因无向、无加权图的任意顶点之间的最短路径由顶点之间的边数决定,可以直接使用原始定义的广度优先搜索算法查找。
但是,无论是有向、还是无向,只要是加权图,最短路径长度的定义是:起点到终点之间所有路径中权重总和最小的那条路径。
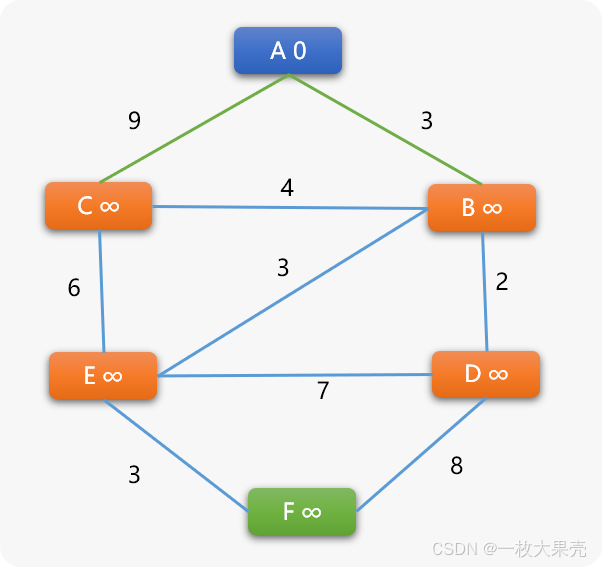
如下图所示,A 到 C 的最短路径并不是 A 直接到 C(权重是 9),而是 A 到 B 再到 C(权重是 7)。所以,需要在广度优先搜索算法的基础上进行算法升级后才能查找到。
加权图的常用最短路径查找算法有:
- 贝尔曼-福特(Bellman-Ford)算法
- Dijkstra(迪杰斯特拉) 算法
A*算法D*算法
Bellman-Ford)算法
贝尔曼-福特算法取自于创始人理查德.贝尔曼和莱斯特.福特,本文简称 BF 算法
BF 算法属于迭代、穷举算法,算法效率较低,如果图结构中顶点数量为 n,边数为 m ,则该算法的时间复杂度为 m*n ,还是挺大的。
理论上讲,图结构中边上的权重一般用来描述现实世界中的速度、时间、花费、里程……基本上都是非负数。即使是负数,BF 算法也能工作得较好。
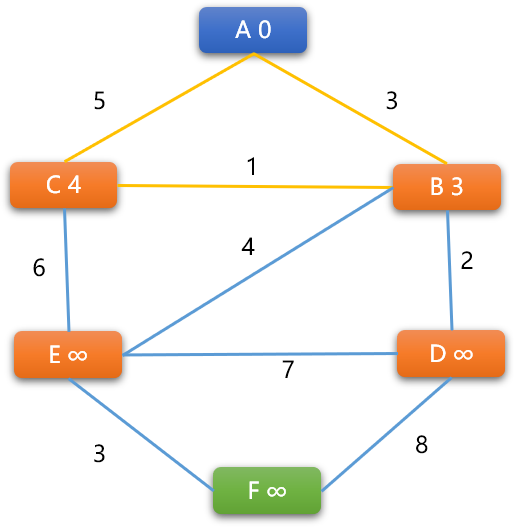
问题:如下图,搜索 A 到其它任意顶点之间的最短路径。
首先给每一个顶点一个权重值(用来存储从起始顶点到此顶点的最短路径上所有边上权重之和),刚开始除了出发点的权重 0 ,因为还不能确定到其它任意顶点的具体路径长度,其它顶点的权重值均初始为无穷大(只要是一个适当值都可以)。
下面的图结构是无向加权图,对于有向加权图同样适用 BF 算法。
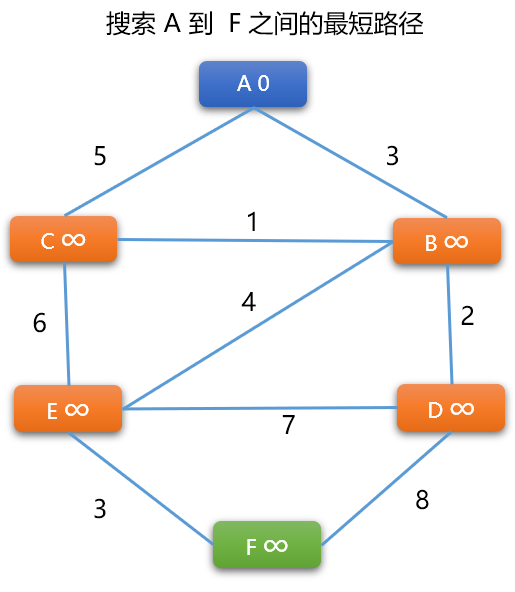
BF 算法流程:
-
更新顶点的权重: 计算任一条边上一端顶点(始点)到另一个端顶点(终点)的权重。新权重=顶点(始点)权重+边的权重,然后使用新权重值更新终点的原来权重值。
-
更新原则: 只有当顶点原来的权重大于新权重时,才更新。
如:先选择
A -> B之间的路径,因为A~B是无向边,需要计算 2 次。如果是有向图,则只计算一个方向。先计算
A -> B的新权重=A的权重+(A,B)边上的权重,新权重=0+3=3。因3小于B顶点现在的权重(无穷大),B的权重被更新为3。再计算
B -> A的新权重=B的权重+(A,B) 边上的权重。新权重=3+3=6。6大于A现有的权重 0,则A顶点不更新。此时,意味着
A -> B的最短路径长度为3。A是B的前序顶点。当然,这绝对不是最后的结论。
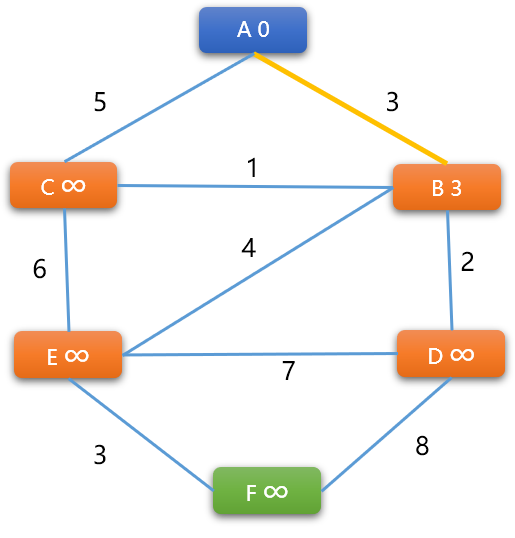
-
对图中每一条边两端的顶点都执行上述同样的操作,对于执行顺序没有特定要求。
如下继续计算
(A,C)边的两端顶点的权重。A -> C的新权重=0+5=5,更新C顶点权重为5。C -> A的新权重=5+5=10不更新。结论:A是C的前序顶点。
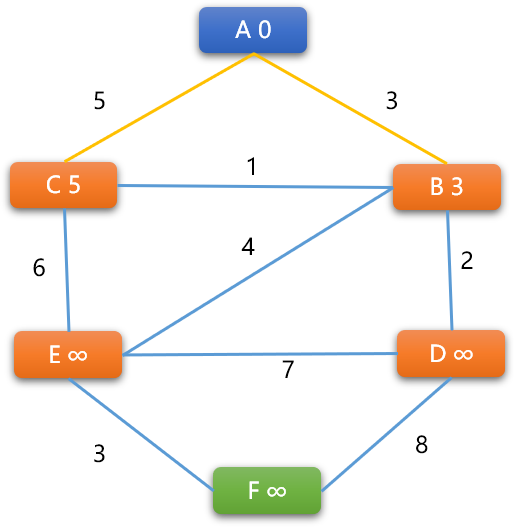
计算 (B,C) 权重:
B -> C 的新权重=3+1=4,小于 C 现有权重 5 ,C 的权重更新为 4,则 B 是 C的前序顶点
C -> B 的新权重= 4+1 =5 ,大于 B 现有权重,不更新。
经过上述操作后 (A,B,C)3 个顶点的前序关系:
A 是 B 的前序、B 是 C 的前序,当前 A -> B 的最短路径是 3,A -> B -> C 的最短路径是 4,但不一定是最后结论。
Tips: 当顶点的权重更新后,也意味着前序顶点也发生了变化。如上述权重更新过程中
C刚开始前序是A,后来又更改成了B。
-
当所有边两端顶点都更新完毕后,需要再重新开始,对图结构中所有边上的顶点权重再进行一次更新,一至到不再引起权重变化时
