随着接触到的模型越来越大,自然就会接触到这种技术。
记录下自己的踩坑过程,当看到多机多卡跑通后,那种苦尽甘来的感觉还是挺舒服的。
我们首先来说一下单机多卡
huggingface上面有大佬上传了中文的BigBird的权重,想尝试能够处理的序列最长长度为4096的模型,但是放到单张卡里面batch_size基本上只能设置成2(16GB),所以为了让梯度下降更稳定,决定使用多卡进行训练。本来是想尝试把模型切成两半,分别放到两张卡里面,但是奈何自己没有能力把bigbird转换成nn.Sequential的样子的类型,所以就放弃了,转用DDP(Distributed Data Parallelism)。
(之后有关注了huggingface的Accelerate和另一个很有名气的Colossal-AI,但是都会有同样的bug)
我是参考这篇文章的:Distributed Training in PyTorch (Distributed Data Parallel) | by Praneet Bomma | Analytics Vidhya | Medium(良心文章,认真参考一次就跑通了)
现在来从头开始,跑通单机多卡。
导入依赖包1 from distutils.command.config import config 2 import os 3 import jieba_fast 4 import json 5 import pandas as pd 6 import re 7 import torch 8 import numpy as np 9 import torch.nn.functional as F 10 import torch.optim as optim 11 import torch.nn as nn 12 import torch.distributed as dist 13 import torch.multiprocessing as mp 14 15 from tqdm.auto import tqdm 16 from transformers import BigBirdModel, BertTokenizer 17 from torch.utils.data import Dataset,DataLoader 18 from matplotlib import pyplot as plt 19 from datasets import load_dataset, load_metric 20 from torch.utils.tensorboard import SummaryWriter编辑配置参数
1 class Config: 2 batch_size_train = 2 3 batch_size_valid = 1 4 5 max_length = 1500 6 seed = 4 7 device = torch.device("cuda:0") if torch.cuda.is_available() else 'cpu' 8 device1 = torch.device("cuda:1") if torch.cuda.is_available() else 'cpu' 9 # device = 'cpu' 10 bigbird_output_size = 768 11 vocab_size = 39999#+3 # len(tokenizer.get_vocab()) +3 是因为后面添加了特殊token 12 13 save_path = "model/BigBird_test3_v3_.bin" 14 15 epochs = 10 16 accumulate_setp = 10 17 18 gpus = 2 19 nr = 1 # global rank 第几台机器 20 nodes = 2 21 word_size = gpus*nodes
对于我来说,我不喜欢argument parser这种东西,所以我喜欢把配置参数放到一个类里面:
对于单机多卡,真正要配置的只有最下面4个:
gpus: 一台机器有多少张显卡
nr:number of rank 这里指的是global rank,也就是在多机多卡环境下,每台机器的编号,现在我们只有一台机器,就设置为0。(多机多卡必须要有一个主机器,所以单机多卡是多机多卡,多机只有一台机器的情况,主机器的global rank设置为0)
nodes:节点的个数(主机的台数)
world_size:整个环境里面,显卡的张数。
定义tokenizer和modelclass JiebaTokenizer(BertTokenizer): ... class BB(torch.nn.Module): ...自定义数据集
class DS(Dataset): ...**定义train函数**
主要关注一下注释部分,在自己的代码中添加需要添加的代码。
def train(gpu,config): rank = config.nr * config.gpus + gpu # train函数会运行到每个GPU上,所以需要显卡的ID 0~world_size-1 dist.init_process_group( backend='nccl', # 显卡的通信方式 init_method='env://', # 初始化方法,从命令行的环境里面读取需要的环境变量 world_size=config.word_size, rank=rank ) torch.manual_seed(config.seed) # 设置随机种子 tokenizer = JiebaTokenizer.from_pretrained('Lowin/chinese-bigbird-base-4096') model = BB() torch.cuda.set_device(gpu) # 选择使用的GPU model.cuda(gpu) # 把模型放到被使用的GPU上 optimizer = optim.AdamW(params=model.parameters(),lr=1e-5,weight_decay=1e-2) model = nn.parallel.DistributedDataParallel(model,device_ids=[gpu],find_unused_parameters=True) # 需要把模型再次包装成多GPU模型 trains = json.load(open("dataset/train.json")) dataSetTrain = DS(trains,tokenizer,config) train_sampler = torch.utils.data.distributed.DistributedSampler( dataSetTrain, num_replicas = config.word_size, rank = rank ) tDL = DataLoader(dataSetTrain,batch_size=config.batch_size_train,shuffle=False,pin_memory=True,sampler=train_sampler) step = 0 for epoch in range(config.epochs): if gpu == 0: # 第一张卡 (local rank) tDL = tqdm(tDL,leave=False) model.train() for batch in tDL: step += 1 labels = batch.pop('labels').cuda(non_blocking=True) # 把数据输入输出放到当前正在使用的显卡(编号为rank的那张显卡)里面,non_blocking=True表示数据异步加载到显卡里面 batch = {key:value.cuda(non_blocking=True) for key,value in batch.items()} logits = model(batch) loss_sum = F.cross_entropy(logits.view(-1,config.vocab_size),labels.view(-1),reduction='sum') # 下面三行是只计算标题的梯度(任务是标题生成),进行梯度累计,可以不需要 title_length = labels.ne(0).sum().item() loss = loss_sum/title_length loss = loss/config.accumulate_setp loss.backward() if gpu == 0: # tqdm常用技巧,只让GPU0上的模型的损失显示出来(其他显卡的模型的损失是一样的,为了不重复显示,所以设置只让0号GPU显示结果) tDL.set_description(f'Epoch{epoch}') tDL.set_postfix(loss=loss.item()) if step % config.accumulate_setp == 0: torch.nn.utils.clip_grad_norm_(model.parameters(), 2) # 梯度裁剪,把梯度归一化到01之间,让梯度下降更稳定。 optimizer.step() optimizer.zero_grad()定义main函数
#-----------------------------------------------------------------------下面的代码主要是保存模型和验证性能,可以不加--------------------------------------------------------------------------------------- if (epoch > 0) and (epoch % 2 == 0): torch.save(model.state_dict(), config.save_path+f'_epoch{epoch}') if ((gpu == 0) and (epoch % 2 == 0)) or epoch==(config.epochs-1): # 以下是评测验证集的代码 tDL.write('*'*120) tDL.write(f'Epoch{epoch},开始评测性能') allIndexes = [] allLabels = [] with torch.no_grad(): model.eval() vDL = tqdm(vDL,leave=False) for sample in vDL: label = sample.pop('labels').cuda(non_blocking=True) sample = {key:value.cuda(non_blocking=True) for key,value in sample.items()} logits = model(sample) logits = logits[0] assert len(logits.shape) == 2 index = logits.argmax(dim=1) index = index>0 # 获取token_id不为0的所有token 所在的输出向量的索引 index = logits[index].argmax(dim=1) label = label[label!=0] allIndexes.append(index) allLabels.append(label) result = rouge.compute(predictions=allIndexes,references=allLabels) tDL.write(f'rouge1:{result["rouge1"][1][1]}') tDL.write(f'rouge2:{result["rouge2"][1][1]}') tDL.write(f'rougeL:{result["rougeL"][1][1]}')if gpu == 0: # 保存最后一个epoch的模型 torch.save(model.state_dict(), config.save_path) writer.close()
def main(): config = Config() # 配置参数 os.environ['MASTER_ADDR'] = '10.100.132.151' # 主机器的IP,单机可以设置为localhost os.environ['MASTER_PORT'] = '12356' # 多机多卡时,不同机器和主机器之间的通信端口,用于传递张量。 mp.spawn(train,nprocs=config.gpus,args=(config,)) # 开启分布式训练 train: 上面定义的train函数,nproc:每一台机器有多少张显卡,args:配置参数 if __name__ == "__main__": main()
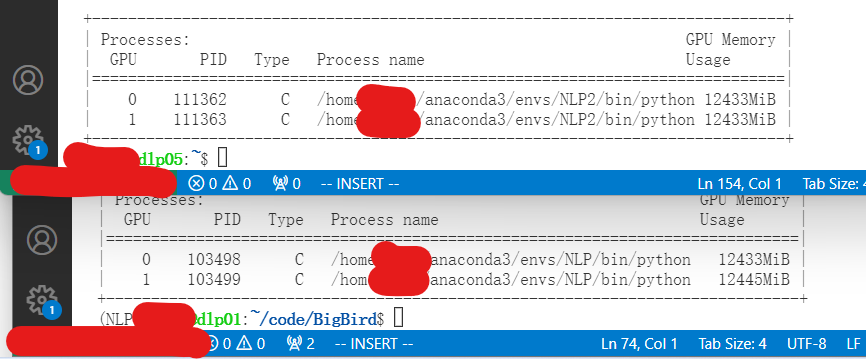
处理完成之后,就可以直接python xxx.py了,然后在终端输入nvidia-smi后,会发现两张卡都用起来了。
再来说一下多机多卡搞定单机多卡后,多机多卡就只需要修改几行代码,然后在不同的机器上分别启动就好了。
只需要修改配置参数,就可以实现多级多卡了:
class Config: ... nr = 0 # global rank 第几台机器,0表示主机器 nodes = 2 # 把这里修改为2,表示我有2台机器 word_size = gpus*nodes
然后再到另外一台机器上,也修改config参数:
class Config: ... nr = 1 # global rank 第二台机器,0表示第一台机器 nodes = 2 # 也把这里修改为2 word_size = gpus*nodes
然后分别在两台主机上使用python xxx.py,对比两台机器的tqdm出现的进度条,会发现进度会同时是一样的,然后就出现文章片头出现的结果了。