
导读: 今天和大家分享京东零售OLAP平台的建设和场景的实践,主要包括四大部分:
- 管控面建设
- 优化技巧
- 典型业务
- 大促备战
--
01 管控面建设 1. 管控面介绍管控面可以提供高可靠高效可持续运维保障、快速部署小时交付的能力,尤其是针对ClickHouse这种运维较弱但是性能很高的OLAP核心引擎,管控面就显示得尤其重要。

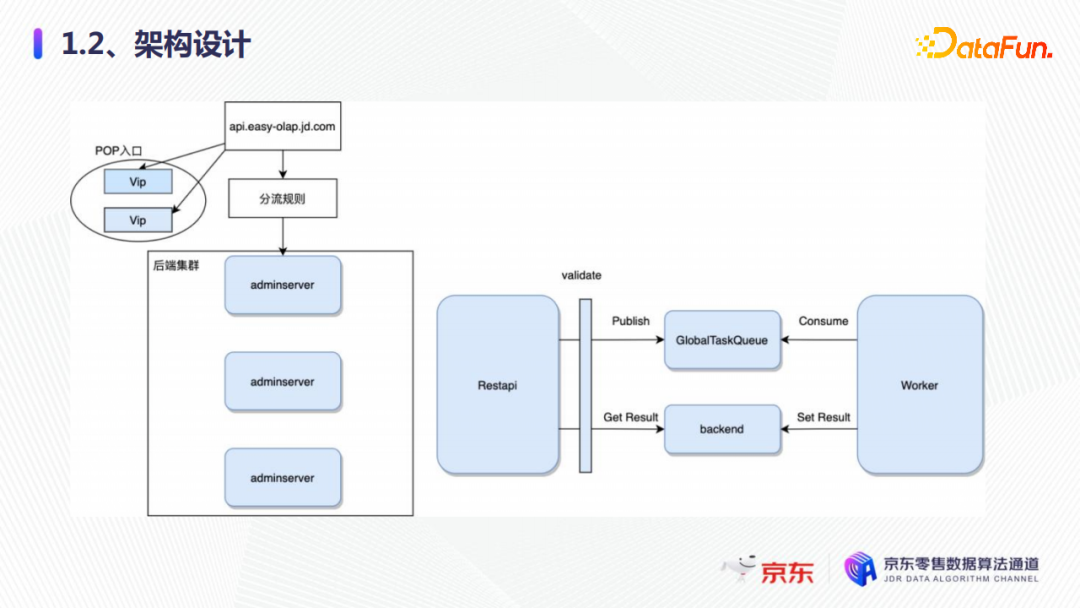
管控面的整体架构设计如上图所示,从开始请求、域名解析和分流规则,到达后端服务adminServer,adminServer有一层校验层,校验完成后会向队列中发送任务,worker会不断地消费队列中的任务,消费完成后会将任务的结果写到后端的存储。如果有大量的集群的部署、配额的更改,就会有一系列的任务在这里完成。完成之后,再到数据部门进行保存,这就是整体的架构设计。
3. 业务管理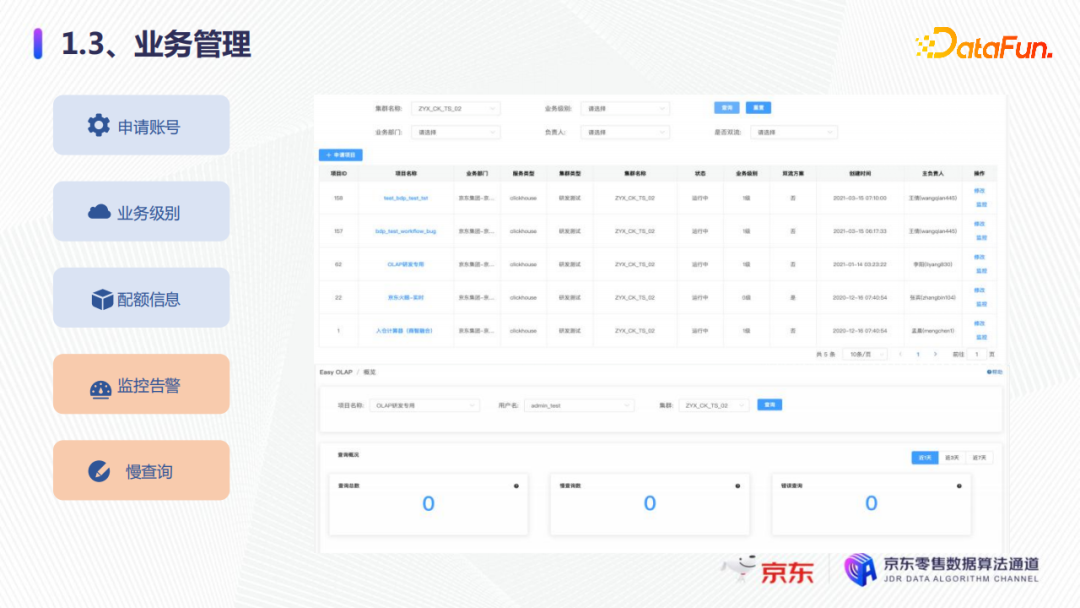
在业务管理方面,管控面可以提供以下功能:
- 可以用于用户的集群账号的申请;
- 业务级别的登记;
- 用户可以进行配额查询,这些配额主要包括查询数、执行的并发以及超时等;
- 用户可以自定义监控告警,通过这些监控告警去实时探索自己的整体服务的可靠性和稳定性;
- 慢查询统计告警,可以通过管控面看到当前集群业务有多少慢查询以及错误的查询、查询的总数等。
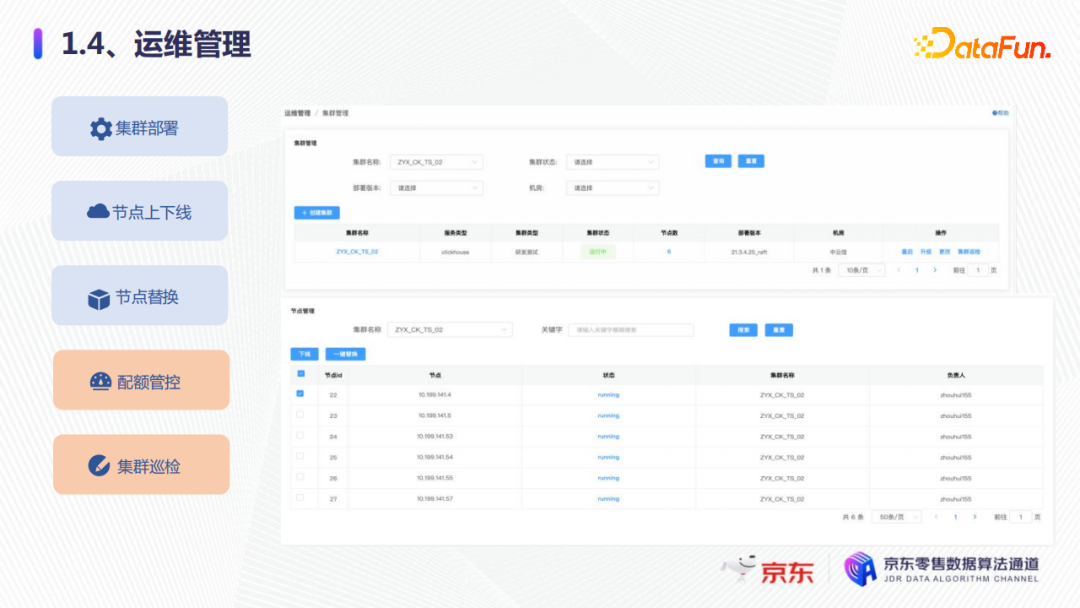
在运维管理方面:
第一,可以进行新集群的部署,比如物理资源或者容器资源已经申请好之后,可以及时进行创建资源,并及时给用户使用;
第二,比如ClickHouse有节点故障时(例如硬件故障如CPU、内存或磁盘故障),要进行及时的节点上下线或者节点替换,否则就会影响整个集群,一是影响DDL,二是影响写入。
第三,可以做配额的管控,这一点在大促中非常有用,它可以用于限制用户的查询数、并发还有超时等,防止突增的流量,导致集群的不稳定。
第四,可以进行集群的巡检,集群巡检之后,可以查看每个集群的服务状态,比如它是否可以创建表、删除表、插入数据、查询数据是否都正常等,也有实时告警集群巡检的服务状态。
以上就是我们京东零售OLAP管控面核心功能,它在集群运维方面不仅提升集群交付的效率,还节约运维的成本。
--
02 优化技巧 1. 场景难点京东零售是以电商交易和用户流量为核心的场景,有以下两方面难点:
