vivo 互联网大数据团队-Lv Jia
Hadoop 3.x的第一个稳定版本在2017年底就已经发布了,有很多重大的改进。
在HDFS方面,支持了Erasure Coding、More than 2 NameNodes、Router-Based Federation、Standby NameNode Read、FairCallQueue、Intra-datanode balancer 等新特性。这些新特性在稳定性、性能、成本等多个方面带来诸多收益,我们打算将HDFS集群升级到HDFS 3.x 版本。
本篇文章会介绍我们是如何将CDH 5.14.4 HDFS 2.6.0 滚动升级到HDP-3.1.4.0-315 HDFS 3.1.1版本,是业界为数不多的从CDH集群滚动升级到HDP集群的案例。在升级中遇到哪些问题?这些问题是如何解决掉的?本篇文章具有非常高的参考借鉴价值。
一、 背景vivo离线数仓Hadoop集群基于CDH 5.14.4版本构建,CDH 5.14.4 Hadoop版本:2.6.0+CDH 5.14.4+2785,是Cloudera公司基于Apache Hadoop 2.6.0版本打入了一些优化patch后的Hadoop发行版。
近几年随着vivo业务发展,数据爆炸式增长,离线数仓HDFS集群从一个扩展到十个,规模接近万台。随着 HDFS 集群规模的增长,当前版本的HDFS的一些痛点问题也暴露出来:
-
在当前低版本的HDFS,线上环境NameNode经常出现RPC性能问题,用户Hive/Spark离线任务也会因为NameNode RPC性能变慢导致任务延迟。
-
一些RPC性能问题在HDFS 3.x版本均已修复,当前只能通过打入HDFS高版本patch的方式解决线上NameNode RPC性能问题。
-
频繁的patch合并增加了HDFS代码维护的复杂度,每一个patch的上线都需要重启NameNode或者DataNode,增加了HDFS集群的运维成本。
-
线上HDFS集群使用viewfs对外提供服务,公司内部业务线众多,很多业务部门申请了独立的HDFS客户端访问离线数仓集群。当修改线上HDFS配置后,更新HDFS客户端配置是一件非常耗时且麻烦的事情。
-
HDFS 2.x不支持EC,冷数据无法使用EC来降低存储成本。
Hadoop 3.x的第一个稳定版本在2017年底就已经发布了,有了很多重大的改进。在HDFS方面,支持了Erasure Coding、More than 2 NameNodes、Router-Based Federation、Standby NameNode Read、FairCallQueue、Intra-datanode balancer 等新特性。HDFS 3.x新特性在稳定性、性能、成本等多个方面带来诸多收益。
-
HDFS Standby NameNode Read、FairCallQueue新特性以及HDFS 3.x NameNode RPC优化patch能极大提升我们当前版本HDFS集群稳定性与RPC性能。
-
HDFS RBF替代viewfs,简化HDFS客户端配置更新流程,解决线上更新众多HDFS客户端配置的痛点问题。
-
HDFS EC应用冷数据存储,降低存储成本。
基于以上痛点问题与收益,我们决定将离线数仓HDFS集群升级到 HDFS 3.x版本。
二、 HDFS 升级版本选择由于我们Hadoop集群基于CDH 5.14.4版本构建,我们首先考虑升级到CDH高版本。CDH 7提供HDFS 3.x发行版,遗憾是CDH 7没有免费版,我们只能选择升级到Apache版本或者Hortonworks公司提供的HDP发行版。
由于Apache Hadoop没有提供管理工具,对于万台规模的HDFS集群,管理配置、分发配置极其不方便。因此,我们选择了Hortonworks HDP发行版,HDFS管理工具选择Ambari。
Hortonworks提供的最新的稳定的免费的Hadoop发行版为HDP-3.1.4.0-315版本。Hadoop版本为Apache Hadoop 3.1.1版本。
三、HDFS 升级方案制定 3.1 升级方案HDFS官方提供两种升级方案:Express 和 RollingUpgrade。
-
**Express **升级过程是停止现有HDFS服务,然后使用新版本HDFS启动服务,会影响线上业务正常运行。
-
**RollingUpgrade **升级过程是滚动升级,不停服务,对用户无感知。
鉴于HDFS停服对业务影响较大,我们最终选择 RollingUpgrade方案。
3.2 降级方案RollingUpgrade 方案中, 有两种回退方式:**Rollback 和 RollingDowngrade **。
-
**Rollback **会把HDFS版本连同数据状态回退到升级前的那一刻 ,会造成数据丢失。
-
RollingDowngrade 只回退HDFS版本,数据不受影响。
我们线上 HDFS 集群是不能容忍数据丢失的,我们最终选择 RollingDowngrade 的回退方案。
3.3 HDFS 客户端升级方案线上 Spark、Hive、Flink 、OLAP等计算组件重度依赖HDFS Client,部分计算组件版本过低,需要升级到高版本才能支持HDFS 3.x,升级HDFS Client有较高风险。
