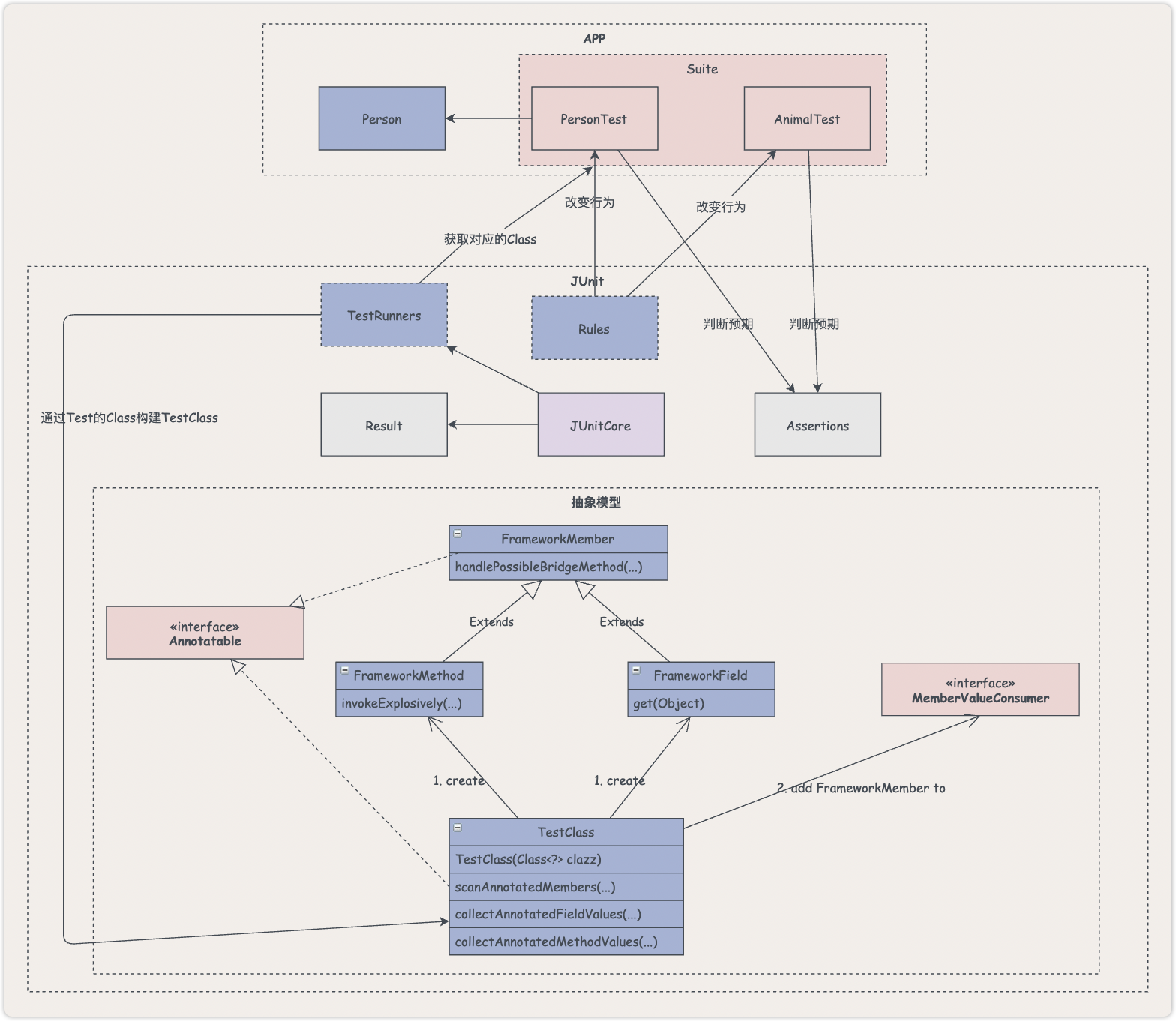
上一篇我们将梳理的核心流程整合进了概念模型,得到了一个相对详细的流程。
本篇是《如何高效阅读源码》专题的第十篇,我们来通过阅读源码来验证上面得到的流程图是否正确,同时进一步细化,从核心流程向外围流程进行梳理,构建一个更完整的流程。
本节主要内容:
-
从调用关系确定调用类
-
梳理调用类结构
-
梳理调用类核心流程
-
完善流程图
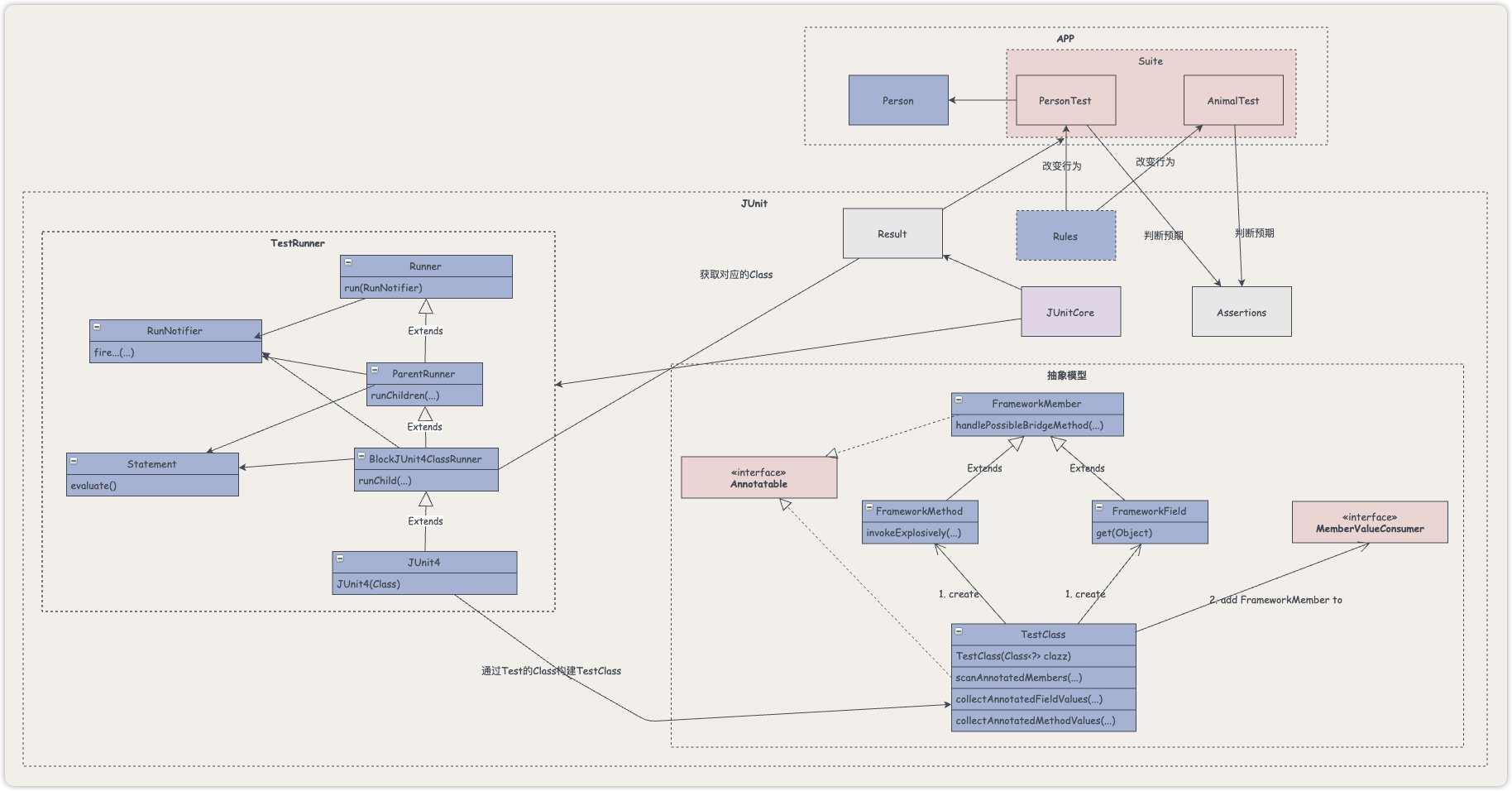
前文我们得到了下面这张图:
我们猜测TestRunners会通过测试的Class来构建TestClass,现在我们通过源码来验证这个猜测。
我们在TestClass的构造方法上按下ALT+F7,IDEA就会列出调用TestClass构造方法的类。
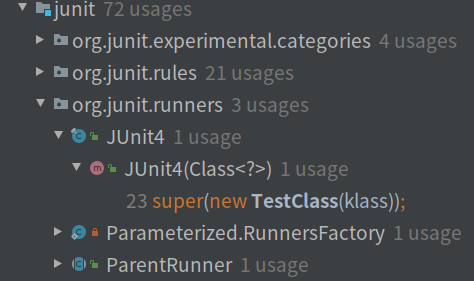
有很多的测试类,结合前面的核心包分析,我们可以直接定位到runners包,runners包中有个JUnit4类。这个类应该就是我们阅读扩展模块的入口了!
