- 如何使用 Redis 缓存
- 前言
- 旁路缓存
- 只读缓存
- 读写缓存
- 设置多大的缓存合适
- 内存被写满了如何处理
- 缓存经常遇到的问题
- 1、缓存中的数据和数据库中的不一致
- 读写缓存
- 只读缓存
- 来个异常的栗子
- 1、先删除缓存后修改数据库
- 2、先修改数据库然后删除缓存
- 只读缓存和读写缓存如何选择
- 2、缓存雪崩
- 什么是缓存雪崩
- 1、大量缓存同时过期
- 2、Redis 实例发生宕机
- 3、缓存击穿
- 4、缓存穿透
- 缓存中的 hot key 和 big key
- 总结
- 参考
对于 Redis 来讲,作为缓存使用,是我们在业务中经常使用的,这里总结下,Redis 作为缓存在业务中的使用。
旁路缓存Cache Aside(旁路缓存)策略以数据库中的数据为准,缓存中的数据是按需加载的。它可以分为读策略和写策略。
只读缓存只读缓存 从缓存中读取数据;如果缓存命中,则直接返回数据;如果缓存不命中,则从数据库中查询数据;查询到数据后,将数据写入到缓存中,并且返回给用户。
如果需要对数据进行修改的时候,直接修改数据库中的数据,然后删除缓存中的旧数据。
只读缓存的优点:
所有最新的数据都在数据库中,数据不存在丢失的风险。
缺点:
每次修改数据,都会删除缓冲,之后的请求会发生一次缓存缺失。
读写缓存除了进行读操作外,数据的修改操作也会发送到缓存中,直接在缓存中对数据进行修改。此时,得益于Redis的高性能访问特性,数据的增删改操作可以在缓存中快速完成,处理结果也会快速返回给业务应用,这就可以提升业务应用的响应速度。
当然 Redis 是内存数据库,一旦掉电或宕机,内存中的数据就有可能存在丢失。
针对这种情况,一般会有两种回写策略:
- 1、同步回写;
写请求发给缓存的同时,也会发给后端数据库进行处理,等到缓存和数据库都写完数据,才给客户端返回。这样,即使缓存宕机或发生故障,最新的数据仍然保存在数据库中,这就提供了数据可靠性保证。
不过,同步直写会降低缓存的访问性能。这是因为缓存中处理写请求的速度是很快的,而数据库处理写请求的速度较慢。即使缓存很快地处理了写请求,也需要等待数据库处理完所有的写请求,才能给应用返回结果,这就增加了缓存的响应延迟。
- 2、异步回写。
所有写请求都先在缓存中处理。可以定时将缓存写入到内存中,然后等到这些增改的数据要被从缓存中淘汰出来时,再次将它们写回后端数据库。这样一来,处理这些数据的操作是在缓存中进行的,很快就能完成。只不过,如果发生了掉电,而它们还没有被写回数据库,就会有丢失的风险了。
优点:
被修改的数据永远在缓存中,不会发生缓存缺失,下次可以直接访问,不在需要向数据库中进行一次查询。
缺点:
数据可能存在丢失的风险。
设置多大的缓存合适缓存能够提高响应速度,但是缓存的数量也不是越多越好?
1、大容量缓存是能带来性能加速的收益,但是成本也会更高;
2、在一些场景中,比如秒杀,少量的缓存承担的就是绝大部分的流量访问。
系统的设计选择是一个权衡的过程:大容量缓存是能带来性能加速的收益,但是成本也会更高,而小容量缓存不一定就起不到加速访问的效果。一般来说,建议把缓存容量设置为总数据量的15%到30%,兼顾访问性能和内存空间开销。
内存被写满了如何处理Redis 中的内存被写满了,就会触发内存淘汰机制了
具体参加内存淘汰机制
缓存经常遇到的问题Redis 作为缓存,经常遇到的几种情况:缓存中的数据和数据库中的不一致;缓存雪崩;缓存击穿和缓存穿透。
下面一一来探讨下
1、缓存中的数据和数据库中的不一致数据一致性,通俗的理解就是,数据库中的数据和缓冲中的数据完全一致就满足一致性。不过对于只读缓存,如果缓冲中没有就去数据库中查询,这样如果缓存中没有数据,但是数据库中的数据是最新的,最终也能满足数据一致性。
所以总结下,一致性大致分成下面的两种情况:
1、缓存中有数据,缓存中的数据和数据库中的数据一样;
2、缓存中没有数据,数据库中记录了最新的数据。
下面分析下只读缓存和读写缓存中的数据不一致情况
读写缓存读写缓存有同步写回和异步写回两种策略
同步写回:缓存在新增修改的时候,也会同步数据到数据库中,这样总能保持缓存中的数据和数据库中的一致;
异步写回:缓存新增修改时候,先不写回到数据库中,定时或者缓存中数据淘汰的时候,再写回到数据库中。这种,如果 Redis 故障宕机了,没有及时写回数据到数据库中,就会造成数据的不一致。
对于读写缓存,使用同步写回的策略,能保证数据数据的一致性。不过,需要在业务应用中使用事务机制,来保证缓存和数据库的更新具有原子性,也就是说,两者要不一起更新,要不都不更新,返回错误信息,进行重试。否则,我们就无法实现同步直写。