BF算法才算结束。 -
BF算法的本质还是广度优先搜索算法,附加了更新顶点权重的逻辑。
本文的图结构存储使用链接表。
顶点类: 此类用来描述顶点本身信息,除了有顶点的常规属性,如编号、名称、链接表……外,还需要添加 2 个属性:
-
顶点的权重:初始化时为无穷大。
顶点权重用来保存起始点到此顶点的最短路径长度(边上权重之和)。
-
前序顶点: 在
BF算法中,如果顶点的权重发生了更新,也意味着前序顶点也发生了变化。
初始化方法:
"""
节(顶)点类
"""
import sys
class Vertex:
def __init__(self, v_name, v_id=0):
# 顶点的编号
self.v_id = v_id
# 顶点的名称
self.v_name = v_name
# 是否被访问过:False 没有 True:有
self.visited = False
# 与此顶点相连接的其它顶点
self.connected_to = {}
# 前序顶点
self.preorder_vertex = None
# 权重(初始为无穷大)
self.weight = sys.maxsize
添加相邻顶点方法:
'''
添加邻接顶点
nbr_ver:相邻顶点
weight:无向无权重图,权重默认设置为 1
'''
def add_neighbor(self, nbr_ver, weight=1):
# 字典中以相邻顶点为键,权重为值
self.connected_to[nbr_ver] = weight
'''
判断给定的顶点是不是当前顶点的相邻顶点
'''
def is_neighbor(self, nbr_v):
return nbr_v in self.connected_to
顶点对象以字符串格式输出:
'''
显示与当前顶点相邻的其它顶点
'''
def __str__(self):
return '权重{0}:名称{1}顶点相邻的顶点有:{2}'.format(self.weight, self.v_name,
str([(key.v_name, val) for key, val in self.connected_to.items()]))
顶点权重更新方法:
'''
得到和某一个相邻顶点的权重
'''
def get_weight(self, nbr_v):
return self.connected_to[nbr_v]
'''
计算顶点权重(路径长度)
'''
def cal_bf_weight(self, nbr_v):
# 顶点权重加上顶点间边的权重
new_weight = self.weight + self.get_weight(nbr_v)
if new_weight < nbr_v.weight:
# 计算出来权重小于顶点原来权重,则更新
nbr_v.weight = new_weight
# 设置前序顶点
nbr_v.preorder_vertex = self
return 1
return 0
上述方法为 BF 算法的关键,参数 nbr_v 是指与当前顶点相邻的顶点。先是计算和当前顶点的新权重,根据更新原则进行更新。如果有更新则需要把当前顶点指定为前序顶点。
Tips: 在图结构中,最短路径算法中的前序顶点指到达此顶点最近的顶点。
图类: 此类用来对图中的顶点进行维护,如添加新顶点,维护顶点之间的关系、提供搜索算法……
初始化方法:
class Graph:
def __init__(self):
# 一维列表,保存节点
self.vert_list = {}
# 顶点个数
self.v_nums = 0
# 使用队列模拟队列或栈,用于路径搜索算法
self.queue_stack = []
