 在本文中,我们将介绍 GraphScope 图交互式查询引擎 GAIA-IR,它支持高效的 Gremlin 语言表达的交互图查询,同时高度抽象了图上的查询计算,具有高可扩展性。
在本文中,我们将介绍 GraphScope 图交互式查询引擎 GAIA-IR,它支持高效的 Gremlin 语言表达的交互图查询,同时高度抽象了图上的查询计算,具有高可扩展性。
背景介绍在本文中,我们将介绍 GraphScope 图交互式查询引擎 GAIA-IR,它支持高效的 Gremlin 语言表达的交互图查询,同时高度抽象了图上的查询计算,具有高可扩展性。
在海量数据的分析中,图查询是一种重要的工具。Gremlin[1] 是由 Apache Tinkerpop 提出并维护的工业界标准的图查询语言,被业界流行图数据库广泛应用,例如 Neo4j[2] 、OrientDB[3]、JanusGraph[4]、Microsoft Cosmos DB[5] 以及 Amazon Neptune[6]。而 GraphScope 中的图查询引擎 GAIA 则是业界首个开源的支持大规模分布式并行化 Gremlin 的系统。然而,尽管 Gremlin 语言的灵活性是它显著的优势,在 GAIA 系统的设计和使用中,我们也发现了一些存在的问题。
现有问题GAIA 查询系统主要有如下几点弊病:
D1: Gremlin 算子数量繁多,并且对同种语义有多种表达。这就导致为了支持丰富的 Gremlin 算子,GAIA 中需要端到端在各个模块中添加对应的算子,并且算子实现之间可能存在冗余的计算逻辑。例如,当我们有查看属性的需求时,Gremlin 中可以通过elementMap()、 valueMap()、values()、 select().valueMap()、 project().valueMap()等表达方式得到类似的结果,示例如下:
gremlin> g.V().elementMap()
==>[id:1,label:person,name:marko,age:29]
==>[id:2,label:person,name:vadas,age:27]
gremlin> g.V().valueMap('name','age')
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
gremlin> g.V().as('a').select('a').by(valueMap('name', 'age'))
==>[name:[marko], age:[29]]
==>[name:[vadas], age:[27]]
gremlin> g.V().as('a').project('a').by(valueMap('name', 'age'))
==>[a:[name:[marko], age:[29]]]
==>[a:[name:[vadas], age:[27]]]
而为了支持这些类似的表达,GAIA 中需要定义多个冗余算子,并且需要在各个模块中支持,对开发并不友好,可扩展性较差。
D2: GAIA 的语言扩展性差。GAIA 是 Gremlin 并行化查询的定制化实现,而现如今也有很多其他常用的图查询语言,例如 Cypher、GSQL 等。如果未来我们需要进一步接入更多的查询语言,则几乎无法通过扩展 GAIA 来实现。
D3:: Gremlin 对复杂的 expression 支持不佳。例如,我们想通过以下 Gremlin 查询语句,找到 "a" 的两度邻居中,满足一定 "age" 属性条件的人:
g.V().as("a").out().as("b").out().as("c")
