- [源码解析] TensorFlow 分布式环境(6) --- Master 动态逻辑
- 1. GrpcSession
- 1.1 运行
- 1.2 GrpcRemoteMaster
- 2. Master
- 2.1 总体概述
- 2.2 建立 & 剪枝
- 2.2.1 建立计算图
- 2.2.2 剪枝
- 2.3 切分注册
- 2.2.1 原理
- 2.2.2 配置
- 2.2.3 切分
- 2.2.3.1 Partition
- 2.2.3.2 AddDummyConst
- 2.2.3.3 AddSend
- 2.2.3.4 AddRecv
- 2.2.3.5 AddInput
- 2.2.3.6 AddReadControl
- 2.2.4 注册
- 2.2.4.1 DoRegisterPartitions
- 2.2.4.2 GrpcRemoteWorker
- 2.4 执行计算图
- 2.4.1 RunPartitions
- 2.4.2 RunPartitionsHelper
- 2.4.3 GrpcRemoteWorker
- 2.5 小结
- 0xFF 参考
- 1. GrpcSession
在具体介绍 TensorFlow 分布式的各种 Strategy 之前,我们首先需要看看分布式的基础:分布式环境。只有把基础打扎实了,才能在以后的分析工作之中最大程度的扫清障碍,事半功倍。本文会从 Client 开始,看看 Master 如何对计算图进行处理。
本文依旧深度借鉴了两位大神:
- [TensorFlow Internals] (https://github.com/horance-liu/tensorflow-internals),虽然其分析的不是最新代码,但是建议对 TF 内部实现机制有兴趣的朋友都去阅读一下,绝对大有收获。
- https://home.cnblogs.com/u/deep-learning-stacks/ 西门宇少,不仅仅是 TensorFlow,其公共号还有更多其他领域,业界前沿。
本系列其他文章是:
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(5) --- Session
1. GrpcSession 1.1 运行首先,客户会调用 GrpcSession 来开始运行,而 Run 方法会调用 RunHelper。
Status GrpcSession::Run(const RunOptions& run_options,
const std::vector<std::pair<string, Tensor>>& inputs,
const std::vector<string>& output_tensor_names,
const std::vector<string>& target_node_names,
std::vector<Tensor>* outputs,
RunMetadata* run_metadata) {
return RunHelper(run_options, inputs, output_tensor_names, target_node_names,
outputs, run_metadata, /* prun_handle */ "");
}
RunHelper 方法如下,这里重要的是添加 feed 和 fetch,然后调用 RunProto 运行 session。
Status GrpcSession::RunHelper(
const RunOptions& run_options,
const std::vector<std::pair<string, Tensor>>& inputs,
const std::vector<string>& output_tensor_names,
const std::vector<string>& target_node_names, std::vector<Tensor>* outputs,
RunMetadata* run_metadata, const string& prun_handle) {
// Convert to proto
std::unique_ptr<MutableRunStepRequestWrapper> req(
master_->CreateRunStepRequest());
std::unique_ptr<MutableRunStepResponseWrapper> resp(
master_->CreateRunStepResponse());
*req->mutable_options() = run_options;
if (run_options.timeout_in_ms() == 0) {
req->mutable_options()->set_timeout_in_ms(
options_.config.operation_timeout_in_ms());
}
if (!prun_handle.empty()) {
req->set_partial_run_handle(prun_handle);
}
for (const auto& it : inputs) {
req->add_feed(it.first, it.second);
}
// Support long error messages by storing the error code in the response body.
req->set_store_errors_in_response_body(true);
// Build an index from fetch tensor name to first index in
// output_tensor_names.
std::unordered_map<string, int> output_name_to_offset;
for (int i = 0, end = output_tensor_names.size(); i < end; ++i) {
const string& name = output_tensor_names[i];
if (output_name_to_offset.insert(std::make_pair(name, i)).second) {
req->add_fetch(name);
}
}
for (const string& target : target_node_names) {
req->add_target(target);
}
CallOptions call_options;
call_options.SetTimeout(req->options().timeout_in_ms());
// 调用 RunProto 运行session
TF_RETURN_IF_ERROR(RunProto(&call_options, req.get(), resp.get()));
// Look for an extended error returned in the response body.
if (resp->status_code() != error::Code::OK) {
return resp->status();
}
if (!output_tensor_names.empty()) {
outputs->resize(output_tensor_names.size());
}
// Convert response back to Tensors in the correct order.
for (size_t i = 0; i < resp->num_tensors(); ++i) {
auto fetch_it = output_name_to_offset.find(resp->tensor_name(i));
if (fetch_it == output_name_to_offset.end()) {
return errors::Internal("Received response for unrequested fetch: ",
resp->tensor_name(i));
}
Tensor output;
TF_RETURN_IF_ERROR(resp->TensorValue(i, &output));
(*outputs)[fetch_it->second] = output;
}
// In the unlikely event that output_tensor_names contains duplicates, fill in
// the duplicate values.
if (output_name_to_offset.size() != output_tensor_names.size()) {
for (int i = 0, end = output_tensor_names.size(); i < end; ++i) {
const string& name = output_tensor_names[i];
int offset = output_name_to_offset[name];
if (offset != i) {
(*outputs)[i] = (*outputs)[offset];
}
}
}
if (run_metadata) {
run_metadata->Swap(resp->mutable_metadata());
}
return Status::OK();
}
最终 RunProto 还是调用到 master_->RunStep 完成业务功能。
Status GrpcSession::RunProto(CallOptions* call_options,
MutableRunStepRequestWrapper* req,
MutableRunStepResponseWrapper* resp) {
string handle;
TF_RETURN_IF_ERROR(Handle(&handle));
req->set_session_handle(handle);
return master_->RunStep(call_options, req, resp);
}
master_ 就是 GrpcRemoteMaster,所以我们接着看下去。
1.2 GrpcRemoteMasterGrpcRemoteMaster 是位于 Client 的 gRPC 客户端实现,它的 RunStep 方法只是通过 gRPC stub 来调用 远端服务 MasterService 的 RunStep 接口,其实就是发送一个 RunStepRequest 请求。
Status RunStep(CallOptions* call_options, RunStepRequestWrapper* request,
MutableRunStepResponseWrapper* response) override {
return CallWithRetry(call_options, &request->ToProto(),
get_proto_from_wrapper(response),
&MasterServiceStub::RunStep, "RunStep/Client");
}
于是,此时 Client 的逻辑拓展如下:

图 1 Master 动态逻辑 1
2. Master从现在开始,我们进入到了 Master 角色对应的服务器。GrpcMasterService 运行的是 gRPC 服务,当收到 RunStepRequest 时候,系统会调用到 RunStepHandler。代码位于:tensorflow/core/distributed_runtime/rpc/grpc_master_service.cc。
// RPC handler for running one step in a session.
