
https://www.citusdata.com/blog/2022/03/26/test-drive-citus-11-beta-for-postgres/
Citus 11.0 beta 的最大变化是 schema 和 Citus 元数据现在在整个数据库集群中自动同步。这意味着您始终可以从 Citus 集群中的任何节点查询分布式表!
使用 Citus 最简单的方法是连接到协调器节点并将其用于 schema 更改和分布式查询,但是对于要求非常高的应用程序,您现在可以选择通过使用不同的连接字符串并考虑一些限制,在应用程序(部分)的工作节点之间对分布式查询进行负载平衡。
我们也在 11.0 beta 版中弃用了一些特性来加速我们的开发,但我们希望这不会影响到你们中的大多数人。
在这篇 11.0 beta 版博客文章中,您将了解:
- Citus 11.0 beta 中新的自动元数据同步功能
- 如何配置 Citus 11.0 beta 集群
- 如何跨工作节点负载平衡查询
- 升级到 11.0 beta 版
- 改进的集群活动视图
- 事务块中的元数据同步
- 弃用
您可以试用新的 Citus 11.0 beta ,看看您的应用程序将如何使用它,或者尝试新功能。 您可以在我们的安装说明中找到这些软件包。
- https://docs.citusdata.com/en/v11.0-beta/installation/multi_node.html
我们刚刚推出了 11.0 beta 的新型发行说明,如果您想深入了解我们的开源 GitHub 存储库并查看我们在此版本中解决的问题,这应该很有用。 如果您觉得它有用,请在 Slack 上告诉我们!我们也计划为即将发布的 Citus 版本发布此类版本说明。您可以通过 Citus 网站顶部导航中的 “UPDATES” 链接找到这些发行说明。
- https://www.citusdata.com/updates/v11-0-beta/
- https://slack.citusdata.com/
Citus 可能是扩展 PostgreSQL 数据库的最佳方式。当您分发表时,Citus 可以跨大型 PostgreSQL 服务器集群路由和并行化复杂查询。除了初始设置之外,分发对应用程序是透明的:您的应用程序仍然连接到单个 PostgreSQL 节点(Citus 用语中的“协调器”),并且协调器在后台分发您的应用程序发送的 Postgres 查询。
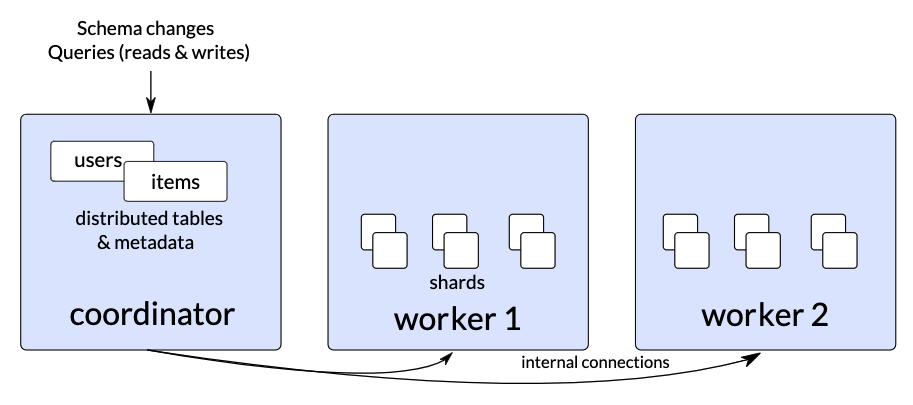
图 1:Citus 10.2 或更早版本中的 Citus 集群,其中用户和项目是分布式表,它们的元数据仅在协调器上。
单协调器架构有很多好处并且性能非常好,但是对于某些高性能工作负载,协调器可能会成为瓶颈。在实践中,很少有应用程序会遇到协调器的瓶颈,因为 Citus 协调器所做的工作相对较少。但是,我们确实发现应用程序开发人员通常希望在可扩展性方面为未来做好准备,并且有一些要求非常高的企业应用程序。
- https://www.citusdata.com/blog/2022/03/12/how-to-benchmark-performance-of-citus-and-postgres-with-hammerdb/
很长一段时间以来,Citus 通过同步分布式表 schema 和元数据,能够通过工作节点执行分布式查询。过去,我们有时将此功能称为“MX”。 但是,MX 功能在使用序列(sequences)、函数(functions)、模式(schemas)和其他数据库对象方面存在各种限制——这意味着并非所有表都支持元数据同步。
Citus 11.0 beta 更改为新的操作模式:现在所有 Citus 数据库集群始终使用元数据同步。这意味着使用 Citus 11.0 beta 和所有未来版本,您始终可以从任何节点运行分布式 Postgres 查询。
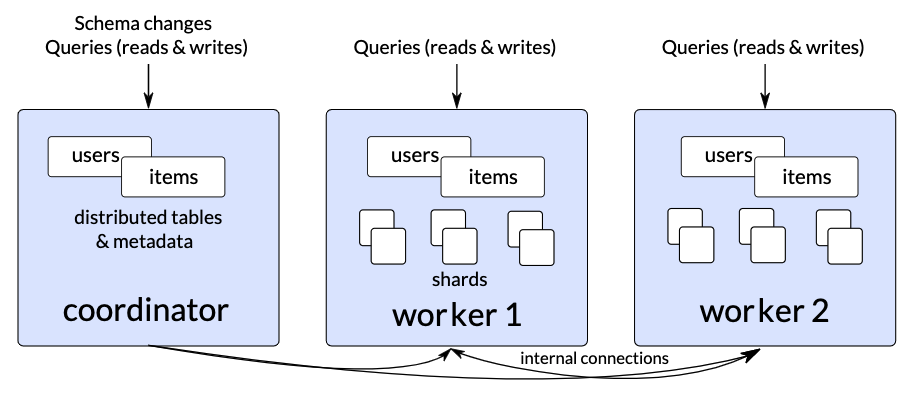
图 2:Citus 11.0 beta 集群,其中 users 和 items 是分布式表,并且使用新的自动元数据同步功能,它们的元数据会同步到所有节点。
当您开始使用 Citus 11.0 beta 时,您无需执行任何操作来启用新的元数据同步功能。 每个分布式表、数据库对象和 schema 更改都将自动传播到所有 Citus worker 节点。 Schema 更改和节点管理仍然需要发送到 Citus 协调器,您可以通过更改应用程序中的连接字符串来选择将分布式 Postgres 查询发送到协调器或任何其他节点。
如何配置 Citus 11.0 beta 集群如果您需要在 PostgreSQL 数据库上每秒执行许多查询,则可能需要使用相对大量的连接。 最终,您的总吞吐量在 [连接数]/[平均响应时间],因为您一次只能对每个连接进行一次查询。
当您的应用程序打开与其中一个 Citus 节点的连接时,该连接会产生一个 Postgres 进程。 这个 Postgres 进程需要与其他节点建立内部连接以查询分布式表的分片。这些内部连接被缓存以最小化响应时间。这确实意味着来自客户端的每个连接最终都会导致与其他节点的额外内部连接,因此每个节点最终将获得与客户端对整个数据库集群的连接数。幸运的是,我们在 PostgreSQL 14 中对连接可扩展性进行了重大改进,允许 Postgres(和 Citus)在高连接数下保持良好的性能。
