本文地址:https://www.ebpf.top/post/ftrace_kernel_dynamic
李程远老师在极客时间 《容器实战高手课》中的 “ 加餐 04 | 理解 ftrace(2):怎么理解 ftrace 背后的技术 tracepoint 和 kprobe?” 留了一道思考题:
想想看,当我们用 kprobe 为一个内核函数注册了 probe 之后,怎样能看到对应内核函数的第一条指令被替换了呢?
kprobe 是内核函数动态跟踪的一种实现机制,使用该机制几乎可跟踪所有的内核函数(排除带有 __kprobes/nokprobe_inline 注解的和标有 NOKPROBE_SYMBOL 的函数)。 kprobe 跟踪机制的实现目前主要有 2 种机制:
-
一般情况下,当 kprobe 函数注册的时候,把目标地址上内核代码的指令码,替换成了 “cc”,也就是 int3 指令。这样一来,当内核代码执行到这条指令的时候,就会触发一个异常而进入到 Linux int3 异常处理函数 do_int3() 里。在
do_int3()这个函数里,进行检查,如果发现有对应的 kprobe 注册了 probe,就会依次执行注册的 pre_handler()、替换前的指令、post_handler()。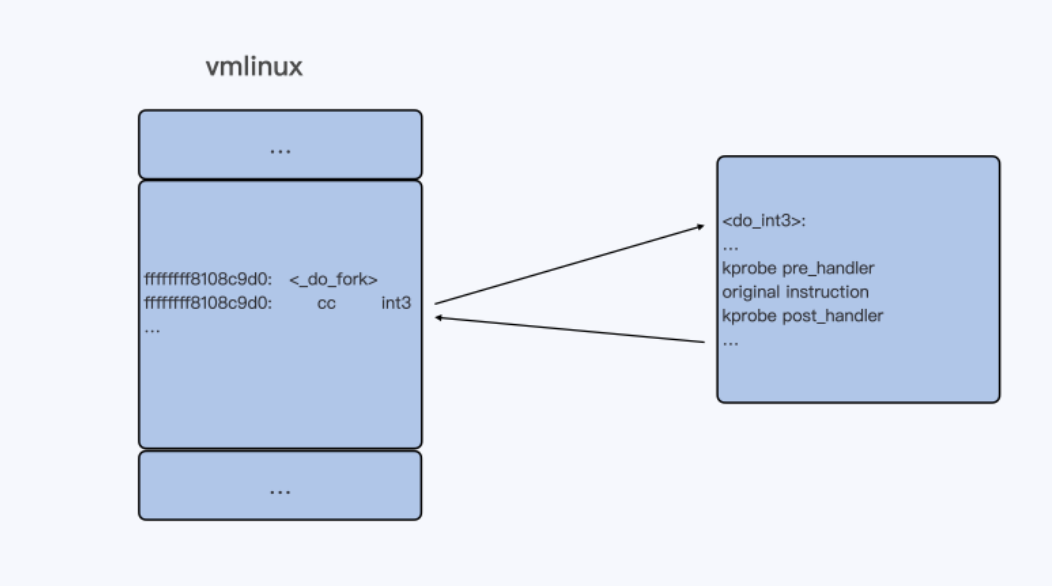
-
如内核基于 ftrace 对函数进行 trace,则会函数头上预留了
callq <__fentry__>的 5 个字节(在启动的时候被替换成了 nop)。kprobe 跟踪机制会复用 ftrace 跟踪预留的 5 个字节,将其替换成ftrace_caller,而不再使用 int3 软中断指令替换。
不论上述那种方式,kprobe 实现原理基本一致:进行目标指令替换,替换的指令可以使程序跳转到一个特定的 handler 里,然后再去执行注册的 probe 的函数。
本文,我将基于 ftrace 机制对整个动态替换的机制进行验证。如对 ftrace 不熟悉,建议提前阅读 Linux 原生跟踪工具 Ftrace 必知必会 。
1. 基础知识 1.1 默认编译我们用 C 语言实现一个非常简单程序进行简单验证:
#include <stdio.h>
#include <stdlib.h>
int a() {
return 0;
}
int main(int argc, char ** argv){
return 0;
}
在默认参数编译后的代码如下,可见函数头部没有特殊定义。
$ gcc -o hello hello.c
$ objdump -S hello
...