我们在测试环境经过多轮测试,验证了HDFS 3.x兼容HDFS 2.x client读写。
因此,我们本次HDFS升级只升级NameNode、JournalNode、DataNode组件,HDFS 2.x Client等YARN升级后再升级。
3.4 HDFS 滚动升级步骤RollingUpgrade 升级的操作流程在 Hadoop 官方升级文档中有介绍,概括起来大致步骤如下:
-
JournalNode升级,使用新版本依次重启 JournalNode。
-
NameNode升级准备,生成 rollback fsimage文件。
-
使用新版本Hadoop重启 Standby NameNode,重启 ZKFC。
-
NameNode HA主从切换,使升级后的 NameNode 变成 Active 节点。
-
使用新版本 Hadoop 重启另一个 NameNode,重启 ZKFC。
-
升级 DataNode,使用新版本 Hadoop 滚动重启所有 DataNode 节点。
-
执行 Finalize,确认HDFS集群升级到新版本。
HDFS 2.x集群,HDFS、YARN、Hive、HBase等组件,使用CM工具管理。由于只升级HDFS,HDFS 3.x使用Ambari管理,其它组件如YARN、Hive仍然使用CM管理。HDFS 2.x client不升级,继续使用CM管理。Zookeeper使用原CM部署的ZK。
具体实现:CM Server节点部署Amari Server,CM Agent节点部署Ambari Agent。
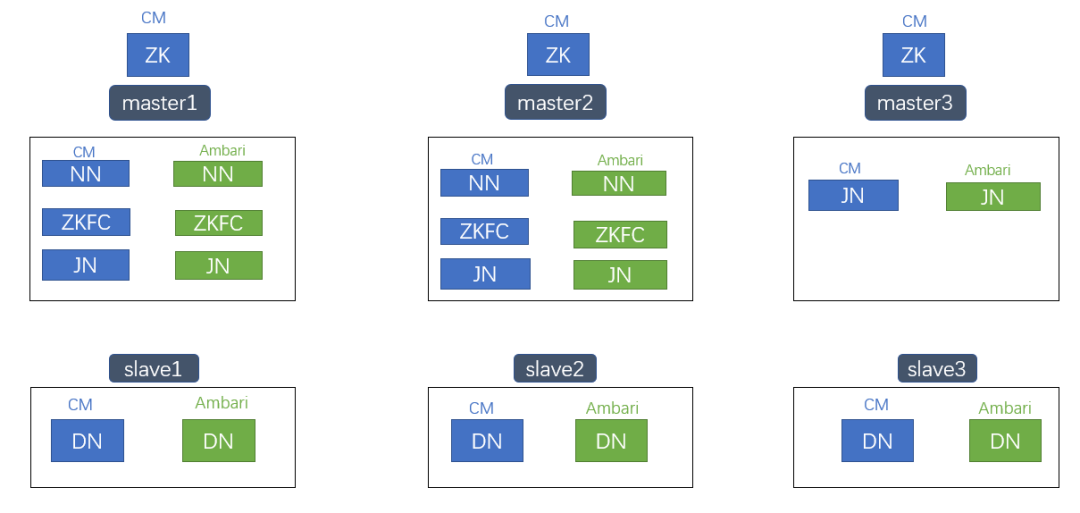
如上图所示,使用Ambari工具在master/slave节点部署HDFS 3.x NameNode/DataNode组件,由于端口冲突,Ambari部署的HDFS 3.x会启动失败,不会对线上CM部署的HDFS 2.x集群产生影响。
HDFS升级开始后,master节点停止CM JN/ZKFC/NN,启动Ambari JN/ZKFC/NN,slave节点停止CM DN,启动Ambari DN。HDFS升级的同时实现管理工具从CM切换到Ambari。
五、HDFS 滚动升级降级过程中遇到的问题 5.1 HDFS 社区已修复的不兼容问题HDFS社区已修复滚动升级、降级过程中关键不兼容的问题。相关issue号为:HDFS-13596、 HDFS-14396、 HDFS-14831。
【HDFS-13596】: 修复Active NamNode升级后将EC相关的数据结构写入EditLog 文件,导致Standby NameNode读取EditLog 异常直接Shutdown的问题。
【HDFS-14396】:修复NameNode升级到HDFS 3.x版本后,将EC相关的数据结构写入Fsimage文件,导致NameNode降级到HDFS 2.x版本识别Fsimage文件异常的问题。
【HDFS-14831】:修复NameNode升级后对 StringTable 的修改导致HDFS降级后 Fsimage 不兼容问题。
我们升级的HDP HDFS版本引入了上述三个issue相关的代码。除此之外,我们在升级过程中还遇到了其它的不兼容问题:
5.2 JournalNode 升级出现 Unknown protocolJournalNode升级过程中,出现的问题:
Unknown protocol: org.apache.hadoop.hdfs.qjournal.protocol.InterQJournalProtocol
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.RpcNoSuchProtocolException): Unknown protocol: org.apache.hadoop.hdfs.qjournal.protocol.InterQJournalProtocol
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.getProtocolImpl(ProtobufRpcEngine.java:557)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:596)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2281)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2277)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2275)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1498)
at org.apache.hadoop.ipc.Client.call(Client.java:1444)
at org.apache.hadoop.ipc.Client.call(Client.java:1354)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy14.getEditLogManifestFromJournal(Unknown Source)
