- [翻译] 使用 TensorFlow 进行分布式训练
- 0x00 摘要
- 1. 概述
- 2. 策略类型
- 2.1 MirroredStrategy
- 2.2 TPUStrategy
- 2.3 MultiWorkerMirroredStrategy
- 2.4 CentralStorageStrategy
- 2.5 ParameterServerStrategy
- 2.6 其他策略
- 2.6.1 默认策略
- 2.6.2 OneDeviceStrategy
- 3. 在tf.keras.Model.fit 中使用
- 4. 在自定义训练循环中使用
- 5. 其他主题
- 5.1 设置 TF_CONFIG 环境变量
- 0xFF 参考
本文以下面两篇官方文档为基础来学习TensorFlow 如何进行分布式训练:
https://tensorflow.google.cn/guide/distributed_training(此文的信息是2.3版本之前)。
https://github.com/tensorflow/docs-l10n/blob/master/site/en-snapshot/guide/distributed_training.ipynb (此文是官方最近更新)。
本系列其他文章是:
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(5) --- Session
[源码解析] TensorFlow 分布式环境(7) --- Worker 动态逻辑
[源码解析] TensorFlow 分布式环境(8) --- 通信机制
1. 概述Tf.distribute.Strategy 是一个可在多个 GPU、多台机器或 TPU 上进行分布式训练的 TensorFlow API。使用此 API,您只需改动较少代码就能基于现有模型和训练代码来实现单机多卡,多机多卡等情况的分布式训练。
tf.distribute.Strategy 旨在实现以下目标:
- 覆盖不同维度的用户用例。
- 易于使用,支持多种用户(包括研究人员和 ML 工程师等)。
- 提供开箱即用的高性能。
- 从用户模型代码之中解耦,这样可以轻松切换策略。
- 支持 Custom Training Loop,Estimator,Keras。
- 支持 eager excution。
Tf.distribute.Strategy 可用于 Keras,Model.fit等高级 API,也可用来分布自定义训练循环(以及(一般来说)使用 TensorFlow 的任何计算)。比如将模型进行构建和 model.compile() 调用封装在 strategy.scope() 内部。
在 TensorFlow 2.x 中,您可以立即执行程序,也可以使用 tf.function在计算图中执行。虽然 tf.distribute.Strategy 对两种执行模式都支持,但使用 tf.function 效果最佳。建议仅将 Eager 模式用于调试,而 tf.distribute.TPUStrategy 支持此模式。尽管本指南大部分时间在讨论训练,但该 API 也可用于在不同平台上分布评估和预测。
您在使用 tf.distribute.Strategy 只需改动少量代码,因为我们修改了 TensorFlow 的底层组件,使其可感知策略。这些组件包括变量、层、模型、优化器、指标、摘要和检查点。
在本指南中,我们将介绍各种类型的策略,以及如何在不同情况下使用它们。
2. 策略类型Tf.distribute.Strategy 打算涵盖不同轴上的许多用例。目前已支持其中的部分组合,将来还会添加其他组合。其中一些轴包括:
- 同步和异步训练:这是通过数据并行进行分布式训练的两种常用方法。在同步训练中,所有工作进程都同步地对输入数据的不同片段进行训练,并且会在每一步中聚合梯度。在异步训练中,所有工作进程都独立训练输入数据并异步更新变量。通常情况下,同步训练通过全归约(all-reduce)实现,而异步训练通过参数服务器架构实现。
- 硬件平台:您可能需要将训练扩展到一台机器上的多个 GPU 或一个网络中的多台机器(每台机器拥有 0 个或多个 GPU),或扩展到 Cloud TPU 上。
要支持这些用例,有 MirroredStrategy, TPUStrategy, MultiWorkerMirroredStrategy, ParameterServerStrategy, CentralStorageStrategy 这六种策略可选。在下一部分,我们将说明当前在哪些场景中支持哪些策略。以下为快速概览:

