导读:京东智能商客之推荐卖点是基于NLP的产品,目前已广泛地助力和赋能于京东商城的各个平台。今天和大家分享一下自然语言处理如何在工业界落地实现。主要围绕以下5个方面展开:
- 推荐卖点技术背景
- 架构描述
- 核心AI技术
- 模型研发与实践
- 产品的落地与回报
--
01 推荐卖点技术背景1. 什么是推荐卖点,用推荐卖点能做什么事情?

如何提升推荐系统的可解释性?京东智能推荐卖点技术全解析
推荐卖点是一种商品文案,或者称之为对商品的描述。商品文案,即电商平台中在线利用文字来描述商品的特征、特色点、详细信息,以辅助商家吸引顾客、促进商品销售,丰富商品的推荐理由。
商品文案有多种类型,不同类型的商品文案有着不同的功能,主要包括长文案(商品标题和商品描述),短文案(卖点)。
商品标题是一种综合性描述信息的文字,在有限的字数内,信息完整且客观地阐述商品,例如描述商品的品牌、是什么物品、主要功能等。
商品描述类似于商品广告,可围绕某些特色点进行宣传,引导用户购买该商品。
商品卖点的目标是突出商品的特色,通常在8个字以内,用于丰富商品推荐理由。
传统的商品文案多是由人工撰写,费时费力,撰写速度也很难跟上新商品的迭代速度。随着自然语言处理飞速地迭代和发展,尤其是深度语言生成模型,通过商品文案自动化生成技术,可以帮助商铺的店家以又快又省的方式进行商品宣传。
2. 目前常用的文案生产技术
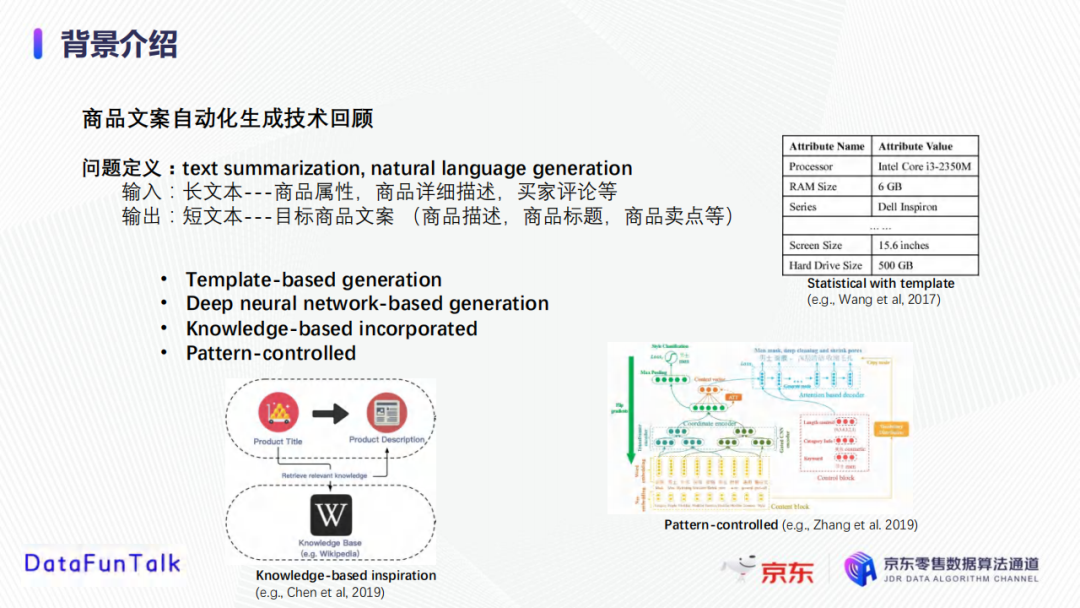
商品文案自动写作属于自然语言处理领域中text summarization或者natural language generation的问题。