at org.apache.hadoop.hdfs.qjournal.protocolPB.InterQJournalProtocolTranslatorPB.getEditLogManifestFromJournal(InterQJournalProtocolTranslatorPB.java:75)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer.syncWithJournalAtIndex(JournalNodeSyncer.java:250)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer.syncJournals(JournalNodeSyncer.java:226)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer.lambda$startSyncJournalsDaemon$0(JournalNodeSyncer.java:186)
at java.lang.Thread.run(Thread.java:748)
报错原因:HDFS 3.x新增了InterQJournalProtocol,新增加的InterQJournalProtocol用于JournalNode之间同步旧的edits数据。
HDFS-14942 对此问题进行了优化,日志级别从ERROR改成DEBUG。此问题不影响升级,当三个HDFS 2.x JN全部升级为HDFS 3.x JN时,JN之间能正常同步数据。
5.3 NameNode升级DatanodeProtocol.proto不兼容NameNode升级后,DatanodeProtocol.proto不兼容,导致Datanode BlockReport 无法进行。
(1)HDFS 2.6.0 版本
DatanodeProtocol.proto
message HeartbeatResponseProto {
repeated DatanodeCommandProto cmds = 1; // Returned commands can be null
required NNHAStatusHeartbeatProto haStatus = 2;
optional RollingUpgradeStatusProto rollingUpgradeStatus = 3;
optional uint64 fullBlockReportLeaseId = 4 [ default = 0 ];
optional RollingUpgradeStatusProto rollingUpgradeStatusV2 = 5;
}
(2)HDFS 3.1.1版本
DatanodeProtocol.proto
message HeartbeatResponseProto {
repeated DatanodeCommandProto cmds = 1; // Returned commands can be null
required NNHAStatusHeartbeatProto haStatus = 2;
optional RollingUpgradeStatusProto rollingUpgradeStatus = 3;
optional RollingUpgradeStatusProto rollingUpgradeStatusV2 = 4;
optional uint64 fullBlockReportLeaseId = 5 [ default = 0 ];
}
我们可以看到两个版本 HeartbeatResponseProto 的第4、5个参数位置调换了。
这个问题的原因在于,Hadoop 3.1.1 版本commit了 HDFS-9788,用来解决HDFS升级时兼容低版本问题,而 HDFS 2.6.0 版本没有commit ,导致了DatanodeProtocol.proto不兼容。
HDFS升级过程中,不需要兼容低版本HDFS,只需要兼容低版本HDFS client。
因此,HDFS 3.x不需要 HDFS-9788 兼容低版本的功能,我们在Hadoop 3.1.1 版本回退了 HDFS-9788 的修改来保持和HDFS 2.6.0 版本的DatanodeProtocol.proto兼容。
5.4 NameNode升级layoutVersion不兼容NameNode升级后,NameNode layoutVersion改变,导致EditLog不兼容,HDFS 3.x降级到HDFS 2.x NameNode 无法启动。
2021-04-12 20:15:39,571 ERROR org.apache.hadoop.hdfs.server.namenode.EditLogInputStream: caught exception initializing XXX:8480/getJournal
id=test-53-39&segmentTxId=371054&storageInfo=-60%3A1589021536%3A0%3Acluster7