注:实验性支持指不保证该 API 的兼容性。
注: 对 Estimator 的支持是有限的。其基本训练和评估是实验性的,高级功能(比如 scaffold)并没有实现。如果一个用例没有被涵盖,您应该使用 Keras 或自定义训练循环。不建议将 Estimator 用于新代码,因为 Estimato r的代码风格属于 "v1.Session",这很难正确编写,而且可能会出现意想不到的行为,特别是当与 TF 2 代码结合时。
2.1 MirroredStrategyTf.distribute.MirroredStrategy 支持在一台机器的多个 GPU 上进行同步分布式训练(单机多卡数据并行)。该策略会为每个 GPU 设备创建一个模型副本。模型中的每个变量都会在所有副本之间进行镜像。这些变量将共同形成一个名为 MirroredVariable 的概念上的单个变量。通过应用相同的更新,这些变量保持彼此保持同步。
MirroredVariable 的同步更新只是提高了计算速度,但并不能像 CPU 并行那样可以把内存之中的变量共享。即,显卡并行计算只是提高速度,并不会让用户数据量翻倍。增加数据仍然会抛出来内存溢出错误。
MirroredStrategy 使用高效的全归约(all-reduce)算法在设备之间传递变量更新。全归约(all-reduce)算法通过把各个设备上的张量加起来使其聚合,并使其在每个设备上可用。这是一种非常高效的融合算法,可以显著减少同步开销。根据设备之间可用的通信类型,可以使用的全归约(all-reduce)算法和实现方法有很多。默认使用 NVIDIA NCCL 作为全归约(all-reduce)实现。您可以选择我们提供的其他选项,也可以自己编写。
具体如下:
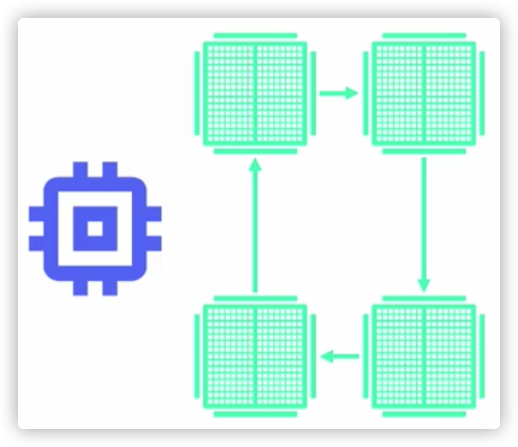
图 1 MirroredStrategy 来自 TensorFlow
以下是创建 MirroredStrategy 最简单的方法:
mirrored_strategy = tf.distribute.MirroredStrategy()
这会创建一个 MirroredStrategy 实例,该实例使用所有对 TensorFlow 可见的 GPU,并使用 NCCL 进行跨设备通信。如果您只想使用机器上的部分 GPU,您可以这样做:
mirrored_strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
如果您想重写跨设备通信,可以通过使用 cross_device_ops 参数来提供 tf.distribute.CrossDeviceOps 的实例。
目前,除了默认选项 tf.distribute.NcclAllReduce 外,还有 tf.distribute.HierarchicalCopyAllReduce 和 tf.distribute.ReductionToOneDevice两个选项。
mirrored_strategy = tf.distribute.MirroredStrategy(
cross_device_ops=tf.distribute.HierarchicalCopyAllReduce())
您可以使用tf.distribute.experimental.TPUStrategy在张量处理单元 (TPU) 上运行 TensorFlow 训练。TPU 是 Google 的专用 ASIC,旨在显著加速机器学习工作负载。您可通过 Google Colab、TensorFlow Research Cloud 和 Cloud TPU 平台进行使用。
就分布式训练架构而言,TPUStrategy 和 MirroredStrategy 是一样的,即实现同步分布式训练。TPU 会在多个 TPU 核心之间实现高效的全归约(all-reduce)和其他集合运算,并将其用于 TPUStrategy。
下面演示了如何将 TPUStrategy 实例化:
cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver( tpu=tpu_address) tf.config.experimental_connect_to_cluster(cluster_resolver) tf.tpu.experimental.initialize_tpu_system(cluster_resolver) tpu_strategy = tf.distribute.experimental.TPUStrategy(cluster_resolver)
