- [源码解析] TensorFlow 分布式环境(7) --- Worker 动态逻辑
- 1. 概述
- 1.1 温故
- 1.2 知新
- 2. 注册子图
- 2.1 GrpcWorker
- 2.2 GraphMgr
- 2.2.1 定义
- 2.2.2 注册图
- 3. 运行子图
- 3.1 Service
- 3.2 GrpcWorker
- 3.3 GraphMgr
- 3.4 小结
- 4. 总结
- 0xFF 参考
- 1. 概述
前文中,Master 在流程之中先后调用了 gRPC 给远端 worker 发送命令,即,GrpcRemoteWorker 类中的每一个函数都通过调用 IssueRequest() 发起一个异步的 gRPC 调用。GrpcRemoteWorker 一共发了两个请求:RegisterGraphAsync,RunGraphAsync,我们看看 GrpcWorkerService 如何处理。
本文依旧深度借鉴了两位大神:
- [TensorFlow Internals] (https://github.com/horance-liu/tensorflow-internals),虽然其分析的不是最新代码,但是建议对 TF 内部实现机制有兴趣的朋友都去阅读一下,绝对大有收获。
- https://home.cnblogs.com/u/deep-learning-stacks/ 西门宇少,不仅仅是 TensorFlow,其公共号还有更多其他领域,业界前沿。
本系列其他文章是:
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(5) --- Session
1. 概述 1.1 温故我们首先回顾一下目前为止各种概念之间的关系。
- Client会构建完整的计算图(FullGraph),但是这个完整计算图无法并行执行,所以需要切分优化。
- Master会对完整计算图进行处理,比如剪枝等操作,生成ClientGraph(可以执行的最小依赖子图)。然后根据Worker信息把ClientGraph继续切分成多个PartitionGraph。把这些PartitionGraph注册给每个Worker。
- Worker接收到注册请求之后,会把收到的PartitionGraph根据本地计算设备集继续做切分成多个PartitionGraph,并且在每个设备上启动一个Executor来执行本设备收到的PartitionGraph。
我们接下来看看Worker的流程概要。当流程来到某个特点 Worker 节点,如果 worker 节点收到了 RegisterGraphRequest,消息会携带 MasterSession 分配的 session_handle 和子图 graph_def(GraphDef形式)。GraphDef是TensorFlow把Client创建的计算图使用Protocol Buffer序列化之后的结果。GraphDef包括了计算图所有的元数据。它可以被ConvertGraphDefToGraph方法转换成Graph。Graph不但有计算图的元数据,还有其他运行时候所需要的信息。
Worker 把计算图按照本地设备集继续切分成多个 PartitionGraph,把PartitionGraph 分配给每个设备,然后在每个计算设备之上启动一个 Executor,等待后续执行命令。Executor类是TensorFlow之中会话执行器的抽象,其提供异步执行局部图的RunAsync虚方法及其同步封装版本Run方法。
当 Worker 节点收到 RunGraphAsync 之后,各个设备开始执行。WorkerSession 会调用 session->graph_mgr()->ExecuteAsync 执行,其又调用到 StartParallelExecutors,这里会启动一个 ExecutorBarrier。当某一个计算设备执行完所分配的 PartitionGraph 后,ExecutorBarrier 计数器将会增加 1,如果所有设备都完成 PartitionGraph 列表的执行,barrier.wait() 阻塞操作将退出。
我们接下来逐步分析一下上述流程。
2. 注册子图当 worker 节点收到了 RegisterGraphRequest 之后,首先来到了 GrpcWorkerService,所以实际调用的是 "/tensorflow.WorkerService/RegisterGraph",对应代码如下,其实展开了就是 RegisterGraphHandler:
#define HANDLE_CALL(method, may_block_on_compute_pool) \
void method##Handler(WorkerCall<method##Request, method##Response>* call) { \
auto closure = [this, call]() { \
Status s = worker_->method(&call->request, &call->response); \
if (!s.ok()) { \
VLOG(3) << "Bad response from " << #method << ": " << s; \
} \
call->SendResponse(ToGrpcStatus(s)); \
}; \
if ((may_block_on_compute_pool)) { \
worker_->env()->env->SchedClosure(std::move(closure)); \
} else { \
worker_->env()->compute_pool->Schedule(std::move(closure)); \
} \
ENQUEUE_REQUEST(method, false); \
}
HANDLE_CALL(RegisterGraph, false);
RegisterGraph 实际调用的是 WorkerInterface 的方法,其内部会转到 RegisterGraphAsync 方法。
Status WorkerInterface::RegisterGraph(const RegisterGraphRequest* request,
RegisterGraphResponse* response) {
return CallAndWait(&ME::RegisterGraphAsync, request, response);
}
RegisterGraphAsync 最后来到 Worker 的实现,其首先依据 session_handle 查找到 WokerSession,然后调用 GraphMgr。
GraphMgr* SessionMgr::graph_mgr() const { return graph_mgr_.get(); }
RegisterGraphAsync 具体如下:
void Worker::RegisterGraphAsync(const RegisterGraphRequest* request,