- 第一点是交易的业务比较复杂,需要关联多张表、sql中的逻辑多,另外就是数据会实时更新,比如交易的状态和金额的变化、组织架构的变化等;
- 第二点是流量数据,它有个特点,首先追加不修改,其次是量大,因为包含了用户的点击和浏览等各类行为的数据,以及衍生的各种指标,比如UV的计算。最后是它的数据质量也会经常变化。
针对以上场景难点,我们主要用到了实时的数据更新,还有物化视图、join的优化。接下来通过一些具体案例详细讲解。
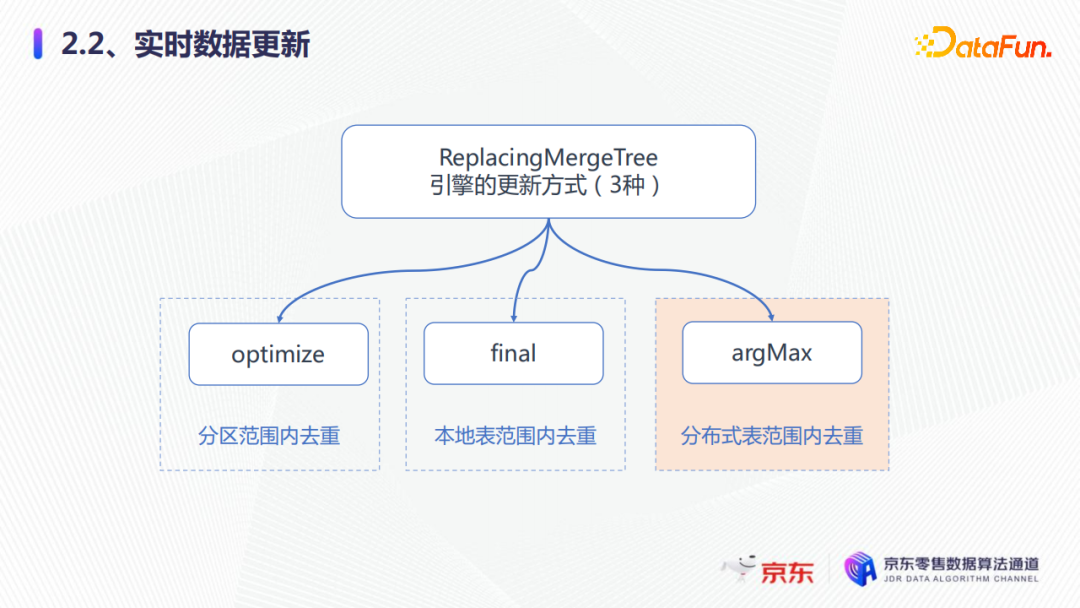
2. 实时数据更新首先看一下实时数据更新。我们创建了两张表,一张是本地表,还有一张是分布式表。

本地表主要采用ReplacingMergeTree去重的引擎,字段分别是create_time创建时间、ID、comment注释,还有数据的版本,分区是创建时间进行格式化得到的天分区,然后按照ID进行排序键去重。现在的需求是对相同的ID进行实时的数据更新。

我们在集群的两个分片中,比如分片1插入了三条数据,分片2插入了三条数据都是相同的ID(0),但是查询分布式表发现,数据并没有去重。

第一种解决方式是使用optmize去重。通过执行一个optmize去重之后,通过查询本地表就发现optmize在多分区间和分片间不能去重,只能在同一个分区中去重。

第二种方式是使用final去重。通过查询一个本地表的final,发现刚才的11日和12日的数据只保留了一条数据,这时再通过查询分布式表final去重,发现有两条12日的数据,所以我们的结论是final的方式在多个分区间可以去重,但是在多分片间不能去重。

因为我们的集群都是多分片的,所以还有第三种方式——使用argMax。我们通过argMax加了一个数据的版本,可以选择最大的一个版本号,然后通过去查询分布式表,发现argMax可以在多分片间去重,这也是我们推荐使用的一种方式。
所以实时数据更新方式一般有以上三种,但是各种方案更新的范围不同,我们可以根据自己的业务场景去使用不同的去重方式,optmize可以在分区范围内去重,final可以在本地表范围内驱动,而argMax可以在分布式表范围内去重。
接下来,我们看一下物化视图。使用物化视图的场景,比如:业务最近3小时看小时的数据,三天之前想看天粒度的数据,这时候物化视图,就是很好的选择。那么物化视图该如何使用?我们看一下这个案例,有一张明细表test,它大概有13亿行左右,直接实时的count聚合进行查询,发现它的耗时大概是2.1秒左右,怎样能让查询变得更快一些?