如果系统没宕机,redis 系统正常的情况下,因为读写缓存,缓存中的数据是一直存在的,所以当修改数据的时候先修改缓存中的数据,这样就算并发很大的情况下,因为缓存中的数据都是最新的,并且一直存在,这样数据总能读取到最新的数据。
只读缓存只读缓存,如果数据新增,直接写入到数据库中,如果有数据修改删除,也是直接操作数据库不过缓存中的数据不会更新,而是直接删除缓存中的数据。
这样数据的更新操作之后,数据库中的数据总是最新的,缓存中就会发生缓存缺失,此时就会从数据库中读取数据,然后再加载到缓存中,这样缓存中的数据总能和数据库中的数据一致。
只读缓存在数据新增的时候,缓存中是没有数据的,所以肯定是要从数据库中加载,这种情况不存在数据不一致的情况。
在只读缓存中,数据不一致的情况,发生在数据的更新删除操作中,下面来一一分析下
删改操作既要修改数据库,同时还要删除对应的缓存,如果这两个操作的原子性无法得到保证,(一起操作成功,或者一起操作失败),那么数据的一致性就得不到保证了。
来个异常的栗子1、先修改数据库,然后删除缓存,但是删除缓存失败了;
删除缓存失败了,那么缓存中存在的就是旧值,这时候用户的请求过来了,首先去缓存中查询,这时候拿到的就是老旧的数据。
2、先删除缓存,在修改数据库,修改数据库失败了;
缓存删除成功,数据库修改失败了,那么数据库中存在的就是旧值,因为缓存已经被删除了,这时候去缓存中查询,发生了缓存的缺失,数据就会从数据库中加载到缓存中,这时候读取到也是老旧的数据。
针对这种问题如何解决呢?
上面出现异常的两种场景,归根到底,就是两者操作的原子性没有得到保证,所以可以借助于消息队列实现最终的一致性。
使用 mq 解决分布式事务可参见分布式事务
这里的操作场景相对简单一点,只要借助于 mq 的重试机制,保证第二步的操成功就可以了。
栗如:
1、先修改数据库;
2、发送删除缓存的消息到 mq 中;
3、下游收到删除的消息,操作删除缓存,如果失败,借助于 mq 的重试机制,就能进行重试操作,直到成功。当然如果,重试多次还是失败,我们需要记录错误原因,然后通知业务方。

那到底应该先删除缓存还是先修改数据库呢?这里我们再探讨一下
1、先删除缓存后修改数据库先删除缓存,然后修改数据库
如果数据库的更新有延迟,那么这时候一个线程过来查询该数据,因为缓存中已经删除了,这时候发生了缓存的缺失,然后就回去数据库中查询,数据库可能还没有更新成功,就可能获取到旧值。
如何解决呢
使用 延迟双删 策略
当数据库被修改之后,线程 sleep 一段时间,然后再次删除缓存,然缓存发生一次缺失,这样下次的请求,就能把数据库中最新的数据加载到缓存中。
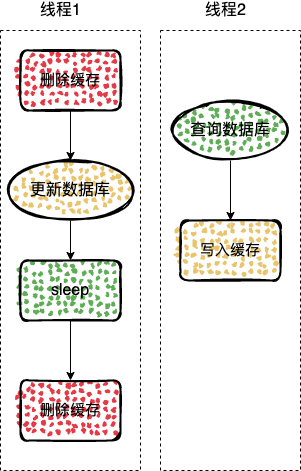
比如上面的这种情况,因为数据库的更新可能存在延迟,所以时候线程2读取到了数据库的旧值,然后加载到了缓存中,这样接下来的所有的查询就都会读取旧值
所以 线程1,通过延迟双删来处理这种情况
线程1,在 sleep 一段时间之后,删除缓存,这样就能使后续的缓存缺失,后续的查询就能加载数据库中最新的数据到缓存中。
不过 sleep 的时间需要大于,线程2,读数据并且写入数据到内存的时间,如果 sleep 时间过小,这时候线程2,的旧值还没有写入到缓存中,线程1,已经再次删除了缓存,然后这时候线程2把旧值写入,导致缓存中依然是旧数据。
redis.delKey(X)
db.update(X)
Thread.sleep(N)
redis.delKey(X)
当然,这在 sleep 的时间内,还是有一部分请求会读取到旧值
2、先修改数据库然后删除缓存先修改数据库,然后删除缓存
如果缓存删除有延迟,那么这时候过来的请求,就会读取到缓存中老旧的数据,不过缓存会马上被删除,只会有少部分的数据读取到老旧的数据,对业务影响比较小。
经过对比,发现先修改数据库然后在删除缓存,对我们业务的影响比较小,同时也跟容易处理。
只读缓存和读写缓存如何选择读写缓存对比只读缓存
优点:缓存中一直会有数据,如果更新操作后会立即再次访问,可以直接命中缓存,能够降低读请求对于数据库的压力。
缺点:如果更新后的数据,之后很少再被访问到,会导致缓存中保留的不是最热的数据,缓存利用率不高(只读缓存中保留的都是热数据)。
所以读写缓存比较适合用于读写相当的业务场景。
2、缓存雪崩 什么是缓存雪崩缓存雪崩是指大量的应用请求无法在Redis缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增。
缓存雪崩有两种场景
1、大量缓存同时过期如果有大量的缓存 key 设置了同样的过期时间,如果这些缓存 key 过期了,同时有大量的请求,进来了,这些请求就会直接打到数据库中,数据库可能因为这些请求,导致数据库压力增大,严重的时候数据库宕机。
如何解决呢?