void RunStepHandler(MasterCall<RunStepRequest, RunStepResponse>* call) {
auto* trace = TraceRpc("RunStep/Server", call->client_metadata());
CallOptions* call_opts = new CallOptions;
if (call->request.options().timeout_in_ms() > 0) {
call_opts->SetTimeout(call->request.options().timeout_in_ms());
} else {
call_opts->SetTimeout(default_session_config_.operation_timeout_in_ms());
}
RunStepRequestWrapper* wrapped_request =
new ProtoRunStepRequest(&call->request);
MutableRunStepResponseWrapper* wrapped_response =
new NonOwnedProtoRunStepResponse(&call->response);
call->SetCancelCallback([call_opts]() { call_opts->StartCancel(); });
master_impl_->RunStep(
call_opts, wrapped_request, wrapped_response,
[call, call_opts, wrapped_request, trace](const Status& status) {
call->ClearCancelCallback();
delete call_opts;
delete wrapped_request;
delete trace;
if (call->request.store_errors_in_response_body() && !status.ok()) {
call->response.set_status_code(status.code());
call->response.set_status_error_message(status.error_message());
call->SendResponse(ToGrpcStatus(Status::OK()));
} else {
call->SendResponse(ToGrpcStatus(status));
}
});
ENQUEUE_REQUEST(RunStep, true);
}
master_impl_ 是 Master 实例,RunStep 会调用master session进行计算。
void Master::RunStep(CallOptions* opts, const RunStepRequestWrapper* req,
MutableRunStepResponseWrapper* resp, MyClosure done) {
// 获取session
auto session = FindMasterSession(req->session_handle());
// 运行session
SchedClosure([this, start_time, session, opts, req, resp, done]() {
Status status = session->Run(opts, *req, resp);
});
}
现在我们正式进入到 Master 的业务逻辑,接下来就看看如何进一步处理。
2.1 总体概述我们先来做一下总体概述。在 Master 上:
- 首先完成对 FullGraph 的剪枝,生成 ClientGraph。
- 然后,按照 Worker 维度将 ClientGraph 切分为多个 PartitionGraph。
- 最后,将 PartitionGraph 列表注册给各个 Worker(这里有一个 RPC 操作),并启动各个 Worker 对 PartitionGraph 列表进行并发执行(这里有一个 RPC 操作)。
结合代码来看如下。首先,Master 会调用 FindMasterSession 找到 session_handle 对应的 MasterSession,这之后,逻辑就由 MasterSession 来接管。
MasterSession* Master::FindMasterSession(const string& handle) {
MasterSession* session = nullptr;
{
mutex_lock l(mu_);
session = gtl::FindPtrOrNull(sessions_, handle);
if (session != nullptr) {
session->Ref();
}
}
return session;
}
其次,MasterSession::Run 有两种调用可能,我们这里选择 DoRunWithLocalExecution 来分析。
Status MasterSession::Run(CallOptions* opts, const RunStepRequestWrapper& req,
MutableRunStepResponseWrapper* resp) {
UpdateLastAccessTime();
{
mutex_lock l(mu_);
if (closed_) {
return errors::FailedPrecondition("Session is closed.");
}
++num_running_;
// Note: all code paths must eventually call MarkRunCompletion()
// in order to appropriate decrement the num_running_ counter.
}
Status status;
if (!req.partial_run_handle().empty()) {
status = DoPartialRun(opts, req, resp);
} else {
status = DoRunWithLocalExecution(opts, req, resp);
}
return status;
}
DoRunWithLocalExecution 会做三个主要操作:
- StartStep 将调用 BuildGraph 来生成 ClientGraph,这里会进行剪枝。
- BuildAndRegisterPartitions 将 计算图按 location 不同切分为多个子图。
- RunPartitions 执行子图。这里的一个子图就对应一个 worker,就是对应一个 worker service。
Status MasterSession::DoRunWithLocalExecution(
CallOptions* opts, const RunStepRequestWrapper& req,
MutableRunStepResponseWrapper* resp) {
PerStepState pss;
pss.start_micros = Env::Default()->NowMicros();
auto cleanup = gtl::MakeCleanup([this] { MarkRunCompletion(); });
// Prepare.
BuildGraphOptions bgopts;
BuildBuildGraphOptions(req, session_opts_.config, &bgopts);
ReffedClientGraph* rcg = nullptr;
int64 count;
// StartStep 将调用 BuildGraph 来生成 ClientGraph,这里会进行剪枝
TF_RETURN_IF_ERROR(StartStep(bgopts, false, &rcg, &count));
// Unref "rcg" when out of scope.
core::ScopedUnref unref(rcg);
// 对计算图进行切分
TF_RETURN_IF_ERROR(BuildAndRegisterPartitions(rcg));
// Keeps the highest 8 bits 0x01: we reserve some bits of the
// step_id for future use.
uint64 step_id = NewStepId(rcg->collective_graph_key());
std::unique_ptr<ProfileHandler> ph;
FillPerStepState(rcg, req.options(), step_id, count, &pss, &ph);
if (pss.collect_partition_graphs &&
session_opts_.config.experimental().disable_output_partition_graphs()) {
return errors::InvalidArgument(
"RunOptions.output_partition_graphs() is not supported when "
"disable_output_partition_graphs is true.");
}
// 执行计算图
Status s = rcg->RunPartitions(env_, step_id, count, &pss, opts, req, resp,
&cancellation_manager_, false);
cleanup.release(); // MarkRunCompletion called in PostRunCleanup().
return PostRunCleanup(rcg, step_id, req.options(), &pss, ph, s,
resp->mutable_metadata());
}
我们接下来对 DoRunWithLocalExecution 三个主要操作一一分析。
2.2 建立 & 剪枝 2.2.1 建立计算图StartStep 关键是建立计算图并且做剪枝。
Status MasterSession::StartStep(const BuildGraphOptions& opts, bool is_partial,
ReffedClientGraph** out_rcg,
int64_t* out_count) {
const uint64 hash = HashBuildGraphOptions(opts);
{
mutex_lock l(mu_);
RCGMap* m = is_partial ? &partial_run_graphs_ : &run_graphs_;
auto iter = m->find(hash);
if (iter == m->end()) {
// We have not seen this subgraph before. Build the subgraph and
// cache it.
std::unique_ptr<ClientGraph> client_graph;
// 建立计算图
TF_RETURN_IF_ERROR(execution_state_->BuildGraph(opts, &client_graph));
WorkerCacheInterface* worker_cache = get_worker_cache();
auto entry = new ReffedClientGraph(
handle_, opts, std::move(client_graph), session_opts_,
stats_publisher_factory_, is_partial, worker_cache,
!should_delete_worker_sessions_);
iter = m->insert({hash, entry}).first;
}
*out_rcg = iter->second;
(*out_rcg)->Ref();
*out_count = (*out_rcg)->get_and_increment_execution_count();
}
return Status::OK();
}
BuildGraph 之中最关键的是调用 PruneGraph 进行剪枝。
Status GraphExecutionState::BuildGraph(const BuildGraphOptions& options,
std::unique_ptr<ClientGraph>* out) {
// Grappler optimization might change the structure of a graph itself, and
// also it can add/prune functions to/from the library.
std::unique_ptr<Graph> optimized_graph;
std::unique_ptr<FunctionLibraryDefinition> optimized_flib;
Status s = OptimizeGraph(options, *graph_, flib_def_.get(), &optimized_graph,
&optimized_flib);
if (!s.ok()) {
// Simply copy the original graph and the function library if we couldn't
// optimize it.
optimized_graph.reset(new Graph(flib_def_.get()));
CopyGraph(*graph_, optimized_graph.get());
optimized_flib.reset(new FunctionLibraryDefinition(*flib_def_));
}
subgraph::RewriteGraphMetadata rewrite_metadata;
if (session_options_ == nullptr ||
!session_options_->config.graph_options().place_pruned_graph()) {
TF_RETURN_IF_ERROR( // PruneGraph 会进行剪枝
PruneGraph(options, optimized_graph.get(), &rewrite_metadata));
} else {
// This GraphExecutionState represents a graph that was
// pruned when this was constructed, so we copy the metadata from
// a member variable.