0000000000001129 <a>:
1129: f3 0f 1e fa endbr64
112d: 55 push %rbp
112e: 48 89 e5 mov %rsp,%rbp
1131: b8 00 00 00 00 mov $0x0,%eax
1136: 5d pop %rbp
1137: c3 ret
...
-pg 选项
使用 -pg 参数编译后,我们可以看到在函数头部增加了对 mcount 函数的调用,这种机制常用用于运行程序性能分析:
$ gcc -pg -o hello.pg hello.c
$ objdump -S hello.pg
...
00000000000011e9 <a>:
11e9: f3 0f 1e fa endbr64
11ed: 55 push %rbp
11ee: 48 89 e5 mov %rsp,%rbp
11f1: ff 15 f1 2d 00 00 call *0x2df1(%rip) # 3fe8 <mcount@GLIBC_2.2.5>
11f7: b8 00 00 00 00 mov $0x0,%eax
11fc: 5d pop %rbp
11fd: c3 ret
...
1.3 使用gcc 添加 -pg 选项后,编译器都会在函数头部增加 mcount/fentry 函数调用( 设置了 notrace 属性函数除外);
#define notrace __attribute__((no_instrument_function))
-pg 和 -mfentry 选项
在 gcc 4.6 版本后,新增编译选项 -mfentry, 将通过调用实现更加简洁高效的 __fentry__ 函数替换 mcount , 在 Linux Kernel 4.19 x86 体系结构默认使用该方式 。
# echo 'void foo(){}' | gcc -x c -S -o - - -pg -mfentry
$ gcc -pg -mfentry -o hello.pg.entry hello.c
$ objdump -S hello.pg.entry
00000000000011e9 <a>:
11e9: f3 0f 1e fa endbr64
11ed: ff 15 05 2e 00 00 call *0x2e05(%rip) # 3ff8 <__fentry__@GLIBC_2.13>
11f3: 55 push %rbp
11f4: 48 89 e5 mov %rsp,%rbp
11f7: b8 00 00 00 00 mov $0x0,%eax
11fc: 5d pop %rbp
11fd: c3 ret
这里我们以 fentry 为例,该函数调用会占用 5 个字节。 Linux 内核中 fentry 函数被定位为 retq 直接返回。
SYM_FUNC_START(__fentry__)
retq
SYM_FUNC_END(__fentry__)
