人类文明史就是一部信息史——人类如何获取、存储和传递信息的历史。
远古时代,人类主要通过观察自然现象来获取信息和知识,通过口口相传的方式传递信息。
而后,人类发明了结绳、符号,可以将个人大脑中的信息加以符号化——这可以说是人类最早的信息存储形式(它也是一种传播形式)。这些符号不断地传播并丰富,最终演化为文字。
文字是个伟大的发明,它使得信息和知识能够跨越时空传递。如果没有文字,人类文明只能以“代代相传”的方式进行。
除了口口相传和文字,人类还发明了诸如烽火、灯塔、鼓声等远距离通信手段——人类对通信距离的不断突破,到近代发明电报、无线电后,达到了一次高峰。
人类生产信息的脚步也是不断加快。欧洲和中国在古希腊和春秋战国时期出现了一次信息生产高峰,古希腊时期建造出了世界上最早的图书馆之一——亚历山大图书馆。
图书馆是人类进行集中式信息管理的伟大尝试。
欧洲文艺复兴和启蒙运动时期是人类信息生产的另一个高峰。如果说在古希腊时期,知识生产大分工只是处于萌芽阶段的话(那时候哲学和科学是不分家的),文艺复兴和启蒙运动时期则正式开启了知识生产大分工的大门。科学从哲学中独立出来,逐步发展成今天所理解的物理学、化学、生物学、经济学等学科。
知识生产大分工的结果是人类进入了知识生产的指数加速时代。人类现在几十年生产出来的知识比过去一千年都要多。
过去,中国古人只需要背熟四书五经大学中庸就行了,现在光一门物理学(或者任意其他一门学科)的知识量就比那些多得多。古人可以做到“无所不知”,而二十世纪后的人类已经不可能做到这一点了——甚至不可能做到穷尽一门学科的知识。
人类知识量指数增长带来的是信息管理问题。面对信息海洋(知识是一种信息),人们不知道该获取哪些信息了,需要某类信息的时候也不知道该去哪里获取了。人类面临着信息失控的危险。
人们可以建造更大的图书馆——再大也装不下所有的知识,而且图书馆规模越大,可能越难快速检索到有用的信息。
人们还尝试编纂百科全书——将那些重要的知识集中到一系列书籍中,为普通大众在知识的海洋中提供指南和导航。中国明朝永乐年间编纂了集大成之类书《永乐大典》;启蒙运动时期法国哲学家丹尼·狄德罗编纂了欧洲第一部大百科全书;1768 年英国人编纂了著名的《不列颠百科全书》。
百科全书同样不可能囊括所有的知识。
万尼瓦尔·布什与 MEMEX
计算机并不是被设计用来处理信息的。
这从计算机的名字就能看出来——Computer 原意是“计算员”,在计算机出现之前是一个专门的职业(像美国的人口普查、欧洲的航海历之前都是由这些人类计算员手工算出来的)。
从巴贝奇的差分机和分析机,到何乐礼的电动制表机,到万尼瓦尔·布什的微分分析仪,到第一台通用电子计算机 ENIAC,其设计的目的无不是为了数值计算。
冯·诺依曼当初“鬼使神差”地加入莫尔学院的 ENIAC 工作小组,原因也在于寻求用计算机计算原子弹核爆问题——这一加入让他“鬼使神差”地成了现代计算机之父。
随着二战结束,计算机逐渐从军事和科研走向商业领域。
同时人们尝试进一步挖掘计算机的计算潜力。根据图灵的理论,通用计算机可以计算所有的可计算问题,可以无限逼近(甚至超越)人脑——这些研究我们今天叫“人工智能”,图灵也被公认为人工智能之父。
然而,还存在另一派研究人员,他们认为计算机研究应该要为提升人类工作效率服务,而不是当前看不到实际用途的所谓的“人工智能”。
他们发现,人们在工作中通常只有 15% 的时间在“思考”,其余时间都在查阅资料、绘制图表等,工作效率非常底下。他们希望能用计算机来处理这些低级而耗时的事务,将人类的大脑解放出来去思考更有价值的事情。
总之,这些人开始研究用计算机处理信息——这些研究最终推动人类文明走向信息化时代。
数值处理和信息处理是不同的。
数值处理关注如何求三角函数、对数、微积分等数学计算问题,主要用在军事、科研以及商业报表领域。
信息处理关注人类社会的各种信息,诸如书籍、信函、图片、音频、视频。
第一台通用电子计算机 ENIAC 全称是 Electronic Numerical Integrator And Computer,翻译过来是“电子数字积分计算机”——看名字就知道人们想用它来干嘛。
计算机的两大分支:数值处理和信息处理,在不同时期存在不同的发展态势。二战时,主要用来做数值处理(ENIAC 的目的是计算弹道);战后其重心逐步转变为信息处理上(当然不是说数值处理方面就没有发展了),最终推动人类走向信息化时代;如今,人工智能被重新提上议程,自动驾驶、智慧城市甚是火热。
前面说随着人类信息量的指数增长,传统的信息存储和检索方式面临越来越大的挑战。
