火焰图(flame graph)是性能分析的利器。本文介绍它的基本用法。
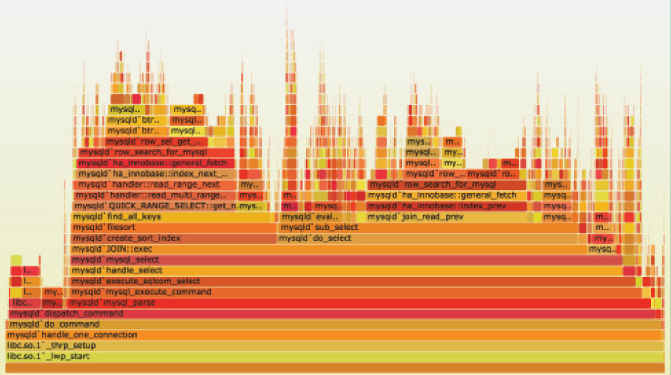
让我们从 perf 命令(performance 的缩写)讲起,它是 Linux 系统原生提供的性能分析工具,会返回 CPU 正在执行的函数名以及调用栈(stack)。
通常,它的执行频率是 99Hz(每秒99次),如果99次都返回同一个函数名,那就说明 CPU 这一秒钟都在执行同一个函数,可能存在性能问题。
$ sudo perf record -F 99 -p 13204 -g -- sleep 30
上面的代码中,perf record表示记录,-F 99表示每秒99次,-p 13204是进程号,即对哪个进程进行分析,-g表示记录调用栈,sleep 30则是持续30秒。
运行后会产生一个庞大的文本文件。如果一台服务器有16个 CPU,每秒抽样99次,持续30秒,就得到 47,520 个调用栈,长达几十万甚至上百万行。
为了便于阅读,perf record命令可以统计每个调用栈出现的百分比,然后从高到低排列。
$ sudo perf report -n --stdio
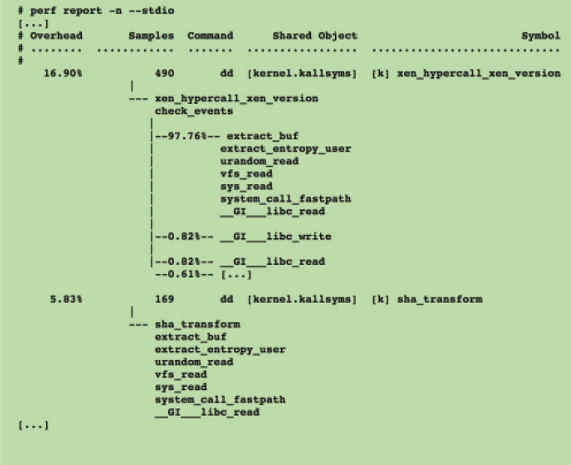
这个结果还是不易读,所以才有了火焰图。
二、火焰图的含义火焰图是基于 perf 结果产生的 SVG 图片,用来展示 CPU 的调用栈。
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
三、互动性火焰图是 SVG 图片,可以与用户互动。
(1)鼠标悬浮
火焰的每一层都会标注函数名,鼠标悬浮时会显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比。下面是一个例子。
mysqld'JOIN::exec (272,959 samples, 78.34 percent)
(2)点击放大
在某一层点击,火焰图会水平放大,该层会占据所有宽度,显示详细信息。

左上角会同时显示"Reset Zoom",点击该链接,图片就会恢复原样。
(3)搜索
按下 Ctrl + F 会显示一个搜索框,用户可以输入关键词或正则表达式,所有符合条件的函数名会高亮显示。
四、火焰图示例下面是一个简化的火焰图例子。
首先,CPU 抽样得到了三个调用栈。
func_c func_b func_a start_thread func_d func_a start_thread func_d func_a start_thread
上面代码中,start_thread是启动线程,调用了func_a。后者又调用了func_b和func_d,而func_b又调用了func_c。
经过合并处理后,得到了下面的结果,即存在两个调用栈,第一个调用栈抽中1次,第二个抽中2次。
start_thread;func_a;func_b;func_c 1 start_thread;func_a;func_d 2
有了这个调用栈统计,火焰图工具就能生成 SVG 图片。

