本片博客使用mysql数据库进行数据操作,使用Navicat for mysql 这个IDE进行可视化操作。每个SQL语句都是亲身实验验证的,并且经过自己的思考的。能够保证sql语句的可运行性。
sql语句的命令不区分大小写,但储存的数据是区分大小写的。在这里我们统一使用英文小写进行命令编辑。如果喜欢大写的可以使用IDE编辑器的一键美化功能,可以统一转化为大写。并且会对你的sql语句进行美化,例如自动换行等。
- 创建数据库
create database <数据库名>;
-- 创建名为dbtest数据库
create database dbtest;
use dbtest;
- 创建表
create table 表名(字段);- comment 是注释的意思
- primary key(stu_id) 把stu_id设置为主键,主键的设置可以细分为三种方式,后面再写
- ENGINE=InnoDB 把储存引擎设置为InnoDB
- charset=utf8mb4 编码格式设置utf8mb4,utf8mb4是超集合,完全兼容utf8,不需要做特殊转换
-- 创建表
create table `t_student`(
`stu_id` char(12) not null COMMENT '学生id',
`stu_name` varchar(12) not null comment '学生姓名',
`stu_sex` tinyint(2) unsigned default null comment '性别:0(男),1(女)',
`stu_age` tinyint(3) unsigned DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`stu_id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='学生基本信息表';
mysql中的数据类型
- 使用insert values 插入数据
-- 插入数据 insert values
insert into `t_student`
(`stu_id`,`stu_name`,`stu_sex`,`stu_age`)
values(1,"hjk","0",18);
- 使用 insert set 插入数据
-- insert set
insert into `t_student`
set `stu_id`=3,`stu_name`='hjk',`stu_sex`=1,`stu_age`=18
- 从另一个表查询的数据插入新表 insert from,这个查询出来的数据要与插入到表里的字段有对应关系,例如查寻出来的数据如果有字段"stu_address"你如果直接插入就会不成功!
insert into `t_student` select `stu_id`,`stu_name`,`stu_sex`,`stu_age` from `t_student01`;
使用存储过程插入数据,在我们做实验时可能需要很多数据进行操作,但是一条一条手动加时不太容易实现的,我们可以使用其他方法插入数据(例如:连接jdbc,进行操作),但是这个插入的是几乎相同的数据,在这里我们使用存储过程并通过调用存储过程实现插入大量数据!
- 创建存储过程
- delimiter ## 定义结束符号,##是你自定义的符号可以是其他的符号(如:$、%、&),在最后end不要忘了写。
- 其实中间就是一个while循环,变量为i。
- 可以在定义的时候输入参数,这个我没有定义。
-- 插入大量数据,使用存储过程
delimiter ##
create procedure insert_pro()
begin
declare i int default 4;
while i <=100000 do
insert into `t_student` values(i,'hjk','0','20');
set i = i+1;
end while;
end ##
- 使用存储过程,创建存储过程后并没有效果,只有使用后才有效果
-- 使用存储过程
call insert_pro();
- 删除存储过程
-- 删除储存过程
DROP PROCEDURE IF EXISTS insert_pro;
这里只记录删除表和删除数据库,其他的会在每个创建后面写,例如给表添加字段,那相应的会在后面写如何删除字段
删除表
-- 删除表
drop table `t_student`;
删除数据库
-- 删除dbtest数据库
drop database dbtest;
DELETE FROM <表名> [WHERE 子句] [ORDER BY 子句] [LIMIT 子句]
删除stu_id为1的数据
delete from `t_student` where `stu_id`="1";
truncate table `t_student`;
- 创建表时,行级添加主键
create table `t_student`(
`stu_id` char(12) not null PRIMARY KEY COMMENT '学生id',
`stu_name` varchar(12) not null comment '学生姓名',
`stu_sex` tinyint(2) unsigned default null comment '性别:0(男),1(女)',
`stu_age` tinyint(3) unsigned DEFAULT NULL COMMENT '年龄'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='学生基本信息表';
- 创建表时表级添加主键 就是在文章刚开始的时候创建的那个表
- 表外添加主键
-- 最后添加主键
alter table `t_student` add primary key(`stu_id`);
- 删除主键
-- 删除主键约束
alter table `t_student` drop primary key;
外键约束经常和主键约束一起使用,用来确保数据的一致性!
