ONNXRuntime,深度学习领域的神经网络模型推理框架,从名字中可以看出它和 ONNX 的关系:以 ONNX 模型作为中间表达(IR)的运行时(Runtime)。 本文许多内容翻译于官方文档:https://onnx
ONNXRuntime,深度学习领域的神经网络模型推理框架,从名字中可以看出它和 ONNX 的关系:以 ONNX 模型作为中间表达(IR)的运行时(Runtime)。
特色:本文许多内容翻译于官方文档:https://onnxruntime.ai/docs/reference/high-level-design.html ,并适当地添加一些自己的理解,由于对ONNXRuntime的认识还不够深入,因此可能会存在一些错误,希望多多指正,深入交流。
- 在不同平台上,最大限度地、自动地使用定制的加速器(accelerators)和运行时(runtimes);
- 针对定制的加速器和运行时,提供良好的抽象和运行时(onnxruntime)来支持运行,这里的抽象也被称之为EP(Execution Provider,eg. CUDA、TensorRT、OpenVINO、ROCm等)。每个EP都各自定义自己的功能,比如内存分配、可以执行的单个的或融合的节点(注意:本文中所说的节点就是算子,两者等同;conv属于单个的算子,conv_bn_relu属于融合的算子),这些功能需要以标准的API形式暴露给 ONNXRuntime,以供其调用;
- ONNXRuntime并不要求每个EP都完全支持ONNX中定义的所有算子,这也就意味着 ONNXRuntime 可能需要在异构环境中才能完整的执行完一个模型,这里的异构环境是指涉及到多个计算硬件,比如CPU和GPU;
- 支持多种图优化(Graph Optimization),主要分为两类:
- 全局变换(Global transformations):这种优化方式需要对整张计算图进行分析并优化;在源码中,每种变换都继承自
GraphTransformer类; - 局部变换(Local transformations):这种优化方式相当于定义一些简单的重写规则(rewriting rules),比如消除一些没有具体操作的图节点(eg.推理阶段的dropout节点);与全局变换不同,重写规则一般只针对图中的部分节点,也就是说需要先判断图中的节点是否满足重写条件,然后再决定是否实施变换;在源码中,每种重写规则都继承自
RewriteRule类,但是最后会使用GraphTransformer的一个派生类RuleBasedGraphTransformer,将所有的RewriteRule类聚合起来。
从这张图中,我们可以看出ONNXRuntime的执行流程。
- ONNXRuntime 首先将 ONNX 模型转变为 In-memory 形式;
- 针对这个模型执行一些与EP无关的优化;
- 根据设置的EP(可能会有多个),将整体计算图分割成多个子图;
- 每个子图都被分配到一个相应的EP中,分配过程中要确保这个EP能够执行该子图;
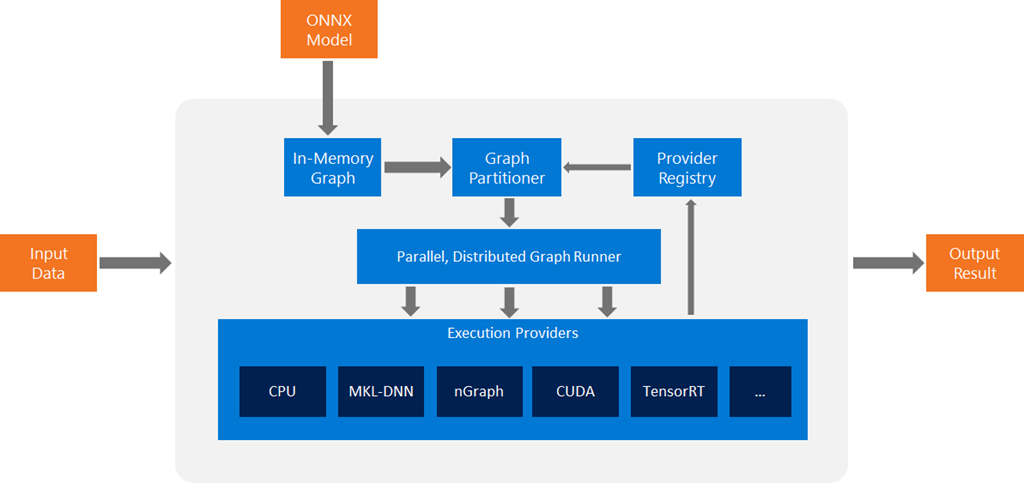
由于很多EP都会对一些特定的算子做特殊优化,因此在分割子图时,ONNXRuntime希望充分利用这些EP的能力,但是仍然会存在一些算子不能被EP执行,或者高效执行,这时就需要设定一个默认的EP进行兜底,这个角色往往由CPU承担。
计算图分割的策略:首先设置可用的EP,比如
ort_sess = ort.InferenceSession('onnx_model/resnet50.onnx', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
然后依照providers中设定的顺序为每个EP充分分配其可以执行的子图,为了确保每个子图都被执行,一般会讲CPU EP放置在最后。ONNXRuntime当前只支持同步的运行模式,并且由其控制整个计算图的运行。