org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream$LogHeaderCorruptException: Unexpected version of the file system log file: -64. Current version = -60.
at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.readLogVersion(EditLogFileInputStream.java:397)
at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.init(EditLogFileInputStream.java:146)
at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.nextopImpl(EditLogFileInputStream.java:192)
at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.nextop(EditLogFileInputStream.java:250)
at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.read0p(EditLogInputStream.java:85)
at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.skipUntil(EditLogInputStream.java:151)
at org.apache.hadoop.hdfs.server.namenode.RedundantEditLogInputStream.next0p(RedundantEditLogInputStream.java:178)
at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.readop(EditLogInputStream.java:85)
at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.skipUntil(EditLogInputStream.java:151)
at org.apache.hadoop.hdfs.server.namenode.RedundantEditLogInputStream.next0p(RedundantEditLogInputStream.java:178)
at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.read0p(EditLogInputStream.java:85)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.LoadEditRecords(FSEditLogLoader.java:188)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.LoadFSEdits(FSEditLogLoader.java:141)
at org.apache.hadoop.hdfs.server.namenode.FSImage.loadEdits(FSImage.java:903)
at org.apache.hadoop.hdfs.server.namenode.FSImage.LoadFSImage(FSImage.java:756)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:324)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.LoadFSImage(FSNamesystem.java:1150)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.LoadFromDisk(FSNamesystem.java:797)
at org.apache.hadoop.hdfs.server.namenode.NameNode.LoadNamesystem (NameNode.java:614)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:676)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:844)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:823)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode (NameNode.java:1547)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1615)
HDFS 2.6.0升级到HDFS 3.1.1,NameNode layoutVersion值 -60 变更成 -64。要解决这个问题,首先搞清楚NameNode layoutVersion什么情况下会变更?