输入是长文本形式,包括商品属性、商品详细描述、买家评论等,输出是目标商品文案,包括商品描述、商品标题、商品卖点等。
目前有以下几种文案生成模型的方法,如Template-based generation、Deep neural network-based generation、Knowledge-based incorporate、Pattern-controlled等。
- Template-based generation:一种较为传统的方式,需要预先定义某类别商品的属性,然后进行商品的属性值提取,最后基于提取的商品属性做文案生成;
- Deep neural network-based generation:随着深度学习的出现,开始使用深度生成模型做自然语言的生成,大多依靠的是典型的编码器和解码器结构,基于transformer等特征处理技术;
- Knowledge-based incorporate:引入知识图谱和知识库等技术使生成的文案信息链更全,即使输入的信息不够完整,也可进行知识整合;
- Pattern-controlled:该种方式能够控制生成文案的过程,比如可以控制生成的主题、重点、语言风格,以及文案长度等。
以上这几种方式主要针对长文本文案生成,目前还没有针对卖点短文案的生成技术。
3. 推荐卖点价值
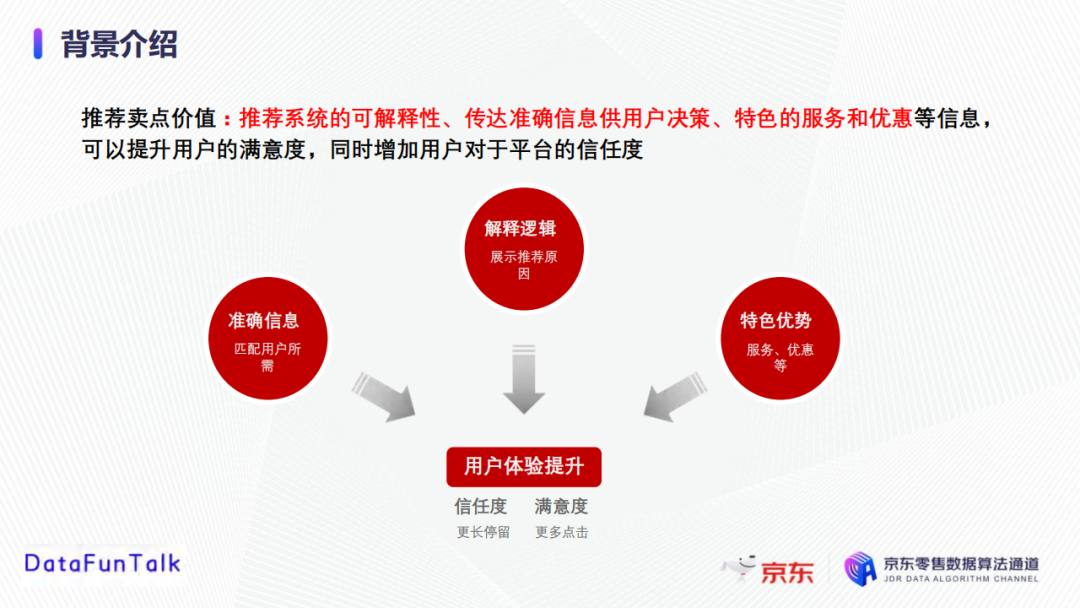
卖点文案生成的核心是服务于推荐系统,可增加推荐系统的可解释性,向用户展示推荐理由;结合用户喜好进行个性化推荐,从而传达准确信息供用户决策;向用户展示特色优势如服务和优惠等信息,可以提升用户的满意度,促进点击行为,同时增加用户对平台的信任度以及延长停留时间。
4. 卖点短文案自动生成技术