外键需要用两个表添加,一个是主表一个是从表。在这里我们使用主表位t_student表,从表位t_coruse表;一种是创建表时创建外键约束,一种时后面添加外键约束;
第一种:
"constraint fk_course_id foreign key(stu_id) references t_student(stu_id)"创建名为fk_course_id的外键,使t_course表里的cou_id字段参照t_student表里的stu_id字段,在这里逻辑不对,重点是说语法。
create table t_course(
`cou_id` char(8) primary key,
`stu_id` char(12) not null,
`cou_name` varchar(12) not null,
`semester` smallint ,
`credit` smallint,
constraint fk_course_id foreign key(`stu_id`) references t_student(`stu_id`)
);
第二种:
添加外键使表里最好不要有数据,不然可能会创建失败
alter table t_student
add constraint fk_student_id foreign key(`stu_id`) references t_course(`cou_id`);
- 删除外键约束
在那个表添加的外键,去哪个表删除
alter table t_course
drop foreign key fk_course_id;
例如在t_student表的stu_name列添加唯一约束
- 创建表时添加唯一约束
-- 创建表
create table `t_student`(
`stu_id` char(12) not null PRIMARY KEY COMMENT '学生id',
`stu_name` varchar(12) unique,
`stu_sex` tinyint(2) unsigned default null comment '性别:0(男),1(女)',
`stu_age` tinyint(3) unsigned DEFAULT NULL COMMENT '年龄',
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='学生基本信息表';
- 建表后添加唯一性约束
alter table `t_student`
add constraint un_age unique(`stu_age`);
- 删除唯一性约束
alter table `t_student`
drop index un_age;
==其实写道这里应该也能看出来,他们的语法格式几乎是一样的都是可以直接在(1)、创建表时在字段后面添加改约束的关键字,(2)、在创建表时在最后用constraint添加并命名、(3)、在创建表后使用alter add添加约束,所以后面的几种约束就不详细写了。
- 检查约束
检查年龄是否大于1小于150
建表时在字段后面直接添加
check(`stu_age`>0 and `stu_age`<150)
- 后续添加
alter TABLE `t_student` add constraint check_age check(`stu_age`<100);
- 删除检查约束
alter table `t_student` drop check check_age;
非空约束和默认值的约束修改和上面的不太一样,时使用change修改
- 默认值约束
在最开始创建表的时候就有几个字段定义位默认值为null,这里不重复了,定义其他默认值就替换null就行了,这个null就是没有定义的意思。 - 修改默认值约束
alter TABLE `t_student` change column `stu_sex` `stu_sex` tinyint(2) default '1';
- 删除默认值约束,默认值改为null就行了
alter TABLE `t_student` change column `stu_sex` `stu_sex` tinyint(2) default null;
- 非空约束
在创建表的时候主键有一个not null约束就是非空约束了。 - 添加非空约束
ALTER TABLE <数据表名> CHANGE COLUMN <字段名> <字段名> <数据类型> NOT NULL; - 删除非空约束
ALTER TABLE <数据表名> CHANGE COLUMN <字段名> <字段名> <数据类型> NULL;
- 修改表数据
UPDATE <表名> SET 字段 1=值 1 [,字段 2=值 2… ] [WHERE 子句 ] [ORDER BY 子句] [LIMIT 子句]
-- 没有条件全部修改
update `t_student` set `stu_name` = 'kjh' ,`stu_age` = '19';
-- 有条件只修改符合条件的
update `t_student` set `stu_name` = 'kjh' ,`stu_age` = 25
where `stu_id` = 10;
- 去重,例如某一列含有大量数据,我们需要统计都出现过那些数据,统计出所有的数据反而不方便我们只需要统计一次这样的数据。
统计数据表中出现的所有的年龄
select distinct `stu_age` from `t_student`;
对年龄和姓名去重
select distinct `stu_name`, `stu_age` from `t_student`;
- 查询所有数据的所有字段
select * from `t_student`;
- 条件查询,查询名字为hjk的
select * from `t_student` where `stu_name` = 'hjk';