我们创建了一张物化视图,对原始表进行预聚合,物化视图选用了SummingMergeTree,这是聚合的一种引擎,大家也可以选择其他引擎去聚合。它会根据排序键进行二次聚合,也就是 Date 字段。还有一个select语句,它的作用是通过批次写入,把这个select语句写入到物化视图列表中。

我们创建物化视图之后,再去执行相同的语句,查询性能提升了大概113倍,耗时0.002秒左右,所以物化视图在比如量大而且可以预聚合的这种场景下非常好用。

那么物化视图就又是什么原理能够达到这样的效果?整体如图所示。
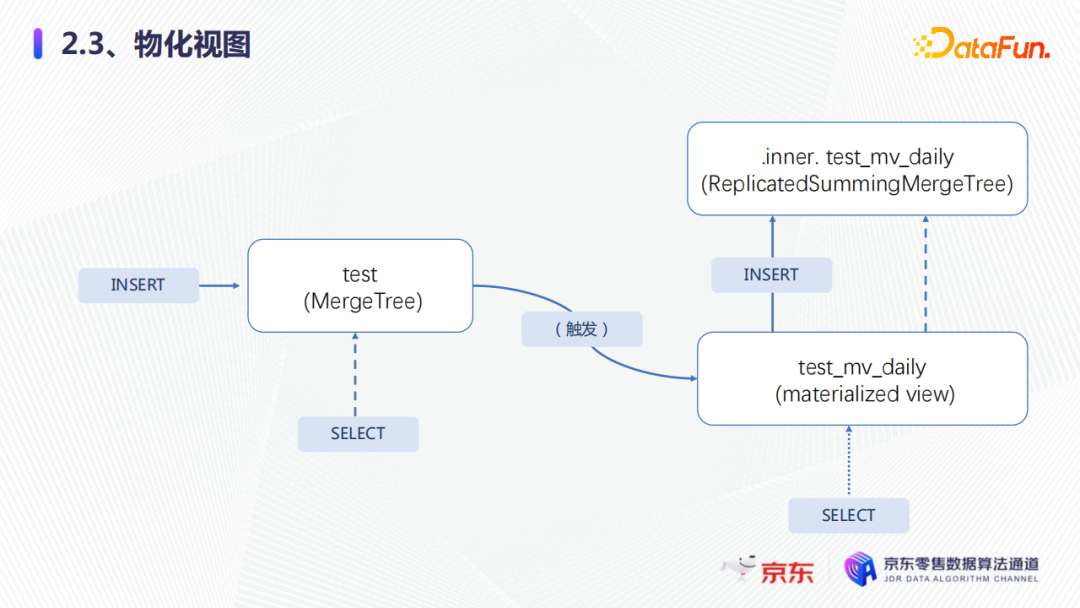
物化视图会创建一个隐藏的内表来保存视图里面的数据,然后物化视图会将写入原始表的数据,也就是通过select第一次聚合后的结果,写入物化视图的内表中列表,再根据排序键进行二次聚合,这样原始表的数据量会大量减少,查询就可以得到加速。
4. join优化在正式介绍join优化前先补充一点基础知识:对本地表的查询我们称之为部分查询,以下划线L为结尾的表称为本地表。在做这种优化之前,先看一下整体的分布式表执行的流程。
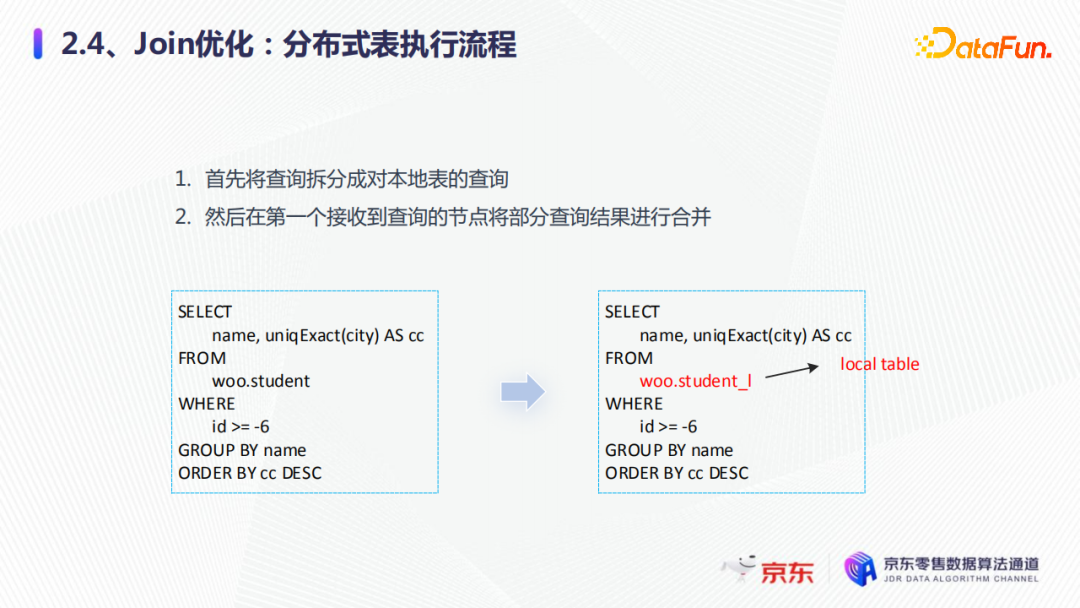
首先分布式表会将查询拆分成对本地表的查询。比如city在精确去重之后,查询分布式表,通过路由下发到各个分片的本地表上面进行查询,然后第一个接收到的查询的节点,再将本地的查询部分的结果进行合并,返回给用户,这是整体分布式表执行的流程。
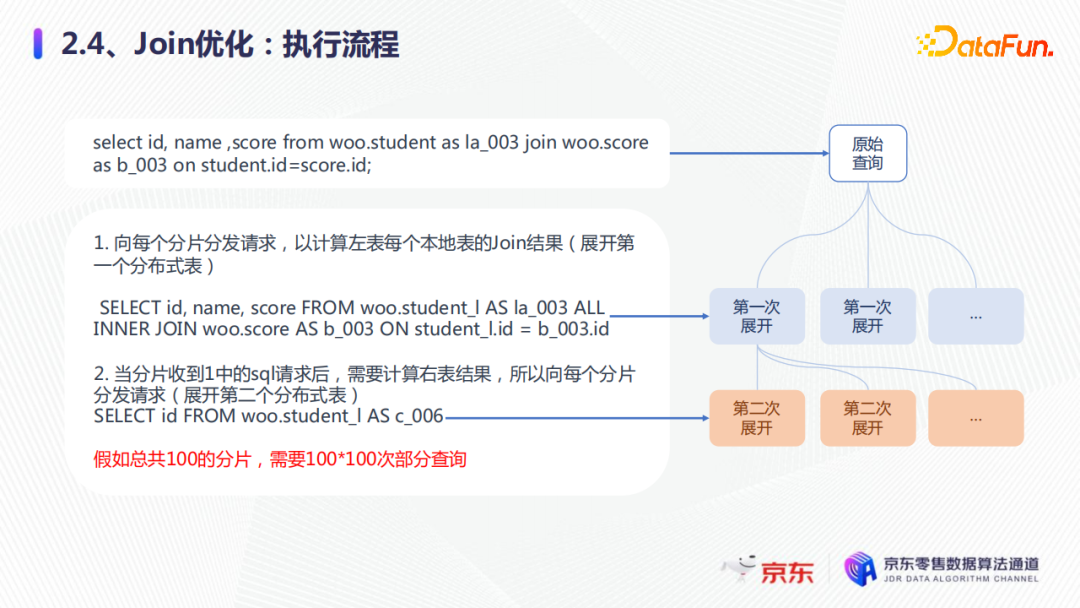
