一直对Service Mesh相关内容比较感兴趣,后面一路学习了Dcoker、Kubernetes等相关内容,可以说是对基本概念和使用有一定了解,随着开始学习一些相关的组件的时候,发现基本上全部都是Go语言编写,虽然这几年国内还是Java这一套微服务很流行,但是我相信未来是Service Mesh的天下,居于这种背景我开始学习Go的一些语法,会做一些Java语法和Go语法的对比,废话不多说开始吧。
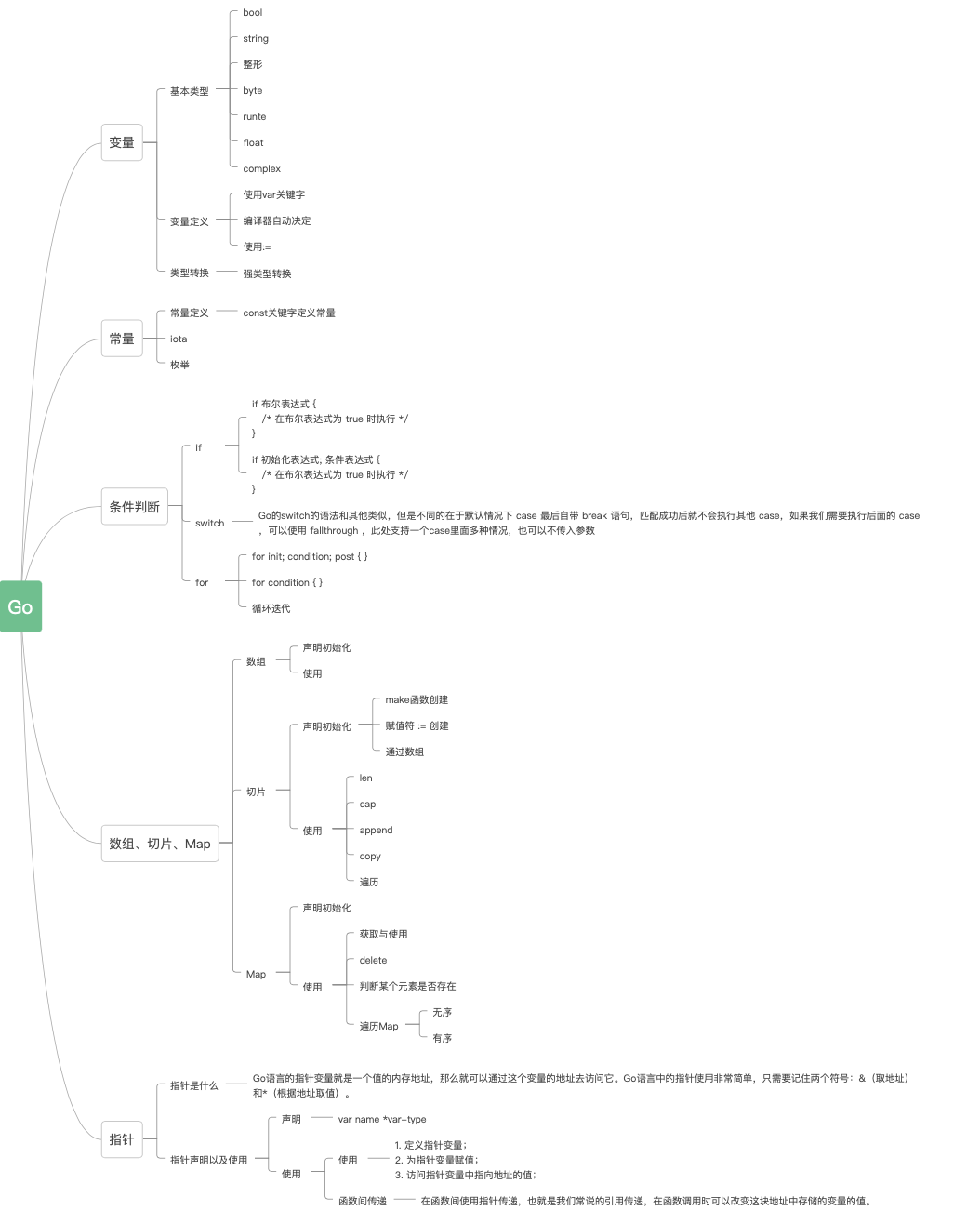
关于变量使用分三个方面讲解,分别是变量定义、基本类型以及类型转换;
变量定义关于变量的定义可以分为三种方式,使用var关键字、编译器自动决定以及使用:=;
使用var关键字使用var声明变量的格式:var 变量名 变量类型,使用var可以放在函数内部也可以直接放到包内,如果觉得每行都用 var 声明变量比较烦琐,可以使用关键字 var 和括号,可以将一组变量定义放在一起。
var (
aaa int = 123
bbb string = "123"
)
func main() {
var a, b, c string = "a", "b", "c"
var (
ccc int = 333
ddd string = "444"
)
fmt.Println(a, b, c)
fmt.Println(aaa, bbb, ccc, ddd)
}
如果觉得每次都要定义变量的类型,可以使用不指定变量的类型;
func main() {
var e, d, f = "aaa", 789, true
fmt.Println(e, d, f)
}
如果觉得使用var也很麻烦,也支持不使用var声明变量;
func main() {
e, d, f := "aaa", 789, true
fmt.Println(e, d, f)
}
Go语言不存在隐式类型转换,因此所有的类型转换都必须显式的声明,string、int、float类型相互转换,相对于Java优势来说这个,Go会将错误的类型返回出来。
func main() {
// string转int
c := "123"
d, err := strconv.Atoi(c)
//如果异常则 err不为空
if err != nil {
fmt.Println(err)
}
fmt.Println("string转int", d)
// string转int64 第二参数表示进制 第三个参数表示int位数
f := "101"
e, er := strconv.ParseInt(f, 2, 64)
if er != nil {
fmt.Println(er)
}
fmt.Println("string转int64", e)
// string转float64 第二个参数表示float位数
h := "123.66"
g, er2 := strconv.ParseFloat(h, 64)
if er2 != nil {
fmt.Println(er2)
}
fmt.Println("string转float64", g)
// int转string
i := 100
j := strconv.Itoa(i)
fmt.Println("int转string", j)
// int转float64
k := float64(i)
fmt.Printf("int转float64%T\n", k)
fmt.Println("int转float64", k)
// float转int 精度丢失
a := 3.1245926
b := int(a)
fmt.Printf("float转int%T\n", a)
fmt.Println("float转int", b)
// float转string
// 第二个参数格式标记 第三个参数数字位数 第四个参数float类型
l := strconv.FormatFloat(a, 'G', 3, 64)
fmt.Println(l)
}
对于布尔值和其他语言一样,布尔型数据只有true和 false两个值,需要注意的是,Go语言中布尔型无法参与数值运算,也无法与其他类型转换。
func main() {
