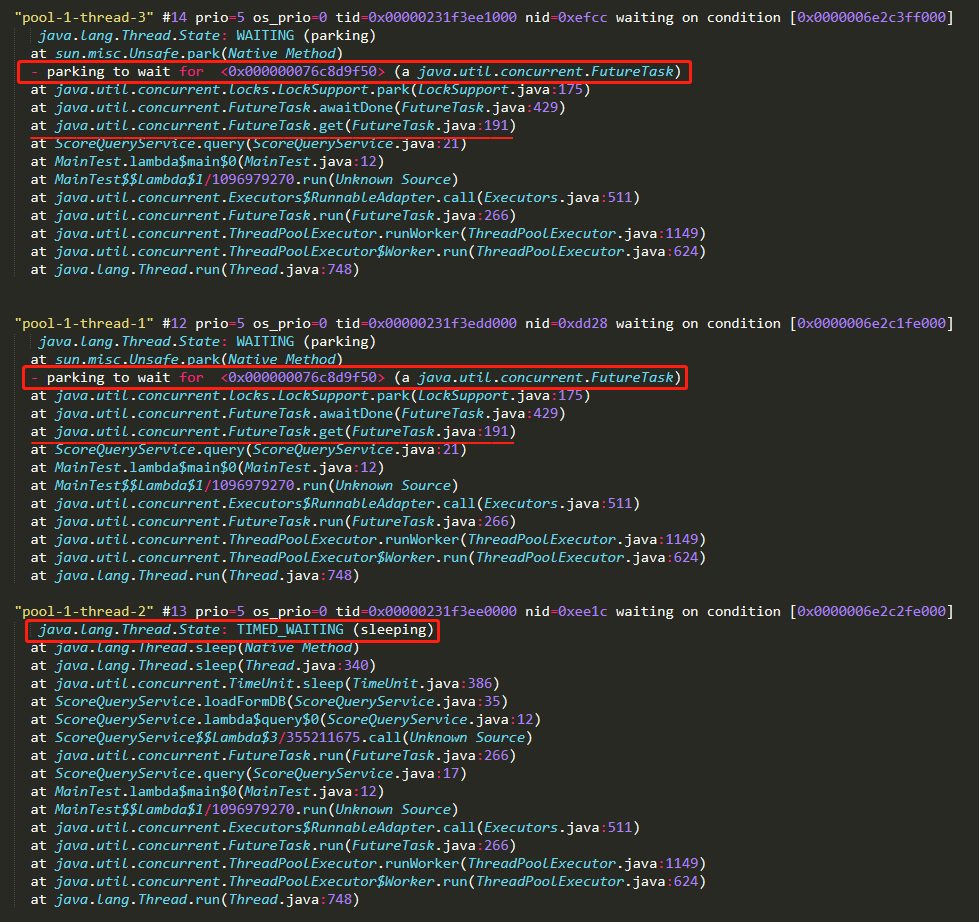
一个线程在 sleep,另外两个线程执行到了 FutureTask 的 get 方法。
sleep 的好理解,为什么另外两个线程阻塞在 get 方法上呢?
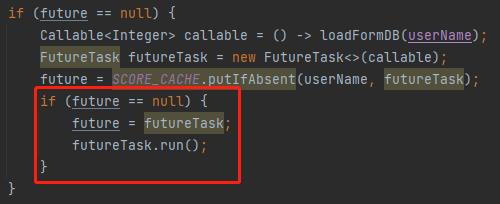
很简单,因为另外两个线程返回的 future 不是 null,这是由 putIfAbsent 方法的特性决定的:
好了,书中给出的最终方案的代码也解释完了。
但是书里面还留下了两个“坑”:
.png)
一个是不支持缓存过期机制。
一个是不支持缓存淘汰机制。
等下再说,先说说我的另一个方案。
还有一个方案其实我也还有一个方案,拿出来给大家看看:
public class ScoreQueryService2 {
public static final Map<String, Future<Integer>> SCORE_CACHE = new ConcurrentHashMap<>();
public Integer query(String userName) throws Exception {
while (true) {
Future<Integer> future = SCORE_CACHE.get(userName);
if (future == null) {
Callable<Integer> callable = () -> loadFormDB(userName);
FutureTask futureTask = new FutureTask<>(callable);
FutureTask<Integer> integerFuture = (FutureTask) SCORE_CACHE.computeIfAbsent(userName, key -> futureTask);
future = integerFuture;
integerFuture.run();
}
try {
return future.get();
} catch (CancellationException e) {
SCORE_CACHE.remove(userName, future);
} catch (Exception e) {
throw e;
}
}
}
private Integer loadFormDB(String userName) throws InterruptedException {
System.out.println("开始查询userName=" + userName + "的分数");
//模拟耗时
