Elasticsearch 是一款分布式,RESTful 风格的搜索和数据分析引擎,可以从海量的数据中高效的找到相关信息。如 wiki 用 ES 进行全文检索及其高亮,Github 用其检索代码,电商平台用其做一些商品推荐等,具有丰富的使用场景。
在本篇文章中,主要涉及以下内容:
- ES 的核心功能及其应用场景的介绍
- ES 逻辑架构(文档,索引)的介绍
- ES 物理架构(集群,节点,shard 等)的介绍
- ES 环境安装
- ES 倒排索引
Elasticsearch 核心功能:
- 海量数据分布式存储及其集群管理
- 服务高可用 - 允许有节点停止服务,但集群可正常服务
- 数据高可用 - 允许节点丢失,但不会丢失数据
- 可拓展性 - 很好的面对请求量的提升,和数据的不断增长。
- 大数据实时搜索引擎
- 结构化数据
- 全文数据
- 地理位置
- 近实时分析
- 聚合
Elasticsearch 核心特性:
- 高性能,非 T +1
- 相较于传统关系型数据库,在搜索,算分,模糊查询上有非常好的体验。
- 相较于大数据分析 Hadoop,具有更高效率的统计和分析能力。
- 容易扩展
- 本身分布式架构
- 丰富的社区生态
Lucene 是由 Java 开发的一款搜索引擎类库,具有高性能,易拓展的优点,但由于其接口只能为 Java ,并且不支持水平拓展的局限性。
2004 年 Shay Banon 基于 Lucene 开发了 Compass,2010 年 重写了 Compass,取名 Elasticsearch,使其支持分布式,可水平拓展,并提供 restful 接口,让任何编程语言进行使用。
ES 生态圈ES 常常搭配一些产品提供一些解决方案,如常提到的 ELK 就是,ES,Logstash 和 Kibana 的统称,下图很好的描述了 ES 家族及其生态。
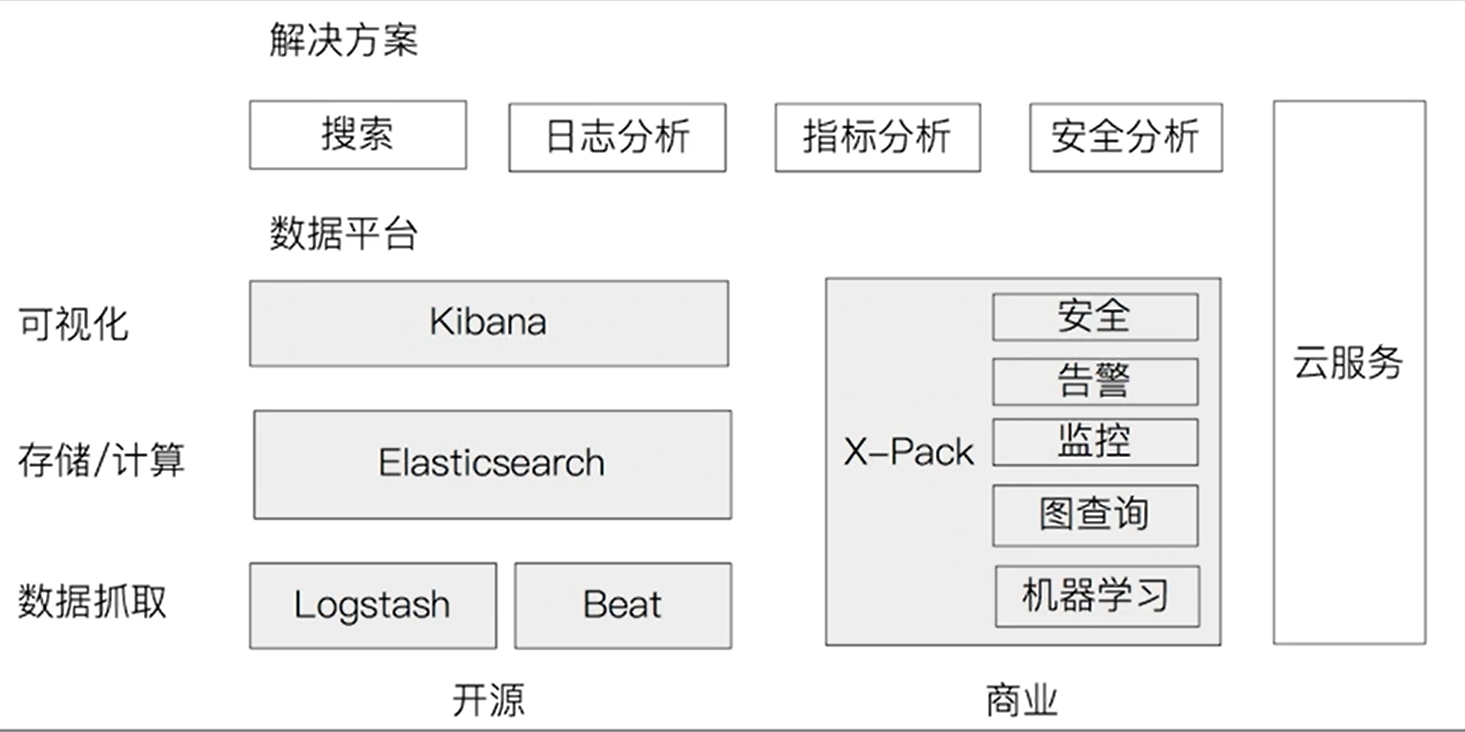
其中 Beat 相较于 Logstash 更加轻量和便携。
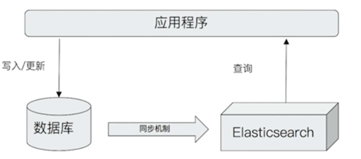
ES 常用案例架构ES 搜索案例,ES 虽然可以单独可以存储引擎,但其无法满足一些事务性的需要,所以常和关系型数据库搭配,采用如下架构:
ES 日志和指标分析案例,一般就是指数据收集,入库,可视化的过程,常采用如下的架构:

ES 有正常安装和 docker 安装两种方式。考虑的安装的方便,推荐 docker 的方式,下面是对应的 compose 文件,直接启动即可。共有 5 个组件,其中 3 个 ES 集群,kibana 作为数据展示和操作 es 的重要工具,cerebro 为查询集群状态的工具。
这里使用的 ES 为 7.1 版本。
# docker-compose.yml
version: '2.2'
services:
cerebro:
image: lmenezes/cerebro:0.8.3
container_name: cerebro
ports:
- "9001:9000"
command:
- -Dhosts.0.host=http://elasticsearch:9200
networks:
- es7net
kibana:
image: docker.elastic.co/kibana/kibana:7.1.0
container_name: kibana7
environment:
- I18N_LOCALE=zh-CN
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
ports:
- "5601:5601"
networks:
- es7net
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_01
environment:
- cluster.name=esdemo
- node.name=es7_01
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01,es7_02,es_03