RegisterGraphResponse* response,
StatusCallback done) {
std::shared_ptr<WorkerSession> session;
Status s;
if (request->create_worker_session_called()) {
s = env_->session_mgr->WorkerSessionForSession(request->session_handle(),
&session);
} else {
session = env_->session_mgr->LegacySession();
}
if (s.ok()) {
s = session->graph_mgr()->Register(
request->session_handle(), request->graph_def(), session.get(),
request->graph_options(), request->debug_options(),
request->config_proto(), request->collective_graph_key(),
session->cluster_flr(), response->mutable_graph_handle());
}
done(s);
}
GraphMgr 负责跟踪一组在 TensorFlow 工作者那里注册的计算图。每个注册的图都由 GraphMgr 生成的句柄 graph_handle 来识别,并返回给调用者。在成功注册后,调用者使用图句柄执行一个图。每个执行都通过调用者生成的全局唯一ID "step_id"与其他执行区分开来。只要使用的 "step_id"不同,多个执行可以同时独立使用同一个图,多个线程可以并发地调用 GraphMgr 方法。
2.2.1 定义GraphMgr 具体定义如下:
class GraphMgr {
private:
typedef GraphMgr ME;
struct ExecutionUnit {
std::unique_ptr<Graph> graph = nullptr;
Device* device = nullptr; // not owned.
Executor* root = nullptr; // not owned.
FunctionLibraryRuntime* lib = nullptr; // not owned.
// Build the cost model if this value is strictly positive.
int64_t build_cost_model = 0;
};
struct Item : public core::RefCounted {
~Item() override;
// Session handle.
string session;
// Graph handle.
string handle;
std::unique_ptr<FunctionLibraryDefinition> lib_def;
// Owns the FunctionLibraryRuntime objects needed to execute functions, one
// per device.
std::unique_ptr<ProcessFunctionLibraryRuntime> proc_flr;
// A graph is partitioned over multiple devices. Each partition
// has a root executor which may call into the runtime library.
std::vector<ExecutionUnit> units;
// Used to deregister a cost model when cost model is required in graph
// manager.
GraphMgr* graph_mgr;
int64_t collective_graph_key;
};
const WorkerEnv* worker_env_; // Not owned.
const DeviceMgr* device_mgr_;
CostModelManager cost_model_manager_;
// Owned.
mutex mu_;
int64_t next_id_ TF_GUARDED_BY(mu_) = 0;
// If true, blocks until device has finished all queued operations in a step.
bool sync_on_finish_ = true;
// Table mapping graph handles to registered graphs.
//
// TODO(zhifengc): If the client does not call Deregister, we'll
// lose memory over time. We should implement a timeout-based
// mechanism to gc these graphs.
std::unordered_map<string, Item*> table_;
TF_DISALLOW_COPY_AND_ASSIGN(GraphMgr);
};
具体各个类之间关系和功能如下,注册图就是往GraphMgr的table_变量之中进行注册新Item,而执行图就是执行具体的Item。

注册图代码如下,其实就是转交给 InitItem,所以我们接下去看看 InitItem。
Status GraphMgr::Register(
const string& handle, const GraphDef& gdef, WorkerSession* session,
const GraphOptions& graph_options, const DebugOptions& debug_options,
const ConfigProto& config_proto, int64_t collective_graph_key,
DistributedFunctionLibraryRuntime* cluster_flr, string* graph_handle) {
Item* item = new Item;
Status s = InitItem(handle, gdef, session, graph_options, debug_options,
config_proto, collective_graph_key, cluster_flr, item);
if (!s.ok()) {
item->Unref();
return s;
}
// Inserts one item into table_.
