多数的前向推理框架不支持AdaptivePooing操作,此时需要将AdaptivePooing操作转换为普通的Pooling操作。AdaptivePooling与Max/AvgPooling相互转换提供了一种转换方法,但我在Pytorch1.6中的测试结果是错误的。通过查看Pytorch源码(pytorch-master\aten\src\ATen\native\AdaptiveAveragePooling.cpp)我找出了正确的转换方式。
inline int start_index(int a, int b, int c) {
return (int)std::floor((float)(a * c) / b);
}
inline int end_index(int a, int b, int c) {
return (int)std::ceil((float)((a + 1) * c) / b);
}
template <typename scalar_t>
static void adaptive_avg_pool2d_single_out_frame(
scalar_t *input_p,
scalar_t *output_p,
int64_t sizeD,
int64_t isizeH,
int64_t isizeW,
int64_t osizeH,
int64_t osizeW,
int64_t istrideD,
int64_t istrideH,
int64_t istrideW)
{
at::parallel_for(0, sizeD, 0, [&](int64_t start, int64_t end) {
for (auto d = start; d < end; d++)
{
/* loop over output */
int64_t oh, ow;
for(oh = 0; oh < osizeH; oh++)
{
int istartH = start_index(oh, osizeH, isizeH);
int iendH = end_index(oh, osizeH, isizeH);
int kH = iendH - istartH;
for(ow = 0; ow < osizeW; ow++)
{
int istartW = start_index(ow, osizeW, isizeW);
int iendW = end_index(ow, osizeW, isizeW);
int kW = iendW - istartW;
/* local pointers */
scalar_t *ip = input_p + d*istrideD + istartH*istrideH + istartW*istrideW;
scalar_t *op = output_p + d*osizeH*osizeW + oh*osizeW + ow;
/* compute local average: */
scalar_t sum = 0;
int ih, iw;
for(ih = 0; ih < kH; ih++)
{
for(iw = 0; iw < kW; iw++)
{
scalar_t val = *(ip + ih*istrideH + iw*istrideW);
sum += val;
}
}
/* set output to local average */
*op = sum / kW / kH;
}
}
}
});
}
上述代码段中isizeH,isizeW分别表示输入张量的宽高osizeH,osizeW则表示输出宽高。关注第二个for循环for(oh = 0; oh < osizeH; oh++){.....}中的内容。假设输入的宽高均为223isizeH = isizeW = 223,输出的宽高均为7osizeH = osizeW = 224,然后简单分析一下oh=0,1,2时的情况:
oh=0, istartH = 0, iendH = ceil(223/7)=32, kH = 32oh=1, istartH = floor(223/7) = 31, iendH = ceil(223*2/7)=64, kH = 33oh=2, istartH = floor(223*2/7) = 63, iendH = ceil(223*3/7)=96, kH = 33
这里的kH就是kernel_size的大小. oh=0时的kernel_size比其他情况要小,所以需要在输入上添加padding,让oh=0时的kernel_size与其他情况相同。添加的padding大小为1,等价于让istartH从-1开始,即kH = 32-(-1) = 33. 下一个需要获取的参数是stride,stride = istartH[oh=i]-istartH[oh=i-1], 在上述例子中即为32。按照上述的例子分析输入宽高为224的情况可以发现padding=0,所以padding也是一个需要转换的参数。下面给出3个参数的转换公式:
stride = ceil(input_size / output_size)kernel_size = ceil(2 * input_size / output_size) - floor(input_size / output_size)padding = ceil(input_size / output_size) - floor(input_size / output_size)
在上述的代码中最后部分,可以看见均值使用*op = sum / kW / kH计算得到的。这表明在边缘部分计算均值没有考虑padding,所以对应的AvgPool中的count_include_pad应该设为False。下面贴出我的测试代码:
def test(size):
import numpy as np
import torch
x = torch.randn(1,1,size,size)
input_size = np.array(x.shape[2:])
output_size = np.array([7,7])
# stride = ceil(input_size / output_size)
# kernel_size = ceil(2 * input_size / output_size) - floor(input_size / output_size)
# padding = ceil(input_size / output_size) - floor(input_size / output_size)
stride = numpy.ceil(input_size / output_size).astype(int)
kernel_size = (numpy.ceil(2 * input_size / output_size) - numpy.floor(input_size / output_size)).astype(int)
padding = (numpy.ceil(input_size / output_size) - numpy.floor(input_size / output_size)).astype(int)
print(stride)
print(kernel_size)
print(padding)
avg1 = nn.AdaptiveAvgPool2d(list(output_size))
avg2 = nn.AvgPool2d(kernel_size=kernel_size.tolist(), stride=stride.tolist(), padding=padding.tolist(), ceil_mode=False, count_include_pad=False)
max1 = nn.AdaptiveMaxPool2d(list(output_size))
max2 = nn.MaxPool2d(kernel_size=kernel_size.tolist(), stride=stride.tolist(), padding=padding.tolist(), ceil_mode=False )
avg1_out = avg1(x)
avg2_out = avg2(x)
max1_out = max1(x)
max2_out = max2(x)
print(avg1_out-avg2_out)
print(max1_out-max2_out)
print(torch.__version__)
- inH = inW=224时的输出
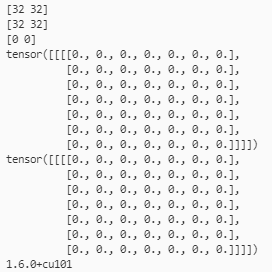
- inH = inW=223时的输出