TPUClusterResolver 实例可帮助定位 TPU。在 Colab 中,您无需为其指定任何参数。
如果要将其用于 Cloud TPU,您必须:
- 在 tpu 参数中指定 TPU 资源的名称。
- 在程序开始时显式地初始化 TPU 系统。这是使用 TPU 进行计算前的必须步骤。初始化 TPU 系统还会清除 TPU 内存,所以为了避免丢失状态,请务必先完成此步骤。
Tf.distribute.experimental.MultiWorkerMirroredStrategy与 MirroredStrategy 非常相似。它实现了跨多个工作进程的同步分布式训练(多机多卡分布式版本),而每个工作进程可能有多个 GPU。与 MirroredStrategy 类似,它也会跨所有工作进程在每个设备的模型中创建所有变量的副本。
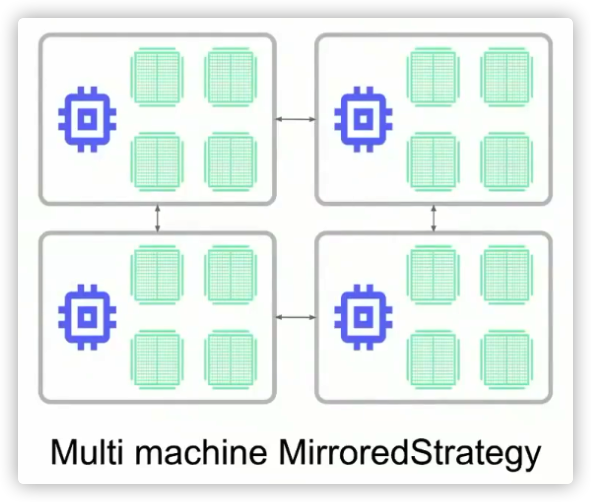
图 2 MultiWorkerMirroredStrategy 来自 TensorFlow
它使用 CollectiveOps 作为多工作进程全归约(all-reduce)通信方法,用于保持变量同步。集合运算是 TensorFlow 计算图中的单个运算,它可以根据硬件、网络拓扑和张量大小在 TensorFlow 运行期间自动选择全归约(all-reduce)算法。
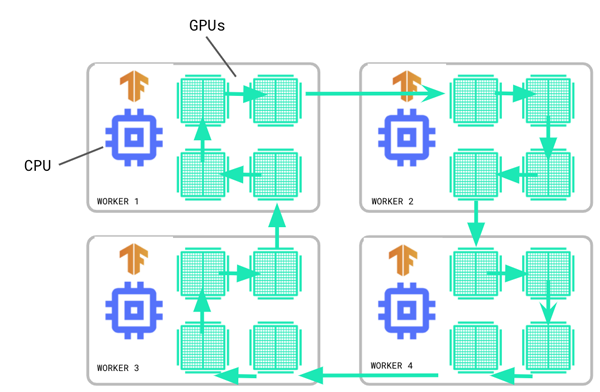
图 3 MultiWorkerMirroredStrategy 数据流. 来自 TensorFlow
它还实现了其他性能优化。例如,静态优化,可以将小张量上的多个全归约(all-reduce)转化为大张量上较少的全归约(all-reduce)。此外,我们还在为它设计插件架构,这样您将来就能以插件的形式使用针对您的硬件进行了更好优化的算法。
以下是创建 MultiWorkerMirroredStrategy 最简单的方法:
multiworker_strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
MultiWorkerMirroredStrategy 目前为您提供两种不同的集合运算实现方法。CollectiveCommunication.RING通过将 RPC 用作通信层来实现基于环的集合,支持CPU和GPU。CollectiveCommunication.NCCL 使用 NCCL 来实现集合。CollectiveCommunication.AUTO 会将选择推迟到运行时。集合实现的最佳选择取决于 GPU 的数量和种类,以及集群中的网络互连。您可以通过以下方式来指定:
communication_options = tf.distribute.experimental.CommunicationOptions(
implementation=tf.distribute.experimental.CommunicationImplementation.NCCL)
strategy = tf.distribute.MultiWorkerMirroredStrategy(
communication_options=communication_options)
或者
if distribution_strategy == "multi_worker_mirrored":
return tf.distribute.experimental.MultiWorkerMirroredStrategy(
communication=_collective_communication(all_reduce_alg))
具体如下:
def _collective_communication(all_reduce_alg):
"""Return a CollectiveCommunication based on all_reduce_alg.
Args:
all_reduce_alg: a string specifying which collective communication to pick,
or None.
