- [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(9)--- Local hash表
- 0x00 摘要
- 0x01 前文回顾
- 0x02 定义
- 0x03 构建
- 3.1 调用
- 3.2 构造函数
- 3.3 如何确定slot
- 0x04 前向传播
- 4.1 总述
- 4.2 alltoall
- 4.3 Reorder
- 4.3.1 思路
- 4.3.2 图示
- 4.4 slot id
- 4.5 输出矩阵
- 0x05 后向传播
- 5.1 Reorder backward
- 5.2 All2all backward
- 5.3 backward
- 0x06 存储
- 0xFF 参考
在这个系列中,我们介绍了 HugeCTR,这是一个面向行业的推荐系统训练框架,针对具有模型并行嵌入和数据并行密集网络的大规模 CTR 模型进行了优化。本文介绍 LocalizedSlotSparseEmbeddingHash 的后向操作。
其中借鉴了HugeCTR源码阅读 这篇大作,特此感谢。
本系列其他文章如下:
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(1)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (2)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器---(3)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (4)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (5) 嵌入式hash表
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (6) --- Distributed hash表
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(7) ---Distributed Hash之前向传播
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(8) ---Distributed Hash之后向传播
0x01 前文回顾从之前的分析我们可以了解到一个嵌入表lookup的总体流程如下。

LocalizedSlotSparseEmbeddingHash类继承自Embedding类,Embedding类是实现所有嵌入层的基类。在LocalizedSlotSparseEmbeddingHash类中,嵌入表中的一些插槽被分配给单个GPU,称为本地化插槽。例如,GPU-0上的插槽0、GPU-1上的插槽1、GPU-0上的插槽2、GPU-1上的插槽3等。作为对比,DistributedSlotSparseEmbeddingHash 之中的一些slots被分配给多个GPU。
嵌入表被封装在一个hash table中。哈希表中的键称为hash_table_key,哈希表中的值称为hash_table_value_index,表示嵌入特征(embedding feature)在嵌入表中的行号,嵌入特征称为hash_table_value。
LocalizedSlotSparseEmbeddingHash 实现了嵌入层的训练过程所需的所有操作,包括前向传播和后向传播。正向传播对应于API forward。反向传播分为两个阶段的API:backward和update_params。该类还提供将哈希表(包括哈希表键、哈希表值索引和哈希表值)从主机文件上载到GPU(名为load_parameters)的操作,以及将哈希表从GPU下载到主机文件(名为dump_parameters)的操作。
template <typename TypeHashKey, typename TypeEmbeddingComp>
class LocalizedSlotSparseEmbeddingHash : public IEmbedding {
using NvHashTable = HashTable<TypeHashKey, size_t>;
private:
EmbeddingData<TypeHashKey, TypeEmbeddingComp> embedding_data_;
std::vector<LocalizedFilterKeyStorage<TypeHashKey>> filter_keys_storages_;
std::vector<std::shared_ptr<NvHashTable>> hash_tables_; /**< Hash table. */
// define tensors
Tensors2<float> hash_table_value_tensors_; /**< Hash table value. */
std::vector<Tensors2<float>> value_table_tensors_;
Tensors2<size_t> hash_table_slot_id_tensors_; /**< the tensors for storing slot ids */
Tensors2<size_t> hash_value_index_tensors_; /**< Hash value index. The index is corresponding to
the line number of the value. */
Tensors2<TypeEmbeddingComp>
embedding_feature_tensors_; /**< the output tensor of the forward(). */
Tensors2<TypeEmbeddingComp> wgrad_tensors_; /**< the input tensor of the backward(). */
std::vector<EmbeddingOptimizer<TypeHashKey, TypeEmbeddingComp>> embedding_optimizers_;
size_t max_vocabulary_size_;
size_t max_vocabulary_size_per_gpu_; /**< Max vocabulary size for each GPU. */
std::vector<size_t> slot_num_per_gpu_; /* slot_num per GPU */
std::vector<size_t> slot_size_array_;
SparseEmbeddingFunctors functors_;
Tensors2<TypeEmbeddingComp> all2all_tensors_; /**< the temple buffer to store all2all results */
Tensors2<TypeEmbeddingComp> utest_all2all_tensors_;
Tensors2<TypeEmbeddingComp> utest_reorder_tensors_;
Tensors2<TypeEmbeddingComp> utest_backward_temp_tensors_;
Tensors2<TypeEmbeddingComp> utest_forward_temp_tensors_;
}
在 HugeCTR/src/parsers/create_embedding.cpp 之中,有如下调用:
case Embedding_t::LocalizedSlotSparseEmbeddingHash: {
const SparseEmbeddingHashParams embedding_params = {batch_size,
batch_size_eval,
max_vocabulary_size_per_gpu,
slot_size_array,
embedding_vec_size,
sparse_input.max_feature_num_per_sample,
sparse_input.slot_num,
combiner, // combiner: 0-sum, 1-mean
embedding_opt_params};
embeddings.emplace_back(new LocalizedSlotSparseEmbeddingHash<TypeKey, TypeFP>(
sparse_input.train_sparse_tensors, sparse_input.evaluate_sparse_tensors, embedding_params,
resource_manager));
break;
}
LocalizedSlotSparseEmbeddingHash 的构造函数如下,具体逻辑请参见下面注释。
template <typename TypeHashKey, typename TypeEmbeddingComp>
LocalizedSlotSparseEmbeddingHash<TypeHashKey, TypeEmbeddingComp>::LocalizedSlotSparseEmbeddingHash(
const SparseTensors<TypeHashKey> &train_keys, const SparseTensors<TypeHashKey> &evaluate_keys,
const SparseEmbeddingHashParams &embedding_params,
const std::shared_ptr<ResourceManager> &resource_manager)
: embedding_data_(Embedding_t::LocalizedSlotSparseEmbeddingHash, train_keys, evaluate_keys,
embedding_params, resource_manager),
slot_size_array_(embedding_params.slot_size_array) {
try {
// 设定每个GPU的最大数据量
if (slot_size_array_.empty()) {
max_vocabulary_size_per_gpu_ = embedding_data_.embedding_params_.max_vocabulary_size_per_gpu;
max_vocabulary_size_ = embedding_data_.embedding_params_.max_vocabulary_size_per_gpu *
embedding_data_.get_resource_manager().get_global_gpu_count();
} else {
max_vocabulary_size_per_gpu_ =
cal_max_voc_size_per_gpu(slot_size_array_, embedding_data_.get_resource_manager());
max_vocabulary_size_ = 0;
for (size_t slot_size : slot_size_array_) {
max_vocabulary_size_ += slot_size;
}
}
CudaDeviceContext context;