首先是存储。传统的信息存储方式主要是书籍、文件这些纸质媒介,这种媒介在信息量骤增的二十世纪已经相当笨重和效率低下。大学需要建造庞大的图书馆,公司需要准备大量的文件柜(不可避免地占用大量空间)归档各种函件。
其次是检索。虽然有各种文件归档方案,在海量文件中找到想要的那个仍然是一件非常费力而又无聊的事情——一旦记不清文件放在何处更是让人抓狂。
所以人们想能否通过计算机来解决这些问题。
1945 年,万尼瓦尔·布什(Vannevar Bush)发表了一篇名为"As We May Think"的文章。文章描述了一种被称为 MEMEX 的机器,实现新型的数字化的信息存储和检索模式。
MEMEX 设备相当于一个数字图书馆,它将现实中的各种书籍、图片、文件等数字化并存储在微缩胶片上,解决纸质媒介的存储效率问题。
MEMEX有一个屏幕,资料可以投影到上面进行阅读,还有一个键盘,一系列按钮和把手。
更重要的,布什在这篇文章中提出了后来被称为“超文本”的概念,两个相关联的文档之间可以建立某种关联使得可以从一篇文档直接跳转到另一篇文档。
布什并没有在他的文章中使用“超文本”这个词,超文本(Hypertext)一词是德特·纳尔逊于 20 世纪 60 年代创造的。
超文本在今天看来稀疏平常,但在布什那个年代是一个非常大胆的、创新的设想。传统的信息检索是集中式检索。想想我们在图书馆看书,在一本书里面看到对另一本书的引用,此时如果我们需要看被引用的那本书,就得在图书馆里面到处找。再想想我们在 Linux 命令行查看某命令的帮助文档,当我们看到 See also 后像去看其引用的命令的细节,我们得退出去然后 man 另一个命令。这种检索模式称为“线性检索”。
和传统的线性检索方式不同,超文本允许任何信息之间交叉引用,可以从一个文档直接转移到另一个文档,且能方便地返回到源文档。
超文本的颠覆性在于它改变了人类几千年来的集中式树形目录的信息检索方式。
超文本的概念催生了后来的万维网。
电子邮件与阿帕网
上世纪 60 年代,计算机资源是非常昂贵的,人们就想能否将这些昂贵的计算机通过某种方式连接起来,用户可以在一台计算机上直接使用另一台计算机资源,从而分摊计算和存储成本。
1963 年,美国国防部的高级研究计划局启动了“阿帕网”(Advanced Research Projects Agency Network,高级研究计划局网,简称 ARPANET)项目——通过将计划局的所有计算机系统连接在一起,用户就能使用网络上的任何计算机设施。
阿帕网使用了存储转发分组交换的数据交换模式,该模式沿用至今。
存储转发是用来解决计算机之间的连接问题。研究员们为如何将众多的计算机两两连接起来犯难。不太可能为每两台计算机都拉一根网线——那样网线数量将很快变得不可控。研究员们借鉴了电报行业的做法。
19 世纪电报行业在英国飞速发展,各大城市设有众多的电报网点。电报公司之间、以及各大城市之间如何通信成为必须解决的问题。英国在几个主要城市设立了交换中心。电报公司之间、城市之间无需两两相连,大家可通过交换中心转发电报。
交换中心内部有两拨人员,第一拨人将发送方的电报内容记录下来,由另一拨人通过合适的出口电报机转发给目的地(或下一个交换中心)。
将电报记录在案的好处是它可以充当存储系统,如果下一个交换中心很忙,则可以将报文暂存起来,等线路空闲时再发。
这就是所谓的“存储转发”。
通过交换中心转发消息,使得计算机之间无需两两相连;通过存储(缓冲队列),让上游不会因下游繁忙而阻塞(另外在分组交换模式下,交换机是先将收到的 bit 存储起来,直到接收到完整的分组后才会转发)。
当然存储转发不是没有缺点的,报文在到达目的地之前,需要经过多个交换中心(交换机)的存储和拷贝,大大增加了时延。
分组交换用来解决占线问题。如果我们一次发送整个报文(可能很大),那么一方面会导致高速通信线路在一段时间内被某个用户独占;另外采用存储转发策略的交换中心需要先存储整个报文,这会带来巨大的存储开销;最后,如果消息传送失败,需要重传整条报文(而不是失败的那部分)。
所以,人们决定将整个报文切分成一个个更小的分组(Package),以分组为单位在网络上传输。这样高速线路就不会被某一个用户的庞大消息独占了,交换中心需要存的东西也小很多。
分组交换也不是没有缺点的。分割成多个分组后,每个分组都必须携带额外元数据(首部),增加了传输的比特数。另外接收端也必须将分组重组成报文(消息)。
最初接入阿帕网的只是高级研究计划局内部的计算机。很快,加利福利亚大学、犹他大学、斯坦福研究院等跟计划局有合作关系的大学计算机也加入到该网络。在大学校园里,一些研究生和程序员也开始将自己的主机接入其中,很快便在校园内形成一种独特的网络社区文化。
到 1971 年春,共有23 台主机联网。