Returns:
tf.distribute.experimental.CollectiveCommunication object
Raises:
ValueError: if all_reduce_alg not in [None, "ring", "nccl"]
"""
collective_communication_options = {
None: tf.distribute.experimental.CollectiveCommunication.AUTO,
"ring": tf.distribute.experimental.CollectiveCommunication.RING,
"nccl": tf.distribute.experimental.CollectiveCommunication.NCCL
}
if all_reduce_alg not in collective_communication_options:
raise ValueError(
"When used with multi_worker_mirrored, valid values for "
"all_reduce_alg are [ring, nccl]. Supplied value: {}".format(
all_reduce_alg))
return collective_communication_options[all_reduce_alg]
与多 GPU 训练相比,多工作进程训练的一个主要差异是多工作进程的设置。TF_CONFIG 环境变量是在 TensorFlow 中为作为集群一部分的每个工作进程指定集群配置的标准方法。
2.4 CentralStorageStrategytf.distribute.experimental.CentralStorageStrategy也执行同步训练。变量不会被镜像,而是统一放在 CPU 上,模型和运算会复制到所有本地 GPU(这属于 in-graph 复制,就是一个计算图覆盖了多个模型副本)。如果只有一个 GPU,则所有变量和运算都将被放在该 GPU 上。这样可以处理 embedding 无法放置在一个 GPU 之上的情况。比如下图是:单机多个 GPU。

图 4 CentralStorageStrategy. 来自 TensorFlow
可以通过以下代码,创建 CentralStorageStrategy 实例:
central_storage_strategy = tf.distribute.experimental.CentralStorageStrategy()
这会创建一个 CentralStorageStrategy 实例,该实例将使用所有可见的 GPU 和 CPU。在副本上对变量的更新将先进行聚合,然后再应用于变量。
注:此策略处于 experimental 阶段,我们目前正在进行改进,使其能够用于更多场景。敬请期待 API 的未来变化。 CentralStorageStrategy 优点是 GPU 负载比较均衡,但是 CPU 和 GPU 通信代价会比较大。
2.5 ParameterServerStrategy参数服务器训练是一种常见的数据并行方法,可以在多台机器上扩展训练。一个参数服务器训练集群由工作者和参数服务器组成。在训练过程之中使用参数服务器来统一创建/管理变量(模型每个变量都被放在参数服务器上),变量在每个步骤中被工作者读取和更新。计算则会被复制到所有工作进程的所有 GPU 中(注:该 V1 版本策略仅适用于 Estimator API)。
在 TensorFlow 2 中,参数服务器训练使用了一个基于中央协调者(central coordinator-based)的架构,这通过tf.distribute.experimental.coordinator.ClusterCoordinator类来完成。
TensorFlow 2 参数服务器使用异步方式来更新,即,会在各工作节点上独立进行变量的读取和更新,无需采取任何同步操作。因为工作节点彼此互不依赖,因此该策略可以对工作者进行容错处理,这样会在使用抢占式服务器时有所助益。
在这个实现中,工作者和参数服务器运行 tf.distribution.Servers 来听取协调者的任务。协调器负责创建资源,分配训练任务,写检查点,并处理任务失败的情况。
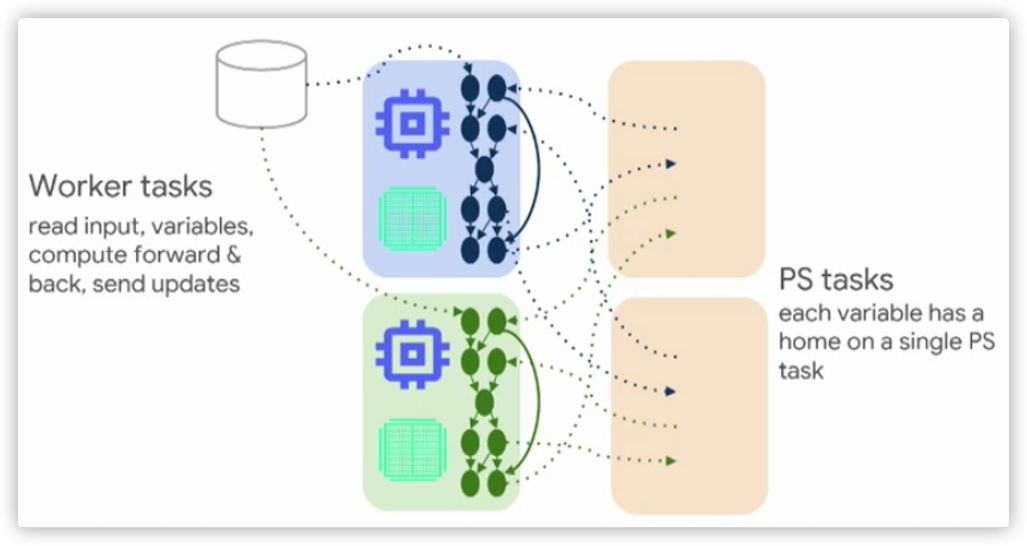
图 5 ParameterServerStrategy. 来自 TensorFlow
如果要在协调器上运行,您需要使用 ParameterServerStrategy 对象来定义训练步骤,并使用 ClusterCoordinator 将训练步骤分派给远程工作者。下面是创建它们的最简单方法。
strategy = tf.distribute.experimental.ParameterServerStrategy(
tf.distribute.cluster_resolver.TFConfigClusterResolver(),
variable_partitioner=variable_partitioner)
coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(
strategy)