通过卖点自动化生成技术,避免人工文案写作,节约了时间成本;同时,卖点短文案不需要复杂的文学表达,比较适合采用自动化文案生成的方式。为了生成高质量的卖点文案,需要做到以下几点:
- 能够捕捉到内容的特色点,足够吸睛;
- 文案长度有限,需要简短精巧,但包含重要信息;
- 能够实现个性化分发,针对不同的目标用户展示不同的推荐理由。
--
02 架构描述接下来通过介绍推荐卖点在推荐系统中的架构设计来介绍卖点如何与推荐系统结合发挥作用。
首先是当请求被初始化时,混合模块(SOA)会触发前端(Broadway)收集用户信息、商品信息等数据;基于收集到的客户资料,Index模块作为Broadway和后端推荐的中转站,将信息提供给推荐模块;AI-flow是推荐模块,执行召回和排序,以获取推荐候选产品,根据产品的库存和受欢迎程度进行筛选,最后确定要推荐的产品同时将请求发送给卖点模块,进行卖点的提取和个性化分发。
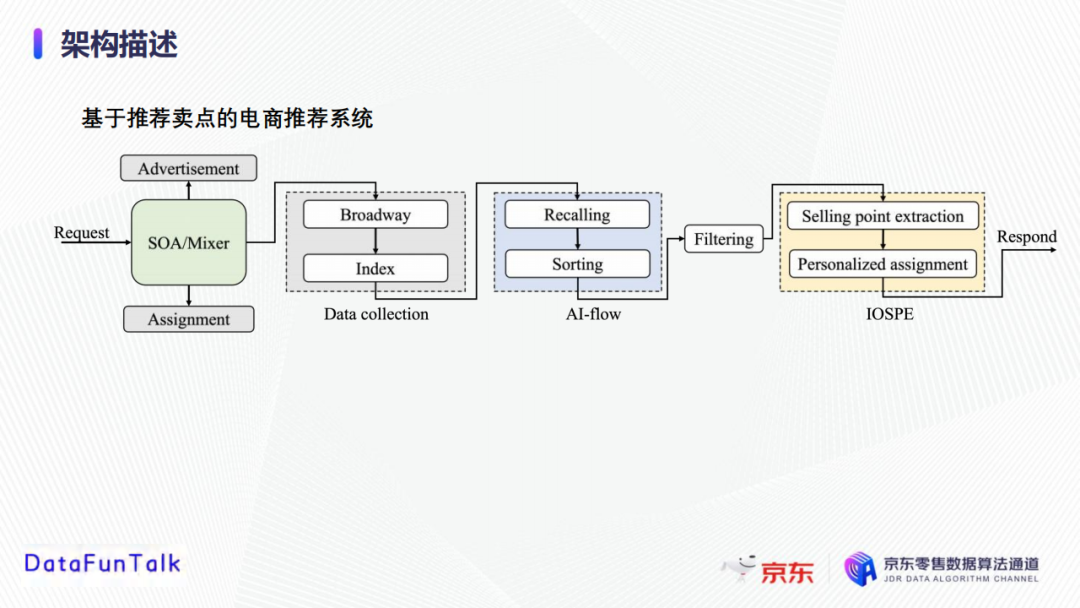
- SOA/Mixer:协调广告、推荐和分配应用的混合模块/平台。所有请求最初都发送到这个混合模块,然后分配给每个应用程序。
- Broadway:推荐系统的前端。收集客户的资料信息和购买历史,以及产品信息(包括属性、评论、描述、和图像等),这些数据被发送到索引模块。
- Index:作为broadway和后端推荐部分的中转站。Index准备好来自broadway的输入数据并转发给推荐模块,并从AI-flow和filtering模块接收推荐产品及卖点。
- AI-flow(召回):推荐模块中负责召回特征的关键组件。这里用到的特征都是离线提取出来的,召回是AI-flow的第一步,它根据用户和产品特征从海量库存中检索出少量可能感兴趣的物品,然后将他们传递给排序模块。