1972 年,阿帕网新负责人罗伯茨在首届国际计算机通信大会上组织了一次公开演示,向世人展示阿帕网。这次演示影响很大,越来越多的研究机构和大学开始接入阿帕网,一年后,网络中的主机数量达到 45 台。
4 年后,数字升到 111 台。
从数量看,增长非常缓慢。
真正推动阿帕网发展的是电子邮件。
阿帕网最初并没有考虑电子邮件。
1971 年,BBN 的两位程序员为阿帕网开发了实验性的电子邮件系统——起初他们并不认为这玩意能成什么气候。
然而很快,电子邮件成为阿帕网中最大的流量,邮件注册用户导 1975 年已过千人。收发电子邮件的需求也成为推动第一批非阿帕网网络发展的主要力量。
计算机服务商看到了电子邮件的商业价值。很多服务商开始搭建自己的计算机网络(大多数是基于阿帕网的技术)提供电子邮件服务,形成了 70 年代的“电子邮件大战”。
电子邮件推动了计算机网络的发展,催生了大量基于阿帕网技术实现的、相互独立的计算机网络。
一个问题是,这些网络之间无法通信(自然也无法收发邮件)。
于是人们开始考虑网际互联问题。
当时阿帕网使用的网络协议叫 NCP(Network Control Protocol,网络控制协议),该协议存在诸多缺陷,其中一个问题是 NCP 仅能用于同构环境中(所有计算机都要运行相同的系统)。
人们决定开发个支持异构系统的新协议替代 NCP。
1973 年,高级研究计划局的研究员罗伯特·卡恩和温顿·瑟夫着手设计 TCP/IP 协议;1980年,用于“异构”网络环境的 TCP/IP 协议研制成功;1982年,ARPANET开始采用TCP/IP协议替代 NCP 协议。
TCP/IP 协议的出现推动了计算机网络之间的网际互联(也就是我们今天说的互联网),最终催生出世界上最重要的互联网——因特网。
个人计算机与因特网
电子邮件推动了阿帕网的发展,并在商业公司的推动下形成各种计算机网络百花齐放的局面,而这种局面最终因网际互联的实际诉求而催生出因特网。
但因特网起初增长速度是很慢的,到 1984 年接入的主机数量也不过千台,主要是大学、科研和一些商业机构。
真正推动因特网快速发展的,是个人计算机浪潮。
80 年代,个人计算机风起云涌,IBM、苹果、微软群雄逐鹿,软硬件百花齐放,个人计算机逐步成为大众普遍接受的电子消费品和办公品。
大量个人计算机开始接入因特网,人们不但在网上用电子邮件交流,还开始交流整篇文档。
很快,因特网上产生了大量没有目录组织的文档——如何组织和检索这些文档成为一个亟待解决的问题。
人们开发了一些目录服务软件来解决文档检索问题。比如有一款叫“阿奇”的软件,通过梳理因特网,创建一个包含所有可供下载文件的目录,用户直接在该软件里面即可下载,无需关注文档的具体位置。有些软件还提供了根据文档名称模糊模糊检索功能。
和我们今天在浏览器中直接点“下载”按钮就能下载文档不同,那个时候人们要下载某个文档,必须先知道该文档的精确位置。典型的操作流程如下:
张三先通过 ftp 登录到某台远程主机上;
登录上去后,进入到某个目录;
从那个目录下载文件;
也就是说,张三必须知道文档所在的主机,而且能登录这台主机,然后要进入到相应目录。
张三不可能知道因特网上所有文档的精确位置。所以说,当时这种目录服务软件还是较好地解决了人们的痛点。
这些软件的目录组织形式和传统书籍无异,也是采用集中式树形结构目录,文档之间没有直接的关系。假如用户在一篇文档中看到“查尔斯·巴贝奇”的名字,他想检索查尔斯·巴贝奇的信息,就要回到目录重新查找——他无法从当前文档直接进入关于查尔斯·巴贝奇生平的另一篇文档。
上面提过,早在 40 年前,万尼瓦尔·布什就提出了超文本的概念来解决信息交叉检索问题。
那么,能否将超文本和因特网结合起来呢?
蒂姆·伯纳斯·李与万维网
在今天看来,因特网和超文本好像天然就是在一起的,然而在上个世纪八十年代却不是这样。那时候超文本和因特网都是很热门的话题(至少在学术界如此),而且超文本也开始应用于一些 CD-ROM 百科全书等消费类产品,然而,两者是单独发展的,没有人真正想到能将超文本应用在因特网上。
有个叫蒂姆·伯纳斯·李的英国软件工程师最终想到了这点,他于 1989 年向欧洲核子研究中心(CERN)递交了一份项目提案,在这份提案中,描述了今后称为“万维网”的雏形。
欧洲核子研究中心是在联合国教科文组织的倡导下,由欧洲 11 个国家于 1954 年 9 月创立。作为一个国际性组织,拥有非常复杂的人员和组织结构,研究项目众多、人员变动频繁。在这样一个大型组织中,如何高效地组织和检索信息(人物信息、项目信息、各种技术档案等)成为一个棘手的问题。
人们经常被诸如下面的问题困扰:
-
这个模块在哪里用到了?