CHECK(rewrite_metadata_);
rewrite_metadata = *rewrite_metadata_;
}
GraphOptimizationPassOptions optimization_options;
optimization_options.session_options = session_options_;
optimization_options.graph = &optimized_graph;
optimization_options.flib_def = optimized_flib.get();
optimization_options.device_set = device_set_;
TF_RETURN_IF_ERROR(OptimizationPassRegistry::Global()->RunGrouping(
OptimizationPassRegistry::POST_REWRITE_FOR_EXEC, optimization_options));
int64_t collective_graph_key = options.collective_graph_key;
if (collective_graph_key == BuildGraphOptions::kNoCollectiveGraphKey) {
// BuildGraphOptions does not specify a collective_graph_key. Check all
// nodes in the Graph and FunctionLibraryDefinition for collective ops and
// if found, initialize a collective_graph_key as a hash of the ordered set
// of instance keys.
std::set<int32> instance_key_set;
bool has_collective_v2 = false;
for (Node* node : optimized_graph->nodes()) {
if (node->IsCollective()) {
int32_t instance_key;
TF_RETURN_IF_ERROR(
GetNodeAttr(node->attrs(), "instance_key", &instance_key));
instance_key_set.emplace(instance_key);
} else if (IsCollectiveV2(node->type_string())) {
has_collective_v2 = true;
} else {
const FunctionDef* fdef = optimized_flib->Find(node->def().op());
if (fdef != nullptr) {
for (const NodeDef& ndef : fdef->node_def()) {
if (ndef.op() == "CollectiveReduce" ||
ndef.op() == "CollectiveBcastSend" ||
ndef.op() == "CollectiveBcastRecv" ||
ndef.op() == "CollectiveGather") {
int32_t instance_key;
TF_RETURN_IF_ERROR(
GetNodeAttr(ndef, "instance_key", &instance_key));
instance_key_set.emplace(instance_key);
} else if (IsCollectiveV2(ndef.op())) {
has_collective_v2 = true;
}
}
}
}
}
if (!instance_key_set.empty()) {
uint64 hash = 0x8774aa605c729c72ULL;
for (int32_t instance_key : instance_key_set) {
hash = Hash64Combine(instance_key, hash);
}
collective_graph_key = hash;
} else if (has_collective_v2) {
collective_graph_key = 0x8774aa605c729c72ULL;
}
}
// Make collective execution order deterministic if needed.
if (options.collective_order != GraphCollectiveOrder::kNone) {
TF_RETURN_IF_ERROR(
OrderCollectives(optimized_graph.get(), options.collective_order));
}
// Copy the extracted graph in order to make its node ids dense,
// since the local CostModel used to record its stats is sized by
// the largest node id.
std::unique_ptr<ClientGraph> dense_copy(
new ClientGraph(std::move(optimized_flib), rewrite_metadata.feed_types,
rewrite_metadata.fetch_types, collective_graph_key));
CopyGraph(*optimized_graph, &dense_copy->graph);
metrics::UpdateGraphBuildTime(Env::Default()->NowMicros() - start_time_usecs);
*out = std::move(dense_copy);
return Status::OK();
}
因为单个设备的计算能力和存储都不足,所以需要对大型模型进行模型分片,其本质就是把模型和相关计算进行切分之后分配到不同的设备之上。
TensorFlow的 Placement 机制就是解决模型分片问题,其作用就是标明哪个 operation 放置在哪个设备之上。Placement 这个名词或者说机制最早应该是 Google Spanner 提出来的,其提供跨区数据迁移时管理功能,也有一定的负载均衡意义。TF 的 Placement 借鉴了 Google 的思想,其原则是:尽量满足用户需求;尽量使用计算更快的设备;优先考虑近邻性,避免拷贝;确保分配之后的程序可以运行。
Placement 机制完成之后,每个节点就拥有了Placement信息,而 Partition 方法就可以根据这些节点的信息对计算图进行切分。
2.2.2 配置BuildAndRegisterPartitions 之中会调用 RegisterPartitions 切分注册,我们首先关注的是这里如何配置切分。可以看到,其使用 SplitByWorker 做了切分标准。
Status MasterSession::BuildAndRegisterPartitions(ReffedClientGraph* rcg) {
// 为切分做配置
PartitionOptions popts;
popts.node_to_loc = SplitByWorker; // 被worker切分
popts.new_name = [this](const string& prefix) {
mutex_lock l(mu_);
return strings::StrCat(prefix, "_S", next_node_id_++);
};
popts.get_incarnation = [this](const string& name) -> int64 {
Device* d = devices_->FindDeviceByName(name);
if (d == nullptr) {
return PartitionOptions::kIllegalIncarnation;
} else {
return d->attributes().incarnation();
}
};
popts.control_flow_added = false; // 控制流
const bool enable_bfloat16_sendrecv =
session_opts_.config.graph_options().enable_bfloat16_sendrecv();
// 是否cast
popts.should_cast = [enable_bfloat16_sendrecv](const Edge* e) {
if (e->IsControlEdge()) {
return DT_FLOAT;
}
DataType dtype = BaseType(e->src()->output_type(e->src_output()));
if (enable_bfloat16_sendrecv && dtype == DT_FLOAT) {
return DT_BFLOAT16;
} else {
return dtype;
}
};
if (session_opts_.config.graph_options().enable_recv_scheduling()) {
popts.scheduling_for_recvs = true;
popts.need_to_record_start_times = true;
}
// 切分注册子图
TF_RETURN_IF_ERROR(rcg->RegisterPartitions(std::move(popts)));
return Status::OK();
}
SplitByWorker 方法如下。
static string SplitByWorker(const Node* node) {
string task;
string device;
CHECK(DeviceNameUtils::SplitDeviceName(node->assigned_device_name(), &task,
&device))
<< "node: " << node->name() << " dev: " << node->assigned_device_name();
return task;
}
BuildAndRegisterPartitions 然后调用了 RegisterPartitions,RegisterPartitions 会调用 DoBuildPartitions 进行分区,调用 DoRegisterPartitions 注册分区。
Status MasterSession::ReffedClientGraph::RegisterPartitions(
PartitionOptions popts) {
{ // Ensure register once.
mu_.lock();
if (client_graph_before_register_) {
// The `ClientGraph` is no longer needed after partitions are registered.
// Since it can account for a large amount of memory, we consume it here,
// and it will be freed after concluding with registration.
std::unique_ptr<ClientGraph> client_graph;
std::swap(client_graph_before_register_, client_graph);
mu_.unlock();
std::unordered_map<string, GraphDef> graph_defs;
popts.flib_def = client_graph->flib_def.get();
// 进行分区
Status s = DoBuildPartitions(popts, client_graph.get(), &graph_defs);
if (s.ok()) {
// NOTE(mrry): The pointers in `graph_defs_for_publishing` do not remain
// valid after the call to DoRegisterPartitions begins, so
// `stats_publisher_` must make a copy if it wants to retain the
// GraphDef objects.
std::vector<const GraphDef*> graph_defs_for_publishing;
graph_defs_for_publishing.reserve(partitions_.size());
for (const auto& name_def : graph_defs) {
graph_defs_for_publishing.push_back(&name_def.second);
}
stats_publisher_->PublishGraphProto(graph_defs_for_publishing);
// 注册分区
s = DoRegisterPartitions(popts, std::move(graph_defs));
}
mu_.lock();
init_result_ = s;
init_done_.Notify();
} else {
mu_.unlock();
init_done_.WaitForNotification();
mu_.lock();
}
const Status result = init_result_;
mu_.unlock();
return result;
}
}
DoBuildPartitions 会调用 Partition 正式进入切分。
#include "tensorflow/core/graph/graph_partition.h"
Status MasterSession::ReffedClientGraph::DoBuildPartitions(
PartitionOptions popts, ClientGraph* client_graph,
std::unordered_map<string, GraphDef>* out_partitions) {
if (popts.need_to_record_start_times) {
CostModel cost_model(true);
cost_model.InitFromGraph(client_graph->graph);
// TODO(yuanbyu): Use the real cost model.