a := true
var b bool
fmt.Printf("%T\n", a)
fmt.Printf("%T value:%v\n", b, b)
}
整型分为以下两个大类: 按长度分为:int8、int16、int32、int64 对应的无符号整型:uint8、uint16、uint32、uint64,int64对应Java的Long,int32对应Java的int。
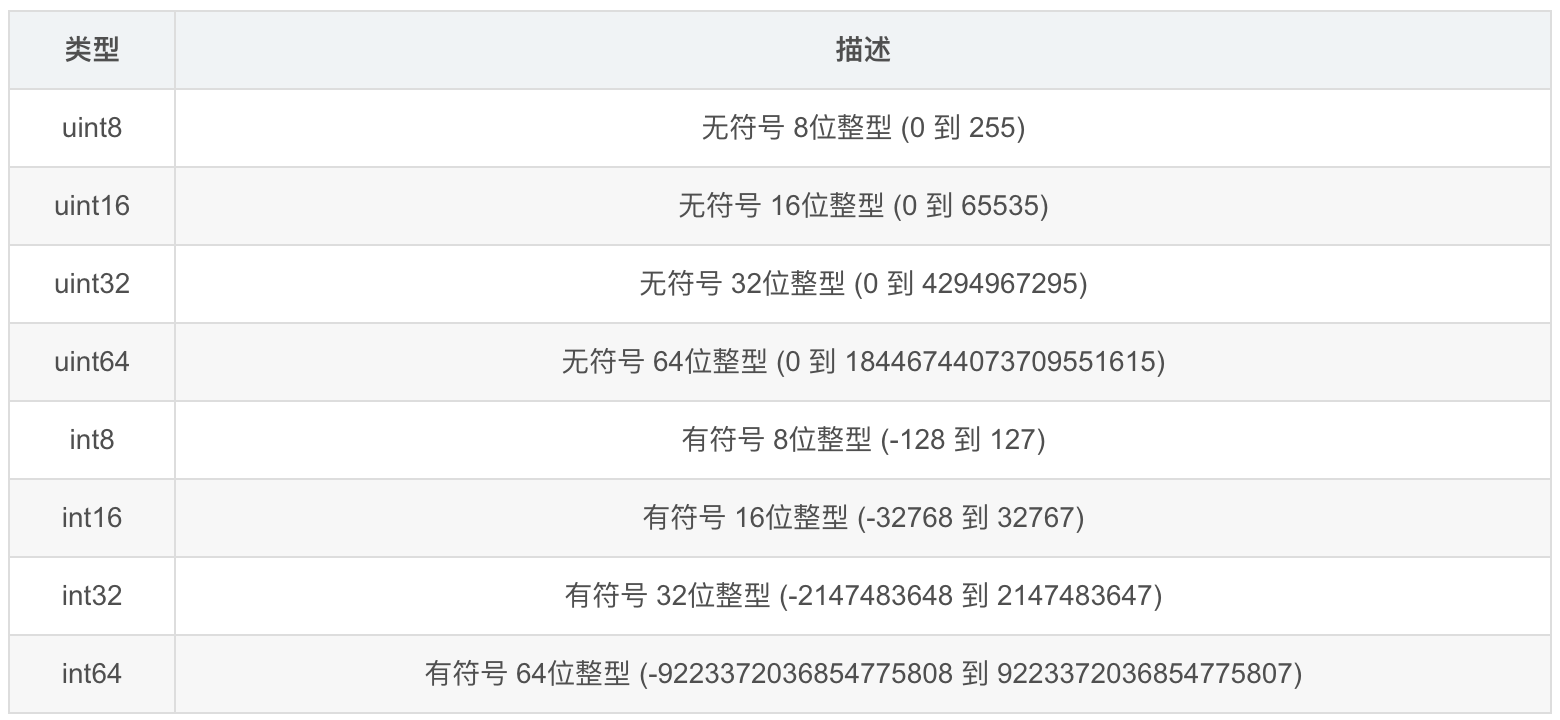
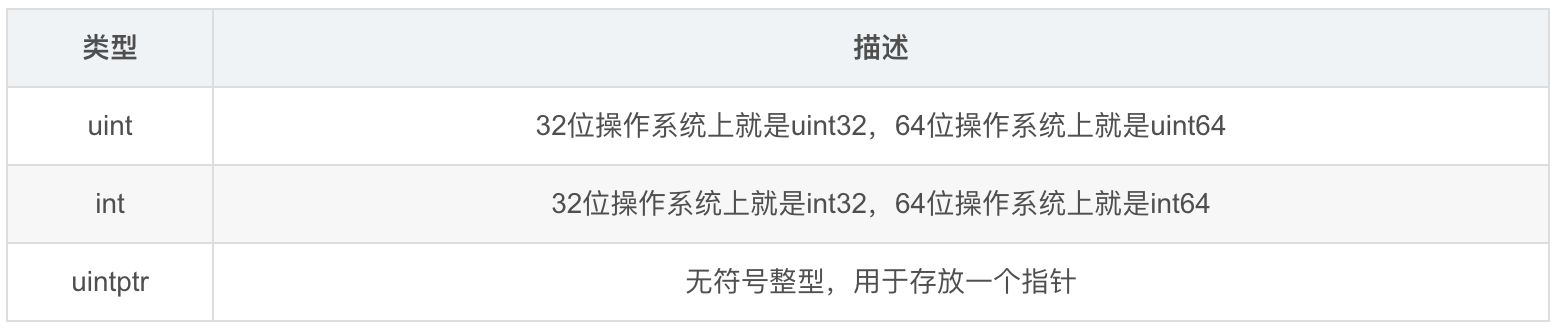
注意: 在使用int和 uint类型时,不能假定它是32位或64位的整型,而是考虑int和uint可能在不同平台上的差异。
数字字面量语法Go1.13版本之后引入了数字字面量语法,使用如下:
func main() {
m := 10
fmt.Printf("十进制%d \n", m)
fmt.Printf("二进制%b \n", m)
fmt.Printf("八进制%o \n", m)
fmt.Printf("十六进制%x \n", m)
}
Go语言支持两种浮点型数:float32和float64。 float32的浮点数的最大范围约为 3.4e38,可以使用常量定义:math.MaxFloat32。 float64的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64。
func main() {
n := 10.11
fmt.Printf("浮点型%f\n", n)
fmt.Printf("浮点型%.2f\n", n)
}
Go相比于其他语言多了一个复数的类型,复数的类型有两种,分别是 complex128(64 位实数和虚数)和 complex64(32 位实数和虚数),其中 complex128 为复数的默认类型。方便我们对一些公式进行表示,侧面说明了Go语言想充分涉猎多个领域。
func main() {
c2 := 2 + 3i
fmt.Println("复数声明", c2)
fmt.Println("获取复数的实部", real(c2), ", 获取复数的虚部", imag(c2))
}
Go语言中的字符串不像其他语言占固定的字节数,Go语言的字符串是一个用UTF-8编码的变宽字符序列,它的每一个字符都用一个或多个字节表示 ,因此Go语言中字符串根据需要占用 1 至 4 个字节。在Go语言中,没有字符类型,字符类型是rune类型,rune实际是一个int32。可使用 []byte() 获取字节数,使用 []rune()获取字符,可对中文进行转换。
func main() {
s := "a我没菜了" //UTF-8编码
fmt.Println("遍历字节")
for _, b := range []byte(s) {
fmt.Printf("%X ", b)
}
fmt.Println()
fmt.Println("获取字符串个数", utf8.RuneCountInString(s))
fmt.Println("获取字节数", len(s))
fmt.Println("遍历字符")
bytes := []byte(s)
for len(bytes) > 0 {
k, v := utf8.DecodeRune(bytes)
bytes = bytes[v:]
fmt.Printf("%c ", k)
}
fmt.Println()
for k, v := range []rune(s) {
fmt.Printf("(%d,%c)", k, v)
}
fmt.Println()
}
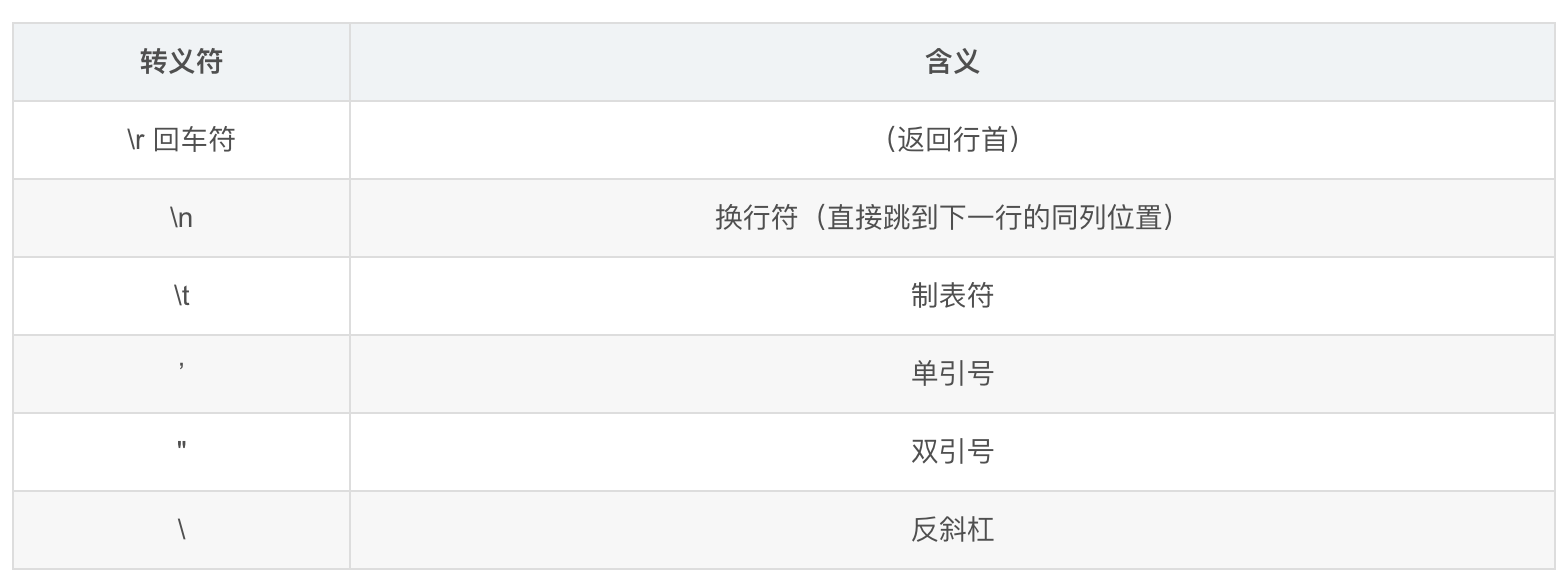
可以使用双引号""来定义字符串,字符串中可以使用转义字符来实现换行、缩进等效果,常用的转义字符包括:
反引号定义字符串,这些字符串可能由多行组成(不支持任何转义序列),原生的字符串字面量多用于书写多行消息、HTML以及正则表达式,不支持做任何转义的原始内容;
func main() {
m := "Go语言字符串\n不能跨行赋值"
fmt.Println(m)