{
mutex_lock l(mu_);
*graph_handle =
strings::Printf("%016llx", static_cast<long long>(++next_id_));
item->handle = *graph_handle;
CHECK(table_.insert({*graph_handle, item}).second);
}
return Status::OK();
}
InitItem 主要功能是:
-
在给定 session 的一个图定义 "gdef" 之后,创建 executors。
-
如果 "gdef"中的一个节点被 "session "中的其他图所共享,则相同的 op kernel 被重复使用。例如,通常一个params节点被一个会话中的多个图所共享。
-
如果 "gdef"被分配给多个设备,可能会添加额外的节点(例如,发送/接收节点)。额外节点的名字是通过调用 "new_name(old_name) "生成的。
-
如果成功的话,"executors"将被分配,每个设备填入一个执行器,调用者将拥有返回的 executors 的所有权。
// Creates executors given a graph definition "gdef" of a "session".
// If a node in "gdef" is shared by other graphs in "session", the
// same op kernel is reused. E.g., typically a params node is shared
// by multiple graphs in a session.
//
// If "gdef" is assigned to multiple devices, extra nodes (e.g.,
// send/recv nodes) maybe added. The extra nodes' name are generated
// by calling "new_name(old_name)".
//
// "executors" are filled with one executor per device if success and
// the caller takes the ownership of returned executors.
Status GraphMgr::InitItem(
const string& handle, const GraphDef& gdef, WorkerSession* session,
const GraphOptions& graph_options, const DebugOptions& debug_options,
const ConfigProto& config_proto, int64_t collective_graph_key,
DistributedFunctionLibraryRuntime* cluster_flr, Item* item) {
item->session = handle;
item->collective_graph_key = collective_graph_key;
item->lib_def.reset(
new FunctionLibraryDefinition(OpRegistry::Global(), gdef.library()));
TF_RETURN_IF_ERROR(ValidateGraphDefForDevices(gdef));
// We don't explicitly Validate the graph def because ConvertGraphDefToGraph
// does that below.
item->proc_flr.reset(new ProcessFunctionLibraryRuntime(
device_mgr_, worker_env_->env, /*config=*/&config_proto,
gdef.versions().producer(), item->lib_def.get(),
graph_options.optimizer_options(), worker_env_->compute_pool, cluster_flr,
/*session_metadata=*/nullptr,
Rendezvous::Factory{
[this, session](const int64_t step_id, const DeviceMgr*,
Rendezvous** r) -> Status {
auto* remote_r = this->worker_env_->rendezvous_mgr->Find(step_id);
TF_RETURN_IF_ERROR(remote_r->Initialize(session));
*r = remote_r;
return Status::OK();
},
[this](const int64_t step_id) {
this->worker_env_->rendezvous_mgr->Cleanup(step_id);
return Status::OK();
}}));
// Constructs the graph out of "gdef".
Graph graph(OpRegistry::Global());
GraphConstructorOptions opts;
opts.allow_internal_ops = true;
opts.expect_device_spec = true;
opts.validate_nodes = true;
TF_RETURN_IF_ERROR(ConvertGraphDefToGraph(opts, gdef, &graph));
// Splits "graph" into multiple subgraphs by device names.
std::unordered_map<string, GraphDef> partitions;
PartitionOptions popts;
popts.node_to_loc = SplitByDevice; // 这里调用了
popts.new_name = [this](const string& prefix) {
mutex_lock l(mu_);
return strings::StrCat(prefix, "_G", next_id_++);
};
popts.get_incarnation = [this](const string& name) -> int64 {
Device* device = nullptr;
Status s = device_mgr_->LookupDevice(name, &device);
if (s.ok()) {
return device->attributes().incarnation();
} else {
return PartitionOptions::kIllegalIncarnation;
}
};
popts.flib_def = item->lib_def.get();
popts.control_flow_added = true;
popts.scheduling_for_recvs = graph_options.enable_recv_scheduling();
TF_RETURN_IF_ERROR(Partition(popts, &graph, &partitions));
if (popts.scheduling_for_recvs) {
TF_RETURN_IF_ERROR(AddControlEdges(popts, &partitions));
}
std::unordered_map<string, std::unique_ptr<Graph>> partition_graphs;
// 对每个分区进行图转换
for (auto& partition : partitions) {
std::unique_ptr<Graph> device_graph(new Graph(OpRegistry::Global()));
GraphConstructorOptions device_opts;
// There are internal operations (e.g., send/recv) that we now allow.
