(上图是数据库连接数监控图) 非常抱歉,今天下午 16:50-17:40 期间,一场龙卷风突袭园子,突增的并发请求狂卷博客站点的 pod,由于风力巨大(70%左右的增量),pod 的 cpu 不堪重负,
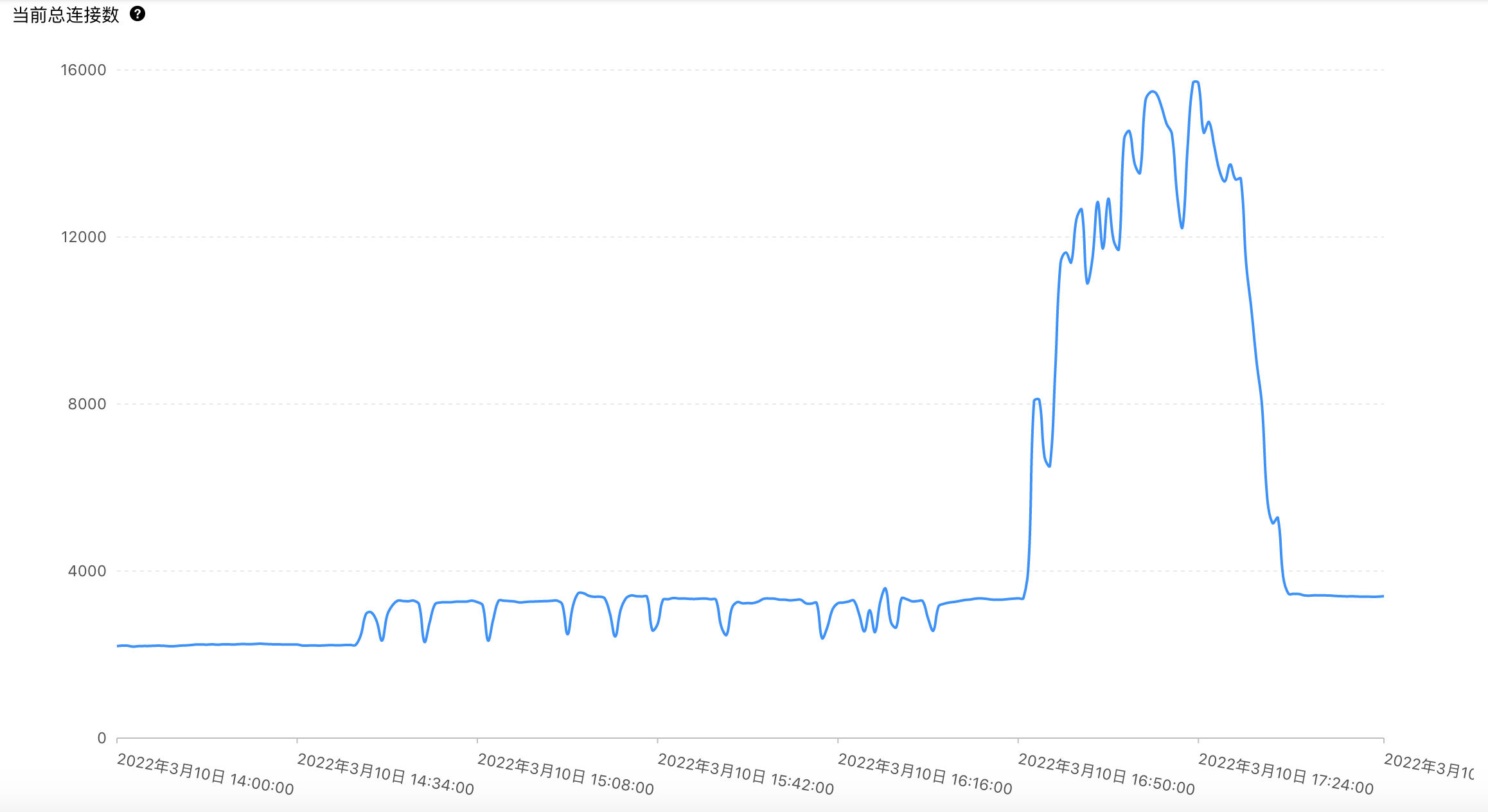
(上图是数据库连接数监控图)
非常抱歉,今天下午 16:50-17:40 期间,一场龙卷风突袭园子,突增的并发请求狂卷博客站点的 pod,由于风力巨大(70%左右的增量),pod 的 cpu 不堪重负,造成博客站点无法正常访问,由此给您带来麻烦,请您谅解。
在没有龙卷风的一般大风(访问高峰)情况下,博客站点单个 pod 的 cpu 通常消耗在 3-4 核之间,所以我们采用了下面的 pod 资源限制配置:
resources:
requests:
memory: "4Gi"
cpu: "3"
limits:
memory: "6Gi"
cpu: "5"但今天龙卷风风力太大, 5 核 cpu 也扛不住。开始我们试图通过增加服务器与更多 pod 减轻单个 pod 的 cpu 压力,但发现这样于事无补,不仅已有 pod 的 cpu 没有明显下降,而且新增 pod 的 cpu 也是扛不住,可能是 k8s service 单位时间转发给单个 pod 的并发请求需要超过 5 核以上 cpu 才能处理得过来。
这时你也许会问为什么不直接调高 cpu 限制?我们现在使用的 k8s 集群多数使用的是高配服务器(至少8核),的确具备调高 cpu 限制的条件。但是修改 cpu limit 会引起所有 pod 重新部署,我们担心在访问高峰进行这个操作会雪上加霜,所有没有优先采用这个方法。
加服务器加 pod 解决不了问题,我们也只能试试调高 cpu 限制,在调高限制并 pod 完成重新部署后很快就恢复正常,但我们不能确定是调高 cpu 限制药到病除,还是巧合,正好在调高 cpu 限制后龙卷风停了。
就这样经历了一次龙卷风袭击造成的故障。抱歉,给大家带来麻烦了。