- cluster.initial_master_nodes=es7_01,es7_02,es_03
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data1:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- es7net
elasticsearch2:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_02
environment:
- cluster.name=esdemo
- node.name=es7_02
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01,es7_02,es_03
- cluster.initial_master_nodes=es7_01,es7_02,es_03
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data2:/usr/share/elasticsearch/data
networks:
- es7net
elasticsearch3:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_03
environment:
- cluster.name=esdemo
- node.name=es7_03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01,es7_02,es_03
- cluster.initial_master_nodes=es7_01,es7_02,es_03
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data3:/usr/share/elasticsearch/data
networks:
- es7net
volumes:
es7data1:
driver: local
es7data2:
driver: local
es7data3:
driver: local
networks:
es7net:
driver: bridge
使用 dockr-compose up 命令创建即可:

这里访问 http://10.124.207.150:5601/ 即可进入,kibana 管理页面。
其中开发者工具是学习 ES 非常好的工具,其自动补全功能,可以很好的熟悉 ES 提供的各种 API.
在讨论 ES 架构前,我们先来区分两种类型的架构:
- 一种偏向于开发人员的视角 - 逻辑架构,其中对应索引,文档等概念。
- 一种偏向于运维人员的视角 - 物理架构,如 节点,集群,分片等。
ES 中最小的单位为 doc,并且是搜索数据的最小单位。文档以 JSON 的格式,保存在 ES 中。每个文档可有不同的字段类型组成。
下面为一个常见文档的举例:
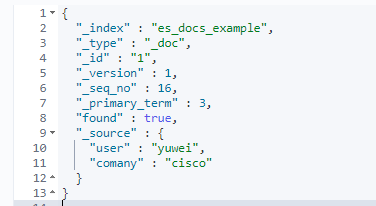
其中:
index 可以理解成所在的索引
_type 表示是文档类型,将来该字段会被废弃,默认都是 doc 类型。
_id 表示唯一标识文档的指示符。
_seq_no 在并发控制会用到,表示并发更新的序列号。
found 表示该 doc 存在。
_source 是我们真正存储到 ES 的信息。
索引Index - 索引,是多个文档的集合,其体现了逻辑空间的概念,每个索引都有自己的 Mapping 定义,表示文档的字段名和类型。
其中索引较为重要的设置分为:
- Mapping 设置:定义了文档字段的类型
- Setting 设置:定义了不同的数据分布。
同样看一个索引的例子:
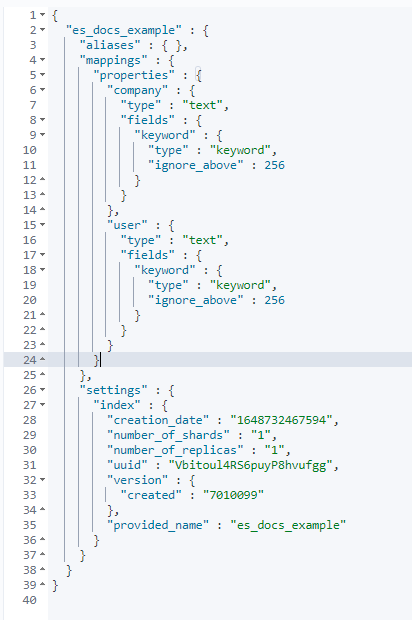
这里的 mapping 定义了 company,user 两个属性。
settings 定义了对应数据以几个分片和副本分布在 ES 中,对应物理架构中的概念。
文档和索引的类比为了方便理解,这里以我们熟悉的关系型数据库进行类比。