1、避免给大量的过期键设置相同的过期时间,设计过期时间的时候,可以考虑加入一个业务上允许的过期随机值;
2、服务降级,只有部分核心业务的请求,才会流转到数据库中,数据库的压力就会被大大减轻了;
-
当业务应用访问的是非核心数据(例如电商商品属性)时,暂时停止从缓存中查询这些数据,而是直接返回预定义信息、空值或是错误信息;
-
当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
Redis 实例的宕机,缓存层就不能处理数据,最总流量都会流入到数据库中
如何解决呢?
1、业务中实现服务熔断或者请求限流机制;
-
服务熔断:如果监听到发生了缓存雪崩,直接暂停对缓存服务的请求,但是这种对业务的影响比较大;
-
服务限流:可以在入口做限流,不要让所有的请求都流入到后端的服务中;
2、提前预防,搭建 Redis 的高可用集群;
- 尝试构建 Redis 的高可用集群,比如当某主节点挂掉了,集群能够马上重新选出新的主节点。例如哨兵机制
其实跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而缓存击穿是一个热点的Key,有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
如何解决?
对于热点 key 可以不设置过期时间,或者设置一个超过使用周期的过期时间,保证这个 key 在业务使用期间永远存在。
4、缓存穿透如果业务请求的缓存,既不在缓存中,也不再数据库中,那么缓存将没有用,所有的请求都会流入到数据库中。
那么,缓存穿透会发生在什么时候呢?一般来说,有两种情况。
1、业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
2、恶意攻击:专门访问数据库中没有的数据。
如何解决?
1、缓存空值或缺省值;
一旦发生缓存穿透,在缓存中写入一个业务中允许的空值,这样缓存中有数据了,就避免了缓存穿透。
2、使用布隆过滤器;
使用布隆过滤器判断下数据是否存在,数据如果不存在,就不向数据库发起请求了。
布隆过滤器
3、在请求入口的前端进行请求检测;
缓存穿透的一个原因是有大量的恶意请求访问不存在的数据,所以,一个有效的应对方案是在请求入口前端,对业务系统接收到的请求进行合法性检测,把恶意的请求(例如请求参数不合理、请求参数是非法值、请求字段不存在)直接过滤掉,不让它们访问后端缓存和数据库。这样一来,也就不会出现缓存穿透问题了。
缓存中的 hot key 和 big key这两种的处理方式可参见
Hot Key 和 big key
总结对于缓存的使用,我们经常用到的有两种1、只读缓存;2、读写缓存;
只读缓存,对比读写缓存
优点:缓存中一直会有数据,如果更新操作后会立即再次访问,可以直接命中缓存,能够降低读请求对于数据库的压力。
缺点:如果更新后的数据,之后很少再被访问到,会导致缓存中保留的不是最热的数据,缓存利用率不高(只读缓存中保留的都是热数据)。
所以读写缓存比较适合用于读写相当的业务场景。
缓存在使用的过程中,会面临缓存中的数据和数据库中的不一致;缓存雪崩;缓存击穿和缓存穿透,这些我们需要弄明白这些情况发生的额场景,然后再业务中一一去避免。
参考【Redis核心技术与实战】https://time.geekbang.org/column/intro/100056701
【Redis设计与实现】https://book.douban.com/subject/25900156/
【什么是缓存雪崩、缓存击穿、缓存穿透】https://zhuanlan.zhihu.com/p/346651831
【详解布隆过滤器的原理,使用场景和注意事项】https://zhuanlan.zhihu.com/p/43263751
【Redis 学习笔记】https://github.com/boilingfrog/Go-POINT/tree/master/redis
【如何使用Redis缓存】https://boilingfrog.github.io/2022/04/20/Redis中缓存如何使用/