// execution_state_->MergeFromGlobal(&cost_model);
SlackAnalysis sa(&client_graph->graph, &cost_model);
sa.ComputeAsap(&popts.start_times);
}
// Partition the graph.
return Partition(popts, &client_graph->graph, out_partitions);
}
Partition 的主要逻辑如下:
- 切分原计算图,产生多个子图。
- 如果跨设备的节点互相有依赖,则插入 Send 和 Recv 节点对。
- 如果需要,插入 Control Flow 边。
具体来说是:
- 分析原计算图。补齐控制流边。
- 为控制流的分布式执行添加 "代码"。只为放在多个设备上的框架(frames)添加代码。新图是原图的等价变换,并且具有这样的特性:它可以随后被任意分割(低至单个设备的水平),以便分布式执行。
- 为每个 operator 的节点/边构建 Memory/Device 信息,也是为了切分做准备。
- TF 希望参与计算的张量被分配到设备上,参与控制的张量被分配到 Host 之上,所以需要对每个 op 进行分析,确定其在 CPU 或者 GPU 上的版本,也需要确定其输入和输出张量的内存信息,比如某些 op 虽然位于 GPU 之上但是依然需要从 CPU 读取数据,又比如有些数据需要强制放到 CPU 之上因为其对 GPU 不友好。
- 遍历图的节点进行分析和切分,插入 Send/Recv 节点和控制边,最终得到多个子图。
- 从原图取出一个节点 dst,拿到 dst 的 location 信息,依据 location 信息拿到其在 partitions 之中的GraphDef,添加 Node,设置设备。
- 将 dst 在原来图之中的输入边分析出来,连同控制边一起,插入到 inputs 数组之中。
- 取出 dst 的一个输入边,得到边的 src 节点,得到 src 节点的图。
- 如果 src/dst 在同一个图之中,则说明是同样分区和可以兼容的内存类型,则在这个图里面把 src,dst 连接起来,遍历到 dst 下一个边。
- 如果 src/dst 不在同一个图里面,所以需要通信,这样就需要依据 edge, src 等信息构建通信 key,依据 key 在 cache 之中查找 Recv 节点,如果找到了,就把 Recv 节点和 dst 节点连起来,遍历到 dst 下一个边。
- 如果存在控制边,因为是跨设备,需要把这种依赖关系跨设备等价表示出来。所以虽然控制边不真正传输张量,也需要发一个消息给接受方,这样接收方才知道有一个依赖关系。所以在src设备上插入一个 dummy const node,在接收方插入一个 identity 节点来读取这个 shape 是 0 的 dummy const,还需要把 identity 确定为接收方的控制依赖。
- 添加 Send 节点和 Recv 节点。
- 针对控制/数据关系做进一步修复。
- 对于同一设备上的发送/接收节点,它们之间是有数据拷贝操作的,所以添加一个从发送到接收的控制边。这样可以防止异步 recv kernel 在数据可用之前就被调度出去,从而保证了执行顺序。
- 否则是跨设备,需要根据数据流来重定向控制边到真实的 recv 节点。
- 收尾工作,比如完善子图的版本信息,函数库,和send/recv节点的 Incarnation
比如分割之后,如下:

图 2 分割计算图,来自 TensorFlow
插入 Send/Recv 节点之后如下:
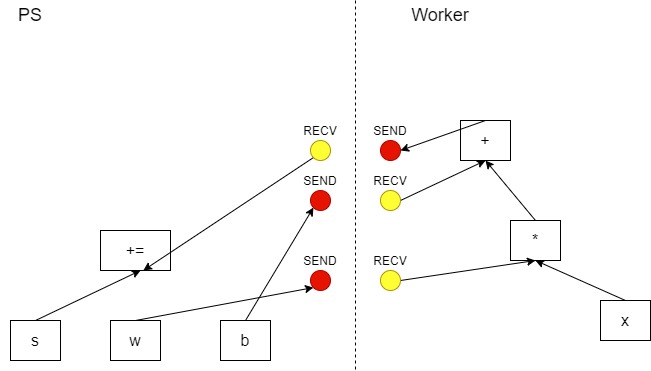
图 3 插入节点,来自 TensorFlow
Partition 代码具体如下,进行大幅精简。
Status Partition(const PartitionOptions& opts, Graph* g,
std::unordered_map<string, GraphDef>* partitions) {
Status status;
partitions->clear();
GraphInfo g_info;
if (!opts.control_flow_added) {
// 分析原计算图。补齐控制流边。
// 为控制流的分布式执行添加 "代码"。只为放在多个设备上的框架(frames)添加代码。新图是原图的等价变换,并且具有这样的特性:它可以随后被任意分割(低至单个设备的水平),以便分布式执行。
status = AddControlFlow(opts, g, &g_info);
if (!status.ok()) return status;
}
// At this point, all the graph mutations have been done. Build memory
// and device type info for every node and edge in the graph.
// 为每个operator的节点/边构建Memory/Device信息,也是为了切分做准备。
// TF希望参与计算的张量被分配到设备上,参与控制的张量被分配到Host之上,所以需要对每个op进行分析,确定其在CPU或者GPU上的版本,也需要确定其输入和输出张量的内存信息,比如某些op虽然位于GPU之上但是依然需要从CPU读取数据,而有些数据需要强制放到CPU之上因为其对GPU不友好。
status = BuildMemoryDeviceInfo(*g, &g_info);
if (!status.ok()) return status;
string dstp;
std::vector<const Edge*> inputs;
DupRecvTable dup_recv(3);
// 对于一个节点dst,'ref_recvs'是由ref边引入到dst的recvs。ref_control_inputs'是由非ref到dst的输入。
// 对于(ref_recvs x ref_control_inputs)之中每一个pair,我们增加一个控制边
std::vector<NodeDef*> ref_recvs;
std::vector<string> ref_control_inputs;
int32_t num_data = 0;
int32_t num_control = 0;
for (const Node* dst : g->op_nodes()) { // 遍历图的节点进行分析和切分,插入Send/Recv节点和控制边
// 从原图取出一个节点dst
dstp = opts.node_to_loc(dst); // 拿到dst的location信息
GraphDef* dst_graph = &(*partitions)[dstp]; // 依据location信息拿到其在partitions之中的GraphDef
NodeDef* dst_def = dst_graph->add_node(); // 添加Node
*dst_def = dst->def();
dst_def->set_device(dst->assigned_device_name()); // 设置设备
dst_def->clear_input(); // Inputs are filled below
// Arrange the incoming edges to dst so that input[i] holds the
// input flowing into slot numbered i. Trailing entries in input[]
// hold control edges.
// 将dst在原来图之中的输入边分析出来,连同控制边一起,插入到inputs数组之中。
inputs.clear();
inputs.resize(dst->num_inputs(), nullptr);
ref_recvs.clear();
ref_control_inputs.clear();
const Edge* control_flow_edge = nullptr;
int32_t num_control_flow_edges = 0;
int32_t num_input_edges = 0;
for (const Edge* edge : dst->in_edges()) {
if (edge->IsControlEdge()) {
if (IsMerge(edge->src()) && IsControlLoop(edge->src())) {
// This is one of the control edges added for control flow. There
// can be multiple such edges as the dest node may have multiple
// remote inputs. We keep track of the number of such edges.
control_flow_edge = edge;
++num_control_flow_edges;
} else {
inputs.push_back(edge);
}
} else {
DCHECK(inputs[edge->dst_input()] == nullptr);
inputs[edge->dst_input()] = edge;
++num_input_edges;
}
}
// Process in order so that all data edges are added as inputs to
// dst in Edge::dst_input() order.
for (const Edge* edge : inputs) { // 取出dst的一个边
const Node* src = edge->src(); // 得到边的src节点
if (!src->IsOp()) continue; // Skip Sink/Source nodes.
