前段时间,客户反馈,有个PC端的功能页面,一点开就卡死,通过查看网络请求,发现有个部门组织架构树的请求数据有点大,共有两万条数据,1.57M。刚开始我以为是表单中的部门选择框渲染的时候,一次性渲染的dom节点过多,把页面内存撑爆了。于是我把项目中使用的antd3的TreeSelect组件,升级到具有无限滚动加载功能的antd5版本,始终只渲染10条数据,按理说页面卡死的问题应该就消失了。结果页面操作几次之后,页面仍旧百分之百会崩掉, 页面卡死问题并未彻底解决。
于是我沉下心来,把出问题的页面的逻辑从头到尾看了一遍,发现有一处采用递归方式查找某个部门id在不在部门树之中的逻辑,可能存在性能问题。没优化之前的写法是这样的:
const findTreeItem = (data, id) => {
for (let i = 0,len=data.length; i < len; i++) {
let item = data[i];
if (item.id === id) {
return true;
} else {
if (item.children) {
if (findTreeItem(item.children, id)) {
return true;
}
}
}
}
};
const isInclude = findTreeItem(treeData,deptId);
这种写法的缺点是,当树的层级很深时,可能会引起暴栈。让我们分析一下这种递归算法的空间复杂度。假设要判断id="1-1-1-0"是否存在于treeData中
const treeData = [
{
id: "1",
children: [
{
id: "1-0",
children: [
{
id: "1-0-0",
children: [
{
id: "1-0-0-0",
},
{
id: "1-0-0-1",
},
{
id: "1-0-0-2",
},
{
id: "1-0-0-3",
},
],
},
{
id: "1-0-1",
},
{
id: "1-0-2",
},
],
},
{ id: "1-1" },
],
},
];
我们想知道,在递归调用的过程中,最大的内存占用量。那就要对递归调用进行拆解,每一次递归函数调用自己,会占用多少内存空间,从方法 findTreeItem(treeData,'1-1-1-0') 调用方法 findTreeItem(treeData[0].children,'1-1-1-0') 时,将创建findTreeItem(treeData[0].children,'1-1-1-0') 相对应的堆栈帧。该堆栈帧将保留在内存中,直到函数对findTreeItem(treeData[0].children,'1-1-1-0') 的调用终止。该堆栈帧负责保存函数findTreeItem(treeData[0].children,'1-1-1-0') 的参数,函数findTreeItem(treeData[0].children,'1-1-1-0') 中的局部变量以及调用方函数findTreeItem(treeData,'1-1-1-0')的返回地址。接着,当此函数 findTreeItem(treeData[0].children,'1-1-1-0') 调用函数 findTreeItem(treeData[0].children[0].children,'1-1-1-0') 时,也会生成findTreeItem(treeData[0].children[0].children,'1-1-1-0') 相对应的堆栈帧,并将其保留在内存中,直到对findTreeItem(treeData[0].children[0].children,'1-1-1-0') 的调用终止。调用 findTreeItem(treeData[0].children[0].children,'1-1-1-0') 时,堆栈框架的调用堆栈如下所示:
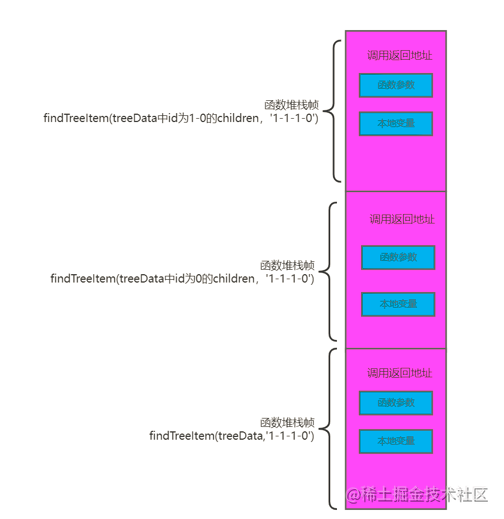
当调用到 findTreeItem(treeData[0].children[0].children[0].children,'1-1-1-0') ,执行完毕,返回对函数 findTreeItem(treeData[0].children[0].children,'1-1-1-0') 的调用时,由于不再需要findTreeItem(treeData[0].children[0].children,'1-1-1-0') 相对应的堆栈帧,js引擎将从内存中删除该堆栈帧。函数 findTreeItem(treeData[0].children,'1-1-1-0')和函数 findTreeItem(treeData,'1-1-1-0') 的堆栈帧也是如此。
通过分析可以看出递归算法的空间复杂度与所生成的最大递归树的深度成正比。如果递归算法的每个函数调用都占用 O(m) 空间,并且递归树的最大深度为 n,则递归算法的空间复杂度将为 O(n·m)。
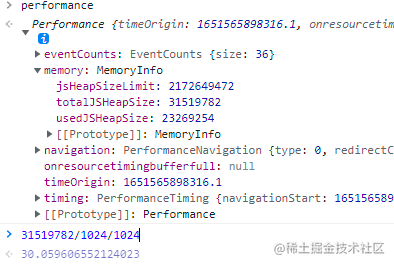
从performance属性可以知道,一个页面可以使用的内存量级是30M左右,假如2万多条数据占用1.5M左右内存空间,最理想的情况下,能支撑的递归深度也就20级左右,实际上要减去存储代码占用的空间,存储基本类型数据和引用类型引用地址,存储引用类型占用的空间,三下五除二,留给递归方法使用的空间就所剩无几了。无怪乎会造成页面卡死。
于是对上面的查找方法进行了一番优化,增加一个不断释放内存空间的步骤,页面出现卡死的问题彻底解决。
findTreeItem(tree, curKey, keyField, childField, node = null) {
const stack = [];
for (const item of tree) {
if (item) {
stack.push(item);
while (stack.length) {
// 重点是这里--边查找边释放内存空间
const temp = stack.pop();
if (temp[keyField] === curKey) {
node = temp;
break;
}
const children = temp[childField] || [];
for (let i = children.length - 1; i >= 0; i--) {
stack.push(children[i]);
}
}
}
}
return node;
}
当数据量比较小的时候,好的算法与差的算法,没有致命的差别。当数据量比较大的时候,算法的优劣,有天壤之别。所以平日在写数据处理逻辑的时候,要对数据处理的算法,保持一定的敏感度。之前对好的算法的优势,仅仅停留在概念和理论上,实际感受不太深切。就好比读了好多书,却依然过不好这一生。以为对书中的道理,看过一遍,知道了就等于懂了。实际上真正要用到的时候,大概率想不起来。因为没有特别深刻的感性认知。这次遭遇到生产问题的毒打之后,让我感受到了好的算法与坏的算法,质的差别,算法还是要重视起来。