join的执行过程如上图所示。比如select id, name, score from student join score,首先展开分布式表,向每个分片分发请求,计算左表的每个本地表join的结果,第二步当分片收到1中的请求后,需要计算右表的结果,向每个分片再发送请求。这样假如集群有100个分片,就需要100×100的部分查询,每一次展开都要通过磁盘网卡,都会有耗时。
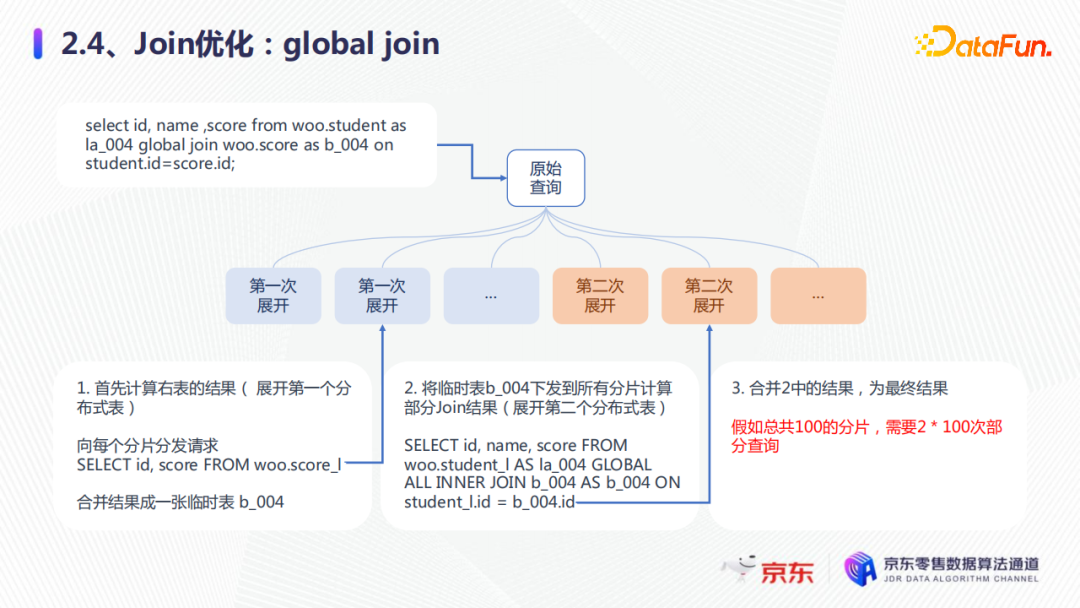
第一种优化是global join。在原始的查询中,会先计算右表结果,展开第一个分布式表,然后合并,成为一个临时表,假设命名为b_004,这是第一次展开。第二次展开时,它会将临时表b_004发送,所有的分片计算部分的join结果,就是第二次展开的分布式表,然后第三步,合并2中的结果,为最终的结果。这样整体的global join就是,假如我们有100个分片,就只需要2×100次的部分查询,大大减少了查询。

第二种优化方案就是本地join,将右表的分布式表改成本地表。这种方式的执行流程是,我们展开左表,只需要把左表的分布式表下发到各个分片上面,而右边它本身就是本地表,就直接进行合并计算,最后会合并整个部分结果即为最终的结果。假如总共有100个分片,只需要展开100次,下发每个分片,100次的查询就行了,这样就减少了带宽消耗,提升了性能。
可以优先使用本地join,其次是global join,最后要小表放在右边,这样就可以提升join的性能。
以上就是我们针对业务场景难点的一些优化技巧。
--
03 典型业务我们也希望实现高并发查询,有大吞吐的写入,但是ClickHouse在默认的配置下,不支持高并发的查询,而且写入也很慢,这是我们业务上的两大痛点。下面具体看一下两种场景。