device_opts.allow_internal_ops = true;
device_opts.expect_device_spec = true;
TF_RETURN_IF_ERROR(ConvertGraphDefToGraph(
device_opts, std::move(partition.second), device_graph.get()));
partition_graphs.emplace(partition.first, std::move(device_graph));
}
GraphOptimizationPassOptions optimization_options;
optimization_options.flib_def = item->lib_def.get();
optimization_options.partition_graphs = &partition_graphs;
TF_RETURN_IF_ERROR(OptimizationPassRegistry::Global()->RunGrouping(
OptimizationPassRegistry::POST_PARTITIONING, optimization_options));
LocalExecutorParams params;
item->units.reserve(partitions.size());
item->graph_mgr = this;
const auto& optimizer_opts = graph_options.optimizer_options();
GraphOptimizer optimizer(optimizer_opts);
for (auto& p : partition_graphs) {
const string& device_name = p.first;
std::unique_ptr<Graph>& subgraph = p.second;
item->units.resize(item->units.size() + 1);
ExecutionUnit* unit = &(item->units.back());
// Find the device.
Status s = device_mgr_->LookupDevice(device_name, &unit->device);
if (!s.ok()) {
// Remove the empty unit from the item as the item destructor wants all
// units to have valid devices.
item->units.pop_back();
return s;
}
// 看看是否需要重写图
// Give the device an opportunity to rewrite its subgraph.
TF_RETURN_IF_ERROR(unit->device->MaybeRewriteGraph(&subgraph));
// Top-level nodes in the graph uses the op segment to cache
// kernels. Therefore, as long as the executor is alive, we need
// to ensure the kernels cached for the session are alive.
auto opseg = unit->device->op_segment();
opseg->AddHold(handle);
// Function library runtime.
FunctionLibraryRuntime* lib = item->proc_flr->GetFLR(unit->device->name());
// 建立 executor
// Construct the root executor for the subgraph.
params.device = unit->device;
params.function_library = lib;
params.create_kernel =
[handle, lib, opseg](const std::shared_ptr<const NodeProperties>& props,
OpKernel** kernel) {
// NOTE(mrry): We must not share function kernels (implemented
// using `CallOp`) between subgraphs, because `CallOp::handle_`
// is tied to a particular subgraph. Even if the function itself
// is stateful, the `CallOp` that invokes it is not.
if (!OpSegment::ShouldOwnKernel(lib, props->node_def.op())) {
return lib->CreateKernel(props, kernel);
}
auto create_fn = [lib, &props](OpKernel** kernel) {
return lib->CreateKernel(props, kernel);
};
// Kernels created for subgraph nodes need to be cached. On
// cache miss, create_fn() is invoked to create a kernel based
// on the function library here + global op registry.
return opseg->FindOrCreate(handle, props->node_def.name(), kernel,
create_fn);
};
params.delete_kernel = [lib](OpKernel* kernel) {
if (kernel && !OpSegment::ShouldOwnKernel(lib, kernel->type_string())) {
delete kernel;
}
};
// 优化图
optimizer.Optimize(lib, worker_env_->env, params.device, &subgraph,
GraphOptimizer::Options());
TF_RETURN_IF_ERROR(
EnsureMemoryTypes(DeviceType(unit->device->device_type()),
unit->device->name(), subgraph.get()));
unit->graph = std::move(subgraph);
unit->build_cost_model = graph_options.build_cost_model();
if (unit->build_cost_model > 0) {
skip_cost_models_ = false;
}
TF_RETURN_IF_ERROR(NewLocalExecutor(params, *unit->graph, &unit->root));
}
return Status::OK();
}
上面需要注意的一点是使用了 SplitByDevice 进行图的二次切分,这次是按照设备来切分。
// NOTE: node->device_name() is not set by GraphConstructor. We
// expects that NodeDef in GraphDef given to workers fully specifies
// device names.
