大家好,我是大D。
今天开始给大家分享关于大数据入门技术栈——Hadoop的学习内容。
初识 Hadoop为了解决大数据中海量数据的存储与计算问题,Hadoop 提供了一套分布式系统基础架构,核心内容包含HDFS ( Hadoop Distributed File System, 分布式文件系统)、MapReduce计算引擎和YARN (Yet Another Resource Negotiator,另一种资源协调者)统一资源管理调度。
随着大数据技术的更新迭代,如今 Hadoop 不再是一个单独的技术,而是一套大数据处理的生态圈,如下图所示。
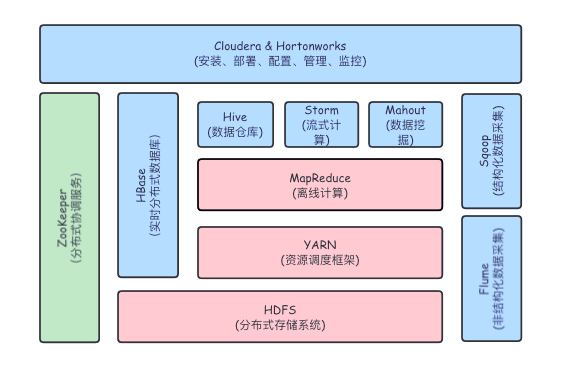
除了上述提到的 Hadoop 三个核心组件之外,还有数据采集工具Sqoop与Flume,它们可以将海量数据抽取到Hadoop平台上,进行后续的大数据分析;ZooKeeper能够保证Hadoop集群在部分节点宕机的情况下依然可靠运行(干货总结!一文搞定 ZooKeeper ,面试再也不用背八股(文末送PDF));基于Hadoop运算平台的数据仓库Hive、流式计算Storm、数据挖掘工具Mahout和分布式数据库HBase等大数据技术框架。
HDFSHDFS (Hadoop Distributed File System, 分布式文件系统) 是Google公司的GFS论文思想的实现,也作为 Hadoop 的存储系统,它包含客户端(Client)、元数据节点(NameNode)、备份节点(Secondary NameNode)以及数据存储节点(DataNode)。

HDFS 利用分布式集群节点来存储数据,并提供统一的文件系统访问接口。这样,用户在使用分布式文件系统时就如同在使用普通的单节点文件系统一样,仅通过对 NameNode 进行交互访问就可以实现操作HDFS中的文件。HDFS提供了非常多的客户端,包括命令行接口、Java API、Thrift接口、Web界面等。
NameNodeNameNode 作为 HDFS 的管理节点,负责保存和管理分布式系统中所有文件的元数据信息,如果将 HDFS 比作一本书,那么 NameNode 可以理解为这本书的目录。
其职责主要有以下三点:
- 负责接收 Client 发送过来的读写请求;
- 管理和维护HDFS的命名空间: 元数据是以镜像文件(fsimage)和编辑日志(editlog)两种形式存放在本地磁盘上的,可以记录 Client 对 HDFS 的各种操作,比如修改时间、访问时间、数据块信息等。
- 监控和管理DataNode:负责监控集群中DataNode的健康状态,一旦发现某个DataNode宕掉,则将该 DataNode 从 HDFS 集群移除并在其他 DataNode 上重新备份该 DataNode 的数据(该过程被称为数据重平衡,即rebalance),以保障数据副本的完整性和集群的高可用性。
SecondaryNameNode 是 NameNode 元数据的备份,在NameNode宕机后,SecondaryNameNode 会接替 NameNode 的工作,负责整个集群的管理。并且出于可靠性考虑,SecondaryNameNode 节点与 NameNode 节点运行在不同的机器上,且 SecondaryNameNode 节点与 NameNode 节点的内存要一样大。
同时,为了减小 NameNode 的压力,NameNode 并不会自动合并 HDFS中的元数据镜像文件(fsimage)和编辑日志(editlog),而是将该任务交由 SecondaryNameNode 来完成,在合并完成后将结果发送到NameNode, 并再将合并后的结果存储到本地磁盘。
DataNode存放在HDFS上的文件是由数据块组成的,所有这些块都存储在DataNode节点上。DataNode 负责具体的数据存储,并将数据的元信息定期汇报给 NameNode,并在 NameNode 的指导下完成数据的 I/O 操作。