TimeUnit.SECONDS.sleep(1);
return ThreadLocalRandom.current().nextInt(380, 420);
}
}
和书中给出的方案差异点在于用 computeIfAbsent 代替了 putIfAbsent:
V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)
computeIfAbsent,首先它也是一个线程安全的方法,这个方法会检查 Map 中的 Key,如果发现 Key 不存在或者对应的值是 null,则调用 Function 来产生一个值,然后将其放入 Map,最后返回这个值;否则的话返回 Map 已经存在的值。
putIfAbsent,如果 Key 不存在或者对应的值是 null,则将 Value 设置进去,然后返回 null;否则只返回 Map 当中对应的值,而不做其他操作。
所以这二者的区别之一在于返回值上。
用了 computeIfAbsent 之后,每次返回的都是同一个 FutureTask,但是由于 FutureTask 的生命周期,或者说是状态扭转的存在,即使三个线程都调用了它的 run 方法,这个 FutureTask 也只会执行成功一次。
可以看一下,这个 run 方法的源码,一进来就是状态和当前操作线程的判断:

所以执行完一次 run 方法之后,再次调用 run 方法并不会真的执行。
但是从程序实现的优雅角度来说,还是 putIfAbsent 方法更好。
坑怎么办?前面不是说最终的方案有两个坑嘛:
一个是不支持缓存过期机制。 一个是不支持缓存淘汰机制。
在使用 ConcurrentHashMap 的前提下,这两个特性如果要支持的话,需要进行对应的开发,比如引入定时任务来解决,想想就觉得麻烦。
同时也我想到了 spring-cache,我知道这里面有 ConcurrentHashMap 作为缓存的实现方案。
我想看看这个组件里面是怎么解决这两个问题的。
二话不说,我先把代码拉下来看看:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
由于 spring-cache 也不是本文重点,所以我就直接说关键地方的源码了。
至于是怎么找到这里来的,就不详细介绍了,以后安排文章详细解释。
另外我不得不说一句:spring-cache 这玩意真的是优雅的一比,不论是源码还是设计模式的应用,都非常的好。

首先,我们可以看到 @Cacheable 注解里面有一个参数叫做 sycn,默认值是 false:
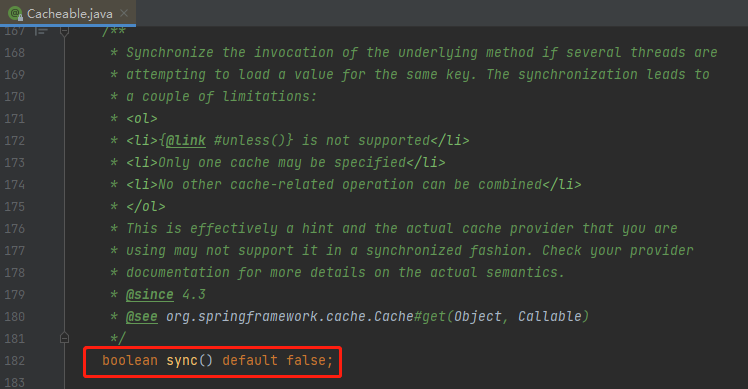