# 保存已经更新过的边
self.is_update = []
添加新顶点: 新顶点的编号由内部提供,统一管理,保证编号的一致性。
def add_vertex(self, vert):
if vert.v_name in self.vert_list:
# 已经存在
return
# 顶点的编号内部生成
vert.v_id = self.v_nums
# 所有顶点保存在图所维护的字典中,以顶点名为键,顶点对象为值
self.vert_list[vert.v_name] = vert
# 数量增一
self.v_nums += 1
查询顶点:
'''
根据顶点名找到顶点对象
'''
def find_vertex(self, v_name):
if v_name in self.vert_list:
return self.vert_list.get(v_name)
'''
查询所有顶点
'''
def find_vertexes(self):
return [str(ver) for ver in self.vert_list.values()]
添加顶点与顶点之间的关系: 此方法是一个封装方法,本质是调用顶点自身的添加相邻顶点方法。这里用到了递归算法,在 BF 算法中,一轮更新后可能还需要后续多轮更新才能让每一个顶点上的权重不再变化。这也是 BF 算法的缺陷。
'''
添加节点与节点之间的关系(边),
如果是无权重图,统一设定为 1
'''
def add_edge(self, from_v, to_v, weight=1):
# 如果节点不存在
if from_v not in self.vert_list:
self.add_vertex(from_v)
if to_v not in self.vert_list:
self.add_vertex(to_v)
from_v.add_neighbor(to_v, weight)
贝尔曼-福特算法: 图结构中 BF 算法的实现。
'''
贝尔曼-福特算法
'''
def bf_nearest_path(self, from_v):
# 记录边更新次数
update_count = 0
# 设备起始点的权重为 0
from_v.weight = 0
# 起始点压入队列
self.queue_stack.append(from_v)
# 检查队列是否为空
while len(self.queue_stack) != 0:
# 从队列获取顶点
tmp_v = self.queue_stack.pop(0)
# 标记为已经处理
tmp_v.visited = True
# 得到与其相邻顶点
nbr_vs = tmp_v.connected_to.keys()
# 更新与其相邻顶点的权重
for v_ in nbr_vs:
# 把相邻顶点压入队列
self.push_queue(v_)
# 更新权重,并记录更新次数
update_count += tmp_v.cal_bf_weight(v_)
# 无向边,要双向更新
update_count +=v_.cal_bf_weight(tmp_v)
# 更新完毕后,如果更新次数为 0 ,则不用再更新。
if update_count != 0:
self.is_update = []
self.bf_nearest_path(from_v)
'''
把某一顶点的相邻顶点压入队列
这里还是使用广度优先算法思路保存下一个需要搜索的顶点
'''
def push_queue(self, vertex):
# 获取 vertex 顶点的相邻顶点
for v_ in vertex.connected_to.keys():
# 检查此顶点是否压入过
if v_.visited:
continue
self.queue_stack.append(v_)
测试 BF 算法:
if __name__ == '__main__':
# 初始化图
graph = Graph()
# 添加节点
for v_name in ['A', 'B', 'C', 'D', 'E', 'F']:
v = Vertex(v_name)
graph.add_vertex(v)
# 添加顶点之间关系
v_to_v = [('A', 'B', 3), ('A', 'C', 5), ('B', 'C', 1), ('B', 'D', 2), ('B', 'E', 4), ('C', 'E', 6), ('D', 'E', 7),
('D', 'F', 8),
('E', 'F', 3)]
# 无向图每 2 个顶点之间互为关系
for v in v_to_v:
f_v = graph.find_vertex(v[0])
t_v = graph.find_vertex(v[1])
graph.add_edge(f_v, t_v, v[2])
graph.add_edge(t_v, f_v, v[2])
# 输出所有顶点
print('-----------顶点及顶点之间的关系-------------')
for v in graph.find_vertexes():
print(v)
# 查找起始点到任一顶点之间的最短路径长度
f_v = graph.find_vertex('A')
graph.bf_nearest_path(f_v)
print('-----------BF 算法后顶点及顶点之间的关系-------------')
for v in graph.find_vertexes():
print(v)
# 查询从起始点到任意顶点间的最短路径长度
print('----------f_v~t_v 最短路径长度------------')
for name in ['B', 'C', 'D', 'E', 'F']:
t_v = graph.find_vertex(name)
path = [t_v]
while True:
v = t_v.preorder_vertex
path.insert(0, v)
if v.v_id == f_v.v_id:
break
t_v = v
print([(v.v_name, v.weight) for v in path])
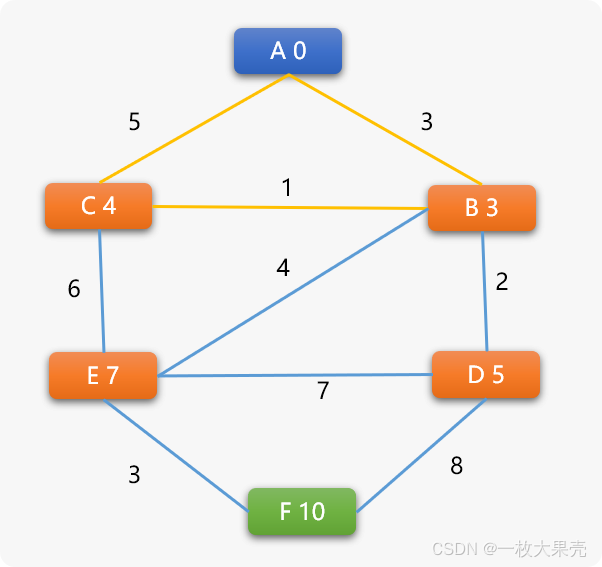
测试结果:
-----------顶点及顶点之间的关系-------------
权重9223372036854775807:名称A顶点相邻的顶点有:[('B', 3), ('C', 5)]
权重9223372036854775807:名称B顶点相邻的顶点有:[('A', 3), ('C', 1), ('D', 2), ('E', 4)]
权重9223372036854775807:名称C顶点相邻的顶点有:[('A', 5), ('B', 1), ('E', 6)]
权重9223372036854775807:名称D顶点相邻的顶点有:[('B', 2), ('E', 7), ('F', 8)]
权重9223372036854775807:名称E顶点相邻的顶点有:[('B', 4), ('C', 6), ('D', 7), ('F', 3)]
权重9223372036854775807:名称F顶点相邻的顶点有:[('D', 8), ('E', 3)]
-----------BF 算法后顶点及顶点之间的关系-------------
权重0:名称A顶点相邻的顶点有:[('B', 3), ('C', 5)]