n := `Go原生原格式字符串
可以跨行`
fmt.Println(n)
}
使用+号连接字符串,Go里面的字符串都是不可变的,每次运算都会产生一个新的字符串,所以会产生很多临时的无用的字符串,不仅没有用,还会给 gc带来额外的负担,所以性能比较差;
str := "hello" + "go"
使用 fmt.Sprintf() 连接字符串,内部使用 []byte 实现,不像直接运算符这种会产生很多临时的字符串,但是内部的逻辑比较复杂,有很多额外的判断,还用到了interface,性能也不是很好;
str := fmt.Sprintf("%s,%s", "hello", "go")
使用 buffer.WriteString()连接,可以当成可变字符使用;
var buffer bytes2.Buffer
buffer.WriteString("hello")
buffer.WriteString(",")
buffer.WriteString("go")
str := buffer.String()
fmt.Println(str)
Go语言中使用单引号用来表示单个的字符,字符也是组成字符串的元素。Go语言的字符有两种:
uint8类型,或者叫 byte 型,代表了ASCII码的一个字符; rune类型,代表一个 UTF-8字符;
rune类型的值在底层都是由一个 UTF-8 编码值来表达的。Unicode字符,我们平时接触到的中英日文,或者复合字符,都是Unicode字符。UTF-8 编码方案会把一个 Unicode 字符编码为一个长度在 1~4 以内的字节。所以,一个rune类型值代表了1~4个长度的byte数组。因此一个string类型的值既可以被拆分为一个包含多个字符的序列,也可以被拆分为一个包含多个字节的序列。前者可以由一个以rune为元素类型的切片来表示,而后者则可以由一个以byte为元素类型的切片代表。
修改字符串要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
func main() {
s1 := "wtz"
byteS1 := []byte(s1)
byteS1[0] = 'p'
fmt.Println(string(byteS1))
s2 := "绿叶"
runeS2 := []rune(s2)
runeS2[0] = '白'
fmt.Println(string(runeS2))
}
常量是指编译期间就已知且不可改变的值,在Go语言中我们可以通过 const 关键字来定义常量,常量只能是布尔、整数、浮点、复数和字符串。
常量定义通过 const 关键字定义常量时,可以指定常量类型,也可以省略(底层会自动推导),如果在运行时修改常量的值,则会在编译期报错。常见的常量定义方式如下:
//通过一个const关键字定义多个常量,和 var 类似
const (
size int64 = 1024
// 无类型整型常量
eof = -1
)
//无类型整型和字符串常量
const a, b, c = 3, 4, "foo"
iota是一个特殊常量,可以认为是一个可以被编译器修改的常量。在每一个const关键字出现时,被重置为0,然后再下一个const出现之前,每出现一次iota,其所代表的数字会自动增加1。
const (
a = iota
b = iota
c = iota
)
对于上面常量声明我们也可以简写为:
const (
a = iota
b
c
)
此外我们也可以进行运算,如下:
import "fmt"
const (
i=1<<iota
j=3<<iota
k
l
)
func main() {
fmt.Println("i=",i)
fmt.Println("j=",j)
fmt.Println("k=",k)
fmt.Println("l=",l)
}
对于Go语言来说不存在枚举类型,但是可以使用常量来表示枚举。枚举中包含了一系列相关的常量,比如下面关于一个星期中每天的定义。Go 语言并不支持其他语言用于表示枚举的 enum 关键字,而是通过在 const 后跟一对圆括号定义一组常量的方式来实现枚举。
const (