.where("c", P.lt("a").or(P.gt("a").and(P.gt("b")))).by("age")
像where() 中这样复杂的嵌套条件过滤并不直观,对用户使用来说不太友好。
D4: GAIA 中没有很好的 Gremlin 语法规范定义,也很难界定当前系统对 Gremlin 算子及算子组合的支持范围,对用户来说并不友好。
解决方案为了解决以上的问题,我们进一步提出了与查询语言无关、普适性更强的中间表示层 GAIA-IR(简称 IR),用来描述通用的图查询语义。我们抽象出的操作算子可以分为两类:关系型操作算子及图相关操作算子。其中,关系型操作算子主要与传统关系型数据库上的操作保持一致,如 Projection、 Selection、 GroupBy、 OrderBy 等;而图相关操作算子则是图数据上的特有查询,如点查询、邻点(边)查询等等。通过这层查询语言无关的中间表示层,我们可以解决上述 GAIA 中存在的问题:
A1: GAIA-IR 层用统一中间表示来实现 Gremlin 算子中类似的表达。例如,我们抽象出 project 算子,用于统一表示上述 D1 中 Gremlin 各种取属性操作。
A2: GAIA-IR 层与查询语言无关,这就方便了 GAIA-IR 后续可以进一步接入更多的语言。将来,我们只需要将不同语言的操作算子翻译到 IR 的统一中间表示层,就可以自然地实现该语言的并行化查询,而不需要再针对每套语言去设计分布式并行化实现。
A3: GAIA-IR 还额外提供了丰富的 expression 支持,从而满足用户的需求。例如,对比 D3 中的例子,我们在 where() 算子中加入 expression 的表达支持会更加直观:
g.V().as("a").out().as("b").out().as("c")
.where(expr("@c.age < @a.age || (@c.age > @a.age && @c.age > @b.age)"))
A4: GAIA-IR 中引入了 Antlr 工具,支持 Gremlin 语法检查功能,并且明确了系统对 Gremlin 算子及组合的支持范围,对用户使用更为友好。
IR整体设计接下来,我们介绍 GAIA-IR 的整体设计。
概念介绍首先,我们介绍 IR 中的一些基本概念。IR 抽象了图数据上的基本计算,从而提供了一套统一的、简洁的、语言无关的中间表示层。
操作算子(IR Operator):目前,我们将操作算子(Graph-Relational Algebra)抽象为两类,即关系型操作和图相关操作。
- 关系型操作包含了:
Projection、Selection、Join、Groupby、Orderby、Dedup、Limit等。这与传统关系型数据库上的操作保持一致。 - 图相关操作包含了:GetV、 E(dge)-Join、 P(ath)-Join,分别表示图上的取点属性操作、取邻点(边)操作、以及路径操作。
通过以上两类算子抽象,我们既可以表达传统的关系型运算,又可以支持图上特有的查询操作。同时,该抽象算子集合并不受查询语言的限制,由此可以很容易地拓展到其他语言。
数据结构(GRecord):我们定义了数据结构 GRecord,用来表示每个 IR Operator 的输入输出。GRecord 是一个多列的结构,每列有自己的别名(Alias)和值(Value):
- 别名(Alias):类似于SQL中的