- https://www.citusdata.com/blog/2020/10/25/improving-postgres-connection-scalability-snapshots/
如果您决定从应用程序连接到 worker 节点以运行分布式查询,那么您的客户端连接在技术上与内部连接竞争。为了确保处理客户端连接的每个 Postgres 进程也可以与所有其他节点建立内部连接,我们添加了 citus.max_client_connections 设置。此设置限制外部客户端连接的数量,同时继续允许 Citus 节点之间的内部连接。除了通常的安装说明外,我们建议在每个 Citus 节点(协调器和所有工作器)上的 postgresql.conf 中添加以下设置,以适应大量客户端连接:
- https://docs.citusdata.com/en/v11.0-beta/installation/multi_node.html
# The maximum number of client + internal connections a node can handle
# The total number of client connections across all nodes should never exceed this number
max_connections = 6000
# The number of client connections an individual node can handle
# Should be no greater than: max_connections / node count including the coordinator
citus.max_client_connections = 500
使用这些设置,每个节点将接受来自您的应用程序的多达 500 个连接,因此如果您有 10 个工作节点和 1 个协调器,那么您的应用程序总共可以建立 5500 个连接。 您可以通过在每个节点上使用像 pgbouncer 这样的连接池来进一步增加这个数字。
- https://www.pgbouncer.org/
我们还强烈建议将 Citus 协调器添加到元数据中,以便工作节点也可以连接到协调器。 仅当协调器在元数据中时,某些 Citus 功能才可用。我们可能会在未来添加所需的协调器。
-- on all nodes:
CREATE EXTENSION citus;
-- only on coordinator: add coordinator to metadata
SELECT citus_set_coordinator_host('<coordinator’s own hostname>', 5432);
-- only on coordinator: add worker nodes to metadata
SELECT citus_add_node('<worker 1 hostname>', 5432);
SELECT citus_add_node('<worker 2 hostname>', 5432);
-- only on coordinator:
CREATE TABLE items (key text, value text);
SELECT create_distributed_table('items', 'key');
-- from any node:
INSERT INTO items VALUES ('hello', 'world');
Citus 11.0 beta 集群启动并运行后,您有 2 个选择:
- 您可以像往常一样将您的应用程序连接到协调器,或者
- 通过使用支持负载平衡的客户端和自定义连接字符串(如 JDBC 或 Npgsql),在工作节点之间对 Postgres 查询进行负载均衡。 您还应该能够在已经使用这些客户端之一的现有应用程序中进行负载均衡。
- https://jdbc.postgresql.org/
- https://www.npgsql.org/
在 2 个 worker 之间进行负载平衡的示例 JDBC 连接字符串:
- https://jdbc.postgresql.org/documentation/head/connect.html
jdbc:postgresql://user@worker1.host:5432,worker2.host:5432/postgres?loadBalanceHosts=true
在 2 个 worker 之间进行负载均衡的示例 Npgsql 连接字符串:
- https://www.npgsql.org/doc/connection-string-parameters.html
Host=worker1.host,worker2.host;Database=postgres;Username=user;Load Balance Hosts=true
另一种方法是设置一个包含所有工作节点 IP 的 DNS 记录。 使用 DNS 的一个缺点是,由于本地 DNS 缓存,来自同一台机器的同时打开的连接通常会使用相同的 IP。 另一种选择是设置一个专用的负载均衡器,如 HAProxy。