// 遍历本地GPU
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); id++) {
// 设定当前上下文
context.set_device(embedding_data_.get_local_gpu(id).get_device_id());
// 每个GPU的slot数目
size_t gid = embedding_data_.get_local_gpu(id).get_global_id();
size_t slot_num_per_gpu =
embedding_data_.embedding_params_.slot_num /
embedding_data_.get_resource_manager().get_global_gpu_count() +
((gid < embedding_data_.embedding_params_.slot_num %
embedding_data_.get_resource_manager().get_global_gpu_count())
? 1
: 0);
slot_num_per_gpu_.push_back(slot_num_per_gpu);
// new GeneralBuffer objects
const std::shared_ptr<GeneralBuffer2<CudaAllocator>> &buf = embedding_data_.get_buffer(id);
embedding_optimizers_.emplace_back(max_vocabulary_size_per_gpu_,
embedding_data_.embedding_params_, buf);
// 接下来就是为各种变量分配内存
// new hash table value vectors
if (slot_size_array_.empty()) {
Tensor2<float> tensor;
buf->reserve(
{max_vocabulary_size_per_gpu_, embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
hash_table_value_tensors_.push_back(tensor);
} else {
const std::shared_ptr<BufferBlock2<float>> &block = buf->create_block<float>();
Tensors2<float> tensors;
size_t vocabulary_size_in_current_gpu = 0;
for (size_t i = 0; i < slot_size_array_.size(); i++) {
if ((i % embedding_data_.get_resource_manager().get_global_gpu_count()) == gid) {
Tensor2<float> tensor;
block->reserve(
{slot_size_array_[i], embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
tensors.push_back(tensor);
vocabulary_size_in_current_gpu += slot_size_array_[i];
}
}
value_table_tensors_.push_back(tensors);
if (max_vocabulary_size_per_gpu_ > vocabulary_size_in_current_gpu) {
Tensor2<float> padding_tensor_for_optimizer;
block->reserve({max_vocabulary_size_per_gpu_ - vocabulary_size_in_current_gpu,
embedding_data_.embedding_params_.embedding_vec_size},
&padding_tensor_for_optimizer);
}
hash_table_value_tensors_.push_back(block->as_tensor());
}
{
Tensor2<TypeHashKey> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(true),
embedding_data_.embedding_params_.max_feature_num},
&tensor);
embedding_data_.train_value_tensors_.push_back(tensor);
}
{
Tensor2<TypeHashKey> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(false),
embedding_data_.embedding_params_.max_feature_num},
&tensor);
embedding_data_.evaluate_value_tensors_.push_back(tensor);
}
{
Tensor2<TypeHashKey> tensor;
buf->reserve(
{embedding_data_.embedding_params_.get_batch_size(true) * slot_num_per_gpu + 1},
&tensor);
embedding_data_.train_row_offsets_tensors_.push_back(tensor);
}
{
Tensor2<TypeHashKey> tensor;
buf->reserve(
{embedding_data_.embedding_params_.get_batch_size(false) * slot_num_per_gpu + 1},
&tensor);
embedding_data_.evaluate_row_offsets_tensors_.push_back(tensor);
}
{ embedding_data_.train_nnz_array_.push_back(std::make_shared<size_t>(0)); }
{ embedding_data_.evaluate_nnz_array_.push_back(std::make_shared<size_t>(0)); }
// new hash table value_index that get() from HashTable
{
Tensor2<size_t> tensor;
buf->reserve({1, embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.max_feature_num},
&tensor);
hash_value_index_tensors_.push_back(tensor);
}
// new embedding features reduced by hash table values(results of forward)
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve(
{embedding_data_.embedding_params_.get_universal_batch_size() * slot_num_per_gpu,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
embedding_feature_tensors_.push_back(tensor);
}
// new wgrad used by backward
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(true) * slot_num_per_gpu,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
wgrad_tensors_.push_back(tensor);
}
// the tenosrs for storing slot ids
// TODO: init to -1 ?
{
Tensor2<size_t> tensor;
buf->reserve({max_vocabulary_size_per_gpu_, 1}, &tensor);
hash_table_slot_id_tensors_.push_back(tensor);
}
// temp tensors for all2all
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.get_universal_batch_size_per_gpu() *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
all2all_tensors_.push_back(tensor);
}
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
utest_forward_temp_tensors_.push_back(tensor);
}
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.get_batch_size_per_gpu(true) *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
utest_all2all_tensors_.push_back(tensor);
}
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.get_batch_size_per_gpu(true) *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
utest_reorder_tensors_.push_back(tensor);
}
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(true) *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
utest_backward_temp_tensors_.push_back(tensor);
}
{
size_t max_nnz = embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.max_feature_num;
size_t rowoffset_count = embedding_data_.embedding_params_.slot_num *
embedding_data_.embedding_params_.get_universal_batch_size() +
1;
filter_keys_storages_.emplace_back(buf, max_nnz, rowoffset_count);
}
}
hash_tables_.resize(embedding_data_.get_resource_manager().get_local_gpu_count());