static string SplitByDevice(const Node* node) {
return node->assigned_device_name();
}
inline const std::string& Node::assigned_device_name() const {
return graph_->get_assigned_device_name(*this);
}
注册图的结果大致如下,就是使用Master传来的各种信息来生成一个Item,注册在GraphMgr之中,同时也为Item生成ExecutionUnit,其中graph_handle是根据handle生成的。
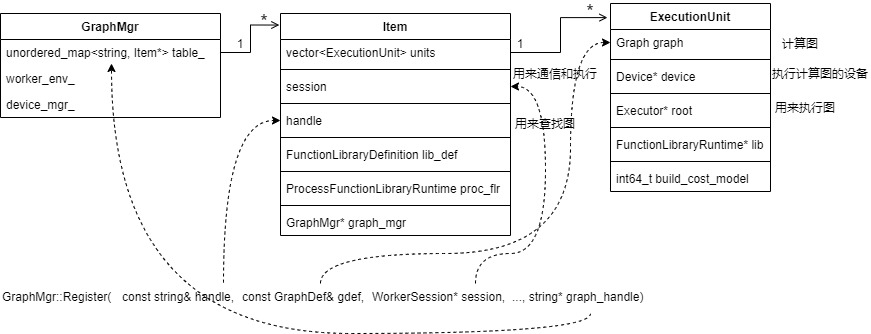
注册完子图之后,后续就可以运行子图。
3. 运行子图Master 用 RunGraphRequest 来执行在 graph_handle下注册的所有子图。Master 会生成一个全局唯一的 step_id 来区分图计算的不同运行 step。子图之间可以使用 step_id 进行彼此通信(例如,发送/转发操作),以区分不同运行产生的张量。
RunGraphRequest 消息的 send 表示子图输入的张量,recv_key 指明子图输出的张量。RunGraphResponse 会返回 recv_key 对应的 Tensor 列表。
3.1 Service首先来到了 GrpcWorkerService,调用到的是 "/tensorflow.WorkerService/RunGraph",对应的代码是:
void RunGraphHandler(WorkerCall<RunGraphRequest, RunGraphResponse>* call) {
// 利用Schedule把计算任务放进线程池队列中
Schedule([this, call]() {
CallOptions* call_opts = new CallOptions;
ProtoRunGraphRequest* wrapped_request =
new ProtoRunGraphRequest(&call->request);
NonOwnedProtoRunGraphResponse* wrapped_response =
new NonOwnedProtoRunGraphResponse(&call->response);
call->SetCancelCallback([call_opts]() { call_opts->StartCancel(); });
worker_->RunGraphAsync(call_opts, wrapped_request, wrapped_response,
[call, call_opts, wrapped_request,
wrapped_response](const Status& s) {
call->ClearCancelCallback();
delete call_opts;
delete wrapped_request;
delete wrapped_response;
call->SendResponse(ToGrpcStatus(s));
});
});
ENQUEUE_REQUEST(RunGraph, true);
}
这里是把计算任务放进线程池队列中,具体业务逻辑在 Worker::RunGraphAsync 函数中。
void Schedule(std::function<void()> f) {
worker_->env()->compute_pool->Schedule(std::move(f));
}
在 RunGraphAsync 之中,有两种执行方式,我们选择 DoRunGraph 来分析。
void Worker::RunGraphAsync(CallOptions* opts, RunGraphRequestWrapper* request,
MutableRunGraphResponseWrapper* response,
StatusCallback done) {
if (request->store_errors_in_response_body()) {
done = [response, done](const Status& status) {
response->set_status(status);
done(Status::OK());
};
}
if (request->is_partial()) {
DoPartialRunGraph(opts, request, response, std::move(done)); // 有兴趣读者可以深入研究
} else {
DoRunGraph(opts, request, response, std::move(done)); // 分析这里
}
}
DoRunGraph 主要是调用了 session->graph_mgr()->ExecuteAsync 来执行计算图。
void Worker::DoRunGraph(CallOptions* opts, RunGraphRequestWrapper* request,
MutableRunGraphResponseWrapper* response,
StatusCallback done) {
const int64_t step_id = request->step_id();
Status s = recent_request_ids_.TrackUnique(request->request_id(),
"RunGraph (Worker)", request);
if (!s.ok()) {
done(s);
return;
}
std::shared_ptr<WorkerSession> session;
if (request->create_worker_session_called()) {
s = env_->session_mgr->WorkerSessionForSession(request->session_handle(),
&session);
} else {
session = env_->session_mgr->LegacySession();
}
if (!s.ok()) {
done(s);
return;
}
GraphMgr::NamedTensors in;
GraphMgr::NamedTensors* out = new GraphMgr::NamedTensors;
s = PrepareRunGraph(request, &in, out);
if (!s.ok()) {
delete out;
done(s);
return;
}
StepStatsCollector* collector = nullptr;
if (request->exec_opts().report_tensor_allocations_upon_oom() ||
request->exec_opts().record_timeline() ||
request->exec_opts().record_costs()) {
collector = new StepStatsCollector(response->mutable_step_stats());
}
DeviceProfilerSession* device_profiler_session = nullptr;
if (collector && request->exec_opts().record_timeline()) {
// If timeline was requested, assume we want hardware level tracing.