GraphDef* src_graph = &(*partitions)[opts.node_to_loc(src)]; // 调用配置的 SplitByWorker 或者 SplitByDevice 进行分区,得到src节点的图
if (src_graph == dst_graph && !NeedSameDeviceSendRecv(edge, g_info)) {
// 在同一个图之中,则说明是同样分区和可以兼容的内存类型,则在这个图里面把src,dst连接起来
// Same partition and compatible memory types:
AddInput(dst_def, src->name(), edge->src_output());
if (edge->IsControlEdge() ||
!IsRefType(src->output_type(edge->src_output()))) {
ref_control_inputs.push_back(src->name());
}
continue; // 遍历到dst下一个边
}
// Check whether there is already a send/recv pair transferring
// the same tensor/control from the src to dst partition.
const bool on_host = IsDstInputOnHost(edge, g_info);
// 因为不在同一个图里面,所以需要通信,这样就需要依据edge, src等信息构建通信key
DupRecvKey key{src->id(), edge->src_output(), dst_graph, on_host};
auto iter = dup_recv.find(key); // 依据key在cache之中查找Recv节点
if (iter != dup_recv.end()) { // 如果找到了,就把Recv节点和dst节点连起来
// We found one. Reuse the data/control transferred already.
const string& recv_node_name = iter->second.recv->name();
if (edge->IsControlEdge()) {
AddInput(dst_def, recv_node_name, Graph::kControlSlot);
} else {
AddInput(dst_def, recv_node_name, 0);
}
ref_control_inputs.push_back(recv_node_name);
continue; // 遍历到dst下一个边
}
// 添加Send节点和Recv节点
NodeDefBuilder::NodeOut send_from; // 设定发送节点信息
if (edge->IsControlEdge()) {
// Insert a dummy const node that will generate a tiny
// data element to be sent from send to recv.
// 如果存在控制边,因为是跨设备,需要把这种依赖关系跨设备等价表示出来。
// 所以虽然控制边不真正传输张量,也需要发一个消息给接受方,这样接收方才知道有一个依赖关系。所以在src设备上插入一个dummy const node,在接收方插入一个identity节点来读取这个shape是0的dummy const,还需要把identity确定为接收方的控制依赖
NodeDef* dummy = AddDummyConst(opts, src_graph, edge, &status);
if (!status.ok()) return status;
AddInput(dummy, src->name(), Graph::kControlSlot);
send_from.Reset(dummy->name(), 0, DT_FLOAT);
} else {
send_from.Reset(src->name(), edge->src_output(), EdgeType(edge));
}
// Need to split edge by placing matching send/recv nodes on
// the src/dst sides of the edge.
NodeDef* send = AddSend(opts, g_info, src_graph, edge, send_from,
send_start_time, &status);
if (!status.ok()) return status;
NodeDef* real_recv = nullptr;
NodeDef* recv =
AddRecv(opts, g_info, dst_graph, edge, &real_recv, &status);
if (!status.ok()) return status;
if (src_graph == dst_graph) {
// For same device send/recv, add a control edge from send to recv.
// This prevents the asynchronous recv kernel from being scheduled
// before the data is available.
// 对于同一设备上的发送/接收节点,它们之间是有数据拷贝操作的,所以添加一个从发送到接收的控制边。这样可以防止异步recv kernel在数据可用之前就被调度出去,从而保证了执行顺序。
AddInput(real_recv, send->name(), Graph::kControlSlot);
} else if (control_flow_edge != nullptr) {
// Redirect control edge to the real recv since this is not the same
// device send/recv.
// 否则是跨设备,需要根据数据流来重定向控制边到真实的recv节点
--num_control_flow_edges;
AddInput(real_recv, control_flow_edge->src()->name(),
Graph::kControlSlot);
}
if (!edge->IsControlEdge() &&
IsRefType(src->output_type(edge->src_output()))) {
// If src is of ref type and the edge is not a control edge, dst has
// read semantics and therefore we must control the recv.
ref_recvs.push_back(real_recv);
} else {
// Memorize the send/recv pair, only if this is not a "ref" edge.
// NOTE(yuanbyu): Collapsing ref edges requires extreme care so
// for now we don't do it.
dup_recv[key] = {recv, real_recv, recv_start_time};
ref_control_inputs.push_back(recv->name());
}
if (edge->IsControlEdge()) {
++num_control;
AddInput(dst_def, recv->name(), Graph::kControlSlot);
} else {
++num_data;
AddInput(dst_def, recv->name(), 0);
}
}
// Add control edges from 'ref_control_inputs' to 'ref_recvs'.
// NOTE(yuanbyu): Adding these control edges should not introduce
// deadlocks. 'dst' has implicit "read" nodes that, when we split
// across devices, are made explicit; Retargeting the dependencies
// to 'dst' to those nodes would not introduce cycles if there isn't
// one before the transformation.
// NOTE(yuanbyu): This may impact performance because it defers the
// execution of recvs until all the other inputs become available.
AddReadControl(ref_recvs, ref_control_inputs);
// Add back the control edges for control flow that are not used.
if (control_flow_edge != nullptr) {
for (int i = 0; i < num_control_flow_edges; ++i) {
AddInput(dst_def, control_flow_edge->src()->name(),
Graph::kControlSlot);
}
}
}
// 收尾工作,比如完善子图的版本信息,函数库,和send/recv节点的Incarnation
const FunctionLibraryDefinition* flib_def = opts.flib_def;
if (flib_def == nullptr) {
flib_def = &g->flib_def();
}
// Set versions, function library and send/recv incarnation.
for (auto& it : *partitions) {
GraphDef* gdef = &it.second;
*gdef->mutable_versions() = g->versions();
// Prune unreachable functions from `flib_def` before adding them to `gdef`.
*gdef->mutable_library() = flib_def->ReachableDefinitions(*gdef).ToProto();
// Traverse the graph to fill every send/recv op's incarnation
// information.
SetIncarnation(opts, gdef);
}
return Status::OK();
}
Partition 用到的部分函数具体如下。
2.2.3.2 AddDummyConst如果存在控制边,因为是跨设备,需要把这种依赖关系跨设备等价表示出来。所以虽然控制边不真正传输张量,也需要发一个消息给接受方,这样接收方才知道有一个依赖关系。
所以在src设备上插入一个 dummy const node 用来表达这种对下游的控制依赖关系,在接收方插入一个 identity节点来读取这个 shape 是 0 的 dummy const,还需要把identity确定为接收方的控制依赖。这样,dummy const node 是生产者,Identity 是消费者角色。就满足了跨设备间的通信需求。
NodeDef* AddDummyConst(const PartitionOptions& opts, GraphDef* gdef,
const Edge* edge, Status* status) {
const Node* src = edge->src();
Tensor tensor(DT_FLOAT, TensorShape({0}));
NodeDef* result = gdef->add_node();
*status = NodeDefBuilder(opts.new_name(src->name()), "Const")
.Device(src->assigned_device_name())
.Attr("dtype", DT_FLOAT)
.Attr("value", tensor)
.Finalize(result, /*consume=*/true);
return result;
}
如果 src 和 dst 分别属于两个 Partition,则需要把原来两者之间的普通边切分开,在它们中间增加 Send 与 Recv 节点,这样就可以将其划归在两个不同 Partition 之内。
NodeDef* AddSend(const PartitionOptions& opts, const GraphInfo& g_info,
GraphDef* gdef, const Edge* edge,
NodeDefBuilder::NodeOut send_from, int64_t start_time,
Status* status) {
const DataType dtype = send_from.data_type;
const DataType cast_dtype = opts.should_cast ? opts.should_cast(edge) : dtype;
const Node* src = edge->src();
const int src_port = edge->src_output();
// host_memory = true iff we need to use HostSend/HostCast.
bool host_memory = false;
if (!edge->IsControlEdge()) {
auto src_it = g_info.output_types.find({src->id(), src_port});
host_memory = (src_it->second == HOST_MEMORY);
}
// Add a cast node that casts dtype to cast_dtype.