-
这些代码是谁写的?在哪里执行?
-
哪些系统依赖该设备?
另外,CERN 的人员流动很大,经常因为人员离职而导致关键信息丢失——多数情况下不是因为离职人员没有存留文档,而是因为后面的人找不到文档了。
CERN 面临着严重的信息丢失问题。
伯纳斯·李进一步补充道:“在不久的将来,世界其他国家和组织也会面临同样的问题”。
所以,必须有一套通用的信息管理方案。
当时人们普遍使用树形结构来组织信息。Unix 文件系统就是一个例子。当时 CERN 正在用的 CERNDOC 文档系统也是。在这种系统中,如果一个文档(树的叶子节点)中引用了另一个文档(另一个叶子节点,如我们 man 查看命令文档时的 See also),你是无法直接打开被引用的那篇文档的,你必须先退出当前文档,然后从目录开始重新检索被引用的那篇文档。
树形结构并没有表达信息之间的真实关系。比如有一篇讲差分机的文章,里面提到了查尔斯·巴贝奇,该场景中,“差分机”和“查尔斯·巴贝奇”是有关联的两条信息,但在集中式树形目录中,这两条信息是作为单独的、毫无关联的实体存在的,我们从目录中看不出“差分机”和“查尔斯·巴贝奇”存在任何关联。
在传统的基于目录的信息组织和检索方式中,我们基本上只是管理了一个个孤零零的信息本身,并没有管理信息之间的关系。
相较于树形目录,交叉检索的超文本更能反映现实世界的信息组织结构,它允许人们从一条信息体直接跳转到与之关联的另一条信息体,而无需重新检索目录,这大大提高了信息的检索效率。
超文本的概念人们四十年前就提出了,在 80 年代已经有一些实际应用,如果仅仅到此为止,伯纳斯·李的这个提案也没有什么出众之处——不过是开发另一款超文本信息管理系统而已。
这份提案的创新之处在于,它所描绘的超文本系统并不是一个系统,而是全球范围的系统集群。
伯纳斯·李发现,如今全球已经面临着信息大爆炸带来的信息管理问题:人们不知道该去哪里找到有用的信息;组织机构每天都面临着大量的信息丢失;用集中式目录管理海量信息力不从心。
另一方面,虽然当时已经开发出一些超文本系统,但这些系统自成一体,相互之间无法实现信息互联互通。A 系统的超文本只能链接到 A 系统内部的文档,无法引用 B 系统的文档;无论是 A 系统还是 B 系统,都无法囊括世界上所有的信息。
伯纳斯·李的设想是,能否将全世界所有的系统看做一个整体的、巨大的、动态的信息存储库,通过超文本将这些信息连接起来?
让超文本跨越系统边界的限制,在地球上构成一个庞大的信息宇宙空间,这是个大胆的设想。
这个设想在当时看并非不可实现。因特网已经打破网络边界,能够将全世界的计算机连接成一个整体。
那么,让超文本插上因特网的翅膀不就能够驰骋于系统之间了吗?
伯纳斯·李将这个基于因特网的超文本信息管理系统称为万维网(World Wide Web)。
万维网的关键组件
URI:
由于信息分布在世界各地,首先的问题便是如何找到这些信息?