#pragma omp parallel for num_threads(embedding_data_.get_resource_manager().get_local_gpu_count())
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); id++) {
// 初始化内部哈希表
CudaDeviceContext context(embedding_data_.get_local_gpu(id).get_device_id());
// construct HashTable object: used to store hash table <key, value_index>
hash_tables_[id].reset(new NvHashTable(max_vocabulary_size_per_gpu_));
embedding_data_.get_buffer(id)->allocate();
}
// 初始化优化器
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); id++) {
context.set_device(embedding_data_.get_local_gpu(id).get_device_id());
embedding_optimizers_[id].initialize(embedding_data_.get_local_gpu(id));
} // end of for(int id = 0; id < embedding_data_.get_local_gpu_count(); id++)
if (!embedding_data_.embedding_params_.slot_size_array.empty()) {
std::vector<TypeHashKey> embedding_offsets;
TypeHashKey slot_sizes_prefix_sum = 0;
for (size_t i = 0; i < embedding_data_.embedding_params_.slot_size_array.size(); i++) {
embedding_offsets.push_back(slot_sizes_prefix_sum);
slot_sizes_prefix_sum += embedding_data_.embedding_params_.slot_size_array[i];
}
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); ++id) {
CudaDeviceContext context(embedding_data_.get_local_gpu(id).get_device_id());
CK_CUDA_THROW_(
cudaMemcpy(embedding_data_.embedding_offsets_[id].get_ptr(), embedding_offsets.data(),
embedding_offsets.size() * sizeof(TypeHashKey), cudaMemcpyHostToDevice));
}
}
// sync
functors_.sync_all_gpus(embedding_data_.get_resource_manager());
} catch (const std::runtime_error &rt_err) {
std::cerr << rt_err.what() << std::endl;
throw;
}
return;
}
我们接下来要看看如何确定哪个GPU上有哪个slot。在init_params之中调用了init_embedding完成了构建。
/**
* Initialize the embedding table
*/
void init_params() override {
// do hash table value initialization
if (slot_size_array_.empty()) { // if no slot_sizes provided, use the old method to init
init_embedding(max_vocabulary_size_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
hash_table_value_tensors_);
} else {
if (slot_size_array_.size() == embedding_data_.embedding_params_.slot_num) {
#ifndef DATA_READING_TEST
init_embedding(slot_size_array_, embedding_data_.embedding_params_.embedding_vec_size,
value_table_tensors_, hash_table_slot_id_tensors_);
#endif
} else {
throw std::runtime_error(
std::string("[HCDEBUG][ERROR] Runtime error: the size of slot_sizes != slot_num\n"));
}
}
}
init_embedding 将会在每个GPU之上建立嵌入表。
template <typename TypeHashKey, typename TypeEmbeddingComp>
void LocalizedSlotSparseEmbeddingHash<TypeHashKey, TypeEmbeddingComp>::init_embedding(
const std::vector<size_t> &slot_sizes, size_t embedding_vec_size,
std::vector<Tensors2<float>> &hash_table_value_tensors,
Tensors2<size_t> &hash_table_slot_id_tensors) {
// 拿到本节点GPU数目和全局GPU数目
size_t local_gpu_count = embedding_data_.get_resource_manager().get_local_gpu_count();
size_t total_gpu_count = embedding_data_.get_resource_manager().get_global_gpu_count();
for (size_t id = 0; id < local_gpu_count; id++) { // 遍历本地GPU
// 这里使用global id来设置
size_t device_id = embedding_data_.get_local_gpu(id).get_device_id();
size_t global_id = embedding_data_.get_local_gpu(id).get_global_id();
functors_.init_embedding_per_gpu(global_id, total_gpu_count, slot_sizes, embedding_vec_size,
hash_table_value_tensors[id], hash_table_slot_id_tensors[id],
embedding_data_.get_local_gpu(id));
}
for (size_t id = 0; id < local_gpu_count; id++) {
CK_CUDA_THROW_(cudaStreamSynchronize(embedding_data_.get_local_gpu(id).get_stream()));
}
return;
}
我们来分析 init_embedding_per_gpu,其实就是简单的用 % 运算来进行分配。举出一个例子来看看:假如10个slot,3个GPU,则slot ID是 0~9,GPU id是0~2。0~10 % 3 = 0,1,2,0,1,2,0,1,2,0,所以10个slot 被分配到3个GPU,分别是:
-
GPU 0 :0,3,6,9
-
GPU 1 : 1,4,7,
-
GPU 2 :2,5,8,
所以,slot per gpu 是不相等的。
void SparseEmbeddingFunctors::init_embedding_per_gpu(size_t gid, size_t total_gpu_count,
const std::vector<size_t> &slot_sizes,
size_t embedding_vec_size,
Tensors2<float> &embedding_tables,
Tensor2<size_t> &slot_ids,
const GPUResource &gpu_resource) {
CudaDeviceContext context(gpu_resource.get_device_id());
size_t *slot_ids_ptr = slot_ids.get_ptr();
size_t key_offset = 0;
size_t value_index_offset = 0;
for (size_t i = 0, j = 0; i < slot_sizes.size(); i++) { // 遍历slot
size_t slot_size = slot_sizes[i];
if ((i % total_gpu_count) == gid) { // 本GPU id
// 只有i等于gid时候,才会继续操作
float up_bound = sqrt(1.f / slot_size);
HugeCTR::UniformGenerator::fill(
embedding_tables[j++], -up_bound, up_bound, gpu_resource.get_sm_count(),
gpu_resource.get_replica_variant_curand_generator(), gpu_resource.get_stream());
// 配置slot id
memset_const(slot_ids_ptr, i, slot_size, gpu_resource.get_stream());
value_index_offset += slot_size;
slot_ids_ptr += slot_size;
}
key_offset += slot_size;
}
}
我们先总述一下前向传播的步骤:
-
首先,使用 filter_keys_per_gpu 配置 EmbeddingData。
-
其次,使用 forward_per_gpu 从embedding之中进行 look up,即调用 functors_.forward_per_gpu 从本gpu的hashmap做lookup操作,来得到一个稠密向量。
-
使用 all2all_forward 让每个GPU之上拥有所有样本的所有数据。这里最终目的和dist思路类似,每个GPU最后只有若干完整的sample,不同GPU上sample不同。所以就需要把当前sample在其他slot的数据拷贝到本GPU之上。或者说,在all2all的结果之中,只选择当前sample的其他slot。