Sunday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
Go关于if的判断做的更加简洁,去掉了括号,此外还可以增加一个表达式,语法如下:
if 布尔表达式 {
/* 在布尔表达式为 true 时执行 */
}
if 初始化表达式; 条件表达式 {
/* 在布尔表达式为 true 时执行 */
}
func main() {
m := 100
if m > 20 {
fmt.Println(m)
} else {
fmt.Println(m * 2)
}
if content, err := ioutil.ReadFile(""); err == nil {
fmt.Println(string(content))
} else {
fmt.Println(" file error", err)
}
}
Go的switch的语法和其他类似,但是不同的在于默认情况下 case 最后自带 break 语句,匹配成功后就不会执行其他 case,如果我们需要执行后面的 case,可以使用 fallthrough ,此处支持一个case里面多种情况,也可以不传入参数,语法如下:
switch var1 {
case val1:
...
case val2:
...
default:
...
}
func grade(score int) string {
g := ""
switch {
case score < 60:
g = "B"
case score > 70:
g = "A"
default:
panic("错误了")
}
return g
}
对于循环语句,在Go语言中只存在for循环,没有while和do...while的语法,此外对于for循环也是可以省略括号的,语法结构如下
for init; condition; post { }
初始化语句只执行一次。在初始化循环之后,将检查该条件。如果条件计算为true,那么{}中的循环体将被执行,然后是post语句。post语句将在循环的每次成功迭代之后执行。在执行post语句之后,该条件将被重新检查。如果它是正确的,循环将继续执行,否则循环终止。在for循环中声明的变量仅在循环范围内可用。因此,i不能在外部访问循环。对于fo循环的r所有的三个组成部分,即初始化、条件和post都是可选的。
对于for实现while的语法如下,该语法类似于Java中for(,,)的效果:
for condition { }
此外for可以循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环。
func main() {
var b int = 15
var a int
numbers := [6]int{1, 2, 3, 5}
for a := 0; a < 10; a++ {
fmt.Printf("a 的值为: %d\n", a)
}
for a < b {
a++
fmt.Printf("a 的值为: %d\n", a)
}
for i,x:= range numbers {
fmt.Printf("第 %d 位 x 的值 = %d\n", i,x)
}
}
Go语言中与Java不同的是数组是一个值类型,对于其他数组是一个固定长度不可以变。在内存上开辟的空间是连续的。
声明数组Go语言中,数组的声明方式为var arr_name [5]int。声明时没有指定数组的初始化值,因此所有的元素都会被自动初始化为默认值 0;
func main() {
//声明一个包含5个元素的数组 默认值为0
var arry [5]int
//声明一个包含5个元素的数组,并初始化每个元素
arry1 := [5]int{1, 2, 3, 4, 5}
//容量由初始化数量决定
arry2 := [...]int{100, 200, 300}
//声明一个包含5个元素的数组 指定特定位置的数组初始化
arry3 := [5]int{1: 20, 4: 40}
fmt.Println(arry)
fmt.Println(arry1)
fmt.Println(arry2)
fmt.Println(arry3)
}
