
自从公司项目前年上了 OpenShift 3.9 私有云平台,更新部署程序的确变得更加容易了。但是带来了很多复杂性,运维实施人员的学习曲线也陡然上升。
上云之前:在项目没上容器云的早期,应用服务集群往往是由一个 Nginx 作为负载均衡器,当有集群中有一个节点出现故障时,只需要将 Nginx 上负载均衡块 upstream 块中的故障节点地址移除,刷新 Nginx 即可达到快速响应,也能慢慢收集性能指标进行分析。
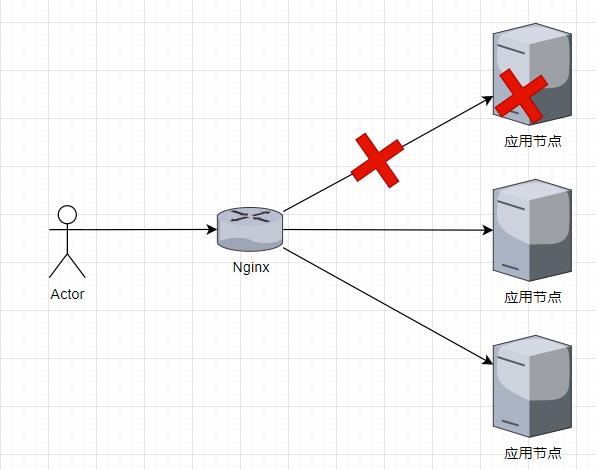
上云之后:在云上部署应用,应用容器生命周期由 Deployment 管理,多实例集群由 Service 负载流量 (本文暂时不谈服务网格)。当应用集群中某个Pod出现故障,通过 Deployment 或 Service 并不能直接把某个 Pod 从流量负载中移出,使用存活探针没办法收集性能指标(Pod 自动重启或重建),使用就绪探针需要开发可靠的就绪检测接口(严重依赖程序员)。以下是k8s部署简图

2 核心诉求就绪探针:能从流量中移出无响应 Pod,严重依赖检测健康的接口可靠度。
存活探针:流量中移除无响应Pod,并重建或重启 Pod。
看了上边的内容,可明确的诉求有以下两点:
- 能够快速流量下线故障节点,给客户快速响应,客户无需长时间等待,提高客户满意度。
- 保留故障节点供深度分析故障原因。
对于 Pod 而言,流量来自于 Service。初学 K8s 时,都会看到类似下边的图,大意是 Service 是通过 Selector 配置的 label 来匹配 Pod 的。

那么,Service 直接连接到了 Pod 上么?
这样说并不准确,Service 与 Pod 中间还有一种资源 —— Endpoints,Service 通过 Selector 将匹配到的 IP 和端口列表存入 Endpoints。当流量到达网络代理(KubeProxy)时,网络代理会从众多 Endpoints 中找出目标 Endpoints 并取出其中一个地址进行转发。
所以,流量能进入 Pod 和 Endpoints 关系很大,由 Service 维护 Endpoints,最终由网络代理建立网络转发规则。
3.2 如何切断流量?我们知道 Endpoints 才是流量能否到达 Pod 的关键,将 Pod 移出 Endpoints 切断流量的具体的方法:
- 通过变更 Service 匹配 label 来影响 Endpoints
- 改变 label 的 Key 与 Value 都可以。
- 就绪探针(Readiness Probe)配合可靠的检测接口
- 就绪探针可以使检测失败的 Pod 临时移出 Endpoints,待检测通过再加回来。
- 需要注意的是就绪探针需要可靠的检测接口,否则有可能出现反复上下线,导致明显卡顿感。
简单的探活接口 + 就绪探针 + 手动下线
适用场景适用于业务应用没有可靠就绪检测接口,仅有简单的探活接口,配合就绪探针舒缓问题,等到人工介入,将正在反复流量上下线的程序快速移出 Endpoints。
配置方式- 就绪探针:推荐使用 HttpGet 类型,初始延迟(initial delay)按 Pod 开始启动到能提供服务时间加上 10s 左右为宜,检测周期(period)在10~20s内为宜,就绪探针接口配置为探活接口地址。
- 优点:
- 简单,不需要开发人员投入太多。
- 缺点:
- 出现故障时,Pod 会反复上下线,影响用户体验。
- 需要人工介入。
简单的探活接口 + 低频存活探针 + 可靠的就绪接口 + 就绪探针 + 手动下线
适用场景适用于业务应用有可靠的就绪检测接口,有探活接口的情况。
- 当 Pod 出现未就绪状态时,由就绪检测探针确定未就绪状态并将其自动流量下线。
- 自动流量下线后,如果未经人工干预能自行恢复,则自动流量上线。
- 自动流量下线后,如果出现无响应,存活探针检测连续3次失败,则自动重启或重建。
- 在自动流量下线后与存活探针连续检测3次失败之前,手动下线移出管理(Deployment/Service/Health Check)供收集性能指标分析定位问题原因。
- 低频存活检测有助于延长人工介入操作时间。
- 当 Pod 重启或重建后,原始故障可能无法复现。
- 当 Pod 突然出现无响应状态,存活探针检测连续3次失败,则自动重启或重建。
- 就绪探针:推荐使用 HttpGet 类型,初始延迟(initial delay)按 Pod 开始启动到能提供服务时间加上 10s 左右为宜,检测周期(period)在 10~20s 为宜,就绪探针接口配置为就绪检测接口地址。
- 存活探针:推荐使用 HttpGet 类型,初始延迟(initial delay)按 Pod 开始启动到能提供服务时间加上 60s 左右为宜,检测周期(period)在 20~30s 为宜,存活探针接口配置为探活检测接口地址。
- 优点:
- 根据服务情况自动进行适当处理。
- 未就绪则下线
- 就绪则上线
- 无响应重启/重建
- 几乎无需人工介入,定位问题除外。
- 根据服务情况自动进行适当处理。
- 缺点:
- 就绪检测接口需要开发人员精心设计。
- 如就绪状态时返回200状态码,未就绪返回500状态码
- 需要准确评估出应用的状态
- 开发人员远程调试需要临时关闭存活探针。
- 就绪检测接口需要开发人员精心设计。
本操作步骤基于通过变更 Service 匹配 label 来影响 Endpoints 的思路。
这里以测试环境 bi 程序举例,通过 Deployment 处的 Actions - Edit Yaml 打开如下界面,确定 Service 匹配的 label。