注:如果您使用TFConfigClusterResolver,您将需要配置 TF_CONFIG 环境变量。它类似于MultiWorkerMirroredStrategy 中的'TF_CONFIG',但有额外的注意事项。在TensorFlow 1 中,ParameterServerStrategy 只能通过tf.compat.v1.distribution.experimental.ParameterServerStrategy 符号与 Estimator一起使用。
注:这个策略是实验性的,它目前正在积极开发中。
2.6 其他策略除上述策略外,还有其他两种策略可能对使用 tf.distribute API 进行原型设计和调试有所帮助。
2.6.1 默认策略默认策略(Default Strategy)是一种分布式策略,当作用域内没有显式指定分布策略时就会使用此策略。此策略会实现 tf.distribute.Strategy 接口,但只具有传递(pass-through)功能,不提供实际分布(distribution)。例如,strategy.run(fn) 只会调用 fn。使用该策略编写的代码与未使用任何策略编写的代码完全一样。您可以将其视为 “无运算 no-op” 策略。
默认策略是一种单一实例,无法创建它的更多实例。可通过在任意显式策略的作用域(与可用于在显式策略的作用域内获得当前策略的 API 相同)外使用 tf.distribute.get_strategy() 获得该策略。
default_strategy = tf.distribute.get_strategy()
该策略有两个主要用途:
- 它允许无条件编写可感知分布的库代码。例如,在优化器中,我们可以执行 tf.distribute.get_strategy() 并使用该策略来规约梯度,而它将始终返回一个我们可以在其上调用 Strategy.reduce API 的策略对象。
# In optimizer or other library code
# Get currently active strategy
strategy = tf.distribute.get_strategy()
strategy.reduce("SUM", 1.) # reduce some values
- 与库代码类似,它可以使用户程序在使用或不使用分布策略的情况下都能工作,而无需条件逻辑。以下示例代码段展示了这一点:
if tf.config.list_physical_devices('gpu'):
strategy = tf.distribute.MirroredStrategy()
else: # use default strategy
strategy = tf.distribute.get_strategy()
with strategy.scope():
# do something interesting
print(tf.Variable(1.))
Tf.distribute.OneDeviceStrategy 是一种会将所有变量和计算放在单个指定设备上的策略。
strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0")
此策略与默认策略在诸多方面存在差异。在默认策略中,与没有任何分布策略的 TensorFlow 运行相比,变量放置逻辑保持不变。但是当使用 OneDeviceStrategy 时,在其作用域内创建的所有变量都会被显式地放在指定设备上。此外,通过 OneDeviceStrategy.run 调用的任何函数也会被放在指定设备上。
通过该策略分布的输入将被预提取到指定设备。而在默认策略中,则没有输入分布。与默认策略类似,在切换到实际分布到多个设备/机器的其他策略之前,也可以使用此策略来测试代码。这将比默认策略更多地使用分布策略机制,但不能像使用 MirroredStrategy 或 TPUStrategy 等策略那样充分发挥其作用。如果您想让代码表现地像没有策略,请使用默认策略。
目前为止,我们已经讨论了可用的不同策略以及如何将其实例化。在接下来的几个部分中,我们将讨论使用它们分布训练的不同方法。我们将在本指南中展示简短的代码段,并附上可以从头到尾运行的完整教程的链接。
3. 在tf.keras.Model.fit 中使用我们已将 tf.distribute.Strategy 集成到 tf.keras。tf.keras 是用于构建和训练模型的高级 API。将该策略集成到 tf.keras 后端以后,您可以使用 model.fit 在 Keras 训练框架中无缝进行分布式训练。您需要对代码进行以下更改:
- 创建一个合适的 tf.distribute.Strategy 实例。
- 将 Keras 模型、优化器和指标的创建转移到 strategy.scope 中。
我们支持所有类型的 Keras 模型:Sequential, Functional, 以及 subclassed。下面是一段代码,执行该代码会创建一个非常简单的带有一个 Dense 层的 Keras 模型:
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])
model.compile(loss='mse', optimizer='sgd')
在此示例中我们使用了 MirroredStrategy,因此我们可以在有多个 GPU 的机器上运行。strategy.scope() 会指示 Keras 使用哪个策略来进行分布式训练。我们可以通过在此作用域内创建模型/优化器/指标来创建分布式变量而非常规变量。设置完成后,您就可以像平常一样拟合模型。MirroredStrategy 负责将模型的训练复制到可用的 GPU 上,以及聚合梯度等。
dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100).batch(10)
model.fit(dataset, epochs=2)
model.evaluate(dataset)
我们在这里使用了 tf.data.Dataset 来提供训练和评估输入。您还可以使用 Numpy 数组:
import numpy as np
inputs, targets = np.ones((100, 1)), np.ones((100, 1))
model.fit(inputs, targets, epochs=2, batch_size=10)
在上述两种情况(Dataset 或 Numpy)中,给定输入的每个批次都被平均分到了多个副本中。例如,如果对 2 个 GPU 使用 MirroredStrategy,大小为 10 的每个批次将被均分到 2 个 GPU 中,每个 GPU 每步会接收 5 个输入样本。如果添加更多 GPU,每个周期的训练速度就会更快。在添加更多加速器时通常需要增加批次大小,以便有效利用额外的计算能力。您还需要根据模型重新调整学习率。您可以使用 strategy.num_replicas_in_sync 获得副本数量。
# Compute global batch size using number of replicas.
BATCH_SIZE_PER_REPLICA = 5
global_batch_size = (BATCH_SIZE_PER_REPLICA *
mirrored_strategy.num_replicas_in_sync)
dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100)
dataset = dataset.batch(global_batch_size)
LEARNING_RATES_BY_BATCH_SIZE = {5: 0.1, 10: 0.15}
learning_rate = LEARNING_RATES_BY_BATCH_SIZE[global_batch_size]
目前支持的策略如下:

如您所见,在 Keras model.fit 中使用 tf.distribute.Strategy 只需改动几行代码。再多花点功夫,您还可以在自定义训练循环中使用 tf.distribute.Strategy。
如果您需要更多使用 Estimator 或 Keras 时的灵活性和对训练循环的控制权,您可以编写自定义训练循环。例如,在使用 GAN 时,您可能会希望每轮使用不同数量的生成器或判别器步骤。同样,高层框架也不太适合强化学习训练。为了支持自定义训练循环,我们通过 tf.distribute.Strategy 类提供了一组核心方法。使用这些方法可能需要在开始时对代码进行轻微重构,但完成重构后,您只需更改策略实例就能够在 GPU、TPU 和多台机器之间进行切换。
下面我们将用一个简短的代码段说明此用例,其中的简单训练样本使用与之前相同的 Keras 模型。首先,在该策略的作用域内创建模型和优化器。这样可以确保使用此模型和优化器创建的任何变量都是镜像变量。
with mirrored_strategy.scope():
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])
optimizer = tf.keras.optimizers.SGD()
接下来,我们创建输入数据集并调用 tf.distribute.Strategy.experimental_distribute_dataset 以根据策略来分布数据集。
dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100).batch(
global_batch_size)
dist_dataset = mirrored_strategy.experimental_distribute_dataset(dataset)
然后,我们定义一个训练步骤。我们将使用 tf.GradientTape 来计算梯度,并使用优化器来应用这些梯度以更新模型变量。要分布此训练步骤,我们加入一个 train_step 函数,并将此函数和从之前创建的 dist_dataset 获得的数据集输入一起传递给 tf.distrbute.Strategy.run:
loss_object = tf.keras.losses.BinaryCrossentropy(
from_logits=True,
reduction=tf.keras.losses.Reduction.NONE)
def compute_loss(labels, predictions):
per_example_loss = loss_object(labels, predictions)
return tf.nn.compute_average_loss(per_example_loss, global_batch_size=global_batch_size)
def train_step(inputs):
features, labels = inputs
with tf.GradientTape() as tape:
predictions = model(features, training=True)
loss = compute_loss(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
@tf.function
def distributed_train_step(dist_inputs):