梳理调用类结构我们通过JUnit4这个类来构建TestRunners的UML结构。直接在JUnit4上右击,选择Diagrams即可。
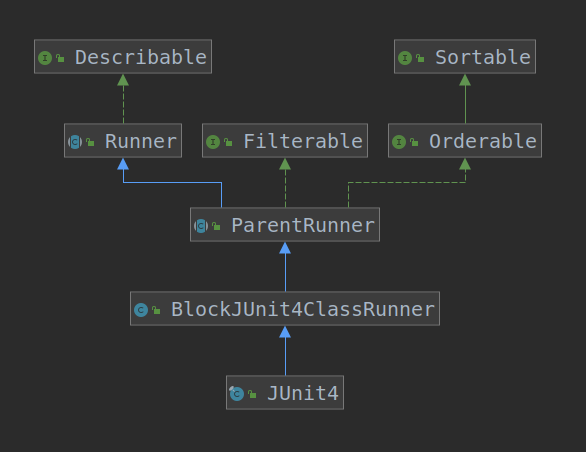
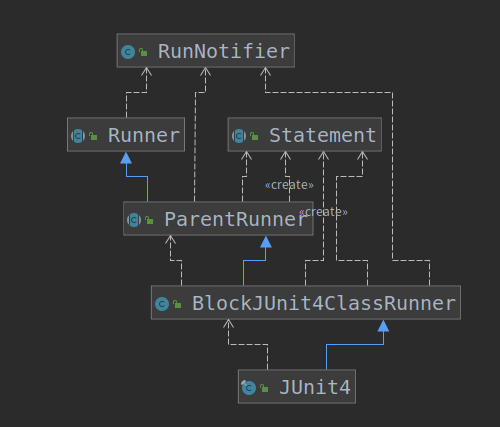
从上图我们可以看到JUnit4有三个父类,一共实现了四个接口。
这里还有个小技巧,IDEA提供了一个功能,能区分各个类是否在同一个包下,只需要选中某个类,如果哪些类和选中的类不在同一个包下,则会被置灰。
例如,我们选中JUnit4,从下图可以看到,除了ParentRunner和BlockJUnit4ClassRunner,其它类都被置灰了。说明其它类和JUnit4不在同一个包下,而ParentRunner和BlockJUnit4ClassRunner与JUnit4同属于org.junit.runners包。结合前面的包关系图,我们可以知道JUnit4与哪些包有关系。

梳理出了大致的调用类模型,我们可以基于这个模型来梳理流程,在梳理流程的同时,再反过来完善调用类模型。
梳理调用类核心流程为了便于梳理,我们先忽略那四个接口,直接看类。
首先,我们注意到Runner和ParentRunner是两个抽象类。好,这里我们停下来回想一下,我们使用抽象类的作用是什么?一般就三个作用:
-
提供子类公用的方法
-
定义流程,比如模板方法模式
-
定义子类需要实现的抽象方法
所以我们可以从这三个角度来看这两个抽象类。我们从最上层的Runner开始。

这个类非常的简单,我们一眼就能看到那个最核心的方法---run方法。我们直接去找run方法的实现。假设你点击IDE右侧的按钮,展示子类,你会发现有很多的子类实现,想要找到具体的实现,是不是要疯?回想一下,你使用debug来读源码的时候,是不是经常遇到这样的问题?
