先来了解一下分布式链路追踪技术产生的背景。
在现在这个发达的互联网世界,互联网的规模越来越大,比如 google 的搜索,Netflix 的视频流直播,淘宝的购物等。
像这种大规模的应用,我们每点击一下鼠标,搜索一个关键字,背后可能会有几百台服务器上的N个服务来为我们提供服务。
我们用谷歌搜索:分布式 3 个字,搜索一些文章来学习分布式的知识。假如,查询时结果返回耗时 5 秒之多。
作为用户的你,等待这么长时间才返回结果,心里肯定不满意。
那作为一项服务来说,公司为了更好的服务用户,让用户满意,就必须要缩短用户等待返回查询结果的时间,要尽可能快的返回结果。
这样用户使用时才会感觉满意。
当然,这个优化任务就落在了产品技术研发人身上了。- -!
作为开发服务的产品技术人员,要怎么样做,才能让用户搜索时返回结果很快呢?
这时,产品研发人就思考在思考:
用户的一次搜索背后可能有几百个后端服务来提供服务。比如现在流行的微服务架构。
如果后端有一条服务比较慢,那么就可能会拖慢这整个搜索结果。
在这么多的服务中,要怎么样做,才能找出慢的服务呢?怎么找出是哪一条后端服务比较慢呢?
产品技术研发研究人员为了解决这个问题,慢慢想出了分布式链路追踪的技术,在到具体的技术实践,这是一个漫长的过程。
他们把研究成果汇聚在了 dapper 论文里。
当然它也借鉴了前人的研究成果 ,尤其是 Magpie 和 X-Trace,还有 Pinpoint。
说明:这里的 Pinpoint 并不是 pinpoint-apm,而是一篇论文
在 [dapper](https://research.google/pubs/pub36356/) 论文开头有这样一段描述:
1.2 一个请求的链路图示Modern Internet services are often implemented as complex, large-scale distributed systems. These applications are constructed from collections of software modules that may be developed by different teams, perhaps in different programming languages, and could span many thousands of machines across multiple physical facili- ties. Tools that aid in understanding system behavior and reasoning about performance issues are invaluable in such an environment.
from: https://research.google/pubs/pub36356/
大意是说现代互连网服务,通常都是用复杂的、大规模分布式集群来实现。这些应用构建在不同的模块上,这些软件模块,可能由不同的团队开发,可能使用不同的开发语言,可能部署在几千台服务器上,横跨多个数据中心。因此,需要一些可以理解这个复杂系统的行为,用于分析性能找出性能问题的工具。
Dapper 论文里的一张图,表示一个请求可能经过的路径节点:
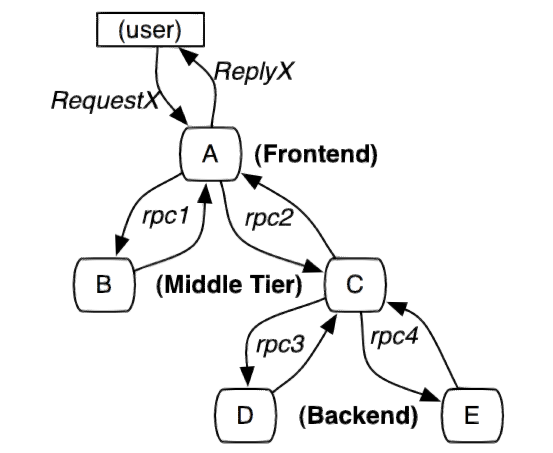
(图 1:这个路径由user用户的RequestX发起请求,穿过一个简单的服务系统。用字母标识的节点代表分布式系统中的不同处理过程,
来自:https://research.google/pubs/pub36356/)
这张图是由 5 台服务器提供相关的一个服务,它包含:A-前端,B,C-2个服务中间层,以及 2 个后端 D 和 E。
当一个用户发起一个请求,首先是到达前端 A, 然后发送 2 个 RPC 请求到服务器 B 和 C。B 马上会响应请求,但是 C 需要和
后端的 D 和 E 交互之后在返回给 A,最后由 A 来响应最初的请求。
上图的调用链经过了不同的系统,这个系统可能是不同团队维护,并且使用不同的语言开发。如果服务中出现了问题,比如请求异常,请求超时,那么怎么定位是哪个系统的哪一步出现了问题呢?