// NOTE(yuanbyu): Only cast for cross-device send/recv.
if (dtype != cast_dtype && !NeedSameDeviceSendRecv(edge, g_info)) {
const string cast_op = (host_memory) ? "_HostCast" : "Cast";
NodeDefBuilder cast_builder(opts.new_name(src->name()), cast_op,
NodeDebugInfo(*src));
cast_builder.Device(src->assigned_device_name()).Input(send_from);
cast_builder.Attr("DstT", cast_dtype);
if (cast_dtype == DT_BFLOAT16) {
// the below attribute specifies that the cast to bfloat16 should use
// truncation. This is needed to retain legacy behavior when we change
// the default bfloat16 casts to use rounding instead of truncation
cast_builder.Attr("Truncate", true);
}
NodeDef* cast = gdef->add_node();
*status = cast_builder.Finalize(cast, /*consume=*/true);
if (!status->ok()) return nullptr;
// Connect the Send op to the cast.
send_from.Reset(cast->name(), 0, cast_dtype);
}
// Add the send node.
const string send_op = (host_memory) ? "_HostSend" : "_Send";
NodeDefBuilder send_builder(opts.new_name(src->name()), send_op,
NodeDebugInfo(*src));
SetSendRecvAttrs(opts, edge, &send_builder);
send_builder.Device(src->assigned_device_name()).Input(send_from);
NodeDef* send = gdef->add_node();
*status = send_builder.Finalize(send, /*consume=*/true);
return send;
}
前面提到的在接收方插入一个 identity 节点来读取这个 shape 是 0 的 dummy const,还需要把 identity 确定为接收方的控制依赖,这部分代码在此实现。Identity 是恒等变化,可以直接输出张量,这样既去除了变量的引用标识,也避免了内存拷贝。
NodeDef* AddRecv(const PartitionOptions& opts, const GraphInfo& g_info,
GraphDef* gdef, const Edge* edge, NodeDef** real_recv,
Status* status) {
const DataType dtype = EdgeType(edge);
const Node* src = edge->src();
const Node* dst = edge->dst();
const int dst_port = edge->dst_input();
DataType cast_dtype = dtype;
// NOTE(yuanbyu): Only cast for cross-device send/recv.
if (opts.should_cast && !NeedSameDeviceSendRecv(edge, g_info)) {
cast_dtype = opts.should_cast(edge);
}
// host_memory = true iff we need to use HostRecv/HostCast.
// Also log the introduction of the send-recv pair, for performance debugging.
bool host_memory = false;
if (!edge->IsControlEdge()) {
auto dst_it = g_info.input_types.find({dst->id(), dst_port});
DCHECK(dst_it != g_info.input_types.end());
host_memory = (dst_it->second == HOST_MEMORY);
bool src_host_memory = false;
} else {
// Log control-edge transfers too, but don't mention memory space since it's
// irrelevant.
// 省略log
}
// Add the recv node.
const string recv_op = (host_memory) ? "_HostRecv" : "_Recv";
NodeDefBuilder recv_builder(opts.new_name(src->name()), recv_op,
NodeDebugInfo(*src));
SetSendRecvAttrs(opts, edge, &recv_builder);
recv_builder.Device(dst->assigned_device_name())
.Attr("tensor_type", cast_dtype);
NodeDef* recv = gdef->add_node();
*status = recv_builder.Finalize(recv, /*consume=*/true);
if (!status->ok()) return nullptr;
*real_recv = recv;
// Add the cast node (from cast_dtype to dtype) or an Identity node.
if (dtype != cast_dtype) {
const string cast_op = (host_memory) ? "_HostCast" : "Cast";
NodeDefBuilder cast_builder(opts.new_name(src->name()), cast_op,
NodeDebugInfo(*src));
cast_builder.Attr("DstT", dtype);
cast_builder.Device(dst->assigned_device_name())
.Input(recv->name(), 0, cast_dtype);
NodeDef* cast = gdef->add_node();
*status = cast_builder.Finalize(cast, /*consume=*/true);
if (!status->ok()) return nullptr;
return cast;
} else if (edge->IsControlEdge()) {
// An Identity is only needed for control edges.
// 这里加入了"Identity"。
NodeDefBuilder id_builder(opts.new_name(src->name()), "Identity",
NodeDebugInfo(*src));
id_builder.Device(dst->assigned_device_name())
.Input(recv->name(), 0, cast_dtype);
NodeDef* id = gdef->add_node();
*status = id_builder.Finalize(id, /*consume=*/true);
if (!status->ok()) return nullptr;
return id;
} else {
return recv;
}
}
AddInput 为下游节点增加输入。
// Add an input to dst that comes from the "src_slot" output of the
// node named by "src_name".
void AddInput(NodeDef* dst, StringPiece src_name, int src_slot) {
if (src_slot == Graph::kControlSlot) {
dst->add_input(strings::StrCat("^", src_name));
} else if (src_slot == 0) {
dst->add_input(src_name.data(), src_name.size());
} else {
dst->add_input(strings::StrCat(src_name, ":", src_slot));
}
}
AddReadControl 其实是通过 add_input 完成控制。
// Add a control edge from each input to each recv.
void AddReadControl(const std::vector<NodeDef*>& recvs,
const std::vector<string>& inputs) {
for (NodeDef* recv : recvs) {
for (const string& input : inputs) {
recv->add_input(strings::StrCat("^", input));
}
}
}
现在分区完毕,我们来到了注册阶段。
2.2.4.1 DoRegisterPartitionsDoRegisterPartitions 会设置哪个 worker 负责哪个分区,关键代码是:
-
调用 part->worker = worker_cache_->GetOrCreateWorker(part->name) 来设置每个 part 的 worker。
-
调用 part.worker->RegisterGraphAsync(&c->req, &c->resp, cb) 来注册图。
Status MasterSession::ReffedClientGraph::DoRegisterPartitions(
const PartitionOptions& popts,
std::unordered_map<string, GraphDef> graph_partitions) {
partitions_.reserve(graph_partitions.size());
Status s;
for (auto& name_def : graph_partitions) {
partitions_.emplace_back();
Part* part = &partitions_.back();
part->name = name_def.first;
TrackFeedsAndFetches(part, name_def.second, popts);
part->worker = worker_cache_->GetOrCreateWorker(part->name);
if (part->worker == nullptr) {
s = errors::NotFound("worker ", part->name);
break;
}
}
if (!s.ok()) {
for (Part& part : partitions_) {
worker_cache_->ReleaseWorker(part.name, part.worker);
part.worker = nullptr;
}
return s;
}
struct Call {
RegisterGraphRequest req;
RegisterGraphResponse resp;
Status status;
};
const int num = partitions_.size();
gtl::InlinedVector<Call, 4> calls(num);
BlockingCounter done(num);
for (int i = 0; i < num; ++i) {
const Part& part = partitions_[i];
Call* c = &calls[i];
c->req.set_session_handle(session_handle_);