HDFS版本升级引入新特性,NameNode layoutVersion跟随新特性变更。Hadoop官方升级文档指出,HDFS滚动升级过程中要禁用新特性,保证升级过程中layoutVersion不变,升级后的HDFS 3.x版本才能回退到HDFS 2.x版本。
接下来,找出HDFS 2.6.0升级到HDFS 3.1.1引入了哪一个新特性导致namenode layoutVersion变更?查看 HDFS-5223、HDFS-8432、HDFS-3107相关issue,HDFS 2.7.0版本引入了truncate功能,NameNode layoutVersion变成 -61。查看HDFS 3.x版本NameNodeLayoutVersion代码:
NameNodeLayoutVersion
public enum Feature implements LayoutFeature {
ROLLING_UPGRADE(-55, -53, -55, "Support rolling upgrade", false),
EDITLOG_LENGTH(-56, -56, "Add length field to every edit log op"),
XATTRS(-57, -57, "Extended attributes"),
CREATE_OVERWRITE(-58, -58, "Use single editlog record for " +
"creating file with overwrite"),
XATTRS_NAMESPACE_EXT(-59, -59, "Increase number of xattr namespaces"),
BLOCK_STORAGE_POLICY(-60, -60, "Block Storage policy"),
TRUNCATE(-61, -61, "Truncate"),
APPEND_NEW_BLOCK(-62, -61, "Support appending to new block"),
QUOTA_BY_STORAGE_TYPE(-63, -61, "Support quota for specific storage types"),
ERASURE_CODING(-64, -61, "Support erasure coding");
TRUNCATE、APPEND_NEW_BLOCK、QUOTA_BY_STORAGE_TYPE、ERASURE_CODING 四个Feature设置了minCompatLV为-61。
查看最终NameNode layoutVersion取值逻辑:
FSNamesystem
static int getEffectiveLayoutVersion(boolean isRollingUpgrade, int storageLV,
int minCompatLV, int currentLV) {
if (isRollingUpgrade) {
if (storageLV <= minCompatLV) {
// The prior layout version satisfies the minimum compatible layout
// version of the current software. Keep reporting the prior layout
// as the effective one. Downgrade is possible.
return storageLV;
}
}
// The current software cannot satisfy the layout version of the prior
// software. Proceed with using the current layout version.
return currentLV;
}
getEffectiveLayoutVersion获取最终生效的layoutVersion,storageLV是当前HDFS 2.6.0版本layoutVersion -60,minCompatLV是 -61,currentLV是升级后的HDFS 3.1.1版本layoutVersion -64。
从代码判断逻辑可以看出,HDFS 2.6.0版本layoutVersion -60 小于等于minCompatLV是 -61不成立,因此,升级到HDFS 3.1.1版本后,namenode layoutVersion的取值为currentLV -64。
从上述代码分析可以看出,HDFS 2.7.0版本引入了truncate功能后,HDFS社区只支持HDFS 3.x 降级到HDFS 2.7版本的NameNode layoutVersion是兼容的。
我们对HDFS truncate功能进行评估,结合业务场景分析,我们vivo内部离线分析暂时没有使用HDFS truncate功能的场景。基于此,我们修改了HDFS 3.1.1版本的minCompatLV为 -60,用来支持HDFS 2.6.0升级到HDFS 3.1.1版本后能够降级到HDFS 2.6.0。
minCompatLV修改为-60:
NameNodeLayoutVersion
public enum Feature implements LayoutFeature {
ROLLING_UPGRADE(-55, -53, -55, "Support rolling upgrade", false),
EDITLOG_LENGTH(-56, -56, "Add length field to every edit log op"),
XATTRS(-57, -57, "Extended attributes"),
CREATE_OVERWRITE(-58, -58, "Use single editlog record for " +
"creating file with overwrite"),
XATTRS_NAMESPACE_EXT(-59, -59, "Increase number of xattr namespaces"),
BLOCK_STORAGE_POLICY(-60, -60, "Block Storage policy"),
TRUNCATE(-61, -60, "Truncate"),
APPEND_NEW_BLOCK(-62, -60, "Support appending to new block"),
QUOTA_BY_STORAGE_TYPE(-63, -60, "Support quota for specific storage types"),
ERASURE_CODING(-64, -60, "Support erasure coding");
DataNode升级后,DataNode layoutVersion不兼容,HDFS 3.x DataNode降级到HDFS 2.x DataNode无法启动。
2021-04-19 10:41:01,144 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/data/dfs/dn/
org.apache.hadoop.hdfs.server.common.IncorrectVersionException: Unexpected version of storage directory /data/dfs/dn. Reported: -57. Expecting = -56.