- https://severalnines.com/resources/database-management-tutorials/postgresql-load-balancing-haproxy
在 11.0 beta 通过 Citus 工作节点运行 Postgres 查询时,需要注意一些限制:
- 您需要配置您的应用程序以通过 Citus 协调器执行 schema 更改,而查询可以通过任何节点进行。
- 如果您在一个工作节点上创建表,如果您随后连接到不同的工作节点,它将不会显示。
- 如果您启用
citus.use_citus_managed_tables设置或创建引用表的外键,则协调器上的本地表仅出现在 worker 节点上。- https://www.citusdata.com/blog/2021/06/18/foreign-keys-between-local-ref-tables/
- 生成
bigint的序列将在序列号的前 16 位包含所连接节点的 ID,这意味着序列号仍然是唯一的,但不是单调的。 - 尝试从工作节点插入时,生成 int/smallint 的序列会抛出错误
我们希望在未来的 Citus 版本中解决上述限制。
将现有 Citus 数据库集群升级到 Citus 11.0 beta如果您要将现有(非生产)集群升级到 Citus 11.0 beta,那么在安装新软件包后,您需要调用一个函数来完成升级:
-- on all nodes
ALTER EXTENSION citus UPDATE;
-- only on the coordinator
select citus_finalize_upgrade_to_citus11();
升级功能将确保所有工作节点都具有正确的 schema 和 metadata。 它还解决了影响分区表分片的几个命名问题。
如果存在任何阻止元数据同步的情况(例如,工作节点上缺少权限或存在冲突的对象),则升级功能将抛出错误。在解决问题并完成升级之前,您仍然可以通过 coordinator 使用现有的 Citus 数据库群集,但一些新的 11.0 beta 功能将不可用。
集群洞察的新视图Citus 经常要求的一项功能是更好地了解数据库集群中正在发生的事情。 当一些查询通过 worker 节点进入时,这变得更加重要。
我们改进了 citus_dist_stat_activity 视图以显示来自所有节点上所有客户端会话的 pg_stat_activity 的信息,以及一个 global_pid(或 gpid),它唯一地标识一个客户端会话和与该会话关联的所有内部连接。gpid 以发起查询的节点的节点 ID 开头,即客户端连接的节点。
SELECT nodeid, global_pid, query FROM citus_dist_stat_activity where application_name = 'psql';
┌────────┬─────────────┬────────┬────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ nodeid │ global_pid │ state │ query │
├────────┼─────────────┼────────┼────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 1 │ 10000001303 │ active │ SELECT nodeid, global_pid, state, query FROM citus_dist_stat_activity where application_name = 'psql'; │
│ 2 │ 20000001346 │ active │ select count(*), pg_sleep(300) from test; │
└────────┴─────────────┴────────┴────────────────────────────────────────────────────────────────────────────────────────────────────────┘
如果要取消特定查询,只需将 global_pid 传递给 pg_cancel_backend。这适用于任何节点。
SELECT pg_cancel_backend(20000001346);
您还可以使用新的 citus_stat_activity 视图查看集群中发生的所有事情(分布式查询和内部查询):
SELECT nodeid, global_pid, state, query, is_worker_query FROM citus_stat_activity WHERE global_pid = 20000001500;
┌────────┬─────────────┬────────┬──────────────────────────────────────────────────────────────────────────────────────────────────┬─────────────────┐
│ nodeid │ global_pid │ state │ query │ is_worker_query │
