回归分析的英文是regression analysis,它是现在数据分析里面用的最多的方法之一吧,也可以说是非常重要的一种统计思想,大学学习的第一个模型就是回归模型,回归分析是一门特别重要的专业课,所以足见这个方法的重要性。
首先回归分析能解决什么问题。
在做实际数据分析的时候我们经常会遇到这样的问题,比如说产品的价格是不是会显著的影响它的销量,比如说不同性别的人在某一个领域,他的收入是不是有显著的差异。这些问题呢,都可以用回归分析的方法来回答,所以可见回归在解决实际问题的时候确实是非常的实用的。
回归需要了解几个要素。
第一个要素呢,叫做因变量,我用大写的Y来记。因变量,英文又叫做response,它顾名思义就是因为别人的改变而变化的量,这个量很重要,它是我们的研究目标,或者在企业里边可能是我们关心的一个核心的业务问题,所以在做数据分析的时候呢,我们往往要先确定因变量,就是明确我们研究的目标和我们核心关心什么问题。
根据因变量的数据类型,可分为不同的回归模型的类型,所以对于因变量的数据类型的把握,实际上是非常重要的。
比较常见的有这么几种:连续型、0-1型、计数型、定序型、生存数据。
连续型比如个人消费金额,
0-1型:比如借款人贷款后会不会还款,
计数型:比如一天内致电客服的人数,
定序型:比如问卷调查里面的满意、一般、不满意,
生存数据:比如半年内客户是否欠款。
确定了研究问题之后就确定了这个因变量,搞清楚它的类型,选对回归模型的形式。
回归分析干的事情就是首先明确这个因变量Y,因变量是因为其他的量的改变而变化的量,
那其他变量是谁?这些就是自变量,我们通常用X来记。自变量是指会去影响到因变量的可能的因素,
比如说我们的因变量是收入,我特别关心收入哪些因素会影响到它,那这里边可能有学历,有职业,有年龄等等,你可以头脑风暴一大堆。
自变量的类型不决定回归模型的类型,自变量不管是定性的还是定量的,它不决定回归模型的基本形式,所以这一点要牢记。
回归模型的基本形式由因变量所决定,那再去确定自变量的时候呢,有一些办法,比如头脑风暴。
头脑风暴是一方面,
另一方面也要看这个数据能不能获取到,有的时候可能头脑风暴想的很好,以及这个指标特别的关键,但没法获取这部分数据,那也是肯定不行的,所以自变量的选择往往就是看数据的一个可获取性,这是因变量和自变量。
那自变量到底是怎么去影响因变量的呢,这个就是我们回归模型的基本的形式了。
自变量呢,通过一个函数去影响因变量,函数的形式可以多种多样,
可以是线性或非线性,
我们看到还有一个很特殊的变量ε,
如果没有这个量就变成了Y=F(X),这是一个数学函数,比如说Y=a+bX,那他就是一个直线的方程,比如说Y=aX**2+bX+c,那他就是一个抛物线的方程。
在回归模型里边最特殊和最重要的,实际上就是这个ε,它的读法是Epsilon,就是经常拿这个符号来记,
ε这一项,叫做随机误差,它英文叫做random Error,Random error是说除了自变量之外,肯定还有观察不到的因素,
对于Y有影响,但是一方面可能是由数据可获取性的原因,实在是拿不到它,
另一方面有可能认识不充分,还没有考虑周全,有一些因素没有被纳入模型里边,
所以呢,把这些通通的合起来放到这个随机误差里边,管它叫做一个这个除了X之外对Y有影响的因素的这么一个集合。
注意他可是观察不到的观测不到的,unobserver的,所以这就是一个回归模型或者一个统计模型最基本的形式了,
我们也管这个F(x)叫做一个确定性或者系统性的一个因素。
随机的误差,看不到的一个因素,Y是由这两部分共同决定的,那统计模型的特殊性就在你不能忽略随机误差,就是它是一定要在的,它也是特色所在,如果没有它的话,就一切都是确定的形式,那就变成了一个数学,而不是统计了。
所以希望大家通过随机误差来理解好到底什么叫做一个统计模型。
那我们举一个具体的例子,比如说我有两个自变量,Y是我的收入,然后我的X1呢,比如说是我的年龄,X2呢,可能是性别。我的Y呢,就等于α0+β1x1+β2x2+ε。这就是特别简单的一个线性回归模型的基本形式,这个模型里边我们注意到啊,实际上F(x)=α0+β1x1+β2x2,你说你怎么知道F(x)这个形式。
实际上F是什么形式,也没人知道,就是不知道这个数据产生的机制是什么样子的,我们就都会有各种假定,各种尝试,那往往都从最简单的开始学习和研究对吧,
线性模型是最简单的一个形式了,所以我们就先会学习线性回归模型,研究它的各种性质哦,那这里边真实情况是怎么样不知道,而且大概率真实情况也不会是一个线性的,但不妨碍我们就是去学习回归或者统计模型,这种思想作为一个起点来理解它。
所以这个线性回归模型虽然简单,但也是最常用的,往往越简单越朴素的越好用,就是效果越好,然后咱们再一起来看一下呗。α0、β1和β2是未知的,他们叫做一个回归系数,我们的核心任务是要去把他估计出来啊,估计出来,比如说β1他就代表了年龄对收入的一种影响,比如说估计出来它是正的,那也就是年龄越大,收入就平均水平就会越高哦,就可以做这种类似的解读,
所以呢,我们的核心任务是把它去估计出来,估计它呢,需要利用到样本数据,我们能获得的样本数据实际上就是X和Y,那是我们能获得的,比如说第一个人,X11她的年龄30岁,X2性别女性,然后收入是多少等等,我们能拿到,就是样本量,N组观测就是我们的样本数据,我们会去估计它,这个是我们的核心的任务,估计完了它之后呢,就把β0、β1和β2算出来了,把她它带进去,这个函数表示这是根据样本数据预测出来的,这就是我的预测的方程,
回归模型的第二个任务就是要做一下整体的一个评价,就是我去用这样一个线性的方程到底整个的效果是怎么样的啊。那把这个评价好了之后,觉得它可用可行,就要去做一个很重要的任务,叫做预测,
比如说一个人,他过来来贷款了对吧,我有一个已有的模型,那我是已知他的X,他填了他的性别,他的收入,我想要去预测它是不是会还不了款。
这时候就要利用已有的模型去预测未知的一个Y,所以从这几个核心的步骤也能看出来,我们建立回归模型就是要完成了两个非常重要的任务,
第一个就是解读。解读,也就是去看这个未知的回归系数啊,比如说估计出来β1=3,它代表着X1对Y的一种影响。这种解读呢,挺重要的,在业务上我可以获得各个因素对我核心的业务指标的一种影响,我可以基于这样的一种数据分析和解读对我的业务提供各种建议和帮助,
第二呢就是预测。预测,就像刚才说的,我来了一个人申请贷款,他只有X,但是我又特别关心他的Y,我就特别想知道他会不会欠款,这对于我来说很重要啊,由已知的X预测未知的Y,是这个回归的另外一个非常重要的任务,
所以总结了两点回归模型能做什么,把他估计出来之后呢,一方面去做解读,另一方面去做预测。
线性回归是在金融数据分析中很基础的机器学习算法,本文将通俗易懂的介绍线性回归的基本概念,优缺点和逻辑回归的比较。
首先回顾一下之前统计学习中比较重要的几个关键点:
---自变量和因变量
在统计学习的背景下,有两种类型的数据:
· 自变量:可以直接控制的数据。
· 因变量:无法直接控制的数据。
无法控制的数据,即因变量,需要进行预测或估计。
---模型
模型本质上就是一个转换引擎,主要的作用就是找到自变量和因变量之间的关系函数。
---参数
参数是添加到模型中用于输出预测的要素。
什么是线性回归?
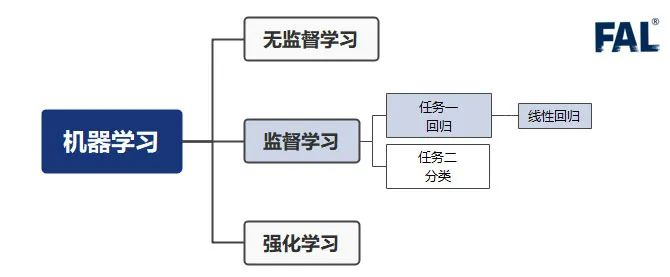
线性回归的位置如上图所示,它属于机器学习 — 监督学习 — 回归 — 线性回归。
什么是回归?
回归是一种基于独立预测变量对目标值进行建模的方法。回归的目的主要是用于预测和找出变量之间的因果关系。比如预测明天的天气温度,预测股票的走势。回归之所以能预测是因为它通过历史数据,摸透了"套路",然后通过这个套路来预测未来的结果。
回归技术主要根据自变量的数量以及自变量和因变量之间的关系类型而有所不同。

