- 1、Kafka概念
- 2、kafka架构
- 3、Kafka消费模型
- 4、实现Kafka的生产端
- 5、实现Kafka的消费端
- 6、Flume整合Kafka
- 1、调整flume的配置文件,监控namenode的日志文件
- 2、启动flume
- 3、启动kafka控制台消费者查看数据
kafka是一个高吞吐的分布式消息系统,它类似HDFS用来存储数,但HDFS是持久化的,文件数据会一直保留,而Kafka只存储一段时间的数据,长时间不消费会自动删除,同时存储采用零拷贝技术,可以不需要再内存中消费资源
2、kafka架构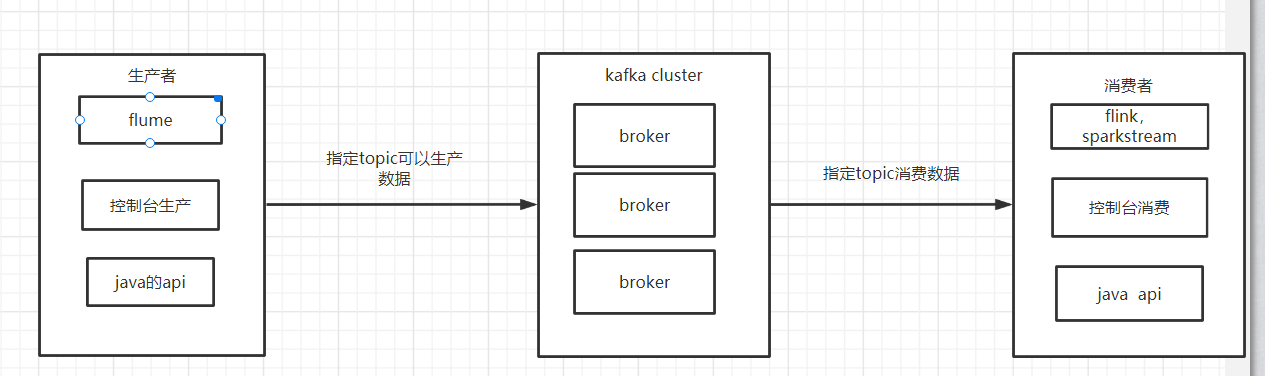
1、broker:kafka集群的server,可以负责处理读写消息并存储,多个broker是利用了zookeeper的协同服务,分布式可以做到数据的备份操作
2、topic:topic就相当于消息队列,本质也是K-V格式的,但其实每一个topic都可以分成多个partition分区的,而每一个分区就相当于一个小文件,一个partition对应一个broker,而一个broker可以管理多个partition
3、partition:每个partition内部的消息都是有序号offset提供的,都是进行排序的,这样方便在读写错误不用重头来。生产者在进行生产数据时,也可以自定义写到哪一个的partition中去,要实现负载均衡,类似于shuffle阶段的基于hashcode分区操作
4、中间消息采用零拷贝技术,数据不需要在内存中拷贝消耗资源,大大加快了速度,而且写入磁盘是有顺序的。常见的零拷贝技术:Linux的sendfile()和java NIO中的FileChannel.transferTo()
5、存储的是数据是根据自己指定的或者默认的策略进行一段时间的删除,并不是消费完就删除了
3、Kafka消费模型1、消费者需要消费kafka集群里面的数据,那么每一个consumer都需要维护好自己消费到哪一个offset
2、每个consumer都有自己对应的group,group内便是消息队列里的消费模型,各个group各自独立消费,互不影响,同时各个consumer消费不同的partition,因此一个消息在group内只消费一次
4、实现Kafka的生产端package com.dtc.bigdata.kafka;
import java.util.Properties;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaProducer {
public static void main(String[] args) {
Properties properties = new Properties();
//指定kafka的broker的地址
properties.setProperty("bootstrap.servers","master2:9092");
//设置key和value的序列化,没有会报"key.serializer"错误
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//创建生产者
org.apache.kafka.clients.producer.KafkaProducer<String, String> producer = new org.apache.kafka.clients.producer.KafkaProducer<>(properties);
//传入topic的值
//如果topic值不存在,则会自动创建一个分区为1,副本为1的topic
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("zhenyun", "zyliyuiyuizylzyl");
producer.send(producerRecord);
producer.flush();
producer.close();
}
}
package com.dtc.bigdata.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.Properties;
public class KafakaComsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "master2:9092");
//反序列化
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//增加组
properties.setProperty("group.id", "aaaa");
//显示最开始的数据
properties.put("auto.offset.reset", "earliest");
//创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
System.out.println("创建消费者成功");
//订阅topic
ArrayList<String> topics = new ArrayList<>();
topics.add("zhenyun");
consumer.subscribe(topics);
while (true) {
ConsumerRecords<String, String> poll = consumer.poll(1000);
Iterator<ConsumerRecord<String, String>> it = poll.iterator();
while (it.hasNext()) {
ConsumerRecord<String, String> consumerRecord = it.next();
//分别取topic,分区,偏移量,值
String topic = consumerRecord.topic();
int partition = consumerRecord.partition();
long offset = consumerRecord.offset();
String value = consumerRecord.value();
System.out.println(topic + "," + partition + "," + offset + "," + value);
}
}
}
}
agent.sources=s1
agent.channels=c1
agent.sinks=k1
agent.sources.s1.type=exec
#监听文件地址
agent.sources.s1.command=tail -F /usr/local/soft/hadoop-2.7.6/logs/hadoop-root-namenode-master.log
agent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100
#设置Kafka接收器
agent.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
agent.sinks.k1.brokerList=master:9092,node1:9092,node2:9092
#设置Kafka的Topic 如果topic不存在会自动创建一个topic,默认分区为1,副本为1
agent.sinks.k1.topic=hadoop-namenode-log
#设置序列化方式
agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder
#将三个主件串联起来
agent.sources.s1.channels=c1
agent.sinks.k1.channel=c1
#flume-ng agent -n agent -f ./FlumeToKafka.properties -Dflume.root.logger=DEBUG,console
#kafka-console-consumer.sh --zookeeper node1:2181 --from-beginning --topic flume
flume-ng agent -n agent -f ./FlumeToKafka.properties -Dflume.root.logger=INFO,console
kafka-console-consumer.sh --bootstrap-server master2:9092, --from-beginning --topic flume