还有,对系统的监控是 7x24 小时不间断的。持续的对系统进行监控。
二、Dapper 的分布式追踪 2.1 怎么定义图1链路信息对于上面图 1 的一个请求响应路径,怎么定义、怎么能实现分布式追踪呢?
简单实现:为服务器每一次的发送和接收请求来收集追踪标识(message identifiers)和时间戳(timestamped events)。
从入口开始发起 Request 的请求者(图 1 中的 RequestX),与这个请求者相关的信息都要关联上,并记录下来分析链路关系,有什么好的方案呢?
2 种方案:黑盒(black-box)和基于标注(annotation-based)的监控方案。
黑盒方案:
假定需要追踪的除了上述信息之外没有额外的信息,这样使用统计回归技术来推断两者之间的关系。
基于标注方案:
依赖于应用程序或中间件明确地标记一个全局 ID,从而连接每一条记录与发起者的请求。
2种方案的比较:
黑盒方案比标注方案跟轻便,但是它需要更多的数据,以获得足够的精度,因为他们依赖于统计推论。
标注方案最主要缺点,需要代码植入。
Google的选择:
在 google 的生产环境中,所有的应用程序都使用相同的线程模型,控制流和RPC系统,他们可以把代码植入限制在一个很小的通用组件库中,从而实现了监测系统的应用对开发人员是有效且透明。
dapper 的追踪架构是内嵌在 RPC 调用链的属性结构里。当然这个调用链路监控,还可以追踪其他行为,比如外界的 HTTP 请求,Gmail的 SMTP 会话和外部对 SQL 服务器查询等。
2.2 Dapper 数据结构模型1、树形结构,追踪树
2、Span 以及 Annotation
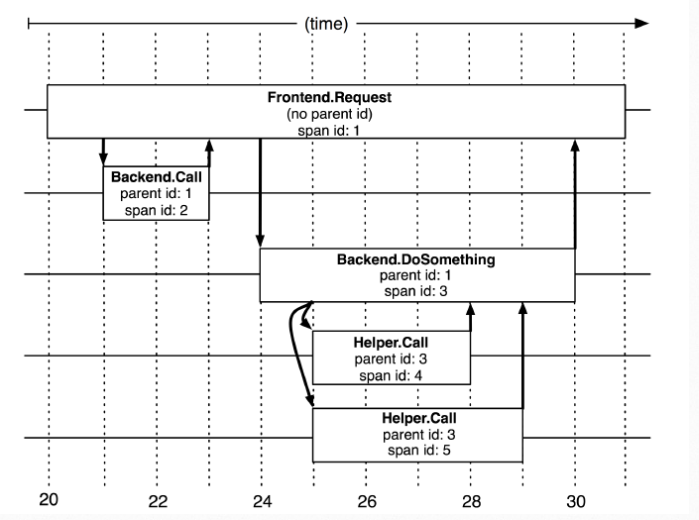
(图 2:来自dapper论文:https://research.google/pubs/pub36356/)
图 2,是一个树形结构,每一个树节点是整个架构的基本单元,这个节点单元叫做 span,每个节点 span 都有一个唯一的 id:span id,还有一个 name:span name。
节点之间的关系可以用父子来表示,parent id 和 span id,parent id 就是它上一个 span 的 id;如果一个 span 没有父 id,那么它就是根节点,root span。
所有的 span 都有一个追踪请求 id,叫 trace id,作用是标识出一次完整请求。这个 trace id 是全局唯一。
最后,每个 span 还有一个 Annotations,记录每个 span 中的其他相关信息,比如 span 的开始时间戳,结束时间戳,发送信息等等信息,客户端和服务端信息都可以记录。
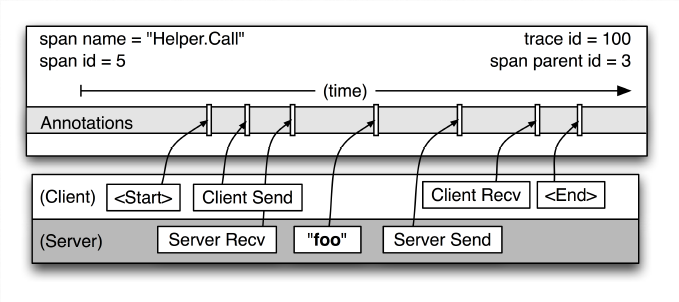
(图3:表示一个单独的 span 结构信息图,来自 dapper 论文)
// 伪码表示结构
struct span {
id // 当前 span 的 id
parent_id // 父 id,上一层 span id
name // 当前 span 的 name
trace_id // 标识一次完整请求的 trace_id
Annotations []annotation // 表示 span 中的其它相关信息
}
struct annotation {
star_time // 此次 span 开始时间戳
end_time // 此次 span 结束时间戳
client_send_info // 客户端发送信息
client_recv_info // 客户端接收信息
server_send_info // 服务端发送信息
.. ...