权重3:名称B顶点相邻的顶点有:[('A', 3), ('C', 1), ('D', 2), ('E', 4)]
权重4:名称C顶点相邻的顶点有:[('A', 5), ('B', 1), ('E', 6)]
权重5:名称D顶点相邻的顶点有:[('B', 2), ('E', 7), ('F', 8)]
权重7:名称E顶点相邻的顶点有:[('B', 4), ('C', 6), ('D', 7), ('F', 3)]
权重10:名称F顶点相邻的顶点有:[('D', 8), ('E', 3)]
----------起始点到任意顶点之间的最短路径长度------------
# A->B 最短路径长度 3
[('A', 0), ('B', 3)]
# A->B->C 最短路径长度为 4
[('A', 0), ('B', 3), ('C', 4)]
# A->B->D 最短路径长度为 5
[('A', 0), ('B', 3), ('D', 5)]
# A->B->E 最短路径长度为 7
[('A', 0), ('B', 3), ('E', 7)]
# A->B->E->F 最短路径长度为 10
[('A', 0), ('B', 3), ('E', 7), ('F', 10)]
Dijkstra(迪杰斯特拉)算法
迪杰斯特拉算法(Diikstra) 是由荷兰计算机科学家狄克斯特拉于1959 年提出的,因此又叫狄克斯特拉算法。为了便于表述,本文简称 DJ 算法。
DJ 算法和前面所聊的 BF 算法,可谓同工异曲,算法的核心思想是相同的:
-
搜索到某一个顶点后,更新与其相邻顶点的权重。
权重计算法则以及权重更新原则两者相同。
-
且顶点权重的数据含义和
BF算法的一样。表示从起始点到此点的最短路径长度(也就是经过的所有边的权重之和)。初始时,因还不能具体最短路径,起始点的权重为 0 ,其它顶点权重可设置为无穷大。
DJ 算法相比较 BF 算法有 2 个不同的地方:
-
在无向加权图中,
BF算法需要对相邻2个顶点进行双向权重计算。 -
DJ算法搜索时,每次选择的下一个顶点是所有权重值最小的顶点。其思想是保证每一次选择的顶点和当前顶点权重都是最短的。如下图结构中,查找
A到任一顶点的最短路径:
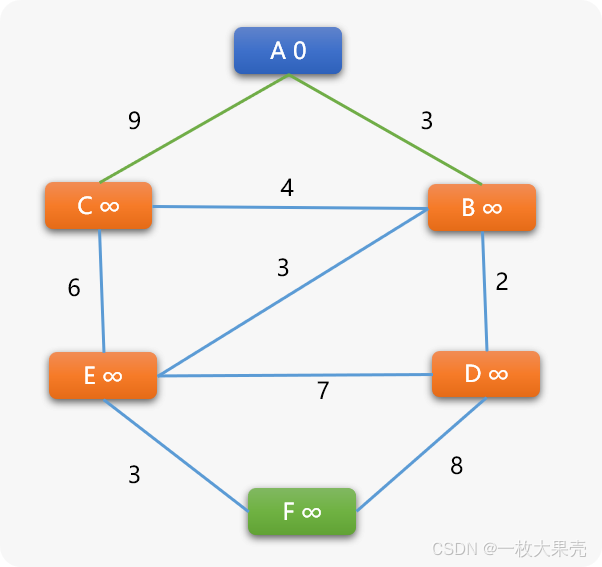
- 定位到起始点
A,A顶点也称为当前顶点。
设置 A 的权重为 0,A 的相邻顶点有 B 和 C,需要计算 A 到 B 以及 A 到 C 之间的权重。这里是先选择 B 还是 C 并不重要。
先选择 B 顶点,计算 A -> B 的路径长度权重。新权重计算公式=A顶点权重+(A,B)边的权重=0+3=3.
更新原则和 BF 算法一样,当计算出来的权重值小于相邻顶点的权重值时,更新。于是 B 的权重更新为 3.此时 A 是 B 的前序顶点。
再选择 C 顶点,计算 A -> C 路径长度权重=0+9=9,因 9 小于 C 现在的无穷大权重,C 的权重被更新为 9.
到这里, 可以说
DJ算法和BF算法没有什么不一样。
但是,DJ 算法不需要对边上 2 个顶点进行双向权重计算,这是 DJ 算法与 BF 算法的第一个差异性。
此时,更新后的图结构如下所示:
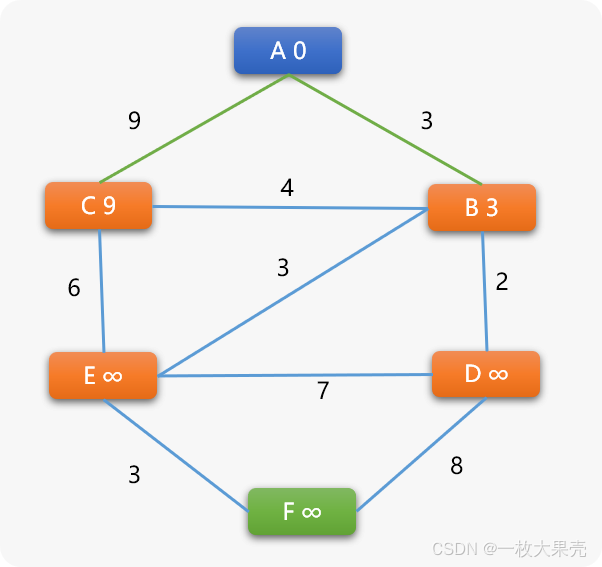
很显然, B 和 C 将成为下一个搜索的候选点,这里 DJ 算法和 BF 算法就有了很大的差异性。
BF 算法对于选择 B 还是 C 的顺序没有要求。
DJ 算法则不同,会选择 B 和 C 中权重值更小的那个, B 的权重 3 小于 C 的权重 9 ,当然选择 B 为下一个搜索顶点。
这是 BF 算法和 DJ 算法的第二个差异性!
选择 B 后也就意味着 A->B 之间的最短路径就确定了。为什么?