Go语言普通的数组无法通过下标直接访问数组,这是与Java不一致的地方,可以通过下标修改数组中的值,也可以将一个数组赋值给另外一个相同的数组,可以通过range关键字遍历数组。在Go语言中数组是一个值类型,所以在函数传递的时候需要在栈上分配相同大小的内存,这也是与Java不一样的地方,关于如何向Java一样使用在后续指针时候介绍。
func main() {
arry := [5]int{10, 20, 30, 40, 50}
//修改索引为2的数组
arry[2] = 35
fmt.Println(arry)
//相同类型数组赋值给另外一个数组
var arry1 [5]int
arry1 = arry
fmt.Println(arry1)
//遍历数组
for k, v := range arry {
fmt.Printf("下标 %d 值 %d \n", k, v)
}
//函数传递
foo(arry)
}
func foo(arry [5]int) {
//遍历数组
for k, v := range arry {
fmt.Printf("下标 %d 值 %d \n", k, v)
}
}
多维数组与数组的区别在于有多个维度,使用上就是通过多个坐标决定位置。
func main() {
//多维数组声明
var arry3 [4][2]int
arry2 := [2][2]int{{10, 11}, {10, 12}}
fmt.Println(arry3)
fmt.Println(arry2)
}
关于切片这个概念是Go语言独有的,Go语言的切片可理解为对数组的一种抽象。由于Go语言的数组长度不可改变,在特定场景中就不太适用,Go提供了切片,与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。slice 并不是数组或数组指针,它通过内部指针和相关属性引用数组片段 ,以实现变长方案。
切片的结构体由3部分构成,Pointer 是指向一个数组的指针,len 代表当前切片的长度,cap 是当前切片的容量。cap 总是大于等于 len 的。
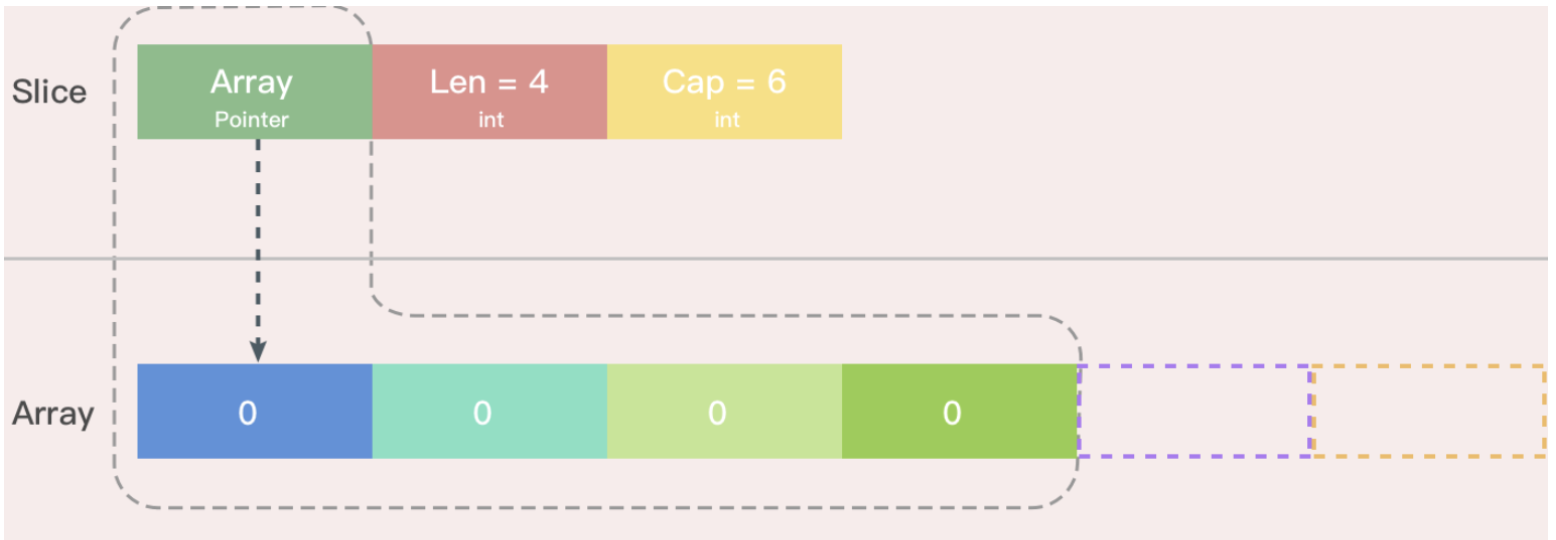
使用make创建切片的语法如下:
var slice1 []type = make([]type, length, capacity)
//也可以简化为
slice1 := make([]type, length, capacity)
需要注意的是当cap值大于len时候创建会报错,下面演示了三种创建的方式;
make函数创建; 赋值符 := 创建,通过索引和之间初始化的方式; 通过数组;
func main() {
//创建一个int类型切片 len cap 都为5
slice := make([]int, 5)
fmt.Println(slice)
//创建一个int类型切片 len为3 cap为5
slice1 := make([]int, 3, 5)
fmt.Println(slice1)
//通过字面量来创建切片 这样cap和len都等于5 与数组不同地方在于不需要指定长度
slice2 := []int{10, 20, 30, 40, 50}
fmt.Println(slice2)
//通过下标来创建 与正常字面量创建不太一样的地方是中间使用: 在下标的第10个位置初始化一个8
slice3 := []int{10: 8}
fmt.Println(slice3)
//通过数组来创建 截取数组下标0到1的元素为一个新切片
arry := [5]int{1, 2, 3, 4, 5}
slice4 := arry[0:2]
fmt.Println(slice4)
}
工作中我们可能需要创建一个nil切片或者空切片,Go语言的nil相当于Java的null,我们可以使用以下方式创建:
func main() {
//创建nil切片
var slice4 []int
if slice4 == nil {
fmt.Println("nil切片", slice4)
}
//创建空切片
slice5 := make([]int, 0)
slice6 := []int{}