- AI-flow(排序):这里我们采用非线性和线性的排序方法。GBDT用于非线性排序,可以更好地从特征中捕捉非线性模式,逻辑回归用于线性特征排序;为了更好地捕捉动态数据分布,我们实施一种基于FTRL(McMahan2011)的在线学习策略来处理在线数据流。
- Intelligent Online Product Selling Point Extraction (IOPSE) :用于产生卖点以支持产品推荐。具体来说,给定一个推荐商品,从卖点池中提取几个优质的卖点,然后根据目标客户的个人资料,通过个性化分配算法选择最适合的卖点,然后将客户ID、产品推荐和卖点发送回前端进行展示。
--
03 核心AI技术1. 智能卖点创作的技术流程
整个智能卖点创作模块分为两个部分:
卖点短文案的提取和生成,采用基于商品详情和用户评论的文本生成技术;
个性化卖点分发,采用基于用户画像的用户个性化卖点分发技术。
以石榴这个商品为例,首先获取卖点素材,比如石榴的属性表,商品标题,以及采用OCR文字识别技术从商品详情图片中提取的文字,买家的正向评论等;然后将获取的卖点素材输入到卖点提取和生产模块中,生成针对一个商品的多个优质卖点;在个性化分配模块中,结合客户兴趣给不同的用户进行不同的推荐卖点展示。
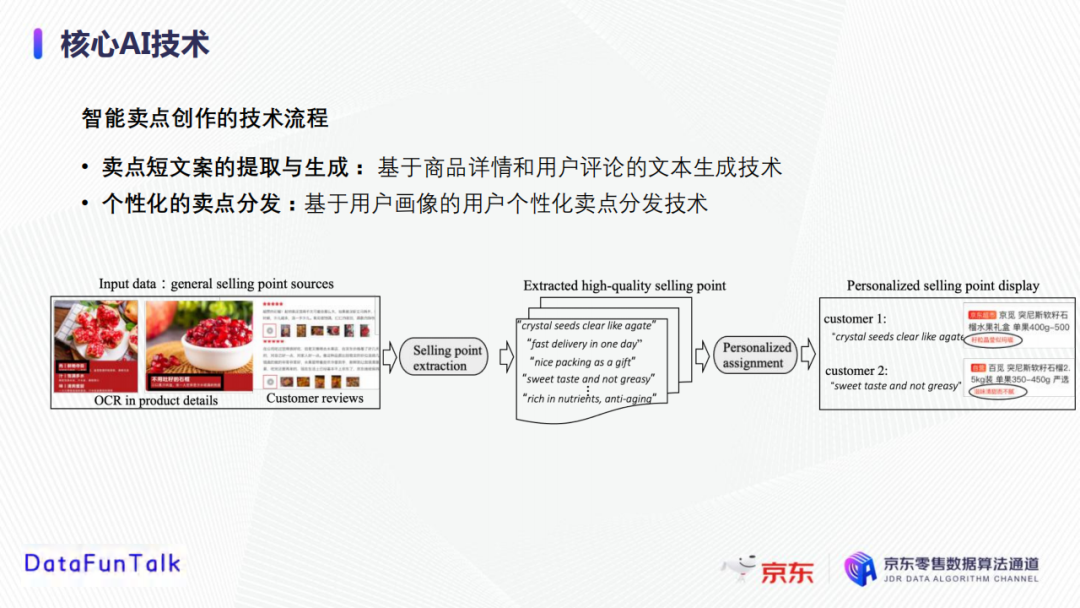
2. 卖点短文案的提取和生成
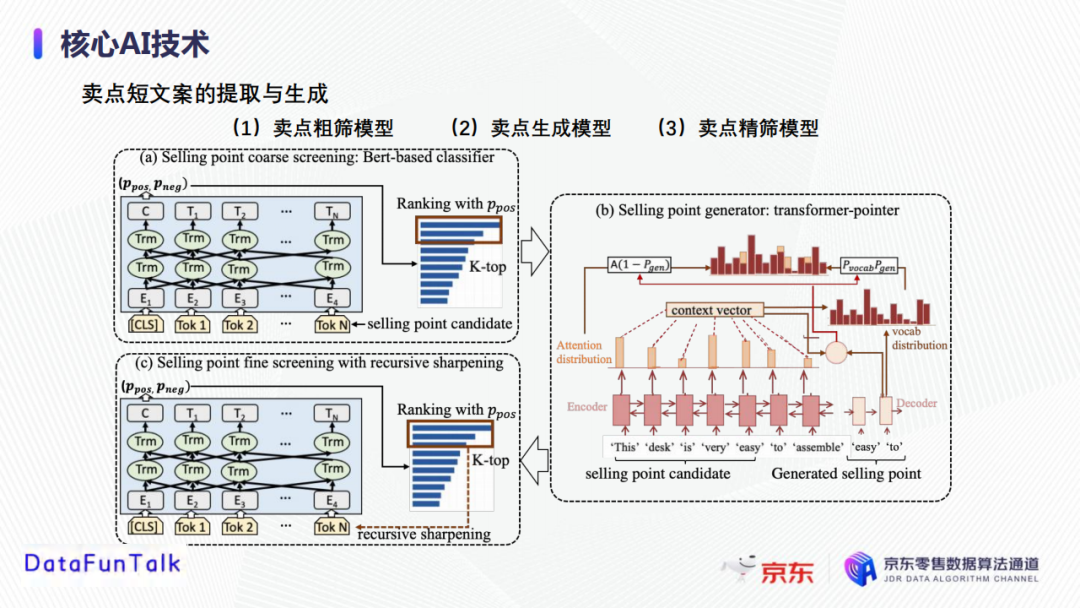
卖点短文案的提取和生成,主要包括卖点粗筛、卖点生成、卖点精筛这三个步骤。
① 卖点粗筛