什么是线性?
线性的意思是:数据点排成一条直线(或接近直线),或者沿直线延长。线性意味着,因变量和自变量之间的关系可以用直线表示。
"越…,越…"符合这种说法的就可能是线性关系:「房子」越大,「租金」就越高「金子」买的越多,花的「钱」就越多杯子里的「水」越多,「重量」就越大……
但是并非所有"越…,越…"都是线性的,比如"充电越久,电量越高",它就类似下面的非线性曲线:
线性关系不仅仅只能存在 2 个变量(二维平面)。3 个变量时(三维空间),线性关系就是一个平面,4 个变量时(四维空间),线性关系就是一个体。以此类推...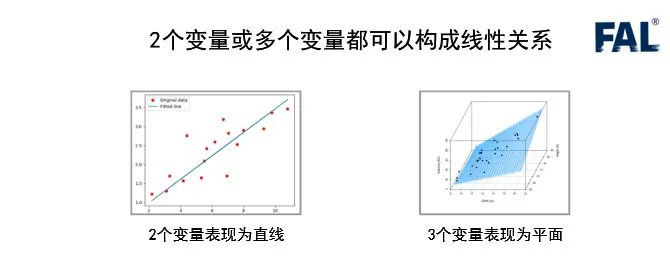
什么是线性回归?
线性回归本来是是统计学里的概念,现在经常被用在机器学习中。
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w'x+e,e为误差服从均值为0的正态分布。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
如果 2 个或者多个变量之间存在"线性关系",那么我们就可以通过历史数据,摸清变量之间的"套路",建立一个有效的模型,来预测未来的变量结果。


线性回归的优缺点
优点:
-
建模速度快,不需要很复杂的计算,在数据量大的情况下依然运行速度很快;
-
可以根据系数给出每个变量的理解和解释。
缺点:
不能很好地拟合非线性数据。所以需要先判断变量之间是否是线性关系。
线性回归 VS 逻辑回归
线性回归和逻辑回归是 2 种经典的算法。经常被拿来做比较,下面整理了一些两者的区别:

- 线性回归只能用于回归问题,逻辑回归虽然名字叫回归,但是更多用于分类问题;
- 线性回归要求因变量是连续性数值变量,而逻辑回归要求因变量是离散的变量;
- 线性回归要求自变量和因变量呈线性关系,而逻辑回归不要求自变量和因变量呈线性关系;
- 线性回归可以直观的表达自变量和因变量之间的关系,逻辑回归则无法表达变量之间的关系;