device_profiler_session = DeviceProfilerSession::Create().release();
}
CancellationManager* cm = new CancellationManager;
opts->SetCancelCallback([this, cm, step_id]() {
cm->StartCancel();
AbortStep(step_id);
});
CancellationToken token;
token = cancellation_manager_.get_cancellation_token();
bool already_cancelled = !cancellation_manager_.RegisterCallback(
token, [cm]() { cm->StartCancel(); });
if (already_cancelled) {
opts->ClearCancelCallback();
delete cm;
delete collector;
delete device_profiler_session;
delete out;
done(errors::Aborted("Call was aborted"));
return;
}
session->graph_mgr()->ExecuteAsync(
request->graph_handle(), step_id, session.get(), request->exec_opts(),
collector, response, cm, in,
[this, step_id, response, session, cm, out, token, collector,
device_profiler_session, opts, done](const Status& status) {
Status s = status;
if (s.ok()) {
// 接受张量
s = session->graph_mgr()->RecvOutputs(step_id, out);
}
opts->ClearCancelCallback();
cancellation_manager_.DeregisterCallback(token);
delete cm;
if (device_profiler_session) {
device_profiler_session->CollectData(response->mutable_step_stats())
.IgnoreError();
}
if (s.ok()) {
for (const auto& p : *out) {
const string& key = p.first;
const Tensor& val = p.second;
response->AddRecv(key, val);
}
}
if (collector) collector->Finalize();
delete collector;
delete device_profiler_session;
delete out;
done(s);
});
}
ExecuteAsync 调用了 StartParallelExecutors 完成并行计算,具体逻辑大致为:
- 找到一个子图;
- 计算子图 cost;
- 生成一个 rendezvous,使用本 session 初始化 rendezvous,后续就是用这个 rendezvous 来通信,rendezvous 利用 session 进行通信;
- 发送张量到 Rendezvous;
- 调用 StartParallelExecutors 执行子计算图;
void GraphMgr::ExecuteAsync(const string& handle, const int64_t step_id,
WorkerSession* session, const ExecutorOpts& opts,
StepStatsCollector* collector,
MutableRunGraphResponseWrapper* response,
CancellationManager* cancellation_manager,
const NamedTensors& in, StatusCallback done) {
const uint64 start_time_usecs = Env::Default()->NowMicros();
profiler::TraceMeProducer activity(
// To TraceMeConsumers in ExecutorState::Process/Finish or RunGraphDone.
[step_id] {
return profiler::TraceMeEncode(
"RunGraph", {{"id", step_id}, {"_r", 1} /*root_event*/});
},
profiler::ContextType::kTfExecutor, step_id,
profiler::TraceMeLevel::kInfo);
// Lookup an item. Holds one ref while executing.
// 找到一个子图
Item* item = nullptr;
{
mutex_lock l(mu_);
auto iter = table_.find(handle);
if (iter != table_.end()) {
item = iter->second;
item->Ref();
}
}
// 计算cost
CostGraphDef* cost_graph = nullptr;
if (response != nullptr) {
cost_graph = response->mutable_cost_graph();
if (opts.record_partition_graphs()) {
for (const ExecutionUnit& unit : item->units) {
GraphDef graph_def;
unit.graph->ToGraphDef(&graph_def);
response->AddPartitionGraph(graph_def);
}
}
}
// 生成一个rendezvous
RemoteRendezvous* rendezvous = worker_env_->rendezvous_mgr->Find(step_id);
// 使用本session初始化rendezvous,后续就是用这个rendezvous来通信,rendezvous 利用session进行通信
Status s = rendezvous->Initialize(session);
CollectiveExecutor::Handle* ce_handle =
item->collective_graph_key != BuildGraphOptions::kNoCollectiveGraphKey
? new CollectiveExecutor::Handle(
worker_env_->collective_executor_mgr->FindOrCreate(step_id),
true)
: nullptr;
// Sends values specified by the caller.