c->req.set_create_worker_session_called(!should_deregister_);
c->req.mutable_graph_def()->Swap(&graph_partitions[part.name]);
StripDefaultAttributes(*OpRegistry::Global(),
c->req.mutable_graph_def()->mutable_node());
*c->req.mutable_config_proto() = session_opts_.config;
*c->req.mutable_graph_options() = session_opts_.config.graph_options();
*c->req.mutable_debug_options() =
callable_opts_.run_options().debug_options();
c->req.set_collective_graph_key(collective_graph_key_);
auto cb = [c, &done](const Status& s) {
c->status = s;
done.DecrementCount();
};
part.worker->RegisterGraphAsync(&c->req, &c->resp, cb);
}
done.Wait();
for (int i = 0; i < num; ++i) {
Call* c = &calls[i];
s.Update(c->status);
partitions_[i].graph_handle = c->resp.graph_handle();
}
return s;
}
上面的 part.worker->RegisterGraphAsync 会调用到 GrpcRemoteWorker,最终发送 RegisterGraphRequest 给下游 Worker。
tensorflow/core/distributed_runtime/rpc/grpc_remote_worker.cc 之中,RegisterGraphAsync 会调用 rpc。
void RegisterGraphAsync(const RegisterGraphRequest* request,
RegisterGraphResponse* response,
StatusCallback done) override {
IssueRequest(request, response, registergraph_, std::move(done));
}
注意是,除非计算图节点被重新编排,或者 Master 进程被重启,否则Master 只会执行一次 RegisterGraph。概念上具体示意如下:
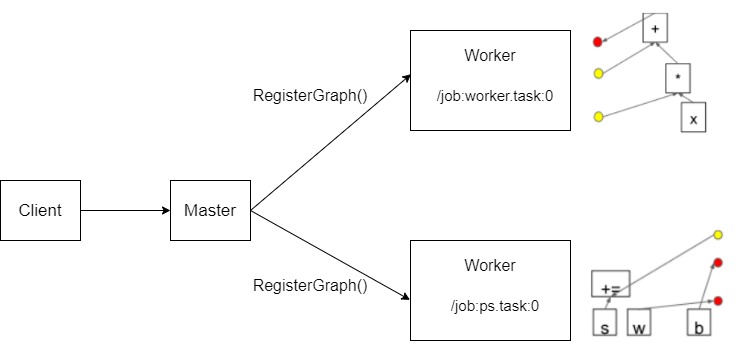
图 4 注册图,来自 TensorFlow
2.4 执行计算图既然已经分区结束,也注册到了远端 Worker 之上,每个worker都拥有自己的子图,接下来就是运行子图。
Master 通过调用 RunGraph 来在 Worker 之上触发子图运算,Worker 会使用 GPU/CPU 运算设备执行TensorFlow Kernel 运算。在 Worker/设备之间会依据情况不同采用不同传输方式:
- 本节点 GPU 和 CPU 之间采用 cudaMemcpyAsync。
- 本节点 GPU 和 GPU 之间采用 peer-to-peer DMA。
- 在 Worker 之间采用 gRPC(TCP) 和 RDMA (Converged Ethernet)。
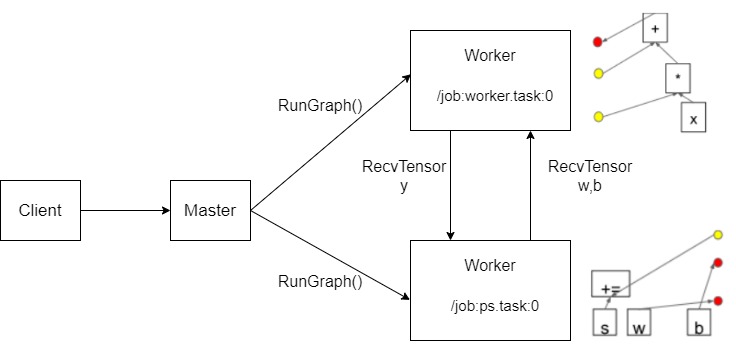
图 5 运行子图
2.4.1 RunPartitionsRunPartitions 调用了 RunPartitionsHelper 执行subgraph。
Status MasterSession::ReffedClientGraph::RunPartitions(
const MasterEnv* env, int64_t step_id, int64_t execution_count,
PerStepState* pss, CallOptions* call_opts, const RunCallableRequest& req,
RunCallableResponse* resp, CancellationManager* cm) {
// Maps the names of fed tensors to their index in `req`.
std::unordered_map<StringPiece, size_t, StringPieceHasher> feeds(3);
for (size_t i = 0, end = callable_opts_.feed_size(); i < end; ++i) {
if (!feeds.insert({callable_opts_.feed(i), i}).second) {
// MakeCallable will fail if there are two feeds with the same name.
return errors::Internal("Duplicated feeds in callable: ",
callable_opts_.feed(i));
}
}
// Create a wrapped response object to collect the fetched values and
// rearrange them for the RunCallableResponse.
RunCallableResponseWrapper wrapped_resp;
wrapped_resp.resp = resp;
// 在这里调用执行
TF_RETURN_IF_ERROR(RunPartitionsHelper(
feeds, callable_opts_.fetch(), env, step_id, execution_count, pss,
call_opts, req, &wrapped_resp, cm, false /* is_last_partial_run */));
// Collects fetches.
for (const string& fetch : callable_opts_.fetch()) {
TensorProto* fetch_proto = resp->mutable_fetch()->Add();
auto iter = wrapped_resp.fetch_key_to_protos.find(fetch);
if (iter == wrapped_resp.fetch_key_to_protos.end()) {
return errors::Internal("Worker did not return a value for fetch: ",
fetch);
}
fetch_proto->Swap(&iter->second);
}
return Status::OK();
}
RunPartitionsHelper执行子图,具体逻辑是:
- 为每一个分区配置一个 RunManyGraphs::Call,给这个 call 配置 request,response,session handle,graph handle,request id,配置 recv key。
- 每个 worker 发送 RunGraphAsync。
- 一个子图分配给一个 worker,对应一个 worker service。
- part.worker 是每个分区对应的 WorkerInterface 对象,如果在远程是 GrpcRemoteWorker 实例,否则是 Worker 实例。
- 注册各种 callback,等待 RunGraphAsync 运行结果。
- 处理运行结果。
template <class FetchListType, class ClientRequestType,
class ClientResponseType>
Status MasterSession::ReffedClientGraph::RunPartitionsHelper(
const std::unordered_map<StringPiece, size_t, StringPieceHasher>& feeds,
const FetchListType& fetches, const MasterEnv* env, int64_t step_id,
int64_t execution_count, PerStepState* pss, CallOptions* call_opts,
const ClientRequestType& req, ClientResponseType* resp,
CancellationManager* cm, bool is_last_partial_run) {
// Collect execution cost stats on a smoothly decreasing frequency.
ExecutorOpts exec_opts;
// 省略统计代码
const int num = partitions_.size();
RunManyGraphs calls(num);
for (int i = 0; i < num; ++i) {
// 为每一个分区配置一个RunManyGraphs::Call
const Part& part = partitions_[i];
RunManyGraphs::Call* c = calls.get(i);
c->worker_name = &part.name;
c->req.reset(part.worker->CreateRunGraphRequest()); // 配置request
c->resp.reset(part.worker->CreateRunGraphResponse()); // 配置response
if (is_partial_) {
c->req->set_is_partial(is_partial_);
c->req->set_is_last_partial_run(is_last_partial_run);
}
c->req->set_session_handle(session_handle_); // 配置session handle
c->req->set_create_worker_session_called(!should_deregister_);
c->req->set_graph_handle(part.graph_handle); // 配置graph handle
c->req->set_step_id(step_id);
*c->req->mutable_exec_opts() = exec_opts;
c->req->set_store_errors_in_response_body(true);
c->req->set_request_id(GetUniqueRequestId()); // 配置request id
// If any feeds are provided, send the feed values together
// in the RunGraph request.
// In the partial case, we only want to include feeds provided in the req.
// In the non-partial case, all feeds in the request are in the part.
// We keep these as separate paths for now, to ensure we aren't
// inadvertently slowing down the normal run path.
if (is_partial_) {
for (const auto& name_index : feeds) {
const auto iter = part.feed_key.find(string(name_index.first));
if (iter == part.feed_key.end()) {
// The provided feed must be for a different partition.
continue;
}
const string& key = iter->second;
TF_RETURN_IF_ERROR(AddSendFromClientRequest(req, c->req.get(),
name_index.second, key));
}
// TODO(suharshs): Make a map from feed to fetch_key to make this faster.