其中索引的概念,可以理解成数据库中的一张表,其中 mapping 和 setting 对应表结构和 scheme 的定义。
文档,可以理解成表中的一行记录。
文档中的 field 可以理解成一行记录中的某一列内容。
拿实际情况举例,文档的内容可以想象成日志文件的一条日志记录,一本电影的具体信息,一篇 PDF 文档的内容,一本书的内容等等。
ES 物理架构ES 作为分布式的系统,可以很好的满足可用性和拓展性。集群是分布式系统中一个常见的概念,在 ES 集群中,是由多个 ES 节点组成。而每个节点具有不同的角色。
在最新 ES8 中角色如下:

这里先着重一些常用节点类型:
下图很好的描述了,ES 水平拓展的过程。
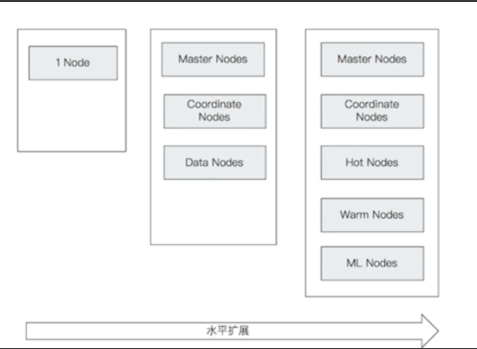
每个 ES 节点,其实就是一个 java 进程,当 ES 集群中只有一个节点时,本身默认就是一个 master eligible 节点。
master 节点会维护集群的状态信息:
- 所有节点的信息
- 所有索引和其相关 Mapping 和 Setting 信息
- 分片的路由信息
ES 在保存数据时,会将数据保存到 Shard 中。Shard 共有两种类型:
- Primary Shard:将数据分布在整个集群内,解决数据水平扩展的问题
- 每个 shard 是一个 lucene 实例
- 数据如何分布在 shard,通过在创建索引时,指定 shard 数量,创建后不允许修改
- Replica Shard:解决数据可用性的问题,是 Primary Shard 的副本
- 副本分片数:可以为 Primary Shard 设置副本的数据,可以动态调整
- 副本可以增加一定的吞吐量
我们知道,ES 在搜索方面有着非常好的性能体验,这很大就取决于 ES 本身使用了倒排索引作为存储的数据结构。
wiki 上对倒排索引的定义是这样:
被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
理解起来很抽象是不是,看一个具体的例子:
假设有这样三句话,我们想要被搜索:
I Love Java.
PHP is the best programming language.
Java awesome.
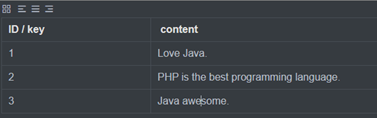
先来看下正排索引的方式,就是常见关系型数据 MySQL 那类的搜索方式。
正排索引:从 id 到内容的查询过程
这里有一行用一个 id 标识对应内容,然后存储
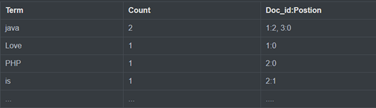
倒排索引:从内容反向查 id 的过程
将每一句话分词后,采用 id 加 位置的形式标识。
比如这里的 java 在文档 1 和 文档 3 都出现了,所以记录了对应的 id 及其 java 在每句话中的位置。
这时我们想搜索 java 的相关文档信息,采用正排索引就需要逐行的遍历,可以想象效率很差。但通过倒排索引,可以很快的找到相关的文档信息。
倒排索引有两部分内容组成:
- 单词词典(Term Dictionary),记录所有文档的单词,以及单词到倒排列表的关系
- 一般具体有 B+ 和哈希拉链发实现
- 倒排列表(Posting List),记录到此对应的文档集合,由倒排索引项组成。
- 倒排索引项:
- 文档 ID
- 词频 TF:该单词在文档中出现的次数,相关性评分
- 位置 - 单词在文档中分词的位置,用于语句搜索。
- 偏移 - 记录单词的开始和结束位置,高亮显示。
- 倒排索引项:
比如上面的 Java 就组成的倒排索引就是这个样子:
当想要搜索 java 时,会查找由 B+ 或者哈希拉链法构成的单词词典,然后根据词典记录的倒排列表关系,获取相应的倒排列表。
总结本篇文章是 ES 部分的第一篇文章,主要对 ES 的基本概念,安装方式,整体架构,数据结构做了整体的入门介绍,便于对 ES 有一定初步的认识,后续的文章对某些部分进入深入的讲解。
最后分享功夫熊猫中的一段话:
昨天已成过去,明天还没有到来,但今天是一个礼物。