因你无法再找出一条比之更短的路径。
这里也是 DJ 算法的关键思想,在选择一个权重最小的候选顶点后,就能确定此顶点和它的前序顶点之间的最短路径长度。
到现在为止, B 的前序顶点是 A;C 的前序顶点也是 A 。
因为 B 已经被选为下一个搜索顶点,于是 B 顶点和它的前序顶点 A 之间的最短路径已经出来了。
A->B 最短路径长度为 3。
而 C 顶点还没有成为搜索顶点,其和 A 顶点之间的最短路径还是一个未知数。
- **B成为当前顶点 **
找到与 B 相邻的 C、D、E 3个顶点,然后分别计算路径长度权重。
B->C 的新权重=3+4=7 小于 C 现有的权重 9 ,C 的权重被更新为 7 ,C 的前序顶点也变成了 B。
同理,B->D 路径中 D 的权重被更新为 5;B->E 路径中 E 的权重被更新为 6 。
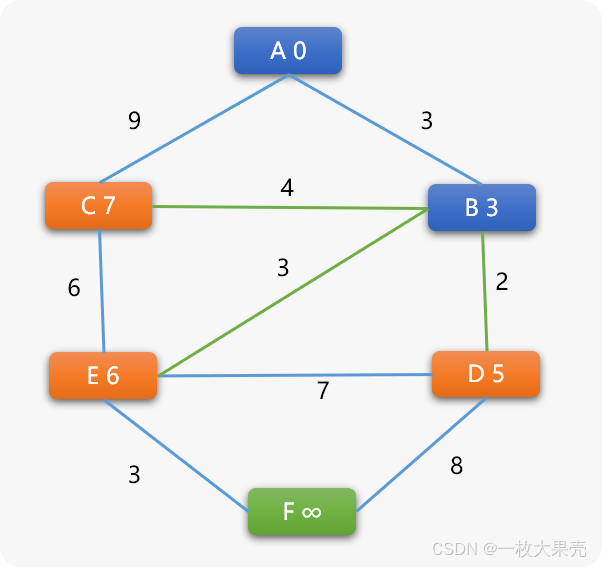
再在 C、 D、 E 3 个顶点中选择权重值最小的 D 为下一个搜索顶点.到这里!可以发现 DJ 算法和原始定义的广度搜索算法以及 BF 之间就有了本质上的区别:
- 广度优先搜索算法会选择和
B同时进入队列的C顶点成为下一个搜索顶点。因为 B 和 C 都是离 A 较近的顶点。 - 而
DJ算法是在候选顶点中,哪一个顶点的权重最少,就选择谁,不采用就近原则.而是以顶点的权重值小作为优先选择条件.
选择 D 后 ,各顶点间的关系:
B 的前序是 A,(A,B)间最短路径已经确定。
D 的前序是 B ,(B,D)间的最短路径可以确定,又因为 B 的前序顶点是 A ,所以 A->B->D 的最短路径可以确定。
其它项点间的最短路径暂时还不明朗。
- D 顶点为当前顶点
计算与 D 相邻的 E、F 顶点的权重。
D->E 的新权重=5+7=12 大于 E 现有权重 6 ,不更新。E 的前序顶点还是 B。
D->F 的新权重=5+8=13 ,F 的权重由无穷大更新为 13。
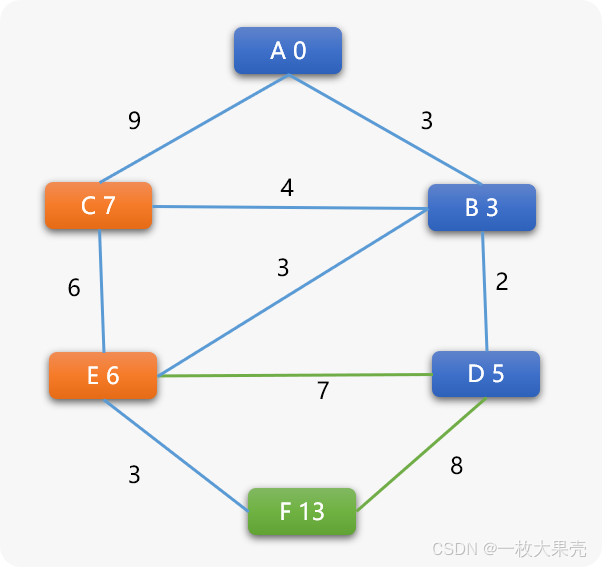
再在省下的所有可选顶点中选择权重值小的 E 顶点为下一个搜索点,当选择 E 后:
E 的前序为 B , B 的前序是 A,所以 A 到 E 的最短路径长度就是 A->B->C ,路径长度为 6。
- E 为当前顶点,计算和其相邻顶点间的权重。
唯一可改变的是 F 顶点的权重,F 顶点的前序顶点变为 E。
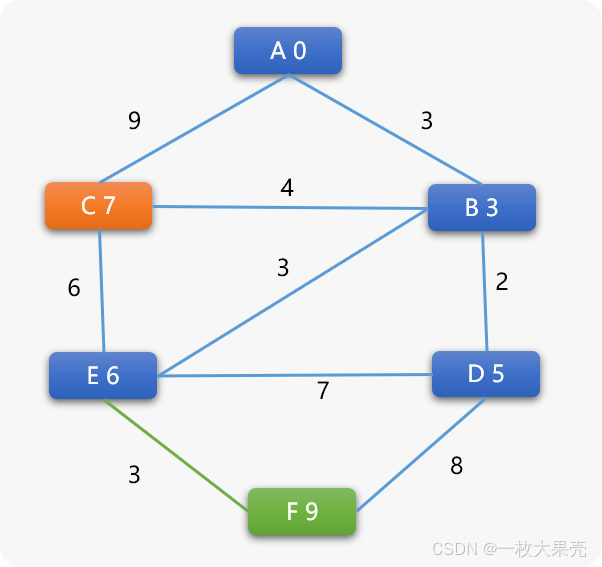
- 再选择 C 为当前顶点
C 和相邻顶点不会再产生任何权重的变化,其前序顶点还是 B。
所以 A 到 C 之间的最短路径应该是 A->B->C 路径长度为 7。
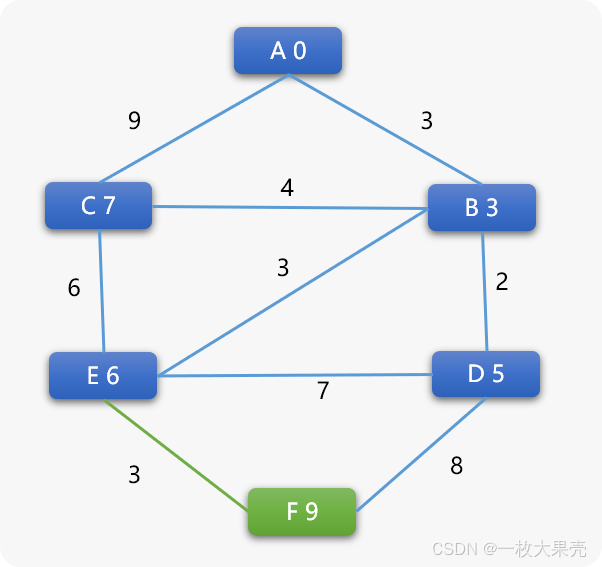
最后选择 F 顶点,也不会再产生任何权重变化,F 的前序是 E,E的前序是B,B的前序是A,所 A 到 F 的最短路径应该是 A->B->E->F 权重值为 9。
最后,以图示方式,比较 BF 算法和 DJ 算法中各顶点出队列的顺序:
BF 采用就近原则出队列,然后不停计算相邻顶点的权重,至到权重不再变化为止,显然用的是蛮力。
DJ 采用权重值小的优先出队列,显然用的是巧力。
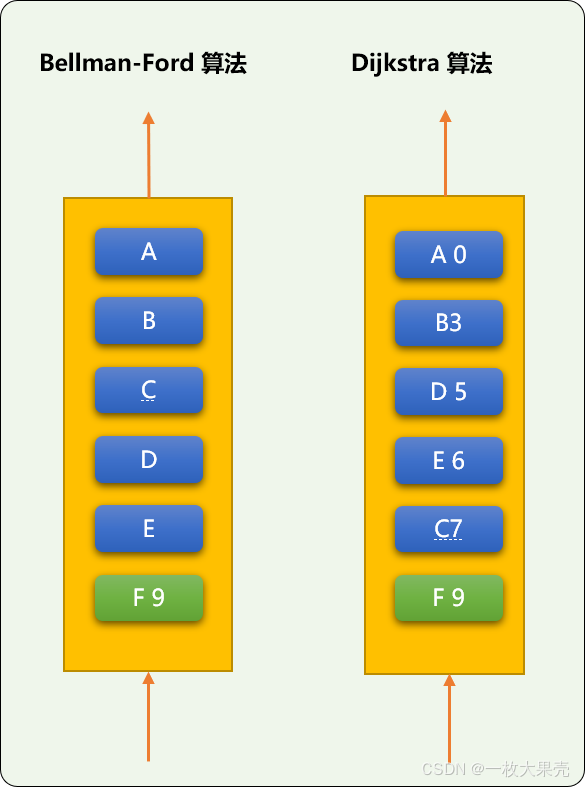
分析完 DJ 算法的流程,现在编写代码:
和上面的 BF 算法相比较,顶点类一样,在图类中添加 DJ 算法:
DJ 算法的本质还是广度优先搜索算法,有所区别的地方是使用优先队列,每次从队列中选择顶点时,选择顶点权重最小的。