├────────┼─────────────┼────────┼──────────────────────────────────────────────────────────────────────────────────────────────────┼─────────────────┤
│ 2 │ 20000001500 │ active │ select count(pg_sleep(300)) from test; │ f │
│ 2 │ 20000001500 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102153 test WHERE true │ t │
│ 2 │ 20000001500 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102155 test WHERE true │ t │
│ 3 │ 20000001500 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102156 test WHERE true │ t │
│ 3 │ 20000001500 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102154 test WHERE true │ t │
└────────┴─────────────┴────────┴──────────────────────────────────────────────────────────────────────────────────────────────────┴─────────────────┘
如果您正在使用 pg_stat_activity 查看特定节点,您现在还可以在 application_name 中找到 worker 查询所属的 gpid:
select pid, application_name, state, query from pg_stat_activity where query like '%count%' and application_name <> 'psql';
┌──────┬─────────────────────────────────┬────────┬──────────────────────────────────────────────────────────────────────────────────────────────────┐
│ pid │ application_name │ state │ query │
├──────┼─────────────────────────────────┼────────┼──────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 1548 │ citus_internal gpid=10000001547 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102153 test WHERE true │
│ 1550 │ citus_internal gpid=10000001547 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102155 test WHERE true │
└──────┴─────────────────────────────────┴────────┴──────────────────────────────────────────────────────────────────────────────────────────────────┘
由于每个节点都需要能够连接到 Citus 集群中的每个其他节点,因此我们还引入了一个新的健康检查功能,用于检查所有可能路径的连通性。 结果列指示连接尝试是否成功。
select * from citus_check_cluster_node_health();
┌───────────────┬───────────────┬─────────────┬─────────────┬────────┐
│ from_nodename │ from_nodeport │ to_nodename │ to_nodeport │ result │
├───────────────┼───────────────┼─────────────┼─────────────┼────────┤
│ localhost │ 1400 │ localhost │ 1400 │ t │
│ localhost │ 1400 │ localhost │ 1401 │ t │
│ localhost │ 1400 │ localhost │ 1402 │ t │
│ localhost │ 1401 │ localhost │ 1400 │ t │
│ localhost │ 1401 │ localhost │ 1401 │ t │
│ localhost │ 1401 │ localhost │ 1402 │ t │