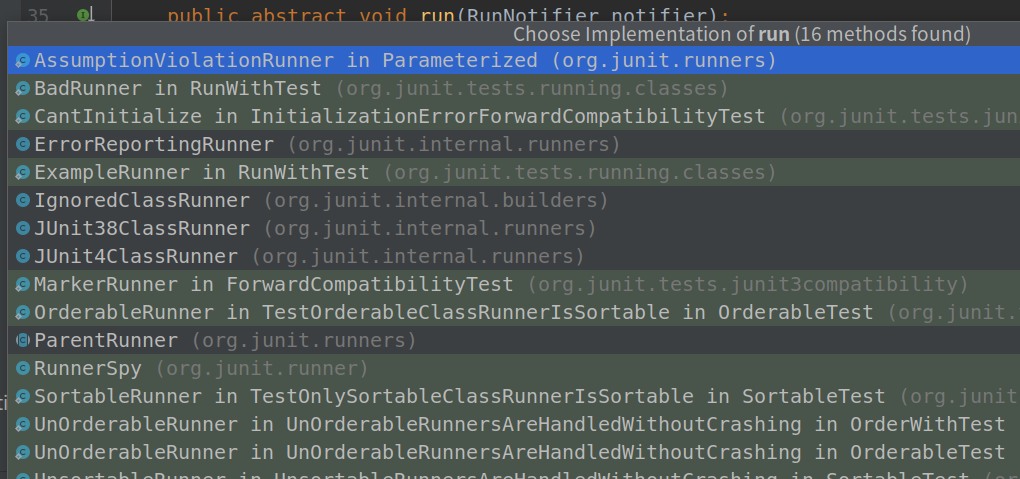
我们在前面梳理出的模型,在这里就起到了非常大的作用,限定了Runner的子类就是ParentRunner,所以我们直接到ParentRunner中去找run方法的实现。这也是先建模再梳理流程的优势之一。

这里的核心是通过classBlock方法构建了一个Statement,然后调用了evaluate方法并通过RunNotifier对象来监听执行过程。从这里我们知道Statement是个执行类,用于执行测试用,TestNotifier是个通知类,用于将执行信息通知给对应的类,所以我们将其加入到调用模型中。
-
为什么使用Statement类?作用是什么?
-
RunNotifier如何进行监听的?
这里我们先提出疑问,记录下来,先梳理流程,后面再进行解答。
我们深入到classBlock方法中。

这里通过childrenInvoker方法来构建了Statement。
if判断里的逻辑是干什么用的呢?看方法名好像和BeforeClass、AfterClass注解有关系,它是怎么处理的呢?
我们先直接跳到childrenInvoker方法来将流程走完。
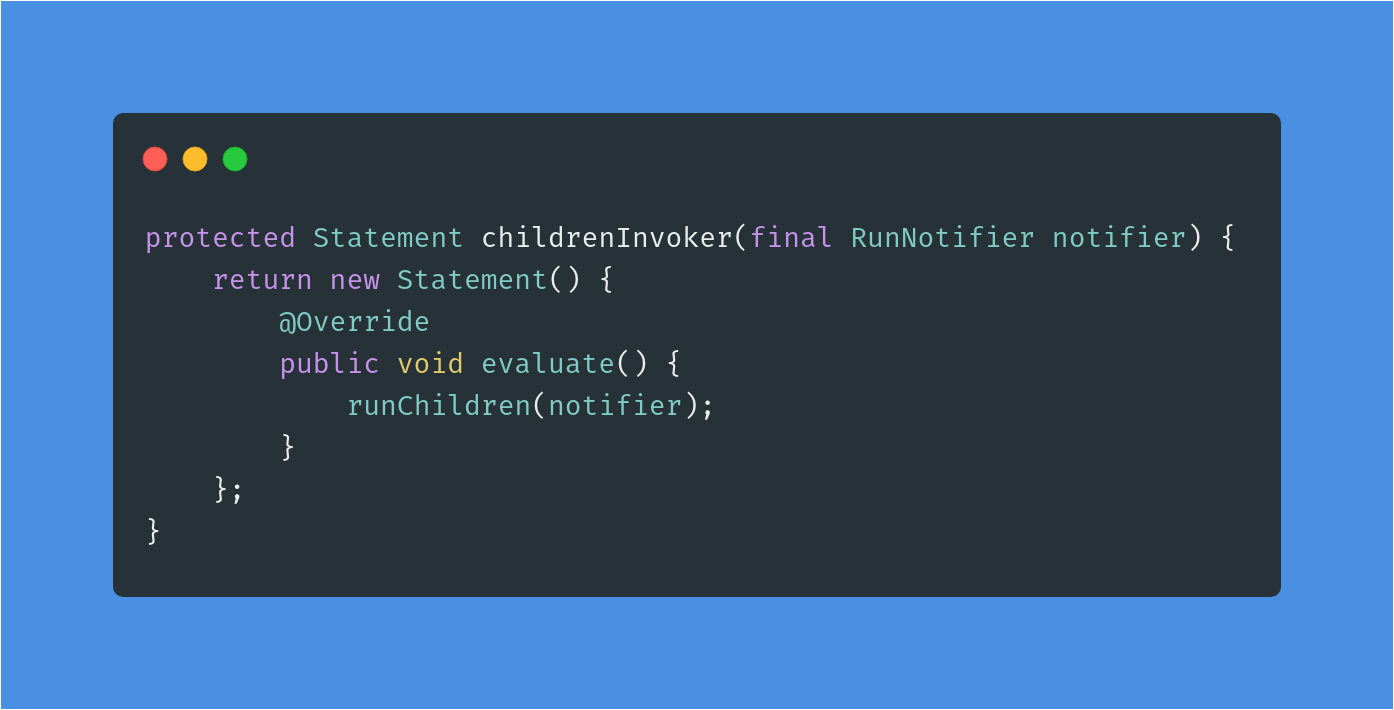
从这里可以看到,这里实际上创建了一个Statement的匿名类,调用的是ParentRunner中的runChildren方法。
为什么要用Statement封装一层?都在ParentRunner类里面,直接调用不就好了吗?