at org.apache.hadoop.hdfs.server.common.StorageInfo.setLayoutVersion(StorageInfo.java:178)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.setFieldsFromProperties(DataStorage.java:665)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.setFieldsFromProperties(DataStorage.java:657)
at org.apache.hadoop.hdfs.server.common.StorageInfo.readProperties(StorageInfo.java:232)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:759)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.LoadStorageDirectory(DataStorage.java:302)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.LoadDataStorage(DataStorage.java:418)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:397)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:575)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1560)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBLockPool(DataNode.java:1520)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:341)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:219)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:673)
at java.lang.Thread.run(Thread.java:748)
HDFS 2.6.0 DataNode layoutVersion是 -56,HDFS 3.1.1 DataNode layoutVersion是 -57。
DataNode layoutVersion改变的原因:Hadoop社区自 HDFS-2.8.0 commit HDFS-8791 后,对DataNode的Layout进行了升级,DataNode Block Pool数据块目录存储结构从256 x 256个目录变成了32 x 32个目录。目的是通过减少DataNode目录层级来优化Du操作引发的性能问题。
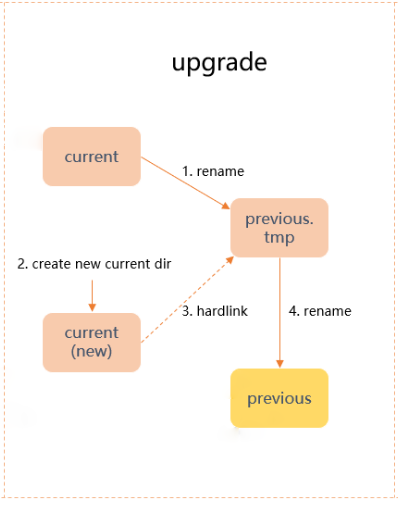
DataNode Layout升级过程:
-
rename当前current目录,到previous.tmp。
-
新建current目录,并且建立hardlink从previous.tmp到新current目录。
-
rename目录previous.tmp为previous目录。
Layout升级流程图:
DN Layout升级过程中存储目录结构:

hardlink的link关联模式图:
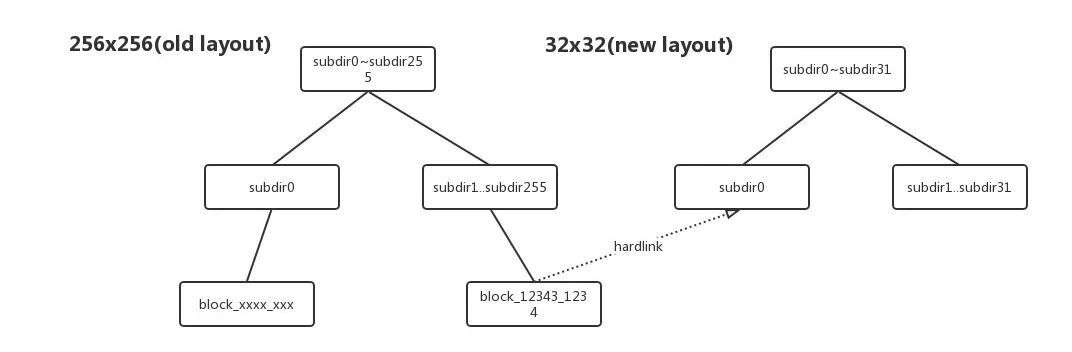
查看DataNodeLayoutVersion代码,定义了32 x 32个目录结构的layoutVersion是-57。说明DataNode Layout升级需要改变layoutVersion。
DataNodeLayoutVersion
public enum Feature implements LayoutFeature {
FIRST_LAYOUT(-55, -53, "First datanode layout", false),
BLOCKID_BASED_LAYOUT(-56,
"The block ID of a finalized block uniquely determines its position " +
"in the directory structure"),
BLOCKID_BASED_LAYOUT_32_by_32(-57,
"Identical to the block id based layout (-56) except it uses a smaller"
+ " directory structure (32x32)");
我们在测试环境进行DataNode Layout升级发现有如下问题:DataNode创建新的current目录并建立hardlink的过程非常耗时,100万block数的DataNode从Layout升级开始到对外提供读写服务需要5分钟。这对于我们接近万台DataNode的HDFS集群是不能接受的,难以在预定的升级时间窗口内完成DataNode 的升级。
因此,我们在HDFS 3.1.1版本回退了 HDFS-8791,DataNode不进行Layout升级。测试发现100200万block数的DataNode升级只需要90180秒,对比Layout升级时间大幅缩短。
回退了 HDFS-8791,DataNode Du带来的性能问题怎么解决呢?