1. 高并发查询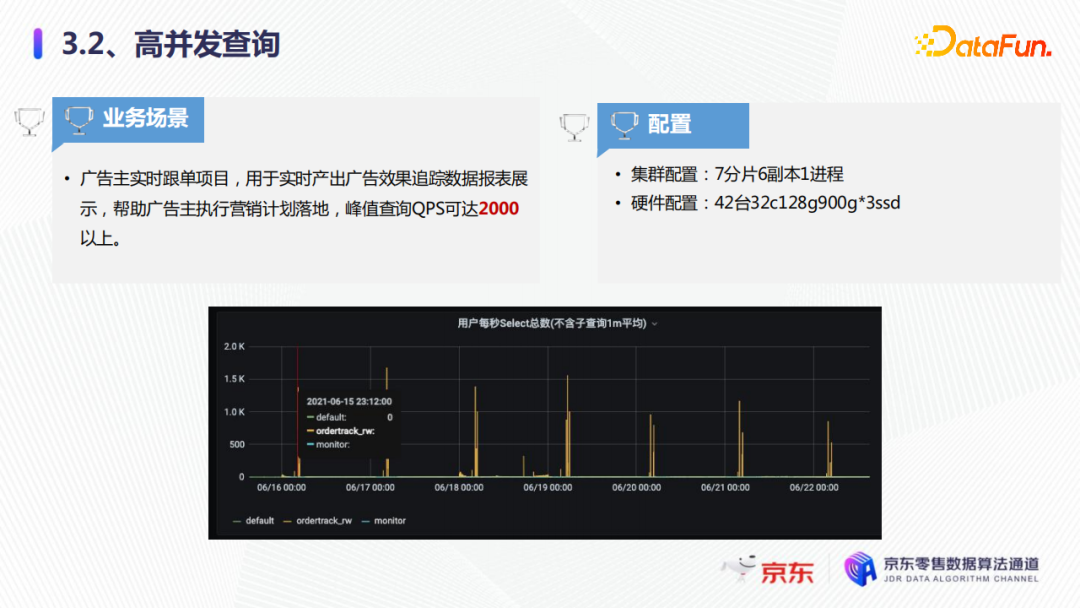
以广告实时跟单项目为例,它是用于实时产生广告效果,最终数据报表展示,帮助广告主执行营销计划落地。如图所示,可以看到每秒的QPS达到将近2000,这是618时候的一个截图。我们的集群整体的配置是7分片6副本1进程,硬件的配置是42台32C128G,900G*3的SSD的磁盘,整个集群的QPS可以达到2000。当然这个配置如果要达到2000的话,我们要进行一系列的技术优化。
首先第一点技术优化就要增加副本,因为增加副本可以提升整个集群的并发能力。第二是max_threads,减少每一个查询所用的线程数,ClickHouse如果不设置这个参数,会用物理内核的所有线程去进行查询,这样就会导致有些任务无法调度,所以要设置这个参数。第三就是要调整query_thread_log的存储,因为大量的QPS过来,会有很多的请求日志,如果我们不调整存储,很快就会将磁盘打满,造成集群的不可用。
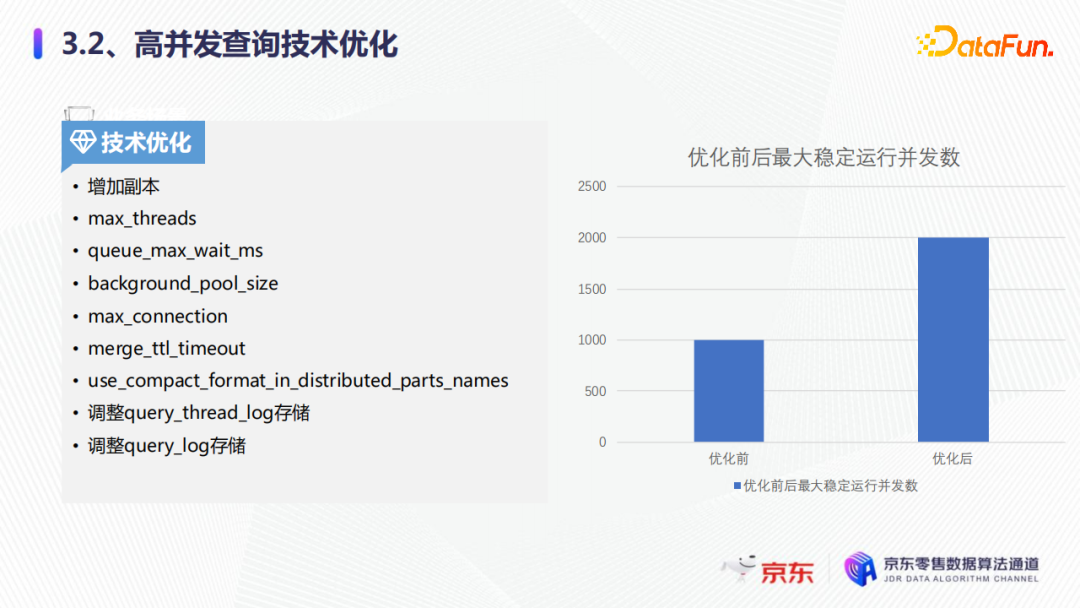
上图展示了优化前后的最大稳定运行并发数。优化前,大概只能达到1000QPS,同样的集群下优化后可以稳地运行在2000QPS左右,可以满足业务需求。
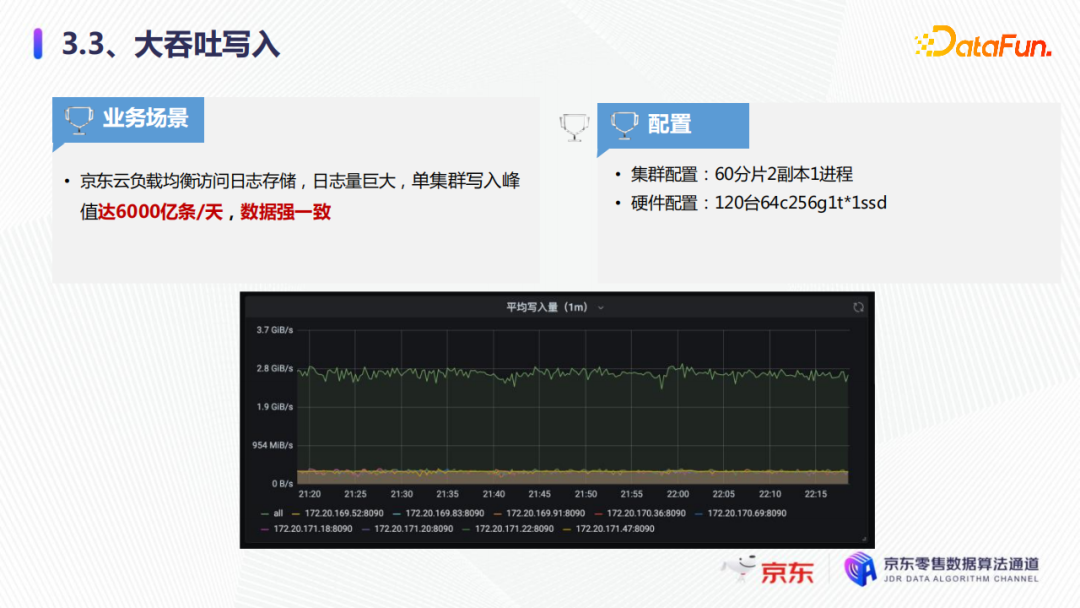
2. 大吞吐写入第二个典型业务是大吞吐的写入。以京东云监控项目为例,它负责京东云负载均衡访问日志的存储,日志量极其大,单集群写作的峰值可以达到6000亿条/天,还可以保持数据的强一致。可以看到集群日常大概是3G/秒,大促可达到6G/秒。我们的集群配置是60分片两副本1进程,硬件配置是120台64核的256G1T*1的SSD。