-
使用 forward_reorder 把每个GPU的数据进行内部顺序调整(后面会详细说明)。
-
使用 store_slot_id 存储 slot id。之所以要保存参数对应的slot id,是因为每个GPU之上原本是不同的slots,现在要把一个样本所有slots都放在同一个GPU之上,所以加载的时候需要知道加载哪个slot。
具体代码如下:
/**
* The forward propagation of embedding layer.
*/
void forward(bool is_train, int eval_batch = -1) override {
#pragma omp parallel num_threads(embedding_data_.get_resource_manager().get_local_gpu_count())
{
size_t i = omp_get_thread_num();
CudaDeviceContext context(embedding_data_.get_local_gpu(i).get_device_id());
if (embedding_data_.embedding_params_.is_data_parallel) {
filter_keys_per_gpu(is_train, i, embedding_data_.get_local_gpu(i).get_global_id(),
embedding_data_.get_resource_manager().get_global_gpu_count());
}
functors_.forward_per_gpu(
embedding_data_.embedding_params_.get_batch_size(is_train), slot_num_per_gpu_[i],
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.embedding_params_.combiner, is_train,
embedding_data_.get_row_offsets_tensors(is_train)[i],
embedding_data_.get_value_tensors(is_train)[i],
*embedding_data_.get_nnz_array(is_train)[i], *hash_tables_[i],
hash_table_value_tensors_[i], hash_value_index_tensors_[i], embedding_feature_tensors_[i],
embedding_data_.get_local_gpu(i).get_stream());
}
// 此时,embedding_feature_tensors_ 里面就是 embedding 表,里面都是 embedding vector
// do all-to-all
#ifndef ENABLE_MPI
if (embedding_data_.get_resource_manager().get_global_gpu_count() > 1) {
functors_.all2all_forward(embedding_data_.get_batch_size_per_gpu(is_train), slot_num_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_feature_tensors_, all2all_tensors_,
embedding_data_.get_resource_manager());
} else {
CK_CUDA_THROW_(cudaMemcpyAsync(
all2all_tensors_[0].get_ptr(), embedding_feature_tensors_[0].get_ptr(),
embedding_data_.get_batch_size_per_gpu(is_train) * slot_num_per_gpu_[0] *
embedding_data_.embedding_params_.embedding_vec_size * sizeof(TypeEmbeddingComp),
cudaMemcpyDeviceToDevice, embedding_data_.get_local_gpu(0).get_stream()));
}
#else
if (embedding_data_.get_resource_manager().get_global_gpu_count() > 1) {
functors_.all2all_forward(embedding_data_.get_batch_size_per_gpu(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_feature_tensors_, all2all_tensors_,
embedding_data_.get_resource_manager());
} else {
CK_CUDA_THROW_(cudaMemcpyAsync(
all2all_tensors_[0].get_ptr(), embedding_feature_tensors_[0].get_ptr(),
(size_t)embedding_data_.get_batch_size_per_gpu(is_train) * slot_num_per_gpu_[0] *
embedding_data_.embedding_params_.embedding_vec_size * sizeof(TypeEmbeddingComp),
cudaMemcpyDeviceToDevice, embedding_data_.get_local_gpu(0).get_stream()));
}
#endif
// reorder
functors_.forward_reorder(embedding_data_.get_batch_size_per_gpu(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size,
all2all_tensors_, embedding_data_.get_output_tensors(is_train),
embedding_data_.get_resource_manager());
// store slot ids
functors_.store_slot_id(embedding_data_.embedding_params_.get_batch_size(is_train),
embedding_data_.embedding_params_.slot_num, slot_num_per_gpu_,
embedding_data_.get_row_offsets_tensors(is_train),
hash_value_index_tensors_, hash_table_slot_id_tensors_,
embedding_data_.get_resource_manager());
return;
}
我们先用下图举例,这里假定一共2个sample,一共4个slot。embedding_vec_size = 8,batch_size_per_gpu = 2。这里就有一个重要的地方:就是如何确定哪个GPU之上有哪个slot。
0~3 % 2 = 0, 1, 0, 1,所以4个slot 被分配到2个GPU,分别是:
- GPU 0 :slot 0,slot 2;
- GPU 1 : slot 1,slot 3;
需要注意到,这里slot顺序不是1,2,3,4,这就是后面要reorder的原因。因为slot不是简单升序,所以下面的数值分配也不是简单的升序,而是:
-
GPU 0 :1,3,5,7;
-
GPU 1 :2,4,6,8;
为什么这样分配?在最后前向传播结束之后可以知道。
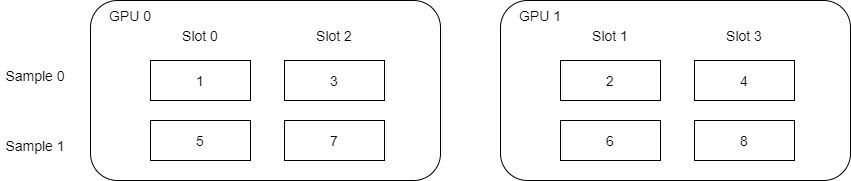
因为 forward_per_gpu 函数已经在前文介绍过,所以我们直接来看 alltoall操作。
我们前文介绍过,每个GPU在本地获取到稠密向量之后,会存入 embedding_feature_tensors_。这是一维数组,在 dist 类型下,长度为 sample_num(batch_size) * slot_num_per_gpu[i] * embedding_vec_size。在local这里就是:batch_size_per_gpu * slot_num_per_gpu[i] * embedding_vec_size。
所以接下来就要在各个GPU之间彼此发送 embedding_feature_tensors_,然后每个GPU只接受自己应该接受的。
template <typename Type>
void SparseEmbeddingFunctors::all2all_forward(size_t batch_size_per_gpu,
const std::vector<size_t> &slot_num_per_gpu,
size_t embedding_vec_size,
const Tensors2<Type> &send_tensors,
Tensors2<Type> &recv_tensors,
const ResourceManager &resource_manager) {
size_t local_gpu_count = resource_manager.get_local_gpu_count();
// Fill in partition table, ith Topo GPU to jth Topo GPU
std::vector<std::vector<size_t>> table(local_gpu_count, std::vector<size_t>(local_gpu_count));
for (size_t i = 0; i < local_gpu_count; i++) {
size_t element_per_send = batch_size_per_gpu * slot_num_per_gpu[i] * embedding_vec_size;
for (size_t j = 0; j < local_gpu_count; j++) {
table[i][j] = element_per_send;
}
}
std::vector<const Type *> src(local_gpu_count);
std::vector<Type *> dst(local_gpu_count);
for (size_t id = 0; id < local_gpu_count; id++) {
src[id] = send_tensors[id].get_ptr();
dst[id] = recv_tensors[id].get_ptr();
}
std::vector<std::vector<const Type *>> src_pos(local_gpu_count,
std::vector<const Type *>(local_gpu_count));
