- 这篇文章说的是操作,也就是重在应用,更多的是一个入门的或者说一篇概览,所以大佬们多多担待,不涉及底层分析和很多的源码,所以如果看官想看以上两者的可以划走了,有时间又不懒的话,可能以后会写个源码实现+分析的哈哈
- spring存在的意义:一言以蔽之:解耦,为简化开发而生。程序员只需专注于业务代码实现,不必关心底层实现,并将程序员从大量机械重复的工作类似创建对象、数据库取出数据、导jar包等解脱出来,同时提高了程序的可靠性,大量避免因程序员管理对象不当等造成的问题。
- spring优点:
轻量;支持场景广泛;面向接口;面向切面;整合其他优秀框架
本文将从IOC;AOP;(这两者都是一种编程思想);spring整合MyBatis框架;事务这四个最重要的层面展开
而用框架,不管是spring还是其他的,说白了就是上环境,上依赖
点击查看代码
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.5.RELEASE</version>
</dependency>
控制反转,即将对象的创建权限和对象之间的依赖关系交给spring框架的容器
其实我的理解就像是做饭:
每次做饭都要买菜,择菜切菜,准备好佐料然后才是上锅炒,有时候没电气了还要先缴费,吃完了还得收拾桌子。
想想要是每次做都只管炒菜,其他的不管,爽不爽?spring就是干这个的,保证电气水充足,佐料都有,,买菜择菜洗菜就好比是根据产品经理的需求创建业务对象(注意不是写实体类),而这个也就是IOC,
接着话茬,吃完饭或者正在吃的要加量,就是后期运维,收拾碗筷就是产品下架了。
好了,有了我的抛砖,相信初学者会很容易理解。
正转:由程序员进行对象的创建和依赖注入称为正转.程序员说了算.
反转:交由spring框架,也就是IOC
<bean id="stu" class="com.huijixu.bean.Students"></bean>
- manner1
实体类必须提供setter()方法
这里插嘴:如果该类在数据库里有主键,最好有主键的构造器和没有主键的构造器各搞一个。
<property name="" value=""></property>
- manner2
实体类必须提供该类相应成员变量的构造方法
<constructor-arg name="" value=""></constructor-arg>
还有按照下标的,意义不大也不常用,大家有兴趣可以自行查找很简单
- manner3
- byName
按照成员变量的名字让spring去找,一般规范按照驼峰命名法
<property name="myname" value=""></property>
- byType
按照类型寻找在spring里和配置文件中同源的实体类注入,可与byName配合使用,比如上文byName 如果是在<bean id="Students" class="..."></bean>内的,那就是找是Students类的前提下,xml中对象名名称为myname的对象自动引用注入
这种方式在中小项目中常用,本人认为注解比xml整洁美观
-
在spring的配置文件
applicationContext.xml中一定要添加包扫描,不添加包扫描spring就不知道去哪里找你写的注解, -
注解创建对象
@Component:实体类
@Service(k可以添加事务管理):ServiceImple实现类
@Controller:控制类
@Repository:数据访问层实现类对象创建 -
注解给对象赋值
@Value:八种基本类型+String
@Autowired:一般用于service层实现类中对于dao层实现类的对象引用类型注入
@Qualifier("名称") 当应用类型有别名时,它和@Autowried成套使用
- 原因:
当项目体量逐步增大时,合理拆分易于缩小问题代码范围,通知在开发过程中易于成员间避免出现类似“幻读”的情况
- 拆分策略:
按功能模块:
book;users;lead;
按层:mapper 、service、 controller
本人习惯于后者,因为这样可以和三层架构保持统一
- 组合策略(以按层拆为例):
一种直接在spring配置文件在中单写一个,再所拆分的配置文件import进来
分批导入:
<import resource="applicationContest_service.xml"></import>
<import resource="applicationContest_mapper.xml"></import>
....
一次性:
<import resource="applicationContest_*.xml"></import>
- spring.xml 创建业务对象
<bean id="someService"class="com.huijixu.s01.SomeServiceImpl"></bean>
这里的class一定是Copy Reference,部分初学者要么手写出错,要不路径用的是/分隔导致错误 - SqlMapperConfig.xml标签一定注意顺序,错了不识别,具体顺序看jar里的说明来就行
强烈建议新手cv!!