目标是从商品文案素材库里(商详页OCR,用户评论,达人文案等)提取初始卖点候选,主要基于self-adversarialBERT对文案素材(句子或者短语)进行打分,然后根据打分排序并选择top-K作为卖点生成素材,大范围地过滤掉与商品无实质性意义的短语或者句子。
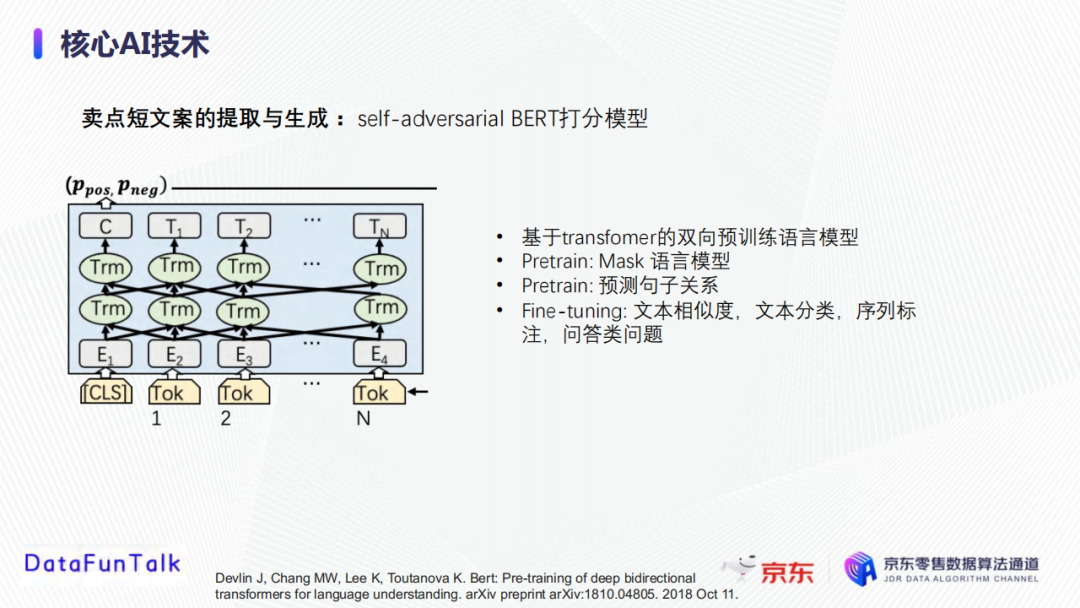
在素材文案评分中,将人工写作的卖点(达人文案)定义为正样本,将用户评论或者商详页OCR等作为负样本,使用自对抗的BERT模型做分类训练。在实践的过程中,当句子输入模型之后,获取Bert模型的softmax层输出概率,表示该句子被分到高质量的概率,根据句子的概率进行排序。这里简单介绍一下Bert模型。它是基于Transformer的双向预训练语言模型,在预训练阶段有Mask语言模型和预测句子关系两个任务,在此基础上进行finetune从而完成文本相似度计算、文本分类、序列标注、问答类问题等。文本输入表征包括了语义表征、segment表征(分割信息表征)、位置表征;最后将softmax层输出作为该文案的质量评分:
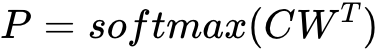

② 卖点生成
由于粗筛中选出的文案素材口语化、不简练,因此我们接下来依据Transformer和Pointer generator的文本生成模型基于已经筛选出的文案素材库进行卖点文案生成。
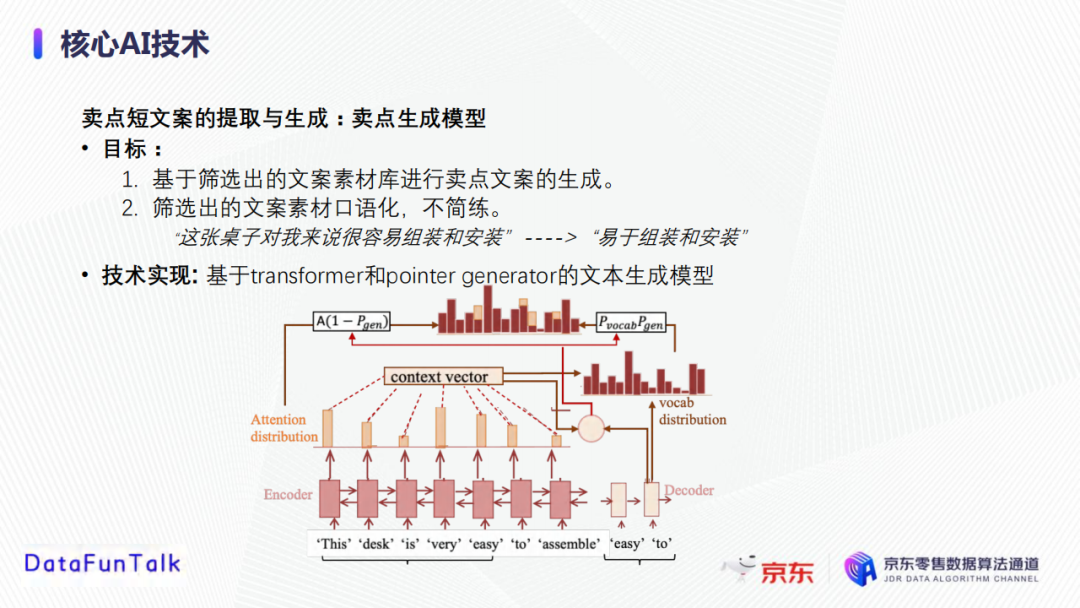
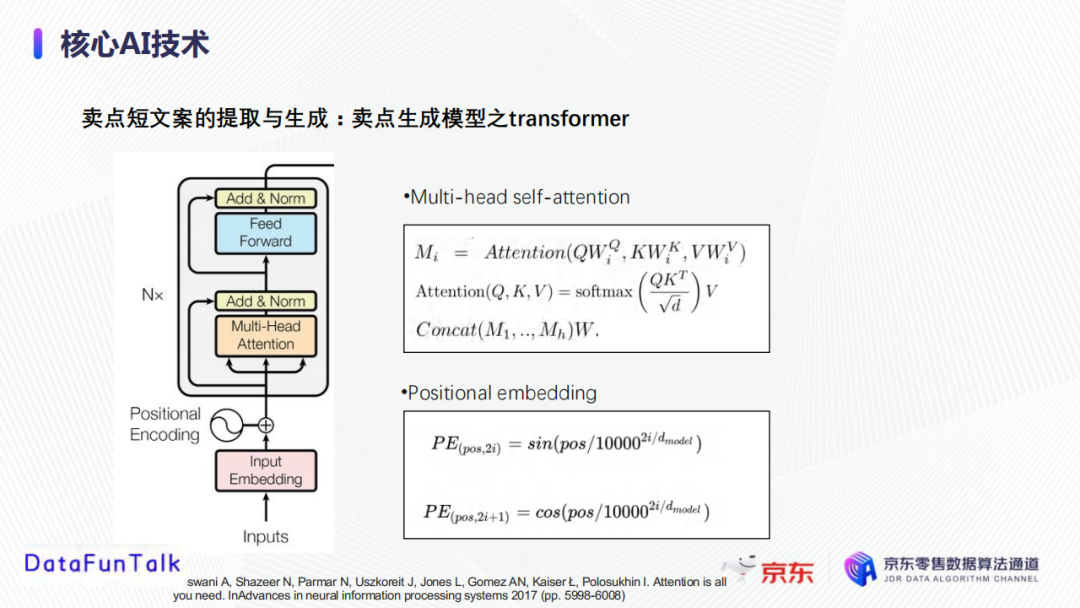