在万维网中,所有的信息统一称为资源。每个资源都有唯一的名字(或者叫标识)。为了让全世界各种系统都能够理解这些名字,资源的命名必须符合某些规范——这个规范叫统一资源标识符(Uniform Resource Identifier,简称 URI)。
现在万维网基本都是用 URL(Uniform Resource Locator,统一资源定位符) 这种 URI 方案。
完整的 URL 长这样:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
不过我们在 HTTP 协议应用中很少用到 user、password 和 params,所以看起来长这样:
<scheme>://<host>:<port>/<path>?<query>#<frag>
这个 URL 格式告诉客户端如何找寻并使用资源。scheme 告诉客户端和服务器端(包括代理)如何解析 URL以及如何处理资源(如通过 HTTP、FTP、SMTP 等协议)。 host 说明资源在哪台主机,port 说明由该主机上哪个端口进程来接收并处理客户端的请求。path 指定资源在该主机上具体什么位置。如果说 host 相当于公司总机号,那么 path 则相当于分机号。frag 说明客户端只关注整个资源的某个片段(注意该参数只对客户端程序有效,不会传给服务器,服务器总是返回完整的资源给客户端)。
URL 的问题是它和资源的具体位置密切绑定,一旦资源位置变了(如换域名了,或者存放位置变了),原来的 URL 也就失效了。这相当于你的身份证只能在本省使用,出省就得换身份证。
URL 的另一个问题是不好记。URL 对美国以外的人(特别是使用表意文字的人群)不太友好。万维网的一个设计原则是最大兼容性,为了实现这一点,URL 标准规定 URL 只能使用 7 位编码方案的 ASCII 字符,这样便能最大程度兼容现有的协议(如 SMTP 协议),超过 7 位的字符都会被转义。另外,随着资源的爆炸式增长,URL 变得越来越长。
所以人们还制定了另一种 URI 方案叫 URN(Uniform Resource Name,统一资源名),这是真正的名字(相较而言,URL 是资源的位置而不是名字),它不会随着资源的位置变化而变化。
URN 虽然看起来更高大上,但很难普及(至少在目前以及不远的将来)。从其目标来看(资源不会随着位置变化而变化),就目前的因特网现状来说,需要某种中转设施(或叫注册中心)去做名称和位置的映射(类似 DNS 服务做域名到 IP 的映射),而且要将现存的大量的 URL 转换成 URN,这是个浩大的工程,许多万维网基础设施需要改变。
另一方面,资源位置改变后,人们可以通过 CNAME、rewrite、HTTP 重定向等手段实现新旧 URL 的转发,甚至对于很多 URL 来说,服务提供者可以简单粗暴地直接废弃也不会造成多大影响。所以对于很多公司来说,这可能并不是个急需解决的问题。
随着网址导航网站特别是搜索引擎出现后,URL 的第二个问题(难以记忆)的问题也随之解决了——现今人们很少直接拿 URL 去访问网站了。
所以到目前为止,URL 的日子过得还挺滋润的。
MIME:
客户端定位并拿到资源后,它如何处理或使用这些资源呢?客户端如何知道服务器返回的是图片还是普通文本呢?
万维网将一切都视为资源,而且还给这些资源分门别类——但这其实不是万维网自己的创举。早在电子邮件时代,人们为了在电子邮件中收发多媒体资源(而不仅仅是纯文本),就发明了 MIME 媒体类型(Multipurpose Internet Mail Extensions,多用途互联网邮件扩展类型),万维网采纳了该类型标准。
MIME 媒体类型采用两层分类结构:主类型+子类型,用 / 分割。有时候可能还要带上一些额外参数说明细节。
例如 HTTP 协议中我们常见的几种类型:
Content-Type: text/html // html 纯文本
Content-Type: text/plain // 纯文本
Content-Type: image/jpeg // jpeg 格式图片
Content-Type: video/quicktime // quicktime 格式音频
Content-Type: application/json // json 格式数据
在 HTML 表单中我们还见过一种复合表单类型:
Content-Type: multipart/form-data;boundary=AauYd8a