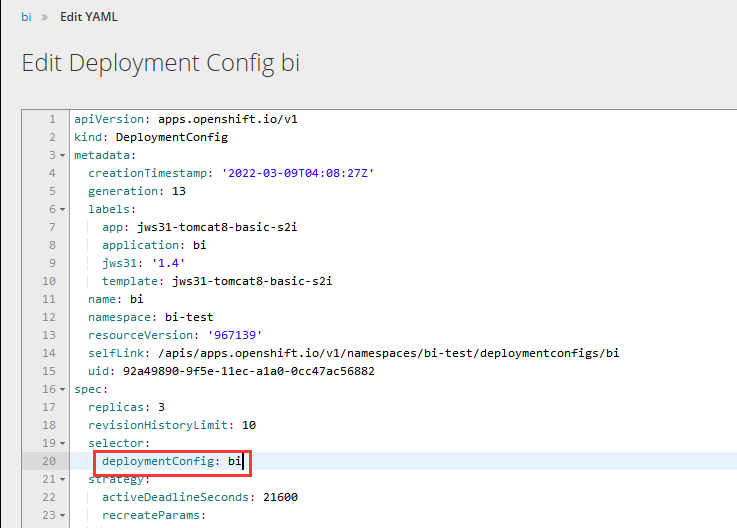
可以看到 selector 选择的 label 为 deloymentConfig: bi,这样我们就能确认 Pod 必须也有这个标签,那么我们去修改故障节点。
退出编辑 yaml 界面,可以看到该 Service 对应的 Pod 列表,这里以 bi-4-7dt6r 作为故障节点演示,点击 bi-4-7dt6r。

进入 bi-4-7dt6r Pod 界面,依次点击 Actions - Edit yaml,我们找到与 Service 中同样的标签(注意大小写)