// 发送张量到Rendezvous
size_t input_size = 0;
if (s.ok()) {
std::vector<string> keys;
std::vector<Tensor> tensors_to_send;
keys.reserve(in.size());
tensors_to_send.reserve(in.size());
for (auto& p : in) {
keys.push_back(p.first);
tensors_to_send.push_back(p.second);
input_size += p.second.AllocatedBytes();
}
// 发送张量
s = SendTensorsToRendezvous(rendezvous, nullptr, {}, keys, tensors_to_send);
}
if (!s.ok()) {
done(s);
delete ce_handle;
item->Unref();
rendezvous->Unref();
return;
}
// 执行子计算图
StartParallelExecutors(
handle, step_id, item, rendezvous, ce_handle, collector, cost_graph,
cancellation_manager, session, start_time_usecs,
[item, rendezvous, ce_handle, done, start_time_usecs, input_size,
step_id](const Status& s) {
profiler::TraceMeConsumer activity(
// From TraceMeProducer in GraphMgr::ExecuteAsync.
[step_id] {
return profiler::TraceMeEncode("RunGraphDone", {{"id", step_id}});
},
profiler::ContextType::kTfExecutor, step_id,
profiler::TraceMeLevel::kInfo);
done(s);
metrics::RecordGraphInputTensors(input_size);
metrics::UpdateGraphExecTime(Env::Default()->NowMicros() -
start_time_usecs);
rendezvous->Unref();
item->Unref();
delete ce_handle;
});
}
具体大致如下,ExecuteAsync使用handle来查找Item,进而找到计算图。其中session用来通信和执行,step_id与通信相关,具体可以参见上面代码。

StartParallelExecutors 会启动一个 ExecutorBarrier。当某一个计算设备执行完所分配的 PartitionGraph 后,ExecutorBarrier 计数器将会增加 1,如果所有设备都完成 PartitionGraph 列表的执行,barrier.wait() 阻塞操作将退出。
void GraphMgr::StartParallelExecutors(
const string& handle, int64_t step_id, Item* item, Rendezvous* rendezvous,
CollectiveExecutor::Handle* ce_handle, StepStatsCollector* collector,
CostGraphDef* cost_graph, CancellationManager* cancellation_manager,