- 使用count(*)统计名字为hjk的个数
select count(*) from `t_student` where `stu_name` = 'hjk';
- 子查询
子查询操作符:操作符可以是比较运算符和 IN、NOT IN、EXISTS、NOT EXISTS 等关键字
select * from `t_student` where `stu_id` in
(select `stu_id` from `t_student` where `stu_age`=18);
子查询语句可以嵌套在 SQL 语句中任何表达式出现的位置
在 SELECT 语句中,子查询可以被嵌套在 SELECT 语句的列、表和查询条件中,即 SELECT 子句,FROM 子句、WHERE 子句、GROUP BY 子句和 HAVING 子句。
SELECT (子查询) FROM 表名;
SELECT * FROM (子查询) AS 表的别名;
SELECT * FROM (SELECT * FROM result) AS Temp;
- 分页查询
从第十的数据开始查,向后查出20个数据。
select * from `t_student` limit 10,20;
- 排序,按照年龄大小升序,默认是升序asc排列,降序需要在order by 字段后添加 desc
select * from `t_student` order by `stu_age`;
- 模糊查询
查询名字为h开头的数据,默认匹配不区分大小写,就是为H开头的也能查出来,但是可以在like后面加binary区分大小写
select * from `t_student` where `stu_name` like 'h%';
查询名字不为h开头的数据
select * from `t_student` where `stu_name` not like 'h%';
通配符%和_的区别:
%代表后面可以匹配任意个字符。
_仅替代一个字符
%”通配符可以到匹配任意字符,但是不能匹配 NULL。也就是说 “%”匹配不到数据表中值为 NULL 的记录
如果查询内容中包含通配符,可以使用“\”转义符
- 范围查询 between
select * from `t_student` where `stu_age` between 17 and 19;
- 空值查询 空值条件不时等于null而是is null进行判断
select * from `t_student` where `stu_age` is null;
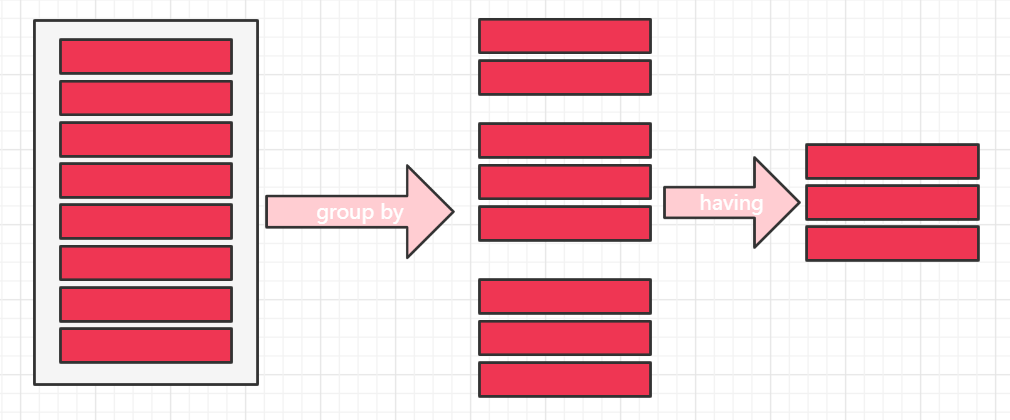
- 分组查询
单独使用 GROUP BY 关键字时,查询结果会只显示每个分组的第一条记录
select `stu_name`,`stu_sex` from `t_student` group by `stu_age`;
和group_count(字段)一起使用
select `stu_name`,GROUP_CONCAT(`stu_sex`) from `t_student` group by `stu_age`;
- having条件查询
having和where区别
一般情况下,WHERE 用于过滤数据行,而 HAVING 用于过滤分组。
WHERE 查询条件中不可以使用聚合函数,而 HAVING 查询条件中可以使用聚合函数。
WHERE 在数据分组前进行过滤,而 HAVING 在数据分组后进行过滤 。
WHERE 针对数据库文件进行过滤,而 HAVING 针对查询结果进行过滤。也就是说,WHERE 根据数据表中的字段直接进行过滤,而 HAVING 是根据前面已经查询出的字段进行过滤。
WHERE 查询条件中不可以使用字段别名,而 HAVING 查询条件中可以使用字段别名。
having查询,这个是正确的,因为代表所有的字段,那当然肯定包含这个having条件的这个字段,但是如果这个地方换成具体的字段,并且没有stu_name那就会报错了。
having通常和group by一起使用
select * from `t_student` having `stu_name` = 'hjk';
MySQL 视图(View)是一种虚拟存在的表,同真实表一样,视图也由列和行构成,但视图并不实际存在于数据库中。行和列的数据来自于定义视图的查询中所使用的表,并且还是在使用视图时动态生成的。
数据库中只存放了视图的定义,并没有存放视图中的数据,这些数据都存放在定义视图查询所引用的真实表中。使用视图查询数据时,数据库会从真实表中取出对应的数据。因此,视图中的数据是依赖于真实表中的数据的。一旦真实表中的数据发生改变,显示在视图中的数据也会发生改变。
视图可以从原有的表上选取对用户有用的信息,那些对用户没用,或者用户没有权限了解的信息,都可以直接屏蔽掉,作用类似于筛选。这样做既使应用简单化,也保证了系统的安全。
视图并不同于数据表,它们的区别在于以下几点:
- 视图不是数据库中真实的表,而是一张虚拟表,其结构和数据是建立在对数据中真实表的查询基础上的。
- 存储在数据库中的查询操作 SQL 语句定义了视图的内容,列数据和行数据来自于视图查询所引用的实际表,引用视图时动态生成这些数据。
- 视图没有实际的物理记录,不是以数据集的形式存储在数据库中的,它所对应的数据实际上是存储在视图所引用的真实表中的。
- 视图是数据的窗口,而表是内容。表是实际数据的存放单位,而视图只是以不同的显示方式展示数据,其数据来源还是实际表。
- 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些 SQL 语句的集合。从安全的角度来看,视图的数据安全性更高,使用视图的用户不接触数据表,不知道表结构。
- 视图的建立和删除只影响视图本身,不影响对应的基本表.