关于这个参数,官网上的解释是这样的:
https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html#cache-annotations-cacheable-cache-resolver
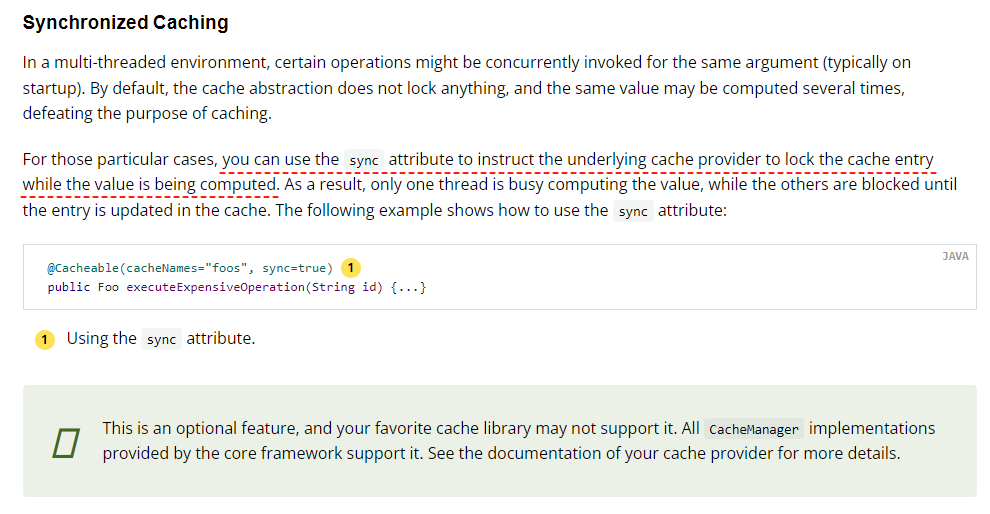
就是针对我们前面提到的缓存如何维护的情况的一个处理方案。使用方法也很简单。
该功能对应的核心部分的源码在这个位置:
org.springframework.cache.interceptor.CacheAspectSupport#execute(org.springframework.cache.interceptor.CacheOperationInvoker, java.lang.reflect.Method, org.springframework.cache.interceptor.CacheAspectSupport.CacheOperationContexts)
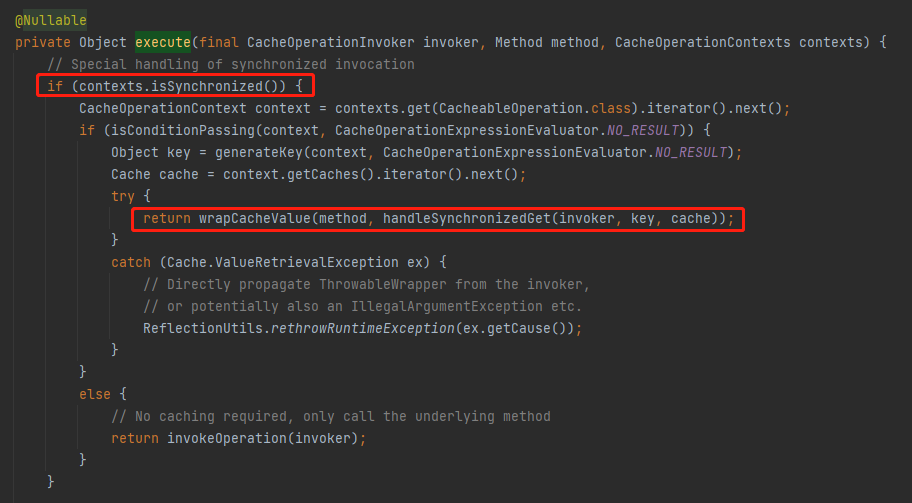
在上面这个方法中会判断是不是 sync=true 的方法,如果是则进入到 if 分支里面。
接着会执行到下面这个重要的方法:
org.springframework.cache.interceptor.CacheAspectSupport#handleSynchronizedGet
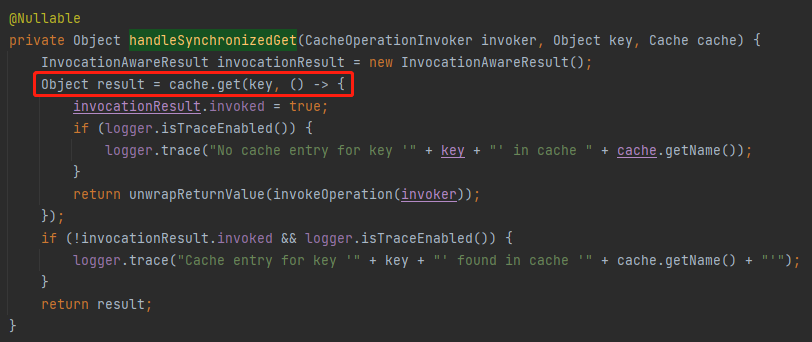
在这个方法里面,入参 cache 是一个抽象类,Spring 提供了六种默认的实现:
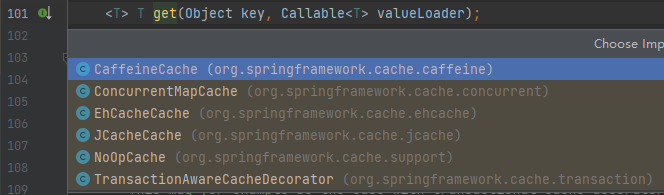
而我关心的是 ConcurrentMapCache 实现,点进去一看,好家伙,这方法我熟啊:
org.springframework.cache.concurrent.ConcurrentMapCache#get
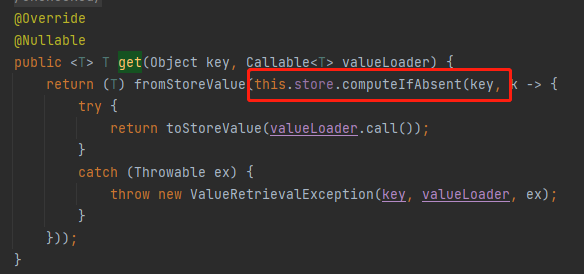
computeIfAbsent 方法,我们不是刚刚才说了嘛。但是我左翻右翻就是找不到设置过期时间和淘汰策略的地方。
于是,我又去翻官网了,发现答案就直接写在官网上的:
https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html#cache-specific-config

这里说了,官方提供的是一个缓存的抽象,而不是具体的实现。而缓存过期和淘汰机制不属于抽象的范围内。
为什么呢?