WorkerSession* session, int64_t start_time_usecs, StatusCallback done) {
const int num_units = item->units.size();
ScopedStepContainer* step_container = new ScopedStepContainer(
step_id,
[this](const string& name) { device_mgr_->ClearContainers({name}); });
ExecutorBarrier* barrier =
new ExecutorBarrier(num_units, rendezvous,
[this, item, collector, cost_graph, step_container,
done](const Status& s) {
BuildCostModel(item, collector, cost_graph);
done(s);
delete step_container;
});
Executor::Args args;
args.step_id = step_id;
args.rendezvous = rendezvous;
args.collective_executor = ce_handle ? ce_handle->get() : nullptr;
args.cancellation_manager = cancellation_manager;
args.stats_collector = collector;
args.step_container = step_container;
args.sync_on_finish = sync_on_finish_;
args.start_time_usecs = start_time_usecs;
if (LogMemory::IsEnabled()) {
LogMemory::RecordStep(args.step_id, handle);
}
thread::ThreadPool* pool = worker_env_->compute_pool;
using std::placeholders::_1;
// Line below is equivalent to this code, but does one less indirect call:
// args.runner = [pool](std::function<void()> fn) { pool->Schedule(fn); };
auto default_runner = std::bind(&thread::ThreadPool::Schedule, pool, _1);
for (const auto& unit : item->units) {
thread::ThreadPool* device_thread_pool =
unit.device->tensorflow_device_thread_pool();
if (!device_thread_pool) {
args.runner = default_runner;
} else {
args.runner =
std::bind(&thread::ThreadPool::Schedule, device_thread_pool, _1);
}
unit.root->RunAsync(args, barrier->Get());
}
}
对于注册/运行子图,我们用一幅图来小结一下。
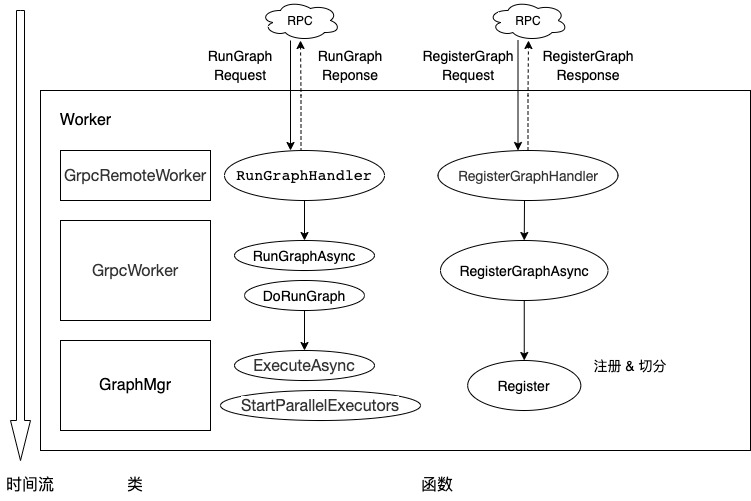
图 1 注册/运行子图
4. 总结我们用一幅图来把整个分布式计算流程总结如下:
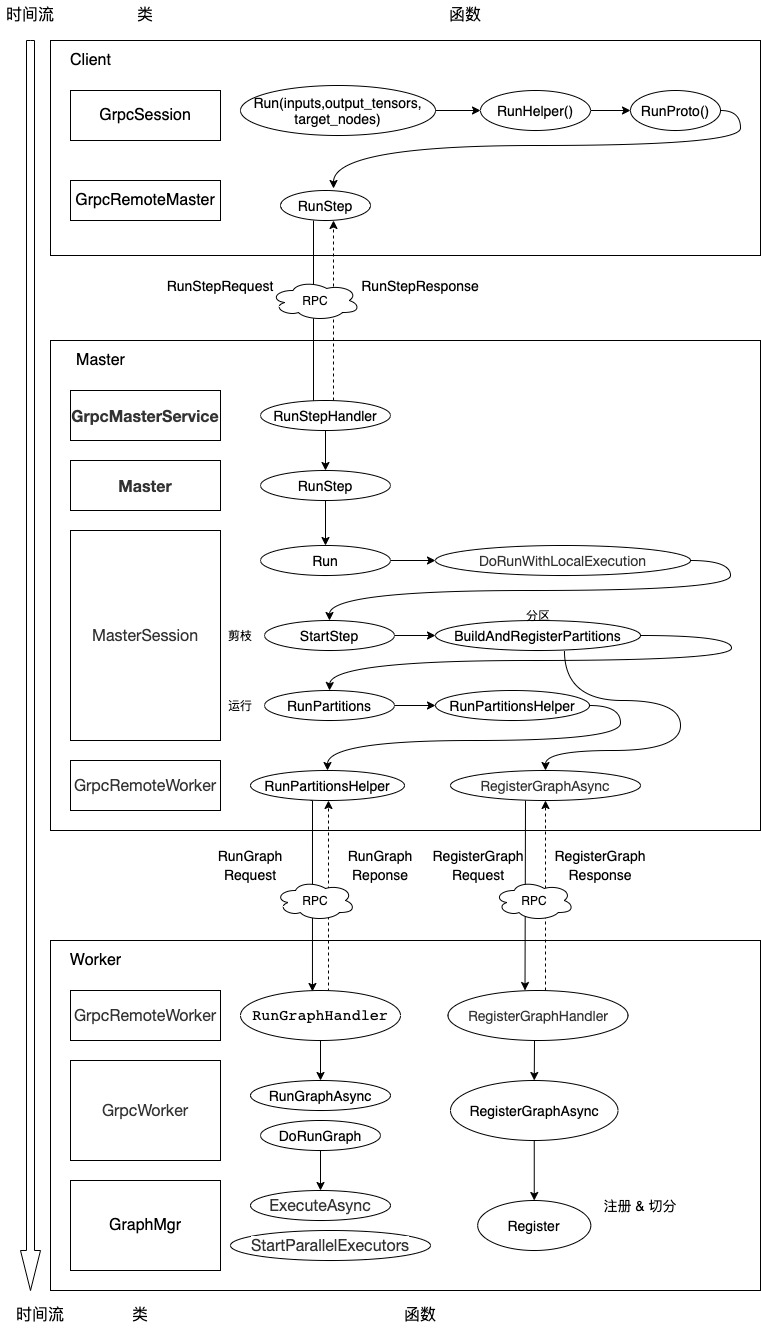
图 2 分布式计算流程
0xFF 参考