所以在图类中,需要修改或重载一个候选顶点入队列的方法:
'''
把当前顶点的相邻顶点压入队列
'''
def push_queue_dj(self, vertex):
# 获取 vertex 顶点的相邻顶点
for v_ in vertex.connected_to.keys():
# 检查此顶点是否压入过
if v_.visited:
continue
# vertex.visited = True
self.queue_stack.append(v_)
# 对队列按顶点权重排序,保证权重值小的排在前面。是 DJ 算法的关键
self.queue_stack.sort(key=lambda v: v.weight)
'''
检查边是否已经更新过
DJ 算法中已经更新过的边不需要再更新
'''
def is_updated(self, *edge):
s = ord(edge[0].v_name) + ord(edge[1].v_name)
for e in self.is_update:
s1 = ord(e[0].v_name) + ord(e[1].v_name)
if s == s1:
return True
return False
实现 DJ 算法:
'''
Dijkstra(迪杰斯特拉)算法
'''
def dj_nearest_path(self, from_v):
# 设备起始点的权重为 0
from_v.weight = 0
# 起始点压入队列
self.queue_stack.append(from_v)
# 检查队列是否为空
while len(self.queue_stack) != 0:
# 从队列获取顶点
tmp_v = self.queue_stack.pop(0)
# 标记为已经处理
tmp_v.visited = True
# 得到与其相邻所有顶点
nbr_vs = tmp_v.connected_to.keys()
# 更新与其相邻顶点的权重
for v_ in nbr_vs:
# 边是否已经处理
if self.is_updated(tmp_v, v_):
continue
# 更新权重
tmp_v.cal_bf_weight(v_)
# 记录已经更新过
self.is_update.append((tmp_v, v_))
# 把相邻顶点压入队列
self.push_queue_dj(v_)
测试代码:
if __name__ == '__main__':
# 初始化图
graph = Graph()
# 添加节点
for v_name in ['A', 'B', 'C', 'D', 'E', 'F']:
v = Vertex(v_name)
graph.add_vertex(v)
# 添加顶点之间关系
v_to_v = [('A', 'B', 3), ('A', 'C', 9), ('B', 'C', 4), ('B', 'D', 2), ('B', 'E', 3), ('C', 'E', 6), ('D', 'E', 7),
('D', 'F', 8),
('E', 'F', 3)]
# 无向图每 2 个顶点之间互为关系
for v in v_to_v:
f_v = graph.find_vertex(v[0])
t_v = graph.find_vertex(v[1])
graph.add_edge(f_v, t_v, v[2])
graph.add_edge(t_v, f_v, v[2])
# 输出所有顶点
print('-----------顶点及顶点之间的关系-------------')
for v in graph.find_vertexes():