- xml文件id名&接口方法名必须一致
- 字段名&实体类成员变量名一致(可以不一致)
- 成员变量名和sql语句中#{}内的名字一定要必须要一致
- 接口名&对应实现类名必须一致(三层架构七大规范之一)
class,pom.xml,sql语句中,经常会出现大量重复的代码片段,而又不能在抽取细分,而这些又是轻易不会改变的,这时候就可以起别名(或者叫做全局变量)
开发的顺序建立SQL表 -->搭建环境(pom文件,各种基础配置文件)-->
构建实体类-->mapper-->service-->controller-->
测试-->前后端绑定-->测试
这是本人的习惯顺序,有条理可以让开发有条不紊,即使出错了也有检查的大致判断,更是程序员基本素养
良好的单元测试习惯写完一个功能,测一个功能,没毛病了再下一个,不然各个功能模块的bug一起报,不好调试
AOP- 在完成一项业务功能时,对那些重复用到的代码,抽取出来单独开发,然后随用随取,就是AOP,有些类似小项目中自定义的工具类
- 还是用做饭的例子,炒菜的过程中的翻炒;或者说切菜时候的一下一下的切,这些重复的动作,而又是每个炒一道菜(完成一个业务功能)所必须的,就可以理解为AOP,实际开发中,日志,权限,缓存,提交事务等等这些公共通用的就是AOP
- 其实原生的AOP实现是比较麻烦的,所以spring就把aspectJ整合进来了,用AspectJ实现AOP这种编程思想
一言以蔽之:上接口使开发更美好
springAOP几种常见的通知类型@Before@After
上面两者见名知义:分别在目标方法之前和之后调用Around
拦截目标方法,可以访问并且修改目标方法的返回值Throws
目标方法抛异常时使用,常用于事务回滚
- 产生原因:比原生AOP更容易使用
- 两个核心概念:通知和切入点。前者解决何时切入;后者解决在哪切入
- 几个术语:
1.切面aspect:公共部分,用时动态织入
2.连接点joinpoint;目标方法 ,链接业务功能与Buffer功能
3.切入点pointcut:由一个及以上个连接点构成,包,类,方法都可以是切入点,但是final方法不可以作为切入点!!
4.目标对象target:被加Buffer的对象,就是写主业务逻辑的有关对象,比如图书管理系统中,UsersServiceImpl就是一个target
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
<version>5.2.5.RELEASE</version>
</dependency>
execution(访问权限 方法返回值 方法的声明(参数) 异常类型)
*标识任意..标识所有
-e.g.:execution( * com.huijixu.service.impl..*(..))表示以任意访问权限任意返回值类型在com.huijixu.service.impl包下的任意class的任意方法名的任意参数的目标方法为切入点
advice
前置通知@Before
- 方法规范
- 方法访问权限是public
- 方法的返回值是void
- 名称自定义
- 方法没有参数,如果有也只能是JoinPoint类型
- 必须使用@Before注解来声明切入的时机是前切功能和切入点
- 参数:value 指定切入点表达式
@AfterReturning
- 方法规范
- 访问权限是public
- 2)方法没有返回值void
- 3)方法名称自定义
- 4)方法有参数(也可以没有参数,如果目标方法没有返回值,则可以写无参的方法,但一般会写有参,这样可以处理无参可以处理有参),这个切面方法的参数就是目标方法的返回值
- 5)使用@AfterReturning注解表明是后置通知
@Around
- 方法规范
- 访问权限是public
- 切面方法有返回值,此返回值就是目标方法的返回值
- 方法名称自定义
- 方法有参数,此参数就是目标方法
- 回避异常Throwable
- 使用@Around注解声明是环绕通知
- 参数: value:指定切入点表达式
@After
- 方法规范
- 访问权限是public
- 方法没有返回值
- 方法名称自定义
* 方法没有参数,如果有也只能是JoinPoint
* 使用@After注解表明是最终通知
* 参数: value:指定切入点表达式
1)建表
2)新建项目,选择quickstart模板
3)修改目录
4)修改pom.xml文件,添加相关的依赖,spring依赖已经在前文贴出,下面是mybatis,mysql ,jdbc依赖
点击查看代码
<!--jdbc -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.2.5.RELEASE</version>
</dependency>
<!--myBaits -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!--mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<!--alibaba druid 连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.12</version>
</dependency>
<!--mybatis集成spring -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.1</version>
</dependency>
5)添加MyBatis相应的模板,下面贴出自用的SqlMapperConfig.xml & XXXMapper.xml模板供大家使用
点击查看代码
```<!--读取属性文件中数据库的配置-->
<properties resource="db.properties"></properties>
<!--设置日志输出语句,显示相应操作的sql语名-->
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
<typeAliases>
<package name="com.bjpowernode.pojo"></package>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://localhost:3308/ssm?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<package name="mapper文件所在的包名"></package>
</mappers>
点击查看代码
<!-- XXXMapper.xml模板-->
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxxxx.mapper.interface"> <!-- 就是接口的完全限定名,注意新手一定要右键 -> copy reference -> cv 防止不必要的错误-->
</mapper>
6)添加MyBatis核心配置文件SqlMapConfig.xml,并拷贝jdbc.propertiest属性文件到resources目录下
同样给大家给书出。jdbc.properties,部分朋友可能会因为spring版本问题会报更新的错,虽然不影响使用但是影响美观哈哈,所以我的驱动加了'cj.'