std::vector<std::vector<Type *>> dst_pos(local_gpu_count, std::vector<Type *>(local_gpu_count));
// 设定源数据的offset
// Calculate the src offset pointer from each GPU to each other
for (size_t i = 0; i < local_gpu_count; i++) {
size_t src_offset = 0;
for (size_t j = 0; j < local_gpu_count; j++) {
src_pos[i][j] = src[i] + src_offset;
src_offset += table[i][j];
}
}
// 设定目标数据的offset
// Calculate the dst offset pointer from each GPU to each other
for (size_t i = 0; i < local_gpu_count; i++) {
size_t dst_offset = 0;
for (size_t j = 0; j < local_gpu_count; j++) {
dst_pos[i][j] = dst[i] + dst_offset;
dst_offset += table[j][i];
}
}
// need to know the Type
ncclDataType_t type;
switch (sizeof(Type)) {
case 2:
type = ncclHalf;
break;
case 4:
type = ncclFloat;
break;
default:
CK_THROW_(Error_t::WrongInput, "Error: Type not support by now");
}
// Do the all2all transfer
CK_NCCL_THROW_(ncclGroupStart());
for (size_t i = 0; i < local_gpu_count; i++) {
const auto &local_gpu = resource_manager.get_local_gpu(i);
for (size_t j = 0; j < local_gpu_count; j++) {
CK_NCCL_THROW_(ncclSend(src_pos[i][j], table[i][j], type, j, local_gpu->get_nccl(),
local_gpu->get_stream()));
CK_NCCL_THROW_(ncclRecv(dst_pos[i][j], table[j][i], type, j, local_gpu->get_nccl(),
local_gpu->get_stream()));
}
}
CK_NCCL_THROW_(ncclGroupEnd());
return;
}
MPI_Alltoall与MPI_AllGahter相比较,区别在于:
- MPI_AllGather:不同进程从某一进程(聚集结果进程)收集到的数据完全相同。
- MPI_Alltoall:不同的进程从某一进程(聚集结果进程)收集到的数据不同。
比如发送的是:
rank=0, 发送 0 1 2
rank=1, 发送 3 4 5
rank=2, 发送 6 7 8
则接受的是:
rank=0, 接受 0 3 6
rank=1, 接受 1 4 7
rank=2, 接受 2 5 8
针对我们的例子,目前如下:
GPU0发送:1,3,5,7
GPU1发送:2,4,6,8
GPU0接受:1,3,2,4
GPU1接受:5,7,6,8
得到如下,"..." 代表 all2all_tensors_ 长度不止是4个item。
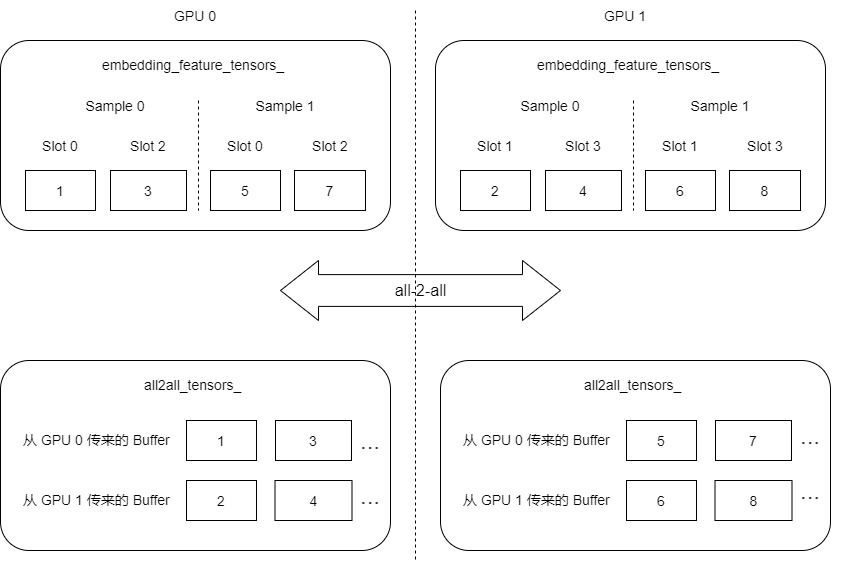
我们可以发现,现在每个GPU之上都拥有自己的数据(每个GPU都是一个完整的sample),但是sample数据内部顺序有点问题,不是按照slot升序,我们把上图再大致调整细化一下(图例与实际变量有出入,这里只是为了更好的演示)。
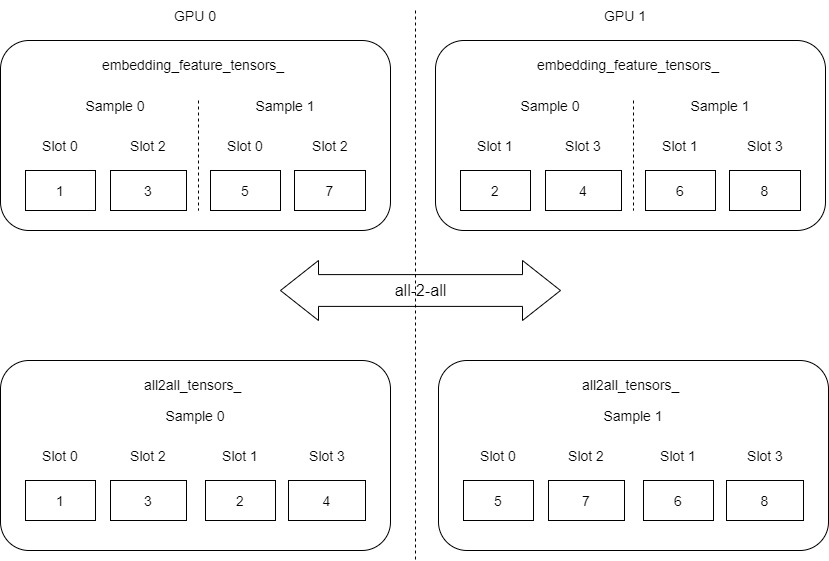
接下来使用 Reorder 从 all2all_tensor 拷贝到 embedding_data_.get_output_tensors(is_train),在拷贝过程中选择会调整顺序,目的是把 slot 0, slot 2, slot 1 , slot 3 转换为 slot 0, slot 1, slot 2, slot3。
template <typename TypeEmbeddingComp>
void SparseEmbeddingFunctors::forward_reorder(size_t batch_size_per_gpu, size_t slot_num,
size_t embedding_vec_size, size_t total_gpu_count,
const Tensors2<TypeEmbeddingComp> &src_tensors,
Tensors2<TypeEmbeddingComp> &dst_tensors,
const ResourceManager &resource_manager) {
CudaDeviceContext context;
size_t local_gpu_count = resource_manager.get_local_gpu_count();
for (size_t id = 0; id < local_gpu_count; id++) { // 遍历本地GPU
const auto &local_gpu = resource_manager.get_local_gpu(id);
context.set_device(local_gpu->get_device_id());
// 拷贝
do_forward_reorder(batch_size_per_gpu, slot_num, embedding_vec_size, total_gpu_count,
src_tensors[id].get_ptr(), dst_tensors[id].get_ptr(),
local_gpu->get_stream());
}
}
do_forward_reorder 代码如下,其是依靠 forward_reorder_kernel 完成具体逻辑。
template <typename TypeEmbeddingComp>
void do_forward_reorder(size_t batch_size_per_gpu, size_t slot_num, size_t embedding_vec_size,
size_t total_gpu_count, const TypeEmbeddingComp *input,
TypeEmbeddingComp *output, cudaStream_t stream) {
const size_t grid_size = batch_size_per_gpu;
const size_t block_size = embedding_vec_size;
forward_reorder_kernel<<<grid_size, block_size, 0, stream>>>(
batch_size_per_gpu, slot_num, embedding_vec_size, total_gpu_count, input, output);
}
具体逻辑是:
- gpu_num 是全局有多少个GPU,后面也是想依据全局信息来计算,因为 all2all之后已经是一个全局视角了。
- 拿到当前样本在当前GPU的sample id(其实就是bid,每个bid对应一个sample),后面都是针对这个sample id进行处理,这样能保证只保留本GPU的sample。比如第2个sample,则sample_id = 1。
- 拿到当前样本的第一个slot的起始位置,比如 1 * 4 * 8 = 32。
- 得到一个slot对应的embedding vector的大小,就是slot和slot之间的stride = 8
- 遍历sample的slots,范围是0~slot num,目的是从 all2all 之中拷贝这些slots到embedding_data_.get_output_tensors,所以需要找到本sample的slot在all2all的起始位置。
- 对于每个slot,需要找到slot在哪个gpu之上。
- 遍历GPU,遍历GPU的目的是,因为slot是按照GPU分配的,所以找前面GPU的位置,其实就是找前面slot的位置。offset_pre 最终得到的就是在本slot之前的GPU之上有多少个slots。
- 这里关键代码是 gpu_id = slot_id % gpu_num,这个用来确定“在哪个GPU传来的buffer之上找到某个slot”。
- 针对我们例子,alltoall发送时候,是2个slot一起发送,这里reorder则需要一个slot一个slot的进行寻找数据,此时gpu_id就是用来寻找的关键点。
- 得到每个GPU对应几个slot。
- 得到当前sample在当前GPU的offset。
- 得到当前sample在其他slot对应的数据起始位置。
- 得到当前slot在 embedding_data_.get_output_tensors 之中的目标位置。
- 拷贝本sample对应的第slot_id的信息。
- 遍历GPU,遍历GPU的目的是,因为slot是按照GPU分配的,所以找前面GPU的位置,其实就是找前面slot的位置。offset_pre 最终得到的就是在本slot之前的GPU之上有多少个slots。
代码如下:
// reorder operation after all2all in forward propagation
template <typename TypeEmbeddingComp>
__global__ void forward_reorder_kernel(int batch_size_per_gpu, int slot_num, int embedding_vec_size,
int gpu_num, const TypeEmbeddingComp *input,
TypeEmbeddingComp *output) {
// blockDim.x = embedding_vec_size; // each thread corresponding to one element of embedding
// vector gridDim.x = batch_size / gpu_num = samples_per_gpu; // each block corresponding to one
// sample on each GPU Each thread needs to process slot_num slots
int tid = threadIdx.x;
int bid = blockIdx.x;
// 当前GPU的sample id,后面都是针对这个sample id进行处理,这样能保证只保留本GPU的sample
int sample_id = bid; // sample_id on the current GPU,比如第2个sample,sample_id = 1