As别名。特别的,为了适配 Gremlin,我们额外提供了一个 Unique Alias -- "HEAD",作为匿名别名,特指上一个算子的输出,即当前算子的输入。 - 值(Value):值的类型分为两种,简单类型 CommonObject(包括 int/string/intArray/stringArray 等)以及图数据类型 GraphObject(包括 Vertex、Edge 以及 Path)。
在 Gremlin 查询中,我们将其翻译成 GRecord 上的一系列 IR Operator 操作,从而支持 Gremlin 的查询语义。例如,在查询 g.V().as('a').select('a').by(valueMap('name', 'age')) 中,g.V().as('a') 会产生如下的中间结果,别名叫做 "a",数据类型为 Vertex 类型:
而我们会将 select('a').by(valueMap('name', 'age')) 翻译为 Project("{a.name,a.age}"),以上述的 GR1、GR2 作为 Project 的输入,我们可以得到输出 GR1'、GR2',即我们所需要的点属性:
类似的,对于 Gremlin 查询 g.V().valueMap('name','age'),我们只需将 GR1、GR2 的 Alias 变为匿名的 "HEAD",并将 valueMap('name','age') 翻译为 Project("{HEAD.name,HEAD.age}"),便可以得到同样的结果。由此,我们就能够将同一语义、不同表达的 Gremlin 算子,翻译成统一的中间表示。更甚,对于其他语言,例如 SQL 中的取属性操作,我们也可以很直观的翻译成 IR 中的 Project 算子。由此可见,IR 是抽象出了一套更为简洁通用、且与查询语言无关的中间表示层。
接下来,我们给出 GAIA-IR 目前对 Gremlin 的并行化计算架构,如下图所示。
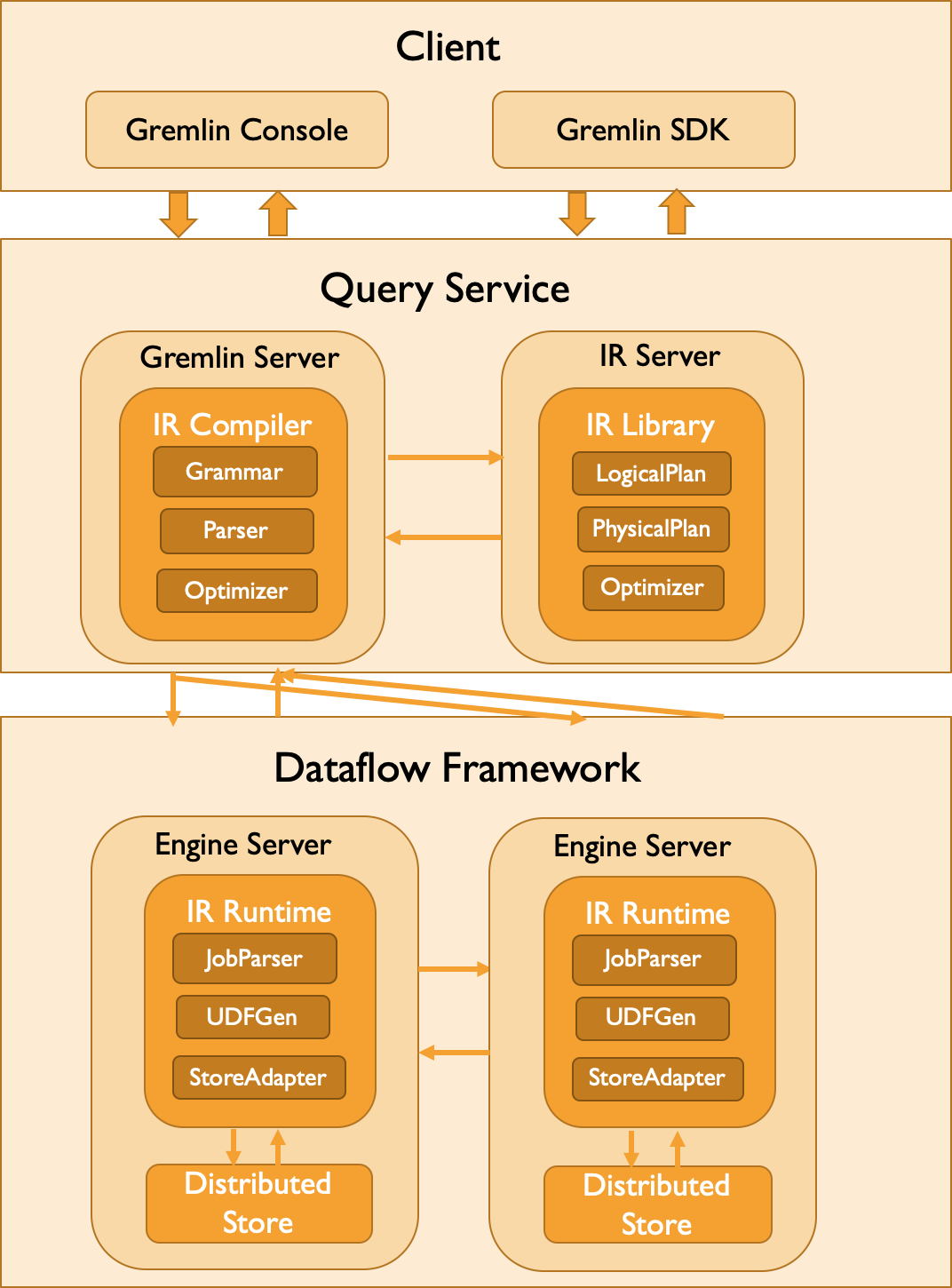
总体来说,我们兼容了官方的 Gremlin Console 以及 Gremlin SDK 的查询方式。在用户提交 Gremlin Query 后:
- IR Compiler 负责对 Query 进行语法检查。对于合法 Query,IR Compiler 通过 IR Library API 对查询语法树进行编译,转换成由 IR Operator 组成的 Logical Plan,并进一步调用 IR Library API 生成 Physical Plan,再将 Physical Plan 分发到分布式的 Dataflow 计算框架。
- Dataflow 框架会在服务拉起阶段预先拉起图数据分区,建立执行计算的线程池。在接收到 IR Compiler 分发过来的物理执行计划后,IR Runtime 负责解析 Physical Plan,并构建引擎可执行的 Execution Plan。同时对于每个 IR Operator,IR Runtime 负责生成其对应的引擎可理解的 UDF,从而实现具体 IR Operator 的计算语义。完成计算后,IR Runtime 将结果返回给 IR Compiler,由 IR Compiler 进一步解析并返回给客户端。
在介绍完 GAIA-IR 的整体设计后,我们介绍如何使用 GAIA-IR 引擎进行查询。
服务部署:在 GraphScope之前的文章中,我们介绍了如何部署 GraphScope。GAIA-IR 作为 GraphScope 中 GIE 的重要实现,整体的拉起方式与 GraphScope 保持一致。我们以 Helm 部署 GraphScope 为例,只需要在安装过程中,指定引擎选项为 GAIA,便可以顺利拉起 GAIA-IR,安装命令示例如下:
helm repo add graphscope https://graphscope.oss-cn-beijing.aliyuncs.com/charts/ helm install [RELEASE_NAME] --set executor=gaia graphscope/graphscope-store
更多详细的部署操作可以参考官方文档[7]。
Gremlin 查询:在成功拉起服务后,我们可以通过 Gremlin Server host 和 port 来进行查询。以 Gremlin Console 查询为例,在服务顺利拉起并且导入数据(具体数据导入步骤可参考官方文档[8])之后,我们便可以通过配置 Gremlin Console 来进行查询。示例如下:
- 首先我们修改 Gremlin Console 的
conf/remote.yaml配置文件,修改对应的 host 和 port; - 打开 Gremlin Console,给定
remote.yaml的配置,便可以开始查询:
gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Configured localhost/127.0.0.1:8182
gremlin> :remote console
==>All scripts will now be sent to Gremlin Server - [localhost/127.0.0.1:8182] - type ':remote console' to return to local mode
gremlin> g.V().valueMap('name','age')
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
结语
本文简述了 GAIA-IR 的设计初衷和总体架构,以及如何使用 GAIA-IR 引擎进行查询。在 GAIA-IR 的目录[9]可以找到 GitHub 上的当前发布版本。GAIA-IR 作为 GraphScope 的图查询引擎,提供高效的 Gremlin 并行化查询实现。同时,在 IR 的统一中间表示上,我们也会引入更多的等价变换、优化实现,支持例如 Pattern Match 等重要场景。在后续的文章中,我们也会介绍更多的技术细节。我们也将持续完善 GAIA-IR 的实现,同时非常欢迎与期待社区的反馈和贡献。
参考资料[1]Gremlin: http://tinkerpop.apache.org/
[2]Neo4j: https://neo4j.com/
[3]OrientDB: https://www.orientdb.org/
[4]JanusGraph: https://janusgraph.org/
[5]Microsoft Cosmos DB: https://azure.microsoft.com/en-us/services/cosmos-db/
[6]Amazon Neptune: https://aws.amazon.com/neptune/
[7]官方文档: https://graphscope.io/docs/persistent_graph_store.html
[8]官方文档: https://graphscope.io/docs/persistent_graph_store.html
[9]GAIA-IR 的目录: https://github.com/alibaba/GraphScope/tree/main/research/query_service/ir