点击查看代码
jdbc.driverClassName=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/ssm?useUnicode=true&characterEncoding=utf8
jdbc.username=yours mysql username
jdbc.password= yours password
7)添加applicationContext_mapper.xml
8)添加applicationContext_service.xml
9)添加实体类
10)添加mapper包,添加xxxMapper接口和xxxxMapper.xml文件并开发 (注意几个配套问题:文件名,方法名。。。)
11)添加service包,添加xxxService接口和xxxxServiceImpl实现类
12)添加测试类进行功能测试
大白话就是,我不成,你也别想成,两个关联动作同时失败或者成功。保证数据的唯一性,一致性,原子性,隔离性;
依赖点击查看代码
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>5.2.5.RELEASE</version>
</dependency>
- mysql默认隔离级别为
REPETABLE_READ:可重复读,这里简单提一嘴就是他可以解决脏读,不可重复读,但存在幻读 - 未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
- 提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)
- 可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读,但是innoDB解决了幻读
- 串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
- 使用数据库默认的隔离级别isolation = Isolation.DEFAULT
多个事务之间的合并,互斥等都可以通过设置事务的传播特性来解决
常用特性- PAGATION_REQUIRED:必被包含事务(增删改必用)
- PAGATION_REQUIRES_NEW:自己新开事务,不管之前是否有事务
- OPAGATION_SUPPORTS:支持事务,如果加入的方法有事务,则支持事务,如果没有,不单开事务
- OPAGATION_NEVER:不能运行中事务中,如果包在事务中,抛异常
- OPAGATION_NOT_SUPPORTED:不支持事务,运行在非事务的环境
其中B是嵌套在A中的事务
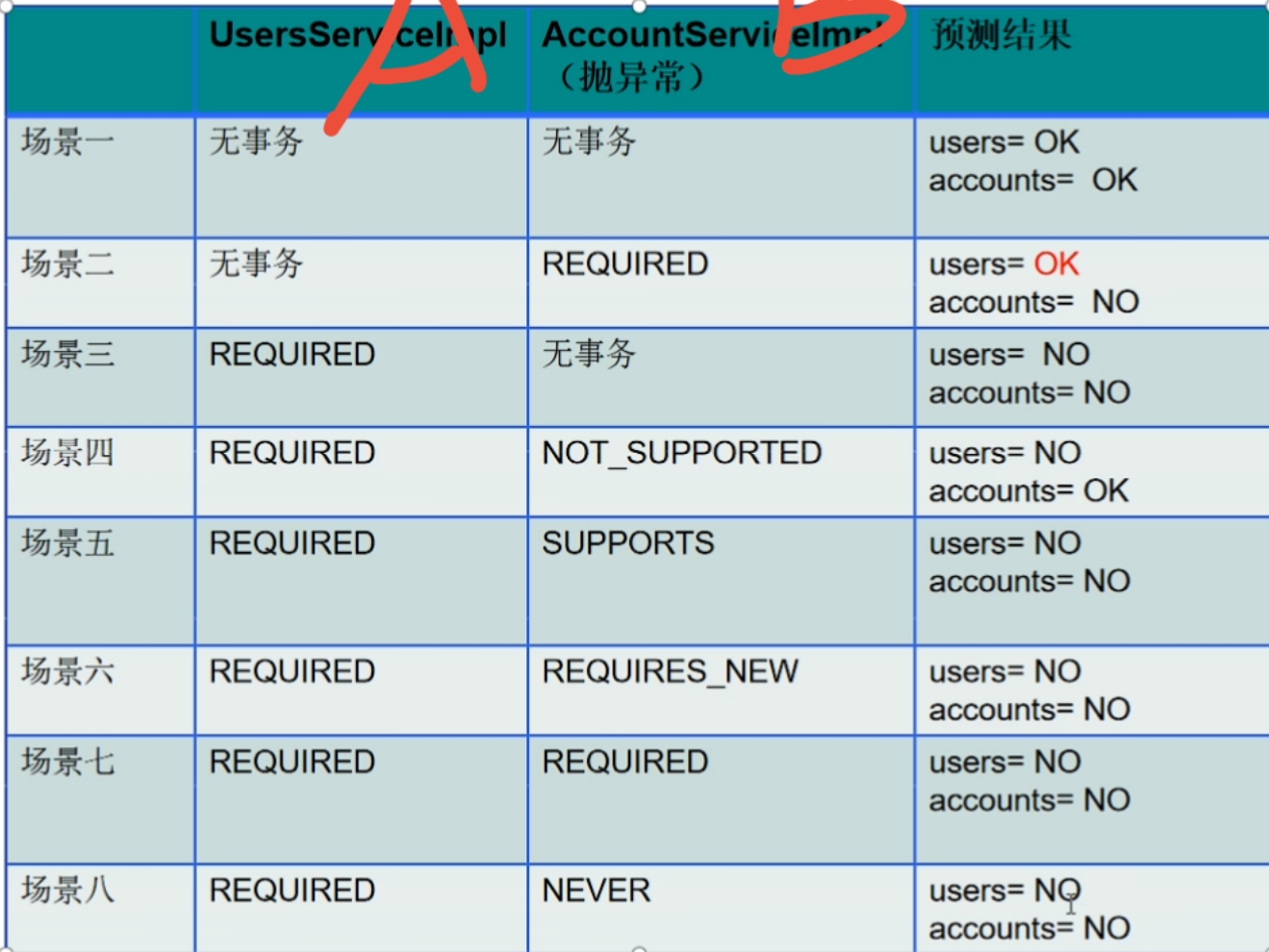
- 1)在applicationContext_service.xml文件中添加事务管理器
ean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <!--因为事务必须关联数据库处理,所以要配置数据源--> <property name="dataSource" ref="dataSource"></property> </bean> - 2)在applicationContext_service.xml文件中添加事务的注解驱动
<tx:annotation-driven transaction-manager="transactionManager"></tx:annotation-driven> - 3)在业务逻辑的实现类上添加注解@Transactional(propagation = Propagation.REQUIRED)
REQUIRED表示增删改操作时必须添加的事务传播特性
下面以curd给出配置事物的代码