这样集群配置下,我们可以实现这6000亿条每天的写入。为支持这个写入量,我们也需要一系列的技术优化。
第一点就是引入了chproxy流量负载均衡,请求粒度细化至每条sql,这样每一个sql请求都会路由到不同的节。如果不引入chproxy,就会通过域名的方式直连客户端,直连集群,如果连接不及时释放,就会一直往节点里写,很容易就把集群单节点打爆了。引入了chproxy的流量负载平衡之后,sql就可以均衡地路由到各个节点。
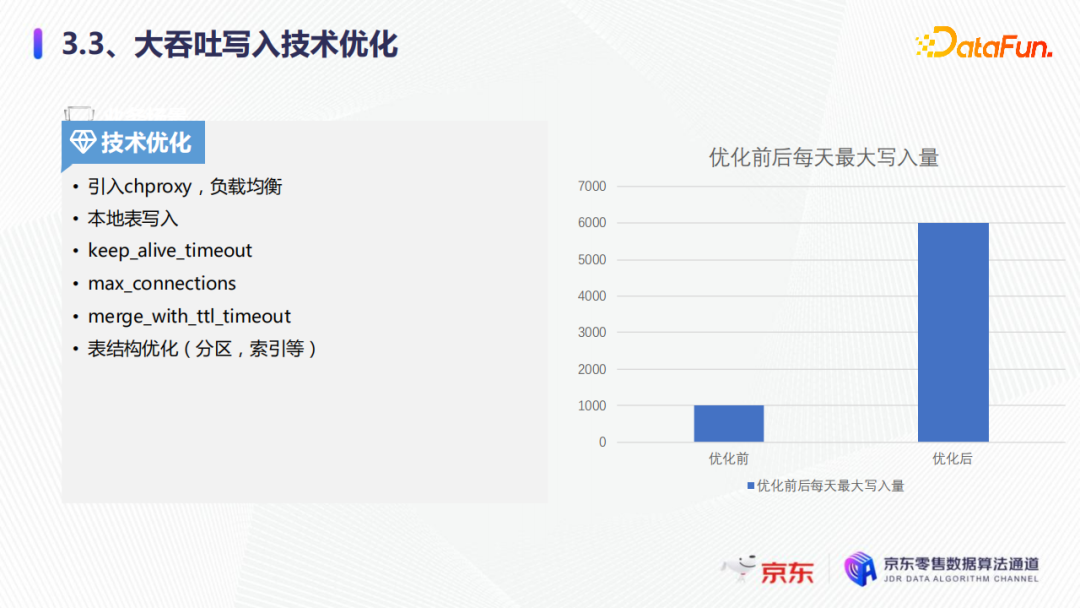
第二点就是本地表的写入,可以提升整体的写入性能,大概是分布式表的两到三倍左右。
最后我们看一下优化前后,每天最大的写入量,优化前大概是1000亿每天,优化后可以达到6000亿每天,这样就实现了大吞吐的写入。
--
04 大促备注电商场景下,经常遇到大促备战,需要保证olap服务的稳定性。
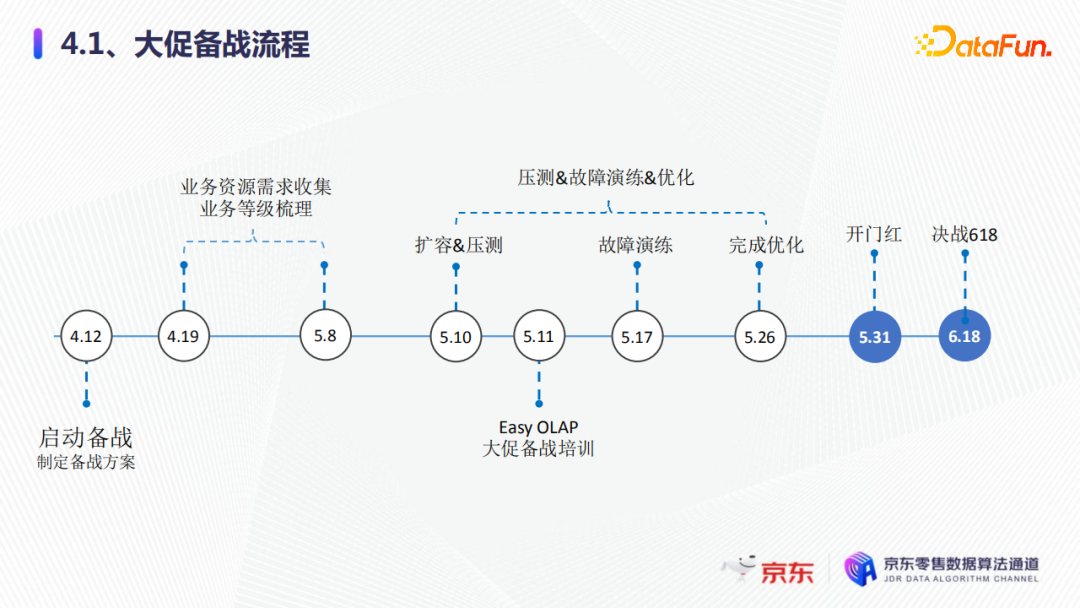
大促备战的整体流程如图所示,我们在不同的时间段需要做不同的事情。一开始是启动备战制定备战方案,收集业务的资源需求,梳理业务等级,接下来是集群的扩容压测,还有故障演练优化等,最后迎来开门红,决战618。
我们的OLAP是如何保证业务的呢?
第一,业务资源收集以及等级确认。大促前,我们平台会向业务收集有资源的需求以及等级确认,并做合理的规划和分配,来保障大促的流量急增时有足够的资源支撑运转。比如资源需求,可能有新上线的业务、扩容的业务、迁移的业务,还有替换已有集群的业务,这些都是我们大促之前要进行梳理的,这样可以提前做好预案。