│ localhost │ 1402 │ localhost │ 1400 │ t │
│ localhost │ 1402 │ localhost │ 1401 │ t │
│ localhost │ 1402 │ localhost │ 1402 │ t │
└───────────────┴───────────────┴─────────────┴─────────────┴────────┘
(9 rows)
使用这些功能,即使您通过协调器执行所有查询,您也应该对集群中发生的事情有更好的了解。
在事务块中严格、即时的元数据同步在分布式数据库中,我们经常需要在一致性、容错性、并行性和其他分布式系统方面进行权衡。Citus 需要支持 PostgreSQL 的交互式多语句事务块,这在分布式环境中尤其具有挑战性。
例如,Citus 通常跨分片并行化昂贵的操作 — 例如分析查询和 create_distributed_table() 在每个 worker 的多个连接上。创建数据库对象时,Citus 通过每个 worker 的单个连接将其传播到 worker 节点。 在单个多语句事务中组合这两个操作可能会导致问题,因为并行连接将无法看到通过单个连接创建但尚未提交的对象。
考虑一个创建类型、表、加载数据和分发表的事务块:
BEGIN;
-- type creation over a single connection:
CREATE TYPE coordinates AS (x int, y int);
CREATE TABLE positions (object_id text primary key, position coordinates);
-- data loading thus goes over a single connection:
SELECT create_distributed_table(‘positions’, ‘object_id’);
\COPY positions FROM ‘positions.csv’
…
在 Citus 11.0 beta 之前,Citus 将推迟在 worker 节点上创建类型,并在执行 create_distributed_table 时单独提交。这使得 create_distributed_table 中的数据复制能够并行发生。然而,这也意味着该类型并不总是出现在 Citus worker 节点上 — 或者如果事务回滚,它只会出现在 worker 节点上。 我们能够隐藏这些不一致之处,但最终它们可能会导致问题。
在 Citus 11.0 beta 中,默认行为更改为优先考虑协调器和工作节点之间的 schema 一致性。 这确实有一个缺点:如果对象传播发生在同一事务中的并行命令之后,则该事务将无法再完成,如下面代码块中的 ERROR 突出显示:
BEGIN;
CREATE TABLE items (key text, value text);
-- parallel data loading:
SELECT create_distributed_table(‘items’, ‘key’);
\COPY items FROM ‘items.csv’
CREATE TYPE coordinates AS (x int, y int);
ERROR: cannot run type command because there was a parallel operation on a distributed table in the transaction
如果您遇到此问题,有 2 个简单的解决方法:
- 使用
set citus.create_object_propagation to deferred;返回旧的对象传播行为,在这种情况下,不同节点上存在哪些数据库对象之间可能存在一些不一致。 - 使用
set citus.multi_shard_modify_mode to sequential来禁用每个节点的并行性。 同一事务中的数据加载可能会更慢。
早在 2016 年,我们就宣布弃用基于语句的分片复制以实现高可用性 (HA),转而支持流式复制。当您在 Azure Database for PostgreSQL 上启用Hyperscale (Citus) 的高可用性时,每个节点都将具有热备用 - 这意味着该节点上的所有分片都通过流复制进行复制。 即使您不启用高可用性,数据也会由托管磁盘在内部复制,以防止任何数据丢失。
- https://www.citusdata.com/blog/2016/12/15/citus-replication-model-today-and-tomorrow/
- https://docs.microsoft.com/azure/postgresql/hyperscale/concepts-high-availability
尽管已弃用,但我们从未删除基于语句的复制……它仍然可以用于在特定场景中扩展读取,但是,已弃用的 HA 相关逻辑经常会导致问题,并阻止我们为复制表实现元数据同步。 因此,作为 Citus 11.0 测试版的一部分,我们将行为更改如下:
在 Citus 11.0 测试版之前,当复制分片的写入在其中一个分片位置上失败时,Citus 将该位置标记为无效 - 之后必须重新复制分片。这个特性从来没有很好地工作,因为零星的写入失败可能会使放置无效并导致昂贵的(写入阻塞)重新复制。
