论文地址:https://arxiv.org/abs/1512.02325
源码地址:http://github.com/amdegroot/ssd.pytorch
环境1:torch1.9.0+CPU
环境2:torch1.8.1+cu102、torchvision0.9.1+cu102
1. StopIteration。Batch_size设置32,训练至60次报错,训练中断;Batch_size改成8训练至240次报错。
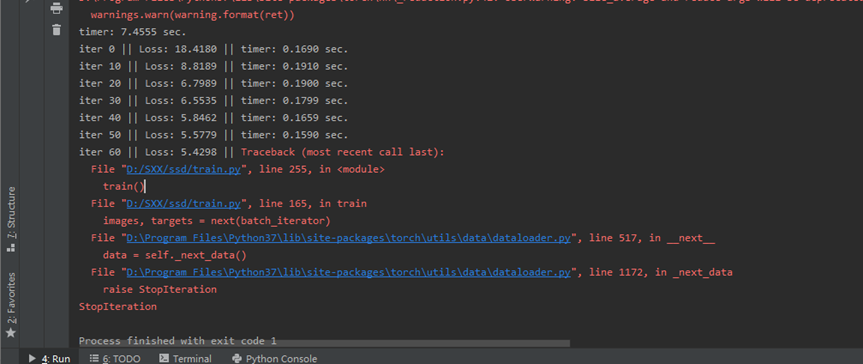
报错原因及解决方法:train.py第165行:
# 修改之前
images, targets = next(batch_iterator)
# 修改之后
try:
images, targets = next(batch_iterator)
except:
batch_iterator = iter(data_loader)
images, targets = next(batch_iterator)
2. UserWarning: volatile was removed and now has no effect. Use 'with torch.no_grad():' instead.
报错原因及解决方法:Pytorch版本问题,ssd.py第34行:
# 修改之前
self.priors = Variable(self.priorbox.forward(), volatile=True)
# 修改之后
with torch.no_grad():
self.priors = torch.autograd.Variable(self.priorbox.forward())
3. UserWarning: nn.init.xavier_uniform is now deprecated in favor of nn.init.xavier_uniform_.

报错原因及解决方法:nn.init.xavier_uniform是以前版本,改成nn.init.xavier_uniform_即可
4. VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
![]()
报错原因及解决方法:版本问题,augmentation.py第238行mode = random.choice(self.sample_options)报错,改为mode = np.array(self.sample_options, dtype=object),但并没卵用。。。由于是Warning,懒得再管了
5. AssertionError: Must define a window to update

报错原因及解决方法:打开vidsom窗口更新时报错(train.py 153行)
# 报错代码(153行) update_vis_plot(epoch, loc_loss, conf_loss, epoch_plot, None, 'append', epoch_size)
将将158行epoch+=1放在报错代码之前即可解决问题
6. KeyError: "filename 'storages' not found"。运行验证脚本eval.py和测试脚本test.py报的错
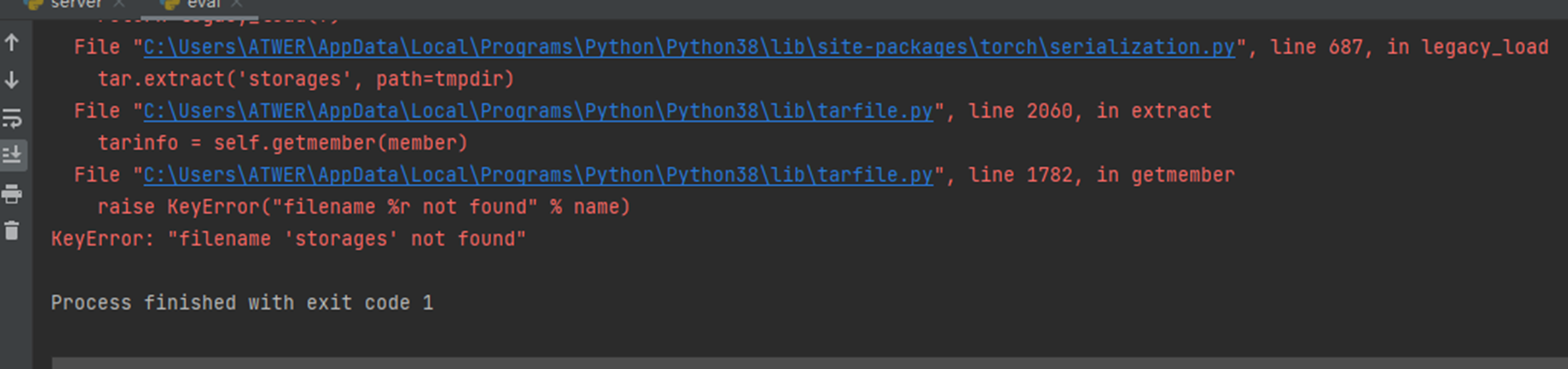
报错原因及解决方法:加载的.pth模型文件损坏
7. UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
![]()
报错原因及解决方法:版本问题,新版本损失函数的参数中,size_average和reduce已经被弃用,设置reduction即可。_reduction.py第90行修改如下:
# 修改之前(90行) loss_l = F.smooth_ll_loss(loc_p, loc_t, size_average=False)
# 修改之后 loss_l = F.smooth_ll_loss(loc_p, loc_t, reduction=’sum’)
8. RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU.