Transformer是用于学习输入文本的表征向量,它的重要组成部分包括自注意力机制(multi-head self-attention)和位置编码(positional embedding)。自注意力机制本质上会对句子中的每个字构建全连接的图,通过计算attention学习每个字的表征向量,考虑到句子中所有的字对该字的影响。位置表征中,每一个位置点都有一个编码,是一个周期函数。
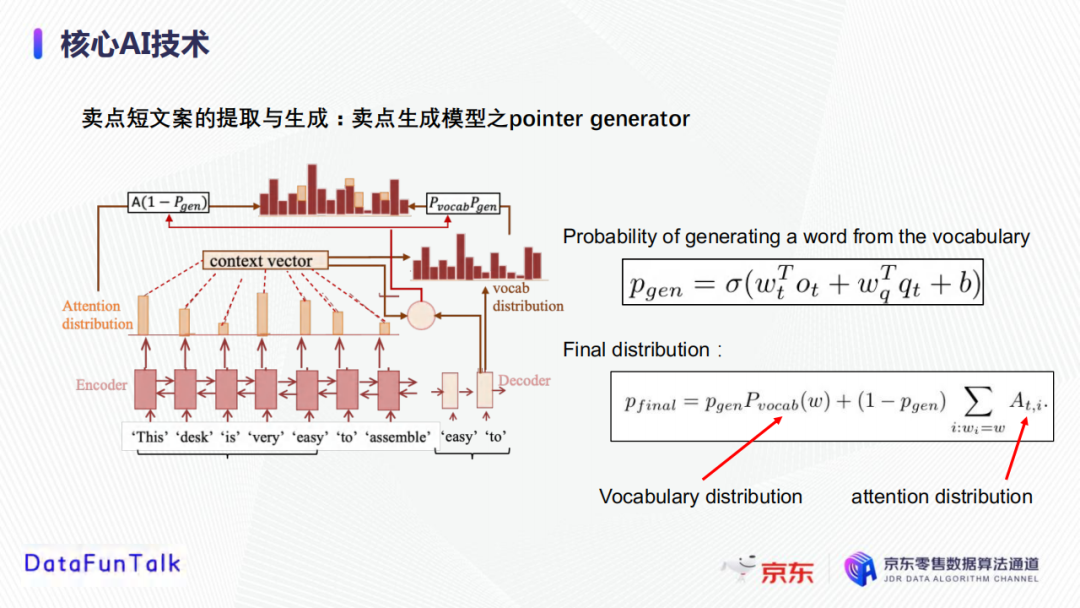
将上一步获取到表征进行Decoder生成卖点文案。Pointer generator与其他的语言生产模型的区别在于,其不仅可以从词库挑选要学习到的字,还可以从输入的句子中挑选字。首先分别计算从词库中选择字和从输入中选择字的概率,然后再将词库中的概率分布和输入中的概率分布结合获得最终的概率分布。
③卖点精筛
卖点精筛模型区别于粗筛模型,将生成后的卖点文案,输入到一种递归锐化的BERT模型中进行训练。具体来说,首先将达人卖点写作当做正样本,素材库文案/初始模型生成文案当做负样本,输入到Bert初始分类模型中进行训练;然后将前一步生成的排名靠前的高质量文案作为负样本,达人卖点文案作为正样本,再次输入到Bert模型中做优化训练,循环多次获得最终的高质量卖点文案。

3. 个性化分发
接下来,我们介绍基于用户画像的个性化分发。每一个产品有不同的特色点,可以产生多个高质量的卖点,我们希望根据客户的兴趣点为其分配最有吸引力的卖点,以引导用户购买该商品。个性化分发分为两个步骤,首先生成卖点文案的表征向量和用户兴趣的表征向量,然后匹配卖点表征向量和用户表征向量,从而实现卖点个性化分发。
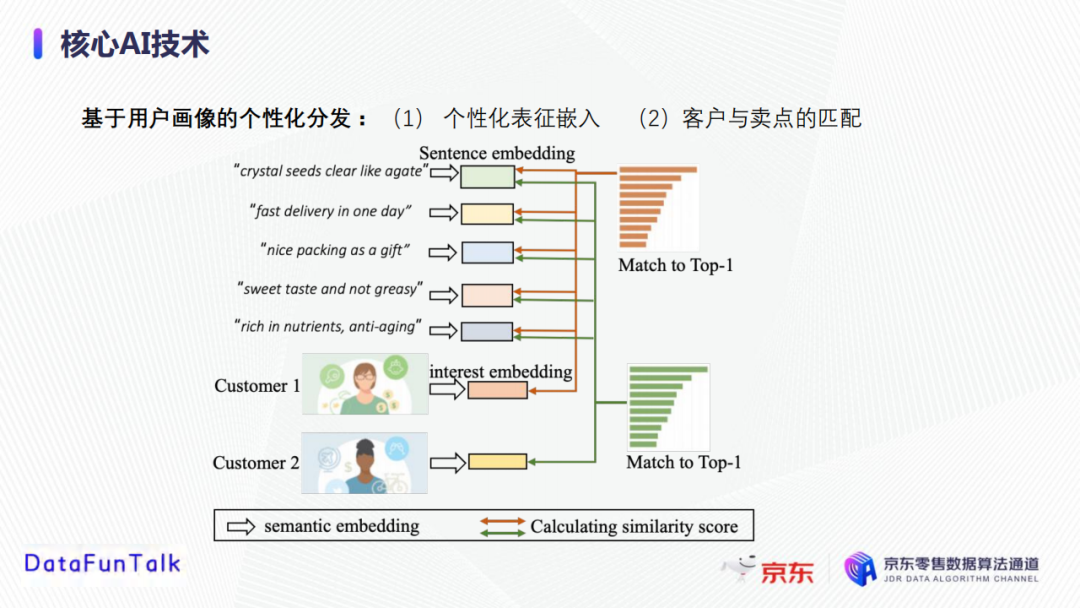