per_replica_losses = mirrored_strategy.run(train_step, args=(dist_inputs,))
return mirrored_strategy.reduce(tf.distribute.ReduceOp.SUM, per_replica_losses,
axis=None)
以上代码还需注意以下几点:
- 我们使用了 tf.nn.compute_average_loss 来计算损失。tf.nn.compute_average_loss 将每个样本的损失相加,然后将总和除以 global_batch_size。这很重要,因为稍后在每个副本上计算出梯度后,会通过对它们求和使其跨副本进行聚合。
- 我们使用了 tf.distribute.Strategy.reduceAPI 来聚合 tf.distribute.Strategy.run 返回的结果。tf.distribute.Strategy.run 会从策略中的每个本地副本返回结果。目前有多种方法使用该结果,比如可以 reduce 它们以获得聚合值。还可以通过执行 tf.distribute.Strategy.experimental_local_results 获得包含在结果中的值的列表,每个本地副本一个列表。
- 当在一个分布策略作用域内调用 apply_gradients 时,它的行为会被修改。具体来说,在同步训练期间,在将梯度应用于每个并行实例之前,它会对梯度的所有副本求和(sum-over-all-replicas)。
最后,当我们定义完训练步骤后,就可以迭代 dist_dataset,并在循环中运行训练:
for dist_inputs in dist_dataset:
print(distributed_train_step(dist_inputs))
在上面的示例中,我们通过迭代 dist_dataset 为训练提供输入。我们还提供 tf.distribute.Strategy.make_experimental_numpy_dataset 以支持 Numpy 输入。您可以在调用 tf.distribute.Strategy.experimental_distribute_dataset 之前使用此 API 来创建数据集。
迭代数据的另一种方法是显式地使用迭代器。当您希望运行给定数量的步骤而非迭代整个数据集时,可能会用到此方法。现在可以将上面的迭代修改为:先创建迭代器,然后在迭代器上显式地调用 next 以获得输入数据。
iterator = iter(dist_dataset)
for _ in range(10):
print(distributed_train_step(next(iterator)))
上面是使用 tf.distribute.StrategyAPI 来分布自定义训练循环(custom training loops)最简单的情况。

在此部分,我们将介绍与多个用例相关的主题。
5.1 设置 TF_CONFIG 环境变量对于多工作进程训练来说,如前所述,您需要为每个在集群中运行的二进制文件设置 TF_CONFIG 环境变量。TF_CONFIG 环境变量是一个 JSON 字符串,它指定了构成集群的任务、它们的地址,以及每个任务在集群中的角色。我们在 tensorflow/ecosystem 仓库中提供了一个 Kubernetes 模板,可为您的训练任务设置 TF_CONFIG。
TF_CONFIG 有两个组件:cluster 和 task。
- cluster 会提供有关训练集群的信息,这是一个由不同类型的作业(如工作进程)组成的字典。在多工作进程训练中,通常会有一个工作进程除了要完成常规工作进程的工作之外,还要承担更多责任,如保存检查点和为 TensorBoard 编写摘要文件。此类工作进程称为 "chief" 工作进程,习惯上会将索引为 0 的工作进程指定为 chief 工作进程(实际上这是 tf.distribute.Strategy 的实现方式)。
- 另一方面,task 会提供有关当前任务的信息。第一个组件 cluster 对于所有工作进程都相同,而第二个组件 task 在每个工作进程上均不相同,并指定了该工作进程的类型和索引。
TF_CONFIG 的示例如下:
os.environ["TF_CONFIG"] = json.dumps({
"cluster": {
"worker": ["host1:port", "host2:port", "host3:port"],
"ps": ["host4:port", "host5:port"]
},
"task": {"type": "worker", "index": 1}
})
此 TF_CONFIG 指定了集群中包含三个工作进程和两个 ps 任务,以及它们的主机和端口。"task" 部分指定当前任务在集群中的角色,即 worker 1(第二个工作进程)。集群中的有效角色是 "chief"、"worker"、"ps" 和 "evaluator"。除使用 tf.distribute.experimental.ParameterServerStrategy 时外,不应有 "ps" 作业。
0xFF 参考使用 TensorFlow 进行分布式训练
https://github.com/tensorflow/docs-l10n/blob/master/site/en-snapshot/guide/distributed_training.ipynb
Tensorflow上手4: 初探分布式训练