实际上,在DataNode节点上,数据块就是一个普通文件,可以在DataNode存储块的对应目录下看到(默认在$(dfs.data.dir)/current的子目录下),块的名称是 blk_ID,其大小可以通过dfs.blocksize设置,默认为128MB。
初始化时,集群中的每个 DataNode 会将本节点当前存储的块信息以块报告的形式汇报给 NameNode。在集群正常工作时,DataNode 仍然会定期地把最新的块信息汇报给 NameNode,同时接收 NameNode 的指令,比如创建、移动或删除本地磁盘上的数据块等操作。
HDFS数据副本HDFS 文件系统在设计之初就充分考虑到了容错问题,会将同一个数据块对应的数据副本(副本个数可设置,默认为3)存放在多个不同的 DataNode 上。在某个 DataNode 节点宕机后,HDFS 会从备份的节点上读取数据,这种容错性机制能够很好地实现即使节点故障而数据不会丢失。
HDFS的工作机制 NameNode 工作机制NameNode简称NN
- NN 启动后,会将镜像文件(fsimage)和编辑日志(editlog)加载进内存中;
- 客户端发来增删改查等操作的请求;
- NN 会记录下操作,并滚动日志,然后在内存中对操作进行处理。
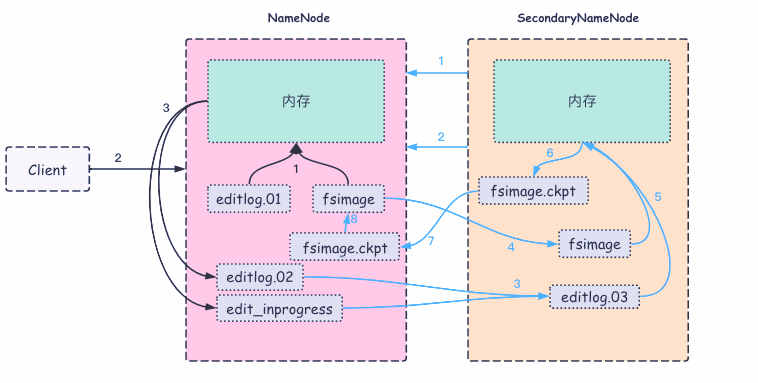
SecondaryNameNode简称2NN
- 当编辑日志数据达到一定量或者每隔一定时间,就会触发 2NN 向 NN 发出 checkpoint请求;
- 如果发出的请求有回应,2NN 将会请求执行 checkpoint 请求;
- 2NN 会引导 NN 滚动更新编辑日志,并将编辑日志复制到 2NN 中;
- 同编辑日志一样,将镜像文件复制到 2NN 本地的 checkpoint 目录中;
- 2NN 将镜像文件导入内存中,回放编辑日志,将其合并到新的fsimage.ckpt;
- 将 fsimage.ckpt 压缩后写入到本地磁盘;
- 2NN 将 fsimage.ckpt 传给 NN;
- NN 会将新的 fsimage.ckpt 文件替换掉原来的 fsimage,然后直接加载和启用该文件。
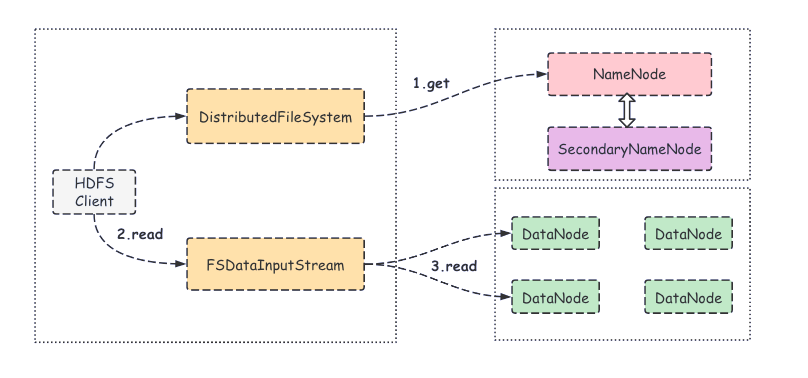
- 客户端调用 FileSystem 对象的open()方法,其实获取的是一个分布式文件系统(DistributedFileSystem)实例;
- 将所要读取文件的请求发送给 NameNode,然后 NameNode 返回文件数据块所在的 DataNode 列表(是按照 Client 距离 DataNode 网络拓扑的远近进行排序的),同时也会返回一个文件系统数据输入流(FSDataInputStream)对象;
- 客户端调用 read() 方法,会找出最近的 DataNode 并连接;
- 数据从 DataNode 源源不断地流向客户端。
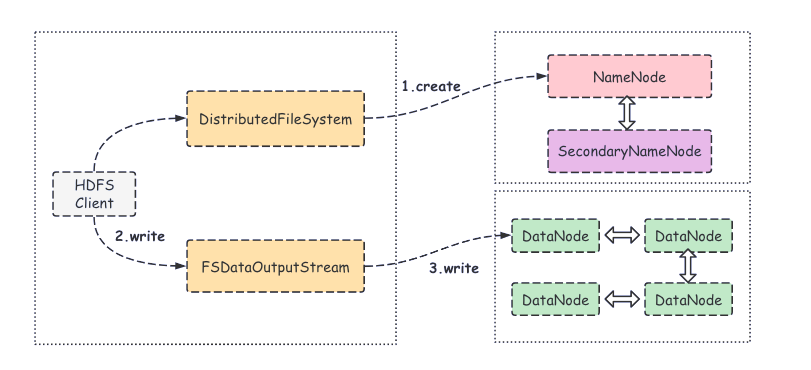
- 客户端通过调用分布式文件系统(DistributedFileSystem)的create()方法创建新文件;
- DistributedFileSystem 将文件写入请求发送给 NameNode,此时 NameNode 会做各种校验,比如文件是否存在,客户端有无权限去创建等;
- 如果校验不通过则会抛出I/O异常。如果校验通过,NameNode 会将该操作写入到编辑日志中,并返回一个可写入的 DataNode 列表,同时,也会返回文件系统数据输出流(FSDataOutputStream)的对象;
- 客户端在收到可写入列表之后,会调用 write() 方法将文件切分为固定大小的数据包,并排成数据队列;
- 数据队列中的数据包会写入到第一个 DataNode,然后第一个 DataNode 会将数据包发送给第二个 DataNode,依此类推。
- DataNode 收到数据后会返回确认信息,等收到所有 DataNode 的确认信息之后,写入操作完成。
更多图解大数据技术的干货文章,关注公众号: Data跳动,回复:图解系列。
另外,非常欢迎大家扫描下方二维码,加我VX:Abox_0226,备注「进群」,有关大数据技术的问题在群里一起探讨。