print(v)
# 查找起始点到任一顶点之间的最短路径长度
f_v = graph.find_vertex('A')
# DJ 算法
graph.dj_nearest_path(f_v)
print('----------- DJ 算法后顶点及顶点之间的关系-------------')
for v in graph.find_vertexes():
print(v)
#
print('----------f_v~t_v 最短路径长度------------')
for name in ['B', 'C', 'D', 'E', 'F']:
t_v = graph.find_vertex(name)
path = [t_v]
while True:
# 找到前序顶点
v = t_v.preorder_vertex
path.insert(0, v)
if v.v_id == f_v.v_id:
break
t_v = v
print([(v.v_name, v.weight) for v in path])
输出结果:
-----------顶点及顶点之间的关系-------------
权重9223372036854775807:名称A顶点相邻的顶点有:[('B', 3), ('C', 9)]
权重9223372036854775807:名称B顶点相邻的顶点有:[('A', 3), ('C', 4), ('D', 2), ('E', 3)]
权重9223372036854775807:名称C顶点相邻的顶点有:[('A', 9), ('B', 4), ('E', 6)]
权重9223372036854775807:名称D顶点相邻的顶点有:[('B', 2), ('E', 7), ('F', 8)]
权重9223372036854775807:名称E顶点相邻的顶点有:[('B', 3), ('C', 6), ('D', 7), ('F', 3)]
权重9223372036854775807:名称F顶点相邻的顶点有:[('D', 8), ('E', 3)]
----------- DJ 算法后顶点及顶点之间的关系-------------
权重0:名称A顶点相邻的顶点有:[('B', 3), ('C', 9)]
权重3:名称B顶点相邻的顶点有:[('A', 3), ('C', 4), ('D', 2), ('E', 3)]
权重7:名称C顶点相邻的顶点有:[('A', 9), ('B', 4), ('E', 6)]
权重5:名称D顶点相邻的顶点有:[('B', 2), ('E', 7), ('F', 8)]
权重6:名称E顶点相邻的顶点有:[('B', 3), ('C', 6), ('D', 7), ('F', 3)]
权重9:名称F顶点相邻的顶点有:[('D', 8), ('E', 3)]
----------f_v~t_v 最短路径长度------------
[('A', 0), ('B', 3)]
[('A', 0), ('B', 3), ('C', 7)]
[('A', 0), ('B', 3), ('D', 5)]
[('A', 0), ('B', 3), ('E', 6)]
[('A', 0), ('B', 3), ('E', 6), ('F', 9)]
DJ 算法不适合用于边上权重为负数的图中,否则可能找不到路径。
3. 总结在加权图中查找最短路径长度算法除了 BF、DJ 算法,还有 A* 算法 D* 算法。有兴趣的可以自行了解。
【本文来源:香港服务器租用 http://www.558idc.com/st.html欢迎留下您的宝贵建议】