第二,业务方要及时的订阅监控和报警。比如监控有CH系统层的、服务层的,还有CH查询和写入层的监控。我们有两个告警系统:一个是服务层的,比如监控CH的一些重要的指标,ZK的一些监控告警,以及chproxy流量负载的一些监控报警等;另一个是系统层的MDC告警,例如CPU、内存、磁盘、连通性,这些主要是监控硬件是否有故障。右图就是报警和监控的样例,我们可以通过它们来及时修复集群故障,也需要业务方去订阅这些监控和报警,来一起监督整个集群的稳定性和可靠性。
大促集群是如何保障的呢?
第一点是压测。我们要进行高保真的一些压测,压测的结果,要设置合理的配额,比如我们共享集群的CPU一般是40%,独占集群是80%,我们通过这些目标值设置业务的合理的配额。如果压测有问题,我们可以及时的协助业务方进行优化,来满足他们的QPS和集群的稳定性。
第二点是故障演练。我们的故障演练有很多,其中第一就是双流切换。比如我们的零级业务就是非常核心的业务,要进行主备双流,在不同的机房分别部署了两个集群,如果同一个机房有问题,要及时切到备用集群去。另外就是故障的修复。故障发生后,我们要通过管控面进行及时下线或者替换,来保证集群的稳定性和业务的可用性。
第三点就是降级措施。我们的降级措施会针对不同的业务等级进行合理分配,尤其是大促的时候不参加压测的业务。如果不参加压测,我们就会在大促前期进行业务降级,防止他们的突增流量影响大促核心业务,以保证大促时整体的集群稳定性。
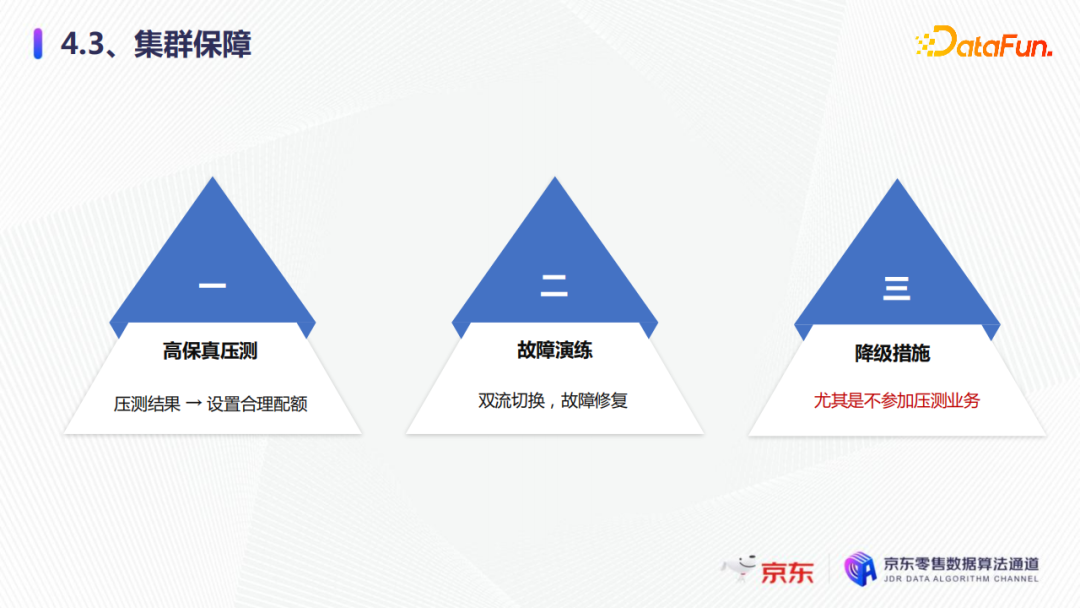
以上三点就是我们集群保障最核心的三个步骤,从一开始的高保真压测,到故障的演练,再到最后的降级措施,我们都会和业务方一起去完成,以保证整体稳定运行。
--
05 精彩问答Q:请问老师您在这个话题中遇到的最大的挑战是什么?