if slice5 != nil && slice6 != nil {
fmt.Println("空切片", slice5)
fmt.Println("空切片", slice6)
}
}
空切片和 nil 切片的区别在于,空切片指向的地址不是 nil,指向的是一个内存地址,但是它没有分配任何内存空间,即底层元素包含0个元素。不管是使用 nil 切片还是空切片,对其调用内置函数 append,len 和 cap 的效果都是一样的。
初始化关于直接创建的切片与通过数组创建的切片还是有一些不一样的,这里来阐述一下不同。
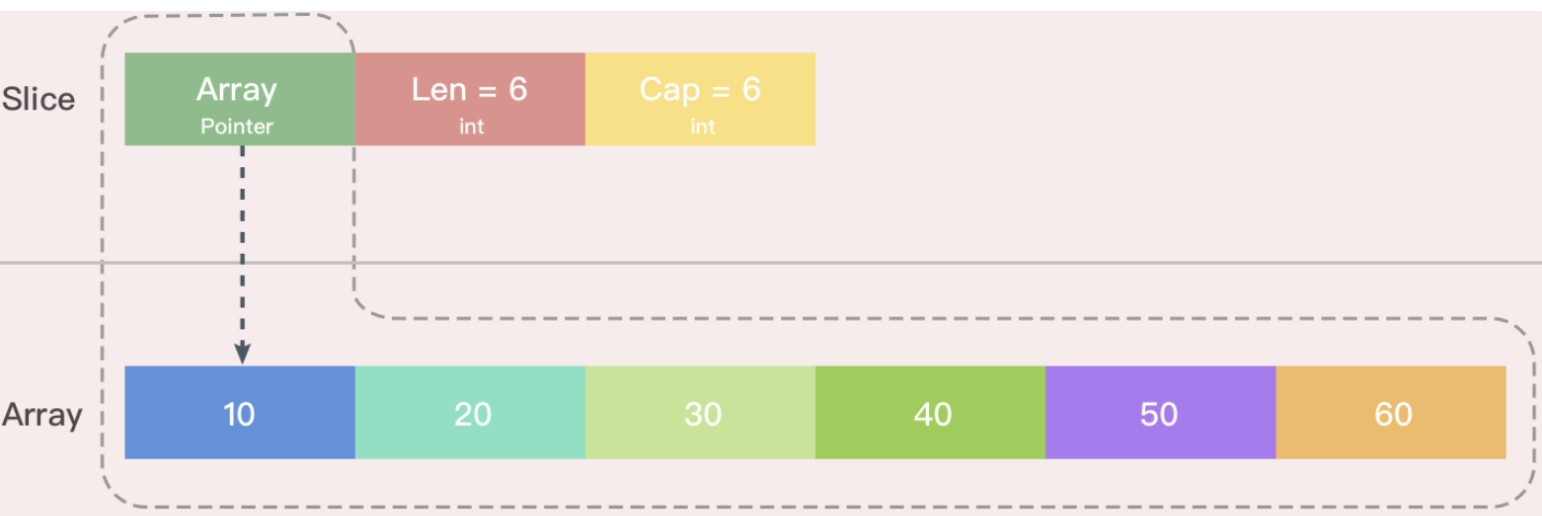
声明的同时初始化声明的同时就完成了初始化操作,采用该方式的结构是这样,同时或默认创建一个数组,cap=len=6;
slice2 := []int{10, 20, 30, 40, 50, 60}
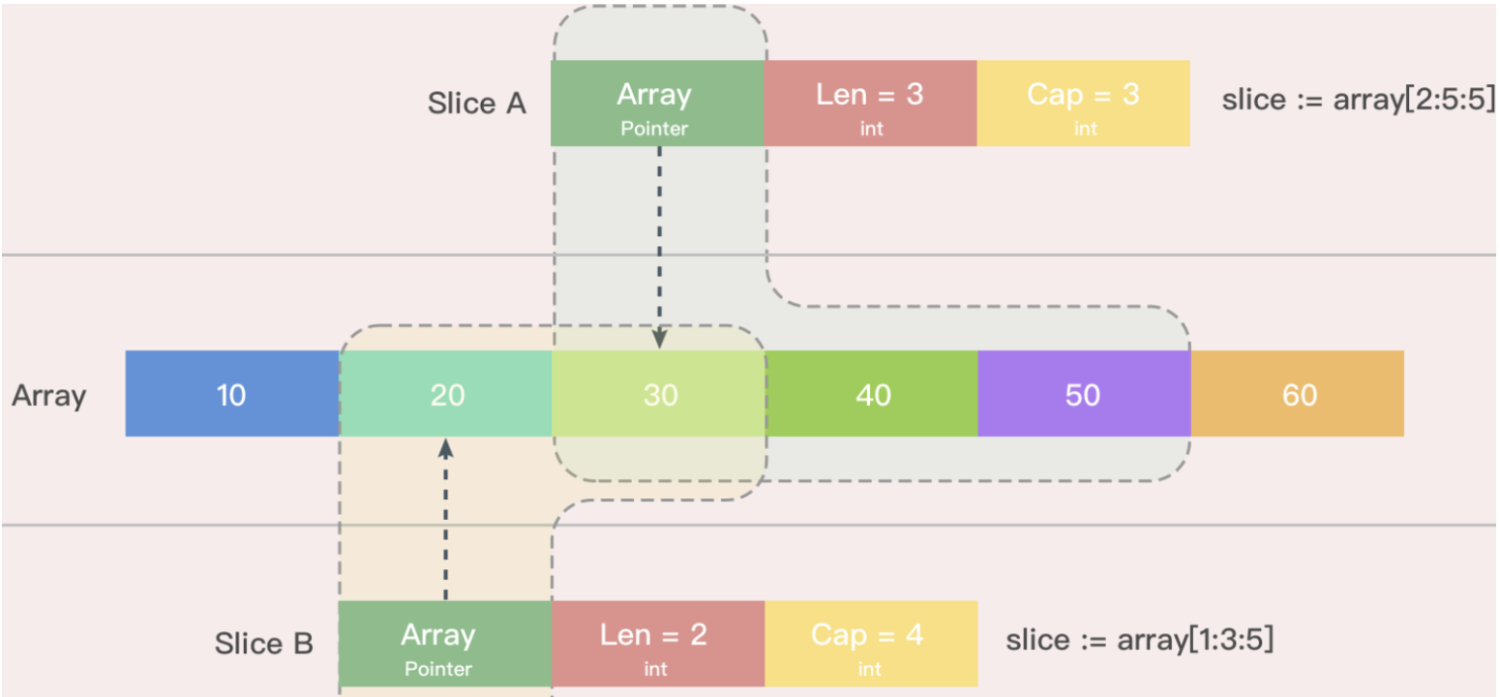
采用数组进行切片的初始化,这个时候切片指向的数组的引用,关于arry[1:3:5]的意思是,从数组下标1位置开始到,len长度等于3-1,cap长度等于5-1,len代表切片的长度,cap代表切片总容量。
arry := [6]int{10, 20, 30, 40, 50, 60}
slice := arry[2:5:5]
slice2 := arry[1:3:5]
fmt.Println(slice)
fmt.Println(slice2)
关于采用数组声明方式介绍如下:
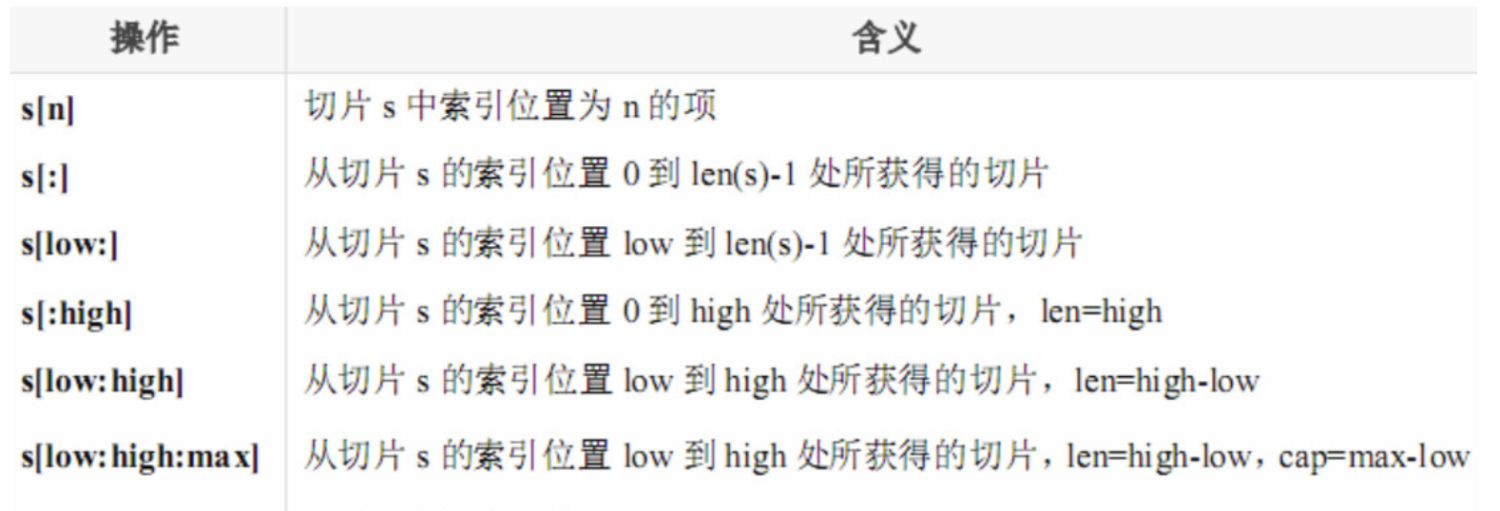
总结:切片的本质是数组,但是并不是数组,它只是引用了数组的一段。创建一个切片,系统会自动为你创建一个底层数组,然后引用这个底层数组生成一个切片。操作的是切片本身,但实际上操作的是它所依托的那个底层的数组。
使用切片介绍数组的时候你会发现我们介绍一些关于数组增加元素、删除元素的操作,在Go语言中这些都是通过切片实现的,关于使用切片这里主要介绍常用函数的使用:
len 和 caplen获取切片的长度,cap获取切片最大的容量。
func main() {
arry := [6]int{10, 20, 30, 40, 50, 60}
slice := arry[2:5:5]
fmt.Println("slice len=%d cap=%d ", len(slice), cap(slice), slice)
}
关于append是切片的尾部添加数据,需要注意的是如果切片超过最大的容量会重新创建新的切片,对于通过数组创建的切片也是一样的。
func main() {
a := []int{1, 2, 3}
b := []int{4, 5, 6}
//向后添加元素
c := append(a, b...)
fmt.Printf("c对象 %p\n", c)
fmt.Print(c)
fmt.Println()
d := append(c, 7)
//c和d已经不是同一个对象 新建一个数组
fmt.Printf("d对象 %p\n", d)
fmt.Println(d)
fmt.Println()
arry := [6]int{10, 20, 30, 40, 50, 60}
e := arry[2:5]
fmt.Printf("e对象 %p\n", e)
fmt.Println(e)
f := append(e, 51, 52)
//e和f对象不一样 底层数组已经发生改变
fmt.Printf("f对象 %p\n", f)
fmt.Print(f)
}
切片的拷贝分为2种,一种是浅拷贝,一种是深拷贝。浅拷贝:源切片和目的切片共享同一底层数组空间,源切片修改,目的切片同样被修改。深拷贝:源切片和目的切片各自都有彼此独立的底层数组空间,各自的修改,彼此不受影响。浅拷贝核心就是共享底层数组,修改某个切片的值也会影响到另外一个切片,案例如下
func main() {
slice := []int{10, 20, 30, 40, 50, 60}
fmt.Println("原切片", slice)
slice1 := slice[1:3]