为什么创建视图
例如学生表里面有学生id、姓名等,课程表有学生所选课程、上课时间等。如果我们查看课程表是是需要学生姓名和课程上课时间就行,不需要其他的一些没有用的信息。这样我们就可以建一个关于这两个表的视图,我们可以直接根据这个视图获取信息。
CREATE VIEW <视图名> AS <SELECT语句>
- 创建一个关于学生名字的视图
create view view_student_name
as select `stu_name` from `t_student`;
- 查看视图信息,和查询表是几乎一样的,我们可以把视图看成不是表的表
select * from view_student_name;
- 查看视图结构
-- 以表的结构显示
desc view_student_name;
-- 以sql语句显示
SHOW CREATE VIEW 视图名;
- 创建基于多表的视图
-- 随便创个表
create table `t_course`(
`cou_id` int(11) primary key,
`s_id` char(12)
);
-- 创建多表视图
create view v_stu_cou (`stu_id`,`cou_id`)
as select `stu_id`,`cou_id` from `t_student` s,`t_course` c
where s.stu_id=c.s_id;
-- 查看视图结构
desc v_stu_cou
- 修改视图
ALTER VIEW <视图名> AS <SELECT语句>
- 删除视图
-- 直接删除,可能已经不存在,会报错
drop view v_stu_cou;
-- 判断是否存在,再删除
drop view if exists v_stu_cou;
索引是一种特殊的数据库结构,由数据表中的一列或多列组合而成,可以用来快速查询数据表中有某一特定值的记录
通过索引,查询数据时不用读完记录的所有信息,而只是查询索引列。否则,数据库系统将读取每条记录的所有信息进行匹配
可以把索引比作新华字典的音序表,例如,要查一个字,如果不使用音序,就需要从字典的全部页码中逐页来找。但是,如果提取拼音出来,构成音序表,就只需要从音序表确定的那几页页的音序表中直接查找。这样就可以大大节省时间。
索引的优缺点
索引有其明显的优势,也有其不可避免的缺点。
优点
索引的优点如下:
通过创建唯一索引可以保证数据库表中每一行数据的唯一性。
可以给所有的 MySQL 列类型设置索引。
可以大大加快数据的查询速度,这是使用索引最主要的原因。
在实现数据的参考完整性方面可以加速表与表之间的连接。
在使用分组和排序子句进行数据查询时也可以显著减少查询中分组和排序的时间
缺点
增加索引也有许多不利的方面,主要如下:
创建和维护索引组要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
索引需要占磁盘空间,除了数据表占数据空间以外,每一个索引还要占一定的物理空间。如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸。
当对表中的数据进行增加、删除和修改的时候,索引也要动态维护,这样就降低了数据的维护速度。
MySQL支持以下几种类型的索引。
(1)B-Tree索引
(2)哈希索引
(3)空间数据索引(R-Tree)
(4)全文索引
(5)其他索引类别
CREATE <索引名> ON <表名> (<列名> [<长度>] [ ASC | DESC])
一个表可以创建多个索引,但每个索引在该表中的名称是唯一的
- 可以再创建表时创建索引
直接在创建表时的字段最后添加 index(字段名)
CREATE TABLE `t_student` (
`stu_id` char(12) NOT NULL COMMENT '学生id',
`stu_name` varchar(12) NOT NULL COMMENT '学生姓名',
`stu_sex` tinyint(2) unsigned DEFAULT NULL COMMENT '性别:0(男),1(女)',
`stu_age` tinyint(3) unsigned DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`stu_id`),
KEY `stu_id` (`stu_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='学生基本信息表'
创建唯一索引,还是同样的位置,添加成unique index(字段)
- 通过show create table 表名 查看会发现,我们写sql那个位置变为 KEY
stu_id(stu_id);
show index from `t_student`;
- 索引参数说明
DROP INDEX <索引名> ON <表名>
drop index stu_id on `t_student`;