runChildren通过getFilteredChildren方法遍历子元素,通过runChild来执行。
为什么这里要构建一个Runnable来执行呢?
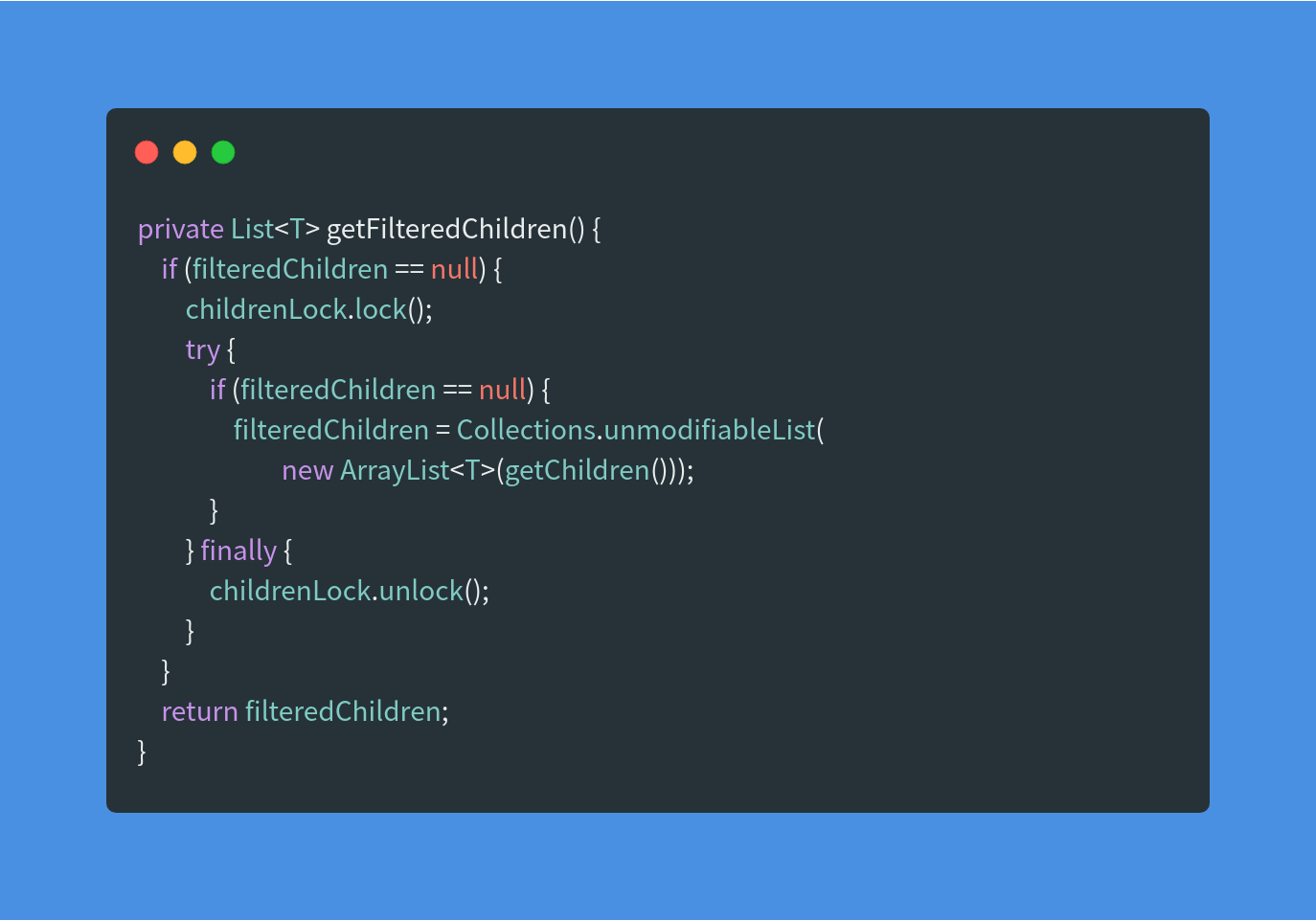
getFilteredChildren方法使用了DCL来加锁,实际调用getChildren来获取子元素,而getChildren是个抽象方法,由子类来实现。具体是哪个子类实现的呢?这里再一次提现了建模的优势。想一想,如果是debug的话,这里是不是又要迷失在一堆子类中了?而我们一开始就限定了需要阅读的类,所以我们可以直接定位到BlockJUnit4ClassRunner这个类,看它的getChildren实现。
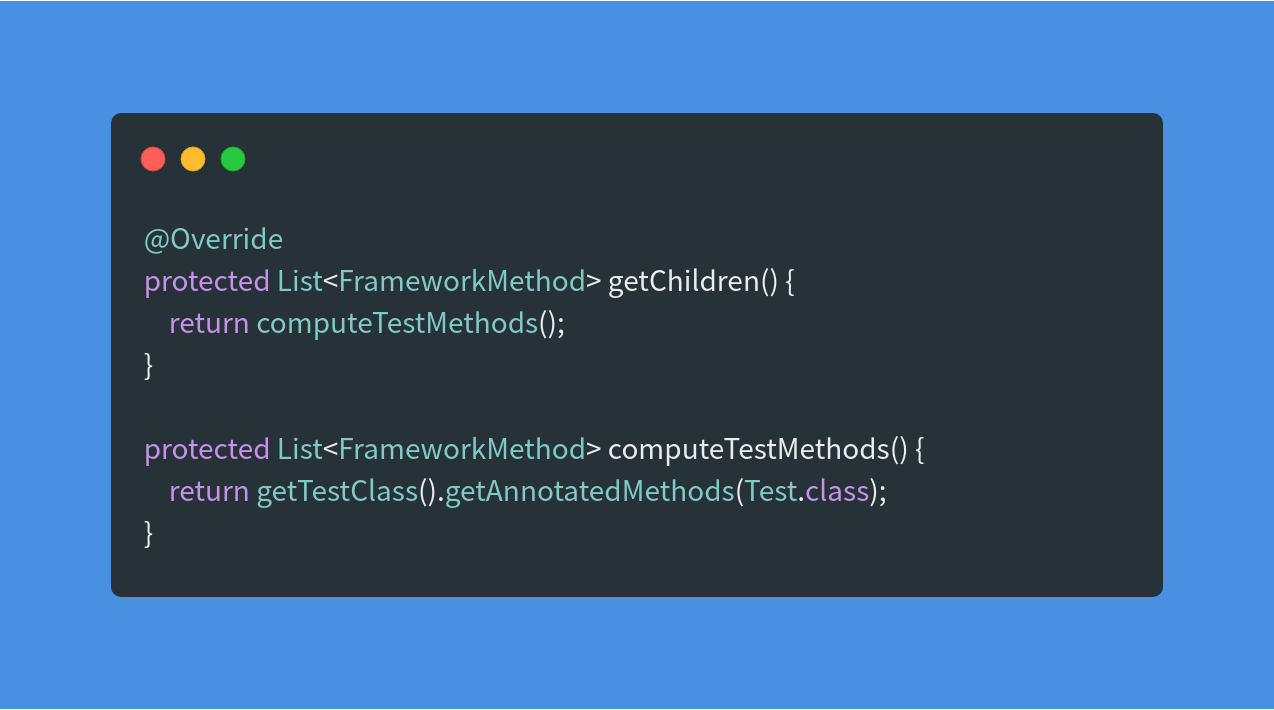
这里可以看到和前面的TestClass关联上了,去获取的是TestClass中的所有包含了Test注解的方法,然后去执行。
完善流程图至此,我们梳理出了TestRunner调用TestClass的流程:
-
某个类会创建一个Runner的实例,创建的可能是BlockJUnit4ClassRunner,也可能是JUnit4
-
然后调用其run方法来执行测试
-
此方法通过RunNotifier来通知对应的类,通过Statement类来执行
-
执行方式是查找测试类中,所有包含了Test注解的方法,一个个的去执行
我们将这个流程添加到流程图中,进一步完善流程。
总结
本文通过调用关系,梳理出了TestRunner调用核心模型的流程。通过此方法不断的向外梳理,你就能构建出完整的项目流程图。
下节将对本节梳理出的问题做出解答,理解为什么这么设计。