上面图片中,最顶层的函数g()占用 CPU 时间最多。d()的宽度最大,但是它直接耗用 CPU 的部分很少。b()和c()没有直接消耗 CPU。因此,如果要调查性能问题,首先应该调查g(),其次是i()。
另外,从图中可知a()有两个分支b()和h(),这表明a()里面可能有一个条件语句,而b()分支消耗的 CPU 大大高于h()。
两种情况下,无法画出火焰图,需要修正系统行为。
(1)调用栈不完整
当调用栈过深时,某些系统只返回前面的一部分(比如前10层)。
(2)函数名缺失
有些函数没有名字,编译器只用内存地址来表示(比如匿名函数)。
六、Node 应用的火焰图Node 应用的火焰图就是对 Node 进程进行性能抽样,与其他应用的操作是一样的。
$ perf record -F 99 -p `pgrep -n node` -g -- sleep 30
详细的操作可以看这篇文章。
七、浏览器的火焰图Chrome 浏览器可以生成页面脚本的火焰图,用来进行 CPU 分析。
打开开发者工具,切换到 Performance 面板。然后,点击"录制"按钮,开始记录数据。这时,可以在页面进行各种操作,然后停止"录制"。
这时,开发者工具会显示一个时间轴。它的下方就是火焰图。

浏览器的火焰图与标准火焰图有两点差异:它是倒置的(即调用栈最顶端的函数在最下方);x 轴是时间轴,而不是抽样次数。

Async-profiler是一个对系统性能影响很少的Java采样分析器,它的实现是基于HotSpot特有的API,通过这些特有的API收集堆栈跟踪和跟踪内存分配,因而其可以和OpenJDK、Oracle JDK和其他基于HotSpot JVM的Java应用在运行时协同工作。
Github项目链接地址:https://github.com/jvm-profiling-tools/async-profiler
Async-profiler可以跟踪以下类型的事件:
- CPU周期;
- 硬件和软件性能计数器,如缓存未命中、分支未命中、页面错误、上下文切换等;
- Java堆中的分配;
- 满足的锁定尝试,包括Java对象监视器和可重入锁;
支持的平台Linux / x64 / x86 / ARM / AArch64macOS / x64注意:macOS分析仅限于用户空间代码。
生成的火焰图,绿色代表用户栈,黄色代表jvm,红色代表内核;横坐标代表cpu使用的时间。例如:
九、Async-profiler的使用 和 火焰图分析
背景:
目前有一个kafka消费者工程,此工程会消费kafka中的消息,并通过fastjson解析该消息为java实体,然后存入到阻塞队列 BlockingQueue中。另外有若干个线程会从queue中批量拿消息,然后以批量形式写入到 elasticsearch 中。目前在使用中发现存在性能瓶颈,需要定位是该工程对消息转化处理较慢,还是写es操作比较慢。
9.1采集cpu profile数据
我们将代码回退到第一次测试的情况,并启动程序,并找到当前进程号(627891),然后通过如下命令进行采集,并转换为火焰图格式 svg。
./profiler.sh -d 15 -i 50ms -o svg -e cpu 627891 > 627891.svg
-
-d N 分析持续时间(以秒为单位)。如果未提供启动,恢复,停止或状态选项,则探查器将运行指定的时间段,然后自动停止。
-
-i N 设置分析间隔(以纳秒或者毫秒等作为单位),默认分析间隔为10ms。
-
-o 转储文件的格式。
等待15s,就会产生结果,生成 627891.svg 文件。vim 627891.svg 并删除第一行,然后下载到本地并使用浏览器打开。
结果如下图,此图俗称火焰图,主要看每个方法的横轴长度,占用横坐标越长的操作,其占用的 cpu 即最长,很直观的。

我们首先发现下图红框内的代码存在严重的性能问题。在append的过程中,获取线程 stack 的过程耗时比较大。从火焰图中分析,耗时占据了接近50%的是,一个logger操作中去拿线程堆栈的过程,那么我们打印的日志的时候,为啥会进行这个操作呢?
首先观察消息日志文件,和一般的日志不同,这里还会打印方法名称,即当前日志时在哪个方法下打印出来的。那么日志框架它是通过线程 stack 去获取到方法名称的,如果配置了 %L,即打印日志所在代码行的情况也是同理。
[2019-10-07 11:50:38 251 INFO ] [PoolDrainDataThreadPool-3] dummy.es.transport.batchAddDocument() - A => {"@timestamp":"2019-10-07T03:50:38.251Z","ipv4":"10.0.49.96:14160;10.0.49.85:14159;10.0.49.85:14160;10.0.49.84:14160;10.0.49.97:14160;10.0.49.96:14159;10.0.49.89:14159;10.0.49.97:14159;10.0.49.86:14159;10.0.49.84:14159;10.0.49.86:14160;10.0.49.89:14160","key":"ss","serviceName":"Redis","spanId":"-496431972509502272","startTs":1570420237,"tag":-1,"timestamp":1570420237329,"traceId":"-2375955836973083482"}
[2019-10-07 11:50:38 251 INFO ] [PoolDrainDataThreadPool-3] dummy.es.transport.batchAddDocument() - A => {"@timestamp":"2019-10-07T03:50:38.251Z","ipv4":"10.0.49.96:14160;10.0.49.85:14159;10.0.49.85:14160;10.0.49.84:14160;10.0.49.97:14160;10.0.49.96:14159;10.0.49.89:14159;10.0.49.97:14159;10.0.49.86:14159;10.0.49.84:14159;10.0.49.86:14160;10.0.49.89:14160","key":"ss","serviceName":"Redis","spanId":"6195051521513685066","startTs":1570420237,"tag":-1,"timestamp":1570420237333,"traceId":"-2375955836973083482"}
观察配置的日志格式:
<appender name="dummyEsAppender"
class="org.apache.log4j.DailyRollingFileAppender">
<param name="File" value="./logs/dummy-es-transport.log"/>
<param name="DatePattern" value="'.'yyyy-MM-dd'.log'"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern"
value="[%d{yyyy-MM-dd HH:mm:ss SSS\} %-5p] [%t] %c.%M() - %m%n"/>
</layout>
</appender>
注意输出格式中的 %M() 一行,这里意味着在打印日志的时候,需要打印当前日志所在执行的方法,这样看来,这个操作严重影响到了性能。
9.3 日志配置规则去除方法名
修改一下日志 append 格式,去掉方法输出,处理速率一下子就达到了7万多。