fmt.Println("浅拷贝切片", slice1)
slice1[1] = 21
fmt.Println("浅拷贝切片赋值以后", slice1)
fmt.Println("原切片", slice)
}
深拷贝的核心是底层数组不相互依赖,相互的修改互不影响,案例如下:
func main() {
slice := []int{1, 2, 3, 4, 5}
fmt.Println("slice 初始化",slice)
slice1 := []int{10, 20, 30, 40, 50, 60}
fmt.Println("slice1 初始化",slice1)
fmt.Println("slice 拷贝 slice1",copy(slice, slice1))
slice[0] = 11
slice1[0] = 12
//这个地方我们会发现输出以后的值不相互影响
fmt.Println("slice 深拷贝完以后修改值",slice)
fmt.Println("slice1 后修改值",slice1)
}
func main() {
slice := []int{1, 2, 3, 4, 5}
for k, v := range slice {
fmt.Printf("key : %v , value : %v\n", k, v)
}
}
声明Map的方式有两种,通过make或者map可以声明,Map是一个引用类型的,如果只声明,而不创建 map,那么就会创建一个 nil map。nil map 不能用来存放键值对,如果对nil map 进行操作会报错。声明之后,map类型的变量默认初始值为 nil,需要使用 make() 函数来分配内存。
func main() {
//采用字面量声明并初始化
m := map[string]string{"A": "A", "B": "B"}
fmt.Println(m)
//make函数创建的是是个空的map
m2 := make(map[string]int)
fmt.Println(m2)
//使用map声明的时候 是一个nil 这个时候必须通过make进行初始化
var m3 map[string]int
//初始化10个容量
m3 = make(map[string]int, 10)
m3["A"] = 1
fmt.Println(m3)
}
获取和使用对应Java就是get和put函数,对于Go语言来说这个就很简单了。
func main() {
//采用字面量声明并初始化
m := map[string]string{"A": "A", "B": "B"}
fmt.Println(m)
//put一个值
m["C"] = "C"
fmt.Println(m)
//获取一个值
fmt.Println(m["A"])
}
delete函数用于删除集合 map 中的元素,类似于Java的remove操作。
func main() {
//采用字面量声明并初始化
m := map[string]string{"A": "A", "B": "B"}
fmt.Println(m)
//删除
delete(m, "A")
fmt.Println(m)
}
Go语言中有个判断 map 中某个键是否存在的特殊写法,格式如下:value, ok := map[key],如果键存在,那么会返回 相应的值 和 true,如果键不存在,那么会空和false。
func main() {
//采用字面量声明并初始化
m := map[string]string{"A": "A", "B": "B"}
fmt.Println(m)
//判断一个值是否存在
value, ok := m["A"]
if ok {
fmt.Println(value)
}
}
对于Map的遍历是无序的,同样也需要采用range遍历,如果需要有序的遍历我们需要使用对键进行排序的方法是把所有的键放在一个切片里,然后用sort包中的函数进行排序。
func main() {
//采用字面量声明并初始化
m := map[string]string{"A": "A", "B": "B", "E": "E", "C": "C", "D": "D"}