即使通过 reqt 直接返回,每个函数都调用的时候仍然会带来大概 13% 的性能损耗,在实际运行过程中,ftrace 机制会在内核启动时候将 5 个字节(ff 15 05 2e 00 00 call __fentry__)直接替换成 nop 指令,在 x86_64 体系中为 nop 指令为: 0F 1F 44 00 00H 。
1.4 对内核进行验证在启用 ftrace 动态跟踪机制时(CONFIG_DYNAMIC_FTRACE),设置跟踪函数后,内核会对当前 nop 指令进行动态替换(hot hook),替换成跳转到 ftrace_caller 函数,从而实现了动态跟踪。在替换过程中为了避免引发多核异常,首先将第一个直接替换成 0xcc 的中断指令,然后再替换后续的指令,具体实现参见 void ftrace_replace_code(int enable);
我们以内核函数 schedule 为例,使用 gdb 调试带有符号信息的 vmlinux 文件时,我们可直接查看到函数编译后的汇编代码:
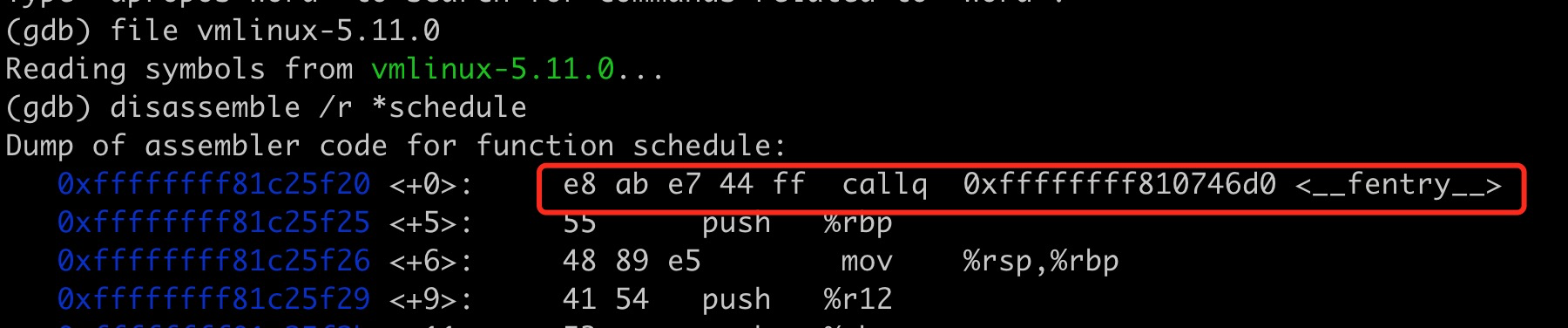
__fentry__ 函数则直接被定义为了 retq 指令:

2. ftrace 中 kprobe 跟踪机制验证call 汇编指令解析:
0xffffffff81c33580 <+0>: e8 1b 41 44 ff call 0xffffffff810776a0 <__fentry__>e8 代表 call, 1b 41 44 ff 相对于下一条指令的偏移量 (0xffffffff81c33580 + 5), FF 44 41 1B 为负数,补码为 BB BE E5, 0xffffffff810776a0 - 0xffffffff81c33585 = -bbbee5
这里,我们打算验证 3 件事情:
- 函数在内核启动后,函数首部的 call 指令会被替换成 nop 指令;
- ftrace 方式下设置 kprobe 函数跟踪后,nop 指令会被替换成相对应的 call 调用;
- kprobe 跟踪停止后,函数头部的 5 个字节会被替换成 nop 指令;(1,2 验证后,则很容易验证)
为了验证内核函数动态替换过程,我首先考虑的是通过内核模块打印函数地址对应的首部 5 个字节。
3. 使用内核模块进行验证 3.1 使用 kallsyms_lookup_name 方式获取最常见或流行的做法是在内核模块中使用内核函数 kallsyms_lookup_name() 获取到跟踪函数的地址,然后进行打印。
首先,我也想尝试通过这种方式进行,其他获取内核符号地址的方式参见 获取内核符号地址的方式 。内核模块的样例代码参考 hello_kernel_module,代码也非常简单:
static int __init hello_init(void)
{
char *func_addr = (char *)kallsyms_lookup_name("schedule");
// 判断地址是否合法,然后进行打印
}
但在编译阶段报错(本地环境 5.11.22-generic):
ERROR: modpost: "kallsyms_lookup_name" [hello_kernel_module/hello.ko] undefined!