点击查看代码
```<!--配置事务切面-->
<tx:advice id="myadvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*select*" read-only="true"/>
<tx:method name="*find*" read-only="true"/>
<tx:method name="*search*" read-only="true"/>
<tx:method name="*get*" read-only="true"/>
<tx:method name="*insert*" propagation="REQUIRED" no-rollback-for="ArithmeticException"/>
<tx:method name="*add*" propagation="REQUIRED"/>
<tx:method name="*save*" propagation="REQUIRED" no-rollback-for="ArithmeticException"/>
<tx:method name="*set*" propagation="REQUIRED"/>
<tx:method name="*update*" propagation="REQUIRED"/>
<tx:method name="*change*" propagation="REQUIRED"/>
<tx:method name="*modify*" propagation="REQUIRED"/>
<tx:method name="*delete*" propagation="REQUIRED"/>
<tx:method name="*remove*" propagation="REQUIRED"/>
<tx:method name="*drop*" propagation="REQUIRED"/>
<tx:method name="*clear*" propagation="REQUIRED"/>
<tx:method name="*" propagation="SUPPORTS"/>
</tx:attributes>
</tx:advice>
<!--绑定切面和切入点-->
<aop:config>
<aop:pointcut id="mycut" expression="execution(* com.bjpowernode.service.impl.*.*(..))"></aop:pointcut>
<aop:advisor advice-ref="myadvice" pointcut-ref="mycut"></aop:advisor>
</aop:config>
@Transactional
@Transactional(propagation = Propagation.REQUIRED,//事务的传播特性
noRollbackForClassName = "ArithmeticException", //指定发生什么异常不回滚,使用的是异常的名称
noRollbackFor = ArithmeticException.class,//指定发生什么异常不回滚,使用的是异常的类型
rollbackForClassName = "",//指定发生什么异常必须回滚
rollbackFor = ArithmeticException.class,//指定发生什么异常必须回滚
timeout = -1, //连接超时设置,默认值是-1,表示永不超时
readOnly = false, //默认是false,如果是查询操作,必须设置为true.
isolation = Isolation.DEFAULT//使用数据库自已的隔离级别
有写错的地方希望大佬们海涵指出!!