它表示我们提交的表单内容由多种媒体类型组成。比如在注册时,我们要填写用户基本信息,还要上传头像,这里就存在 text/plain 和 image/jpeg 两种媒体类型,所以此时我们得用 multipart/form-data 来表示该 HTTP 主体是个复合类型,然后在主体中将每个类型内容都带过去,这些类型的内容之间通过 boundary 分割(此处就是字符串 AauYd8a)。
我们用 postman 模拟注册请求,填写了两个字段:字段 name 是姓名,普通文本;字段 avatar 是头像,png 图片。得到的 HTTP 请求报文如下:
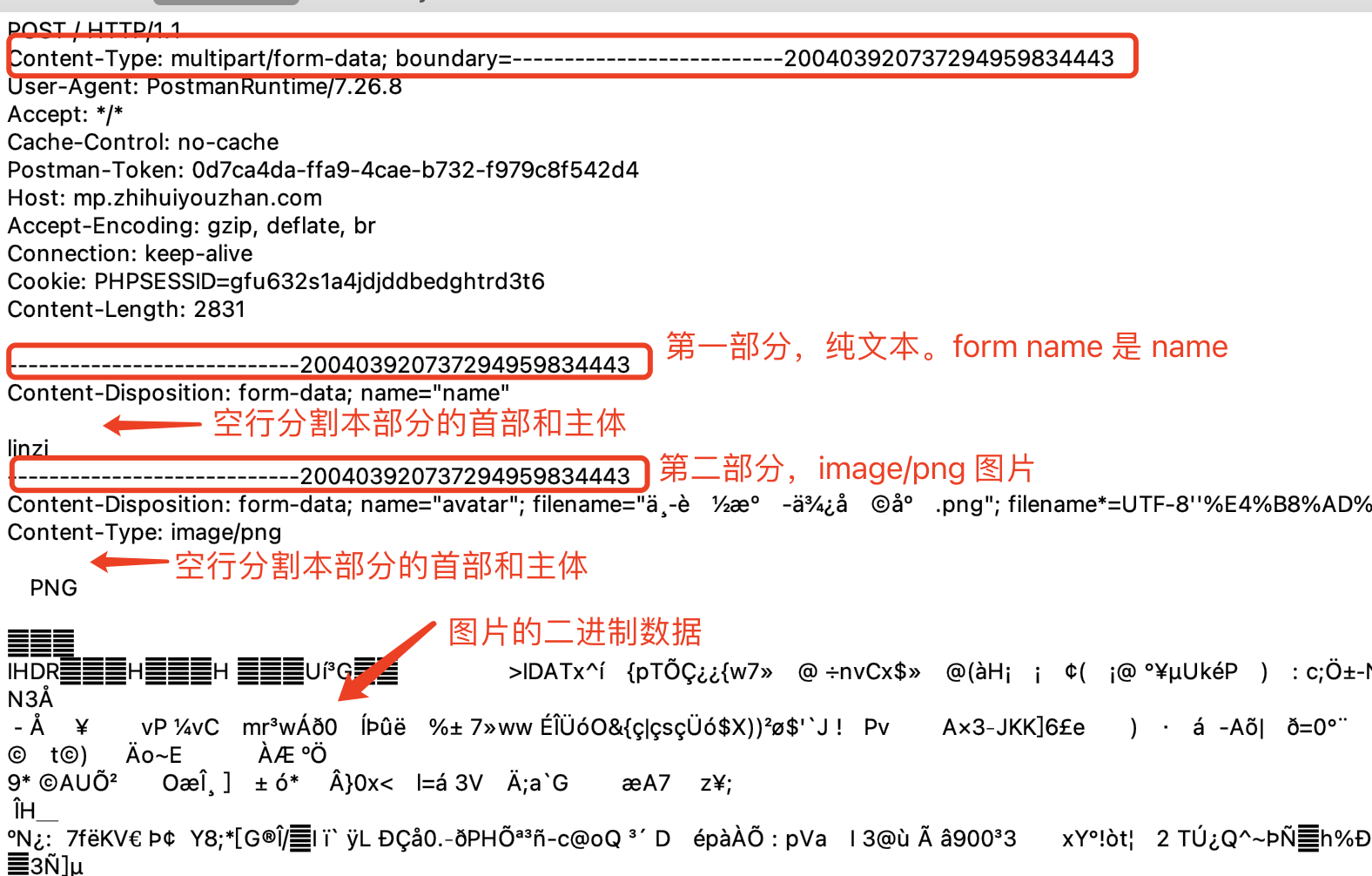
本报文主体是由 text/plain 和 image/png 两种媒体类型组成的复合媒体类型,两者之间通过 HTTP 首部指定的 boundary 分割。
当然复合媒体内部还可以再放复合媒体,比如上图中第二部分我们可以再由音频和视频复合,然后由本部分首部指定新的 boundary 来分割音频和视频内容的分隔符。
目前存在几千个 MIME 类型,完整的类型列表可在 IANA 官网查看。
客户端拿到资源并知道了资源类型后,如果客户端能够编解码此种类型,便能够正确处理并显示。现今浏览器一般都能支持几百种常见类型处理,而且可以通过安装扩展(或者调起本地软件)支持更多的媒体类型。
HTTP:
虽然 URI 本身并不限制方案(scheme),但要想将全世界的计算机组织成一个庞大的统一的超文本系统,则必须使用统一的数据传输协议——这个协议就叫 HTTP。
如果说万维网是一个信息帝国,那么 HTTP 就是这个帝国的官方语言。
HTTP 协议的核心功能是让客户端能够告诉服务器端它想要对资源进行做什么操作——这个能力体现在 HTTP 请求报文的起始行,如:
GET /doc.html HTTP/1.1
......
这个起始行包括三部分:操作、资源、协议版本。
HTTP 的一个创举是将种类繁多的、乱七八糟的操作高度抽象成几个动词。在第一版(HTTP/0.9)中,由于人们只需要查看资源,所以只有 GET 这一个动词。后续版本加入了 HEAD、PUT、POST、TRACE、OPTIONS、DELETE 等动词(动词是可扩展的)。
说下几个常用的:
-
GET:最常用的方法,请求获取某个资源;
-
HEAD:和 GET 类似,不过服务器只返回首部而不返回主体(Body),在客户端不需要主体信息的时候(如仅想查看资源的元信息)能节约带宽;
-
PUT:如其名,客户端向服务器写入(put)文档(和 GET 的行为相反,类似于我们用 FTP 上传文件)。PUT 的标准行为是用客户端请求报文的主体内容覆盖服务器上的整个资源(如果资源不存在,则创建);
-
POST:向服务器”输入“数据。有时候我们并不是想创建一个新资源,而仅仅是修改或增删该资源的一些属性,就可以用 POST 将相关数据提交给服务器。和 PUT 不同,POST 的具体行为由服务器端决定(而 PUT 的语义已经包含了其行为);
-
DELETE:如其名,删除资源。删除操作的语义是确定的,但服务器端可以拒绝执行该操作(拒绝删除某资源,或者仅仅是做资源归档)。
起始行的第二部分是资源。这里一般是写本地资源路径(在使用代理时也可能写绝对 URL)。
第三部分说明客户端支持的 HTTP 协议的最高版本,服务器端可据此决定返回的数据格式(如有些低版本协议客户端不支持某些新特性)。
相应地,服务器端需响应处理结果——这个也是体现在 HTTP 响应报文的起始行,如:
HTTP/1.1 200 OK
也是由三部分构成:协议版本、处理结果状态码、结果描述。
HTTP 的状态码分成五大类:
- 100 ~ 199:信息性状态码,平时见到最多的可能是 101 Switching Protocols,协议升级(如 WebSocket 中就用到);
- 200 ~ 299:成功状态码,说明服务器端成功执行了客户端的请求;
- 300 ~ 399:重定向状态码,说明要到其他地方查找资源;
- 400 ~ 499:客户端错误,如未授权、请求的资源不存在;
- 500 ~ 599:服务器端错误,如经常遇到的 502 Bad Gateway;
HTTP 报文的第二大块是首部。首部提供应用程序和资源的元信息,如客户端支持的媒体类型列表、主体的媒体类型、主体长度、缓存策略等。
HTTP 首部有两个特点(这里说的是 HTTP/1.X):
- 纯文本;
- 可扩展;
我们有时会听说 HTTP 是纯文本协议,这不是说 HTTP 只能传输纯文本(HTTP 能够传输图片、视频等所有类型数据),而是说 HTTP 的首部是 ASCII 纯文本的。比如下面的请求首部:
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
......
