前言 本文介绍了NMS的应用场合、基本原理、多类别NMS方法和实践代码、NMS的缺陷和改进思路、介绍了改进NMS的几种常用方法、提供了其它不常用的方法的链接。
本文很早以前发过,有个读者评论说没有介绍多类别NMS让他不满意,因此特来补充。顺便补充了NMS的缺点和改进思路。
欢迎关注公众号
Non-Maximum Suppression(NMS)非极大值抑制。从字面意思理解,抑制那些非极大值的元素,保留极大值元素。其主要用于目标检测,目标跟踪,3D重建,数据挖掘等。
目前NMS常用的有标准NMS, Soft NMS, DIOU NMS等。后续出现了新的Softer NMS,Weighted NMS等改进版。
原始NMS以目标检测为例,目标检测推理过程中会产生很多检测框(A,B,C,D,E,F等),其中很多检测框都是检测同一个目标,但最终每个目标只需要一个检测框,NMS选择那个得分最高的检测框(假设是C),再将C与剩余框计算相应的IOU值,当IOU值超过所设定的阈值(普遍设置为0.5,目标检测中常设置为0.7,仅供参考),即对超过阈值的框进行抑制,抑制的做法是将检测框的得分设置为0,如此一轮过后,在剩下检测框中继续寻找得分最高的,再抑制与之IOU超过阈值的框,直到最后会保留几乎没有重叠的框。这样基本可以做到每个目标只剩下一个检测框。

原始NMS(左图1维,右图2维)算法伪代码如下:


实现代码:(以pytorch为例)
def NMS(boxes,scores, thresholds):
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
areas = (x2-x1)*(y2-y1)
_,order = scores.sort(0,descending=True)
keep = []
while order.numel() > 0:
i = order[0]
keep.append(i)
if order.numel() == 1:
break
xx1 = x1[order[1:]].clamp(min=x1[i])
yy1 = y1[order[1:]].clamp(min=y1[i])
xx2 = x2[order[1:]].clamp(max=x2[i])
yy2 = y2[order[1:]].clamp(max=y2[i])
w = (xx2-xx1).clamp(min=0)
h = (yy2-yy1).clamp(min=0)
inter = w*h
ovr = inter/(areas[i] + areas[order[1:]] - inter)
ids = (ovr<=thresholds).nonzero().squeeze()
if ids.numel() == 0:
break
order = order[ids+1]
return torch.LongTensor(keep)
除了自己实现以外,也可以直接使用torchvision.ops.nms来实现。
torchvision.ops.nms(boxes, scores, iou_threshold)
上面这种做法是把所有boxes放在一起做NMS,没有考虑类别。即某一类的boxes不应该因为它与另一类最大得分boxes的iou值超过阈值而被筛掉。
对于多类别NMS来说,它的思想比较简单:每个类别内部做NMS就可以了。
实现方法:把每个box的坐标添加一个偏移量,偏移量由类别索引来决定。
下面是torchvision.ops.batched_nms的实现源码以及使用方法
#实现源码
max_coordinate = boxes.max()
offsets = idxs.to(boxes) * (max_coordinate + torch.tensor(1).to(boxes))
boxes_for_nms = boxes + offsets[:, None]
keep = nms(boxes_for_nms, scores, iou_threshold)
return keep
#使用方法
torchvision.ops.boxes.batched_nms(boxes, scores, classes, nms_thresh)
这里偏移量用boxes中最大的那个作为偏移基准,然后每个类别索引乘以这个基准即得到每个类的box对应的偏移量。这样就把所有的boxes按类别分开了。
在YOLO_v5中,它自己写了个实现的代码。
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) 这里的max_wh相当于前面的boxes.max(),YOLO_v5中取的定值4096。这里的agnostic用来控制是否用于多类别NMS还是普通NMS。
NMS的缺点
1. 需要手动设置阈值,阈值的设置会直接影响重叠目标的检测,太大造成误检,太小达不到理想情况。
2. 低于阈值的直接设置score为0,做法太hard。
3. 只能在CPU上运行,成为影响速度的重要因素。
4. 通过IoU来评估,IoU的做法对目标框尺度和距离的影响不同。
NMS的改进思路
1. 根据手动设置阈值的缺陷,通过自适应的方法在目标系数时使用小阈值,目标稠密时使用大阈值。例如Adaptive NMS
2. 将低于阈值的直接置为0的做法太hard,通过将其根据IoU大小来进行惩罚衰减,则变得更加soft。例如Soft NMS,Softer NMS。
3. 只能在CPU上运行,速度太慢的改进思路有三个,一个是设计在GPU上的NMS,如CUDA NMS,一个是设计更快的NMS,如Fast NMS,最后一个是掀桌子,设计一个神经网络来实现NMS,如ConvNMS。
4. IoU的做法存在一定缺陷,改进思路是将目标尺度、距离引进IoU的考虑中。如DIoU。
下面稍微介绍一下这些方法中常用的一部分,另一部分仅提供链接。
Soft NMS
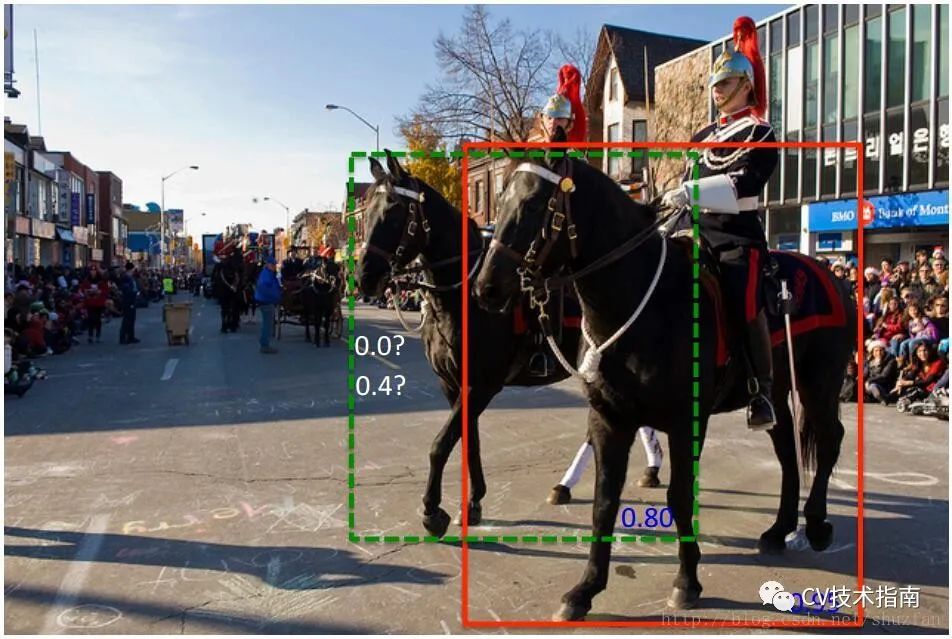
根据前面对目标检测中NMS的算法描述,易得出标准NMS容易出现的几个问题:当阈值过小时,如下图所示,绿色框容易被抑制;当过大时,容易造成误检,即抑制效果不明显。因此,出现升级版soft NMS。
Soft NMS算法伪代码如下:

标准的NMS的抑制函数如下:
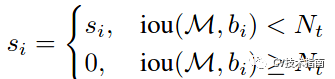
IOU超过阈值的检测框的得分直接设置为0,而soft NMS主张将其得分进行惩罚衰减,有两种衰减方式,第一种惩罚函数如下:
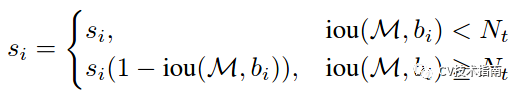
这种方式使用1-Iou与得分的乘积作为衰减后的值,但这种方式在略低于阈值和略高于阈值的部分,经过惩罚衰减函数后,很容易导致得分排序的顺序打乱,合理的惩罚函数应该是具有高iou的有高的惩罚,低iou的有低的惩罚,它们中间应该是逐渐过渡的。因此提出第二种高斯惩罚函数,具体如下:
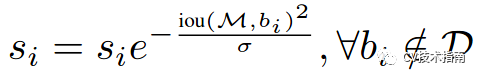
这样soft NMS可以避免阈值设置大小的问题。
Soft NMS还有后续改进版Softer-NMS,其主要解决的问题是:当所有候选框都不够精确时该如何选择,当得分高的候选框并不更精确,更精确的候选框得分并不是最高时怎么选择 。论文值得一看,本文不作更多的详解。
此外,针对这一阈值设置问题而提出的方式还有Weighted NMS和Adaptive NMS。
Weighted NMS主要是对坐标进行加权平均,实现函数如下:
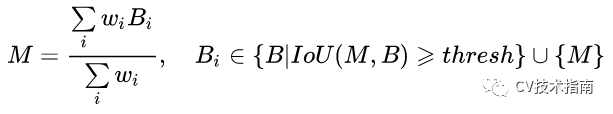
其中Wi = Si *IoU(M,Bi),表示得分与IoU的乘积。
Adaptive NMS在目标分布稀疏时使用小阈值,保证尽可能多地去除冗余框,在目标分布密集时采用大阈值,避免漏检。
Softer NMS论文链接:
https://arxiv.org/abs/1809.08545
Softer NMS论文代码:
https://github.com/yihui-he/softer-NMS
Weighted NMS论文链接:
https://ieeexplore.ieee.org/document/8026312/
Adaptive NMS论文链接:
https://arxiv.org/abs/1904.03629
DIoU NMS
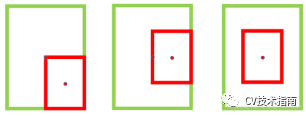
当IoU相同时,如上图所示,当相邻框的中心点越靠近当前最大得分框的中心点,则可认为其更有可能是冗余框。第一种相比于第三种更不太可能是冗余框。因此,研究者使用所提出的DIoU替代IoU作为NMS的评判准则,公式如下:
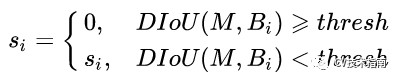
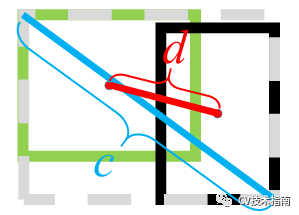
DIoU定义为DIoU=IoU-d²/c²,其中c和d的定义如下图所示
在DIoU实际应用中还引入了参数β,用于控制对距离的惩罚程度。
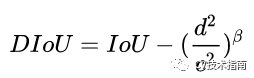
当 β趋向于无穷大时,DIoU退化为IoU,此时的DIoU-NMS与标准NMS效果相当。
当 β趋向于0时,此时几乎所有中心点与得分最大的框的中心点不重合的框都被保留了。
注:除了DIoU外,还有GIoU,CIoU,但这两个都没有用于NMS,而是用于坐标回归函数,DIoU虽然本身也是用于坐标回归,但有用于NMS的。
GIoU
GIoU的主要思想是引入将两个框的距离。寻找能完全包围两个框的最小框(计算它的面积Ac)。