我们梳理了HDFS 3.3.0版本的patch,发现了HDFS-14313 从内存中计算DataNode使用空间,不再使用Du操作, 完美的解决了DataNode Du性能问题。我们在升级后的HDFS 3.1.1版本打入HDFS-14313,解决了DataNode升级后Du操作带来的io性能问题。
5.6 DataNode Trash目录处理
上图所示,DataNode升级过程中,DataNode 在删除 Block 时,是不会真的将 Block 删除的,而是先将Block 文件放到磁盘BlockPool 目录下一个 trash 目录中,为了能够使用原来的 rollback_fsimage 恢复升级过程中删除的数据。我们集群磁盘的平均水位一直在80%,本来就很紧张,升级期间trash 中的大量Block文件会对集群稳定性造成很大威胁。
考虑到我们的方案回退方式是滚动降级而非Rollback,并不会用到trash 中的Block。所以我们使用脚本定时对 trash 中的 Block 文件进行删除,这样可以大大减少 Datanode 上磁盘的存储压力。
5.7 其它问题上述就是我们HDFS升级降级过程中遇到的所有不兼容问题。除了不兼容问题,我们还在升级的HDP HDFS 3.1.1版本引入了一些NameNode RPC 优化patch。
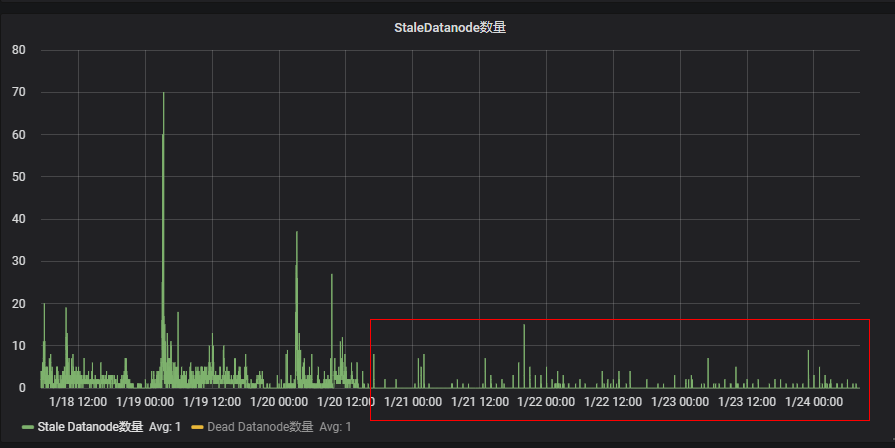
HDFS 2.6.0版本FoldedTreeSet红黑树数据结构导致NameNode运行一段时间后RPC性能下降,集群出现大量StaleDataNode,导致任务读取block块失败。Hadoop 3.4.0 HDFS-13671 修复了这个问题,将FoldedTreeSet回退为原来的LightWeightResizableGSet 链表数据结构。我们也将HDFS-13671 patch引入我们升级的HDP HDFS 3.1.1版本。
升级后HDFS-13671的优化效果:集群StaleDataNode数量大幅减少。
我们在2021年3月份启动离线数仓集群HDFS升级专项,在测试环境搭建了多套HDFS集群进行了viewfs模式下多轮HDFS升级、降级演练。不断的总结与完善升级方案,解决升级过程中遇到的问题。
6.1 全量组件 HDFS 客户端兼容性测试在HDFS升级中只升级了Server端,HDFS Client还是HDFS 2.6.0版本。因此,我们要保证业务通过HDFS 2.6.0 Client能正常读写HDFS 3.1.1集群。
我们在测试环境,搭建了线上环境类似的HDFS测试集群,联合计算组同事与业务部门,对Hive、Spark、OLAP(kylin、presto、druid)、算法平台使用HDFS 2.6.0 Client读写HDFS 3.1.1,模拟线上环境进行了全量业务的兼容性测试。确认HDFS 2.6.0 Client能正常读写HDFS 3.1.1集群,兼容性正常。
6.2 升级操作脚本化我们严格梳理了HDFS升级降级的命令,梳理了每一步操作的风险与注意事项。通过CM、Ambari API启停HDFS服务。将这些操作都整理成python脚本,减少人为操作带来的风险。