if ((bid < batch_size_per_gpu) && (tid < embedding_vec_size)) {
// 当前样本的第一个slot的起始位置,比如 1 * 4 * 8 = 32
int dst_offset =
sample_id * slot_num * embedding_vec_size; // offset for the first slot of one sample
// 一个slot对应的embedding vector的大小,就是slot和slot之间的stride = 8
int dst_stride = embedding_vec_size; // stride from slot to slot
// 遍历sample的slots,范围是0~slot num,目的是从 all2all 之中拷贝这些slots到embedding_data_.get_output_tensors
// 所以需要找到本sample的slot在all2all的起始位置
for (int slot_id = 0; slot_id < slot_num; slot_id++) {
int gpu_id = slot_id % gpu_num; // 关键代码,确定slot在哪个gpu之上
int offset_pre = 0; // offset in previous gpus
// 遍历GPU的目的是,因为slot是按照GPU分配的,所以找前面GPU的位置,其实就是找前面slot的位置
// offset_pre 最终得到的就是在本slot之前的GPU之上有多少个slots
for (int id = 0; id < gpu_id; id++) {
int slot_num_per_gpu = slot_num / gpu_num + ((id < (slot_num % gpu_num)) ? 1 : 0);
int stride = batch_size_per_gpu * slot_num_per_gpu;
offset_pre += stride; // 找到前面的位置
}
// 每个GPU对应几个slot
int slot_num_per_gpu = slot_num / gpu_num + ((gpu_id < (slot_num % gpu_num)) ? 1 : 0);
// 当前sample在当前GPU的offset
int offset_cur = sample_id * slot_num_per_gpu; // offset in current gpu
// 当前sample在其他slot对应的数据起始位置
// (offset_cur + offset_pre + (int)(slot_id / gpu_num))就是本slot前面有多少个slot
int src_addr = (offset_cur + offset_pre + (int)(slot_id / gpu_num)) * embedding_vec_size;
// 当前slot在 embedding_data_.get_output_tensors 之中的目标位置
int dst_addr = dst_offset + dst_stride * slot_id;
// 拷贝本sample对应的第slot_id的信息
output[dst_addr + tid] = input[src_addr + tid];
}
}
}
这里是为了演示,把逻辑简化了, embedding_feature_tensors_, all2all_tensors_ 本来应该是一维数组,这里抽象成了二维数组。
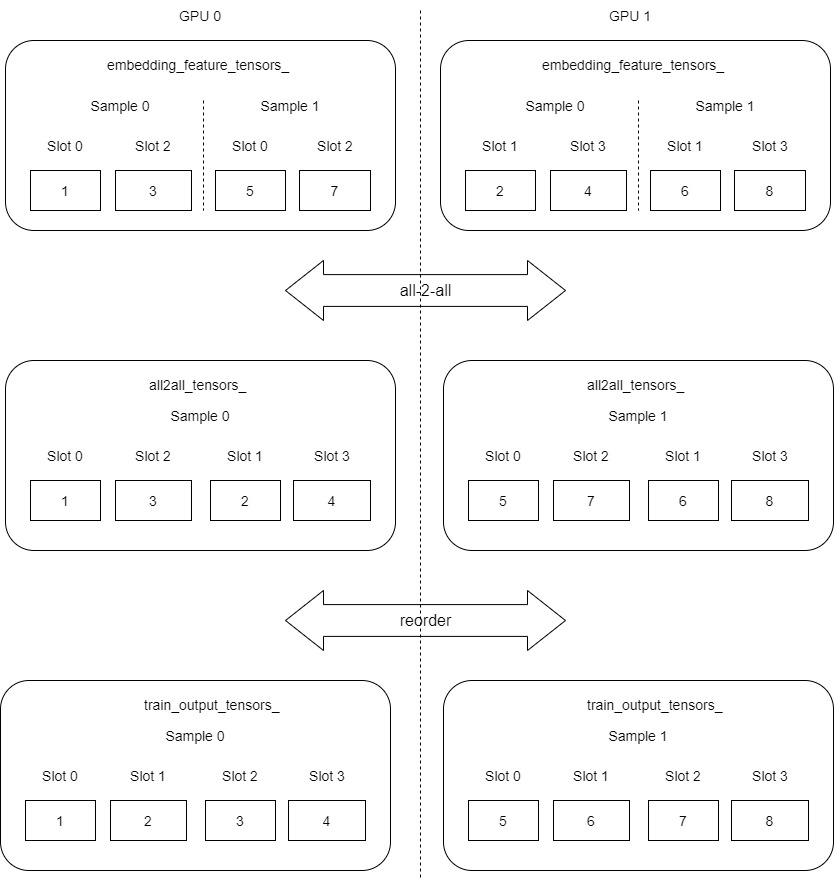
最后需要存储slot id。之所以要保存参数对应的slot id,是因为每个GPU之上原本是不同的slots,现在要把一个样本所有slots都放在同一个GPU之上,所以加载的时候需要知道加载哪个slot。
// store slot_id by row_offset and value_index
template <typename TypeKey, typename TypeValueIndex>
__global__ void store_slot_id_kernel(size_t batch_size,
int slot_num, // total slot number in hash table
int slot_num_per_gpu,
int gpu_num, // total gpu number
int gpu_id, // global gpu device id
const TypeKey *row_offset, const TypeValueIndex *value_index,
TypeValueIndex *slot_id) {
size_t gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < (batch_size * slot_num_per_gpu)) {
int sid = gid % slot_num_per_gpu;
sid = gpu_id + sid * gpu_num; // global slot id
if (sid < slot_num) {
TypeKey offset = row_offset[gid];
int value_num = row_offset[gid + 1] - offset;
for (int i = 0; i < value_num; i++) {
TypeValueIndex index = value_index[offset + i]; // row number
slot_id[index] = sid;
}
}
}
}
} // namespace
template <typename TypeKey>
void SparseEmbeddingFunctors::store_slot_id(size_t batch_size, size_t slot_num,
const std::vector<size_t> &slot_num_per_gpu,
const Tensors2<TypeKey> &row_offset_tensors,
const Tensors2<size_t> &value_index_tensors,
Tensors2<size_t> &slot_id_tensors,
const ResourceManager &resource_manager) {
CudaDeviceContext context;
size_t local_gpu_count = resource_manager.get_local_gpu_count();
size_t total_gpu_count = resource_manager.get_global_gpu_count();
for (size_t id = 0; id < local_gpu_count; id++) {
if (slot_num_per_gpu[id] == 0) {
continue;
}
const auto &local_gpu = resource_manager.get_local_gpu(id);
size_t local_device_id = local_gpu->get_device_id();
size_t global_id = local_gpu->get_global_id();
const size_t block_size = 64;
const size_t grid_size = (batch_size * slot_num_per_gpu[id] + block_size - 1) / block_size;
context.set_device(local_device_id);
store_slot_id_kernel<<<grid_size, block_size, 0, local_gpu->get_stream()>>>(
batch_size, slot_num, slot_num_per_gpu[id], total_gpu_count, global_id,
row_offset_tensors[id].get_ptr(), value_index_tensors[id].get_ptr(),
slot_id_tensors[id].get_ptr());
}
}
我们这里通过一个函数来看输出稠密矩阵的大小,其就是 batch_size_per_gpu * slot_num * embedding_vec_size。
// only used for results check
/**
* Get the forward() results from GPUs and copy them to the host pointer
* embedding_feature. This function is only used for unit test.
* @param embedding_feature the host pointer for storing the forward()
* results.
*/
void get_forward_results(bool is_train, Tensor2<TypeEmbeddingComp> &embedding_feature) {
size_t memcpy_size = embedding_data_.get_batch_size_per_gpu(is_train) *
embedding_data_.embedding_params_.slot_num *
embedding_data_.embedding_params_.embedding_vec_size;
functors_.get_forward_results(memcpy_size, embedding_data_.get_output_tensors(is_train),
embedding_feature, utest_forward_temp_tensors_,
embedding_data_.get_resource_manager());
return;
}
get_batch_size_per_gpu 定义如下:
size_t get_batch_size_per_gpu(bool is_train) const {
return embedding_params_.get_batch_size(is_train) / resource_manager_->get_global_gpu_count();
}
因为前向传播先后做了 all2all 和 backward,所以后向传播要先做其反向操作,然后做backward。
虽然我们知道all2all_backward 和 backward_reorder 就是分别做前向传播的逆向操作,但是这里代码还是比较烧脑,结合图来看会更好。
/**
* The first stage of backward propagation of embedding layer,
* which computes the wgrad by the dgrad from the top layer.
*/
void backward() override {
// Read dgrad from output_tensors -> compute wgrad
// reorder