计算公式如下:
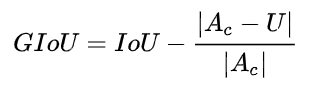
当两个框完全不相交时,没有抑制的必要。
当两个框存在一个大框完全包围一个小框时或大框与小框有些重合时,GIoU的大小在(-1,1)之间,不太好用来作为NMS的阈值。
GIoU的提出主要还是用于坐标回归的loss,个人感觉用于NMS不合适,CIoU也是如此,这里之所以提这个,是因为它与DIoU、CIoU一般都是放一起讲的。
其它相关NMS
为了避免阈值设置大小、目标太密集等问题,还有一些其他方法使用神经网络去实现NMS,但并不常用,这里只提一笔,感兴趣的读者请自行了解。如:
ConvNMS:A Convnet for Non-maximum Suppression
Pure NMS Network:Learning non-maximum suppression
Yes-Net: An effective Detector Based on Global Information
Fast NMS:
https://github.com/dbolya/yolact
Cluster NMS:
https://github.com/Zzh-tju/CIoU
Matrix NMS:
https://github.com/WXinlong/SOLO
Torchvision封装的免编译CUDA NMS
此处参考:
https://zhuanlan.zhihu.com/p/157900024
欢迎关注公众号
CV技术指南创建了一个免费的

![]()
征稿通知:欢迎可以写以下内容的朋友联系我(微信号:“FewDesire”)。
- TVM入门到实践的教程
- TensorRT入门到实践的教程
- MNN入门到实践的教程
- 数字图像处理与Opencv入门到实践的教程
- OpenVINO入门到实践的教程
- libtorch入门到实践的教程
- Oneflow入门到实践的教程
- Detectron入门到实践的教程
- CUDA入门到实践的教程
- caffe源码阅读
- pytorch源码阅读
- 深度学习从入门到精通(从卷积神经网络开始讲起)
- 最新顶会的解读。例如最近的CVPR2022论文。
- 各个方向的系统性综述、主要模型发展演变、各个模型的创新思路和优缺点、代码解析等。
- 若自己有想写的且这上面没提到的,可以跟我联系。
声明:有一定报酬,具体请联系详谈。若有想法写但觉得自己能力不够,也可以先联系本人(微信号:FewDesire)了解。添加前请先备注“投稿”。
其它文章