修改 deloymentConfig: bi 为 deloymentConfig: bi-debug,只要标签不同即可,然后 Save

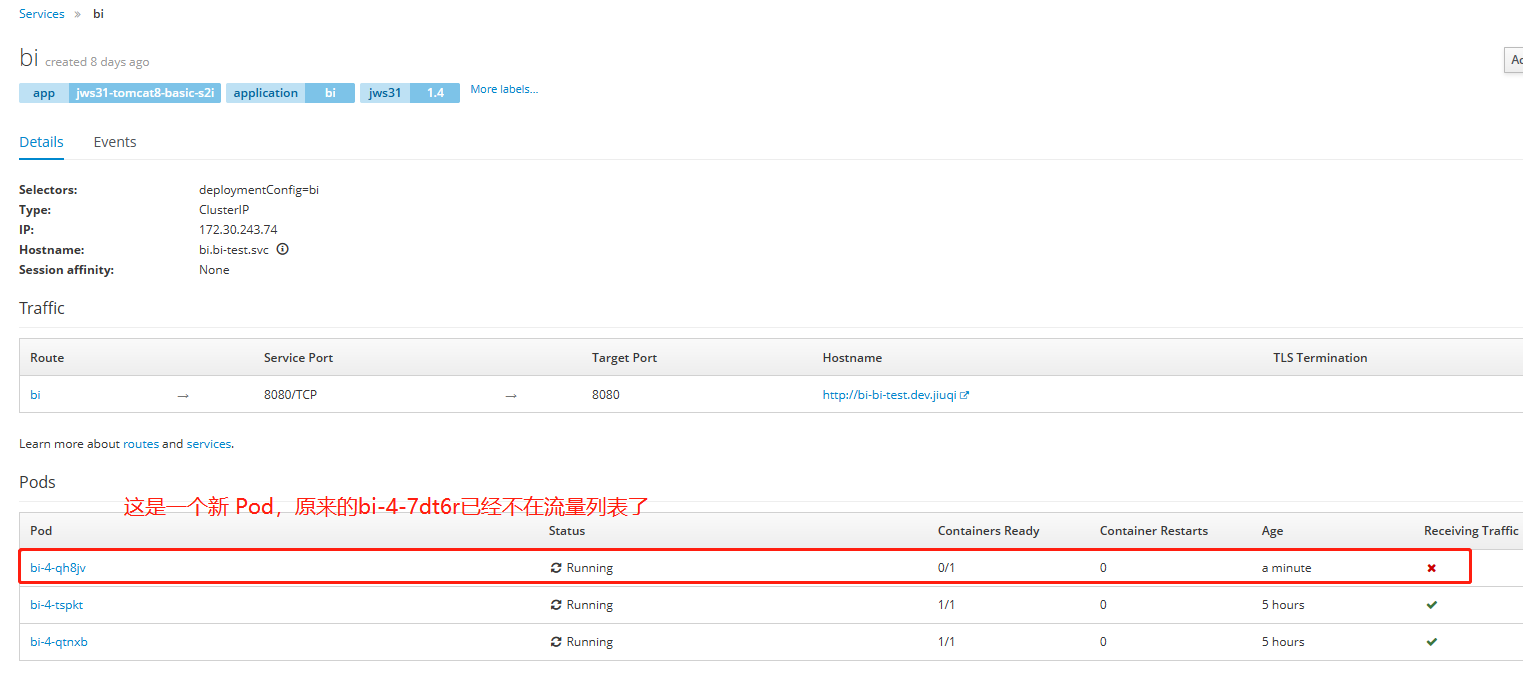
回到 Service 界面,如下图,原来的 bi-4-7dt6r 已经不在负载列表中了
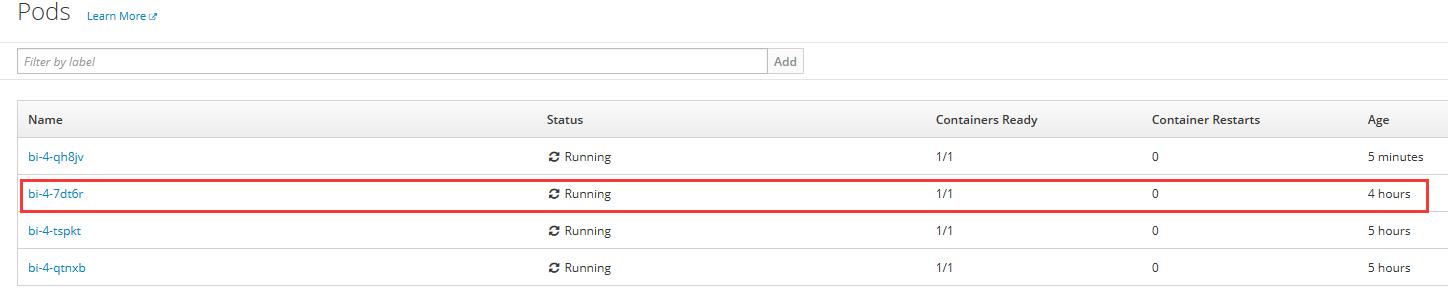
我们再去 Pods 界面查看 bi-4-7dt6r 是否依然存在,如图,原来的 Pod 依然存在。
主要目标——断开流量已经达成,至于为什么会创建了一个新的 Pod 呢?
打开这个应用的 Deployment yaml,我们可以看到:原来 Deployment 匹配 Pod 的标签也是 deloymentConfig: bi!
这也很好解释自动创建新节点的原因了:由于 DeploymentConfig 查询不到它期待的3个 Pod 副本数,就创建了一个新的!
以上,今天要分享的内容都在这里了。如果本文对你有所启发,请为我送上一个赞吧!如有错漏处,还望评论告知一二!
我是 Hellxz,我们下次再见!
参考书目《Kubernetes in Action》