fmt.Println(m)
//遍历 k v
for k, v := range m {
fmt.Printf("key %s value %s \n", k, v)
}
//遍历 k
//将key存放到一个切片中
keys := make([]string, 5, 10)
for k := range m {
fmt.Printf("key %s \n", k)
keys = append(keys, k)
}
//key排序
sort.Strings(keys)
//有序遍历
fmt.Printf("有序遍历")
for _, v := range keys {
fmt.Printf("key %s value %s \n", v, m[v])
}
}
我们上面介绍基本类型,在函数传递的过程中都是值传递,也就是说必须在栈上开辟对应的空间,在Go语言引入指针的概念,让我们可以实现引用传递,在传递过程中传递数据使用指针,而无须拷贝数据,区别于C/C++中的指针,Go语言中的指针不能进行偏移和运算,是安全指针,也是一种简化的指针。在Go语言中的指针使用非常简单,只需要记住两个符号:&(取地址)和*(根据地址取值)。
指针是什么Go语言的指针变量就是一个值的内存地址。那么就可以通过这个变量的地址去访问它。
func main() {
a := 10
b := &a
//&a获取的是地址
fmt.Printf("a的值:%d a指针地址:%p\n", a, &a)
//*b取值
fmt.Printf("变量b:%p b的类型:%T b变量的存储的值%d\n", b, b, *b)
fmt.Printf("变量b指针地址:%p \n", &b)
}
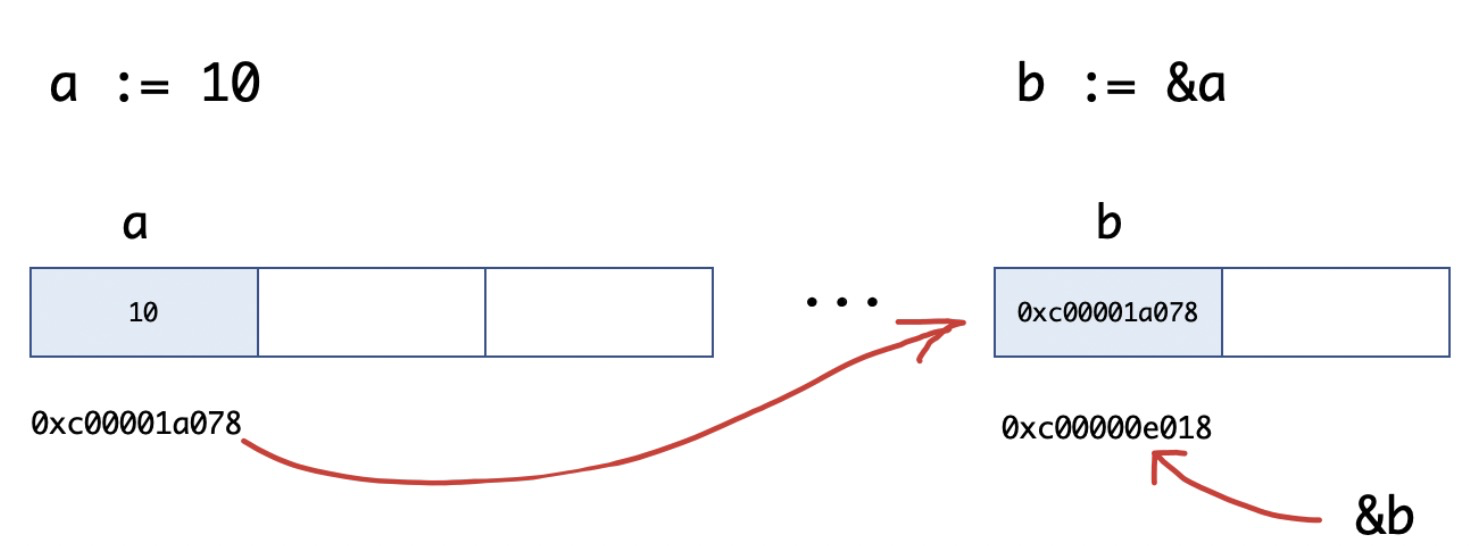
指针的声明的格式如下: var-type 为指针类型,name 为指针名,* 号用于指定变量是一个指针。Go语言中的值类型(int、float、bool、string、array、struct)都可以声明为指针类型。
var name *var-type
指针的使用:
定义指针变量; 为指针变量赋值; 访问指针变量中指向地址的值;
需要注意的是,如果只声明指针却不初始化,直接使用会报错。对于Go语言来说,值类型声明的时候就已经创建好内存空间,对于引用类型来说,我们声明的时候只是一个指针变量,没有进行初始化,也就是没进行内存空间的开辟,直接使用自然会报错。当一个指针被定义后没有分配到任何变量时,它的值为 nil。nil 指针也称为空指针,这时候就和Java是一样的了。
func main() {
//声明变量
a := 20
//声明指针变量
var ip *int
//指针变量的存储地址
ip = &a
fmt.Printf("a 变量的地址是: %x\n", &a)
//指针变量的存储地址
fmt.Printf("ip 变量储存的指针地址: %x\n", ip)
//使用指针访问值
fmt.Printf("*ip 变量的值: %d\n", *ip)
}
在Go语言中为我们提供new函数,可以让我们完成一次性完成上面的三个步骤。
func main() {
a := new(int)
fmt.Println(a)
fmt.Println(*a)
*a = 100
fmt.Println(*a)
}
在上面这个案例中new函数得到的是指向一个类型的指针,并且该指针对应的值为该类型的零值。这里还要提一下make函数,make函数也是用于内存分配的。区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。
函数间传递在函数间使用指针传递,也就是我们常说的引用传递,在函数调用时可以改变这块地址中存储的变量的值。
func main() {
a := 10
//值传递
modify(a)
fmt.Println("值传递", a)
//引用传递
modify2(&a)
fmt.Println("引用传递", a)
}
func modify(x int) {
x = 100
}
func modify2(x *int) {
*x = 100
}
欢迎大家点点关注,点点赞!