用户兴趣嵌入表征:通过work2vector方式获得产品词里每个字的word embedding,将产品词中每个字的表征向量求和获取该产品词的表征,结合用户对每个产品词的喜好权重,然后对所有的产品词进行加权平均,获取用户对产品词的喜好的表征向量。
卖点文案的特征向量:通过work2vector方式获得卖点文案里每个字的word embedding,然后对卖点文案中每个字的表征向量求和得到卖点文案特征向量。

个性化分发:通过计算用户兴趣表征向量和卖点文案表征向量的相似度来实现。可用的向量相似度计算的主要方法有余弦相似度、皮尔森系数、欧式距离和基于Kernel的相似度计算等。

--
04 模型研发与实践1. 文案输出素材选择
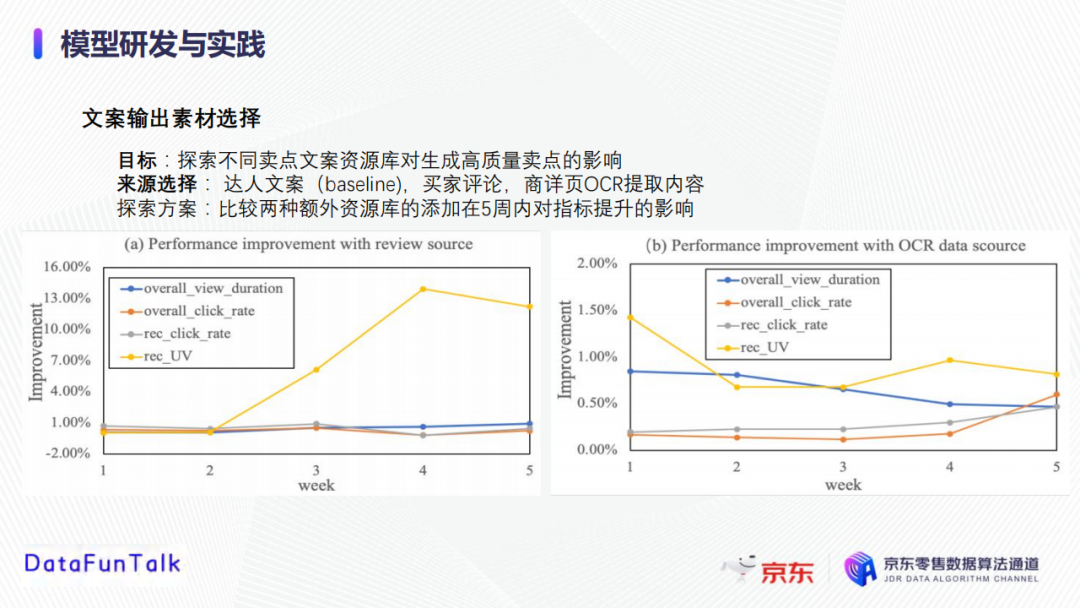
在模型开发的过程中,首先需要探索不同的卖点文案资源库对生成高质量卖点的影响。候选的卖点素材库除了基本的商品描述外,还有买家评论和商详页OCR提取文字。为了探索这两种素材来源的优劣,我们对比了这两种文案(买家评论、商详页OCR提取内容)在5周内对指标提升的影响。从下图中可以观察到,买家评论和商详页OCR提取内容均可以提高与销售相关的性能指标。特别地,买家评论素材源可将UV提升7%左右,原因可能是其他用户的评论更能激发用户的兴趣,即所谓的买家更了解买家;此外,商详页OCR素材源可能会带来1%左右的提升;这些数据告诉我们可以将这两个素材库作为初始素材库。
2. 在线卖点文案质量监管