functors_.backward_reorder(embedding_data_.get_batch_size_per_gpu(true),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.get_output_tensors(true), all2all_tensors_,
embedding_data_.get_resource_manager());
// do all2all
#ifndef ENABLE_MPI
if (embedding_data_.get_resource_manager().get_global_gpu_count() > 1) {
functors_.all2all_backward(embedding_data_.get_batch_size_per_gpu(true), slot_num_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
all2all_tensors_, embedding_feature_tensors_,
embedding_data_.get_resource_manager());
} else {
CudaDeviceContext context(embedding_data_.get_local_gpu(0).get_device_id());
CK_CUDA_THROW_(cudaMemcpyAsync(
embedding_feature_tensors_[0].get_ptr(), all2all_tensors_[0].get_ptr(),
embedding_data_.get_batch_size_per_gpu(true) * slot_num_per_gpu_[0] *
embedding_data_.embedding_params_.embedding_vec_size * sizeof(TypeEmbeddingComp),
cudaMemcpyDeviceToDevice, embedding_data_.get_local_gpu(0).get_stream()));
}
#else
if (embedding_data_.get_resource_manager().get_global_gpu_count() > 1) {
functors_.all2all_backward(
embedding_data_.get_batch_size_per_gpu(true), embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size, all2all_tensors_,
embedding_feature_tensors_, embedding_data_.get_resource_manager());
} else {
CudaDeviceContext context(embedding_data_.get_local_gpu(0).get_device_id());
CK_CUDA_THROW_(cudaMemcpyAsync(
embedding_feature_tensors_[0].get_ptr(), all2all_tensors_[0].get_ptr(),
embedding_data_.get_batch_size_per_gpu(true) * slot_num_per_gpu_[0] *
embedding_data_.embedding_params_.embedding_vec_size * sizeof(TypeEmbeddingComp),
cudaMemcpyDeviceToDevice, embedding_data_.get_local_gpu(0).get_stream()));
}
#endif
// do backward
functors_.backward(embedding_data_.embedding_params_.get_batch_size(true), slot_num_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.embedding_params_.combiner,
embedding_data_.get_row_offsets_tensors(true), embedding_feature_tensors_,
wgrad_tensors_, embedding_data_.get_resource_manager());
return;
}
Reorder反向传播目的就是让所有GPU之上的梯度被分散拷贝到 all2all_tensors_ 不同的位置。下图之中,每个slot对应一个梯度embedding vector,现在 train_output_tensors_(gradients) 之中是梯度。现在每个GPU之上的梯度都是一个完整的两个sample的梯度。
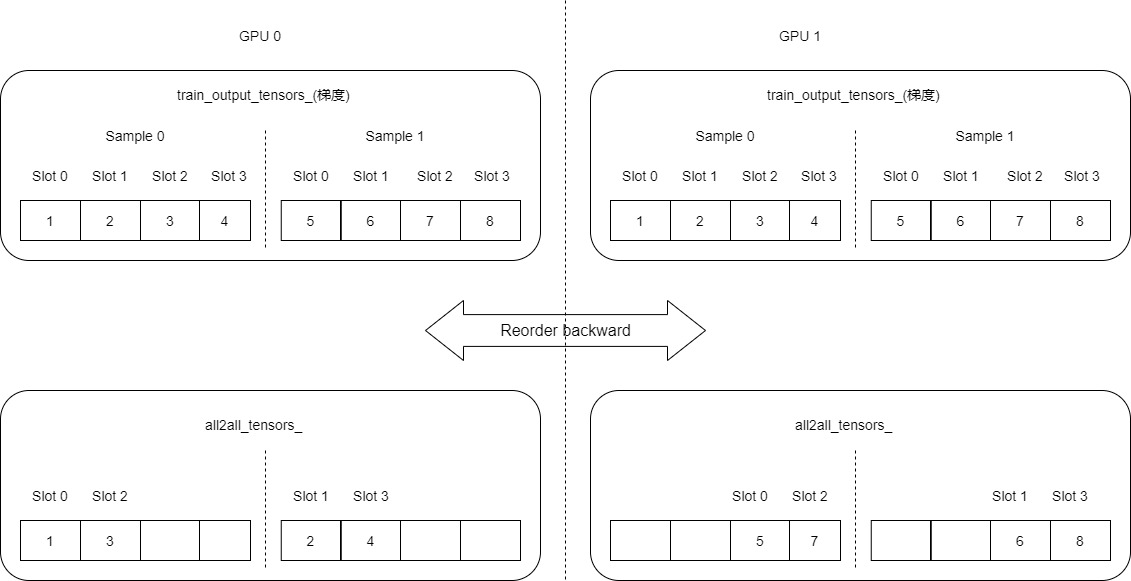
具体代码如下,这里每个GPU上都会有两个bid,分别对应了sample 1 和 sample 2:
// reorder operation before all2all in backward propagation
template <typename TypeEmbeddingComp>
__global__ void backward_reorder_kernel(int batch_size_per_gpu, int slot_num,
int embedding_vec_size, int gpu_num,
const TypeEmbeddingComp *input, TypeEmbeddingComp *output) {
// blockDim.x = embedding_vec_size; // each thread corresponding to one element of embedding
// vector gridDim.x = batch_size / gpu_num = samples_per_gpu; // each block corresponding to one
// sample on each GPU Each thread needs to process slot_num slots
int tid = threadIdx.x;
int bid = blockIdx.x;
int sample_id = bid; // sample_id on the current GPU
if ((bid < batch_size_per_gpu) && (tid < embedding_vec_size)) {
// 源:本样本梯度的起始位置。GPU0是0,GPU1是1*4*embedding_vec_size
int src_offset = sample_id * slot_num * embedding_vec_size;
int src_stride = embedding_vec_size; // 跨度。这里是4
for (int slot_id = 0; slot_id < slot_num; slot_id++) { // 取值是0~3
int gpu_id = slot_id % gpu_num; // 取值是0~1
int offset_pre = 0; // offset in previous gpus
for (int id = 0; id < gpu_id; id++) {
// 数值是2
int slot_num_per_gpu = slot_num / gpu_num + ((id < (slot_num % gpu_num)) ? 1 : 0);
// 数值是2*2
int stride = batch_size_per_gpu * slot_num_per_gpu;
// 找到前面GPU之中,所有样本的起始位置,GPU0是0,GPU1是4
offset_pre += stride;
}
// 目标位置:找到当前GPU之中,本样本的起始位置
// slot_num_per_gpu = 2
int slot_num_per_gpu = slot_num / gpu_num + ((gpu_id < (slot_num % gpu_num)) ? 1 : 0);
// 2*sample_id
int offset_cur = sample_id * slot_num_per_gpu; // offset in current gpu
// 需要注意的是,embedding_vec_size 是4,但是在图上我们都把 embedding_vec_size 归结为一个slot
// 如果对应到图上就是以slot为单位,embedding_vec_size就是1,所以简化如下:
// GPU0=sample_id*2+0+slot_id/gpu_num,sample1是0~1,sample2是4~5
// GPU1=sample_id*2+4+slot_id/gpu_num,sample1是2~3,sample2是6~7
int dst_addr = (offset_cur + offset_pre + (int)(slot_id / gpu_num)) * embedding_vec_size;
// 源位置:找到当前梯度之中,本样本的起始位置
// 需要注意的是,embedding_vec_size 是4,但是在图上我们都把 embedding_vec_size 归结为一个slot
// 如果对应到图上就是以slot为单位,embedding_vec_size就是1,所以简化如下:
// src_offset=sample_id * slot_num
// src_addr = sample_id * slot_num + slot_id
// 则src_addr应该是:sample_id * slot_num + slot_id
// 所以,GPU0,GPU1的取值范围都是sample1=0~3,sample2=4~7
int src_addr = src_offset + src_stride * slot_id;
output[dst_addr + tid] = input[src_addr + tid]; // 把本样本的梯度拷贝到 all2all_tensors_ 张量上应在的位置
}
}
}
这里就是进行交换,本质和前向传播起始一样,把自己群发,但是只接受自己应该接受的。最终每个GPU之上只有自己原先样本的梯度。我们可以看到,最终得到的梯度和原来 embedding_feature_tensors_ 完全对应,无论是 sample,还是 slot,还是具体数值。

具体代码如下:
/**
* nccl all2all communication for backward
* @param batch_size_per_gpu batch size per GPU
* @param slot_num slot number
* @param embedding_vec_size embedding vector size
* @param send_tensors the send tensors of multi GPUs.
* @param recv_tensors the recv tensors of multi GPUs.
* @param device_resources all gpus device resources.