}
dapper 里面叫植入点。
怎么把相关追踪代码放入到程序中?并且能比较少的改动代码,又能达到下面三个设计目标。
dapper 里提了 3 个设计目标:
- 低损耗
追踪系统对在线服务的影响最小化。因为在一些性能比较敏感的服务里,一点点的性能消耗也可能影响用户体验。
- 对应用程序透明
对于应用程序来说,它根本觉察不到追踪系统的存在。
一个追踪系统,如果需要应用开发者主动配合植入追踪代码,那么追踪系统的存在不仅会导致众多额外代码的修改,最重要的是可能会使
运行良好的系统产生bug。
- 扩展性
google 在未来几年随着业务规模增长而扩展集群规模,追踪系统也能够应对这种情况。
对于上面 3 点中最重要的一点就是追踪系统对**应用程序透明**。
那怎么做才能对应用程序透明?
Dapper 可以近乎零浸入的成本对应用程序链路进行追踪,得益于 google 的服务设施依赖几个少数的通用组件库,只要改造这
几个组件库就可以了。比如 google 中几乎所有进程间通信都是建立在 C++ 和 Java 开发的 RPC 框架上,那么我们只用改造这个 RPC 框架,追踪系统就能在依赖这个 RPC 框架的应用程序里生效。
当然 dapper 也允许应用开发人员给链路追踪系统添加额外的信息,以监控更高级别的系统行为,或帮助调试问题。它允许用户通过一个简单的 API 定义带时间戳的 Annotation。
2.4 采样率和追踪信息的收集低损耗是 dapper 的一个设计目标,所以 dapper 对系统链路信息收集工作对基本组件性能损耗要尽可能的小。还有就是遇到大量请求时只记录其中一小部分。
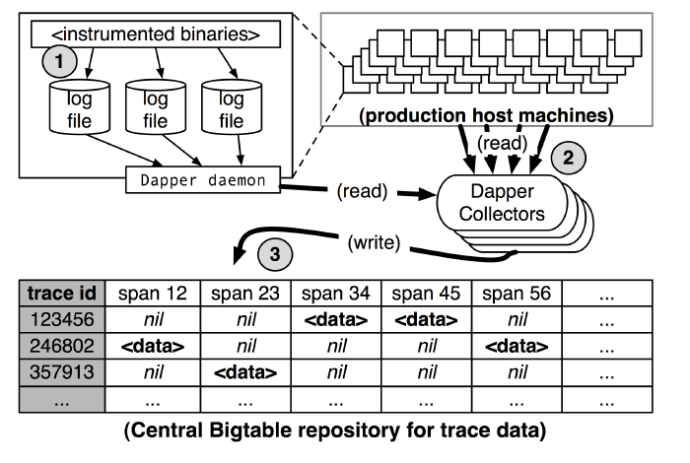
(图4:dapper 收集管道总览,来自 dapper 论文)
dapper 追踪系统记录和收集信息过程分为三个阶段(如上图4):
- span 的数据写入(1)本地日志文件,
- 然后 dapper 的 daemon 进程和收集组件把追踪的数据从生产环境读取处理(2)。
- 最后一些(3)的 bigtable 仓库中。
看上面图4:一次追踪信息被存储为 bigtable 的一行,每一列相当于一个 span。 引用参考
-
dapper 论文:https://research.google/pubs/pub36356/,