采用上文中的方法继续使用 async-profiler 生成火焰图,并用浏览器打开。这时候,日志 append 操作所占用的横轴长度显著下降,并且此时速度已经达到了关闭日志append 时的速度,说明修改日志输出格式后能够带来显著的性能提升。

但是观测上图,我们发现了新的性能黑点,如红框所述,我们将其展开,见详细图:

这里主要是一个 toHexString 的操作,竟然占用的cpu资源这么大,这里需要定位。
9.4 ObjectId.toHexString 性能优化查看这一步转换为16进制的字符串的代码如下,我们结合上面的火焰图可以看出来,主要耗时是在 String.format()
这一步操作。
private String toHexString() {
StringBuilder buf = new StringBuilder(24);
byte[] bytes = new byte[12];
bytes[0] = int3(this.timestamp);
bytes[1] = int2(this.timestamp);
bytes[2] = int1(this.timestamp);
bytes[3] = int0(this.timestamp);
bytes[4] = int2(this.machineIdentifier);
bytes[5] = int1(this.machineIdentifier);
bytes[6] = int0(this.machineIdentifier);
bytes[7] = short1(this.processIdentifier);
bytes[8] = short0(this.processIdentifier);
bytes[9] = int2(this.counter);
bytes[10] = int1(this.counter);
bytes[11] = int0(this.counter);
for (byte b : bytes) {
buf.append(String.format("%02x", new Object[]{Integer.valueOf(b & 0xFF)}));
}
return buf.toString();
}
上面这种模式存在比较大的性能问题。byte 数组转换为 16进制字符串性能最好的代码:
private static final char[] HEX_ARRAY = "0123456789ABCDEF".toCharArray();
private String toHexString2() {
//这一步获取到bytes数组,和上面的操作相同,单独抽离出来。
byte[] bytes = this.toByteArray();
char[] hexChars = new char[bytes.length * 2];
for (int j = 0; j < bytes.length; j++) {
int v = bytes[j] & 0xFF;
hexChars[j * 2] = HEX_ARRAY[v >>> 4];
hexChars[j * 2 + 1] = HEX_ARRAY[v & 0x0F];
}
return new String(hexChars);
}
9.5 重新测试
修改完耗时的 toHexString() 操作之后,打包上传到服务器,并重新启动程序,此时发现每秒处理速率已经飙升到了 12万。这种使用频繁又耗时的黑点操作解决以后,果然性能能够得到翻倍的提升。

此时日志输出格式已经优化,并且 toHexString()操作也进行了优化。重新使用 async-profiler 查看一下最新的火焰图信息。

之前的 toHexString() 耗时已经几乎看不到了,但是感觉日志append 的操作横轴还是略长,于是将日志输出关闭来看看极限处理速度。
将日志级别调整为 warn,并启动程序,观测到处理速度已经能够达到 18万/s了,这相当于 toHexString()优化前的快3倍了。

此时决定再将日志append 模式改为异步模式,然后启动程序,观察,处理速率也能够达到 18万/s。

十、参考链接
- 火焰图的介绍论文
- 火焰图官方主页
- 火焰图生成工具
- https://www.ruanyifeng.com/blog/2017/09/flame-graph.html
- https://www.cnblogs.com/leihuazhe/p/11630466.html
(完)