比如拿 ConcurrentHashMap 来说,假设我提供了缓存过期和淘汰机制的抽象,那你说 ConcurrentHashMap 怎么去实现这个抽象方法?
实现不了,因为它本来就不支持这个机制。
所以官方认为这样的功能应该由具体的缓存实现类去实现而不是提供抽象方法。
这里也就回复了前面的最终方案引申出的这两个问题:
一个是不支持缓存过期机制。 一个是不支持缓存淘汰机制。
別问,问就是原生的方法里面是支持不了的。如果要实现自己去写代码,或者换一个缓存方案。
再说两个点最后,再补充两个点。
第一个点是之前的《当Synchronized遇到这玩意儿,有个大坑,要注意!》这篇文章里面,有一个地方写错了。
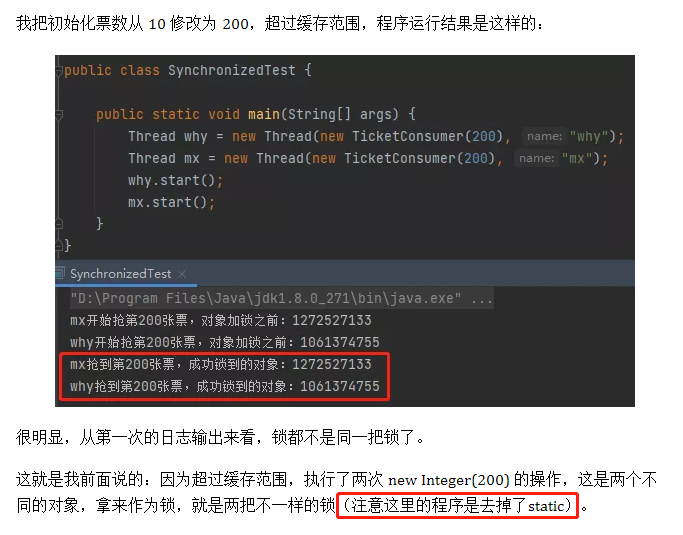
框起来的地方是我后面加上来的。

上周的文章发出去后,大概有十来个读者给我反馈这个问题。
我真的特别的开心,因为真的有人把我的示例代码拿去跑了,且认真思考了,然后来和我讨论,帮我指正我写的不对的地方。
再给大家分享一下我的这篇文章《当我看技术文章的时候,我在想什么?》
里面表达了我对于看技术博客的态度:
看技术文章的时候多想一步,有时候会有更加深刻的理解。
带着怀疑的眼光去看博客,带着求证的想法去证伪。
多想想 why,总是会有收获的。
第二个点是这样的。
关于 ConcurrentHashMap 的 computeIfAbsent 我其实也专门写过文章的:《震惊!ConcurrentHashMap里面也有死循环,作者留下的“彩蛋”了解一下?》
老读者应该是读到过这篇文章的。
之前在 seata 官网上闲逛的时候,看到了这篇博客:
https://seata.io/zh-cn/blog/seata-dsproxy-deadlock.html
名字叫做《ConcurrentHashMap导致的Seata死锁问题》,我就随便这么点进去一看:
这里提到的这篇文章,就是我写的。
在 seata 官网上偶遇自己的文章是一种很神奇的体验。
四舍五入,我也算是给 seata 有过贡献的男人。
而且你看这篇文章其实也提到了我之前写过的很多文章,这些知识都通过一个小小的点串起来了,由点到线,由线到面,这也是我坚持写作的原因。
共勉之。
最后,呼应一下文章的开头部分,考研马上要查分了,我知道我的读者里面还是有不少是今年考研的。
如果你看到了这里,那么下面这个图送给你:

本文已收录至个人博客,更多原创好文,欢迎大家来玩:
https://www.whywhy.vip/