6.3 升级点检我们梳理了HDFS升级过程中的关键点检事项,确保HDFS升级过程中出现问题能第一时间发现,进行回退,降底对业务的影响。
6.4 正式升级我们在测试环境中进行了多次HDFS升级降级演练,完成HDFS兼容性测试相关的工作,公司内部写了多篇WIKI 文档进行记录。
确认测试环境HDFS升级降级没问题之后,我们开始了升级之路。
相关的具体里程碑上线过程如下:
-
2021年3~4月,梳理HDFS 3.x版本新特性与相关patch,阅读HDFS滚动升级降级的源码,确定最终升级的HDFS 3.x版本。完成HDFS 2.x已有优化patch与HDFS 3.x高版本patch移植到升级的HDFS 3.x版本。
-
2021年5~8月,进行HDFS升级降级演练,全量Hive、Spark、OLAP(kylin、presto、druid)兼容性测试,确定HDFS升级降级方案没有问题。
-
2021年9月,yarn日志聚合HDFS集群(百台)升级到HDP HDFS 3.1.1,期间修复日志聚合大量ls调用导致的RPC性能问题,业务未受到影响。
-
2021年11月,7个离线数仓HDFS集群(5000台左右)升级到HDP HDFS 3.1.1,用户无感知,业务未受到影响。
-
2022年1月,完成离线数仓HDFS集群(10个集群规模接近万台)升级到HDP HDFS 3.1.1,用户无感知,业务未受到影响。
升级之后,我们对离线数仓各个集群进行了观察,目前HDFS服务运行正常。
七、总结我们耗时一年时间将万台规模的离线数仓HDFS集群从CDH HDFS 2.6.0升级到了HDP HDFS 3.1.1版本,管理工具从CM成功切换到了Ambari。
HDFS 升级过程漫长,但是收益是非常多的,HDFS升级为后续YARN、Hive/Spark、HBase组件升级打下了基础。
在此基础上,我们可以继续做非常有意义的工作,持续在稳定性、性能、成本等多个方面深入探索,使用技术为公司创造可见的价值。
参考资料
-
https://issues.apache.org/jira/browse/HDFS-13596
-
https://issues.apache.org/jira/browse/HDFS-14396
-
https://issues.apache.org/jira/browse/HDFS-14831
-
https://issues.apache.org/jira/browse/HDFS-14942
-
https://issues.apache.org/jira/browse/HDFS-9788
-
https://issues.apache.org/jira/browse/HDFS-3107
-
https://issues.apache.org/jira/browse/HDFS-8791
-
https://issues.apache.org/jira/browse/HDFS-14313
-
https://issues.apache.org/jira/browse/HDFS-13671