// For now, we just iterate through partitions to find the matching key.
for (const string& req_fetch : fetches) {
for (const auto& key_fetch : part.key_fetch) {
if (key_fetch.second == req_fetch) {
c->req->add_recv_key(key_fetch.first); // 配置 recv key
break;
}
}
}
} else {
for (const auto& feed_key : part.feed_key) {
const string& feed = feed_key.first;
const string& key = feed_key.second;
auto iter = feeds.find(feed);
if (iter == feeds.end()) {
return errors::Internal("No feed index found for feed: ", feed);
}
const int64_t feed_index = iter->second;
TF_RETURN_IF_ERROR(
AddSendFromClientRequest(req, c->req.get(), feed_index, key));
}
for (const auto& key_fetch : part.key_fetch) {
const string& key = key_fetch.first;
c->req->add_recv_key(key); // 配置 recv key
}
}
}
// Issues RunGraph calls.
for (int i = 0; i < num; ++i) {
const Part& part = partitions_[i];
RunManyGraphs::Call* call = calls.get(i);
part.worker->RunGraphAsync( // 每个 worker 发送 RunGraphAsync
&call->opts, call->req.get(), call->resp.get(),
std::bind(&RunManyGraphs::WhenDone, &calls, i, std::placeholders::_1));
}
// Waits for the RunGraph calls.
// 注册各种callback,等待运行结果
call_opts->SetCancelCallback([&calls]() {
calls.StartCancel();
});
auto token = cm->get_cancellation_token();
const bool success =
cm->RegisterCallback(token, [&calls]() { calls.StartCancel(); });
if (!success) {
calls.StartCancel();
}
calls.Wait();
call_opts->ClearCancelCallback();
if (success) {
cm->DeregisterCallback(token);
} else {
return errors::Cancelled("Step was cancelled");
}
// Collects fetches and metadata.
// 处理运行结果
Status status;
for (int i = 0; i < num; ++i) {
const Part& part = partitions_[i];
MutableRunGraphResponseWrapper* run_graph_resp = calls.get(i)->resp.get();
for (size_t j = 0; j < run_graph_resp->num_recvs(); ++j) {
auto iter = part.key_fetch.find(run_graph_resp->recv_key(j));
if (iter == part.key_fetch.end()) {
status.Update(errors::Internal("Unexpected fetch key: ",
run_graph_resp->recv_key(j)));
break;
}
const string& fetch = iter->second;
status.Update(
resp->AddTensorFromRunGraphResponse(fetch, run_graph_resp, j));
if (!status.ok()) {
break;
}
}
if (pss->collect_timeline) {
pss->step_stats[i].Swap(run_graph_resp->mutable_step_stats());
}
if (pss->collect_costs) {
CostGraphDef* cost_graph = run_graph_resp->mutable_cost_graph();
for (int j = 0; j < cost_graph->node_size(); ++j) {
resp->mutable_metadata()->mutable_cost_graph()->add_node()->Swap(
cost_graph->mutable_node(j));
}
}
if (pss->collect_partition_graphs) {
protobuf::RepeatedPtrField<GraphDef>* partition_graph_defs =
resp->mutable_metadata()->mutable_partition_graphs();
for (size_t i = 0; i < run_graph_resp->num_partition_graphs(); i++) {
partition_graph_defs->Add()->Swap(
run_graph_resp->mutable_partition_graph(i));
}
}
}
return status;
}
上面调用到了如下代码通知远端 Worker 运行子图。
part.worker->RunGraphAsync(
&call->opts, call->req.get(), call->resp.get(),
std::bind(&RunManyGraphs::WhenDone, &calls, i, std::placeholders::_1));
RunGraphAsync 具体定义就是 GrpcRemoteWorker 之中。GrpcRemoteWorker 的每个函数调用 IssueRequest() 发起一个异步 gRPC 调用。
void RunGraphAsync(CallOptions* call_opts, const RunGraphRequest* request,
RunGraphResponse* response, StatusCallback done) override {
IssueRequest(request, response, rungraph_, std::move(done), call_opts);
}
远端运行的 GrpcWorkerService 作为守护进程,将会处理传入的 gRPC 请求。
我们总结 DoRunWithLocalExecution 总体逻辑如下:
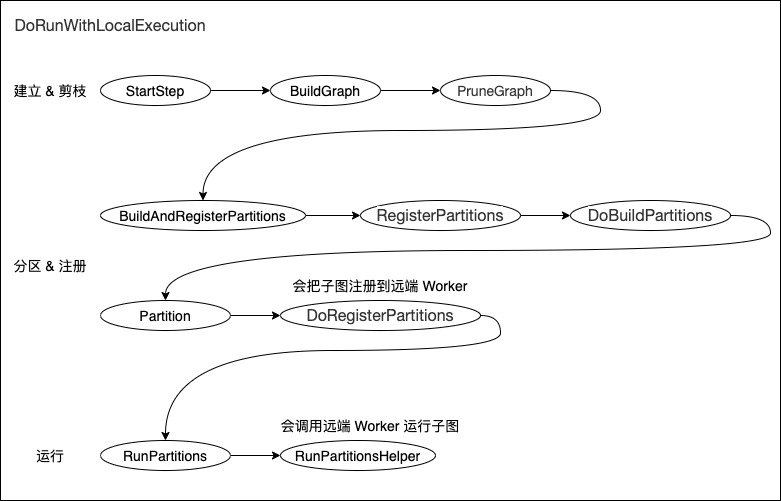
图 6 DoRunWithLocalExecution 总体逻辑
2.5 小结运行逻辑小结如下,注意这里有两个grpc 调用,一个是 register,一个是 run。首先调用 register 把子图注册到远端 Worker 之上,其次调用 run 来让远端 Worker 完成子图计算。
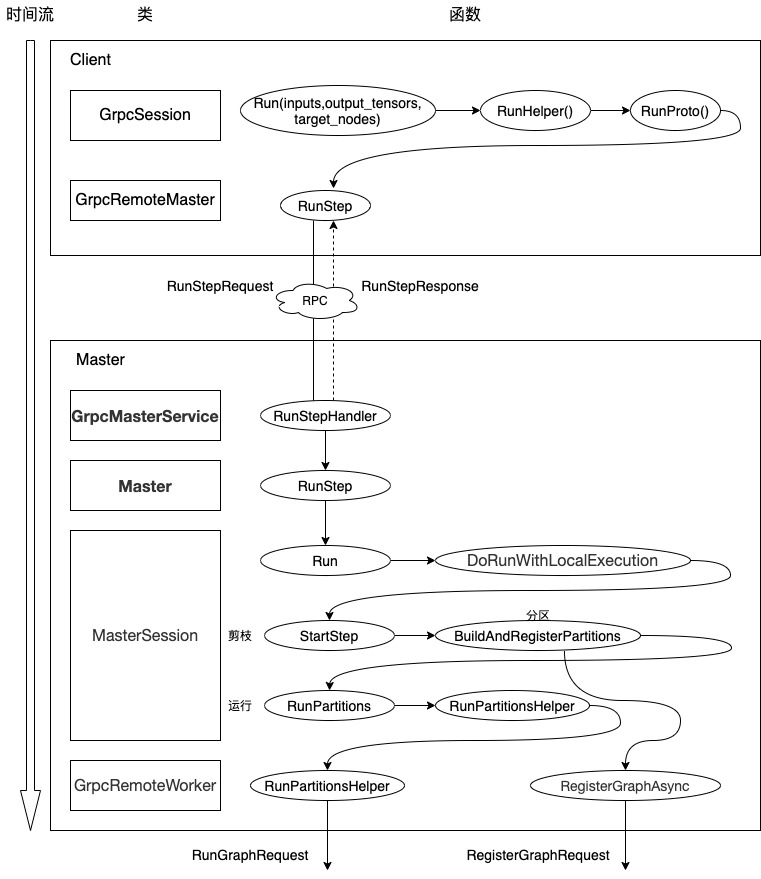
图 7 Master 动态逻辑 2
我们马上会去 Worker 来一探究竟。
0xFF 参考[1]. Abadi M, Agarwal A, Barham P, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems[J]. arXiv preprint arXiv:1603.04467, 2016.
[2] TensorFlow的图切割模块——Graph Partitioner
[3] TensorFlow中的Placement启发式算法模块——Placer
[4] TensorFlow中的设备管理——Device的创建与注册机制