在新版内核 ( >= 5.7 ) 中,出于安全考虑 kallsyms_lookup_name 函数不再被导出,在内核模块中不能再直接应用,相关说明可参见文章 Unexporting kallsyms_lookup_name 和提交的 补丁 。 这里 讨论了几种可行的替代方案,另外关于多内核版本下的统一方案可参考 The Linux Kernel Module Programming Guide 中的样例代码 syscall.c。这里为了简化,我使用 kprobe 注册机制(仅支持 Linux 5.11 内核),完整代码如下:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kprobes.h>
static struct kprobe kp = {
.symbol_name = "kallsyms_lookup_name"
};
static int __init hello_init(void)
{
typedef unsigned long (*kallsyms_lookup_name_t)(const char *name);
int i = 0;
kallsyms_lookup_name_t kallsyms_lookup_name;
register_kprobe(&kp);
kallsyms_lookup_name = (kallsyms_lookup_name_t) kp.addr;
unregister_kprobe(&kp);
char *func_addr = (char *)kallsyms_lookup_name("schedule");
pr_info("fun addr 0x%lx\n", func_addr);
for (i = 0; i < 5; i++)
{
pr_info("0x%02x ", (u8)func_addr[i]);
}
return 0;
}
完整代码参见 get_inst.c。编译并安装后,可通过 dmesg 进行查看:
$ sudo insmod ./hello.ko
$ dmesg -T
[Sat Apr 9 12:11:25 2022] fun addr 0xffffffff9eea3eb0
[Sat Apr 9 12:11:25 2022] 0x0f 0x1f 0x44 0x00 0x00
这里我们可以看到函数首部的 5 个字节已被替换成 nop 指令(0f 1f 44 00 00),这个过程是在内核启动时由 ftrace_init() 函数统一处理替换的。同样,新安装的内核模块中导出的函数,首部也会自动被替换成成 nop 指令。
对应到 ftrace pdf 中 schedule 函数的样例如下:

图 未启用 kprobe 跟踪前,函数首部 5 个字节为 nop 指令 <图来自于 ftrace pdf P36>
接着,启用内核函数 schedule 的跟踪,再进行验证:
$ cd /sys/kernel/debug/tracing
$ sudo echo 'p:schedule schedule' >> kprobe_events
$ sudo cat kprobe_events
p:kprobes/schedule schedule
$ sudo echo 1 > events/kprobes/schedule/enable
$ insmod ./hello.ko
$ demsg -T
[Sun Apr 10 20:07:12 2022] 0xe8 0x7b 0x5a 0xd9 0x20
[Sun Apr 10 20:07:12 2022] fun addr 0xffffffff9fa33580
$ sudo echo 0 > events/kprobes/schedule/enable
在启用内核函数 schedule 函数跟踪后,我们可以看到首部 5 个字节 (nop)已经被替换成了其他函数调用。大体效果如下所示:
 图:在注册 kprobe 函数 nop 指令被替换效果 <来自于 ftrace pdf P37>
图:在注册 kprobe 函数 nop 指令被替换效果 <来自于 ftrace pdf P37>
如果不通过 kallsyms_lookup_name 函数,直接使用 /boot/System.map 中的地址是否可以?答案是可以的,但是需要小心 KASLR(Kernel Address Space Layout Randomization)机制。
KASLR 可能会在每次启动时随机化内核代码和数据的地址,目的是保护内核空间不被攻击者破坏,这样以来 /boot/System.map 中列出的静态地址会被随机值调整。如果没有 KASLR,攻击者可能会在固定地址中轻易找到目标地址。如果 /proc/kallsyms 中的符号地址与 /boot/System.map 中的地址不同,说明 KASLR 系统运行的内核中被启用。两个查看需要 root 用户权限才能查看。
$ grep GRUB_CMDLINE_LINUX_DEFAULT /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
$ sudo grep schedule$ /boot/System.map-$(uname -r)
ffffffff81c33580 T schedule
$ grep schedule$ /proc/kallsyms
ffffffff9fa33580 T schedule
# 如果系统未启用 KASLR(内核地址空间随机地址)功能,两者地址会相等,否则会不一致。
如果启用了 KASLR,我们必须在每次重启机器时注意 /proc/kallsyms 的地址(** 每次重启机器都会发生变化 **)。为了使用 /boot/System.map 中的地址,要确保 KASLR 被禁用。我们可以在启动命令行中添加 nokaslr 来禁用 KASLR,重启生效:
$ grep GRUB_CMDLINE_LINUX_DEFAULT /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
$ sudo perl -i -pe 'm/quiet/ and s//quiet nokaslr/' /etc/default/grub
$ grep quiet /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet nokaslr splash"
$ sudo update-grub
我们可在内核模块中添加一个 sym 变量获取传入的函数地址,样例代码如下:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kallsyms.h>
static unsigned long sym = 0;
module_param(sym, ulong, 0644);
static int __init hello_init(void)
{
char *func_addr = 0;
int i = 0;
if (sym != 0)
{
func_addr = (char *)sym;
for ( i = 0; i < 5; i++)
pr_info("0x%02x ", (u8)func_addr[i]);
}
pr_info("fun addr 0x%p\n", func_addr);
return 0;
}
module_init(hello_init);
在确保 KASLR 被禁用后,我们编译上述模块并运行,可得到与上述方式一致的结果:
$ addr=`grep -w "schedule" /proc/kallsyms|cut -d " " -f 1`
$ insmod ./hello.ko sym=0x$addr
$ dmesg -T
[Sun Apr 10 20:50:51 2022] 0xe8 0x7b 0x5a 0xd9 0x20
[Sun Apr 10 20:50:51 2022] fun addr 0x000000005aad203e
$ rmmod hello
如果不禁用 KASLR 使用固定地址进行编译,加载驱动则会报错:
$ sudo dmesg -T
[Fri Apr 8 17:39:47 2022] BUG: unable to handle page fault for address: ffffffff810a3eb2
[Fri Apr 8 17:39:47 2022] #PF: supervisor read access in kernel mode
[Fri Apr 8 17:39:47 2022] #PF: error_code(0x0000) - not-present page
我将编译内核带上 DEBUG 选项的内核及相关文件保存到了 百度网盘 ,提取码 av28。关于内核编译及调试的详细过程可参考 使用 GDB + Qemu 调试 Linux 内核 。
这里介绍一下如何在 Mac 环境下使用 qemu 软件进行内核调试:
$ brew install qemu
$ brew link qemu
需要提前下载网盘的文件至本地目录,运行 qemu 进行测试:
$ cat run.sh
#!/bin/bash
qemu-system-x86_64 -machine type=q35,accel=hvf -kernel ./bzImage -initrd ./rootfs_root.img -append "nokaslr console=ttyS0" -s c
$ ./run.sh
注意这里添加了 -machine type=q35,accel=hvf 标记,在 mac 环境下使用 hvf 加速,如果不启用加速,默认使用 xen 虚拟化指令集。

如果在 qemu-system-x86_64 命令行没有启用 hvf 加速,看到函数前 5 个字节会有所差异,默认为
66 66 66 66 90 data16 data16 data16 xchg %ax,%ax,这是因为 nop 指令在不同的体系结构会有所不同。
# cd /sys/kernel/debug/tracing
# echo 'p:schedule schedule' >> kprobe_events
# echo 1 > events/kprobes/schedule/enable

这里我们对传入头部的函数继续进行跟踪:
(gdb) x/100i 0xffffffffc0002000
在后续翻页中可以看到调用了 kprobe_ftrace_handler 注册函数。

参考需要注意地址 0xffffffffc0002000 的函数并不是 ftrace 注册函数 ftrace_caller 或 ftrace_regs_caller,而是依据这两个函数在内存中动态构建的 trampoline(蹦床),将 ftrace_caller 或 ftrace_regs_caller 修改注册函数后的汇编拷贝到这段 trampoline 中,(本次调试 ftrace 函数为 ftrace_regs_caller,事件注册函数为 kprobe_ftrace_handler)。
- ftrace 作者的 pdf:Ftrace Kernel Hooks: More than just tracing
- 探秘 ftrace
- 内核文档 Function Tracer Design
- 二十分钟 Linux ftrace 原理抛砖引玉 - Cache One
- KASLR
- 当 ftrace 用于用户空间
- Linux kernel debug on macOS 搭建可视化内核 debug 环境