A:我遇到的最大挑战就是解决高并发的问题,因为高并发瞬间QPS能达到2000以上,而我们的ClickHouse默认就是100个并发。我们在高并发方面做出了很多技术调优,可以让业务达到高并发的场景。高并发的场景,遇到过很多问题,我们首先增加了多副本(一般默认情况下就是三副本或者两副本来保证数据的安全),因为每增加一台副本,就可以提升整体的一个分片的查询能力。我们还进行了一些参数调优,比如如果高并发过来,有很多的队列,这些线程我们都要去控制好,不然很容易就无法调度了。另外,高并发场景会很容易把集群的一些日志给打满,因为我们的每一条查询都会记录一条日志,我们要把日志的表的存储周期设置小一点。还要加快它的merge,因为如果不加快merge,删除数据就很慢,也很容易将磁盘打满,这是查询日志的方面。第三点就是高并发很容易触发我们的一些配额的限制,我们要对它进行一些放大。我们要进行内存的一些限制,如果不进行这些限制,或者是不放大这些限制都会引发QPS达不到,造成整体的稳定性和可用性不够。
还有一个难点是join的优化,效能优化里面其中有一个是本地join,本地join我们也做了很多的测试。比如和字典表做对比,我们发现字典表在100万以下的数据量,就是使用字典表做join性能较好,100万以上我们发现用本地join就非常好,我们通过一系列的测试实验才得到这个结论。一开始我们都是用字典表去进行黄金眼刷,但是我们最后发现在一定的性能之上,字典表还不如本地表的join。大量的POC才得到了这个结论。所以大家在字典表和本地join,也可以自己做一下全面的性能测试。
以上就是我们的两点挑战。
Q:OLAP是什么?主要用哪些引擎?
A:OLAP是在线的多维高性能实时分析服务,专业术语就是在线联机查,和mysql OLTP在线事务查询是两种不同的类型。OLAP主要面向海量数据。
我们京东零售主要用clickhouse为主、doris为辅的两个引擎。现在最流行的就是ClickHouse,其次是doris和druid这两个引擎,但是现在很多大厂,包括腾讯阿里字节都在往ClickHouse上面转,当然京东零售也应用ClickHouse两三年了。我们也进行了一系列的内核的研发,解决一些zookeeper的性能,还有在线弹性伸缩系统的一些东西,因为ClickHouse在弹性伸缩系统方面不太好,所以我们也在做这方面的工作。
Q:看到有一个业务场景中使用了120台高配置的机器,那么如果申请到这么多的资源进行业务支持,怎么考虑投入产出?
A:我们投入了120台,产出就是可以把整个京东云的所有的负载均衡。第一,我们为什么要用120台,为什么要用SSD的机型?还有为什么这么高配的机器?因为它的写入量很大,平均每天大概6000亿,算出每秒大概有1000万的数据量在往集群里写,如果不用这么高配的机器,磁盘已经是SSD了,它的性能永远达不到这个效果。第二点就是投入产出比,我们可以通过这个集群监控整个京东云的日志,还有负载均衡的效果。比如京东云,一是对外,二是对内,监控和负载均衡都是非常重要的,所以用了我们的京东零售的OLAP来实监控京东云的一个整体效果,还有整体稳定性,这样产出比就非常大。
Q:主备库切换时数据有延迟吗,如何做到让用户感知最小?
A:主备库切换,我们采用的是双写的流程,我们核心的业务都是双写的,就算在日常也都是双写,然后分流去查询,不会造成主备储备的集群的空闲。大促的时候,会采用一个百分比,比如说或者100%在主机型另一个集群就是当做备用,或者是会按照一定的比例80%-20%左右采用双写。业务方切换的时候基本上没有任何延迟,只是将域名切换了一下,数据都是在实时写入,两个集群,基本上没有延迟。这是我们准备切换的一个功能。
Q:想问一下咱们的调优过程是怎么样的?
A:我们的调优过程先是结合自己的经验,去优化一些参数,业务再进行压测。因为想达到这么大的QPS和这么高的大吞吐的写入,要时常进行压测,压测时如果遇到问题,会进行内核源码的分析,然后再进行一系列参数调优或者内核优化。
本文首发于微信公众号“DataFunTalk”。