在实践过程中,我们希望能够实时地检测和过滤历史数据中对购买行为产生负面影响的低质量卖点或者对购买行为产生促进作用的高质量卖点。由于人工很难综合评估卖点是否对客户有吸引力,所以我们希望通过业务端的反馈作为指标来帮助我们去识别高质量卖点或低质量卖点,在此基础上,可以过滤掉低质量卖点,同时通过实际生产过程中的高质量卖点来重新优化模型。对于在线监控模块,我们需要通过与业务相关的指标(曝光率、点击价值、客户停留时间等)计算相对提升指标。

3. 离线卖点文案模型优化
对于离线优化模块,我们发现经过业务反馈过滤出的低质量卖点和高品质卖点可以使模型对高质量卖点文案选择更加敏感,起到优化模型的作用。在实践过程中,我们将相对提升指标大于30%并且基础点击PV > 5%的短文案作为高质量正样本,剩余文案作为负样本,然后输入到BERT模型中进行finetune,重新打分排序获取高质量文案;同时我们将基础点击PV大于对比点击PV或者对比点击PV小于某个阈值的短文案作为低品质负样本,剩余文案作为正样本,然后输入到BERT模型中进行finetune, 从而打分排序同时过滤低评分的卖点文案。

--
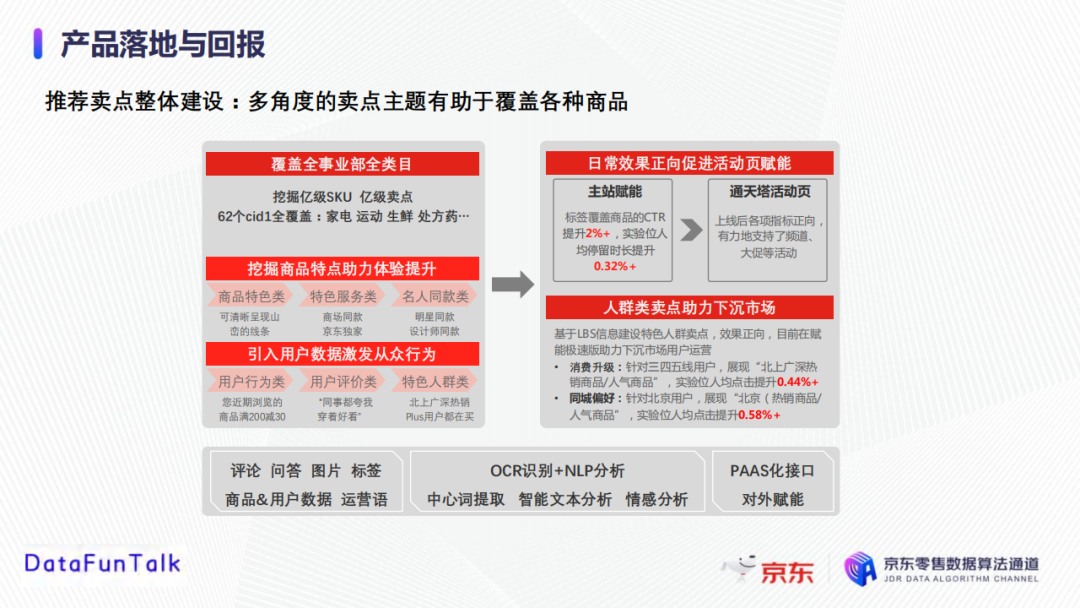
05 产品落地与回报当目前为止,我们已经完成了亿级别的卖点挖掘和生产,覆盖了上亿的SKU,62个品类(包括家电、运动、生鲜、处方药等);同时,生成的卖点是多样化的,包括商品特色类、特色服务类、名人同款类、用户行为类、用户评价类、特色人群类,旨在能够挖掘商品特点以助力体验提升或者引入用户数据激发从众行为;另一方面,从销售指标上看,卖点技术可以有效帮助提升商品点击率(+2%)和停留时长(0.32%+),日常效果正向促进活动页赋能;基于LBS信息建设特色人群卖点(消费升级或者同城偏好),效果正向,目前在赋能极速版助力下沉市场用户运营。此外,推荐卖点也广泛地赋能于主站、京喜、极速版、通天塔活动页等多个应用场景。