我们能看出它是在讲人话。首部是 key: value 格式的文本表示。
相应地,什么是二进制协议呢?像 IP、TCP、DNS 协议的首部那样,采用二进制位来表示特定含义的协议,这些协议的首部往往也是固定的。
纯文本首部的缺点是效率低,文本显然比二进制形式更占空间,比如"Cache-Control:no-cache"占了 22 字节,但在二进制协议中可能只需要 4 个比特就能搞定。另外报文接收方需分割字符串首部后进行字符串比较,其效率也远低于位操作。
但纯文本首部的一大优点是扩展性很好。二进制协议一般都是固定长度首部(如 TCP、DNS),所能表达的信息有限。纯文本首部一方面可以随意增加新首部,另外对现有首部的值也可以随意扩展——可扩展性是 HTTP 协议的一个重要原则。
这里说的是 HTTP/1。HTTP/2 是二进制协议,采用 frame 作为传输单元。
HTTP 报文的第三大块是主体。主体可以是任何文本或二进制数据,HTTP 协议通过一系列首部提供了主体的相关信息,如 Content-Type 指定主体的 MIME 类型,Content-Length 指定主体的长度,Content-Encoding 指定主体的编码方式(如 gzip 压缩)。
早期 HTTP 并没有 Content-Length 首部,客户端是通过服务器端关闭连接来感知主体传输完毕,但有一个问题:客户端无法知道该连接是否正常关闭的(有可能服务器端除了问题,数据发送一半的时候宕掉了)。所以后面加了 Content-Length 首部。该首部在持久连接场景下是必须的——此场景服务器端发送完报文后不会关闭 TCP 连接。
从上面三大块我们发现,可扩展性是 HTTP 协议的一个核心设计原则。灵活的扩展能力一方面满足了万维网上千姿百态的资源和资源使用方式,另外也使得 HTTP 协议自身拥有良好的向后兼容性(HTTP 协议还专门有个状态码 101 表示协议版本协商)。
B/S 架构:
万维网相较于传统超文本系统的一大特点是存储和展示分离。
万维网的资源是分布式存储的,存储系统(分布在世界各地的计算机)之间采用的操作系统、软件以及协议各不相同,这要求资源的展示不能依赖于存储实现细节。
万维网采取了浏览器/服务器架构(B/S 架构。这里说的浏览器是泛指实现了万维网相关协议,能够正确展示各种资源的终端程序)。浏览器负责展示资源,服务器负责存储资源。浏览器不关心服务器如何处理和存储资源,服务器只需要做两件事情:首先,给资源取个名字(URI)并公布出来;然后,服务器将资源以合适的方式(HTTP 协议)提供给浏览器——如此,浏览器便能正确地获取并展示该资源。
资源的展示和存储分离在今天看来稀疏平常,其实它是一个非凡的创举。当时在大部分系统中,信息的展示是依赖于存储格式的,一种系统中的信息无法在另一种系统正常显示(就好比无法在 PDF 阅读器中打开 excel 格式文件一样)——或者说,特定格式的信息资源必须用对应的应用程序打开。
伯纳斯·李提出“浏览器”的概念——它是一款不关心资源存储而只专注于资源展示的软件。因为我们对浏览器过于熟悉,可能并不会被这个概念激起多少波澜,我们不妨换个名称叫“通用信息阅览器”。什么意思呢?这个应用程序并不是只能打开某一种类型的资源,它(理论上)可以打开任何类型资源——这才是“资源的展示不依赖于存储格式”的终极理念。
当然,现实中没有哪一款浏览器能支持所有 MIME 媒体类型,所以存在类型协商。具体做法是浏览器在 HTTP 请求报文中通过 Accept 首部告诉服务器它能够(或说希望)接收的媒体类型有哪些;服务器则在响应报文首部通过 Content-Type 告知浏览器自己返回的资源具体是什么媒体类型(这不代表服务器端一定是以该类型存储资源的,参见后面“网关”一节的说明),如此,如果浏览器支持该媒体类型,则能够正常解析与展示。
也就是说,只要服务器端返回的资源格式是浏览器支持的 MIME 类型,浏览器就一定能够正确展示(而不管该资源在服务器端是怎么存储的)。