报错原因及解决方法:eval.py第425行,如果在cpu上运行则需要指定cpu模式
# 修改之前 net.load_state_dict(torch.load(args.trained_model)) # 修改之后 net.load_state_dict(torch.load(args.trained_model, map_location='cpu'))
9. RuntimeError: Legacy autograd function with non-static forward method is deprecated. Please use new-style autograd function with static forward method.
出现在eval.py和train.py ★★★★★★

(Example: https://pytorch.org/docs/stable/autograd.html#torch.autograd.Function)
报错原因:在pytorch1.3及以后的版本需要规定forward方法为静态方法,所以在pytorch1.3以上的版本执行出错。
官方建议:在自定义的autorgrad.Function中的forward,backward前加上@staticmethod
解决方法:
方法一:pytorch回退版本至1.3以前
方法二:根据官方建议,在ssd.py中forward前加@staticmethod,结果报出另一个错误

紧接着,将eval.py第385行 detections = net(x).data 改为 detections = net.apply(x).data,执行时又报如下错误

再然后,在ssd.py第100行加forward(或apply)
output=self.detect.forward(loc.view(loc.size(0), -1, 4),
self.softmax(conf.view(conf.size(0), -1, self.num_classes)),
self.priors.type(type(x.data)))
还是报和上边同样的错误,直接弃疗。。。
在该项目issues里看到:
It has a class named 'Detect' which is inheriting torch.autograd.Function but it implements the forward method in an old deprecated way, so you need to restructure it i.e. you need to define the forward method with @staticmethod decorator and use .apply to call it from your SSD class.
Also, as you are going to use decorator, you need to ensure that the forward method doesn't use any Detect class constructor variables.
也就是在forward定义前边加@statemethod,然后调用的时候用.apply。staticmethod意味着Function不再能使用类内的方法和属性,去掉init()用别的方法代替
最终解决方案(方法三):
detection.py改为如下,即将init()并入到forward函数中:
def forward(self, num_classes, bkg_label, top_k, conf_thresh,
nms_thresh, loc_data, conf_data, prior_data)
然后在ssd.py中调用的时候改为:
# 修改之前(46行)
# if phase == 'test':
# self.softmax = nn.Softmax(dim=-1)
# self.detect = Detect(num_classes, 0, 200, 0.01, 0.45)
# 修改之后
if phase == 'test':
self.softmax = nn.Softmax()
self.detect = Detect()
# 修改之前(99行)
# if self.phase == "test":
# output = self.detect(
# loc.view(loc.size(0), -1, 4), # loc preds
# self.softmax(conf.view(conf.size(0), -1,
# self.num_classes)), # conf preds
# self.priors.type(type(x.data)) # default boxes
# )
# 修改之后
if self.phase == "test":
output = self.detect.apply(2, 0, 200, 0.01, 0.45,
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(-1, 2)), # conf preds
self.priors.type(type(x.data)) # default boxes
)
注意:方式三中,ssd.py的Forward方法前边不能加@staticmethod,否则会报和方法二中相同的错。detection.py的Forward方法前加不加@staticmethod都没影响。
10. cv2.error: OpenCV(4.5.5) :-1: error: (-5:Bad argument) in function 'rectangle'
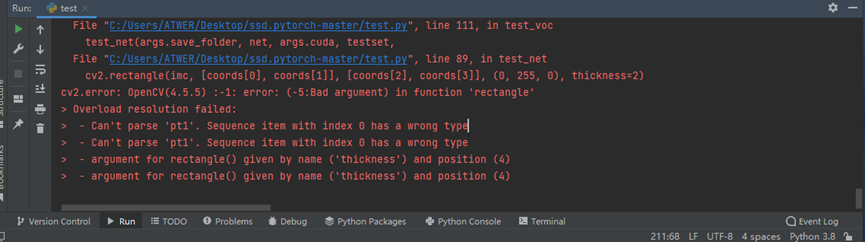
报错原因及解决方法:opencv版本过高,不兼容,改装4.1.2.30问题解决
总结:遇到报错别急着求助,一定要仔细阅读报错信息,先自己分析下为什么报错,一般对代码比较熟悉的话都是能找到原因的。实在解决不了再百度或Google,另外可以多多参考源码的Issues。
参考资料:
1、https://blog.csdn.net/qq_39506912/article/details/116926504(主要参考这篇博客)
2、http://github.com/amdegroot/ssd.pytorch/issues/234