从 Citus 11.0 beta 开始,对复制分片的写入始终使用 2PC — 这意味着它们只有在所有放置都已启动时才能成功。 此外,复制表的元数据是同步的,因此可以从任何节点查询它们。
今天使用基于语句的分片复制的开源用户可以升级到 Citus 11.0 测试版——但是,当持有一个副本的节点发生故障时,要继续接受对分片的写入,应该通过 citus_disable_node 函数禁用故障节点。在替换或重新激活节点后,仍然可以使用 replicate_table_shards 重新复制分片。
- https://docs.citusdata.com/en/stable/develop/api_udf.html#citus-disable-node
- https://docs.citusdata.com/en/latest/develop/api_udf.html#replicate-table-shards
如果要使用基于语句的复制来扩展读取吞吐量,则需要:
- 在创建分布式表之前将
citus.shard_replication_factor设置为 2,并且 - 将
citus.task_assignment_policy设置为“round-robin(循环)”以在副本之间负载均衡查询。
使用基于语句的复制来扩展读取吞吐量的缺点是写入具有更高的响应时间,并且更新和删除被序列化以保持副本同步。
弃用:告别很少使用的功能与 PostgreSQL 一样,Citus 保持长期的向后兼容性。 我们竭尽全力确保您的应用程序在升级 Citus 时继续工作。 但是,有时某个功能不再符合 Citus 的使用方式并妨碍了开发。 我们决定在 11.0 测试版中删除一些 Citus 功能:
- 无效的分片放置:如上一节所述,当写入失败时,分片不再被标记为无效,因为这种行为在使用基于语句的复制时存在一些缺陷并降低了可靠性。
- 追加分布式表函数:Citus 中最初的分发方法是“append(追加)”分发,它针对仅追加数据进行了优化。 Hash-distributed 表更容易使用并且具有更多功能,并且还可以通过分区很好地处理仅附加数据。Citus 11.0 beta 删除了用于创建分片和将新数据加载到附加分布式表中的功能。 我们不知道有任何附加分布式表用户,但以防万一:您仍然可以升级到 11.0 beta,但这些表将变为只读。 我们建议创建使用默认 hash-distribution 的新分布式表,并使用 INSERT .. SELECT 命令移动数据。
- https://docs.citusdata.com/en/latest/develop/reference_ddl.html
- 分布式 cstore_fdw 表(应切换到列访问方式):从 10.0 版开始,Citus 带有内置的列式存储。 在 Citus 10.0 之前,可以使用现已弃用的 cstore_fdw 扩展将 Citus 与列存储一起使用。但是,
cstore_fdw不支持流式复制和备份等重要的 PostgreSQL 功能,因此在 Citus 10 之前我们很少看到 Citus 客户使用列存储。许多公司现在成功地使用 Citus 的内置列存储来存储时间序列数据,因此我们放弃了对创建或使用分布式cstore_fdw表的支持。如果您已分发 cstore_fdw 表,我们建议在升级到 11.0 beta 之前将它们转换为列访问方法。- https://github.com/citusdata/cstore_fdw
- https://www.citusdata.com/blog/2021/10/22/how-to-scale-postgres-for-time-series-data-with-citus/
Citus 是唯一一个完全作为 PostgreSQL 扩展实现的事务和分析工作负载的分布式数据库,这意味着 Citus 大规模支持 PostgreSQL 的强大功能,并继承了 PostgreSQL 的稳定性、性能、多功能性、可扩展性,以及庞大的工具生态系统和 扩展。
- https://github.com/citusdata/citus
借助 Citus 开源 11.0 测试版中的自动元数据同步功能,您现在可以选择从任何节点查询您的 Citus 集群,从而进一步提高 Citus 的可扩展性。
如果您有兴趣试用新的 Citus 11.0 beta,您可以在 Citus 文档中找到 beta 版的安装说明。安装 Citus 后,入门页面上有很多关于如何入门的好内容,包括教程和视频。 最后,如果您想了解更多有关 Citus 内部工作原理的信息,请查看我们的 SIGMOD 论文。
- https://docs.citusdata.com/en/v11.0-beta/installation/multi_node.html
- https://www.citusdata.com/getting-started/
- https://dl.acm.org/doi/10.1145/3448016.3457551
探索 Python/Django 支持分布式多租户数据库,如 Postgres+Citus
【文章转自:新加坡服务器 http://www.558idc.com/sin.html 复制请保留原URL】