*/
template <typename Type>
void SparseEmbeddingFunctors::all2all_backward(size_t batch_size_per_gpu, size_t slot_num,
size_t embedding_vec_size,
const Tensors2<Type> &send_tensors,
Tensors2<Type> &recv_tensors,
const ResourceManager &resource_manager) {
size_t local_gpu_count = resource_manager.get_local_gpu_count();
size_t total_gpu_count = resource_manager.get_global_gpu_count();
size_t num_proc = resource_manager.get_num_process();
std::vector<const Type *> src(local_gpu_count);
std::vector<Type *> dst(local_gpu_count);
for (size_t id = 0; id < local_gpu_count; id++) {
src[id] = send_tensors[id].get_ptr(); // send_tensors是一个对应了多个GPU的列表
dst[id] = recv_tensors[id].get_ptr(); // recv_tensors是一个对应了多个GPU的列表
}
std::vector<std::vector<size_t>> send_table(local_gpu_count,
std::vector<size_t>(total_gpu_count));
std::vector<std::vector<size_t>> recv_table(local_gpu_count,
std::vector<size_t>(total_gpu_count));
// Fill in receiving partition table, ith Topo GPU receive from jth global GPU
for (size_t i = 0; i < local_gpu_count; i++) {
size_t global_id = resource_manager.get_local_gpu(i)->get_global_id();
size_t slot_num_per_gpu =
slot_num / total_gpu_count + ((global_id < (slot_num % total_gpu_count)) ? 1 : 0);
size_t element_per_recv = batch_size_per_gpu * slot_num_per_gpu * embedding_vec_size;
for (size_t j = 0; j < total_gpu_count; j++) {
recv_table[i][j] = element_per_recv;
}
}
// Fill in sending partition table, ith Topo GPU send to jth global GPU
for (size_t j = 0; j < total_gpu_count; j++) {
size_t global_id = j;
size_t slot_num_per_gpu =
slot_num / total_gpu_count + ((global_id < (slot_num % total_gpu_count)) ? 1 : 0);
size_t element_per_send = batch_size_per_gpu * slot_num_per_gpu * embedding_vec_size;
for (size_t i = 0; i < local_gpu_count; i++) {
send_table[i][j] = element_per_send;
}
}
std::vector<std::vector<const Type *>> src_pos(local_gpu_count,
std::vector<const Type *>(total_gpu_count));
std::vector<std::vector<Type *>> dst_pos(local_gpu_count, std::vector<Type *>(total_gpu_count));
// Calculate the src offset pointer from each GPU to each other
for (size_t i = 0; i < local_gpu_count; i++) {
size_t src_offset = 0;
for (size_t j = 0; j < total_gpu_count; j++) {
src_pos[i][j] = src[i] + src_offset;
src_offset += send_table[i][j];
}
}
// Calculate the dst offset pointer from each GPU to each other
for (size_t i = 0; i < local_gpu_count; i++) {
size_t dst_offset = 0;
for (size_t j = 0; j < total_gpu_count; j++) {
dst_pos[i][j] = dst[i] + dst_offset;
dst_offset += recv_table[i][j];
}
}
// need to know the Type
ncclDataType_t type;
switch (sizeof(Type)) {
case 2:
type = ncclHalf;
break;
case 4:
type = ncclFloat;
break;
default:
CK_THROW_(Error_t::WrongInput, "Error: Type not support by now");
}
// Do the all2all transfer
CK_NCCL_THROW_(ncclGroupStart());
for (size_t i = 0; i < local_gpu_count; i++) {
const auto &local_gpu = resource_manager.get_local_gpu(i);
for (size_t j = 0; j < total_gpu_count; j++) {
CK_NCCL_THROW_(ncclSend(src_pos[i][j], send_table[i][j], type, j, local_gpu->get_nccl(),
local_gpu->get_stream()));
CK_NCCL_THROW_(ncclRecv(dst_pos[i][j], recv_table[i][j], type, j, local_gpu->get_nccl(),
local_gpu->get_stream()));
}
}
CK_NCCL_THROW_(ncclGroupEnd());
return;
}
现在就得到了GPU之上原有样本对应的梯度,于是可以进行backward,这部分在之前介绍过,所以我们不再赘述。
// do backward
functors_.backward(embedding_data_.embedding_params_.get_batch_size(true), slot_num_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.embedding_params_.combiner,
embedding_data_.get_row_offsets_tensors(true), embedding_feature_tensors_,
wgrad_tensors_, embedding_data_.get_resource_manager());
这里简单分析一下。存储时候,rank 0负责写文件。
Error_t Session::download_params_to_files_(std::string weights_file,
std::string dense_opt_states_file,
const std::vector<std::string>& embedding_files,
const std::vector<std::string>& sparse_opt_state_files) {
try {
{
// 存储参数
int i = 0;
for (auto& embedding_file : embedding_files) {
embeddings_[i]->dump_parameters(embedding_file);
i++;
}
}
{
// 存储优化器
int i = 0;
for (auto& sparse_opt_state_file : sparse_opt_state_files) {
std::ofstream out_stream_opt(sparse_opt_state_file, std::ofstream::binary);
embeddings_[i]->dump_opt_states(out_stream_opt);
out_stream_opt.close();
i++;
}
}
// rank 0 节点负责写文件
if (resource_manager_->is_master_process()) {
std::ofstream out_stream_weight(weights_file, std::ofstream::binary);
networks_[0]->download_params_to_host(out_stream_weight);
std::ofstream out_dense_opt_state_weight(dense_opt_states_file, std::ofstream::binary);
networks_[0]->download_opt_states_to_host(out_dense_opt_state_weight);
std::string no_trained_params = networks_[0]->get_no_trained_params_in_string();
if (no_trained_params.length() != 0) {
std::string ntp_file = weights_file + ".ntp.json";
std::ofstream out_stream_ntp(ntp_file, std::ofstream::out);
out_stream_ntp.write(no_trained_params.c_str(), no_trained_params.length());
out_stream_ntp.close();
}
out_stream_weight.close();
out_dense_opt_state_weight.close();
}
} catch (const internal_runtime_error& rt_err) {
std::cerr << rt_err.what() << std::endl;
return rt_err.get_error();
} catch (const std::exception& err) {
std::cerr << err.what() << std::endl;
return Error_t::UnspecificError;
}
return Error_t::Success;
}
以 optimizer 为例,其他worker节点把数据发给rank0节点,rank 0 节点收到数据之后,会进行处理。
template <typename TypeEmbeddingComp>
void SparseEmbeddingFunctors::dump_opt_states(
std::ofstream& stream, const ResourceManager& resource_manager,
std::vector<Tensors2<TypeEmbeddingComp>>& opt_states) {
size_t local_gpu_count = resource_manager.get_local_gpu_count();
CudaDeviceContext context;
for (auto& opt_state : opt_states) {
size_t total_size = 0;
for (size_t id = 0; id < local_gpu_count; id++) {
total_size += opt_state[id].get_size_in_bytes();
}
size_t max_size = total_size;
#ifdef ENABLE_MPI
bool is_master_process = resource_manager.is_master_process();
CK_MPI_THROW_(MPI_Reduce(is_master_process ? MPI_IN_PLACE : &max_size, &max_size,
sizeof(size_t), MPI_CHAR, MPI_MAX,
resource_manager.get_master_process_id(), MPI_COMM_WORLD));
#endif
std::unique_ptr<char[]> h_opt_state(new char[max_size]);
size_t offset = 0;
for (size_t id = 0; id < local_gpu_count; id++) {
size_t local_size = opt_state[id].get_size_in_bytes();
auto& local_gpu = resource_manager.get_local_gpu(id);
context.set_device(local_gpu->get_device_id());
CK_CUDA_THROW_(cudaMemcpyAsync(h_opt_state.get() + offset, opt_state[id].get_ptr(),
local_size, cudaMemcpyDeviceToHost, local_gpu->get_stream()));
offset += local_size;
}
sync_all_gpus(resource_manager);
int pid = resource_manager.get_process_id();
if (resource_manager.is_master_process()) {
// rank 0负责写
stream.write(h_opt_state.get(), total_size);
}
#ifdef ENABLE_MPI
else {
// 其他worker节点把数据发给rank0节点
int tag = (pid << 8) | 0xBA;
CK_MPI_THROW_(MPI_Send(h_opt_state.get(), total_size, MPI_CHAR,
resource_manager.get_master_process_id(), tag, MPI_COMM_WORLD));
}
if (resource_manager.is_master_process()) {
for (int r = 1; r < resource_manager.get_num_process(); r++) {
int tag = (r << 8) | 0xBA;
int recv_size = 0;
MPI_Status status;
CK_MPI_THROW_(MPI_Probe(r, tag, MPI_COMM_WORLD, &status));
CK_MPI_THROW_(MPI_Get_count(&status, MPI_CHAR, &recv_size));
// rank 0节点收到数据
CK_MPI_THROW_(MPI_Recv(h_opt_state.get(), recv_size, MPI_CHAR, r, tag, MPI_COMM_WORLD,
MPI_STATUS_IGNORE));
stream.write(h_opt_state.get(), recv_size);
}
}
#endif
MESSAGE_("Done");
}
}
https://developer.nvidia.com/blog/introducing-merlin-hugectr-training-framework-dedicated-to-recommender-systems/
https://developer.nvidia.com/blog/announcing-nvidia-merlin-application-framework-for-deep-recommender-systems/
https://developer.nvidia.com/blog/accelerating-recommender-systems-training-with-nvidia-merlin-open-beta/
HugeCTR源码阅读
embedding层如何反向传播
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html
稀疏矩阵存储格式总结+存储效率对比:COO,CSR,DIA,ELL,HYB
无中生有:论推荐算法中的Embedding思想
tf.nn.embedding_lookup函数原理
求通俗讲解下tensorflow的embedding_lookup接口的意思?
【技术干货】聊聊在大厂推荐场景中embedding都是怎么做的