如此,我们在终端上只需要安装一个浏览器(而无需像过去那样安装上百个专用软件)就能浏览互联网上各种形式的信息。
这种架构使得浏览器成为万维网的入口,浏览器因此成为各公司和创业者的争夺焦点,在 90 年代掀起一场浏览器大战,其中最著名的两个角斗士是网景和微软。开始的时候微软压根不是网景的对手,但微软最终使用捆绑销售策略,在 Windows 98 中免费附赠 IE 浏览器,据此击败网景。IE 从此横着走了十几年,还产生了一款让开发者痛恨欲绝的钉子户——IE6。
HTML:
在万维网的 B/S 架构中,浏览器测负责资源的展示,具体来说是用一种叫 HTML 的标记语言来展示资源。
HTML 的全称是 Hyper Text Markup Language,即超文本标记语言,由伯纳斯·李和同事丹尼尔·康诺利于 1990 年设计。
在 HTML 中,通过各种标签(tag,如a、img、div)来标记文本的结构、格式或引用。浏览器不但可以展示不同媒体类型的资源,还能够在一篇文档(或叫页面)中组织和展示多种媒体类型的资源,这种页面我们叫超媒体页面。
可以通过head、body、div、p、tr、td 来管理文档的结构。
可以通过 i、b、h1 来表达文档的格式。
可以通过 a、img、audio、video 这些超链接标签给文档引入文本、图片、音频、视频资源,这些资源有可能和当前页面在同一个服务器上,也可能位于遥远的另一台服务器——万维网的资源仓库分布在全球各地。
随着层叠样式表 CSS 的出现,HTML 语言的重心逐渐转向表达文档的结构,而由 CSS 来负责文档的布局和样式。
浏览器随着 HTML、CSS、JavaScript 这些前端语言的发展而愈发强大起来,从最初只能展示基本的 HTML 静态页面,到可以通过 CSS 控制各种炫酷的样式和布局,到通过 JavaScript 实现动态交互,到 ajax 实现动态内容和信息流式交互。
网关:
伯纳斯·李在设计万维网时,世界上已经存在大量的信息系统,这些系统间的信息格式迥异,大多数并不符合万维网协议标准,但万维网不能抛弃这些既有信息。
伯纳斯·李提出了网关(Gateway)的概念来解决此问题。
网关其实就是一个文档格式转换器:将现有的不符合万维网标准的文档转换成标准文档,然后发给客户端。
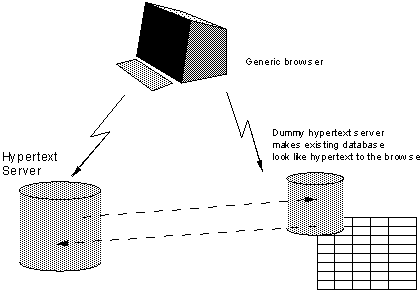
伯纳斯·李的网关模型
如上图,浏览器访问 Web 服务器(左侧那个 Hypertext Server),该服务器会去访问网关服务器(右侧小的那个),网关服务器将原始文档转换成符合万维网格式的文档后返回给 Web 服务器,Web 服务器再返回给浏览器。这里只是增加一层网关服务器,无需修改原始文档,也不用大面积改造 Web 服务器。
伯纳斯·李这个网关概念和我们今天说的网关服务器是类似的。我们今天所说的网关主要起到协议转换作用,它的一头通过 HTTP 协议和浏览器(或者代理)通信,另一头通过其他协议(FTP、STMP、fast-cgi 等)和其他应用程序通信。另外,今天的 Web 服务器大部分同时也是网关服务器,如 nginx:

今天的 Web 服务器网关
如图,如今网上很大部分内容都是由应用程序动态生成的,当浏览器访问 Web 服务器时,Web 服务器并不是在它本地直接找到资源并返回,而是通过诸如 fast-cgi 协议访问后面的应用程序服务,应用程序生成相关结果返回给 Web 服务器,Web 服务器再返回给浏览器。对于浏览器来说,该过程是透明的,所以对于浏览器来说,它就是 Web 服务器;对于应用程序来说,它将自己返回的 fast-cgi 格式数据转换成了 HTTP 协议格式数据,因而它是个网关——因而这种网关又叫做服务器端网关。
有了网关这层转换,就可以基于现有的数据、现有的服务(如邮件服务)对外提供统一的 HTTP 服务,从而高效快速地接入万维网。
